摘要
自监督学习(Self-Supervised Learning, SSL)在3D医学图像分析中已展现出良好的效果。然而,预训练阶段缺乏高层语义信息,严重制约了下游任务的性能。我们观察到,3D医学图像中包含相对一致的上下文位置信息,即不同器官之间具有稳定的几何关系,这为我们提供了一种在预训练阶段学习一致语义表示的潜在途径。
本文提出了一种简单而有效 的体积对比学习框架(Volume Contrast, VoCo) ,以利用这种上下文位置先验进行预训练。具体而言,我们首先从不同区域生成一组"基础裁剪块"(base crops),并通过强制它们之间的特征差异性,将其视为不同区域的"类别标签"。随后,我们随机裁剪子体积(sub-volumes),并通过对比其与各个基础裁剪块的相似性,预测该子体积属于哪个类别(即位于哪个区域)------这本质上是在预测子体积的上下文位置。
通过这一预训练任务,VoCo 能在无需人工标注的情况下,将上下文位置先验隐式地编码到模型的表示中,从而有效提升那些依赖高层语义信息的下游任务性能。在六个下游任务上的大量实验结果表明,VoCo 具有显著优越的有效性。
图1.
(a) 在3D医学图像中,上下文位置(即不同器官之间的几何关系)具有相对一致性。
(b) 为利用这种上下文位置先验进行预训练,我们提出了用于3D医学图像分析的体积对比学习框架(VoCo)。
1. 引言
深度学习在3D医学图像分析中取得了卓越成果,但其性能严重受限于专家标注的高昂成本。为解决这一问题,自监督学习(SSL) 因其无需标注即可学习有效表示的能力,受到了广泛关注,已成为3D医学图像分析中一种重要的标签高效解决方案。
现有方法大多基于信息重建来学习对数据增强不变的表示:首先对图像施加强数据增强,然后尝试重建原始信息。例如:
-
•
旋转-重建方法(如 rotate-and-reconstruct)通过随机旋转3D体数据并让模型恢复原始方向,促使模型学习旋转不变特征;
-
•
多视角重建方法(如 PCRL、GVSL)通过裁剪全局与局部图像块,进行多尺度重建,或利用仿射变换探索多扫描间的几何相似性;
-
•
掩码重建方法(如受 MAE 启发的策略)通过遮盖部分图像并重建缺失像素来学习表示。
尽管这些方法取得了不错的效果,但已有研究指出:预训练阶段缺乏高层语义信息,会严重限制下游任务(如器官分割、病灶检测)的性能。
为应对这一挑战,我们认为应在3D医学图像预训练中引入更强的高层语义 。具体而言,应进一步挖掘上下文位置先验(contextual position priors)。如**图1(a)所示,**在3D医学图像中,不同器官(即语义区域)具有相对固定的空间位置和解剖形态。这种器官间稳定的几何关系,为我们提供了一种学习一致语义表示的新思路。
为此,本文提出一种上下文位置预测的预训练任务,旨在将位置先验编码进模型表示中,从而提升依赖高层语义的下游任务性能。
我们提出的 VoCo 框架 如图1(b)所示,其核心流程如下:
-
从图像不同位置裁剪一组互不重叠的基础体积块(base crops),并通过约束其特征差异性,将其视为不同空间区域的"伪类别";
-
随机裁剪新的子体积,并通过对比学习计算其与各个基础块的相似度,预测它"属于哪个区域"------即预测其上下文位置。
通过这一任务,VoCo 在无监督条件下隐式地学习了器官的空间布局和语义结构。大量实验表明,VoCo 在六个下游任务上显著优于当前最先进的3D医学图像自监督学习方法。
【
1. 问题背景:为什么现有SSL方法在医学图像中效果有限?
