温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
一、项目背景与意义
随着人们生活水平的提高,健康问题日益受到重视。然而,优质医疗资源相对稀缺,医院人满为患,普通患者在面对常见病症时往往缺乏专业的指导,容易产生恐慌或盲目就医。
医疗智能问诊系统应运而生,它利用自然语言处理(NLP)和知识图谱(Knowledge Graph)技术,将海量的医学教材、指南和病例数据结构化,构建成医疗知识库。用户可以通过自然语言与系统交互,系统能精准识别用户意图(如"感冒了吃什么药?"、"头痛是什么原因?"),并从知识库中检索准确答案。
系统的主要意义在于:
- 分级诊疗辅助:为患者提供初步诊断建议,缓解线下门诊压力。
- 知识科普:以直观的图谱形式展示疾病、症状、药物之间的关联,普及医学常识。
- 7x24小时服务:提供即时、便捷的在线问诊服务。
系统演示视频及代码详情:https://www.bilibili.com/video/BV1sditBLE2o/
二、系统技术架构
本系统采用 B/S(Browser/Server)架构,前后端分离开发(逻辑上分离,物理上通过模板渲染)。
1. 技术栈
- 开发语言:Python 3.10
- Web 框架:Flask (轻量级、易扩展)
- 数据库:SQLite (轻量级关系型数据库,存储结构化知识)
- 前端技术 :HTML5, CSS3 (TailwindCSS), JavaScript, D3.js (知识图谱可视化)
- NLP 核心库 :
ahocorasick(AC自动机,用于高效多模式匹配),jieba(辅助分词,本项目主要依赖 AC 自动机)
2. 架构分层
- 数据层:存储医疗实体(疾病、药物、症状等)及其关系,以及用户信息。本项目为了简化部署,使用 SQLite 存储结构化的"三元组"信息。
- 算法层 :
- 实体识别:利用 AC 自动机算法从用户问句中快速提取医疗实体。
- 意图识别:基于特征词(如"怎么治"、"多少钱")的规则匹配算法,判断用户提问类型。
- 应用层:Flask 处理 HTTP 请求,调度算法层返回答案,并渲染 HTML 页面。
- 表现层:用户交互界面,包括聊天窗口、图谱展示页面等。
三、关键技术与实现逻辑
3.1 核心问答算法(Chatbot Logic)
系统的核心在于理解用户的自然语言提问。我们没有使用复杂的深度学习模型(如 BERT),而是设计了一套高效的基于规则与关键词匹配的算法,非常适合垂直领域的精确问答。
处理流程:
- 加载词典:系统启动时,加载疾病、科室、症状、药物等几大类实体的特征词库。
- 构建 AC 自动机 :使用
pyahocorasick库将数万个特征词构建成 Trie 树,实现 O(n)O(n) 复杂度的快速扫描。 - 意图分类 :根据问句中包含的"疑问词"(如"为什么"、"吃什么")和"实体类型"(如"疾病"、"症状"),将问题分为 10+ 类(如
user_intent_symptom查询症状,user_intent_cure查询治疗方法)。 - SQL 查询:根据分类结果构造 SQL 语句,从数据库中提取对应字段。
