引言:代码在测试环境跑得飞快,上线就崩?
很多后端开发者都经历过这样的"至暗时刻":
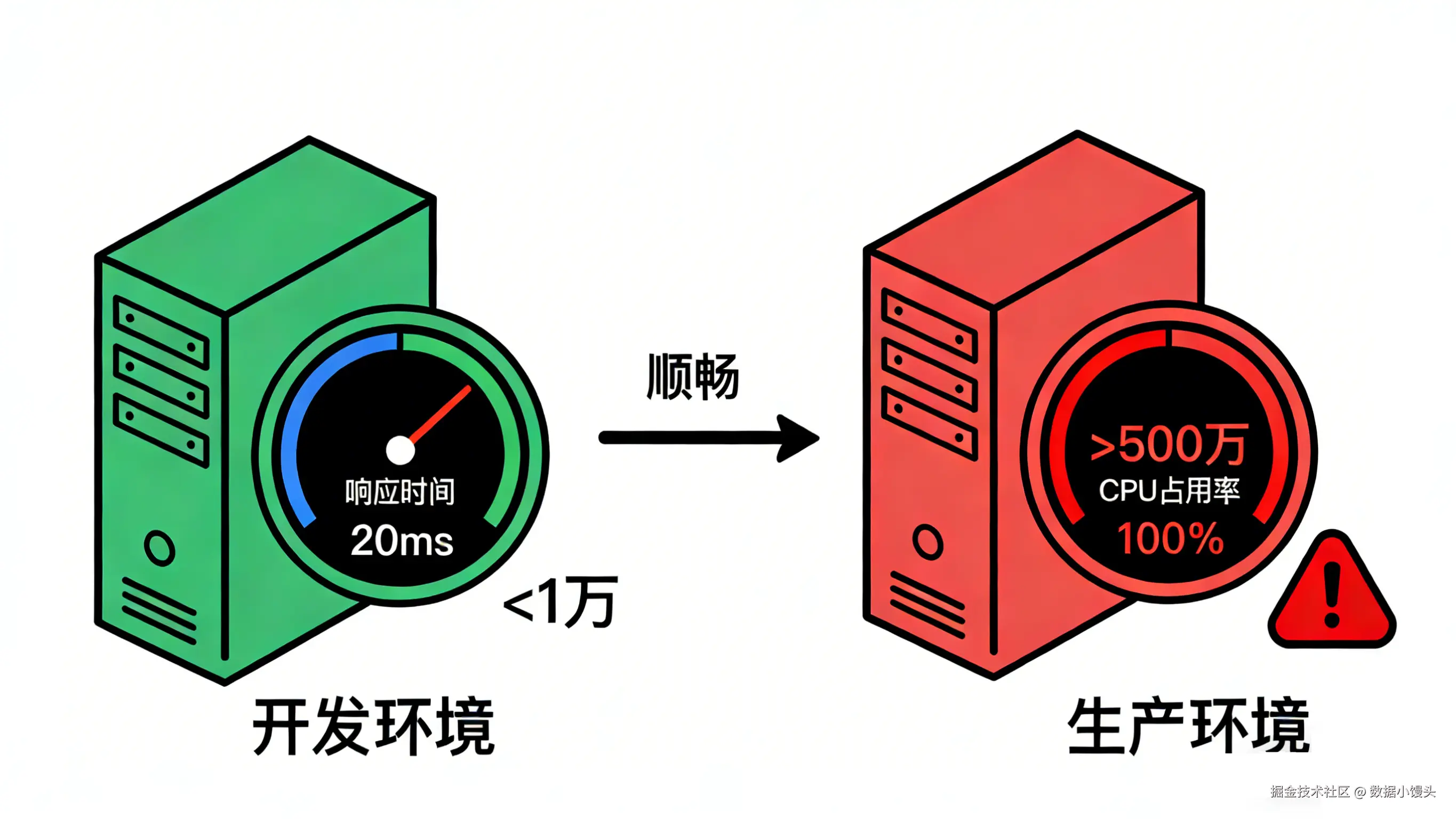
功能在开发环境(数据量 < 1万)测试时丝般顺滑,接口响应时间 20ms。一上线到生产环境(数据量 > 500万),同一个接口直接超时(Timeout),甚至把数据库 CPU 拖到 100%,导致整个服务不可用。
通常,这类问题的根源可能在于 SQL 执行效率低下。
第一步:诊断------读懂 EXPLAIN
当一条 SQL 跑得慢,第一反应不应该是"改代码",而是"看病"。MySQL 提供的 EXPLAIN 命令就是数据库的 X 光机。
在任何 SQL 语句前加上 EXPLAIN,数据库不会执行它,而是会告诉你:"如果你让我执行这条语句,我会怎么做。"
ini
EXPLAIN SELECT * FROM t_users WHERE phone = '13800138000';输出结果中,有两列决定了查询的生死:
1. type 列:性能的"阶级划分"
这个字段代表了 MySQL 查找数据的方式。从优到差,性能阶梯如下:
- system / const :⚡️ 极快。直接命中主键或唯一索引,只读一行。
