本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
自然语言理解(NLU)作为AI智能体与用户交互的核心环节,其效果直接决定了用户体验的优劣。在NLU技术体系中,意图识别 (Intent Detection)与槽位抽取(Slot Filling)构成语义解析的完整链路,共同承担着理解用户输入的关键任务。
意图识别负责精准判断用户语义目的,如通过「订机票」这个关键词来识别意图;槽位抽取则聚焦于结构化关键信息的提取,如从订餐需求中提取"菜品名称""送餐地址"等必备参数。今天我将系统剖析从初级到高阶的4套技术方案,希望能帮助到大家。

一、初级方案:提示词工程驱动(快速入门首选)
作为多数AI智能体初期的默认方案,初级方案A通过精细化提示词设计,在单一LLM节点中同时实现意图识别与槽位抽取,无需额外算法或架构改造,门槛极低。
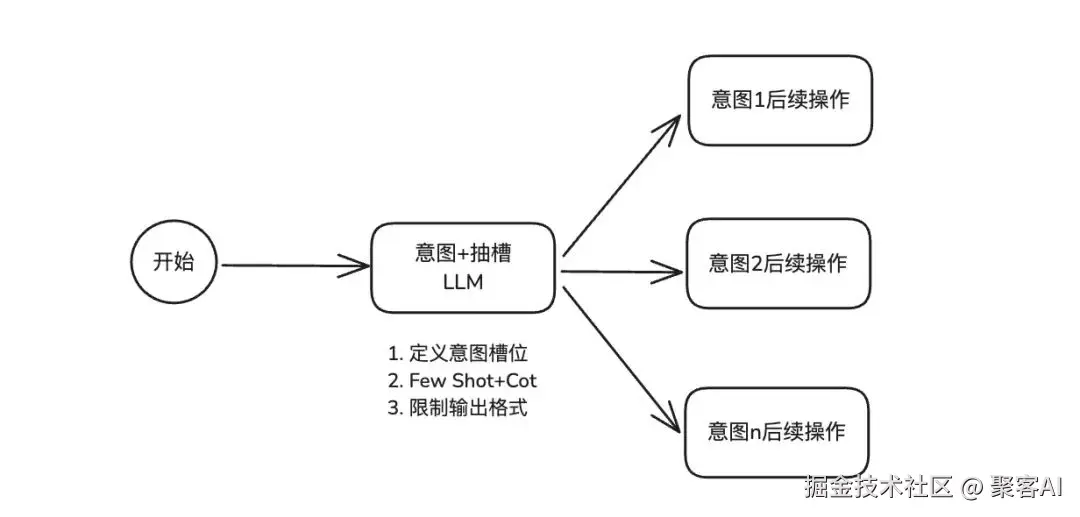
核心实现逻辑
方案A的提示词设计包含三大关键模块:
- 意图槽位明确定义:为AI智能体提供"任务字典",精准界定意图范畴、槽位名称、数据类型及取值范围
- Few-Shot + CoT引导:为每个意图搭配典型示例,同时融入思维链引导大模型逐步拆解用户输入
- 结构化输出约束:强制大模型以JSON、XML等标准格式输出结果,确保后续系统可直接解析
方案特性
- 优势:开发成本低、落地速度快,无需复杂技术栈,在意图数量较少(5个以内)的场景中能以低成本实现较高准确率。
- 局限:可扩展性差,当意图数量增多时提示词长度会大幅膨胀,导致大模型处理负担加重,易出现意图混淆和槽位抽取错误。
- 适用场景:意图分支少(≤5个)、业务场景简单、对识别准确性容错率较高的需求,如小型工具类智能体、内部试用版系统。
二、中级方案:意图与抽槽节点分离(复杂意图适配)
