简单认识一下数据库
目录
知识点
部分定义来自《数据库系统概论》第6版(王珊,杜小勇,陈红)
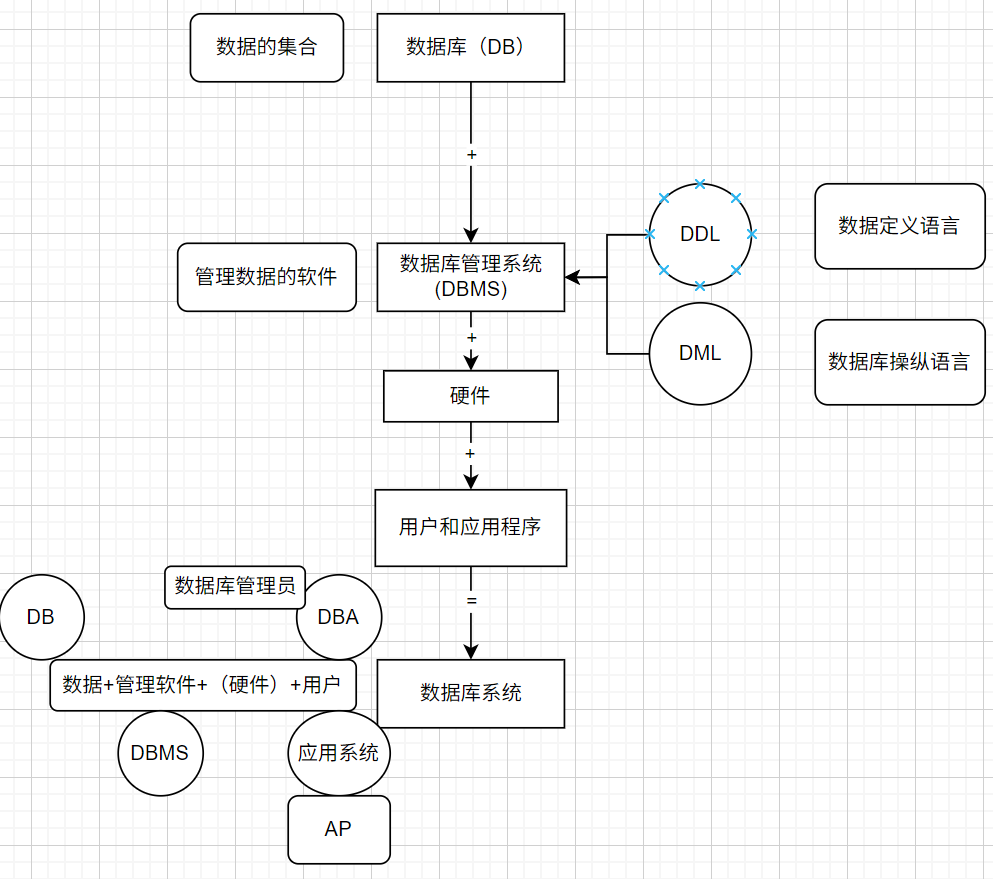
数据库(DB):长期储存在计算机内有组织,可共享的大量数据的集合 。
数据库管理系统(DBMS):介于用户和操作系统之间的用来管理数据的软件,同操作系统一样属于计算机基础软件。
主要功能:
1.数据定义 DDL
2.数据库操纵功能 DML
3.数据的组织,存储和管理
4.数据库的运行和管理与控制
5.数据库建立和维护
数据库系统(DBS):由数据库,数据空管理系统,数据库管理员,硬件,用户及应用程序 共同构成的一个系统
1.数据的结构化 采用数据模型
2.数据的共享性高,冗余度低,易扩展
3.数据的独立性高
4.数据由数据库管理系统统一管理控制
5.数据的最小存取单位是数据项
考点:
1.数据管理技术的三个阶段
人工管理阶段
1)数据不保存
2)应用程序管理数据
3)数据不共享
4)数据不具有独立性
文件系统阶段
1)数据长期保存
2)数据由专门的软件进行管理
3)共享弱,冗余度高
4)数据独立性弱
特点:应用程序与数据间一一对应
数据库系统阶段
1)整体数据的结构化
2)数据的共享性高,冗余度低且易于扩充
3)数据的独立性高
4)数据由数据库管理系统统一管理和控制
数据模型的三要素
1.数据结构
2.数据操纵
3.完整性约束
层次模型
树形结构表示各类实体以及实体间的联系
1.数据库系统中最早出现的数据模型
2.层次数据库系统典型代表 IBM 的 IMS
网状模型
网状数据库系统采用网状模型作为数据的组织方式
典型 DBTG
实际 IDMS DMS-1100 IDS/2 IMAGE
数据结构 (1) 允许一个以上的结点无双亲结点 (2)一个结点可以有多于一个的双亲结点
关系模型
1970 IBM 公司 E.F.Codd 首次提出关系模型
|-----|-------------------|
| 关系 | 一张二维表 |
| 元组 | 表中的一个行 |
| 属性 | 表中的一个列 |
| 键/码 | 可以确定唯一元组的某一或某一组属性 |
| 域 | 某一属性的取值范围 |
| 分量 | 元组中的一个属性值 |关系模式:对关系的描述 关系名(属性1,属性2,属性3.......,属性n)
例:学生表:
|------------|----|------|-----|
| 学号 | 姓名 | 班级 | 学院 |
| 2424000001 | 张三 | 计科3班 | 信息院 |
| 2424000002 | 李四 | 计科4班 | 信息院 |这张表就是关系
一个元组:|------------|----|------|-----|
| 2424000001 | 张三 | 计科3班 | 信息院 |属性:学号,姓名,班级,学院 都是属性
码:学号是码 一个学生只能有一个学号 姓名为什么不是 会有重名的时候
域:班级 有的班才能填 比如计科只有8各班域就是(计科1到计科8)不能有计科9,10
分量:|------------|----|------|-----|
| 2424000001 | 张三 | 计科3班 | 信息院 |2424000001 就是这个元组的一个分量
关系模式:学生(学号,姓名,班级,学院)关系的完整性
1.实体完整性
2.参照完整性
3.用户定义的完整性
关系的操作
主要两大类:查询和更新
更新包括:插入,删除,修改
还是 增删改查
查询还可进一步分为 选择,投影,交,差,笛卡尔积 5种基本操作
下面我们来看一下这些操作的效果吧
学生表:
|------------|----|------|-----|
| 学号 | 姓名 | 班级 | 学院 |
| 2424000001 | 张三 | 计科3班 | 信息院 |
| 2424000002 | 李四 | 计科4班 | 信息院 |
选择:
有条件的查询,从一张表中查出符合条件的行
找到姓名叫张三的
