引言
在过去十年里,个人、企业与机构产生的数据量激增,这给"超大规模数据"的管理带来了挑战。产生海量数据的企业需要为正在生成的数据寻找合适的管理方案,还要识别数据的访问模式,区分"高频访问数据"和"低频访问数据"。完成这种数据分层后,就需要设计一种既能优化访问又能优化存储成本的方案。
要想在访问与存储成本之间找到最优解,必须基于"访问频度"和"数据新近性"做权衡。
- 访问频度 直接决定用户体验:被频繁访问的数据若延迟高,会导致大量用户的糟糕体验。
- 数据新近性 也很关键:尤其是做时间序列分析时,最近写入的数据往往在短期内被访问。
本章将介绍如何识别冷热分层 中的热数据、温数据与冷数据,并区分热数据与冷数据;我们还会引入通过数据缓存来服务热数据的存储与服务模式(第 14 章将详细展开缓存与低延迟服务),并在本章探讨冷数据的存储、归档与服务模式。
结构
本章涵盖以下主题:
- 识别热数据、温数据与冷数据
- 数据缓存简介
- 数据归档
- 使用 AWS S3 定义数据生命周期
目标
读完本章,你将理解为何需要对数据做冷热分离,并掌握可用于冷热分离的设计模式与工具。你将能基于访问频度、访问成本、访问延迟 三者之间的权衡做出设计决策。
本章还将引入数据归档的概念,以及利用数据工程模式来实现归档的典型用例。
识别热、温、冷数据
我们延续"旅行聚合平台"的示例来说明如何区分热/温/冷数据。前面提到,访问模式受访问频度 与数据新近性共同影响。理解二者有助于正确分层,也将决定应用的性能与成本。
数据访问频度
以"酒店预订"流程为例,用户可能会:
- 按目的地城市搜索酒店;
- 按评分或价格排序;
- 打开若干酒店的详情页,查看设施、地址、用户评价、用户上传的图片等;
- 选择房型与其他预订信息;
- 支付并完成预订。
其中第 3 步会频繁读取大量详情数据(评论与照片可能是"成百上千")。若每次都直接从云存储(如 Amazon S3)读取,既耗时又计费;同一数据重复读取也会重复计费。并且,跨区域读取会进一步增加延迟与费用。
为保证浏览体验,通常会将这些高频访问 的评论与照片缓存在内存缓存 (如 Memcached、Redis)中。因此,热门酒店的评论与照片可视为热数据 ;而访问较少的酒店相关内容则可视为温/冷数据。
数据新近性
再看"预订历史"。多年累积下,预订记录可能非常庞大。出于合规或业务需要,企业可能必须保留若干年的订单、发票等数据;超过一定年限后,若访问概率极低,可将其归档。
一个典型的生命周期是:
- 从预订日到离店日:数据被频繁访问,视为热数据;
- 离店后数月:仍可能被访问(售后/退款/对账等),视为温数据;
- 再往后:访问概率极低,可视为冷数据。
可视化冷热分层
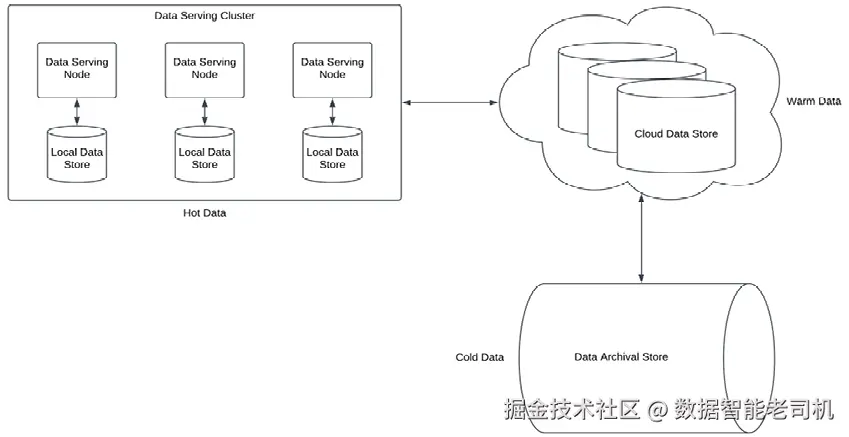
在云环境中,热/温/冷数据通常如下部署(见图 13.1 的概念示意):
-
热数据 :常存于缓存 。缓存位于应用节点的本地存储/内存,容量远小于云存储,且通常是易失的(节点宕机即丢失)。新节点上线后会按策略重新填充缓存(如何填充将在第 14 章展开)。
-
温数据 :常存于云对象存储 (如 Amazon S3)。S3 作为持久层,具备高可用;若与计算在同一区域,读延迟可达亚秒级。但每次读取都计费,因此对热点数据配合缓存可显著降费。
-
冷数据 :存于归档存储 。当温数据不再用于日常交易或分析时,可转入归档层。归档存储费用更低,但访问延迟更高。以 S3 为例:
- S3 Infrequent Access(低频访问) :存储成本约为标准 S3 的一半,但访问延迟更高;
- S3 Glacier:存储成本约为 S3 IA 的三分之一,但访问延迟更高,且默认假设访问频度很低。
上述分层让我们能将高频、低延迟 的访问集中在缓存与近端存储上,同时把大体量、低频的数据下沉到低成本介质,从而在成本与性能之间取得平衡。
数据缓存简介
数据缓存是一种把数据"放在更靠近服务节点处"的技术。数据离得越近,访问与返回所需的时间就越长。
让我们继续以酒店预订为例,如下图所示:
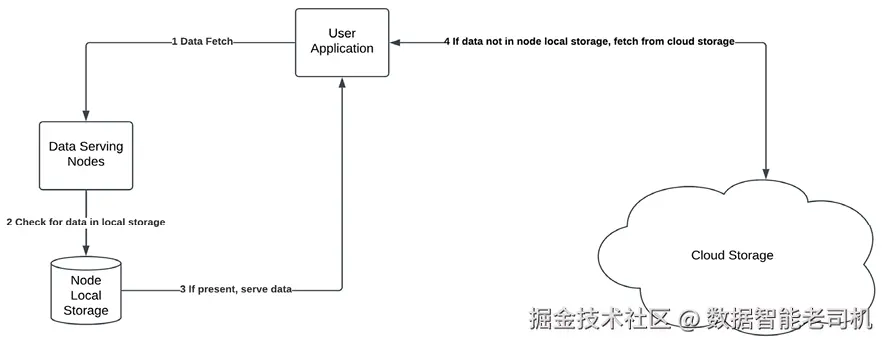
图 13.2:数据缓存
