注:本系列源码分析基于XxlJob 2.3.0,gitee仓库链接:gitee.com/funcy/xxl-j....
在上一篇文章中,要执行的任务终于通过ExecutorBiz.run(...)发往了executor,由此开始了executor上任务的执行操作。关于admin到executor之间的通讯,在《admin与executor通讯》一文中已详细分析过了,这里我们直接看executor进程中ExecutorBiz.run(...)方法的操作。
ExecutorBizImpl#run
获取 jobHandler
进入 ExecutorBizImpl#run 方法,内容如下:
java
public ReturnT<String> run(TriggerParam triggerParam) {
// load old:jobHandler + jobThread
JobThread jobThread = XxlJobExecutor.loadJobThread(triggerParam.getJobId());
IJobHandler jobHandler = jobThread!=null?jobThread.getHandler():null;
String removeOldReason = null;
// 先分析这么多,剩下的接下来再分析
...方法一开始,就从XxlJobExecutor中获取JobThread,然后从JobThread中获取IJobHandler。这简单的3行代码,一下子出现了3个类,下面一一来分析。
XxlJobExecutor.loadJobThread
关于XxlJobExecutor,从名称上来看,就是处理xxlJob任务执行逻辑的,在《执行器启动流程》一文中对该类的部分功能也做过分析,这里我们直接来看loadJobThread(...)相关方法的内容:
java
private static ConcurrentMap<Integer, JobThread> jobThreadRepository
= new ConcurrentHashMap<Integer, JobThread>();
public static JobThread loadJobThread(int jobId){
JobThread jobThread = jobThreadRepository.get(jobId);
return jobThread;
}在XxlJobExecutor中,有一个ConcurrentMap结构,key是jobId,value是jobThread,loadJobThread(xxx)方法就是从这个ConcurrentMap中获取jobThread的操作了。
关于JobThread放入jobThreadRepository中的操作,我们下面会分析到。
IJobHandler
IJobHandler是一个接口,其中定义了3个方法:
java
/**
* job handler
*
* @author xuxueli 2015-12-19 19:06:38
*/
public abstract class IJobHandler {
/**
* 处理任务的执行,当executor收到调度请求时被调用
* execute handler, invoked when executor receives a scheduling request
*
* @throws Exception
*/
public abstract void execute() throws Exception;
/*@Deprecated
public abstract ReturnT<String> execute(String param) throws Exception;*/
/**
* 初始化 handler,当 JobThread 初始化时被调用
* init handler, invoked when JobThread init
*/
public void init() throws Exception {
// do something
}
/**
* 销毁 handler,当 JobThread 销毁时被调用
* destroy handler, invoked when JobThread destroy
*/
public void destroy() throws Exception {
// do something
}
}每个方法的作用代码中已给出了注释,这个IJobHandler就是执行任务的组件了,它有3个子类:
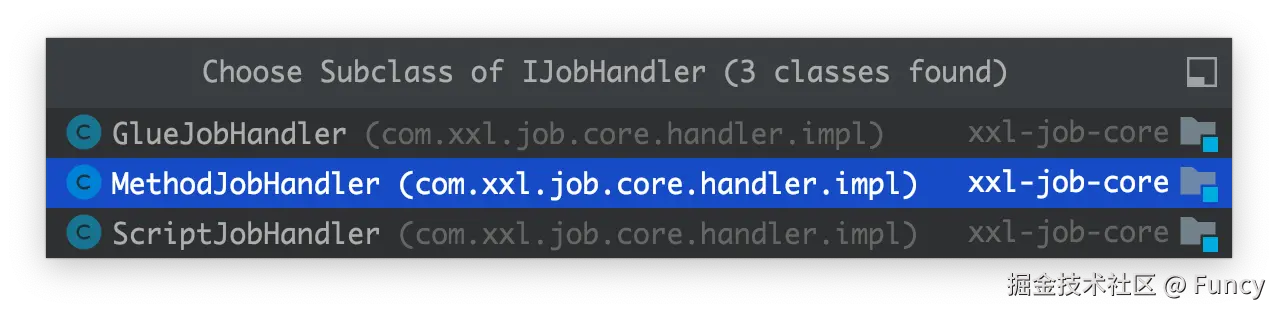
在管理后台新增任务时,可以指定任务的运行模式:
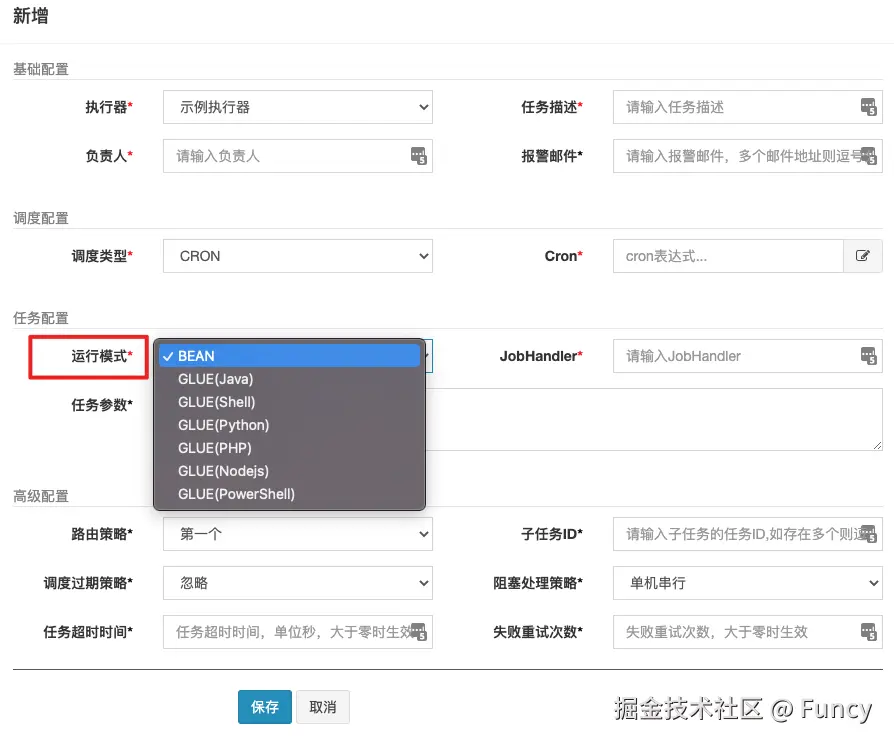
上述IJobHandler的3个子类就是用来处理这些运行模式的,各运行模式与对应IJobHandler的关系如下:
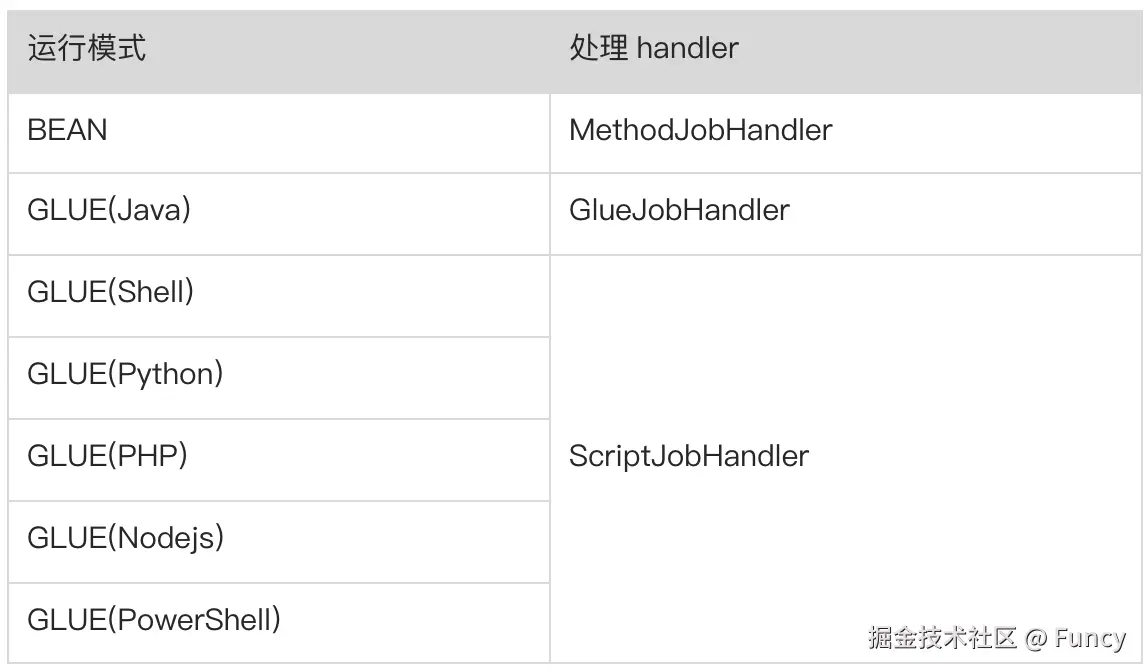
本系列文章我们仅关注BEAN模式下任务的执行,后续我们重点关注MethodJobHandler。
JobThread
JobThread的部分内容如下:
java
public class JobThread extends Thread {
private static Logger logger = LoggerFactory.getLogger(JobThread.class);
/** 任务id */
private int jobId;
/** 处理该处理的 handler */
private IJobHandler handler;
/** 队列,用于保存待执行的任务 */
private LinkedBlockingQueue<TriggerParam> triggerQueue;
/** 任务日志id,用来去重 */
private Set<Long> triggerLogIdSet;
...