|------------|----|------|-----|
| 2424000001 | 张三 | 计科3班 | 信息院 |
投影:
指定列查询
查姓名
|----|
| 姓名 |
| 张三 |
| 李四 |
交:
既满足条件A,又满足条件B
学生 ID(s_id) 学生姓名(s_name) 课程名称(course) 101 张三 高数 101 张三 英语 101 张三 计算机基础 102 李四 高数 102 李四 线性代数 103 王五 英语 103 王五 计算机基础 104 赵六 高数 104 赵六 线性代数 104 赵六 英语 查询 "既选修了'高数'又选修了'线性代数'" 的学生
s_id s_name 101 张三 102 李四 104 赵六
差
(A-B 属于A但不属于B)
查询 "选修了'英语'但没选修'计算机基础'" 的学生
s_id s_name 101 张三 103 王五 104 赵六
笛卡尔积
|---|---|
| A | B |
| 1 | 1 |
| 1 | 0 |笛卡尔积运算后
|---|---|---|---|
| A | B | A | B |
| 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 0 |
| 1 | 0 | 1 | 1 |
| 1 | 0 | 1 | 0 |
数据库系统的三级模式
1.模式:所有用户的公共数据视图。 一个数据库只有一个模式 (视图一种虚拟表)
2.外模式/子模式/用户模式 是模式的子集 一个数据库可以有多个外模式
数据库用户能够看见和使用的局部数据的逻辑结构和特征的描述。 用户的数据视图
3.内模式/物理模式/存储模式 一个数据库只有一个内模式
对数据物理结构和存储方式的描述,是数据在数据库内部的组织方式
两级映像/数据独立性
物理独立性: 用户应用程序 与 数据库(物理存储)相互独立
实现方式靠调整内模式和模式间的映像保证内模式发生变化时,只要模式不变,应用程序就不用改
逻辑独立性: 应用程序 与 数据库(逻辑结构)相互独立
实现方式靠调整外模式和模式间的映像保证模式发生变化时,只要外模式不变,应用程序就不用改
使用
库操作
本机登录
mysql -uroot -p 输入密码
创建库
create database if not exists 库名 character set 字符集 collate 校对规则
eg: create database if not exists tb_name character set utf8mb4 collate utf8mb4_0900_ai_ci;

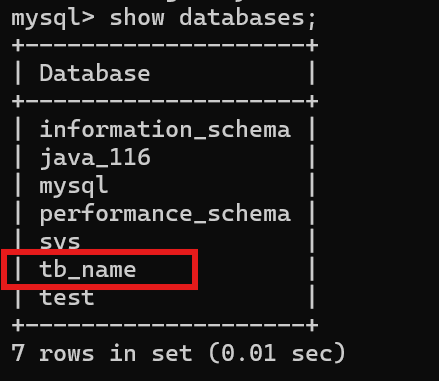
查看库
show databases;
使用库
use 库名;

删除库
drop database if exists 库名;

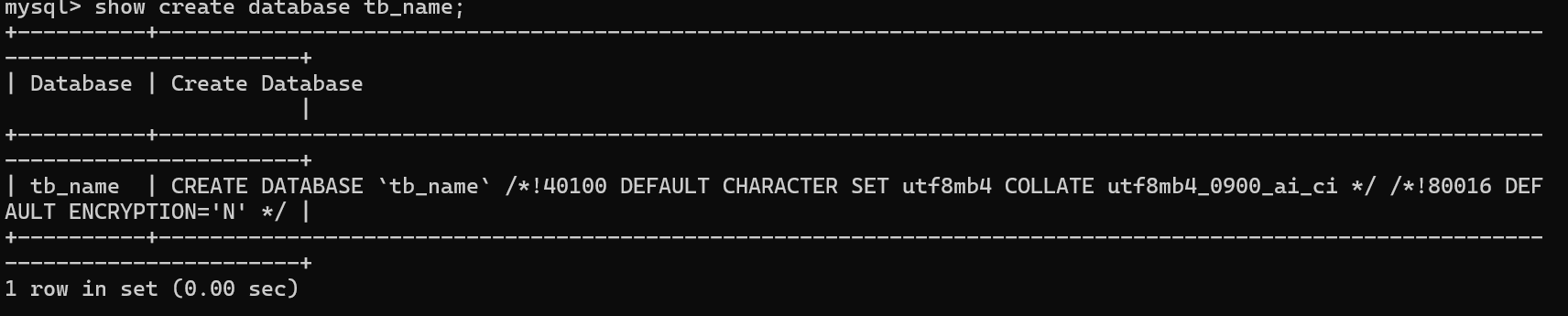
查看指定库详情
show create database 库名;
表操作
创建表
create table if not exists 表名 (列名 数据类型 comment '注解', 列名........)engine = charset = ;

数据类型
|--------------|-----------------|-------------|
| 类型 | 大小 | 含义 |
| BIT(M) | bit | 存0/1 M长度范围 |
| TINYINT(M) | 1B | 很小的整数类型 |
| BOOL | 1B = TINYINT(1) | 真/假 |
| SMALLINT | 2B | 较小范围的整数 |
| MEDIUMINT | 3B | 中等范围整数 |
| INT | 4B | 用于存储常规范围的整数 |
| INTEGER | 4B | 用于存储常规范围的整数 |
| BIGINT | 8B 常用 | 存储大范围整数 |