-
•
医学图像(如CT、MRI)中,器官的位置、形状具有高度一致性(例如肝脏总在右上腹,心脏在胸腔中央)。
-
•
现有SSL方法(如旋转预测、掩码重建)主要学习低层纹理或局部结构 ,缺乏对全局语义布局(如"这是肝脏区域")的理解。
-
•
下游任务(如肿瘤分割、器官定位)需要模型理解"这是什么器官、在什么位置",而不仅仅是"像素值是多少"。
2. VoCo 的核心创新:用"位置"作为语义代理
-
•
VoCo 不依赖真实标签 ,而是将空间位置本身作为监督信号。
-
•
它假设:不同空间区域对应不同语义内容(如左肺 vs 右肾),因此预测"一个子块来自哪个区域"就等价于学习高层语义。
-
•
通过对比学习,模型学会区分不同区域的特征,从而隐式建模器官的空间分布规律。
3. 技术实现:两阶段对比学习
-
•
第一阶段:构建"伪类别中心"
-
•
从整幅3D图像中固定裁剪 K 个不重叠的区域(如8个),作为"基础块"。
-
•
通过损失函数(如最大化它们之间的特征距离)确保这些基础块代表不同语义区域。
-
-
•
第二阶段:预测随机子块的来源区域
-
•
随机裁剪一个新的子体积。
-
•
计算它与 K 个基础块的相似度(如余弦相似度)。
-
•
用 InfoNCE 等对比损失,让模型预测该子块最可能来自哪个基础区域。
-
✅ 这本质上是一种无监督聚类+对比学习的结合:基础块充当"聚类中心",随机子块被分配到最相似的中心。
4. 为什么有效?
-
•
利用了医学图像解剖结构稳定的先验知识。
-
•
将空间上下文转化为可学习的监督信号。
-
•
避免了重建任务中常见的"只学低频信息"问题(如MAE容易只恢复模糊轮廓)。
-
•
对比学习天然适合捕捉判别性语义特征。
5. 优势总结
-
•
简单:无需复杂重建头或额外网络分支。
-
•
有效:在多个任务(分割、分类、检测)上超越SOTA。
-
•
通用:适用于各种3D医学模态(CT、MRI等)
】
图2. 典型的对比学习框架。
(a) 实例级对比学习 (Instance-level contrastive learning)10, 11, 29, 22, 7 通过对输入数据施加强数据增强或模型扰动,生成同一实例的不同视角(views),然后约束这些视角之间的一致性。
(b) 原型级对比学习 (Prototype-level contrastive learning)5, 6, 55, 44, 15, 16 通过两种方式之一获得"原型"(prototypes)作为类别分配:(1) 在线聚类,或 (2) 随机初始化后在线更新;随后利用这些原型对每个输入图像进行对比学习。
(c) 我们的 VoCo 遵循原型级对比学习的思想。具体而言,我们并未采用耗时的在线聚类与更新过程 ,而是利用3D医学图像中宝贵的上下文位置先验 ,通过基础裁剪块(base crops)来生成原型(即"基" bases)。
{
-
•
实例级对比学习:把同一张图的不同增强版本视为"正样本对",与其他图像的增强版本(负样本)对比,如 SimCLR、MoCo。
-
•
原型级对比学习:将特征空间划分为若干"原型"(类似聚类中心),每个样本被分配到某个原型,学习目标是让样本靠近其所属原型,远离其他原型,如 SwAV、DeepCluster。
-
•
VoCo 的创新点 :在医学图像中,空间位置天然对应语义类别 (如"左肺区域"、"肝脏区域"),因此无需复杂聚类,直接用固定位置裁剪的图像块作为原型,既高效又符合医学先验。
}
2. 相关工作
本节首先介绍先前主流的对比学习范式;然后综述现有的医学图像分析(尤其是3D医学图像)中的自监督学习方法;最后回顾与位置相关的自监督学习方法,并与我们的方法进行比较,突出其差异。
对比学习(Contrastive Learning)
对比学习是自监督学习中的主流范式之一,其目标是在无需额外标注 的情况下,通过对比样本的正负对来学习一致的表示 10, 6, 29, 11。根据文献 6,对比学习主要分为实例级 (instance-level)和原型级(prototype-level)两类,如图2所示。
-
•
实例级对比学习 10, 11, 29, 22, 7 通过对输入图像施加不同的数据增强或模型扰动,生成同一实例的多个视图,并比较它们的特征表示。
-
•
原型级对比学习 5, 6, 55, 44, 15, 16 则提出为每个输入图像生成"原型"(也称为聚类中心或基),并基于这些原型进行对比学习。
具体而言,生成原型主要有两种典型方式:
-
