【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】
关于ai,关于深度学习,各方面的资料都比较多。比如说怎么标记,怎么训练,怎么调优,零零散散的资料不少。但是这些技术,或者框架之间是什么关系,怎么从训练到最终部署,这方面谈的不多。今天正好可以花点时间聊一下。如果要自己训练数据,到最终嵌入式部署,要做些什么。
1、搜集训练的数据或者图片
如果是学术领域,很多图片都是开源集。但是如果是商用,很多时候只能自己购买,或者想办法自己搜集。搜集好了还没有结束,因为需要对这些图片进行标记。标记也是一个体力活,因为标记的图片不是几十、几百张,而是几千、几万张。
另外一些数据其实非常难拿到,要么价值很高,类似于医学类,要么是政府部门,很难获取到。
2、准备训练的板卡
通常训练的话,需要专门的显卡,这样训练的时候会快一点,毕竟cuda和cudnn会效率高不少。单纯的cpu训练也是可以的,比如利用下班的时候,或者周末两天,放在那里训练都是可以的。合理错峰分配,也是不错的一个选择。
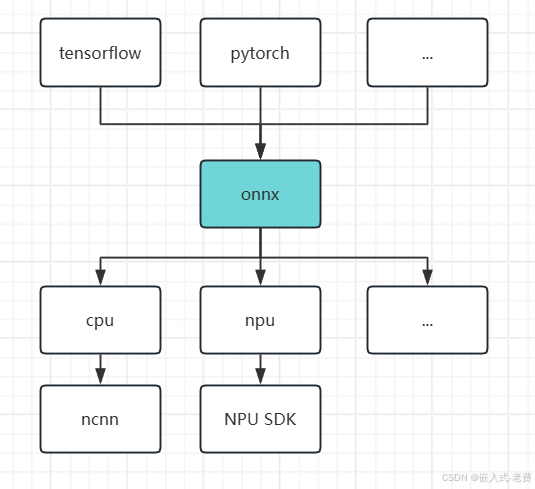
3、选择自己熟悉的训练框架
每一个同学都有自己擅长的框架,比如有的熟悉tensorflow,有的熟悉pytorch。这个就和IDE一样,无所谓好坏,自己用着顺手就行。
4、选择深度网络,开始训练
大多数情况下,我们用模型都是为了解决问题。**针对这些问题,很多时候我们都有现成的深度网络可以参考。**比如,最终的目的是分类,还是检测,或者是回归。选择好了之后,就可以开始利用之前准备好的数据开始训练了。当然,如果是特别复杂的模型,一般不是网络的所有参数都进行训练,只需要固定训练后几层网络参数即可,也就是所谓的后训练。
5、得到的模型翻译为通用onnx文件
不同的训练框架,大家都有自己的网络保存格式、参数保存格式。为了兼容所有的框架,就需要一个公共的文件格式,可以实现不同框架之间的转换。这也为下一步的网络部署做好准备。
6、确认最终嵌入式加速设备
很多嵌入式设备有npu,这个时候就可以用npu对网络进行加速。不同soc厂家的npu不一定是兼容的。每一家都有自己的ip、自己的驱动,所以相关信息需要提前确认好,比如是否提供相关的工具,可以实现onnx和厂家模型之间的转换。
如果没有npu,但是cpu比较强,或者有其他的算力设备,比如dsp、gpu、fpga,也是可以的,只要算力够就行。
7、onnx模型再次翻译
前面我们已经把模型,从不同框架翻译成了onnx格式。这个时候还需要继续翻译,是cpu平台,就翻译成cpu sdk支持的格式,比如ncnn。是npu平台,就需要去找厂家,拿到对应的工具、sdk、手册,看看怎么把onnx翻译成对应的模型。其他dsp、gpu、fpga也是类似的道理。
8、c/c++或者python编程
模型翻译好了,这个时候就需要对嵌入式设备进行编程处理了。主要的编程语言,要么是c/c++,要么是python。流程一般是这样的,加载模型,读取视频、或者是图片、甚至是实时视频流,对图片做标准化处理,把图片送给模型处理,将处理结果进行后处理,看看是分类,还是检测。整个基本流程就是这样的一个过程。
9、持续调优迭代
这部分调优分成两种,一种是模型本身的调优迭代,一种是部署时候的优化。两者一般都需要做,甚至有的时候没有添加的算子,还要在类似ncnn框架中添加自己需要的算子。