}上述代码仅展示了JobThread部分属性,对该类几点说明如下:
JobThread继承了Thread,它的run()用来处理任务的具体执行操作,这点我们后面再分析JobThread中有两个属性:jobId与handler,即每一个任务,都有一个对应的handler来处理该任务的执行JobThread中triggerQueue用来保存即将执行的任务,即任务是异步执行的,先放入triggerQueue中,再另一个线程(JobThread)从triggerQueue中取出并执行,这部分的内容我们后面会分析- 注意到
JobThread有一个属性:triggerLogIdSet,这是一个Set类型,用来保存jobLogId,可以避免任务重复执行。对于同一个任务(jobId),每次执行都会生成一条记录(jobLog)从而得到一个jobLogId,如果一个jobLogId在triggerLogIdSet中已存在,这就表明本次是重复执行。
GlueType 的处理
让我们回到ExecutorBizImpl#run继续往下:
java
// 获取 GlueTypeEnum
GlueTypeEnum glueTypeEnum = GlueTypeEnum.match(triggerParam.getGlueType());
if (GlueTypeEnum.BEAN == glueTypeEnum) {
// 加载 IJobHandler
IJobHandler newJobHandler = XxlJobExecutor.loadJobHandler(
triggerParam.getExecutorHandler());
// 判断新的 JobHandler 与 jobThread 中的 JobHandler是否相同
if (jobThread!=null && jobHandler != newJobHandler) {
removeOldReason = "change jobhandler or glue type, "
+ "and terminate the old job thread.";
// 不相同,置为 null
jobThread = null;
jobHandler = null;
}
// 使用新的 JobHandler,最终得到的 JobHandler 就是最新的了
if (jobHandler == null) {
jobHandler = newJobHandler;
if (jobHandler == null) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "job handler ["
+ triggerParam.getExecutorHandler() + "] not found.");
}
}
} else if (GlueTypeEnum.GLUE_GROOVY == glueTypeEnum) {
// 省略
...
} else if (glueTypeEnum!=null && glueTypeEnum.isScript()) {
// 省略
...
} else {
return new ReturnT<String>(ReturnT.FAIL_CODE,
"glueType[" + triggerParam.getGlueType() + "] is not valid.");
}这一步是根据GlueTypeEnum来获取对应的jobHandler,本系列文章重点关注BEAN运行模式,因此其他运行模式的代码进行了删减,我们也逐步来分析这块的操作。
GlueTypeEnum
GlueTypeEnum内容如下:
java
public enum GlueTypeEnum {
BEAN("BEAN", false, null, null),
GLUE_GROOVY("GLUE(Java)", false, null, null),
GLUE_SHELL("GLUE(Shell)", true, "bash", ".sh"),
GLUE_PYTHON("GLUE(Python)", true, "python", ".py"),
GLUE_PHP("GLUE(PHP)", true, "php", ".php"),
GLUE_NODEJS("GLUE(Nodejs)", true, "node", ".js"),
GLUE_POWERSHELL("GLUE(PowerShell)", true, "powershell", ".ps1");
// 省略其他
...
}这部分内容与界面配置的运行模式一致,就不多作分析了。
BEAN模式下获取IJobHandler
获取IJobHandler的代码为
java
IJobHandler newJobHandler = XxlJobExecutor.loadJobHandler(
triggerParam.getExecutorHandler());同样是XxlJobExecutor,前面分析了XxlJobExecutor.loadJobThread方法,这里我们再来分析XxlJobExecutor.loadJobHandler方法:
java
/**
* 用来保存 executorHandler 对应的 IJobHandler
* key: executorHandler
* value: IJobHandler
*/
private static ConcurrentMap<String, IJobHandler> jobHandlerRepository
= new ConcurrentHashMap<String, IJobHandler>();
/**
* 从 jobHandlerRepository 中获取 IJobHandler
*/
public static IJobHandler loadJobHandler(String name){
return jobHandlerRepository.get(name);
}可以看到,在XxlJobExecutor中,有一个jobHandlerRepository属性用来保存executorHandler对应的IJobHandler.
那么何谓executorHandler呢?我们在编写任务时,是这个进行的:
java
@XxlJob("demoJobHandler")
public void demoJobHandler() throws Exception {
...
}@XxlJob注解中的demoJobHandler就是executorHandler了。
这个IJobHandler是什么时候放入jobHandlerRepository中的呢?在《执行器启动流程》一文中,我们分析过xxl-job对@XxlJob注解的处理,IJobHandler就是在这个阶段放入jobHandlerRepository中的,具体参考XxlJobSpringExecutor#initJobHandlerMethodRepository方法。
阻塞策略
回到 ExecutorBizImpl#run 方法,继续:
java
// 处理阻塞策略
if (jobThread != null) {
ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(
triggerParam.getExecutorBlockStrategy(), null);
if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) {
// 丢弃后续调度
if (jobThread.isRunningOrHasQueue()) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:"
+ ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());
}
} else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) {
// 覆盖之前调度
if (jobThread.isRunningOrHasQueue()) {
removeOldReason = "block strategy effect:"
+ ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();
jobThread = null;
}
} else {
// 默认策略:什么也不处理
}
}
if (jobThread == null) {
// 注册线程,即一个job对应一个jobThread对象
jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(),
jobHandler, removeOldReason);
}这部分是来处理阻塞策略的,何谓阻塞策略呢?如果一个任务处于执行中,又收到了该任务的执行请求,这就造成了任务的阻塞。
在xxl-job中,支持如下阻塞策略:
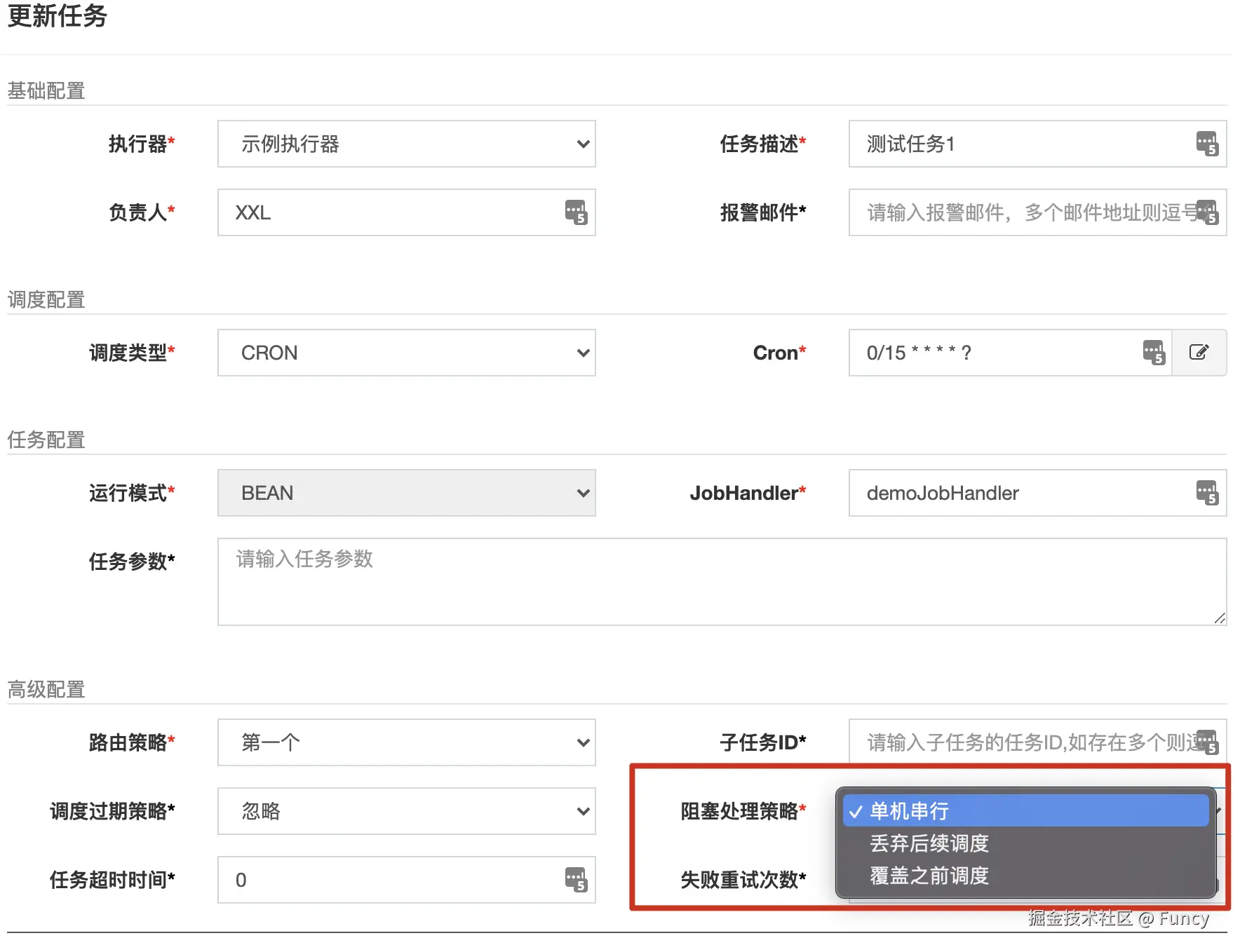
阻塞策略的枚举类为ExecutorBlockStrategyEnum:
java
public enum ExecutorBlockStrategyEnum {
/** 单机串行 */
SERIAL_EXECUTION("Serial execution"),
/** 丢弃后续调度 */
DISCARD_LATER("Discard Later"),
/** 覆盖之前调度 */
COVER_EARLY("Cover Early");
// 省略其他代码
...