| DOUBLE | 8B 不建议用 | 双精度浮点 |
| FLOAT | 4B 不建议用 | 单精度浮点 |
| DECIMAL(M,D) | 动态的 用这个 | 无损浮点精度极高 |
字符类型
| 数据类型 | 说明 |
|---|---|
| CHAR(M) | 固定长度字符串,M 为长度(0 - 255),如存储长度一致的身份证、邮编等,浪费磁盘空间 |
| VARCHAR(M) | 可变长度字符串,M 为最大长度(最高 65535,不同存储引擎有差异),如存储长度变化的姓名、地址等,节省磁盘空间 |
| TEXT(M) | 长文本字符串 |
| TINYTEXT | 小型长文本 |
| MEDIUMTEXT | 中型长文本 |
| LONGTEXT | 大型长文本 |
| BINARY | 固定长度二进制字节,M 为长度,以字节为单位 |
| VARBINARY | 可变长度二进制字节 |
| TINYBLOB | 小型二进制大对象 |
| BLOB | 二进制大对象 |
| MEDIUMBLOB | 中型二进制大对象 |
| LONGLOB | 大型二进制大对象 |
| ENUM('value1','value2',...) | 枚举类型,从给定的字符串值列表中选一个 基本没用 |
| SET('value1','value2',...) | 集合类型,从给定的字符串值列表中选一个或多个值 基本没用 |
标红:在 MySQL 中已不建议使用相关旧的存储形式已经不存这些数据了
日期类型
| 数据类型 | 存储大小 | 时间范围 / 说明 |
|---|---|---|
| TIMESTAMP(p) | 4 bytes | 时间戳类型,范围约 1970-01-01 00:00:01 到 2038-01-19 03:14:07 |
| DATETIME(p) | 8 bytes | 日期时间类型,范围 1000-01-01 00:00:00 到 9999-12-31 23:59:59 |
| DATE | 3 bytes | 日期类型,范围 1000-01-01 到 9999-12-31 |
| TIME | 3 bytes | 时间类型,范围 -838:59:59 到 838:59:59(可表示一天之外的时间间隔) |
| YEAR | - | 年份类型 |
| 函数 | 说明 |
|---|---|
CURRENT_DATE / CURRENT_DATE() / CURDATE() |
获取当前日期 |
CURRENT_TIME / CURRENT_TIME([p]) / CURTIME([p]) |
获取当前时间 |
CURRENT_TIMESTAMP / CURRENT_TIMESTAMP([p]) / NOW() |
获取当前日期和时间 |
查看表
desc table 表名;

修改表
1.alter table 表名 add column 列名 数据类型约束 comment ' ' 注解; 加一列
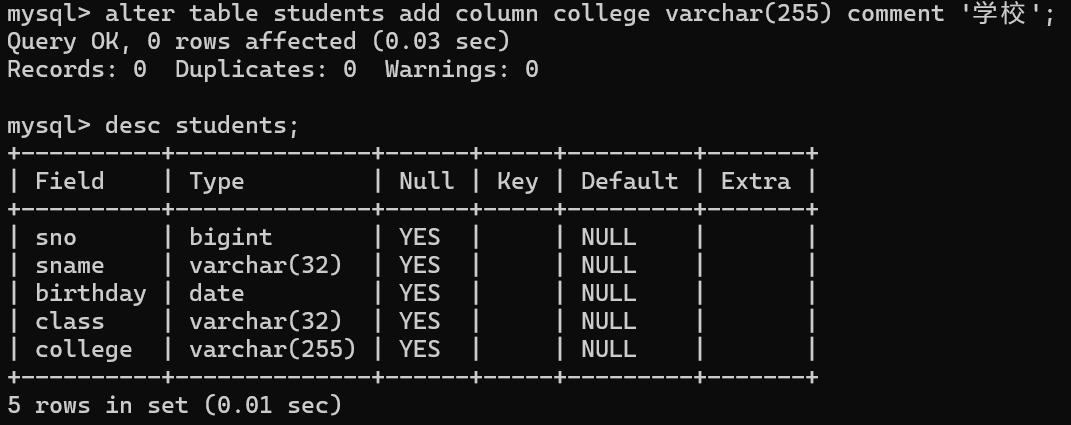 2.alter table 表名 modify column 列名 数据结构约束 ; 改一列
2.alter table 表名 modify column 列名 数据结构约束 ; 改一列
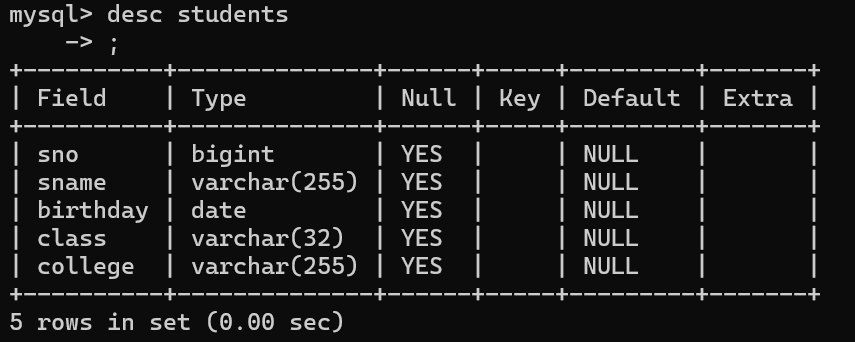
3.alter table 表名 drop column 列名; 删一列
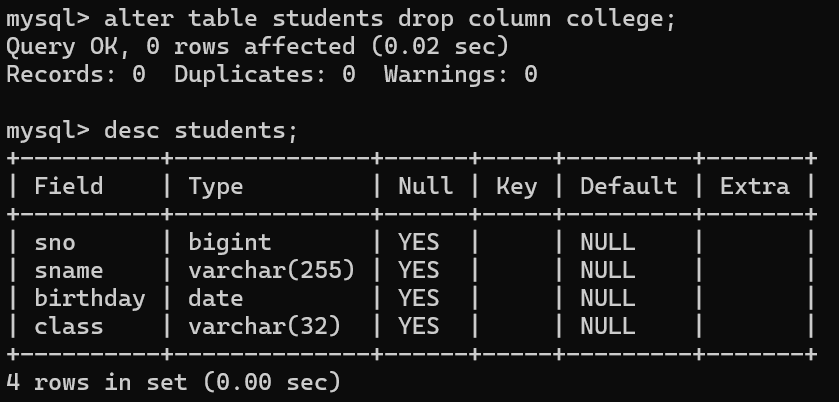
删除表
drop table if exists 表名;
插入
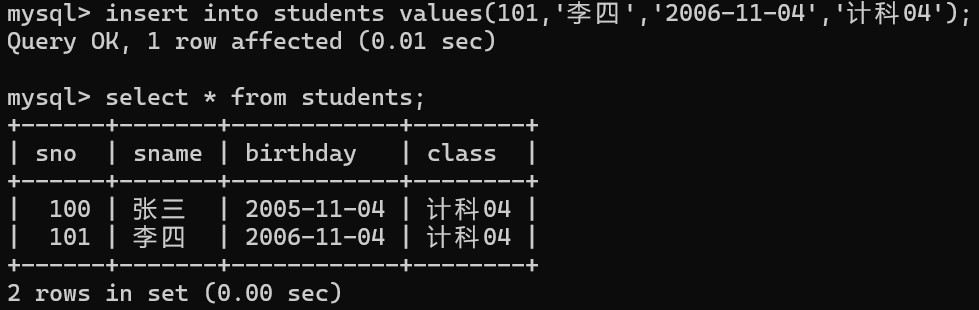
insert into 表名 (列名1,列名2,.....) values(值1,值2,.......); 多行指定列插入
