目录
[SIM 模型](#SIM 模型)
[(1)General Search Unit(GSU)](#(1)General Search Unit(GSU))
[(2)Exact Search Unit(ESU)](#(2)Exact Search Unit(ESU))
SIM 模型很好地解决了 DIN 模型的缺点,主要目的就是保留用户的长期兴趣。
论文:Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction
链接:https://arxiv.org/abs/2006.0563
背景
其他模型的缺点
-
MIMN:当用户行为序列长度超过1000时,由于MIMN将用户的历史行为编码到一个固定长度的memory matrix,因而会带来大量的噪声
-
DIN:只关注短期兴趣、遗忘长期兴趣, 面临无法接受的计算、存储问题,只适用于用户行为序列<150的建模。而在实践中,长序列(长期兴趣)的效果是要优于短序列(短期兴趣)的。
-
不考虑上述模型,直接基于用户行为序列建模,会占用大量的存储、计算资源,带来较大的响应延迟问题,在实际应用中是无法接受的
解决方案
通过两个串行的搜索模块提取用户兴趣,实现在序列规模、效果准确率上的提升
SIM 模型
符号
用户:U
用户的行为序列:B=b1, b2, ..., bT,b表示用户的第n个行为,T是用户的行为序列长度
用户的子行为序列:B'=b1\*, b2\*, ..., bK\*,K是经过GSU获取得到的Top-k相关的子行为序列
模型结构
如下所示,主要包含两个单元:通用搜索单元(GSU)和精确搜索单元(ESU)
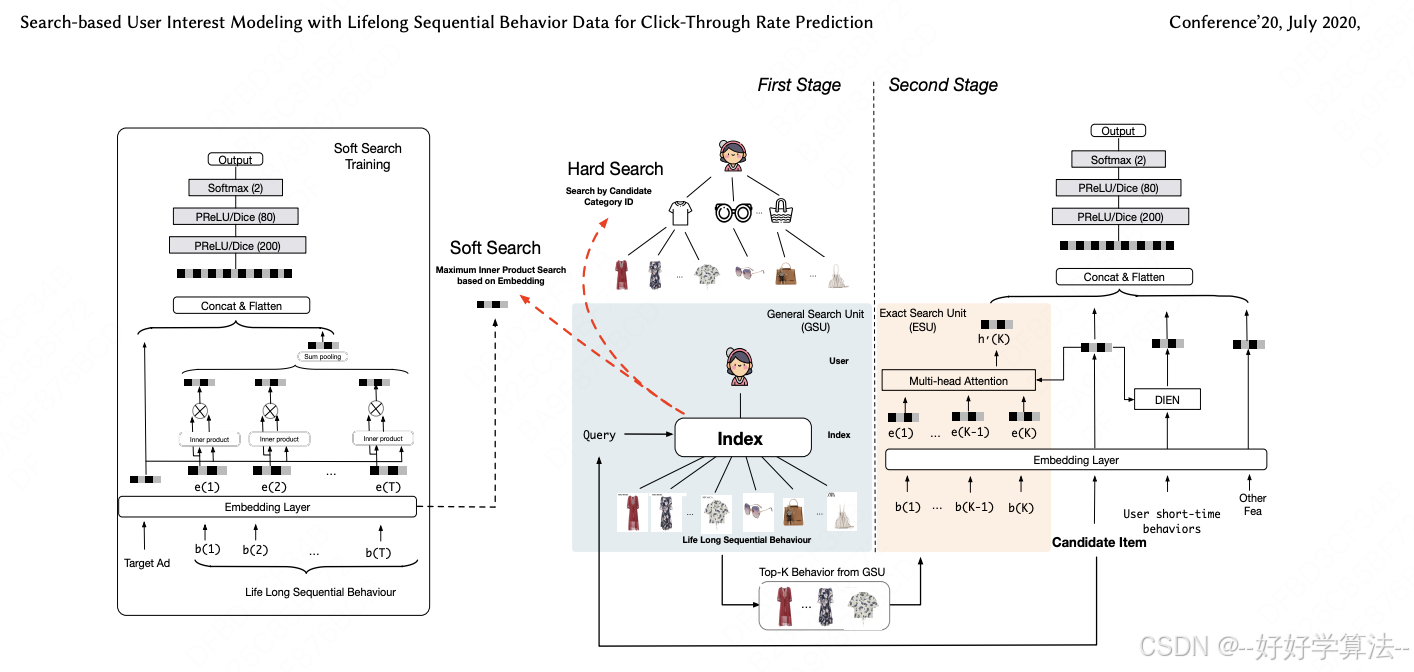
在第一阶段,利用通用搜索单元(GSU)以次线性时间复杂度从原始长期行为序列中寻找top-K相关的子行为序列。这里K通常比行为序列的原始长度短得多。如果能够在有限的时间和计算资源的限制下对相关行为进行搜索,则可以得到一种高效的搜索方法。本文提供了两个简单的GSU实现:软搜索(soft-search)和硬搜索(hard-search)。GSU采用了一种通用而有效的策略来截断原始序列行为的长度,以满足时间和计算资源的严格限制。
同时,第一阶段的搜索策略可以过滤长期用户行为序列中存在的大量噪声,这些噪声可能会影响用户兴趣建模。
在第二阶段,引入精确搜索单元(ESU),以过滤后的子序列用户行为作为输入,进一步捕捉精确的用户兴趣。在这里,可以应用具有复杂体系结构的复杂模型,如DIN和DIEN,因为长期行为的长度已经减少到数百个。
⚠️注意,这两个阶段实际上是一起训练的。
(1)General Search Unit(GSU)
目标:提取超长用户行为中和广告相关的行为数据,从而降低基于长期行为的用户兴趣建模的难度
两种方案:hard-search 和 soft-search
实现方式:
每一个用户行为计算一个相关性分数r_i。然后根据r_i从原始行为中选出Top-K相关行为,生成一个新的子序列B^*。r_i的计算方式如下