}这块正是对应了管理后台任务编辑界面的策略选择了。接下来我们具体分析这3个阻塞策略。
单机串行
所谓的"单机串行",指的是在每一个executor,任务都是串行执行。虽然该策略叫单机串行且是默认策略(位于else代码块),但是代码中并没有对该策略进行任何操作,那么为什么该策略会叫单机串行呢?
此时我们还未分析到jobThread执行任务的流程,但不妨碍我们先"剧透"下这块的流程:下面的操作中,我们可以看到任务会添加到jobThread的triggerQueue队列中,之后jobThread的线程会从triggerQueue一个一个地获取任务,然后执行。
这里需要注意两点:
- 任务是先放入
JobThread#triggerQueue中再执行的 - 任务执行时,同一个
jobId都是由同一个线程执行的
由这两点可以看出,任务确实是串行执行的。
丢弃后续调度
处理该策略的代码如下:
java
if (jobThread.isRunningOrHasQueue()) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:"
+ ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());
}如果jobThread中有任务在执行,就返回失败,即丢弃了该任务。从代码来看,丢弃后续调度可概括为丢弃当前任务的执行请求。
判断任务是否在执行的方法为jobThread.isRunningOrHasQueue(),我们来看看它做了什么,进入JobThread#isRunningOrHasQueue:
java
public boolean isRunningOrHasQueue() {
return running || triggerQueue.size()>0;
}这里有两个判断条件:
runningtriggerQueue.size()
先来看看running,它的更新位于JobThread#run()方法中:
java
/** 是否执行任务的标识 */
private boolean running = false;
@Override
public void run() {
// init
try {
handler.init();
} catch (Throwable e) {
logger.error(e.getMessage(), e);
}
// execute
while(!toStop){
running = false;
idleTimes++;
TriggerParam triggerParam = null;
try {
triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);
if (triggerParam!=null) {
// 任务在执行,变更 running 的值
running = true;
...
}
}
...
}
}从代码来看,executor在执行该任务时,running就会变成true,表明正在执行任务。
再来说说triggerQueue,在前面分析JobThread时,提到JobThread中的triggerQueue属性用于存放待执行的任务的,因此当triggerQueue.size() > 0时,就表明待执行任务数大于0,即JobThread中有正在执行的任务,来不及从triggerQueue中取出任务来执行。
覆盖之前调度
处理该策略的方法如下:
java
if (jobThread.isRunningOrHasQueue()) {
removeOldReason = "block strategy effect:"
+ ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();
jobThread = null;
}从代码来看,如果有任务在执行,将jobThread置为null就完了。
但事实并没有这么简单,当jobThread为null时,接下来就有这么一段代码:
java
if (jobThread == null) {
// 注册线程,即一个job对应一个jobThread对象
jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(),
jobHandler, removeOldReason);
}从表面来看,这个方法是处理jobHandler操作,我们进入XxlJobExecutor.registJobThread方法:
java
public static JobThread registJobThread(int jobId,
IJobHandler handler, String removeOldReason) {
JobThread newJobThread = new JobThread(jobId, handler);
// 启动线程
newJobThread.start();
logger.info(">>>>>>>>>>> xxl-job regist JobThread success, jobId:{}, handler:{}",
new Object[]{jobId, handler});
// put 操作会返回旧的值
JobThread oldJobThread = jobThreadRepository.put(jobId, newJobThread);
if (oldJobThread != null) {
// 更新jobThread,并且关闭旧的线程
oldJobThread.toStop(removeOldReason);
oldJobThread.interrupt();
}
return newJobThread;
}这块代码比较简单,就是创建线程,接着启动线程,然后将线程放入jobThreadRepository中。这里需要特别注意jobThreadRepository.put(...)操作,在Map中,put(...)的返回值为旧的值:
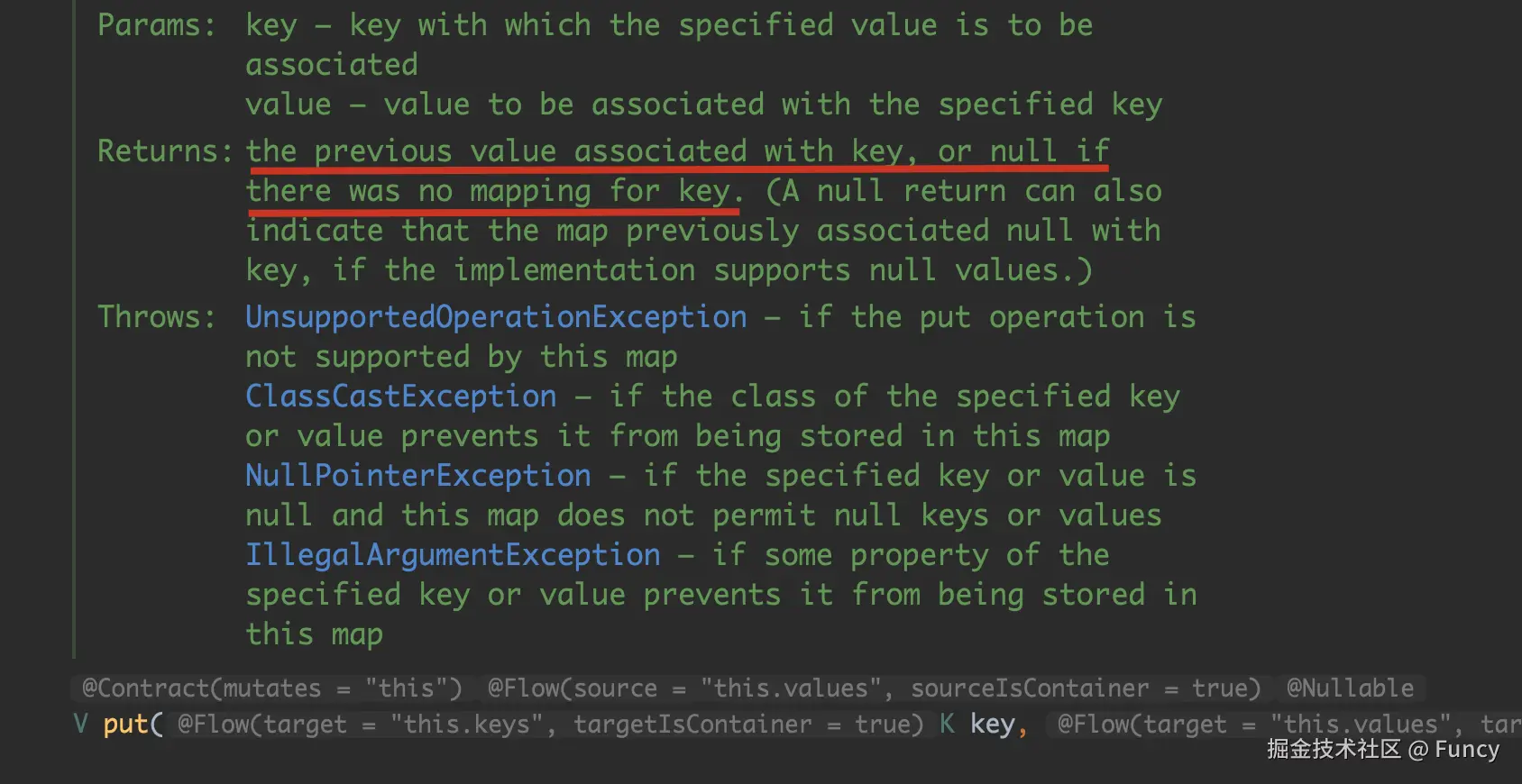
因此这里的oldJobThread,就是旧的jobThread,在该值不为null时,会进行停止操作:
java
oldJobThread.toStop(removeOldReason);
oldJobThread.interrupt();关于线程停止操作,在xxl-job中都是基于一个套路,这里就不赘述了。
分析到这里,就可以看到,覆盖之前调度的策略会停止旧的执行线程,总结下该策略的执行操作:
- 将当前
jobThread置为null - 创建新的
jobThread,并放入jobThreadRepository - 停止
jobThreadRepository中旧的jobThread
保存执行数据
继续分析ExecutorBizImpl#run方法:
java
ReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);
return pushResult;
}这是该方法的收尾操作了,这块就是将任务添加到jobThread的triggerQueue队列的操作,进入JobThread#pushTriggerQueue 方法:
java
public ReturnT<String> pushTriggerQueue(TriggerParam triggerParam) {
// 使用 triggerLogIdSet 进行去重操作
if (triggerLogIdSet.contains(triggerParam.getLogId())) {
logger.info(">>>>>>>>>>> repeate trigger job, logId:{}", triggerParam.getLogId());
return new ReturnT<String>(ReturnT.FAIL_CODE, "repeate trigger job, logId:"
+ triggerParam.getLogId());
}
// 两个结构中都要添加
triggerLogIdSet.add(triggerParam.getLogId());
triggerQueue.add(triggerParam);
return ReturnT.SUCCESS;
}前面提到过JobThread的triggerLogIdSet属性,这里可以清晰地看到它的去重操作:对于某一个任务(jobId),每次执行都会生成一条记录(jobLog)从而得到一个jobLogId,如果一个jobLogId在triggerLogIdSet中已存在,这就表明本次是重复执行。
比如,jobId为2的任务执行了4次,生成了4条jobLogId:
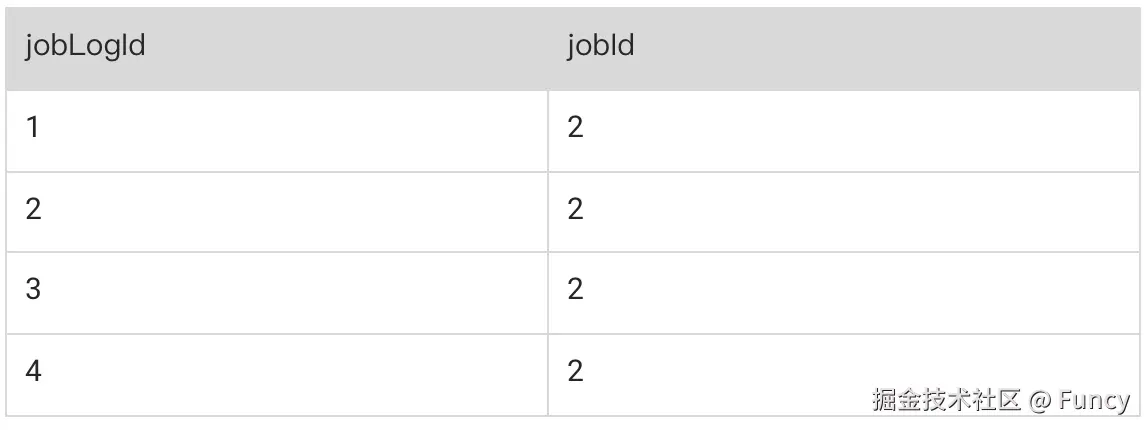
如果jobLogId为3的记录已经存在,就表示jobLogId=3重复执行了。
再来看看添加操作,所谓的添加操作就是调用队列的add(...)方法,这里就不多说了。
到了这里,ExecutorBizImpl#run的调用就完结了,即任务调度完成,admin到executor的http请求已经结束了。
任务调度虽然完成,但任务的执行还远没结束,调度结果是成功还是失败admin并不知道,我们还需要继续往下分析。
任务的执行:JobThread#run
前面我们多次提到,任务的执行是在JobThread线程中,我们直接来看看JobThread#run方法:
java
public void run() {
// 1. 执行初始化方法
try {
handler.init();
} catch (Throwable e) {
logger.error(e.getMessage(), e);
}
// 2. while 循环中执行
while(!toStop){
running = false;
idleTimes++;
TriggerParam triggerParam = null;
try {
// 3. 从队列中获取待任务,注意到这是一个阻塞操作,时间为3s
triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);
if (triggerParam!=null) {
running = true;
idleTimes = 0;
triggerLogIdSet.remove(triggerParam.getLogId());
// 4. 执行前的准备
// 日志名称
String logFileName = XxlJobFileAppender.makeLogFileName(
new Date(triggerParam.getLogDateTime()), triggerParam.getLogId());
// 上下文参数
XxlJobContext xxlJobContext = new XxlJobContext(