核心代码片段(基于特征词的分类):
python
# question_classifier.py
def classify(self, question):
data = {}
# 1. 实体识别 (AC自动机)
medical_dict = self.check_medical(question)
if not medical_dict:
return {}
# 2. 收集实体类型
types = []
for type_ in medical_dict.values():
types += type_
question_types = []
# 3. 规则匹配意图
# 例如:如果问句包含"症状"相关词且包含"疾病"实体 -> 询问某病的症状
if self.check_words(self.symptom_qwds, question) and ('disease' in types):
question_types.append('disease_symptom')
# 例如:如果问句包含"原因"相关词且包含"疾病"实体 -> 询问病因
if self.check_words(self.cause_qwds, question) and ('disease' in types):
question_types.append('disease_cause')
# ... (省略其他十几种规则)
data['question_types'] = question_types
data['args'] = medical_dict
return data3.2 知识图谱构建与存储
本项目将非结构化的文本数据(如《内科学》教材内容)清洗后,转化为结构化的字段存储在 Medical 表中。虽然底层使用关系型数据库 SQLite,但在逻辑上我们维护了图谱结构(实体-关系-实体)。
数据模型设计 (models.py):
python
class Medical(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(100), unique=True, index=True) # 实体名:疾病
desc = db.Column(db.Text) # 属性:描述
category = db.Column(db.String(255)) # 关系:属于科室
symptom = db.Column(db.Text) # 关系:包含症状 (以逗号分隔存储)
recommand_drug = db.Column(db.Text) # 关系:推荐药物
# ... 其他字段如 check(检查), prevent(预防), cure_way(治疗方式)这种设计在毕设规模下既保证了查询效率,又避免了引入 Neo4j 带来的部署复杂度。
3.3 知识图谱可视化 (D3.js)
为了让"知识"看得见,我们使用 D3.js (Data-Driven Documents) 库实现了力导向图(Force-Directed Graph)。
