)
01.慢查询
慢查询日志就是Redis的"行车记录仪"。建议线上环境至少保留100条记录,阈值按业务调整。它的原理很简单:系统会记录每条命令的执行时间,一旦超过设定的阈值,就把这条命令的相关信息(eg:发生时间、耗时、具体操作内容)记下来。Redis 也支持类似的功能,方便排查那些"拖后腿"的慢操作。
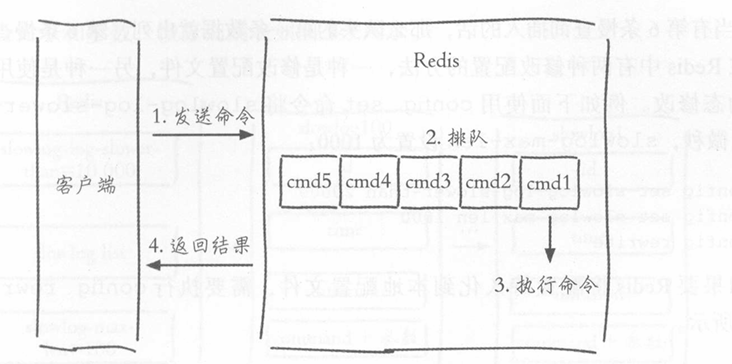
- 发送命令
- 命令排队
- 命令执行
- 返回结果
Redis的慢查询只统计命令在Redis内部执行的时间(就是步骤3),不包含网络传输和排队等待的时间。所以即使慢查询日志干干净净,客户端照样可能超时。
为了解决预设阀值怎么设置以及慢查询记录存放在哪的问题,可以使用一下配置进行解决。-
slowlog-log-slower-than- 设定"慢"的门槛,单位是微秒(1秒=100万微秒)
- 默认10000微秒(10毫秒)------超过这个时间的命令才会被记录
- 设成0:记录所有命令(慎用!)
- 设成负数:直接关闭慢查询功能
-
slowlog-max-len- 控制慢查询日志最多存多少条(本质是个内存列表)
- 新记录进来时,老记录自动弹出(先进先出)
- 比如设成100,第101条进来时,最早那条就被踢掉
02.Redis pipeline
已知传统模式是请求---效应,任意两个请求之间没有关联。Pipeline 是 Redis 的批处理技术,一次发送多个命令,Redis 按序执行并按序返回响应。减少网络往返时间(RTT),提升批量操作吞吐量。
Redis 客户端执行一条命令的四个阶段(发送 → 排队 → 执行 → 返回)