triggerParam.getJobId(),
triggerParam.getExecutorParams(),
logFileName,
triggerParam.getBroadcastIndex(),
triggerParam.getBroadcastTotal());
// init job context
XxlJobContext.setXxlJobContext(xxlJobContext);
// execute
XxlJobHelper.log("<br>----------- xxl-job job execute start "
+ "-----------<br>----------- Param:" + xxlJobContext.getJobParam());
// 5. 执行任务
if (triggerParam.getExecutorTimeout() > 0) {
// 处理任务超时
Thread futureThread = null;
try {
FutureTask<Boolean> futureTask = new FutureTask<Boolean>(
new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
// init job context
XxlJobContext.setXxlJobContext(xxlJobContext);
// 这里执行了任务的具体内容
handler.execute();
return true;
}
});
futureThread = new Thread(futureTask);
futureThread.start();
// 在 futureTask 中执行
Boolean tempResult = futureTask.get(
triggerParam.getExecutorTimeout(), TimeUnit.SECONDS);
} catch (TimeoutException e) {
XxlJobHelper.log("<br>----------- xxl-job job execute timeout");
XxlJobHelper.log(e);
// handle result
XxlJobHelper.handleTimeout("job execute timeout ");
} finally {
futureThread.interrupt();
}
} else {
// just execute
// 这里执行了任务的具体内容
handler.execute();
}
// 6. 处理执行结果
if (XxlJobContext.getXxlJobContext().getHandleCode() <= 0) {
XxlJobHelper.handleFail("job handle result lost.");
} else {
String tempHandleMsg = XxlJobContext.getXxlJobContext().getHandleMsg();
tempHandleMsg = (tempHandleMsg!=null&&tempHandleMsg.length()>50000)
?tempHandleMsg.substring(0, 50000).concat("...")
:tempHandleMsg;
XxlJobContext.getXxlJobContext().setHandleMsg(tempHandleMsg);
}
XxlJobHelper.log("<br>----------- xxl-job job execute end(finish) "
+ "-----------<br>----------- Result: handleCode="
+ XxlJobContext.getXxlJobContext().getHandleCode()
+ ", handleMsg = "
+ XxlJobContext.getXxlJobContext().getHandleMsg()
);
} else {
// 轮空达到30次,且队列中无待执行的任务,清除当前线程
if (idleTimes > 30) {
if(triggerQueue.size() == 0) {
XxlJobExecutor.removeJobThread(jobId, "excutor idel times over limit.");
}
}
}
} catch (Throwable e) {
if (toStop) {
XxlJobHelper.log("<br>----------- JobThread toStop, stopReason:" + stopReason);
}
// handle result
StringWriter stringWriter = new StringWriter();
e.printStackTrace(new PrintWriter(stringWriter));
String errorMsg = stringWriter.toString();
XxlJobHelper.handleFail(errorMsg);
XxlJobHelper.log("<br>----------- JobThread Exception:"
+ errorMsg + "<br>----------- xxl-job job execute end(error) -----------");
} finally {
if(triggerParam != null) {
// 8. 回调处理,即将执行结果传回 admin
// callback handler info
if (!toStop) {
// 正常情况:从`triggerQueue`中获取到了任务并执行完成
// 所谓的 callback,所做的工作即将任务执行结果回传到 xxl-job-admin
TriggerCallbackThread.pushCallBack(new HandleCallbackParam(
triggerParam.getLogId(),
triggerParam.getLogDateTime(),
XxlJobContext.getXxlJobContext().getHandleCode(),
XxlJobContext.getXxlJobContext().getHandleMsg() )
);
} else {
// 任务执行完但线程已停止:从`triggerQueue`中获取到任务并且执行完成,但
// 线程就执行了停止流程
TriggerCallbackThread.pushCallBack(new HandleCallbackParam(
triggerParam.getLogId(),
triggerParam.getLogDateTime(),
XxlJobContext.HANDLE_COCE_FAIL,
stopReason + " [job running, killed]" )
);
}
}
}
}
// 运行到这里,表示退出了循环,即 toStop = true
// 线程停止但任务未执行:线程执行停止流程后,`triggerQueue`中还存在任务,
// 跑个while循环,对这些任务都执行回调操作
while(triggerQueue !=null && triggerQueue.size()>0){
TriggerParam triggerParam = triggerQueue.poll();
if (triggerParam!=null) {
// is killed
// 线程关闭后,队列中的任务放在 callBack 队列中
TriggerCallbackThread.pushCallBack(new HandleCallbackParam(
triggerParam.getLogId(),
triggerParam.getLogDateTime(),
XxlJobContext.HANDLE_COCE_FAIL,
stopReason + " [job not executed, in the job queue, killed.]")
);
}
}
// 9. 执行销毁方法
try {
handler.destroy();
} catch (Throwable e) {
logger.error(e.getMessage(), e);
}
logger.info(">>>>>>>>>>> xxl-job JobThread stoped, hashCode:{}", Thread.currentThread());
}方法比较长,重点位置都已作了注释,接下来我们就一一分析该方法中的关键之处。
1. 执行初始化方法
执行初始化方法的代码如下:
java
try {
handler.init();
} catch (Throwable e) {
logger.error(e.getMessage(), e);
}执行的是handler的init()方法,这里以MethodJobHandler为例,在创建handler时,可以这样指定它的init与destroy方法:
java
@Component
public class SampleXxlJob {
/**
* 生命周期任务示例:任务初始化与销毁时,支持自定义相关逻辑;
*/
@XxlJob(value = "demoJobHandler2", init = "init", destroy = "destroy")
public void demoJobHandler2() throws Exception {
XxlJobHelper.log("XXL-JOB, Hello World.");
}
public void init(){
logger.info("init");
}
public void destroy(){
logger.info("destory");
}
}在@XxlJob注解中,可以使用init与destroy属性来指定初始化与销毁方法。
handler.init()最终调用的是MethodJobHandler#init,代码如下:
java
public class MethodJobHandler extends IJobHandler {
private final Object target;
private Method initMethod;
// 省略其他属性
...
/**
* init 方法的执行,使用反射调用
*/
@Override
public void init() throws Exception {
if(initMethod != null) {
initMethod.invoke(target);
}
}
// 省略其他方法
...