Caron 等人提出的 DeepCluster 5 通过对整个数据集进行在线聚类来生成原型。然而,在大规模数据集上计算聚类非常耗时。
-
因此,一些近期工作 6, 55, 15, 16 提出随机初始化一组原型 ,然后在训练过程中通过反向传播对其进行更新,取得了良好效果。但这类方法无法保证随机初始化的原型在训练中能被有效优化。
我们的 VoCo 遵循原型级对比学习的基本思想 。如图2(c)所示,为解决上述问题,VoCo 并未采用随机初始化并更新原型的方式 ,而是利用3D医学图像中宝贵的上下文位置先验 ,通过从固定空间位置裁剪的"基础块"(base crops)来生成原型。该方法无需对大规模数据集进行耗时的聚类计算。
医学图像分析中的自监督学习(SSL for Medical Image Analysis)
由于在标签高效学习 方面具有巨大潜力 29, 56, 59, 57, 58, 37,自监督学习在医学图像分析领域也受到了广泛关注 68, 32, 31, 50, 19。现有方法主要基于对比式自监督学习 69。
具体而言:
-
•
Zhou 等人 67 将 Mixup 64 引入 MoCo 29,以增强 InfoNCE 损失 43 中正负样本的多样性。
-
•
Azizi 等人采用多实例学习,比较来自同一患者的多个图像视图。
此外,也有大量方法 25, 68, 69 通过从原始图像中恢复低层信息 来监督模型。在3D医学图像分析中,重建原始信息是一种流行的预训练任务 49, 50, 69。这些方法通常先对图像施加强数据增强(例如:旋转 50, 73, 51、多视角裁剪 68, 69, 32、掩码 13, 71, 54),然后通过重建原始3D信息来监督模型。
尽管这些方法取得了不错的效果,但大多数仍严重忽视了将高层语义融入模型表示的重要性,这极大地限制了下游任务的性能。
与位置相关的自监督学习(Position-related SSL)
在自然图像领域,已有若干工作探索了与位置相关的自监督学习方法 8, 9, 40, 46, 42, 17, 62, 66:
-
•
Noroozi 等人 42 提出预测一组被打乱顺序的图像块的原始排列顺序。
-
•
Zhai 等人 62 和 Caron 等人 8 提出训练 Vision Transformer(ViT)18 来预测每个输入图像块的位置。
然而,由于自然图像中不同物体的几何关系并不一致 ,仅凭视觉外观很难有效学习到一致的位置表示(如文献 66 所指出)。此外,这些方法 62, 8, 66 通常直接使用一个线性层输出位置坐标,这种方式缺乏可解释性,属于"黑箱"操作。
在本文中,我们将上下文位置预测 这一预训练任务引入3D医学图像领域 。由于医学图像中不同器官之间的几何关系高度一致 ,这为我们提供了学习一致语义表示的可靠先验。与以往方法不同,我们提出了一种全新的位置预测范式 :
不是通过线性层直接回归位置坐标,而是基于体积对比(volume contrast)------这种方式更直观、更有效。
【
总结:VoCo 的三大创新点
-
利用医学先验:将稳定的器官空间布局作为无监督信号。
-
高效原型生成:用固定位置裁剪代替耗时聚类或随机初始化。
-
可解释的位置预测:通过对比学习实现"区域归属判断",而非黑箱坐标回归。
】
3. 方法
本节首先在 3.1 节介绍我们提出的 VoCo 框架的整体结构;随后在 3.2 节阐述上下文位置预测的具体过程;最后在 3.3 节描述 VoCo 框架中通过体积对比(volume contrast)实现的正则化机制。
3.1 整体框架
我们提出的 VoCo 框架如图3所示,包含两个分支:上下文位置预测分支 和正则化分支。
-
•
预测分支 用于预测不同裁剪体积之间的上下文位置关系。
具体而言,给定一个输入体积,我们首先将其裁剪为若干个互不重叠的基础体积块 (base volumes),这些基础块覆盖整个输入体积。
然后,我们随机裁剪一个子体积 ,并通过一个典型主干网络(如 CNN 30 或 Transformer 18)将其映射到高维特征空间。
目标是预测该随机裁剪体积与各个基础体积块之间的上下文位置关系。
与以往工作 62, 9, 8, 66 中使用线性分类器直接预测位置坐标不同,本文提出通过体积对比(volume contrast)来实现这一目标。我们设计了一个预测损失函数 Lpred 来监督最终的预测结果。
-
•
此外,我们还引入了一个正则化损失函数 Lreg,通过增大不同基础块之间的特征距离 ,来增强它们作为"类别分配"(class assignments)的判别性。