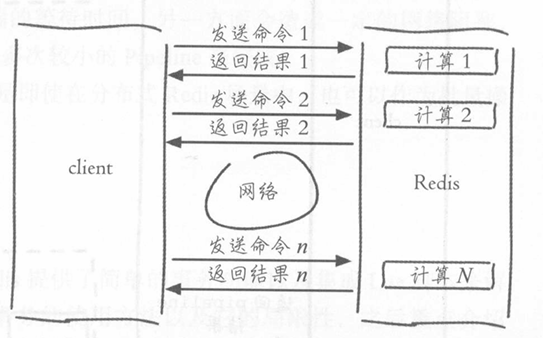
Pipeline纯客户端行为,Redis 服务端无感知。类似 HTTP/1.1 的"请求管道化"(Pipelining),解决"请求-响应串行阻塞"问题。不保证原子性和事务语义,仅用于性能优化。

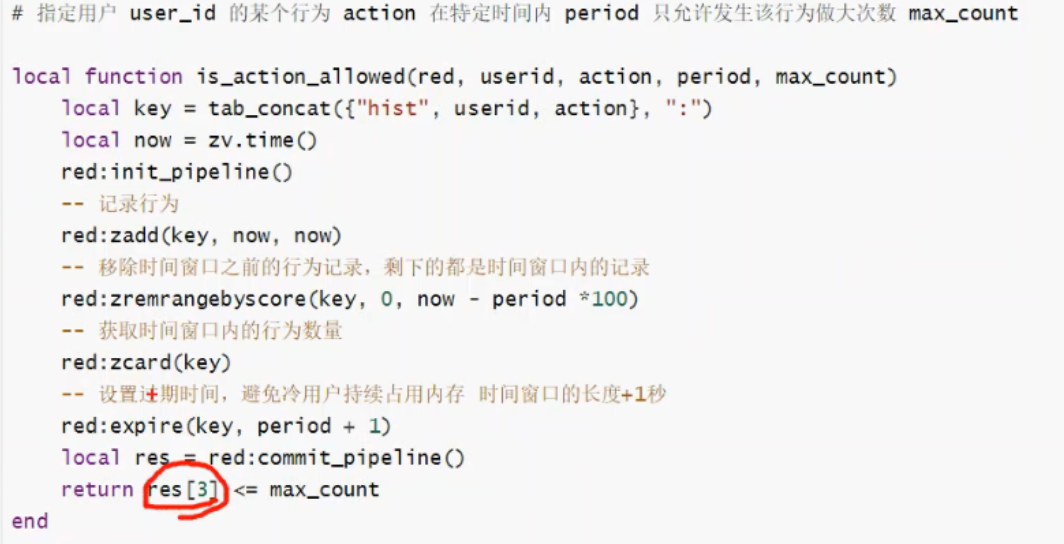
03.事务与Lua
3.1事务
Redis事务是用户定义一系列数据库操作,这些操作视为一个完整的逻辑处理工作单元,要么全部执行,要么全部不执行,是不可分割的工作单元。
Redis 命令遵循 请求-响应 模型------每个命令需等待服务器确认后才能发下一个。而事务通过 MULTI/EXEC 将多次网络往返压缩为两次交互 (入队 + 执行),大幅提升效率。 事务存在并发连接 时,需保证一组操作的逻辑完整性。eg:对 counter 执行 "读取 → 计算翻倍 → 写回",避免中间被其他客户端干扰。
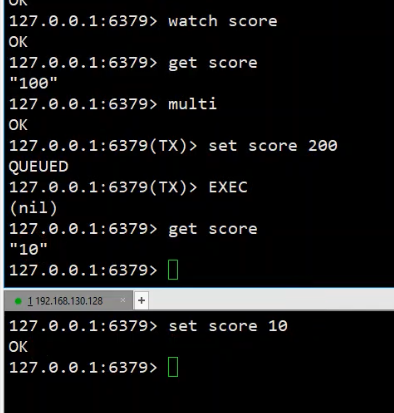
在下面的例子中,开启事务执行后未提交事务,后被另外一个连接对数据进行了修改,造成事务内部的数据key变动,事务被取消。
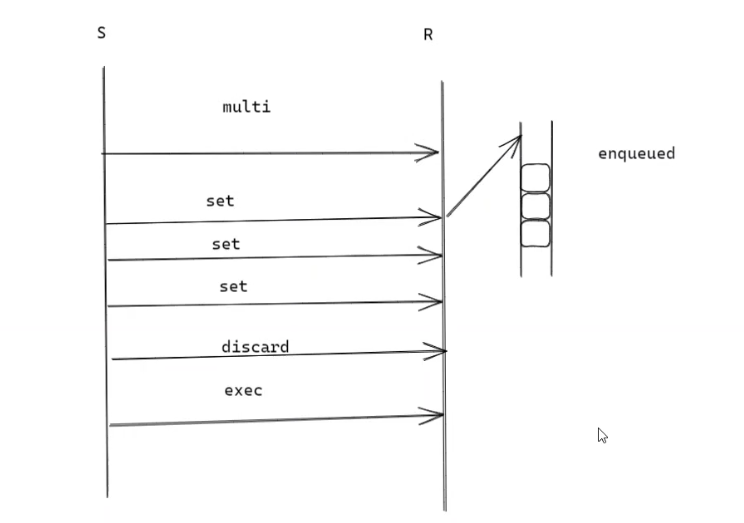
Redis 事务通过 队列 + 原子执行 实现:
- MULTI 开启事务 :后续命令(如多个 SET)不会立即执行,而是入队缓存;
- EXEC 触发执行:一次性原子化执行队列中所有命令(单线程特性保证执行过程不被其他请求打断);
- DISCARD取消事务:清空已入队的命令,不执行任何操作。
WATCH机制:
- 通过 WATCH 监控 key ,若事务入队后、EXEC 前该 key 被其他客户端修改,则 EXEC 会自动丢弃整个队列,避免脏写。
下面每一条指令都是请求-响应的双向连接。一来一回的。
3.1ACID
原子性
- 事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败;redis不支持回滚;即使事务队列中的某个命令在执行期间出现了错误,整个事务也会继续执行下去,直到将事务队列中的所有命令都执行完毕为止。
一致性
- 事务的前后,所有的数据都保持一个一致的状态,不能违反数据的一致性检测;这里的一致性是指预期的一致性而不是异常后的一致性;所以redis 也不满足;这个争议很大:redis 能确保事务执行前后的数据的完整约束;但是并不满足业务功能上的一致性;比如转账功能,一个扣钱一个加钱;可能出现扣钱执行错误,加钱执行正确,那么最终还是会加钱成功;系统凭空多了钱;
- 完整约束的一致
- 用户逻辑的一致
- 是指我操作之间不能被其他操作影响

隔离性
- 各个事务之间互相影响的程度;redis是单线程执行,天然具备隔离性;
持久性
- redis 只有在laof持久化策略的时候,并且需要在redis.conf 中appendfsync=always才具备持久性;实际项目中几乎不会使用aof持久化策略;
3.2Lua脚本
Redis 内置 Lua 虚拟机,脚本执行具有原子性:一旦开始运行,整个脚本会独占 Redis 单线程,期间不会插入任何其他命令或脚本,所有操作连续完成。MySQL 不具备事务原子性。lua脚本满足原子性和隔离性;一致性和持久性不满足;
- 脚本中的命令直接修改数据状态 ,无需额外事务(使用 Lua 后,无需