实现原理:
- API 接口 :后端
/api/graph_data接口接收查询词,从数据库中查询相关联的实体(如查询"感冒",返回"感冒"节点及其关联的"头痛"、"发烧"节点,"呼吸内科"节点等)。 - 前端渲染 :前端接收
nodes和links数据,利用 D3 的forceSimulation模拟物理引力和斥力,生成动态平衡的网络图。
前端代码片段块 (templates/graph.html):
python
let simulation = d3.forceSimulation()
.force("link", d3.forceLink().id(d => d.id).distance(100)) // 连线引力
.force("charge", d3.forceManyBody().strength(-150)) // 节点斥力(防重叠)
.force("center", d3.forceCenter(width / 2, height / 2)); // 中心引力
// 颜色映射:不同类型的节点显示不同颜色
const colorMap = {
'disease': '#3b82f6', // 蓝色
'category': '#ec4899', // 粉色
'symptom': '#ef4444', // 红色
'drug': '#10b981' // 绿色
};四、系统功能展示
1. 首页
2. 用户注册登录
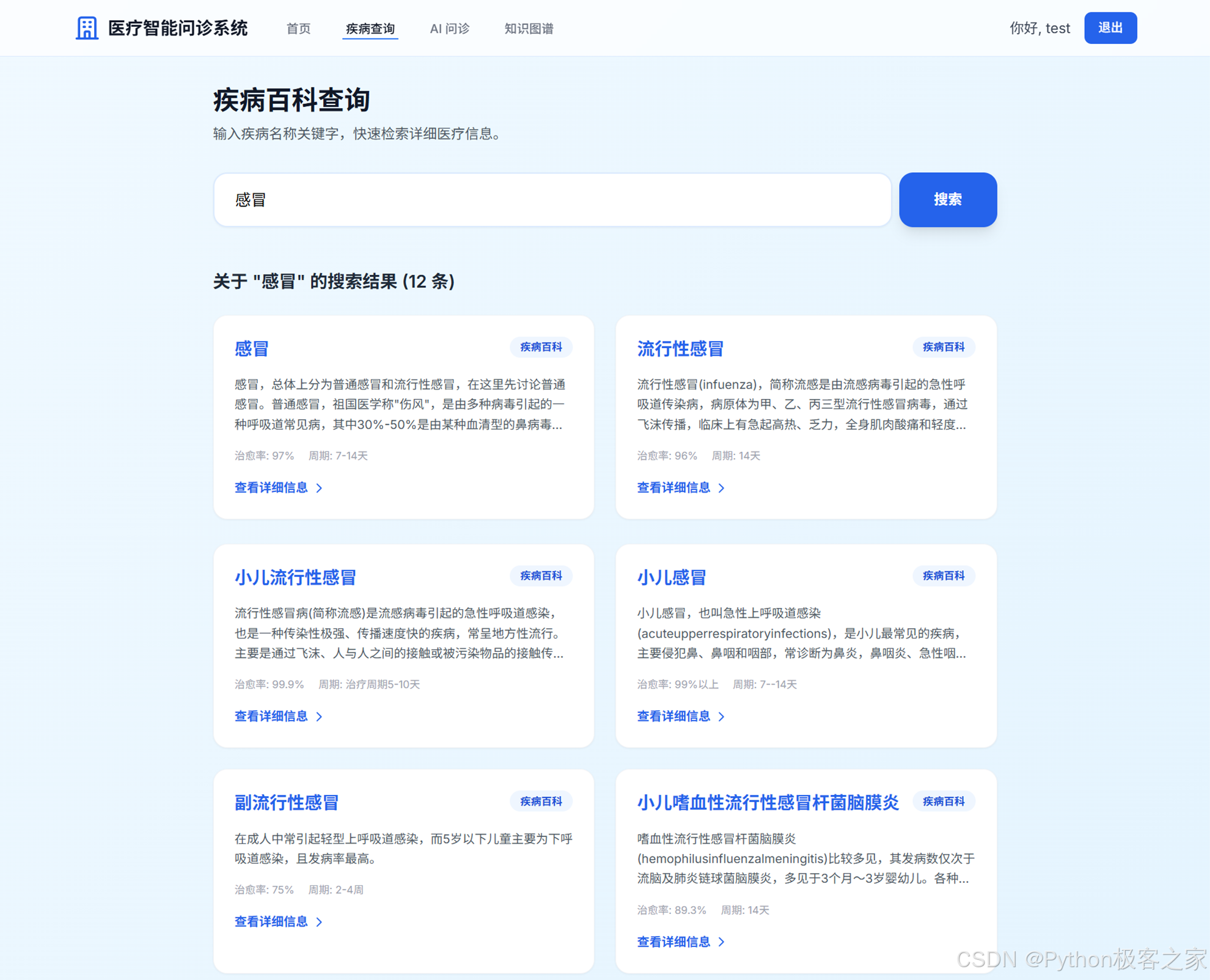
3. 疾病搜索
支持模糊搜索,用户输入关键词即可查看相关疾病的详细百科信息,包括简介、病因、预防、并发症等。
4. 疾病详情页

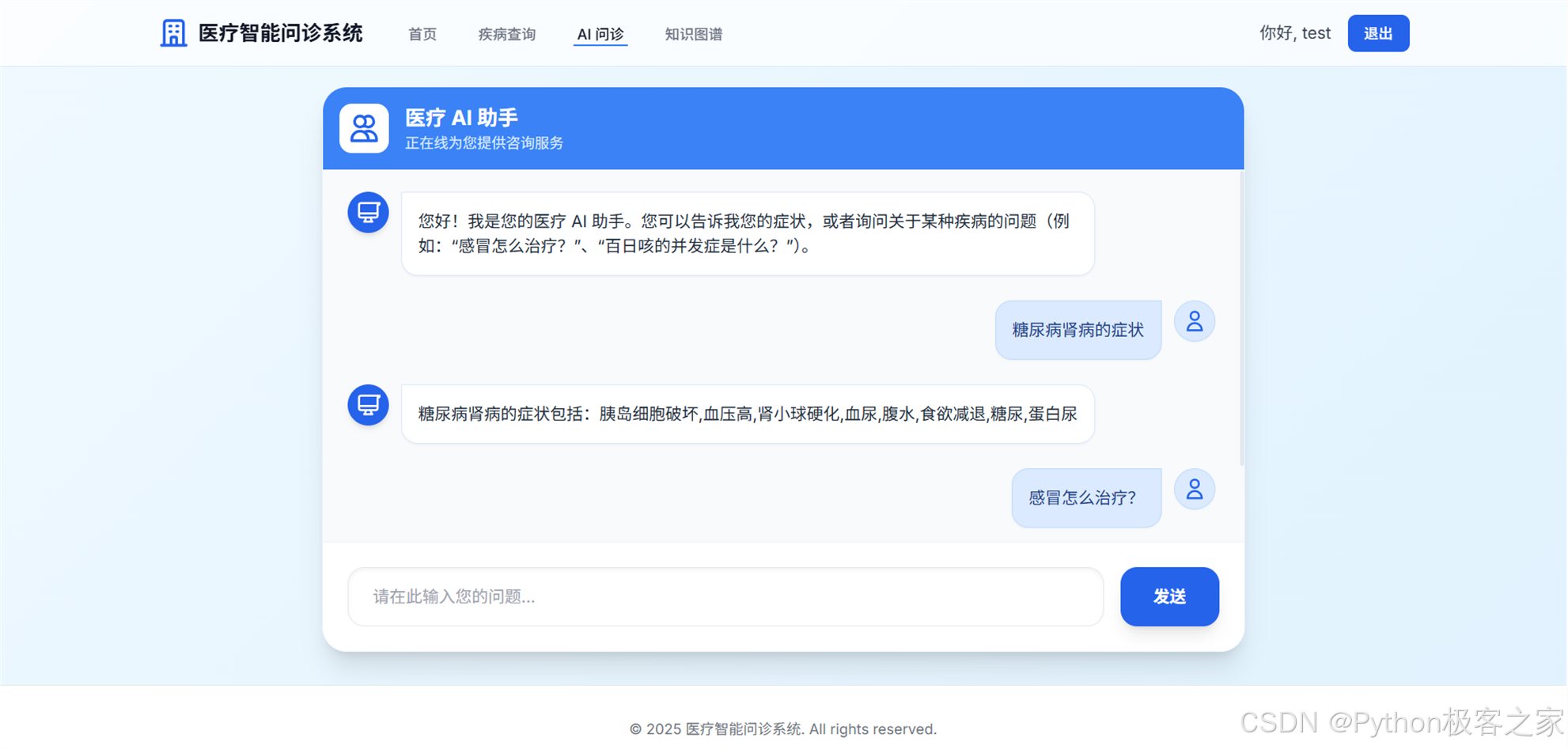
5. 智能问答对话
用户在聊天框输入问题,如"感冒了怎么办?",系统自动回答治疗建议、推荐药物等。支持多轮对话风格(一问一答)。
6. 知识图谱可视化
系统最具特色的功能。通过动态的力导向图,展示疾病与症状、科室、药物之间的网状关系。支持拖拽节点、缩放查看、全局搜索定位节点。

五、总结与展望
本系统成功实现了一个轻量级的医疗智能问答 Demo,巧妙地结合了传统的规则匹配算法与 Web 开发技术。
- 响应速度快:AC 自动机算法极其高效。
- 准确度可控:基于规则的回答不会像生成式大模型那样产生"幻觉",适合医疗领域的严谨性要求。
- 交互友好:图谱可视化提升了数据展示的趣味性和直观性。
不足与改进方向:
- 语义理解:对于口语化极强或表达含糊的问句,规则匹配可能失效。未来可引入 BERT 或 LLM (如 ChatGPT API) 进行意图识别增强。
- 图数据库:随着数据量增长,建议迁移至 Neo4j 以获得原生的图查询性能。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取 认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