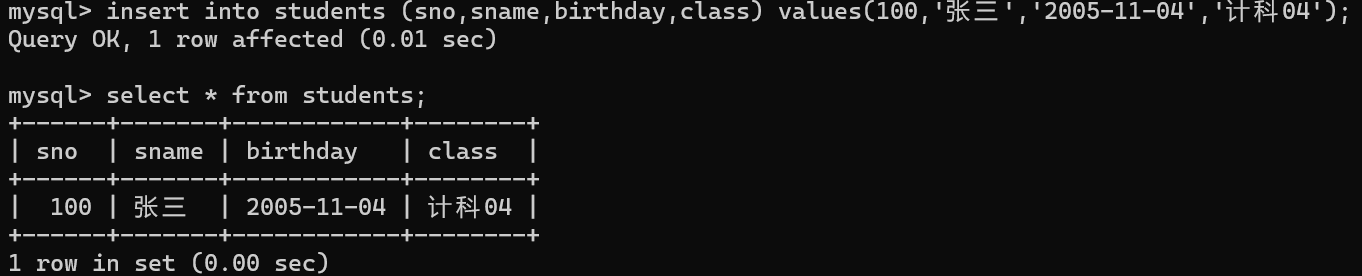
insert into 表名 (列名) values(值1); 单行指定列插入
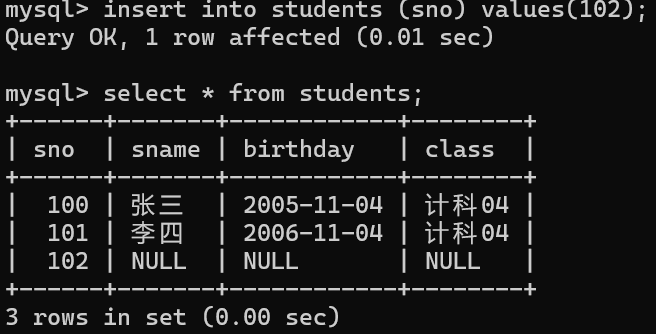
insert into 表名 values(值1,值2,.......); 不指定列插入
查询
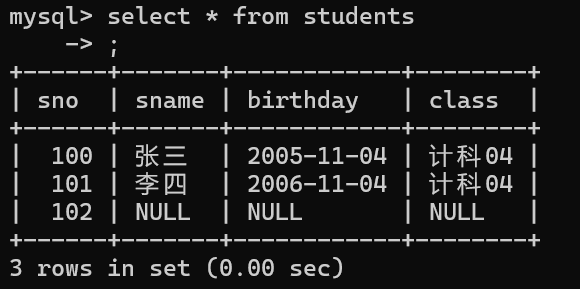
查全表
select * from 表名;
指定列查询
select 列名,列名,...... from 表名;
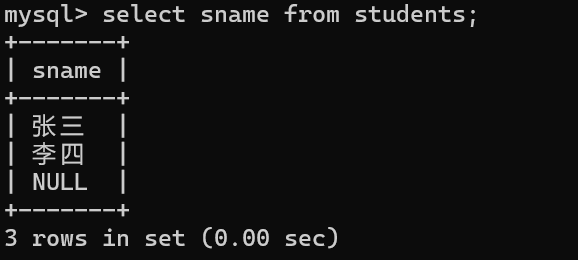
条件查询
select * from 表名 where 条件;
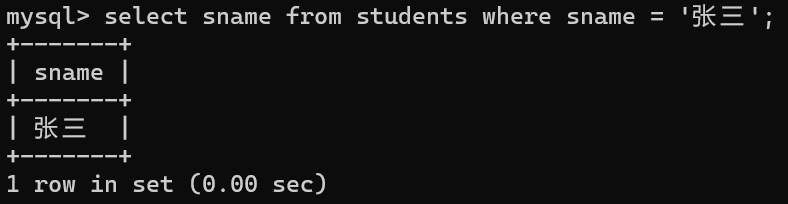
查询字段为表达式
select 列名1,列名2,列1 运算符 列2 from 表名 where;
select 列1 运算符 列2 from 表名 where;
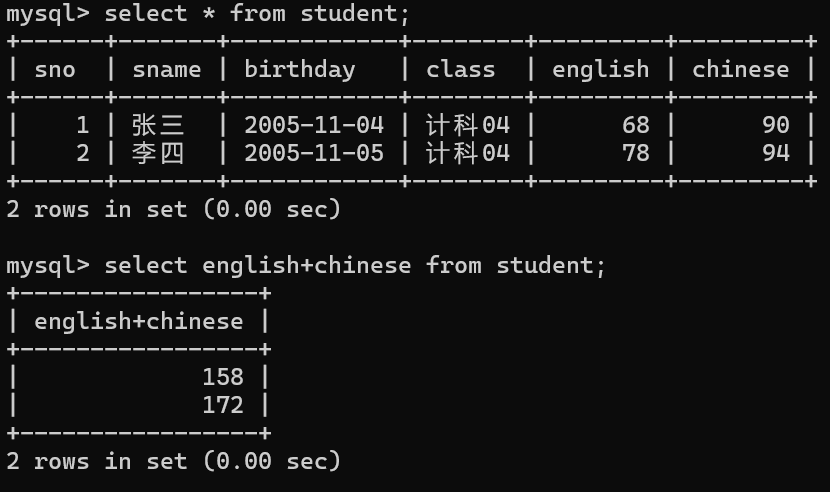
排序
select * from 表名 where 条件 order by 列名1,列名2,......;
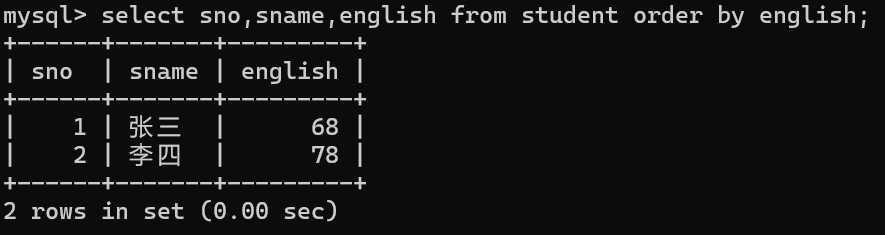
默认升序排列
去重查询
select distinct 列名.. where 条件 order by 列名1,列名2,......;
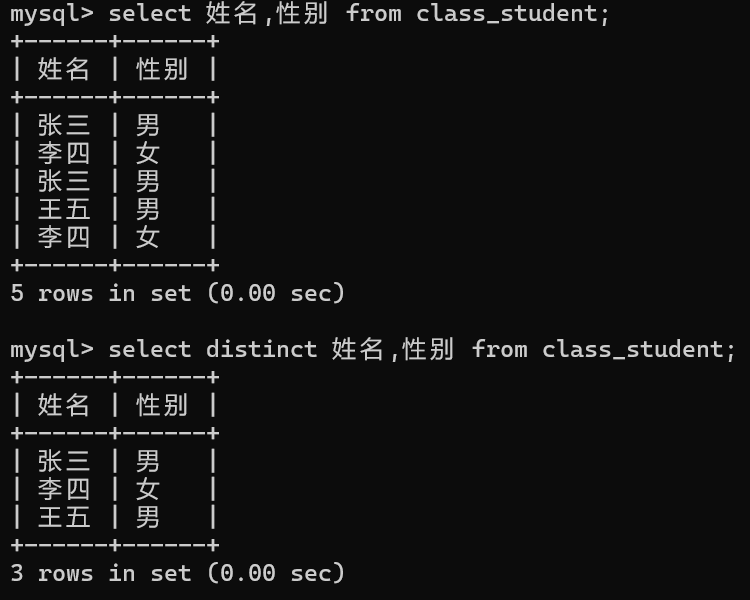
分页查询
select 列名,.... from 表名 where 条件 order by 列名1,列名2,...... limit num;
//从0开始 查num条
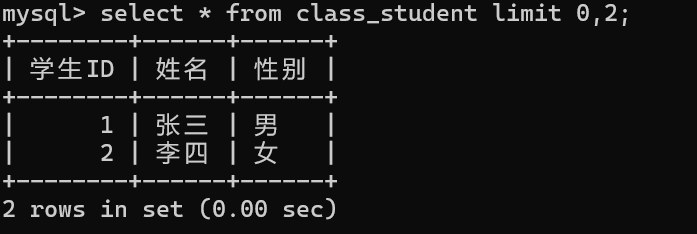
select 列名,.... from 表名 where 条件 order by 列名1,列名2,...... limit start,num;
//从start开始 查num条
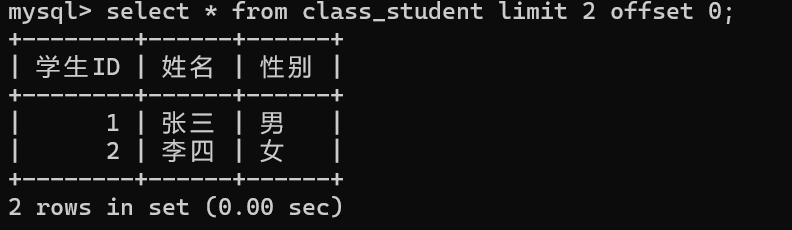
select 列名,.... from 表名 where 条件 order by 列名1,列名2,...... limit num offset start;
//从start开始 查num条
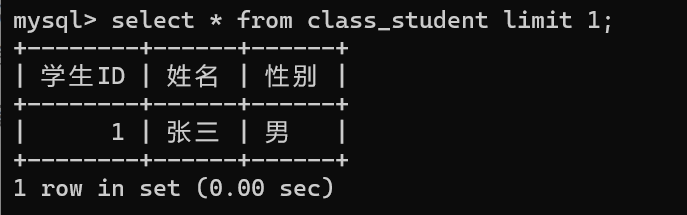
分组查询
select 列1,聚合函数(列2) from 表名 where 条件 group by 列1 having 分组后的条件;

因为 select 后出现了聚合函数和普通列,数据库需要明确"按哪些列分组",才能保证这些普通列在每个分组内的取值是"有意义且一致"的,进而让聚合函数能基于正确的分组去计算,所以select后非聚合函数的普通列必须出现在group by 后。
聚合函数
|---------|---------------|
| count() | 计数(返回查询结果的数量) |
| sum() | 加和(返回查询结果的总和) |
| avg() | 求平均值 |
| max() | 求最大值 |
| min() | 求最小值 |
模糊查询
通配符的使用 % _
% 匹配任意长度的任意字符 1% 以1开头的任意字符 10 ,111111等等都可以
_ 匹配单个任意字符 1_ 以1开头的两位字符 10,11,12,1w .....都可以
注意 \[\] 这个MySql 不支持 在sql server 中 \[\] 表示\[\]内有或关系 like at% 表示以a开头或以t开头
select 列名 from 表名 where 列名 like '匹配模式';
select * from 表名 where 条件 group by 列名,列名,.... order by 列名1,列名2,......
