你是否也曾面对成山倒海的服务器监控数据,感到头皮发麻?CPU、内存、磁盘IO、网络流量......这些随着时间不断涌来的数据,就像一场永不停歇的洪水。别慌!今天我给你介绍一位专治"数据洪水"的狠角色------InfluxDB,它能把这些"洪水"收拾得服服帖帖,还能让你优雅地"翻旧账"。
一、InfluxDB 是谁?它为啥能"治水"?
简单说,InfluxDB 是一个专为时序数据打造的高性能数据库。
时序数据是个啥? 想象一下,你给你家猫主子装了个智能称重器,它每天早上去称一下,你就会得到这样一系列数据: (时间: 2023-10-01 08:00, 体重: 5.0kg) (时间: 2023-10-02 08:05, 体重: 5.1kg) (时间: 2023-10-03 08:02, 体重: 4.9kg) ... 看,这就是典型的时序数据:数据点与时间戳强关联,并且源源不断地产生。
InfluxDB 的"杀手级"应用场景:
- 运维监控:服务器CPU在过去的24小时内是怎么"蹦迪"的?内存使用率有没有"爆表"?用它!
- 物联网:你家智能空调每分钟的温度、湿度数据,工厂里传感器传回的压力、转速,用它!
- 金融数据分析:股票价格每秒的波动,交易量的实时变化,用它!
- 应用性能监控:你的API接口响应时间、QPS,用它!
它不像MySQL那种"万能"数据库,它是"专业选手",干时序数据的活儿,效率能高出几个数量级。
二、InfluxDB 的数据模型:像写日记一样记录数据
InfluxDB的数据模型非常直观,咱们用一个监控服务器的例子来理解:
假设我们记录一台Web服务器web-server-01的CPU使用情况。
在InfluxDB里,一条数据长这样:
ini
measurement,host=web-server-01,cpu=cpu0 usage=76.5,idle=23.5 1696123456789000000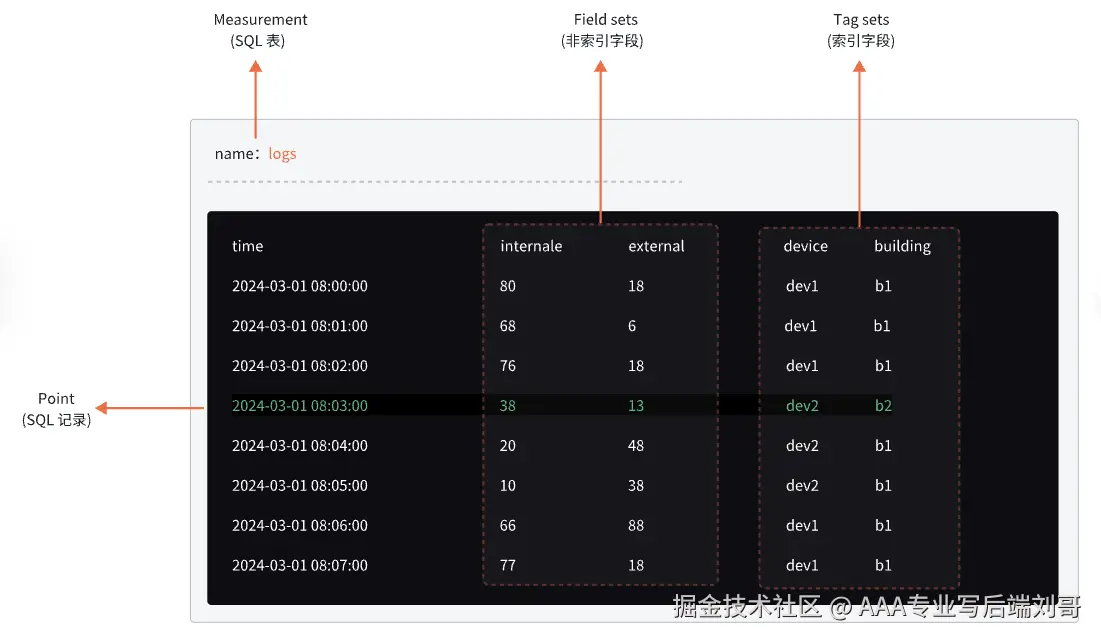 别慌,我们来"拆盲盒":
别慌,我们来"拆盲盒":
- Measurement :
measurement。这就像MySQL里的表名,比如cpu_usage,memory_info。这里我们简化了。 - Tags :
host=web-server-01,cpu=cpu0。标签 ,用来描述数据的元数据,是会被索引的,查询起来飞快。适合存放维度信息,比如主机名、地区、设备ID等。 - Fields :
usage=76.5,idle=23.5。字段 ,是你真正关心的数值数据,比如温度、速度、价格。不会被索引,适合做聚合计算。 - Timestamp :
1696123456789000000。时间戳,每个数据点的"出生证明",InfluxDB的核心。
一个精辟的比喻: 想象你在写日记。
- Measurement 就是日记本的名字,比如《工作日记》。
- Tags 就是你用荧光笔标出的关键词,比如
#项目A,#紧急,方便你快速查找。 - Fields 就是日记的具体内容,比如"今天写了500行代码,解决了3个Bug"。
- Timestamp 就是你写日记的日期。
三、存储架构:时间序列数据为啥这么快?