正如前文按访问频度所述,最常被浏览的酒店评论与照片可以缓存在数据服务节点的本地存储中。因此,如图 13.2,当应用需要访问数据时,会执行以下步骤:
- 对给定数据对象,先检查其是否存在于节点本地缓存;
- 若命中,则直接从本地缓存返回;
- 若未命中,则从云存储获取该数据对象;
- 按缓存策略,将取回的数据写入缓存以供后续复用。
一些常见的缓存原则如下:
- 缓存中的数据通常只是持久化云存储 中数据的子集。
- 当发生写入、更新或删除时,首先作用于持久层 ,随后再反映到缓存 ;也就是说,用户程序不直接修改缓存内容,以保证缓存的最终一致性。
- 缓存内容是可丢弃且可重建的:当现有节点下线或新节点上线时,可清空并按策略重新填充。
第 14 章《数据缓存与低延迟服务》将进一步讨论缓存模式与淘汰策略。
数据归档
数据归档 是将不再需要 的业务数据从温存储(如 AWS S3)迁移到归档存储 的过程。被归档的数据极少被访问(如果会被访问的话),当满足清理条件时可从归档中永久删除。归档的动机通常包括:
- 合规要求:例如个人信息、健康数据、金融数据需保存若干年;
- 审计需求:未来的财务审计需要保留数年历史;
- 安全防护:为防攻击在归档层保留一份副本;
- 降本:归档层的单位存储成本更低。
以一项假设的法律合规要求为例:
对旅行聚合业务,可能规定所有出行与酒店预订 需至少保存 8 年 。这些数据在日常业务或分析中的价值,过了两三年后大多不再需要,但一旦发生诉讼,仍需调取以还原行为路径。因此必须设计归档系统以满足合规。
在该场景中可以看到:
- 不再用于日常业务/分析的数据可能只"两三年 "之久,但出于法律 原因需至少保存 8 年 ,我们称之为归档数据;
- 归档数据通常不被访问,除非发生与之相关的诉讼;
- 真正被访问的往往只是极小子集;
- 这类访问不要求秒级 ,甚至小时级延迟也可接受;
- 因此无需继续放在像 S3 这类为低延迟优化、但更昂贵的温存储中。
这类归档数据的访问模式通常称为 WORM(Write Once Read Many)一次写入,多次读取。
为了在存储成本 与访问时延 之间做权衡,我们接下来以 Amazon S3 的数据生命周期(Lifecycle) 功能为例进行说明。
使用 AWS S3 定义数据生命周期
AWS S3 提供多种对象存储级别(Storage Class)。不同的级别在数据访问成本 、数据存储成本 以及取回延迟上各不相同。结合本书场景,我们重点关注三种级别:
- Standard(标准存储)
- Infrequent Access(低频访问,简称 IA)
- Glacier(归档)
**注:**无论哪种存储级别,Amazon S3 都会将数据持久化到磁盘,从而确保最终一致性。
为理解如何选择与定义存储级别,我们继续"网约车发票"的例子。
网约车发票场景假设:
- 支持在出行日前 60 天内下单;
- 每笔订单都会生成一张 发票,并存放在 S3 桶中;
- 发票下载很少见;用户通常只会在出行后 30 天内 至多下载 一两次;此后几乎不再访问;
- 合规要求:自下单日起至少保存 3 年以便审计;
- 审计员可能在这 3 年内索取发票,之后就不再需要。
据此,我们可定义如下策略:
- 发票生成后不必 使用 Standard;可直接使用 S3 Infrequent Access 。由于访问稀少,可以用更低的存储费 换取更高的访问费。
- 发票生成 90 天后 ,将其转入 Glacier ,因为之后更少被访问。这样可进一步降低存储费,再次以更高访问费与更长取回时延 换取更低存储费。
这些策略在应用设计上对应为:
- 写入 S3 时,将对象默认 StorageClass 设为 STANDARD_IA;
- 在桶上设置 Lifecycle 规则 ,将对象在 90 天后转储到 Glacier。
将对象存为低频访问(IA)的示例代码:
ini
import boto3
client = boto3.client('s3')
response = client.put_object(
Body='<S3 Object Content>',
Bucket='travel',