具体细节将在 3.2 节和 3.3 节中详细介绍。
3.2 上下文位置预测
基础裁剪与随机裁剪
给定一个输入体积,我们首先将其裁剪为 n 个互不重叠的基础体积块 (base crops),这些块覆盖整个输入体积。
我们将这些基础块提取的特征 z作为类别分配(class assignments),即不同空间位置的原型级特征(我们称之为"bases")。
随后,遵循以往自监督学习方法 10, 11, 29,我们使用一个由线性层组成的投影头(projector)将 z 投影到潜在特征空间,得到 q。
接着,我们随机裁剪一个子体积,并通过相同的主干网络和投影头将其映射为高维特征 p。
用于上下文位置预测的体积对比
在提取主干和投影头的特征后,我们首先对特征进行 3D 自适应平均池化(3D adaptive average pooling),将其压缩为一维向量:
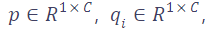
,其中 C 为通道数(本文经验性地设为 2048,与 10, 11, 29 一致)。
然后,我们计算随机裁剪特征 � 与每个基础块特征 �� 之间的相似度 logits ��。具体使用余弦相似度:
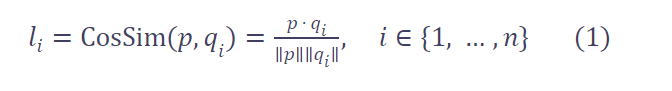
其中 li 表示 p 与第 i 个基础块的相似度,取值范围为 0, 1。
值得注意的是,在计算公式 (1) 时,我们对 qi 的梯度进行截断(stop gradient),以避免特征坍塌(feature collapse)10, 11, 6。
直观上,更高的 li 意味着 p 与第 i 个基础块在空间上重叠的可能性更大 。
因此,我们可以将相似度值直接与位置信息关联:li 越高,说明该子体积越可能位于第 i 个基础区域。
与使用"黑箱"线性层预测位置不同,VoCo 通过体积对比进行位置预测,更加直观且有效。
位置标签的生成
位置标签的生成过程如图4所示。
例如,当我们将输入划分为 n=4×4=16 个基础块时,就对应 16 个类别分配。
然后,我们计算随机裁剪体积与每个基础块的空间重叠面积 ,并将重叠面积的比例作为软标签(soft label)y,其值也在 0, 1 范围内。
这样,我们就可以通过计算预测 logits l 与位置标签 y 之间的距离来监督模型。
基础块数量 n 的设置将在第 4.4 节讨论。
上下文位置预测的损失函数
预测损失函数 Lpred 基于熵的思想 设计。
首先,计算预测值 l 与标签 y 之间的绝对误差:
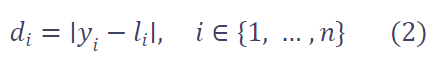
然后,定义预测损失为:
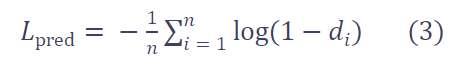
值得注意的是 :VoCo 预测的是一个体积的上下文位置分布 (即可能与多个基础块重叠),不要求一一对应 。
例如在图4中,一个随机裁剪块可能同时与第 5、6、9、10 个基础块重叠,因此对应的 yi>0 且 li 也应较高。
损失函数通过衡量 li 与 yi 的整体匹配程度进行优化。
3.3 用于正则化的体积对比
为了提升"类别分配"(即基础块特征)的判别性,我们希望不同基础块对应不同的语义内容 (如不同器官),因此应增大它们在高维特征空间中的差异。
为此,我们设计了一个正则化损失 Lreg,用于增大不同基础块特征 z 之间的差异。
具体地,给定投影后的基础特征 qi,我们计算任意两个不同基础块之间的余弦相似度:
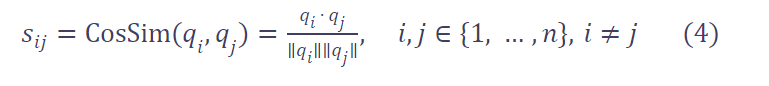
我们的目标是让 Sij→0,即强制不同基础块的特征相互正交(正交性增强判别性)。
因此,正则化损失定义为:
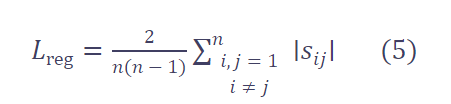
通过该损失,我们希望优化 q 使其成为线性无关的基(linearly independent bases):
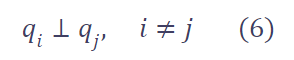
这样,我们就能学习到一组覆盖高维特征空间各个方向的判别性原型,从而更好地监督位置预测任务。
总体损失函数
最终的总损失函数是预测损失与正则化损失的加权和:
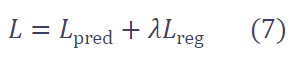
其中 � 用于平衡两项损失的贡献。在实验中,我们经验性地将 � 设为 1.0,因为我们认为两项同等重要。
关于 � 的消融实验详见补充材料


【
一、什么是"梯度截断"(Stop Gradient)?