在 InfluxDB 中可以创建多个数据库,不同数据库中的数据文件是隔离存放的,存放在磁盘上的不同目录,每个database 可以有多个RP(retention policy数据保存策略),但是只有一个默认策略。策略下按照时间段分为多个ShardGroup分片组,每个ShardGroup存储一个时间段的数据。每个shardgroup下分多个shard来存储数据。如下图所示:
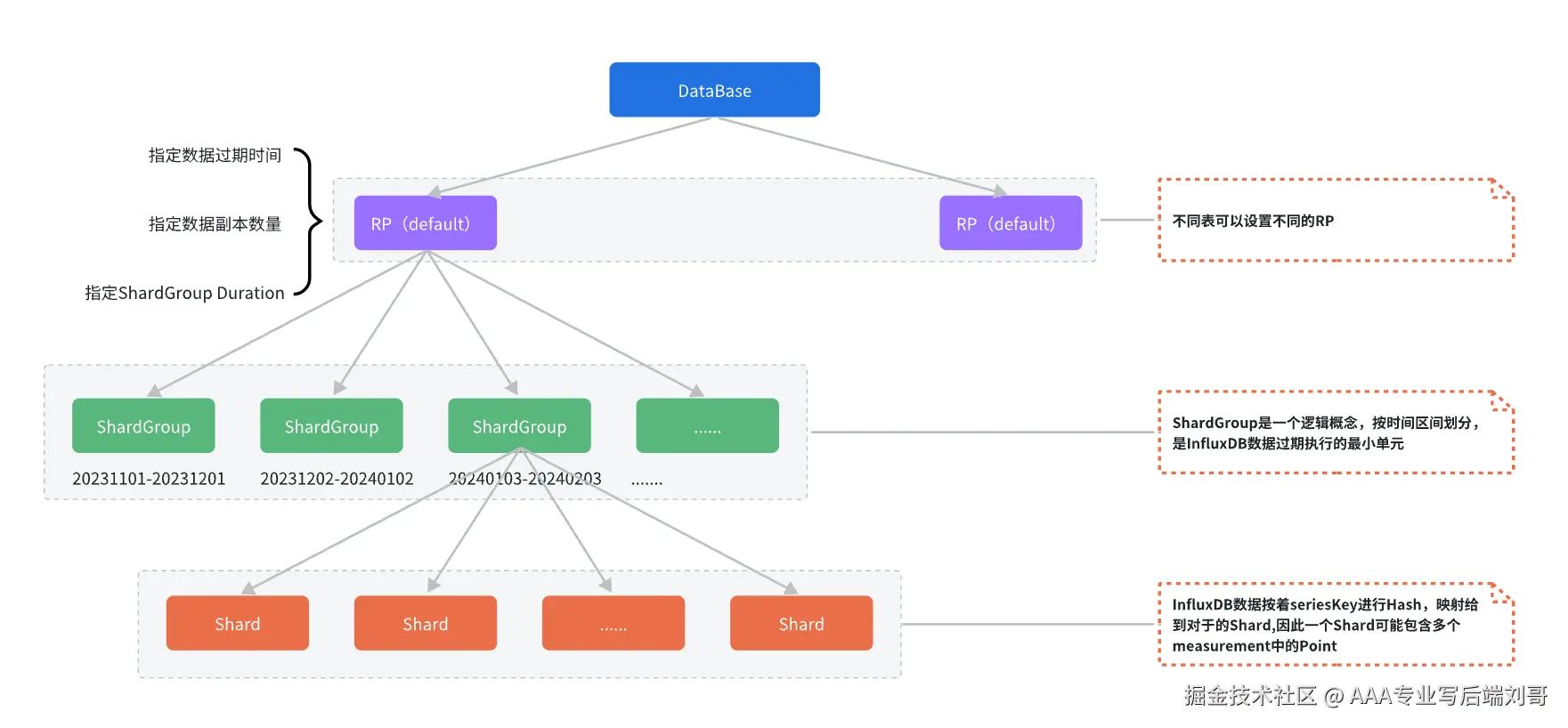
- retention policy:数据保存策略 ,用于设置数据保留时间,每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久,之后用户可以自己设置,例如保留最近2小时的数据。插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。InfluxDB 会定期清除过期的数据。
- ShardGroup: 是一个逻辑概念,按时间区间划分,是InfluxDB数据过期执行的最小单元
- Shard: 在 InfluxDB 中是一个比较重要的概念,它和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。每一个 shard 都对应一个底层的 tsm存储引擎。
简单来说,它把"按时间顺序来的数据"用"最懂时间的方式"存了起来,不快就没天理了。
四、上手玩玩:InfluxDB 基础数据库操作
理论说再多,不如敲行命令。我们进入InfluxDB的CLI界面 (influx) 实操一下。
1. 连上数据库,创建它!