查张开头的学生信息
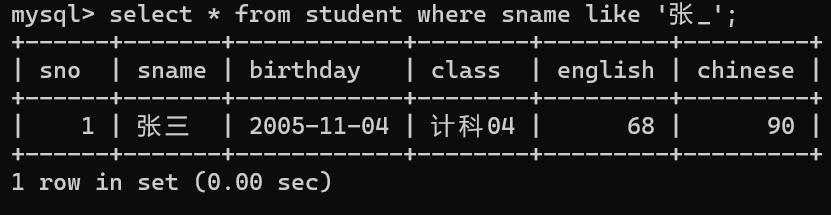
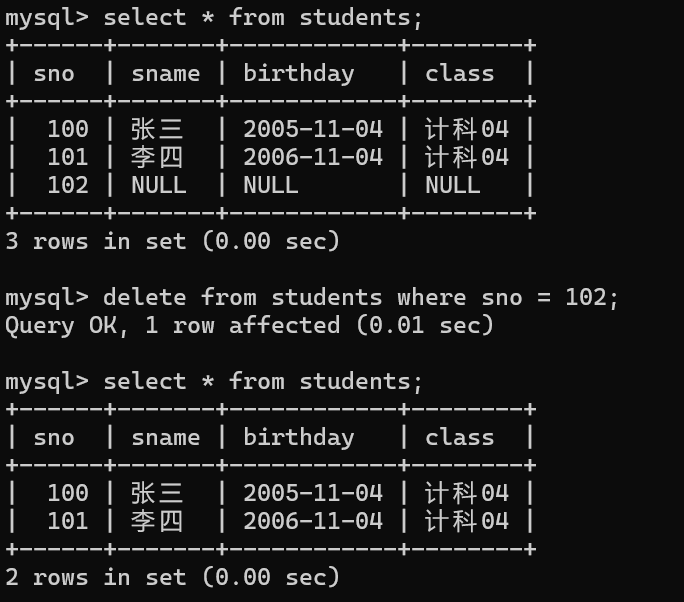
删除数据
delete from 表名 where 条件; 实际中所有删除语句谨慎使用
数据库约束
not null 非空约束 not null 的列不能出现NULL值
primary key 主键约束 唯一且不为空 可有1个或多个列
foreign key 外键约束 有关联关系的表中指定
unique 唯一约束 每行数据有唯一值 就像身份证
defalut 默认约束 没指定时的默认值
check 约束 有些列有指定值的范围比如性别(男/女)限制不能出现其他
联合查询
内连接
select 列1,列2,.... from 表1 inner join 表2 on 连接条件 where ;
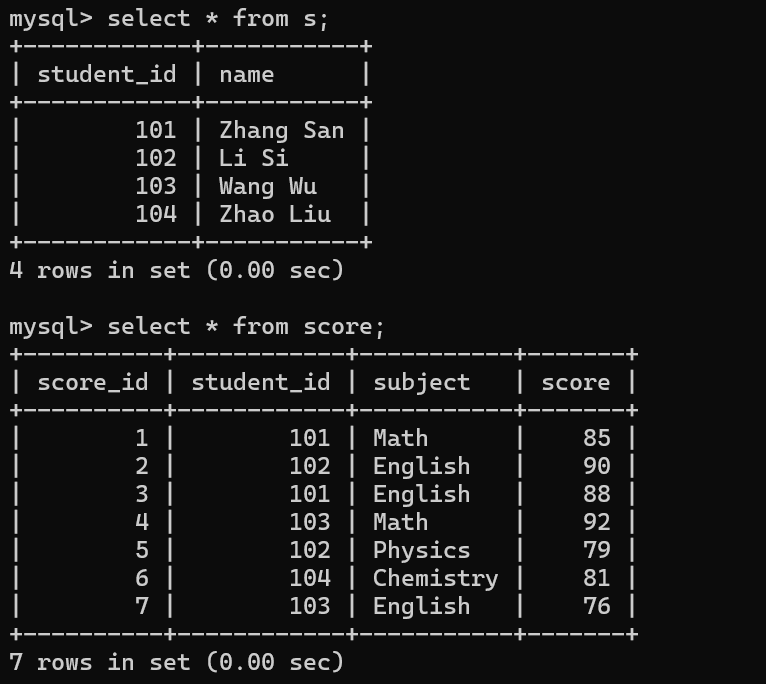
内连接查询 "学生姓名 + 对应科目成绩"
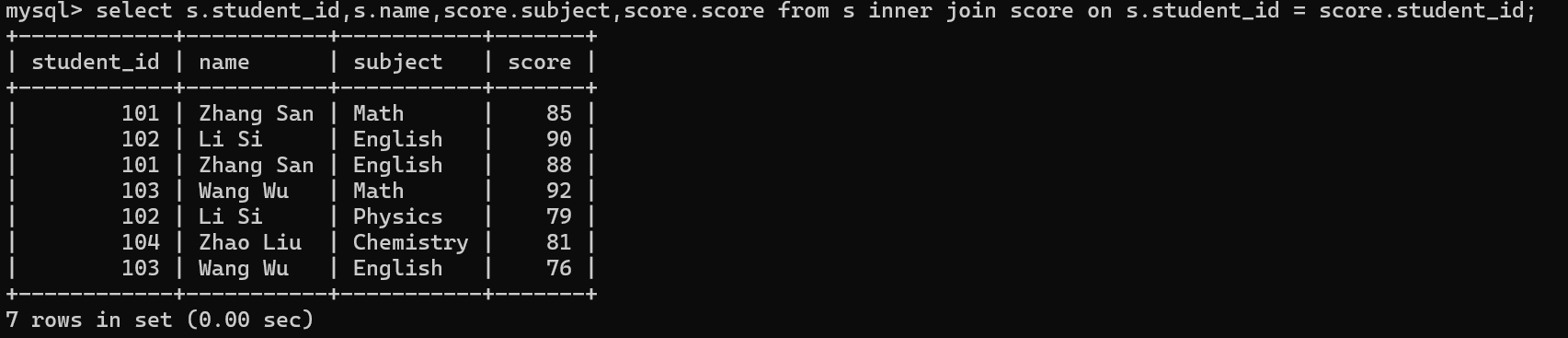
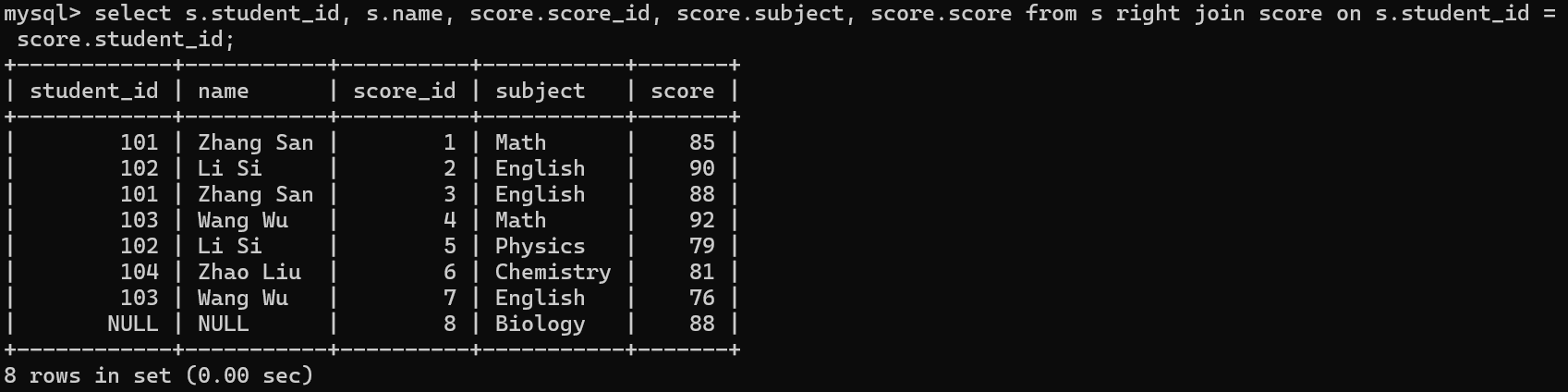
外连接
select 列1,列2,.... from 表1 left join 表2 on 连接条件 where ; 左外连接
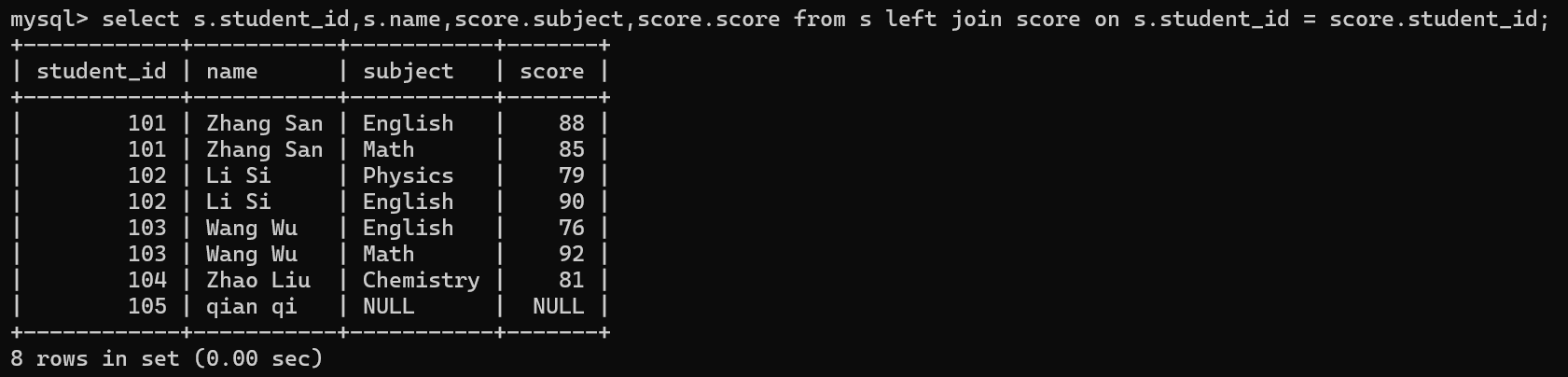
select 列1,列2,.... from 表1 right join 表2 on 连接条件 where ; 右外连接
自连接
select * from 表1,表1;
select * from 表1 as t1, 表1 as t2; 指定别名
找出 "既参加了数学考试,又参加了英语考试的学生"

自然连接
