
文章目录
- 深入浅出Java集合
-
- 一、Map的核心接口定义
- 二、Map家族的成员
-
- [1. HashMap🥝](#1. HashMap🥝)
- [2. LinkedHashMap:"有记忆"的HashMap🐦🔥](#2. LinkedHashMap:“有记忆”的HashMap🐦🔥)
- [3. TreeMap🥝](#3. TreeMap🥝)
- 三、Map使用的注意事项
- 四、总结
深入浅出Java集合
在Java集合框架中,Map是一个非常重要的分支,它不同于List、Set这些以"单列数据"为核心的集合,而是以"键值对(key-value)"的形式存储数据的双列集合,就像现实生活中的字典------通过"键"快速找到对应的"值"。今天我们就来好好聊聊Map家族的核心成员、特性以及使用场景。
双列集合的特点:
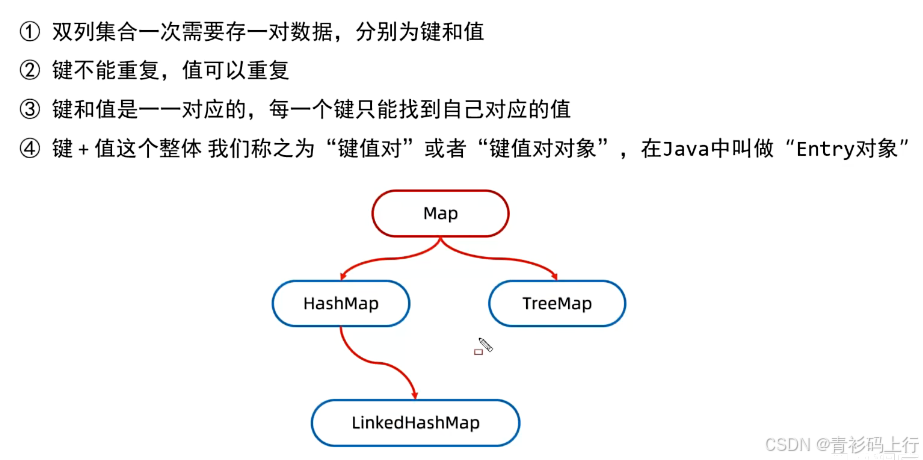
一、Map的核心接口定义
Map接口是整个家族的基石,它定义了键值对存储的基本规范:
- 键(key)不可重复,每个键最多对应一个值;
- 值(value)可以重复,多个键可以对应相同的值;
- 键和值都可以为
null(但不同实现类对null的支持不同)。
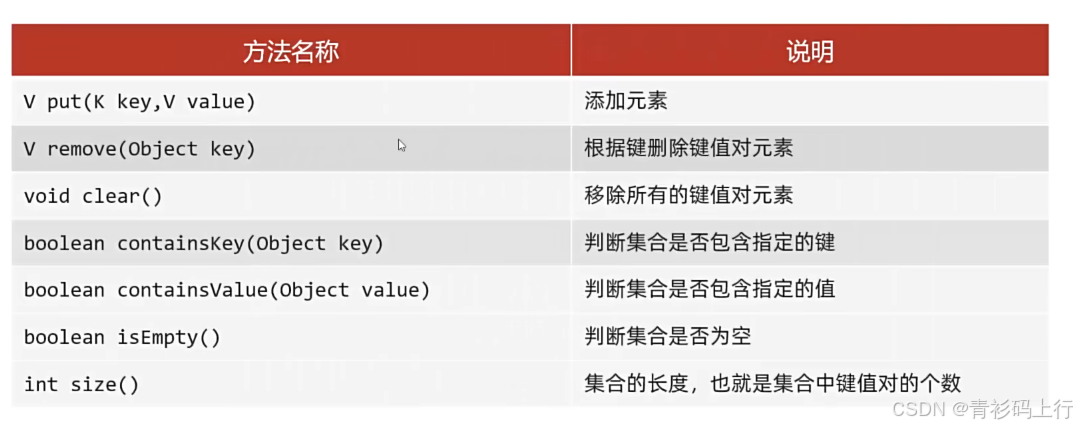
Map接口的核心方法包括:
put方法细节:添加 / 覆盖
添加:在添加数据的时候,如果键不存在,那么会直接把键值对对象添加到Map集合中,方法返回null
覆盖:在添加数据的时候,如果键是存在的,那么会把原有的键值对对象覆盖,并且返回原来覆盖的值
Map的三种遍历方式:
java
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class MapTraversalExample {
public static void main(String[] args) {
// 创建并初始化一个Map
Map<String, Integer> map = new HashMap<>();
map.put("Apple", 10);
map.put("Banana", 20);
map.put("Cherry", 30);
System.out.println("=== 1. 遍历键集(Key Set) ===");
// 1.1 增强for循环遍历键集
for (String key : map.keySet()) {
System.out.println("Key: " + key + ", Value: " + map.get(key));
}
// 1.2 迭代器遍历键集
Set<String> keySet = map.keySet();
Iterator<String> keyIterator = keySet.iterator();
while (keyIterator.hasNext()) {
String key = keyIterator.next();
System.out.println("Key: " + key + ", Value: " + map.get(key));
}
// 1.3 Lambda表达式遍历键集
map.keySet().forEach(key ->
System.out.println("Key: " + key + ", Value: " + map.get(key))
);
System.out.println("\n=== 2. 遍历值集(Value Collection) ===");
// 2.1 增强for循环遍历值集
for (Integer value : map.values()) {
System.out.println("Value: " + value);
}
// 2.2 迭代器遍历值集
Iterator<Integer> valueIterator = map.values().iterator();
while (valueIterator.hasNext()) {
System.out.println("Value: " + valueIterator.next());
}
// 2.3 Lambda表达式遍历值集
map.values().forEach(value -> System.out.println("Value: " + value));
System.out.println("\n=== 3. 遍历键值对(Entry Set) ===");
// 3.1 增强for循环遍历键值对
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
// 3.2 迭代器遍历键值对
Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator();
while (entryIterator.hasNext()) {
Map.Entry<String, Integer> entry = entryIterator.next();
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
// 3.3 Lambda表达式遍历键值对(直接使用Map的forEach方法)
map.forEach((key, value) ->
System.out.println("Key: " + key + ", Value: " + value)
);
}
}二、Map家族的成员
Map接口有多个实现类,每个类都有独特的底层结构和适用场景,我们重点看几个最常用的:
1. HashMap🥝
注意:依赖hashCode方法和equals方法保证键的唯一
如果键存储的是自定义对象,需要重写hashCode和equals方法
如果键存储的是非自定义对象,不需要重写hashCode和equals方法
- 底层结构 :JDK 1.8后采用 "数组+链表+红黑树" 实现。当链表长度超过8且数组容量≥64时,链表会转为红黑树,提升查询效率''【底层结构和HashSet差不多,都是哈希表结构】。
- 特性 :
- 无序(键值对的存储顺序与插入顺序无关);
- 允许键和值为
null(但键只能有一个null); - 线程不安全,效率高。
- 适用场景:大多数单线程环境下的键值对存储,追求查询、插入的高效性(平均时间复杂度接近O(1))。
java
import java.util.HashMap;
import java.util.Map;
public class HashMapDemo {
public static void main(String[] args) {
// 创建HashMap,键是字符串(名字),值是整数(年龄)
Map<String, Integer> userAges = new HashMap<>();
// 存数据:put(键, 值)
userAges.put("张三", 20);
userAges.put("李四", 22);
userAges.put("王五", 25);
userAges.put("张三", 21); // 键重复,会覆盖之前的20
// 查数据:get(键)
System.out.println("李四的年龄:" + userAges.get("李四")); // 输出22
// 遍历所有键值对(推荐用entrySet,效率高)
System.out.println("所有用户:");
for (Map.Entry<String, Integer> entry : userAges.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue() + "岁");
}
// 输出可能是:张三:21岁 李四:22岁 王五:25岁(顺序不固定)
// 删数据:remove(键)
userAges.remove("王五");
System.out.println("删除后是否有王五:" + userAges.containsKey("王五")); // 输出false
}
}2. LinkedHashMap:"有记忆"的HashMap🐦🔥
- 底层结构 :继承自HashMap ,额外通过双向链表记录键值对的插入顺序(或访问顺序)
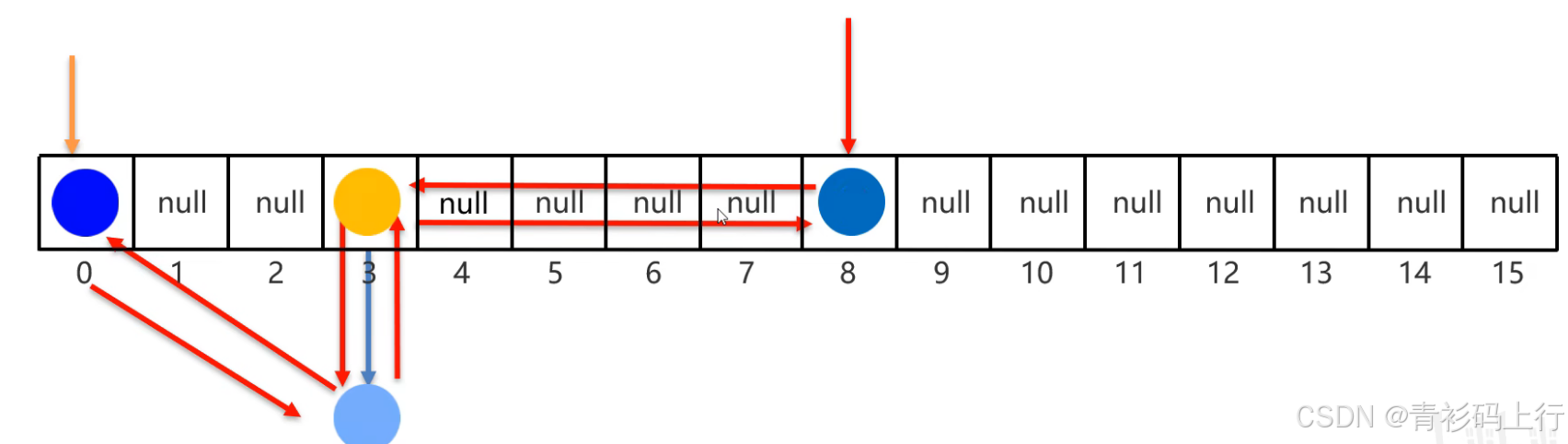
- 特性 :
- 有序:可以保持插入顺序(默认)或访问顺序(通过构造方法
LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)设置为true时,每次访问一个键值对会将其移到链表尾部); - 不重复,无索引
- 允许键和值为
null; - 线程不安全,效率略低于HashMap(因维护链表额外开销)。
- 有序:可以保持插入顺序(默认)或访问顺序(通过构造方法
- 适用场景:需要保留插入顺序(如日志记录)或实现LRU(最近最少使用)缓存策略的场景。
java
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapDemo {
public static void main(String[] args) {
// 1. 默认按插入顺序保存
Map<String, String> fruits = new LinkedHashMap<>();
fruits.put("apple", "苹果");
fruits.put("banana", "香蕉");
fruits.put("orange", "橙子");