梯度截断 (Stop Gradient / Gradient Stop)是一种在深度学习中阻止反向传播(backpropagation)通过某一部分计算图的技术。
-
•
在 PyTorch 中,可通过
.detach()实现; -
•
在 TensorFlow/JAX 中,也有类似机制(如
stop_gradient)。
作用 :让某一部分的参数在当前损失计算中不被更新,即使它参与了前向计算。
二、"两个分支"指的是什么?
在对比学习中(如 MoCo、SimCLR、VoCo),"两个分支"通常指:
-
在线分支 (online branch):包含主干网络 + 投影头,参数会被更新;
-
目标分支 (target branch)或固定分支 :其输出作为对比目标,参数被冻结或缓慢更新(如 EMA)。
但在 VoCo 的上下文中,这两个"分支"更具体地指:
-
•
随机裁剪块的特征 p:来自在线网络,梯度正常传播;
-
•
基础块的特征 qi:作为"原型"或"目标",梯度被截断 (
.detach()),不参与参数更新。
】
4. 实验
本节首先介绍预训练和下游任务所使用的数据集;然后简要说明 VoCo 的实现细节;最后,我们将 VoCo 与当前最先进的 3D 医学图像自监督学习(SSL)方法进行详细对比。更多细节见补充材料。
4.1 数据集
预训练数据集
为与先前工作 50, 54, 68, 69, 13, 71 进行公平比较,我们在相同的三个公开数据集上进行预训练实验,即:
-
•
BTCV 35(腹部 CT)
-
•
TCIA Covid-19 14(胸部 CT)
-
•
LUNA 47(肺部 CT)
总计约 1.6k 例 CT 扫描用于预训练。
注意 :在 BTCV 下游任务实验中,为与 71, 13 公平比较,我们仅使用 BTCV 和 TCIA Covid-19 进行预训练;
对于其他下游任务,则使用全部三个数据集进行预训练。详情见补充材料。
下游任务数据集
为评估 VoCo 的有效性,我们在六个公开数据集上进行下游实验:
-
•
BTCV 35(腹部器官分割)
-
•
LiTs 4(肝脏肿瘤分割)
-
•
MSD Spleen 1(脾脏分割)
-
•
MM-WHS 72(心脏多器官分割)
-
•
BraTS 21 48(脑肿瘤 MRI 分割)
-
•
CC-CCII 65(COVID-19 CT 分类)
其中前五个为分割任务 ,CC-CCII 为分类任务。
关键设置:
•
除 BTCV 外,其余下游数据集在预训练阶段完全未见过(unseen);
•
为验证跨模态泛化能力 ,我们将在 CT 上预训练的模型 迁移到 MRI 数据集 BraTS 21;
•
所有实验设置与先前工作 13, 71, 26, 54, 32 保持一致;
•
我们还评估了在 2D 医学数据集 53 上的性能。
4.2 实现细节
-
•
主干网络 :遵循 50, 54,使用 SwinUNETR 26 进行预训练和下游任务;
-
•
优化器:AdamW 38 + 余弦学习率调度;
-
•
训练步数:预训练 100K 步;
-
•
推理方式:采用滑动窗口(slicing window inference),与 50, 54, 13, 71 保持一致;
-
•
公平性原则 :不使用基础模型(foundation models)或后处理技术 34, 36,以评估 VoCo 本身的纯有效性。
对比方法
我们与两类 SSL 方法对比:
-
通用 SSL 方法:
-
•
MAE 28, 13(掩码自编码器代表)
-
•
MoCo v3 29, 12(对比学习代表)
-
•
SimCLR 10、SimMIM 61(结果引自 13)
-
-
位置感知方法:
-
•
Jigsaw 9(拼图预测)
-
•
PositionLabel 66(位置标签预测)
-
-
医学专用 SSL 方法:包括 PCRL、GVSL、GL-MAE 等 SOTA 方法。
公平性说明:由于 3D 医学图像计算成本高,无法使用大 batch size,因此所有方法均采用与 MAE/MoCo 在医学图像上的适配设置。
4.3 下游任务实验结果
1. 在 BTCV 数据集上显著超越现有方法
-
•
基线 :从零训练(scratch)的 SwinUNETR 仅达 80.53% Dice;
-
•
VoCo 预训练 :提升 3.32% ,达 83.85% Dice;
-
•
对比 SOTA :超越当前最佳方法 GL-MAE(82.01%)1.84% ,提升显著。
关键观察:
•
通用 SSL 方法(如 MoCo v3 仅 79.54%)表现较差,因其依赖大 batch size 获取负样本,这在 3D 医学图像中不现实;
•