select * from 表1 natural join 表2 on 连接条件;
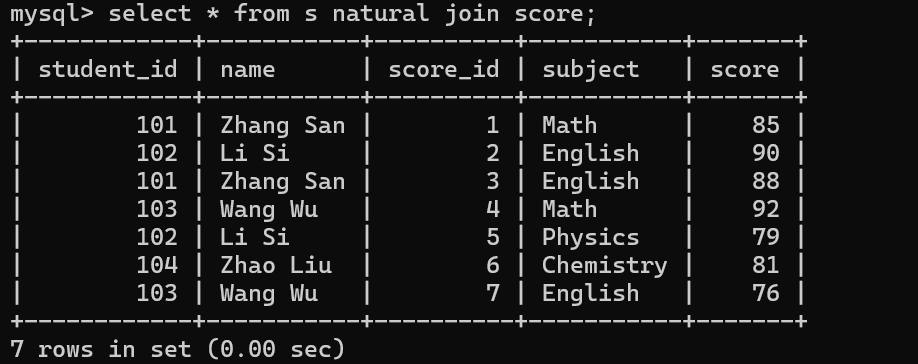
union合并查询
select * from 表1 where union select * from 表2 where 将两次查询的结果并在一起自动去重
合并 "数学成绩≥90 分" 和 "英语成绩≥90 分" 的学生 ID
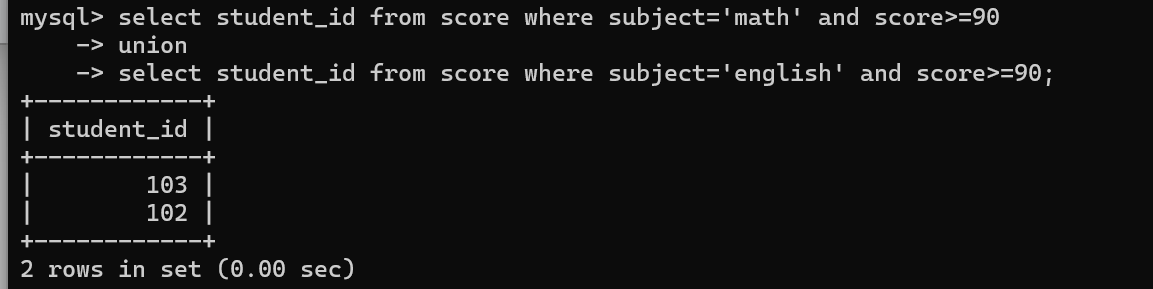
select * from 表1 where union all select * from 表2 where 将两次查询的结果并在一起不去重
查看所有数学和英语成绩
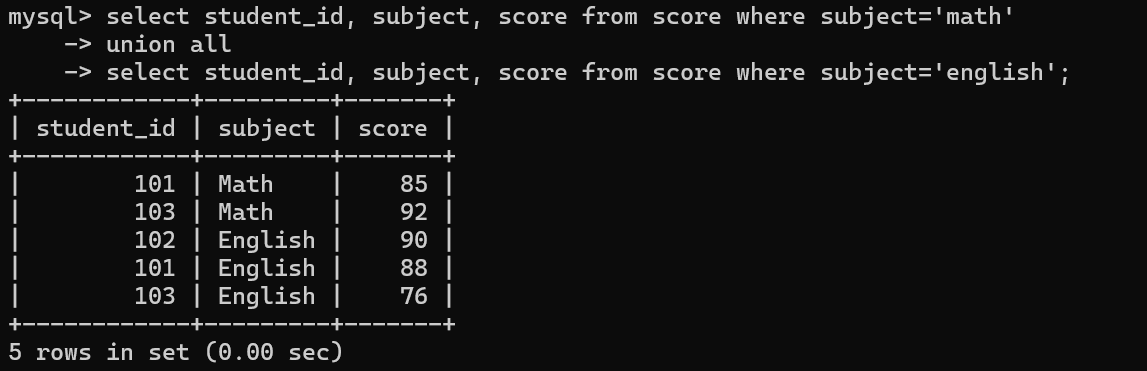
子查询
单行子查询
查询与 "Zhang San(101 号)数学成绩相同的记录
select * from 表1 where 列1 =/>/.... (select * from 表 where 条件);

多行子查询
查询 "所有参加了英语考试的学生信息"
select * from 表1 where 列1 in(select * from 表 where 条件);

from中的子查询
查询 "平均分高于 85 分的学生姓名及平均分"
select * from 表1 ,(select * from 表 where) where 连接条件 and 限制条件;

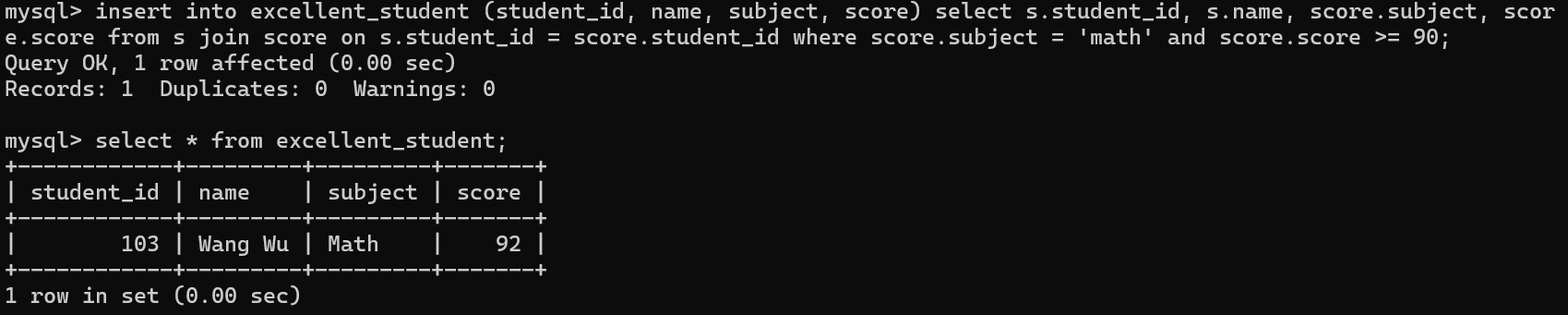
插入查询结果
insert into 表名 列1,列2,.... select 列1,列2,.... from 表名 where;
数据库设计三大范式
第一范式
定义:表的每一列都是不可分割的原子数据项 关系型数据库必须满足第一范式
|-----|----|----|----|