为解决初级方案在多意图场景下的"提示词膨胀"问题,中级方案B采用"解耦架构",将单一节点拆分为"意图识别"和"槽位抽取"两个独立LLM节点。
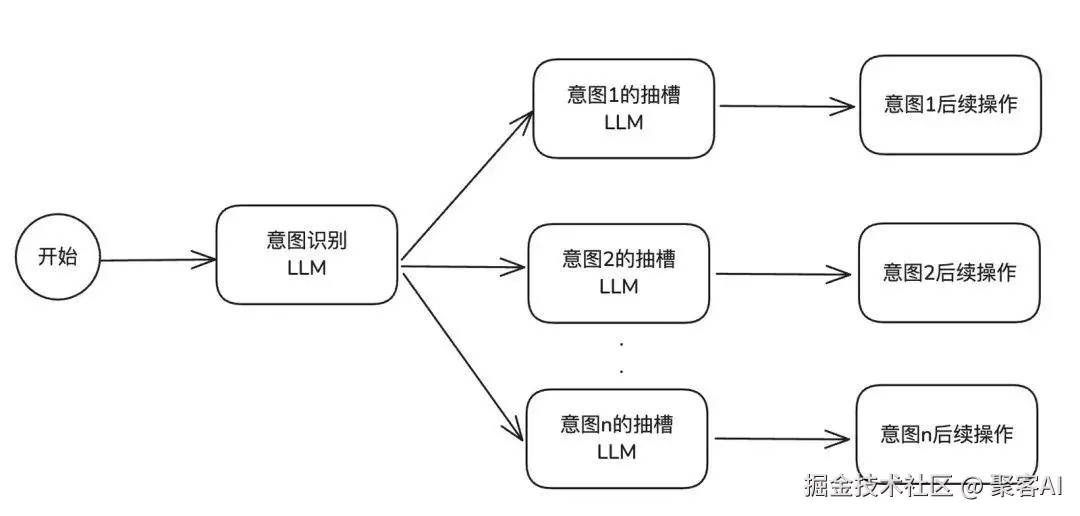
核心实现逻辑
方案B的架构设计遵循"职责单一"原则:
- 意图识别节点:仅负责判断用户输入所属意图类别,提示词中仅包含所有意图的基本描述
- 槽位抽取节点:为每个意图单独配置专属抽槽节点,每个节点仅聚焦对应意图的槽位规则
- 流程联动:用户输入先进入意图识别节点,确定意图后自动路由至对应抽槽节点
方案特性
- 优势:架构逻辑清晰,维护性强,新增或修改意图时仅需调整对应抽槽节点;提示词长度可控,单节点处理效率提升。
- 局限:系统调用次数增加导致延迟升高,意图识别(2.66s)+槽位抽取(2.15s)总耗时近5秒。
- 适用场景:意图分支多(5-15个)、业务逻辑复杂但对响应延迟敏感度较低的场景,如企业内部业务咨询智能体、非实时性服务预约系统。
三、进阶方案:前置意图RAG召回(泛化能力提升)
随着AI智能体上线,实践中发现基础方案无法很好理解方言、反问句等特异表达。进阶方案C引入RAG(检索增强生成)技术,通过"预泛化+检索"提升意图识别泛化能力。
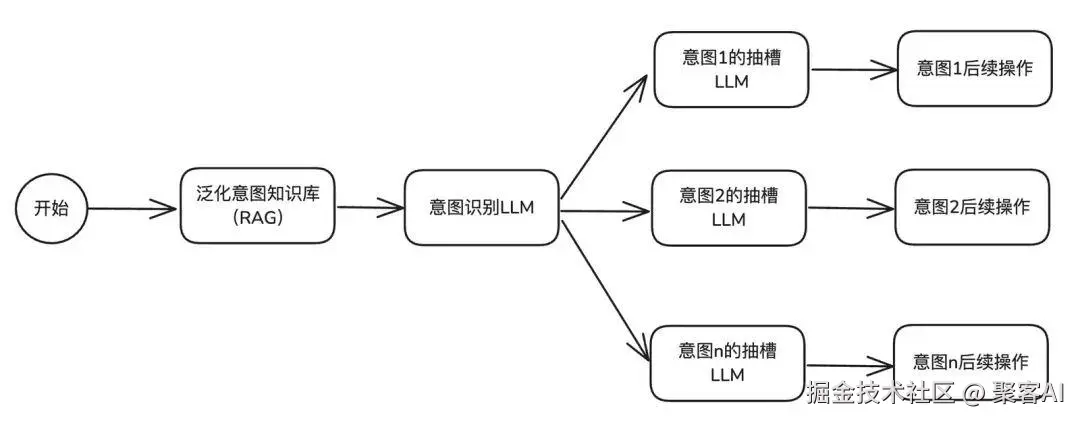
核心实现逻辑
方案C的核心是构建"意图泛化知识库",将LLM的实时泛化转化为预泛化:
- 构建意图语料种子:按垂类行业确定意图分类后,人工收集30-50个该意图的典型Query
- LLM泛化扩充语料:利用LLM对种子语料生成同义句,覆盖口语化、地域化、反问句等变体
- RAG召回辅助识别:用户提问时,系统先将输入与"意图泛化知识库"进行语义检索,召回最相似的泛化Query及对应意图
方案特性
- 优势:泛化能力可控,Bad Case修复快;模型成本降低,可选用性价比模型,意图识别准确率提升至94.8%。