- ref :🚀 快。使用了普通索引。
- range :🚗 还行。索引范围扫描,常见于 > <、BETWEEN。
- index :🚲 慢。虽然用了索引,但扫描了整个索引树(全索引扫描)。
- ALL :🐢 极慢(死罪)。全表扫描(Full Table Scan),几百万条数据一条条过。
实战准则: 生产环境的 SQL,至少要达到 range 级别,最好是 ref 。如果是 ALL,必须优化。
2. Extra 列:警惕"副作用"
- Using filesort :⚠️ 危险。说明数据库没法利用索引顺序,必须在内存或磁盘中进行额外的排序操作。CPU 杀手。
- Using temporary :⚠️ 危险。创建了临时表来处理查询。常见于 GROUP BY 或 DISTINCT。
第二步:治疗------联合索引的"最左前缀"陷阱
诊断出 type: ALL 后,最直接的解法是加索引。但索引不是乱加的,尤其是联合索引(Joint Index)。
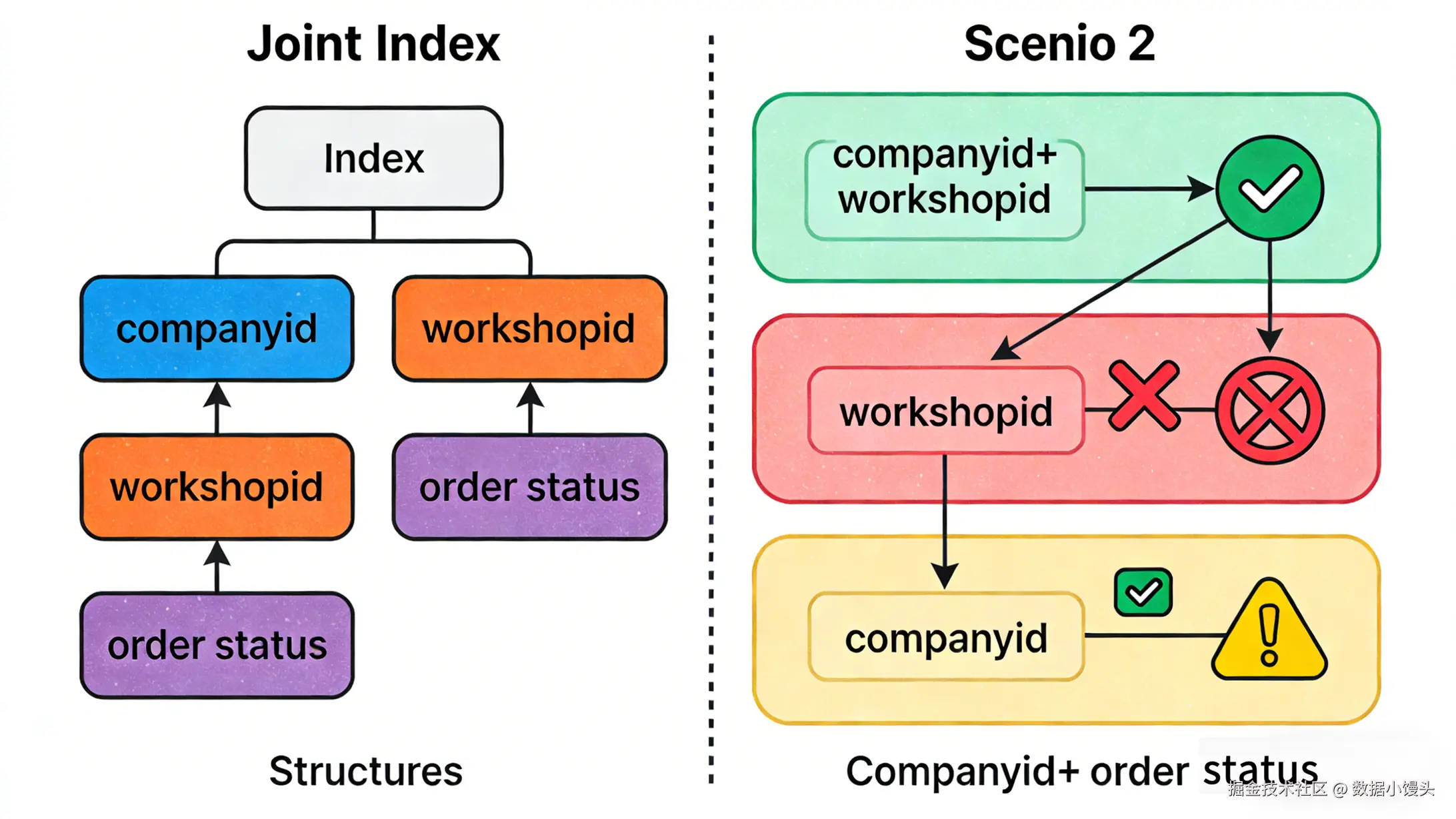
假设我们有一张订单表,建了一个联合索引 idx_a_b_c (company_id, workshop_id, order_status)。
陷阱:为什么索引失效了?