}以上述SampleXxlJob为例,MethodJobHandler#init方法中出现的target就是SampleXxlJob的实例,initMethod就是SampleXxlJob#init方法,最终是通过反射进行调用。
2. while 循环中执行
回到JobThread#run,接着就是一段while循环:
java
while(!toStop){
running = false;
idleTimes++;
// 任务参数
TriggerParam triggerParam = null;
...
}这里又是一段while循环,关于线程中跑while循环的操作,前面的文章中已经多次遇到过了,这块操作就不多说了。这里有3个属性值得注意下:
- running:运行标识,用来判断当前线程是否正在执行任务,默认为
false,接下来的代码会看到running变成true的情况 - idleTimes:记录空闲次数,所谓的空闲,是指从线程中没有任务在执行的情况,接下来的代码也会看到
idleTimes值的变化 - triggerParam:任务参数
3. 从队列中获取待任务
获取任务的操作如下:
java
triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);
if (triggerParam!=null) {
running = true;
idleTimes = 0;
triggerLogIdSet.remove(triggerParam.getLogId());
// 省略其他代码
...
} else {
// 轮空达到30次,且队列中无待执行的任务,清除当前线程
if (idleTimes > 30) {
if(triggerQueue.size() == 0) {
XxlJobExecutor.removeJobThread(jobId, "excutor idel times over limit.");
}
}
}前面多次提到,triggerQueue队列里存放的是待执行的任务,这里通过poll(...)方法从triggerQueue中获取待执行的任务,这是个阻塞操作,阻塞时间为3s,即:如果队列中有任务,立即返回,如果无任务就阻塞,直到有任务加入或达到阻塞时间(3s)。
接着,如果从triggerQueue中拿到了待执行任务,会进几个操作:
running = true:running字段改成true,即表示任务正在执行中idleTimes = 0:空闲次数设置为0,表示空闲次数重新统计triggerLogIdSet.remove(triggerParam.getLogId()):前面提到,triggerLogIdSet用来存放jobLogId,用于判断任务是否重复执行,任务真正执行前,会从triggerLogIdSet中删除jobLogId,这相当于是保持triggerQueue与triggerLogIdSet的统一性。
如果从triggerQueue获取不到待执行的任务,就判断idleTimes的值,对于idleTimes > 30并且triggerQueue为空的情况,就移除当前线程。
4. 执行前的准备
执行前的准备工作如下:
java
// 日志名称
String logFileName = XxlJobFileAppender.makeLogFileName(
new Date(triggerParam.getLogDateTime()), triggerParam.getLogId());
// 上下文参数
XxlJobContext xxlJobContext = new XxlJobContext(
triggerParam.getJobId(),
triggerParam.getExecutorParams(),
logFileName,
triggerParam.getBroadcastIndex(),
triggerParam.getBroadcastTotal());
// init job context
XxlJobContext.setXxlJobContext(xxlJobContext);1. 处理日志文件名
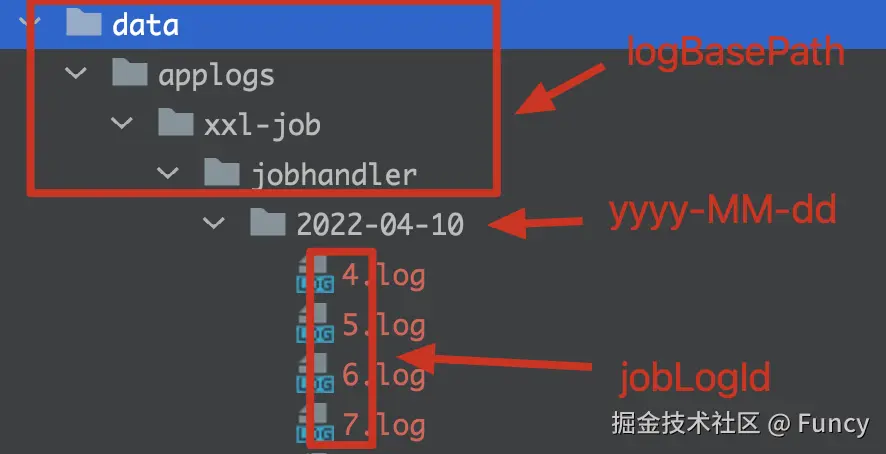
xxl-job会为每一次任务的执行生成一个日志文件,日志文件会保存在executor所在的服务器上。日志文件名格式:
bash
${logBasePath}/yyyy-MM-dd/${jobLogId}.log看个本人机器鲜活的例子:
2. 处理任务上下文参数
这块有个关键类:XxlJobContext:
java
public class XxlJobContext {
/** 任务执行的结果码,200-成功,500-失败,502-超时 */
public static final int HANDLE_COCE_SUCCESS = 200;
public static final int HANDLE_COCE_FAIL = 500;
public static final int HANDLE_COCE_TIMEOUT = 502;
// ---------------------- base info ----------------------
/**
* job id
* 任务id
*/
private final long jobId;
/**
* job param
* 任务参数
*/
private final String jobParam;
// ---------------------- for log ----------------------
/**
* job log filename
* 任务日志名称
*/
private final String jobLogFileName;
// ---------------------- for shard ----------------------
/**
* shard index
* 分片索引
*/
private final int shardIndex;
/**
* shard total
* 分片结点数
*/
private final int shardTotal;
// ---------------------- for handle ----------------------
/**
* handleCode:The result status of job execution
*
* 200 : success
* 500 : fail
* 502 : timeout
* 任务执行的结果码
*/
private int handleCode;
/**
* 任务执行结果的说明
* handleMsg:The simple log msg of job execution
*/
private String handleMsg;
// 省略其他内容
...
}这个类中有一系列的属性,用来保存任务的执行参数,以上都是一个简单的bean操作。
回到JobThread#run,得到xxlJobContext实例后,接着进行了一个设置操作:
java
XxlJobContext.setXxlJobContext(xxlJobContext);调用的也是XxlJobContext提供的方法:
java
public class XxlJobContext {
// 省略其他
...
/**
* 使用 InheritableThreadLocal
* 它与 ThreadLocal 的最大区别是,变量可与子线程共享
*/
private static InheritableThreadLocal<XxlJobContext> contextHolder
= new InheritableThreadLocal<XxlJobContext>();
/**
* 设置操作
*/
public static void setXxlJobContext(XxlJobContext xxlJobContext){
contextHolder.set(xxlJobContext);
}
/**
* 获取操作
*/
public static XxlJobContext getXxlJobContext(){
return contextHolder.get();
}
}这块操作使用的是InheritableThreadLocal,将xxlJobContext与当前线程及其子线程绑定,这样在当前线程及其子线程中都可通过XxlJobContext.getXxlJobContext() 得到 这个xxlJobContext实例。
5. 执行任务
接着就是执行任务了,代码如下:
java
if (triggerParam.getExecutorTimeout() > 0) {
// 处理任务超时
Thread futureThread = null;
try {
FutureTask<Boolean> futureTask = new FutureTask<Boolean>(
new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
// init job context
XxlJobContext.setXxlJobContext(xxlJobContext);
// 这里执行了任务的具体内容
handler.execute();
return true;
}
});
futureThread = new Thread(futureTask);
futureThread.start();
// 在 futureTask 中执行
Boolean tempResult = futureTask.get(
triggerParam.getExecutorTimeout(), TimeUnit.SECONDS);
} catch (TimeoutException e) {
XxlJobHelper.log("<br>----------- xxl-job job execute timeout");
XxlJobHelper.log(e);
// handle result
XxlJobHelper.handleTimeout("job execute timeout ");
} finally {
futureThread.interrupt();
}
} else {
// just execute
// 这里执行了任务的具体内容
handler.execute();
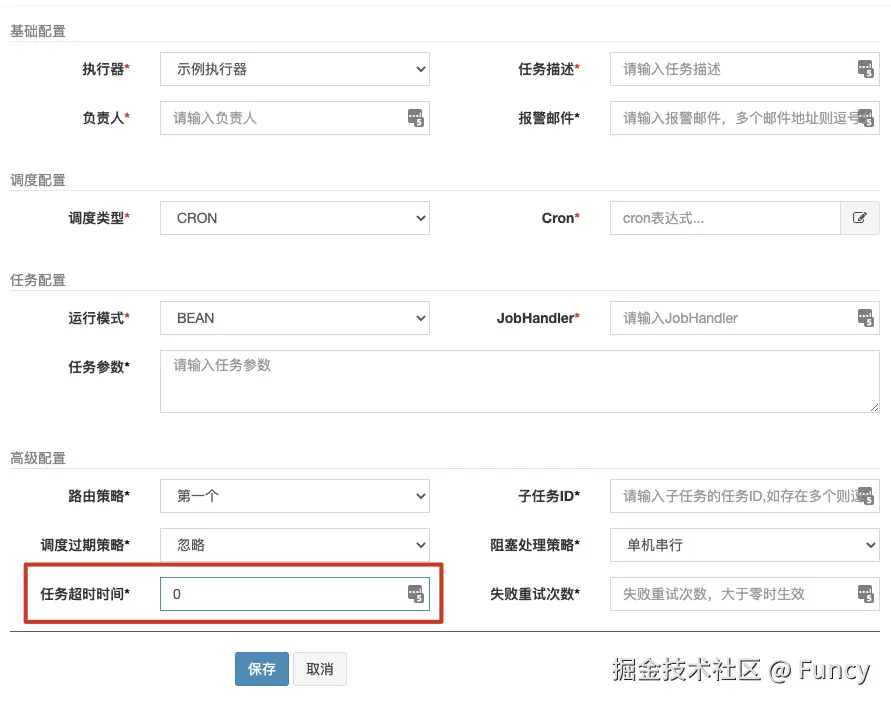
}从代码来看,任务并不是直接执行的,而是区分有没有设置超时参数,这个参数可以在管理后台界面设置,默认为0:
对于超时时间大于0的情况,需要把任务放到FutureTask中执行,futureTask.get(xxx)可以指定执行阻塞时间,即在指定时间内未获得结果就会抛出异常,这块是java并发编程相关知识,就不展开了,这里我们目光聚集任务的执行方法handler.execute()。
不管有没有设置超时,最终执行的方法都是handler.execute(),这里我们重点来看MethodJobHandler#execute方法:
java
public void execute() throws Exception {
Class<?>[] paramTypes = method.getParameterTypes();
if (paramTypes.length > 0) {
method.invoke(target, new Object[paramTypes.length]);
} else {
method.invoke(target);
}
}一个简单的反射调用。
等等,这个方法的执行是不是有问题,没处理传入的参数,也没处理方法的返回值,记得我们平时使用中@XxlJob方法是这么写的:
java
@XxlJob("demoJobHandler3")
public ReturnT<String> demoJobHandler3(String param) throws Exception {
XxlJobHelper.log("job param:" + param);
return ReturnT.FAIL;
}印象中handler方法如上图所示,方法可传入参数,可接收管理后台传入的参数:
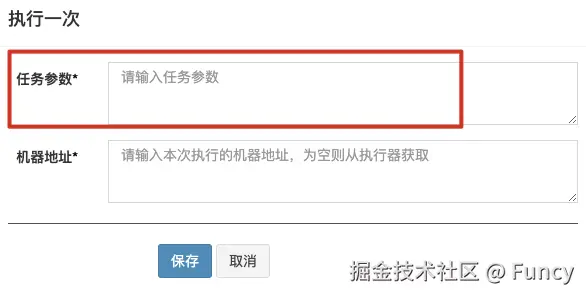
并且返回支持返回值,可根据返回值来判断任务是否执行成功,但从代码来看,并没有处理方法的参数与返回,这是怎么回事呢?