- 局限:需额外投入研发成本构建RAG知识库,且多轮对话场景下效果不佳。
- 适用场景:单轮对话为主、存在大量特异表达(方言、口语化表述)的垂类场景,如地域化服务智能体、方言客服系统。
四、高阶方案:合并节点+升级RAG(多轮场景攻坚)
现实业务中用户需求往往涉及多轮对话,同时业务还要求"低延迟+高准确率"。高阶方案D在方案C基础上,优化为"合并节点+多轮RAG召回"架构。
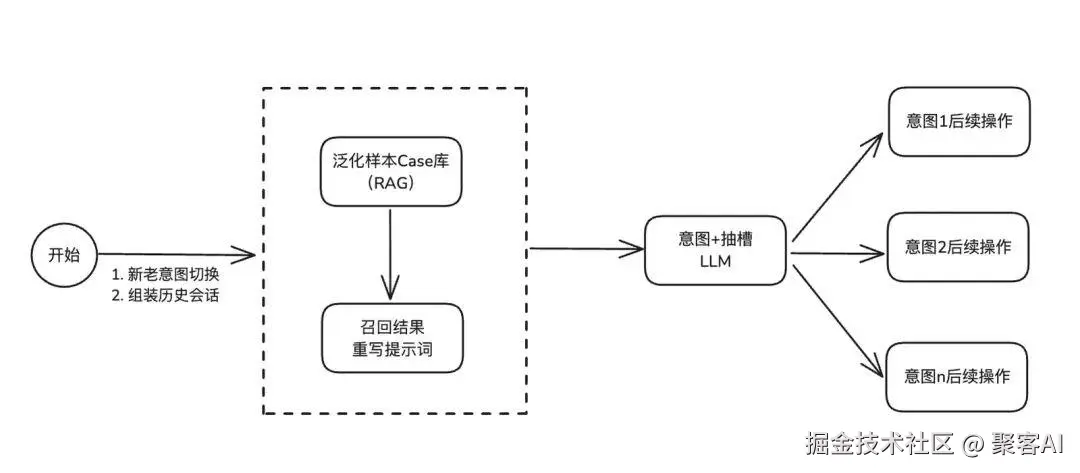
核心实现逻辑
方案D的关键在于"兼顾多轮理解与效率",核心设计包括四大模块:
- 意图槽位Case库管理:构建包含完整对话上下文的Case库,通过RAG统一管理
- 多轮会话组装召回:用户输入时,系统自动过滤历史对话中的无意义信息,组装检索文本并召回最匹配的多轮Case
- 延迟优化:直接回答机制:为无需LLM处理的意图设置直接回答机制,降低部分场景延迟
- 新老意图切断策略:当一个意图流程完全结束,系统自动清空该意图的历史记录,避免后续新意图受干扰
方案特性
- 优势:多轮理解能力强,准确率达97.6%;延迟可控,总耗时约2.7秒;Bad Case修复极快,仅需更新Case库。
- 局限:开发成本高,需人工标注多轮Case、泛化特异表达,每个意图需准备5-10个多轮案例。
- 适用场景:多轮对话为主、实时性要求高、准确率要求严格的核心业务场景,如客服对话机器人、智能出行助手。
ps:关于RAG优化,我之前也整理了一份3W字的付费技术文档,点赞+关注,我的粉丝朋友可以免费领取查阅:《检索增强生成(RAG)》
作者总结
AI智能体的意图识别优化是持续迭代的过程。从初级方案起步,根据用户反馈逐步升级至高阶方案,既能控制成本,又能确保系统始终贴合业务需求。在实际项目中,各位可以根据业务场景特点、资源约束和性能要求,选择最适合的技术方案。好了,今天的分享就到这里,点个小红心,我们下期见。