场景 1:
ini
SELECT * FROM t_orders WHERE company_id = 10 AND workshop_id = 5;✅ 索引生效。 命中了前两个字段。
场景 2:
ini
SELECT * FROM t_orders WHERE workshop_id = 5;❌ 索引失效(type: ALL)。 因为跳过了第一个字段 company_id。
场景 3:
ini
SELECT * FROM t_orders WHERE company_id = 10 AND order_status = 'DONE';⚠️ 部分失效。 只有 company_id 用到了索引,order_status 没用到(因为中间断了 workshop_id)。
原理解析:电话簿法则
联合索引就像一本电话簿。它是先按"姓"排序,如果"姓"一样,再按"名"排序。
- 如果你找"姓张"的人(company_id),很快能找到。
- 但如果你只知道某个人"名伟"(workshop_id),你没法利用目录,只能从第一页翻到最后一页(全表扫描)。
这就是著名的**"最左前缀原则" (Leftmost Prefix Principle)**。
第三步:进阶------JSON 字段的性能黑科技
随着业务灵活性的要求,越来越多的表开始使用 JSON 类型字段来存储非结构化数据(替代繁琐的 EAV 模型)。
但 DBA 往往很反感 JSON,因为:"JSON 里的 key 没法加索引,查起来太慢!"
比如:
kotlin
-- data 字段是 JSON 类型:{"device_model": "iPhone 15", "os_ver": "17.0"}
SELECT * FROM t_log WHERE data->'$.device_model' = 'iPhone 15';在老版本 MySQL 中,这绝对是全表扫描。但在 MySQL 5.7+ 和 8.0 中,我们可以通过"虚拟列 (Virtual Generated Column)"来解决这个问题。
优化方案:虚拟列索引
我们不需要修改业务代码,只需在数据库层做两步操作:
1. 创建一个虚拟列,自动提取 JSON 中的字段:
sql
ALTER TABLE t_log
ADD COLUMN v_device_model VARCHAR(50)
GENERATED ALWAYS AS (data->>'$.device_model') VIRTUAL;注意:VIRTUAL 关键字表示这个列不占用磁盘空间,它是实时计算的(但开销极小)。
2. 给这个虚拟列加索引:
scss
CREATE INDEX idx_device_model ON t_log(v_device_model);3. 见证奇迹:
再次执行查询(既可以查虚拟列,也可以查原 JSON 路径,优化器会自动识别):
ini
EXPLAIN SELECT * FROM t_log WHERE v_device_model = 'iPhone 15';type 变成了 ref。
通过这种"空间换时间"(索引占用空间)的方式,我们将 JSON 内部字段的查询性能提升到了与普通字段相同的水平。

总结
数据库性能优化中,80% 的性能问题可以通过规范的 SQL 编写解决:
- 保持敏感: 开发完 SQL,顺手跑一下 EXPLAIN,消灭所有的 ALL。
- 遵守规则: 建立联合索引时,把区分度高、查询最频繁的字段放在最左边。
- 拥抱新特性: 在处理 JSON 数据时,善用虚拟列索引,兼顾灵活性与性能。