为了解答这个问题,我特地对比了上个版本(2.2.0)的代码:

从JobThread代码来看,旧版确实处理了参数与返回值,这块是新旧版本的最大区别。
既然新版本没有处理参数与返回,那我们如何实现与旧版相同的功能呢?我们继续往下看。
6. 处理执行结果
执行完任务后,接着就是处理任务的执行结果了:
java
if (XxlJobContext.getXxlJobContext().getHandleCode() <= 0) {
XxlJobHelper.handleFail("job handle result lost.");
} else {
String tempHandleMsg = XxlJobContext.getXxlJobContext().getHandleMsg();
tempHandleMsg = (tempHandleMsg!=null&&tempHandleMsg.length()>50000)
?tempHandleMsg.substring(0, 50000).concat("...")
:tempHandleMsg;
XxlJobContext.getXxlJobContext().setHandleMsg(tempHandleMsg);
}这里获取任务的结果是从XxlJobContext中获取的,任务的结果码与结果说明都保存在了XxlJobContext中。而handleCode的默认值为SUCCESS:
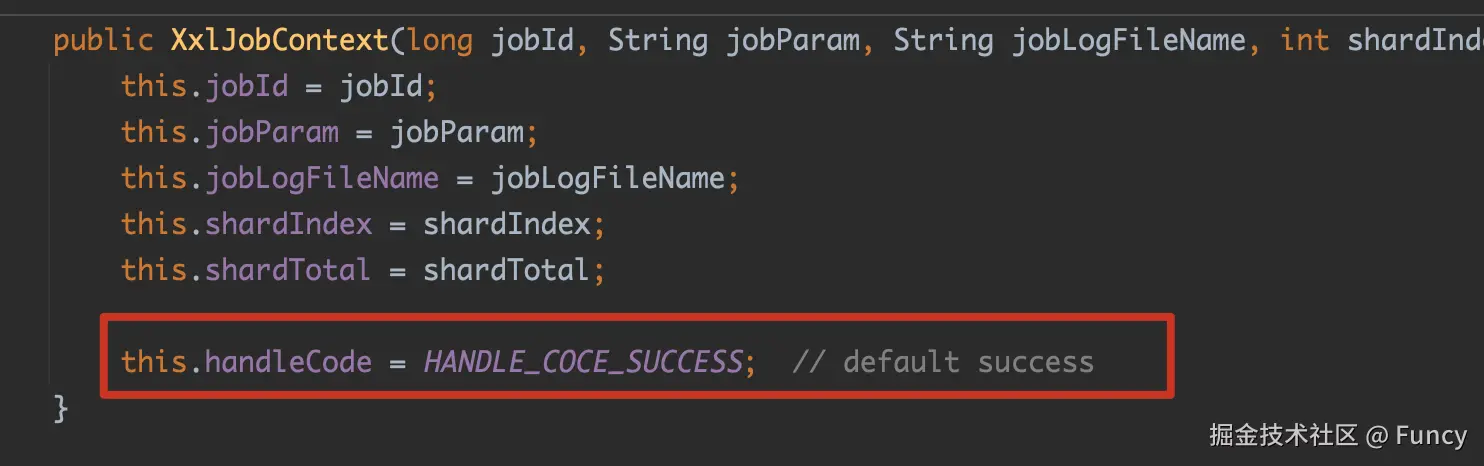
而从创建XxlJobContext到从XxlJobContext中获取执行结果,中间运行的是任务执行的代码,这说明我们可以在自己编写的handler方法中操作XxlJobContext,像这样:
java
@XxlJob("demoJobHandler5")
public void demoJobHandler5() throws Exception {
// 获取执行参数
String jobParam = XxlJobContext.getXxlJobContext().getJobParam();
XxlJobHelper.log("job param:" + jobParam);
boolean result = xxx;
if (result) {
XxlJobContext.getXxlJobContext().setHandleCode(
XxlJobContext.HANDLE_COCE_SUCCESS);
XxlJobContext.getXxlJobContext().setHandleMsg("success msg");
} else {
// 错误的返回值
XxlJobContext.getXxlJobContext().setHandleCode(
XxlJobContext.HANDLE_COCE_FAIL);
XxlJobContext.getXxlJobContext().setHandleMsg("fail msg");
}
}进一步研究发现,xxl-job将XxlJobContext的相关操作由XxlJobHelper做了一个封装,上述代码可简化如下:
java
@XxlJob("demoJobHandler4")
public void demoJobHandler4() throws Exception {
// 获取执行参数
String jobParam = XxlJobHelper.getJobParam();
XxlJobHelper.log("job param:" + jobParam);
boolean result = xxx;
if (result) {
XxlJobHelper.handleSuccess("success msg");
} else {
// 错误的返回值
XxlJobHelper.handleFail("fail msg");
}
}demoJobHandler4()正是xxl-job推荐的写法,xxl-job文档中有提及:
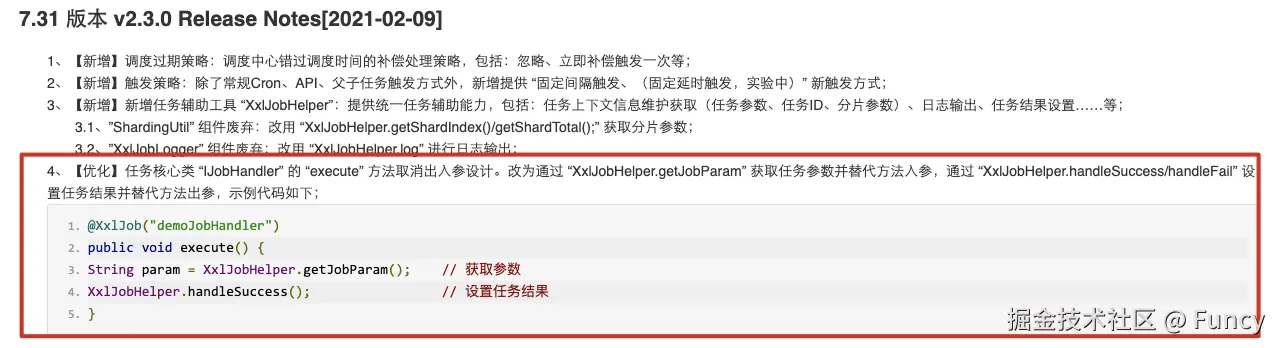
7. 回调处理
所谓的回调,是指将任务的执行结果传回给admin,JobThread#run方法中回调处理的代码分的略散,主要是回调处理分为几种情况:
- 正常情况:从
triggerQueue中获取到了任务并执行完成 - 任务执行完但线程已停止:从
triggerQueue中获取到任务并且执行完成,但线程就执行了停止流程 - 线程停止但任务未执行:线程执行停止流程后,
triggerQueue中还存在任务,需要对这些任务都执行回调操作
以上3种情况都会调用到TriggerCallbackThread.pushCallBack(xxx)方法,只不过只有正常情况是按任务的结果来处理,其他两种情况都是按任务失败来处理。处理回调的关键代码如下:
java
TriggerCallbackThread.pushCallBack(new HandleCallbackParam(
triggerParam.getLogId(),
triggerParam.getLogDateTime(),
XxlJobContext.getXxlJobContext().getHandleCode(),
XxlJobContext.getXxlJobContext().getHandleMsg() )
);这里引出了一个关键类:TriggerCallbackThread,从名字来看,它就是来处理回调操作的,TriggerCallbackThread.pushCallBack(xxx)方法代码如下:
java
public class TriggerCallbackThread {
private static Logger logger = LoggerFactory.getLogger(TriggerCallbackThread.class);
// 单例模式
private static TriggerCallbackThread instance = new TriggerCallbackThread();
public static TriggerCallbackThread getInstance(){
return instance;
}
/**
* job results callback queue
* 存入任务的执行结果
*/
private LinkedBlockingQueue<HandleCallbackParam> callBackQueue
= new LinkedBlockingQueue<HandleCallbackParam>();
/**
* 添加操作
*/
public static void pushCallBack(HandleCallbackParam callback){
// 将结果添加到队列中
getInstance().callBackQueue.add(callback);
logger.debug(">>>>>>>>>>> xxl-job, push callback request, logId:{}",
callback.getLogId());
}
// 省略其他
...