System.out.println("插入顺序遍历:");
fruits.forEach((k, v) -> System.out.println(k + "=" + v));
// 输出:apple=苹果 banana=香蕉 orange=橙子(和插入顺序一致)
// 2. 按访问顺序(最近访问的放最后),可实现LRU缓存
// 构造方法:容量16,负载因子0.75,accessOrder=true(访问顺序)
Map<String, Integer> lruCache = new LinkedHashMap<>(16, 0.75f, true);
lruCache.put("a", 1);
lruCache.put("b", 2);
lruCache.put("c", 3);
lruCache.get("a"); // 访问a,会把a移到最后
System.out.println("访问a后顺序:");
lruCache.forEach((k, v) -> System.out.print(k + " ")); // 输出:b c a
lruCache.put("d", 4); // 新增d,顺序变为b c a d
System.out.println("\n新增d后顺序:");
lruCache.forEach((k, v) -> System.out.print(k + " ")); // 输出:b c a d
// 当容量满时,最早没被访问的(比如b)会被自动删除,这就是LRU缓存的核心
}
}3. TreeMap🥝
- 底层结构 :基于 红黑树 实现。
- 特性 :
- 有序:默认按键的自然顺序(如数字从小到大、字符串字典序)排序,也可通过代码书写两种排序规则:①
实现Comparator接口自定义排序规则 ②创建集合时传递Comparator比较器对象,指定比较规则 - 不重复,无索引
- 不允许键为
null(值可以为null); - 线程不安全。
- 有序:默认按键的自然顺序(如数字从小到大、字符串字典序)排序,也可通过代码书写两种排序规则:①
- 适用场景:需要对键进行排序的场景,例如实现排行榜、按日期排序数据等。查询、插入时间复杂度为O(log n)。
java
public class TreeMapDemo {
public static void main(String[] args) {
//默认升序排列
TreeMap<Integer,String > tp2 = new TreeMap<>();
tp2.put(1, "糖果");
tp2.put(3, "双皮奶");
tp2.put(2, "姜撞奶");
tp2.put(4, "咖啡");
System.out.println(tp2);
// 输出:{1=糖果, 2=姜撞奶, 3=双皮奶, 4=咖啡}
System.out.println("=========");
//降序排列
TreeMap<Integer, String> tp = new TreeMap<>((o1, o2) -> {
// o1:当前要添加的元素
// o2:表示已经在红黑树中存在的元素
return o2 - o1;
}
);
tp.put(1, "糖果");
tp.put(3, "双皮奶");
tp.put(2, "姜撞奶");
tp.put(4, "咖啡");
System.out.println(tp);
// 输出:{4=咖啡, 3=双皮奶, 2=姜撞奶, 1=糖果}
}
}三、Map使用的注意事项
-
HashMap的扩容问题:
- 初始容量默认16,负载因子0.75。当元素数量超过"容量×负载因子"时,会触发扩容(容量翻倍),扩容时需重新计算哈希并迁移元素,成本较高。
- 建议:根据预估数据量设置初始容量(如预估1000个元素,可设为
1000/0.75≈1334),减少扩容次数。
-
TreeMap的键必须可比较:
- 若键的类未实现
Comparable接口,且未指定Comparator,会抛出ClassCastException。
- 若键的类未实现
-
遍历方式的选择:
-
遍历所有键值对时,
entrySet()比"先keySet()再get(key)"更高效(避免重复查询)。 -
示例:
java// 推荐方式 for (Map.Entry<String, Integer> entry : map.entrySet()) { String key = entry.getKey(); Integer value = entry.getValue(); }
-
四、总结
使用场景:
- 追求速度选HashMap;
- 需要排序选TreeMap;
- 要保留顺序选LinkedHashMap;
如果我的内容对你有帮助,请 点赞 , 评论 , 收藏 。创作不易,大家的支持就是我坚持下去的动力!
