点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年10月07日更新到: Java-141 深入浅出 MySQL Spring事务失效的常见场景与解决方案详解(3) MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成了如下的内容:
- Flink DataSet
- Flink DataSet 转换操作
- Flink DataSet 输出
- 容错机制、对比、发展方向

Flink Window 背景
Flink认为Batch是Streaming的一个特例,这种设计理念源于流批一体的架构思想。具体来说,Flink将批处理视为流处理的一种特殊情况,即有限流(bounded stream)处理。这与传统的批处理框架(如Hadoop MapReduce)有着本质区别。
Flink底层引擎是一个高度优化的流式引擎,核心组件包括:
- 分布式运行时环境
- 状态管理后端
- 检查点机制
- 时间处理模型
在这个流式引擎基础上,Flink实现了两种处理模式:
- 流处理(Streaming):处理无限流(unbounded stream)
- 批处理(Batch):处理有限流(bounded stream)
Window机制确实是从Streaming到Batch的重要桥梁,其作用主要体现在:
- 时间窗口(Time Window):包括滚动窗口、滑动窗口和会话窗口
- 计数窗口(Count Window):基于元素数量的窗口
- 全局窗口(Global Window):适用于批处理的特殊窗口
例如,在电商数据分析场景中:
- 流处理模式下,可以使用5分钟的滚动窗口实时统计成交量
- 批处理模式下,可以使用24小时的全局窗口处理历史订单数据
这种统一的设计使得开发者可以用同一套API处理实时和离线数据,大大简化了大数据处理架构的复杂度。同时,Flink通过优化批处理模式下的调度策略(如阻塞式数据传输)来提升批处理性能,使其在批处理场景也能保持竞争力。
通俗讲,Window是用来对一个无限的流的设置一个有限的集合,从而有界数据集上进行操作的一种机制,流上的集合由Window来划定范围,比如"计算过去10分钟"或者"最后50个元素的和"。 Window可以由时间(TimeWindow)比如30秒或者数据,(CountWindow)比如100个元素驱动。 DataStreamAPI提供了Time和Count的Window。
Flink Window 总览
基本概念
- Window 是Flink处理无限流的核心,Windows将流拆分为有限大小"桶",我们可以在其上应用计算。
- Flink 认为Batch是Streaming的一个特例,所以Flink底层引擎是一个流式引擎,在上面实现了流处理和批处理。
- 而Window窗口是从Streaming到Batch的一个桥梁。
- Flink提供了非常完善的窗口机制
- 在流处理中,数据是连续不断的,因此我们不可能等到所有等到所有数据都到了再开始处理。
- 当然我们可以每来一个消息就处理一次,但是有时候我们需要做一些聚合操作,例如:在过去一分钟内有多少用户点击了我们的网页
- 在这种情况下,我们必须定义一个窗口,用来收集最近的一分钟内的数据,并对这个窗口的内数据进行计算
- 窗口可以基于时间驱动、也可以基于事件驱动
- 同样基于不同事件驱动的可以分为:翻滚窗口(TumblingWindow 无重叠)、滑动窗口(Sliding Window 有重叠)、会话窗口(SessionWindow 活动间隙)、全局窗口
- Flink要操作窗口,先要将StreamSource转换成WindowedStream
转换步骤
- 获取流数据源
- 获取窗口
- 操作窗口数据
- 输出窗口数据
滚动时间窗口
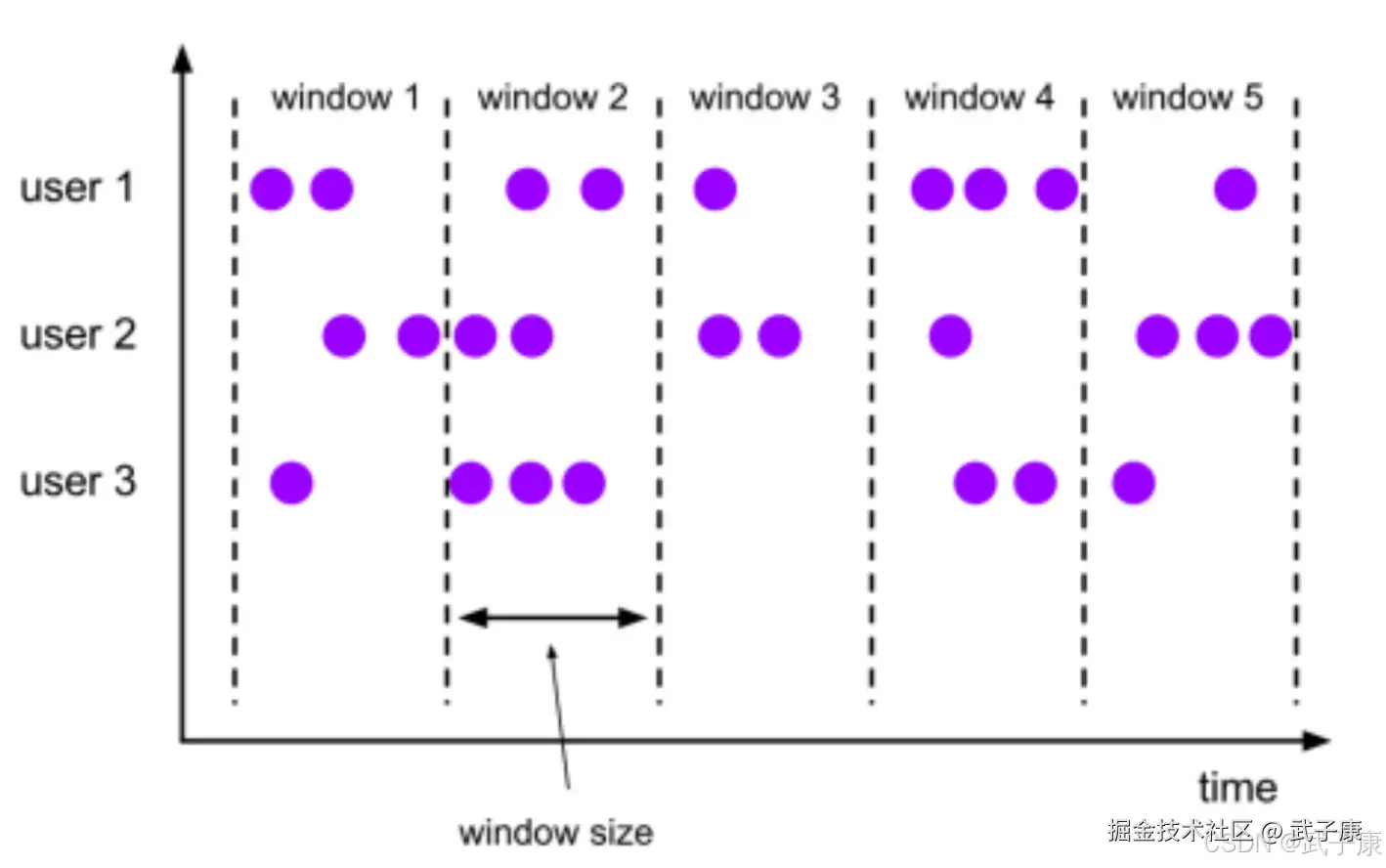
类型特点
将数据依据固定的窗口长度对数据进行切分时,需要遵循以下详细步骤和注意事项:
- 时间对齐处理
- 首先需要确保数据的时间戳是连续的、等间隔的
- 对于缺失的时间点,可以采用插值法(线性插值、样条插值等)或填充法(前向填充、后向填充)进行补全
- 示例:在5分钟间隔的传感器数据中,若缺少10:15的数据点,可用10:10和10:20的数据进行线性插值
- 固定窗口长度切分
- 根据业务需求确定窗口大小(如1小时、1天等)
- 从起始时间点开始,严格按窗口长度切分数据
- 每个窗口的数据量取决于采集频率
- 示例:对于每秒采样的数据,1小时窗口包含3600个数据点
- 无重叠处理
- 相邻窗口间严格分隔,不共享任何数据点
- 确保每个数据点只属于一个窗口
- 窗口边界处理:采用左闭右开区间,即[t, t+window_size)
- 应用场景
- 时间序列分析(如股票价格分析)
- 周期性数据统计(如每日用户活跃度统计)
- 设备监控(如每小时机器运行状态监测)