| 学号 | 姓名 | 性别 | 班级 |
| 001 | 张三 | 男 | 1班 |
| 002 | 李四 | 女 | 1班 |
如同上表学号,姓名,性别,班级都是原子的,符合第一范式
反例
|-----|----|----|----|----|
| 学号 | 姓名 | 性别 | 班级 | 学校 |
| 101 | 张三 | 男 | 1班 | 复旦 |
| 102 | 李四 | 女 | 1班 | 交大 |
学校还可以继续拆分,拆成学校地址,学校名等等,不符合第一范式
| 学生 ID | 学生姓名 | 选课科目 |
|---|---|---|
| 101 | 张三 | 数学,英语,物理 |
| 102 | 李四 | 语文,历史 |
选课科目可以拆,要其满足第一范式可以这样
| 学生 ID | 学生姓名 | 选课科目 |
|---|---|---|
| 101 | 张三 | 数学 |
| 101 | 张三 | 英语 |
| 101 | 张三 | 物理 |
| 102 | 李四 | 语文 |
| 102 | 李四 | 历史 |
第二范式
定义:满足第一范式且不存在非关键字段对任意候选键(主键的候选人,满足唯一标识一列可以有多个)部分函数依赖。
| 学生 ID | 学生姓名 | 成绩 | 选课 |
|---|---|---|---|
| 101 | 张三 | 90 | 物理 |
| 102 | 李四 | 59 | 语文 |
这里成绩依赖于选课且选课是候选键(暂定一个学生只能选一门课)所以存在部分函数依赖
修改成符合第二范式的:
课程表
| 课程 ID(主键) | 课程名称 |
|---|---|
| 001 | 物理 |
| 002 | 语文 |
学生表
| 学生 ID(主键) | 学生姓名 |
|---|---|
| 101 | 张三 |
| 102 | 李四 |
成绩表