}这里我们仅关注添加操作,TriggerCallbackThread 采用了单例模式,getInstance()用于获取实例,这没啥好说的。
在TriggerCallbackThread中,有一个属性callBackQueue用来保存任务的执行结果,有了JobThread的triggerQueue,我们大概也能猜想到后面也会有线程中callBackQueue中获取元素执行操作,不过这块的分析我们后面再进行。
8. 执行销毁方法
执行销毁方法的代码如下:
java
try {
handler.destroy();
} catch (Throwable e) {
logger.error(e.getMessage(), e);
}这块操作与执行初始化方法基本一致,最终在MethodJobHandler#destroy方法中也是通过反射调用,这里就不多说了。
到这里为止,任务的执行操作也分析完了,但是整个执行流程依然没完,我们到目前为止只是看到了任务的执行,但任务的执行结果并没有提交给admin,我们还得继续前行。
执行结果的回调:TriggerCallbackThread
上一小节我们提到,任务执行完成后,会调用TriggerCallbackThread.pushCallBack(xxx)方法放入TriggerCallbackThread的callBackQueue队列中,之后回调的处理就由TriggerCallbackThread来处理了,接下来我们来分析执行结果放入callBackQueue后的操作。
在TriggerCallbackThread中有两个Thread属性:
java
public class TriggerCallbackThread {
/**
* 处理回调的线程
*/
private Thread triggerCallbackThread;
/**
* 回调重试线程
*/
private Thread triggerRetryCallbackThread;
// 省略其他
...
}两个线程的作用在注释中已指明,这里就不多说了。
线程的启动在 TriggerCallbackThread#start 方法中:
java
public void start() {
// 校验操作
if (XxlJobExecutor.getAdminBizList() == null) {
logger.warn(">>>>>>>>>>> xxl-job, executor callback config fail, "
+ "adminAddresses is null.");
return;
}
// 回调线程的启动
triggerCallbackThread = new Thread(new Runnable() {
@Override
public void run() {
...
}
});
triggerCallbackThread.setDaemon(true);
triggerCallbackThread.setName("xxl-job, executor TriggerCallbackThread");
triggerCallbackThread.start();
// 回调重试线程的启动
triggerRetryCallbackThread = new Thread(new Runnable() {
@Override
public void run() {
...
}
});
triggerRetryCallbackThread.setDaemon(true);
triggerRetryCallbackThread.start();
}整个方法看下来,主要就是启动了这两个线程。以上代码省去了两个线程的run()方法,这两个run()方法将是我们分析的重点。
这个TriggerCallbackThread#start方法是在何时调用的呢?在《执行器启动流程》一文中,我们分析过XxlJobExecutor#start方法,在这个方法里就调用了TriggerCallbackThread#start:
triggerCallbackThread的run()方法
接下来我们来分析triggerCallbackThread的具体功能,进入它的run()方法:
java
@Override
public void run() {
// while 循环中进行
while(!toStop){
try {
// 从 callBackQueue 中获取,注意 take() 是个阻塞操作
HandleCallbackParam callback = getInstance().callBackQueue.take();
if (callback != null) {
// 运行到这里,就表示从callBackQueue拿到了参数
List<HandleCallbackParam> callbackParamList
= new ArrayList<HandleCallbackParam>();
// 将 callBackQueue 中的内容转移到 callbackParamList 中
int drainToNum = getInstance().callBackQueue.drainTo(callbackParamList);
callbackParamList.add(callback);
// 进行回调操作
if (callbackParamList!=null && callbackParamList.size()>0) {
doCallback(callbackParamList);
}
}
} catch (Exception e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
}
// 跳出循环后,最后进行一次回调,套路跟上面类似
try {
List<HandleCallbackParam> callbackParamList
= new ArrayList<HandleCallbackParam>();
// 将 callBackQueue 中的内容转移到 callbackParamList 中
int drainToNum = getInstance().callBackQueue.drainTo(callbackParamList);
if (callbackParamList!=null && callbackParamList.size()>0) {
doCallback(callbackParamList);
}
} catch (Exception e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
logger.info(">>>>>>>>>>> xxl-job, executor callback thread destory.");
}这段代码总的操作就两个:
- 从
callBackQueue获取元素 - 调用
doCallback(...)方法处理回调操作
先来看看从callBackQueue获取元素的操作,代码一开始就调用了LinkedBlockingQueue提供的阻塞方法take(),它会移除队首元素并且将元素返回。当take()方法获得了返回值时,就表示队列中可能还存在其他元素,接着就使用drainTo(xxx)方法将队列中的元素都转移出来:
java
int drainToNum = getInstance().callBackQueue.drainTo(callbackParamList);关于 drainTo() 方法,注释如下:
Removes all available elements from this queue and adds them to the given collection. This operation may be more efficient than repeatedly polling this queue. A failure encountered while attempting to add elements to collection c may result in elements being in neither, either or both collections when the associated exception is thrown. Attempts to drain a queue to itself result in IllegalArgumentException. Further, the behavior of this operation is undefined if the specified collection is modified while the operation is in progress.
从此队列中删除所有可用元素并将它们添加到给定集合中。此操作可能比重复轮询此队列更有效。尝试将元素添加到集合 c 时遇到的失败可能会导致在引发相关异常时元素既不在集合中,又不属于任何一个集合或两个集合。尝试将队列排空到自身会导致 IllegalArgumentException。此外,如果在操作正在进行时修改了指定的集合,则此操作的行为是未定义的.
注释看着挺长,其实只要关注第一句就明白它是干什么的了:Removes all available elements from this queue and adds them to the given collection,运行完这句后,队列中已存在的元素就都到了callbackParamList中了。
处理完元素的获取操作后,接着就处理回调操作,也就doCallback(callbackParamList)方法:
java
private void doCallback(List<HandleCallbackParam> callbackParamList){
boolean callbackRet = false;
// 回调操作,使用 admin 客户端,请求到 admin 实例
for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) {
try {
// 真正处理回调操作
ReturnT<String> callbackResult = adminBiz.callback(callbackParamList);
if (callbackResult!=null && ReturnT.SUCCESS_CODE == callbackResult.getCode()) {
callbackLog(callbackParamList,
"<br>----------- xxl-job job callback finish.");
callbackRet = true;
// 回调成功,就退出 for 循环,即只要在其中一个 adminBiz 回调成功就算成功了
break;
} else {
callbackLog(callbackParamList, "<br>----------- xxl-job job callback fail, "
+ "callbackResult:" + callbackResult);
}
} catch (Exception e) {
callbackLog(callbackParamList,
"<br>----------- xxl-job job callback error, errorMsg:" + e.getMessage());
}
}
// 回调失败,加入到错误日志中,等待重试
if (!callbackRet) {
appendFailCallbackFile(callbackParamList);
}
}这个方法的功能主要有两个:
- 处理回调操作
- 回调失败,加入错误日志
回调操作
我们先来看回调操作,同前面介绍的executor注册、executor摘除操作一样,回调操作也是在AdminBizList的for循环中进行的,并且只要在其中之一的adminBiz上回调成功,就算回调成功,就不再需要在剩下的adminBiz上再执行回调操作了。
adminBiz处理回调操作的方法为AdminBizClient#callback,代码如下:
java
@Override
public ReturnT<String> callback(List<HandleCallbackParam> callbackParamList) {
return XxlJobRemotingUtil.postBody(addressUrl+"api/callback",
accessToken, timeout, callbackParamList, String.class);
}这是一个http请求,它会把回调数据通过http协议发往admin实例,关于这其中的通讯流程在《admin与executor通讯》一文已经分析过了,这里直接进入admin实例的处理方法AdminBizImpl#callback:
java
@Override
public ReturnT<String> callback(List<HandleCallbackParam> callbackParamList) {
return JobCompleteHelper.getInstance().callback(callbackParamList);
}深入JobCompleteHelper#callback(xxx)方法:
java
public ReturnT<String> callback(List<HandleCallbackParam> callbackParamList) {
// 在线程池中执行
callbackThreadPool.execute(new Runnable() {
@Override
public void run() {
// 循环传入的 callback 参数
for (HandleCallbackParam handleCallbackParam: callbackParamList) {
// 调用 callback 方法处理
ReturnT<String> callbackResult = callback(handleCallbackParam);
logger.debug(">>>>>>>>> JobApiController.callback {}, "
+ "handleCallbackParam={}, callbackResult={}",
(callbackResult.getCode()== ReturnT.SUCCESS_CODE?"success":"fail"),
handleCallbackParam, callbackResult);
}
}
});
return ReturnT.SUCCESS;
}继续,最终发现处理回调操作的方法为JobCompleteHelper#callback(xxx):
java
private ReturnT<String> callback(HandleCallbackParam handleCallbackParam) {
// 日志任务执行日志,表:xxl_job_log
XxlJobLog log = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao()
.load(handleCallbackParam.getLogId());
if (log == null) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "log item not found.");
}
if (log.getHandleCode() > 0) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "log repeate callback.");
}
// 处理执行信息
StringBuffer handleMsg = new StringBuffer();
if (log.getHandleMsg()!=null) {
handleMsg.append(log.getHandleMsg()).append("<br>");
}
if (handleCallbackParam.getHandleMsg() != null) {
handleMsg.append(handleCallbackParam.getHandleMsg());
}
// 填充执行结果
log.setHandleTime(new Date());
log.setHandleCode(handleCallbackParam.getHandleCode());
log.setHandleMsg(handleMsg.toString());
XxlJobCompleter.updateHandleInfoAndFinish(log);
return ReturnT.SUCCESS;
}可以看到,这个方法会找到jobLogId对应的XxlJobLog记录,然后填充执行结果。到这里,整个回调流程就完成了,不过这只是正常的情况,下面我们再来看看异常的情况。
回调失败的处理
让我们再回到TriggerCallbackThread#doCallback方法,继续往下分析:
java
private void doCallback(List<HandleCallbackParam> callbackParamList){
boolean callbackRet = false;
// 回调操作,使用 admin 客户端,请求到 admin 实例
// 省略回调处理代码
...