Key='invoices/invoiceId',
StorageClass='STANDARD_IA'
)配置生命周期:从 IA 迁移到 Glacier(boto3 示例):
ini
import boto3
client = boto3.client('s3')
# 仅对发票生效的过滤器
filters = {
'Prefix': 'invoices/',
}
# 转储规则:90 天后转至 Glacier
transitions = [
{
'Days': 90,
'StorageClass': 'GLACIER',
},
]
# 生命周期配置
lifecycle_config = {
'Rules': [
{
'ID': 'InvoicesToGlacier',
'Status': 'Enabled',
'Filter': filters,
'Transitions': transitions,
},
]
}
# 应用到指定桶
response = client.put_bucket_lifecycle_configuration(
Bucket='bucket_name',
ChecksumAlgorithm='CRC32',
LifecycleConfiguration=lifecycle_config,
)访问已归档的数据
对于 Standard/IA 的对象,可直接使用 boto3 的 get_object API 读取。
若对象已迁移到 Glacier,需先**恢复(Restore)**到 S3,随后再读取。因此分两步:
- 从 Glacier 发起恢复到 S3(可能需要数小时);
- 轮询 恢复状态;完成后使用
get_object读取。
示例代码:
ini
import boto3
import time
client = boto3.client('s3')
# 1) 发起恢复,请求对象在 S3 中保留 7 天
response = client.restore_object(
Bucket=bucket_name,
Key=object_key,
RestoreRequest={
'Days': 7,
'GlacierJobParameters': {'Tier': 'Standard'}
}
)
# 2) 轮询恢复状态(生产中应加入超时控制)
while True:
response = client.head_object(Bucket=bucket_name, Key=object_key)
restore_status = response.get('Restore', '')
if 'ongoing-request="false"' in restore_status:
# 恢复完成,读取对象
obj = client.get_object(Bucket=bucket_name, Key=object_key)
break
# 每 10 分钟检查一次
time.sleep(10 * 60)Glacier 恢复等级(按时效/成本不同):
- Expedited:约 1--5 分钟,适用于紧急恢复;
- Standard:约 3--5 小时,常规恢复;
- Bulk:约 5--12 小时,批量恢复性价比更高。
存储级别对比汇总
| 存储级别 | 相对存储成本 | 相对访问成本 |
|---|---|---|
| Standard | 最高 | 最低 |
| Infrequent Access | 低于 Standard | 高于 Standard |
| Glacier | 低于 IA | 高于 IA |
表 13.1:S3 各存储级别成本对比
小结
本章介绍了如何依据访问频率 与数据新鲜度 区分热/温/冷数据 ,并据此在访问成本 与存储成本 之间做权衡。我们简述了数据缓存 (将热数据放在更靠近计算的位置以降低时延与成本),并给出了使用 AWS S3 存储级别与生命周期策略 实现数据归档 的实践方法,以及使用 boto3 恢复归档对象 的流程。需要强调的是,S3 生命周期策略可随时调整,便于将来按业务变化进行优化。
下一章将继续探讨数据缓存相关的数据工程模式。