医学图像中"不同图像间的负样本关系"不成立(因患者解剖结构差异大);
•
位置感知方法(Jigsaw、PositionLabel)也明显弱于 VoCo。
2. 在未见数据集上表现优异
-
•
LiTs(肝脏):
-
•
SwinUNETR + VoCo:96.52% Dice(+3.10%)
-
•
3D UNet + VoCo:96.03% Dice → 证明 VoCo 适用于不同网络架构
-
-
•
MSD Spleen & MM-WHS:
-
•
VoCo 达 96.34% (脾)和 90.54% (心脏),均超越 GVSL(SOTA)
-
3. 跨模态泛化能力(CT → MRI)
-
•
在 BraTS 21 (脑肿瘤 MRI)上,VoCo 达 78.53% Dice ,优于所有现有方法,证明其跨模态迁移能力。
4. 分类任务同样有效
-
•
在 CC-CCII (COVID-19 分类)上,VoCo 达 90.83% 准确率,显著优于复现的其他 SSL 方法。
5. 六任务综合对比
-
•
如图5所示,VoCo 在所有六个下游任务 上均显著领先现有 SOTA 方法。
4.4 消融实验
1. 损失函数有效性
| 方法 | BTCV Dice | MM-WHS Dice |
|---|---|---|
| Scratch | 80.53% | 86.11% |
| + �pred | 82.96% | 88.82% |
| + �pred+�reg | 83.85% | 90.54% |
→ 证明:位置预测任务 (�pred)是核心,正则化损失(�reg)进一步提升判别性。
2. 基础块数量 � 的影响
-
•
由于 CT 在 Z 轴(层厚方向)分辨率不一致,难以在 Z 方向裁剪多个基础块(会导致尺度不一致);
-
•
实验发现:
-
•
�=2×2×1:性能较低(BTCV 81.56%)
-
•
�=4×4×1:性能最佳(BTCV 83.85%)
-
•
�=5×5×1 或 4×4×2:无进一步提升,甚至下降
-
结论 :�=4×4×1 是性能与效率的最佳平衡点。
4.5 可视化结果
-
•
图6展示了 BTCV 上的分割结果;
-
•
VoCo 的预测更完整、边界更准确,尤其在小器官(如胰腺、肾脏)上优势明显;
-
•
更多可视化见补充材料。
| 下游任务 | 预训练数据 | |------|-------| | **BTCV 分割** | BTCV + TCIA(约 1000+ CT) | |--------------------------------------------------|------------------------------------| | **LiTs / MSD Spleen / MM-WHS / BraTS / CC-CCII** | **BTCV + TCIA + LUNA**(全部 1.6k CT) | * • 的 Z 间距(slice thickness)常不一致(如 1mm vs 5mm),强行裁剪会导致几何失真; * • **n=4×4×1 的合理性** : 覆盖腹部主要器官(肝、脾、肾、胰等),又不至于过细导致噪声。 *** ** * ** *** #### 🔍 **4. 实验设计的严谨性** * • **公平比较**:统一主干(SwinUNETR)、统一推理方式(滑动窗口); * • **多任务验证**:分割 + 分类,CT + MRI,seen + unseen 数据; * • **多架构验证**:SwinUNETR + 3D UNet,证明方法通用性。 #### 5.模型没见过脑部 MRI,为何能在 BraTS(脑肿瘤 MRI)上表现好? 这是 跨模态(CT → MRI) 的迁移能力,其成功依赖于以下几点: ##### 1. 学到的是"通用解剖空间先验" ,而非具体器官外观 * • VoCo 学到的核心知识是:"不同语义区域在3D空间中有稳定相对位置" 。 * • 这种先验在所有人体解剖结构中都成立: * • 腹部:肝在右,脾在左; * • 胸部:心脏居中偏左,肺在两侧; * • 头部:左右脑对称,脑室居中。 * • 因此,即使没见过脑部,模型也泛化了"器官有固定空间布局"这一高层语义规律。 ##### 2. 预训练数据覆盖多部位 CT,增强了泛化性 * • BTCV:腹部(肝、脾、肾等) * • TCIA:胸部(肺、心脏) * • LUNA:肺部(结节、气管) * • → 模型见过多种解剖结构的空间组织方式,学会了"如何建模位置语义",而非死记硬背某个器官。 ##### 3. MRI 与 CT 共享解剖坐标系 * • 尽管模态不同(CT 看密度,MRI 看信号),但人体解剖结构的空间关系是一致的。 * • 模型在 CT 上学到的"位置编码能力",可迁移到 MRI 的相同空间框架中。 ##### 4. 下游微调(fine-tuning) * • 在 BraTS 实验中,预训练模型会在 BraTS 的 MRI 数据上进行微调(只是预训练阶段没见过它)。 * • 预训练提供良好的初始化(如空间注意力、区域判别能力),让微调更快、更稳、性能更高。