// 回调失败,加入到错误日志中,等待重试
if (!callbackRet) {
appendFailCallbackFile(callbackParamList);
}
}如果回调失败了,会调用appendFailCallbackFile方法处理,进入该方法:
java
/** 回调失败文件的路径 */
private static String failCallbackFilePath = XxlJobFileAppender.getLogPath()
.concat(File.separator).concat("callbacklog").concat(File.separator);
/** 回调失败文件的名称 */
private static String failCallbackFileName = failCallbackFilePath
.concat("xxl-job-callback-{x}").concat(".log");
/**
* 处理回调失败的文件
*/
private void appendFailCallbackFile(List<HandleCallbackParam> callbackParamList){
// 参数校验
if (callbackParamList==null || callbackParamList.size()==0) {
return;
}
// jdk序列化,将List中的内容序列化成byte数组
byte[] callbackParamList_bytes = JdkSerializeTool.serialize(callbackParamList);
// 得到文件名
File callbackLogFile = new File(failCallbackFileName.replace("{x}",
String.valueOf(System.currentTimeMillis())));
// 如果文件存在,使用当前时间(System.currentTimeMillis())+ 1-100 以内的序列找到一个不存在的文件
if (callbackLogFile.exists()) {
for (int i = 0; i < 100; i++) {
callbackLogFile = new File(failCallbackFileName.replace("{x}",
String.valueOf(System.currentTimeMillis()).concat("-").concat(String.valueOf(i)) ));
if (!callbackLogFile.exists()) {
break;
}
}
}
// 将前面得到的byte数组写入文件
FileUtil.writeFileContent(callbackLogFile, callbackParamList_bytes);
}这个方法的主要作用就是将回调失败记录保存到文件中,要完成这个操作,包含以下3点:
- 文件路径:
${logBasePath}/callbacklog/ - 文件名:
xxl-job-callback-${System.currentTimeMillis()}.log,如果文件名重复了,加个序号:xxl-job-callback-${System.currentTimeMillis()}-0.log、xxl-job-callback-\${System.currentTimeMillis()}-1.log,序号最多可达到99 - 序列化方式:使用jdk提供的序列化方式
最终,回调失败的记录就保存在了${logBasePath}/callbacklog/xxl-job-callback-${System.currentTimeMillis()}-{index}.log文件中了。
triggerRetryCallbackThread的run()方法
我们再回到TriggerCallbackThread#start方法,上面分析的是triggerCallbackThread的run()方法,我们继续来分析triggerRetryCallbackThread的run()方法:
java
@Override
public void run() {
while(!toStop){
try {
// 处理回调重试操作
retryFailCallbackFile();
} catch (Exception e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
// 处理休眠操作,时间为 30 s,即每30s执行一次重试操作
try {
TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);
} catch (InterruptedException e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, executor retry callback thread destory.");
}这个方法比较简单,就是调用了retryFailCallbackFile()方法来处理重试操作,我们进入该方法:
java
private void retryFailCallbackFile(){
// 校验文件路径是否存在
File callbackLogPath = new File(failCallbackFilePath);
if (!callbackLogPath.exists()) {
return;
}
if (callbackLogPath.isFile()) {
callbackLogPath.delete();
}
if (!(callbackLogPath.isDirectory() && callbackLogPath.list()!=null && callbackLogPath.list().length>0)) {
return;
}
// 遍历路径下的文件
for (File callbaclLogFile: callbackLogPath.listFiles()) {
// 读取文件内容,得到byte数组
byte[] callbackParamList_bytes = FileUtil.readFileContent(callbaclLogFile);
// 保证文件内容不为空
if(callbackParamList_bytes == null || callbackParamList_bytes.length < 1){
callbaclLogFile.delete();
continue;
}
// 进行 jdk 反序列化
List<HandleCallbackParam> callbackParamList = (List<HandleCallbackParam>) JdkSerializeTool
.deserialize(callbackParamList_bytes, List.class);
// 清除回调失败的文件,再次进行 callback 操作
callbaclLogFile.delete();
doCallback(callbackParamList);
}
}在前面我们将失败的记录转成byte数组,然后采用jdk序列化操作将失败记录写入文件中,这个方法会先将文件中的内容读取为byte数组,然后使用jdk反序列化操作得到回调失败的记录,得到这些失败的记录后,就再次调用doCallback(xxx)方法进行回调了,回调重试操作就完成了。
总结
本文介绍了executor执行任务的流程,流程细节比较多,我总结了一张图如下:
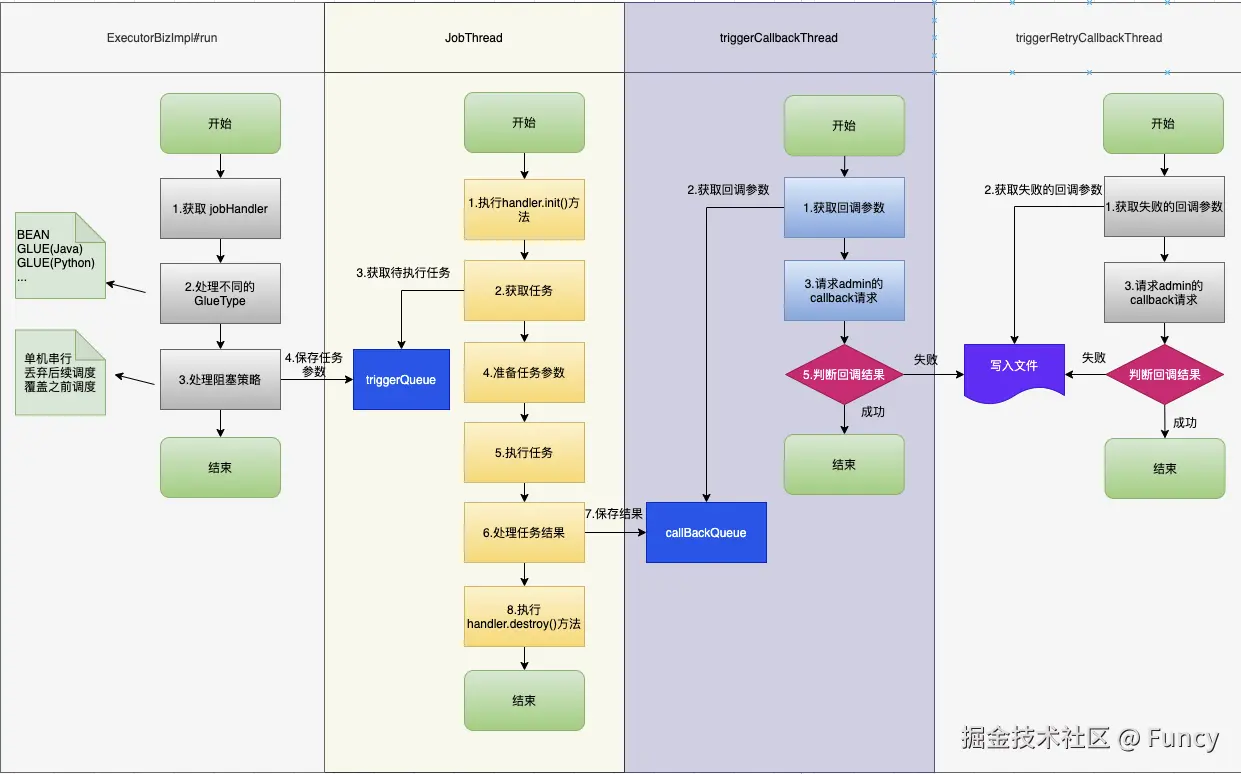
整个执行流程类似于"接力式"操作,其中的LinkedBlockQueue与文件扮演了数据流转的载体。
限于作者个人水平,文中难免有错误之处,欢迎指正!原创不易,商业转载请联系作者获得授权,非商业转载请注明出处。