MULTI/EXEC等事务命令) - 通过
EVAL或EVALSHA触发执行,避免网络往返开销
bash
# 从文件加载脚本(生成 SHA1 校验码)
cat test.lua | redis-cli --eval /dev/stdin
# 手动加载脚本字符串
> SCRIPT LOAD 'return KEYS[1]'
"b8059ba43af6ffe8bed3db65bac35d452f8115d8"
# 检查脚本是否已缓存
> SCRIPT EXISTS "b8059ba43af6ffe8bed3db65bac35d452f8115d8"
1) (integer) 1 # 1=存在,0=不存在
# 清理所有缓存脚本(重启 Redis 也会自动清空)
> SCRIPT FLUSH
OK
# 终止卡死的脚本(如死循环)
> SCRIPT KILL
(error) NOBUSY # 无运行中脚本时返回此提示 通过第一次发送的脚本生成的hash值,这个值就是未来执行lua脚本,通过hash值找到脚本索引找到脚本进行执行。
shell
# 1. 开发测试:直接执行脚本
> EVAL "return {KEYS[1], ARGV[1]}" 1 user:1001 "profile"
# 2. 生产环境:先加载脚本获取 SHA1
> SCRIPT LOAD "return redis.call('GET', KEYS[1])"
"767e31a4d5a0f9a3d3d3d3d3d3d3d3d3d3d3d3d3"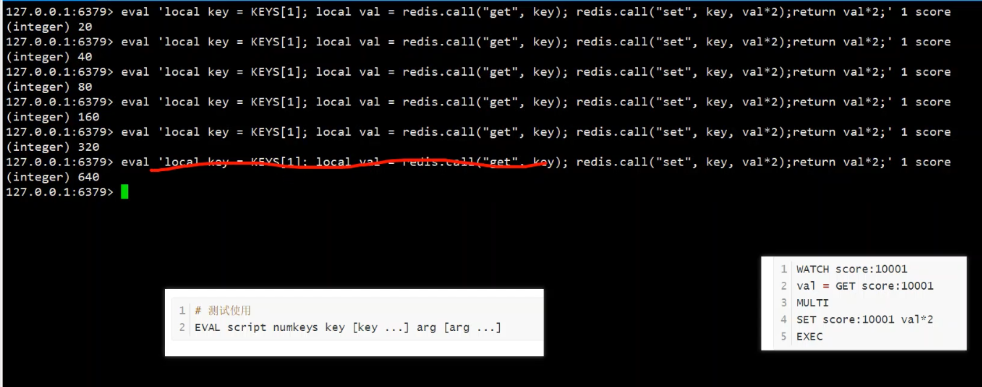
04.发布订阅