| 学生 ID(主键) | 课程 ID(主键) | 成绩 |
|---|---|---|
| 101 | 001 | 90 |
| 101 | 002 | 59 |
第三范式
定义:满足第二范式且不存在非关键字段对任意候选键的传递依赖
| 学生 ID | 学生姓名 | 年龄 | 性别 | 授课老师 | 老师电话 |
|---|---|---|---|---|---|
| 101 | 张三 | 19 | 男 | 王伟 | 12352346474 |
| 102 | 李四 | 20 | 男 | 赵六 | 31647186427 |
学生id 为主键 学生姓名,年龄,性别都与学生id相关,但老师电话和授课老师相关
| 学生 ID | 学生姓名 | 年龄 | 性别 | 授课老师 |
|---|---|---|---|---|
| 101 | 张三 | 19 | 男 | 1 |
| 102 | 李四 | 20 | 男 | 2 |
| ID | 授课老师 | 老师电话 |
|---|---|---|
| 1 | 王伟 | 12352346474 |
| 2 | 赵六 | 31647186427 |
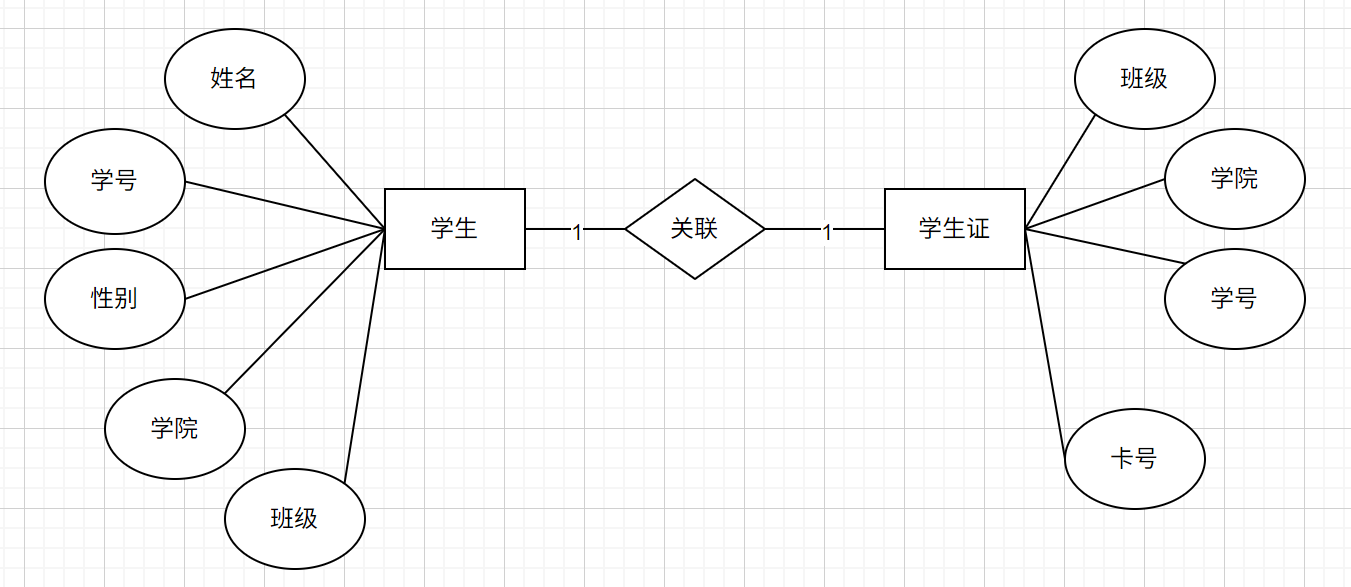
E-R图
实体: 一个对象 用矩形表示
属性:对象的属性 用圆角矩形/椭圆形表示
关系: 两个对象的关系 用菱形表示
一对一关系
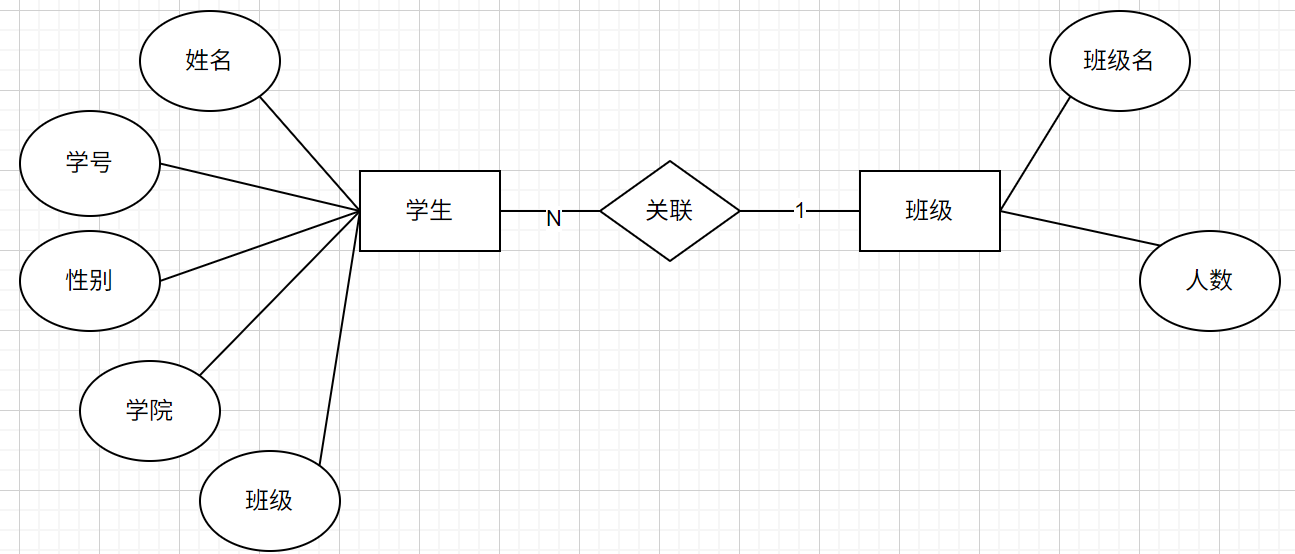
一对多关系
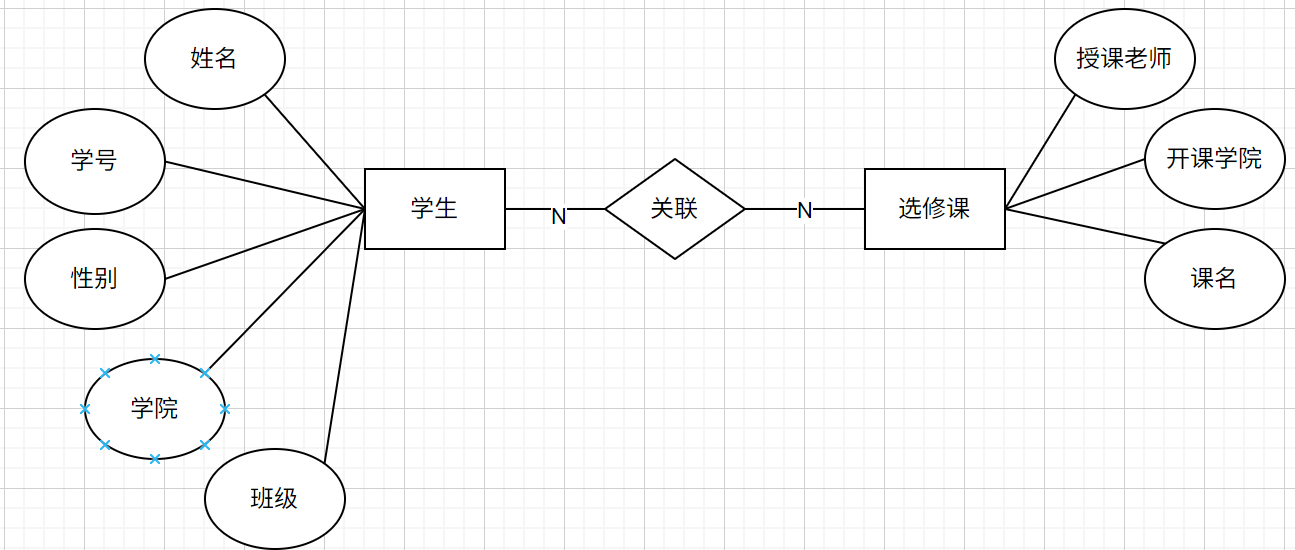
多对多关系
下篇将进入视图,索引
请你给我一个拥抱 为我祝福和祈祷 我们心中都已明了 明天依然要来到 也许该把门打开 风才能进来 放我们的心自由 是到了那时候 So I say goodbye
-------再见以前先说再见 DT
👍💕⭐