sql
-- 连接数据库(本地默认)
influx
-- 创建一个叫`mydb`的数据库
CREATE DATABASE mydb
-- 使用这个数据库
USE mydb2. 写入数据(增)
用我们前面学到的数据模型,插入一条CPU数据。
sql
INSERT cpu,host=serverA,region=us_west usage=0.64,idle=0.36瞧,InfluxDB的写入语法就是这么直白,像在说人话。
3. 查询数据(查)
是时候看看我们存进去的数据了。
sql
-- 查询最近的所有数据
SELECT * FROM "cpu"
-- 查询特定主机,并且usage大于0.5的数据
SELECT * FROM "cpu" WHERE "host" = 'serverA' AND "usage" > 0.5
-- 按时间聚合,比如查询过去1小时内,每5分钟的CPU平均使用率
SELECT MEAN("usage") FROM "cpu" WHERE time > now() - 1h GROUP BY time(5m)这个 GROUP BY time() 是时序查询的灵魂,简直是为监控图表而生!
4. 更新与删除(改 & 删)
- 注意:在时序数据库中,更新和删除是比较"重"的操作,通常用于数据修正。
- 更新主要是通过插入一个相同时间戳和Series(即measurement+tags确定的一条时间线)的新值来实现覆盖。
- 删除可以使用
DELETE语句,但一般我们更依赖数据自动过期策略。
sql
-- 删除measurement
DROP MEASUREMENT "cpu"
-- 根据条件删除数据点
DELETE FROM "cpu" WHERE time < '2023-01-01'五、优雅封装:在代码里和InfluxDB"打交道"
总不能每次都手敲SQL吧?在我们的Java/Go/Python应用里,我们需要对InfluxDB的操作进行持久层封装。
这里以Python为例,展示一种简单清晰的封装思路:
python
from influxdb import InfluxDBClient
class InfluxDBHelper:
def __init__(self, host='localhost', port=8086, username=None, password=None, database=None):
self.client = InfluxDBClient(host, port, username, password, database)
# 可以在这里确保数据库存在
# self.client.create_database(database)
def write_data(self, measurement, tags, fields, timestamp=None):
"""写入单条数据"""
data_point = {
"measurement": measurement,
"tags": tags,
"fields": fields
}
if timestamp:
data_point["time"] = timestamp
json_body = [data_point]
try:
self.client.write_points(json_body)
print(f"数据写入成功: {data_point}")
except Exception as e:
print(f"数据写入失败: {e}")
def query_data(self, query_sql):
"""执行查询"""
try:
result = self.client.query(query_sql)
return result.raw
except Exception as e:
print(f"查询执行失败: {e}")
return None
def close(self):
"""关闭连接"""
self.client.close()
# 使用示例
if __name__ == '__main__':
db_helper = InfluxDBHelper(database='mydb')
# 写入一条模拟的服务器指标
db_helper.write_data(
measurement='server_metrics',
tags={'host': 'my-pc', 'service': 'web-api'},
fields={'cpu_usage': 45.2, 'memory_used': 1024},
# timestamp 不传则默认使用当前时间
)
# 查询数据
data = db_helper.query_data('SELECT * FROM "server_metrics" LIMIT 5')
print(data)
db_helper.close()封装的核心思想:
- 连接管理:初始化时建立连接,使用时保持单例,避免频繁创建销毁。
- 简化API :将复杂的JSON数据点构建和写入操作封装成
write_data这样的简单方法。 - 异常处理:对网络波动、写入失败等情况进行妥善处理,保证程序健壮性。
- 资源释放 :提供
close方法,确保连接被正确关闭。
在实际项目中,你还可以结合配置文件、连接池等技术,让这个封装类更加强大和通用。
写在最后
好了,朋友们,从InfluxDB是啥,到怎么存,再到怎么用代码跟它"玩耍",我们一气呵成。
记住,当你下次再遇到海量时间序列数据这场"洪水"时,别再手忙脚乱地拿MySQL这个"水瓢"去舀了,果断请出InfluxDB这位"专业泄洪闸",保证你的人生从此"风调雨顺"!
快去你的服务器上部署一个试试吧,保证让你的监控数据变得前所未有的性感!