Redis提供了基于"发布/订阅"模式的消息机制,此种模式下,消息发布者(可以是web服务器也可以是普通服务器?)和订阅者不进行直接通信,发布者客户端向指定的频道(channel)发布消息,订阅该频道的每个客户端都可以收到该消息。
shell
#订阅频道
subscribe频道
#订阅模式频道
psubscrihe 频道人
#取消订阅频道
unsubscribe 频道
#取消订阅模式频道
punsubscribe 频道
#发布具体频道或模式频道的内容
publish频道 内容
#客户端收到具体频道内容
message 具体频道 内容
#客户端收到模式频道内容
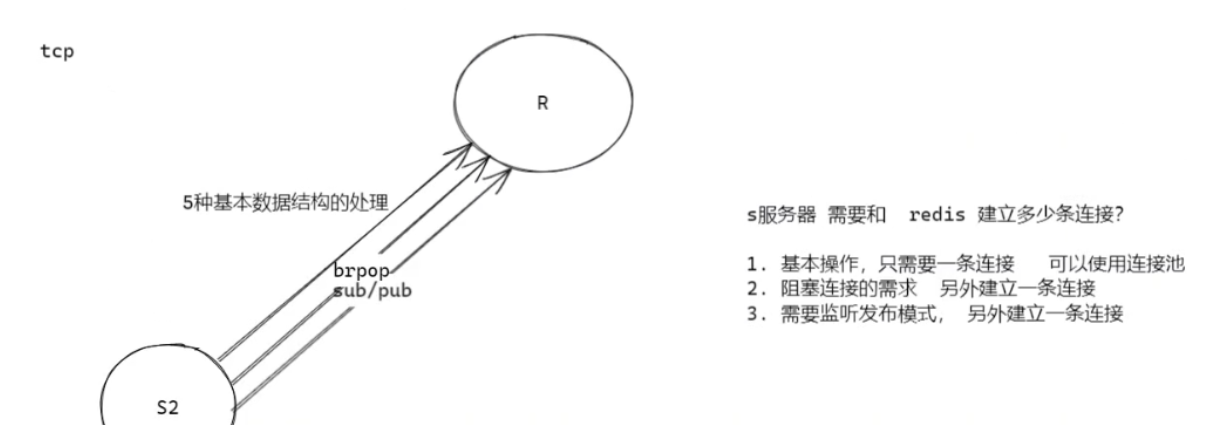
pmessage模式频道具体频道内容 发布订阅模式基于 TCP 长连接实现,应用此功能一般要区别命令连接重新开启一个连接;因为命令连接严格遵循请求回应模式;而pub/sub能收到redis主动推送的内容;所以实际项目中如果支持pub/sub的话,需要另开一条连接用于处理发布订阅。
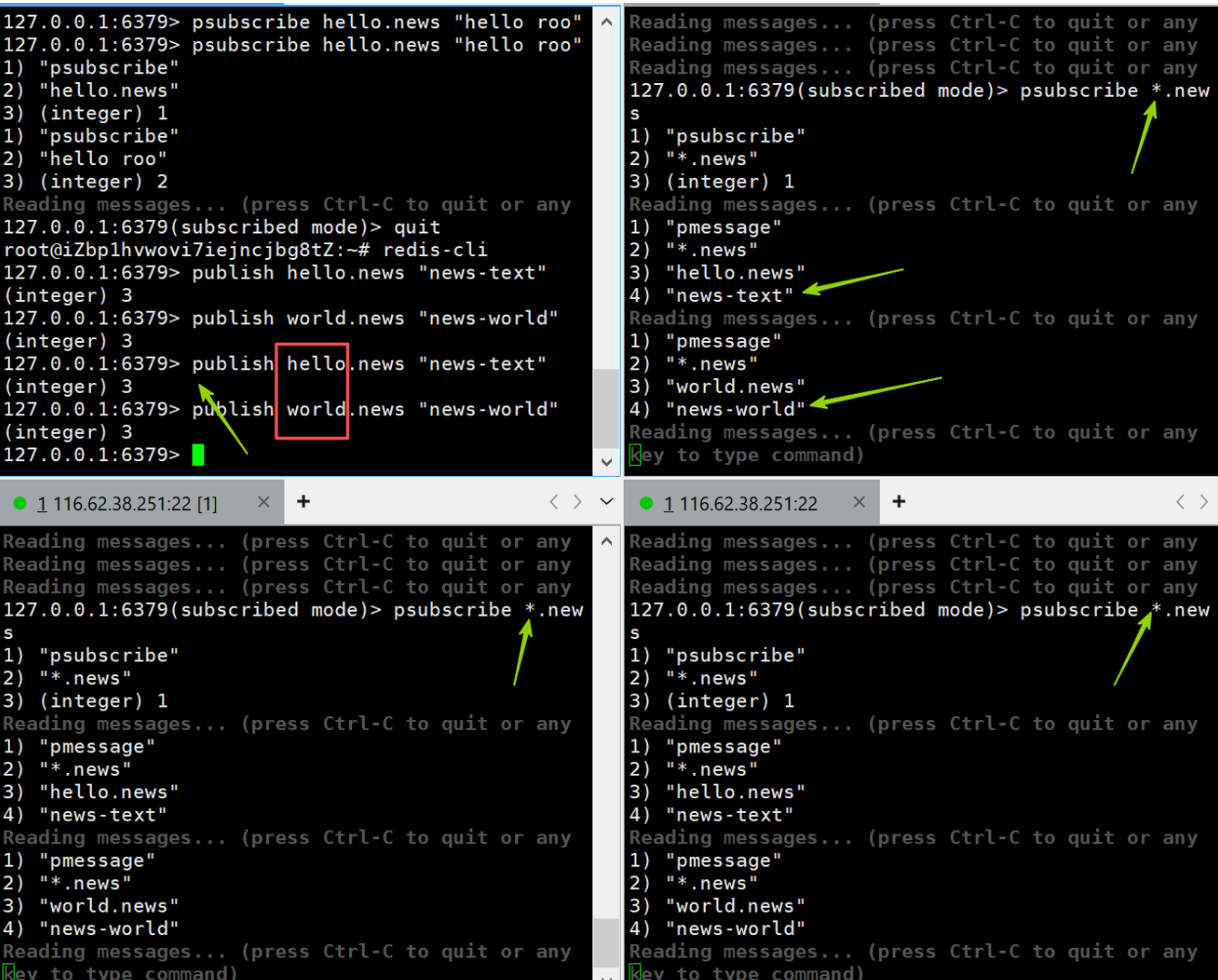
发布订阅的生产者传递过来一个消息,redis会直接找到相应的消费者并传递过去;假如没有消费者,消息直接丢弃;假如开始有2个消费者,一个消费者突然挂掉了,另外一个消费者依然能收到消息,但是如果刚挂掉的消费者重新连上后,在断开连接期间的消息对于该消费者来说彻底丢失了;
另外,redlis停机重启,pub/sub的消息是不会持久化的,所有的消息被直接丢弃;
适用场景:适用于容忍消息丢失的实时广播场景:
-
实时通知(如在线状态变更)
-
日志收集(非关键日志)
-
配置热更新广播