- 实现注意事项
- 边界数据:最后一个不完整窗口的处理方式(丢弃或单独处理)
- 计算效率:大数据量时需考虑并行处理
- 数据一致性:确保窗口切分不会改变数据的统计特性
这种切分方式特别适合需要严格时间对齐的分析场景,如计算移动平均值、检测周期性模式等。
Flink 的滚动时间窗口(Tumbling Window)是一种常见的基于时间的窗口机制,可以通过事件驱动进行计算。滚动窗口的特点是时间窗口是固定长度的,窗口之间没有重叠,每个事件只能进入一个窗口。
在 Flink 中,滚动时间窗口可以基于事件时间(Event Time)或者处理时间(Processing Time)来定义。为了基于事件时间驱动,可以使用 EventTimeSessionWindows 或者 TumblingEventTimeWindows 来进行定义。
关键点
- 事件时间和水印 (Watermark): 通过 assignTimestampsAndWatermarks 来指定事件时间,并使用水印确保窗口计算不会遗漏延迟的事件。
- 窗口定义: 使用 TumblingEventTimeWindows.of(Time.seconds(x)) 定义滚动窗口。窗口长度为 x 秒。
- 触发器: 采用 EventTimeTrigger 触发计算,确保窗口是基于事件时间的。
基于时间驱动
场景:我们需要统计每一分钟用户购买商品的总数,需要将用户的行为事件按每一分钟进行切分,这种切分被叫做 翻滚时间窗口(Tumbling Time Window)。 启动的主类:
java
package icu.wzk;
public class TumblingWindow {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> dataStreamSource = env.getJavaEnv().socketTextStream("localhost", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = dataStreamSource
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
long timeMillis = System.currentTimeMillis();
int random = new Random().nextInt(10);
System.out.println("value: " + value + ", random: " + random + ", time: " + format.format(timeMillis));
return Tuple2.of(value, random);
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = mapStream
.keyBy(new KeySelector<Tuple2<String, Integer>, Tuple>() {
@Override
public Tuple getKey(Tuple2<String, Integer> value) throws Exception {
return Tuple1.of(value.f0);
}
});
// 基于时间驱动 每隔 10秒 划分一个窗口
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> timeWindow = keyedStream
.timeWindow(Time.seconds(10));
timeWindow.apply(new MyTimeWindowFunction()).print();
env.execute("TumblingWindow");
}
}我们实现一个 MyTimeWindowFunction,滚动时间窗口:
java
package icu.wzk;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.text.SimpleDateFormat;
public class MyTimeWindowFunction implements WindowFunction<Tuple2<String, Integer>, String, Tuple, TimeWindow> {
/**
* 场景:我们需要统计每一分钟用户购买商品的总数,需要将用户的行为事件按每一分钟进行切分,这种切分被叫做 翻滚时间窗口(Tumbling Time Window)
* @author wzk
* @date 16:58 2024/7/26
**/
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<String> out) throws Exception {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