4.4
基块数量(Number of bases) 。我们进一步评估了 VoCo 中基块数量 n 的不同设置。在消融实验中,我们比较了不同 n 值的效果,如表7所示。值得注意的是,由于 ROI(感兴趣区域)在 Z 方向(即切片堆叠方向)上尺寸不一致,若在 Z 方向裁剪多个基块是不现实的------因为裁剪后必须对体数据进行重采样缩放,这会导致体数据尺度不一致。此外,受计算资源限制,增加 n 的值会带来高昂的计算成本。如表7所示,当 n = 2×2×1 时,VoCo 在 BTCV 和 MM-WHS 数据集上仅分别达到 81.56% 和 86.73% 的 Dice 分数。当我们将 n 增加到 3×3×1 和 4×4×1 时,性能明显提升。特别是当 n = 4×4×1 时,我们在 BTCV 和 MM-WHS 上分别达到了 83.85% 和 90.54%。然而,我们观察到更高的 n 值(如 5×5×1)并不能进一步提升性能。我们还进一步验证了在 Z 方向上生成基块的效果,结果表明 3×3×2 和 4×4×2 并未带来性能提升。因此,为了在性能和效率之间取得平衡,我们在 VoCo 中将 n 设置为 4×4×1。由此可见,n 的设置对 VoCo 至关重要。
1. "Number of bases. We further evaluate different settings of the number of bases n in VoCo. "
-
•
"基块(bases)" 是 VoCo 方法中的核心概念,可以理解为"从3D体数据中采样出的局部3D子块",用于后续对比学习或特征增强。
-
•
这里"n"指的是在空间上划分多少个这样的基块 ,比如
4×4×1表示在 X-Y 平面划分 4×4 个块,在 Z 方向只取 1 层(即不划分)。 -
•
研究者想探索:划分多少个基块最合适?太多或太少对性能有何影响?
2. "It is worth noting that due to the ROI size inconsistency in the Z direction... "
-
•
医学图像(如 CT/MRI)通常是各向异性的:X-Y 分辨率高,Z 方向(层厚)分辨率低且层间距不一致。
-
•
如果在 Z 方向也像 X-Y 那样划分多个块(比如
4×4×2),就需要对每个块做重采样(resize) ,以统一分辨率或尺寸。 -
•
但重采样会扭曲解剖结构、引入插值误差、破坏空间一致性,反而损害模型性能。
-
•
✅ 所以作者选择不在 Z 方向划分多个块 ,即 Z 维度始终为 1(如
n×n×1)。
3. "due to the computation limitation, it is costly to increase the values of n. "
-
•
每增加一个基块,就意味着模型要处理更多局部3D块 → 更多计算量、显存占用、训练时间。
-
•
尤其是 3D CNN 本身计算开销就大,再叠加多个基块,很容易超出 GPU 显存或训练预算。
-
•
✅ 所以"n 不能无限增大",必须在性能和效率之间权衡。
4. "As shown in Table 7... with n = 2×2×1... only achieves 81.56%... "
-
•
实验数据表明:基块太少(2×2×1)→ 性能差。
-
•
原因:局部上下文信息不足,模型难以学习到足够的空间变化和结构多样性。
5. "When we increase n to 3×3×1 and 4×4×1, performance improved obviously... "
-
•
增加基块数量 → 模型看到更多局部区域 → 增强了空间多样性感知能力 → 提升分割精度。
-
•
特别是
4×4×1时,Dice 分数显著提升(BTCV +2.3%,MM-WHS +3.8%),说明此时达到了一个性能拐点。
6. "However, higher n (5×5×1) cannot further bring higher performance. "
-
•
继续增加到
5×5×1,性能不再提升甚至可能下降。 -
•
可能原因:
-
•
基块过多 → 每个块太小 → 丢失语义信息;
-
•
训练不稳定、过拟合风险增加;
-
•
数据增强或对比学习策略无法有效利用过多基块。
-