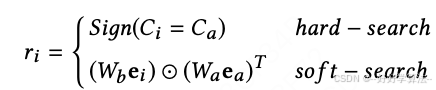
hard-search是无参数的。只有和候选广告类目相同的用户行为数据才会被选出送到下一级进行建模。其他C_a代表了候选广告类目,C_i代表了第i个用户行为的类目。
在soft-search中,将用户行为序列B映射成为embedding表达E=e_1; e_2; ......; e_T。W_b和W_a都是模型参数,其中e_a代表了候选广告的embedding,e_i代表了第i个用户行为embedding。为了加速上万个用户行为的Top-K检索,采用基于内积的近似最近邻检索出Top_K个相关的行为,比如Maximum Inner Product Search (MIPS)。
由于长期兴趣和短期兴趣的数据分布存在差异,所以 soft-search 采用了基于长期行为数据的辅助 CTR 任务来学习soft-search模型中的参数。如上图左面所示,行为表示U_r通过以下方式获得:
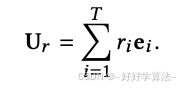
行为表示U_r和目标项向量e_a拼接在一起作为MLP的输入。
(2)Exact Search Unit(ESU)
目标:基于获取到的top-K相关的子行为序列,更精准地捕捉用户兴趣
实现方式:
使用 GSU 筛选 Top-K 与广告相关的用户行为子序列作为输入。由于用户行为序列较长且横跨时间久,行为分布不同,因此为每个行为引入时间状态属性,衡量用户行为时间与当前广告预估时间差。将行为向量与时间状态属性向量拼接为最终用户行为表示,并通过 multi-head attention 结构捕捉多样的用户兴趣。
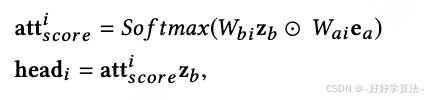
其中,i 表示第i个attention score,W_bi、W_ai是模型学习的权重参数。最终的用户多个长期兴趣表示:
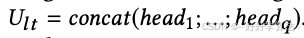
Loss
第一阶段和第二阶段是采用交叉熵 loss 联合学习
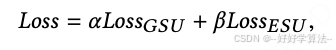
若GSU采用soft-search model,则设置alpha,beta 均为1;否则,设置alpha=0、beta=1
工业实现
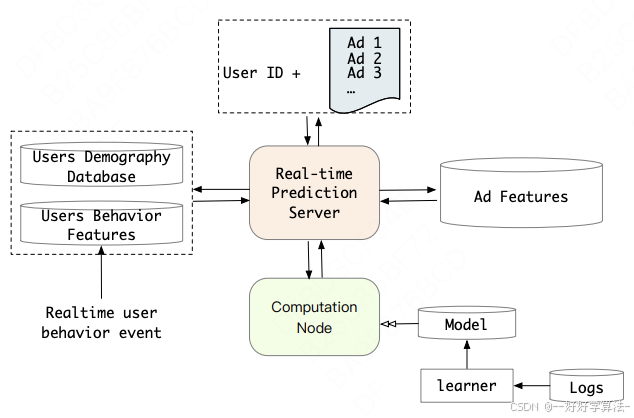
下图简单的描述了在线展现广告系统中的Real Time Prediction(RTP)系统。
在线系统改进
虽然采用soft-search相比hard-search,具有更好的效果,但是从性能、资源消耗的角度考虑,在在线展示广告系统中采用hard-search,如下图所示。
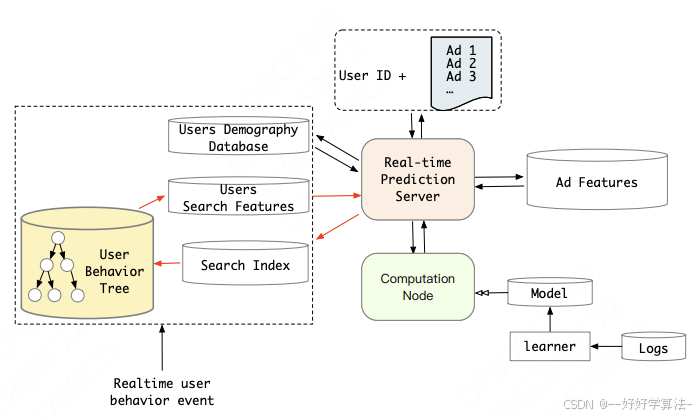
主要改进点
为每个用户建立two-level索引(即user behavior tree, UBT),第一层表示用户id,第二层表示类目id,索引值是行为序列的item