-
不适用于 需要可靠投递、消息追溯或强一致性的业务(如订单、支付、审计日志),此类场景应考虑 Redis Stream 或专业消息队列(如 Kafka、RabbitMQ)。
05.Reactor异步连接拆解
1. 与Redis建立连接
socket(fd,&addr,&len) 非阻塞I/O
1.创建socket,设置文件描述符为非阻塞模式
2.调用connect,当返回-1且errno为EINPROGRESS时表示连接正在进行中
3.将文件描述符注册到epoll的写事件
4.当连接建立成功后,epoll会触发写事件,此时注销写事件
2. 向Redis发送数据
使用Redis协议对命令进行编码
-
通过TCP发送数据
-
调用int n = write(fd, buf, sz),若返回n < sz&&n != -1; n = -1且errno = EWOULDBLOCK,说明fd对应的发送缓冲区已满
-
此时注册写事件,当写事件触发时调用write(fd, buf, sz),继续发送剩余数据
-
数据全部发送完毕后,注销写事件并注册读事件
-
3. 读取Redis的返回
- 通过tcp接收数据分割数据包
- 使用redis协议解密
- 当读事件触发时,int n = read(fd , buf , sz ),通过TCP接收数据
- 根据Redis协议格式分割 数据包
- 对协议数据进行解码,获取最终响应结果
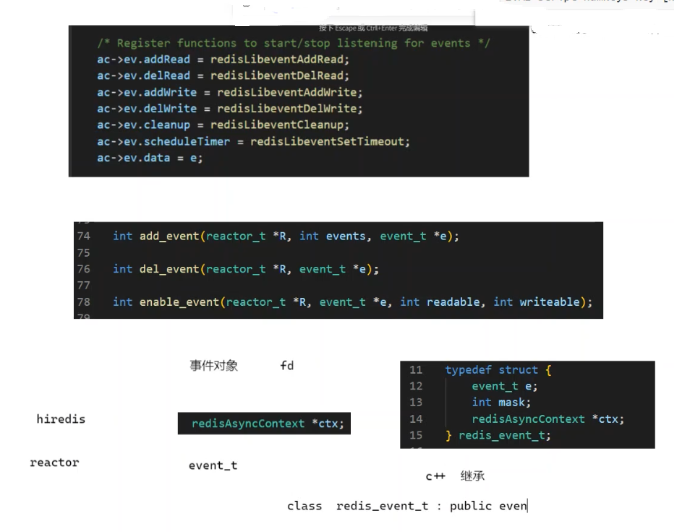
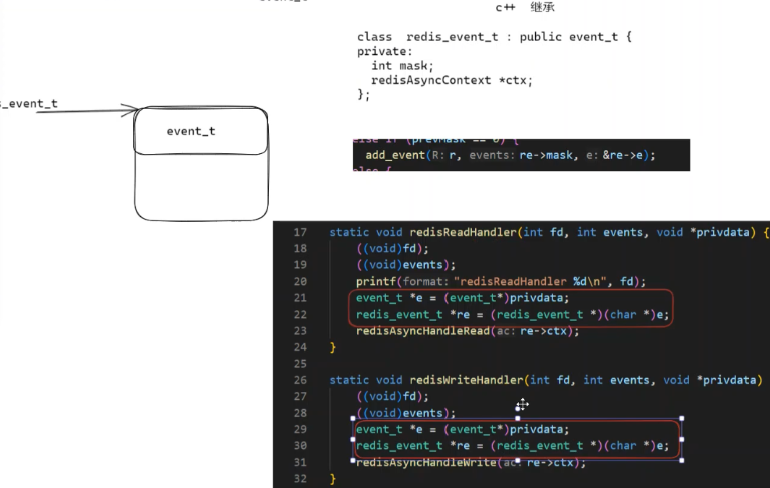
c语言通过typedef,C++通过继承获取evenr_t和ctx两个对象