7. "We further verify... 3×3×2 and 4×4×2 cannot yield improvements. "
-
•
尝试在 Z 方向也划分(如
3×3×2),即每个样本生成 2 个 Z 层的基块。 -
•
但如前所述,Z 方向分辨率低、需重采样 → 引入噪声和失真 → 性能反而下降或持平。
-
•
✅ 验证了"不在 Z 方向划分"是合理选择。
8. "Thus, aiming to balance performance and efficiency, we set n as 4×4×1 in VoCo. "
-
•
最终选择
4×4×1:在 X-Y 平面划分 16 个基块,在 Z 方向不划分。 -
•
这个设置:
-
•
性能足够好(接近饱和);
-
•
计算开销可控;
-
•
避免 Z 方向重采样问题。
-
-
•
✅ 是经验性最优解。
9. "It can be seen that the setting of n is crucial to VoCo. "
-
•
强调:基块数量 n 是 VoCo 方法的关键超参数。
-
•
设置不当(太少→性能差,太多→计算贵/性能饱和,Z方向划分→失真)都会影响最终效果。
-
•
类似于 CNN 中的 kernel size、batch size ------ 需要通过消融实验仔细调优。 2 个 Z 层的基块。
-
•
但如前所述,Z 方向分辨率低、需重采样 → 引入噪声和失真 → 性能反而下降或持平。
-
•
✅ 验证了"不在 Z 方向划分"是合理选择。
8. "Thus, aiming to balance performance and efficiency, we set n as 4×4×1 in VoCo. "
-
•
最终选择
4×4×1:在 X-Y 平面划分 16 个基块,在 Z 方向不划分。 -
•
这个设置:
-
•
性能足够好(接近饱和);
-
•
计算开销可控;
-
•
避免 Z 方向重采样问题。
-
-
•
✅ 是经验性最优解。
9. "It can be seen that the setting of n is crucial to VoCo. "
-
•
强调:基块数量 n 是 VoCo 方法的关键超参数。
-
•
设置不当(太少→性能差,太多→计算贵/性能饱和,Z方向划分→失真)都会影响最终效果。
-
•
类似于 CNN 中的 kernel size、batch size ------ 需要通过消融实验仔细调优。成 2 个 Z 层的基块。
-
•
但如前所述,Z 方向分辨率低、需重采样 → 引入噪声和失真 → 性能反而下降或持平。
-
•
✅ 验证了"不在 Z 方向划分"是合理选择。
8. "Thus, aiming to balance performance and efficiency, we set n as 4×4×1 in VoCo. "
-
•
最终选择
4×4×1:在 X-Y 平面划分 16 个基块,在 Z 方向不划分。 -
•
这个设置:
-
•
性能足够好(接近饱和);
-
•
计算开销可控;
-
•
避免 Z 方向重采样问题。
-
-
•
✅ 是经验性最优解。
9. "It can be seen that the setting of n is crucial to VoCo. "
-
•
强调:基块数量 n 是 VoCo 方法的关键超参数。
-
•
设置不当(太少→性能差,太多→计算贵/性能饱和,Z方向划分→失真)都会影响最终效果。
-
•
类似于 CNN 中的 kernel size、batch size ------ 需要通过消融实验仔细调优。 引入噪声和失真 → 性能反而下降或持平。
-
•
✅ 验证了"不在 Z 方向划分"是合理选择。
8. "Thus, aiming to balance performance and efficiency, we set n as 4×4×1 in VoCo. "
-
•
最终选择
4×4×1:在 X-Y 平面划分 16 个基块,在 Z 方向不划分。 -
•
这个设置:
-
•
性能足够好(接近饱和);
-
•
计算开销可控;
-
•
避免 Z 方向重采样问题。
-
-
•
✅ 是经验性最优解。
9. "It can be seen that the setting of n is crucial to VoCo. "
-
•
强调:基块数量 n 是 VoCo 方法的关键超参数。
-
•
设置不当(太少→性能差,太多→计算贵/性能饱和,Z方向划分→失真)都会影响最终效果。
-
•
类似于 CNN 中的 kernel size、batch size ------ 需要通过消融实验仔细调优。