int sum = 0;
for (Tuple2<String, Integer> tuple2 : input) {
sum += tuple2.f1;
}
out.collect("key: " + tuple.getField(0) + ", value: " + sum +
", window start: " + format.format(window.getStart()) + ", window end: " + format.format(window.getEnd()));
}
}基于事件驱动
场景:当我们想要每100个用户的购买行为作为驱动,那么每当窗口中填满了100个"相同"元素,就会对窗口进行计算。 编写一个启动类:
java
package icu.wzk;
public class TumblingWindow {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> dataStreamSource = env.getJavaEnv().socketTextStream("localhost", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = dataStreamSource
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
long timeMillis = System.currentTimeMillis();
int random = new Random().nextInt(10);
System.out.println("value: " + value + ", random: " + random + ", time: " + format.format(timeMillis));
return Tuple2.of(value, random);
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = mapStream
.keyBy(new KeySelector<Tuple2<String, Integer>, Tuple>() {
@Override
public Tuple getKey(Tuple2<String, Integer> value) throws Exception {
return Tuple1.of(value.f0);
}
});
// 基于时间驱动 每隔 10秒 划分一个窗口
WindowedStream<Tuple2<String, Integer>, Tuple, GlobalWindow> globalWindow = keyedStream
.countWindow(3);
globalWindow.apply(new MyCountWindowFuntion());
env.execute("TumblingWindow");
}
}编写一个事件驱动的类:MyCountWindowFuntion
java
package icu.wzk;
public class MyCountWindowFuntion implements WindowFunction<Tuple2<String, Integer>, String, Tuple, GlobalWindow> {
/**
* 场景:当我们想要每100个用户的购买行为作为驱动,那么每当窗口中填满了100个"相同"元素,就会对窗口进行计算。
* @author wzk
* @date 17:11 2024/7/26
**/
@Override
public void apply(Tuple tuple, GlobalWindow window, Iterable<Tuple2<String, Integer>> input, Collector<String> out) throws Exception {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
int sum = 0;
for (Tuple2<String, Integer> tuple2 : input) {
sum += tuple2.f1;
}
// 无用的时间戳:默认值是:Long.MAX_VALUE,在事件驱动下,基于计数的情况,不关心时间
long maxTimestamp = window.maxTimestamp();
out.collect("key:" + tuple.getField(0) + ", value: " + sum + ", maxTimestamp :"
+ maxTimestamp + "," + format.format(maxTimestamp));
}
}