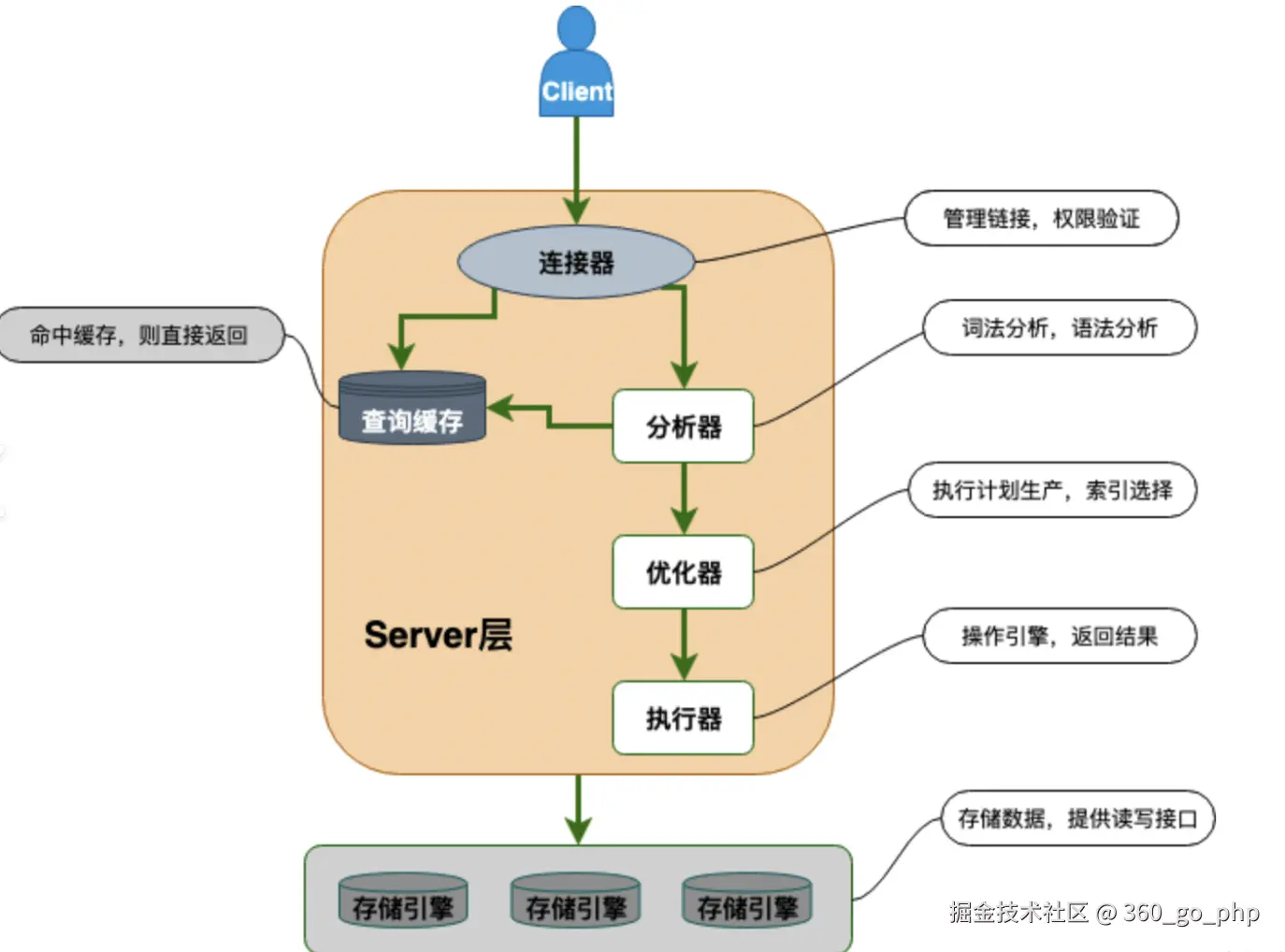
MySQL 是大厂面试中常见的考察内容,尤其是在数据库相关岗位。以下是一些常见的 MySQL 面试问题和详细解答。 编辑
编辑
1. 聚簇索引和非聚簇索引底层实现
-
聚簇索引(Clustered Index) :在 InnoDB 中,聚簇索引是数据表的主键索引,数据行存储在 B+ 树的叶子节点中,数据表的物理顺序与索引顺序一致。换句话说,数据行的存储位置是由索引决定的,索引的叶子节点存储的是数据行的完整信息。
 编辑
编辑优点 :
- 查询数据速度快,尤其是根据主键查询数据时。
- 因为数据行存储在 B+ 树中,所以根据主键范围查询时非常高效。
缺点 :
- 插入数据时,如果新数据需要插入到中间,会发生较大范围的移动,导致性能下降。
-
非聚簇索引(Non-Clustered Index) :非聚簇索引在 InnoDB 中是一个独立的结构,数据表的存储顺序和索引顺序是分开的。非聚簇索引的叶子节点存储的是数据行的指针,而不是数据本身。
 编辑
编辑优点 :
- 可以在多个列上建立索引,提高查询效率。
- 索引更新操作较为轻量。
缺点 :
-
需要额外的存储空间来保存索引。
-
查询数据时需要通过索引查找数据的物理位置,再去获取数据行。
2. 隔离级别
MySQL 中的事务隔离级别包括:
- READ UNCOMMITTED(读未提交):一个事务可以读取另一个事务未提交的数据(脏读)。
- READ COMMITTED(读已提交):一个事务只能读取另一个事务已提交的数据,避免脏读,但可能会产生不可重复读。
- REPEATABLE READ(可重复读):在一个事务中多次读取同一数据,返回的结果是一样的,避免了脏读和不可重复读,但可能会产生幻读。
- SERIALIZABLE(串行化) :最高的隔离级别,事务完全串行执行,避免脏读、不可重复读和幻读,但性能开销大。
 编辑
编辑
3. MySQL 在业务中怎么实现乐观锁
MySQL 中的乐观锁通常通过 MVCC(多版本并发控制) 实现。MVCC 在 InnoDB 存储引擎中用于处理并发事务,避免锁的竞争,提高数据库性能。
- 原理:InnoDB 为每一行记录维护多个版本,每个版本都有一个唯一的时间戳或者版本号。事务操作时,读取的数据行会带有该行的版本信息,事务提交时会检查数据是否被其他事务修改过。如果修改过,则当前事务会失败或回滚。
- 应用场景:乐观锁适用于读取多、修改少的场景,如电子商务中的库存管理、社交平台等。
4. MVCC原理,和FOR UPDATE有什么区别
- MVCC原理 :MVCC 通过在每个数据行中维护一个 事务 ID(或版本号) 和 回滚指针 ,实现数据的并发控制。每次查询时,数据库会根据当前事务 ID 来判断该数据是否可见,从而实现并发控制。MVCC 可以有效减少锁的使用,提升并发性能。
- FOR UPDATE :
FOR UPDATE用于在查询数据时锁定查询结果,防止其他事务修改被查询到的行。在事务提交之前,其他事务不能修改或删除锁定的行。这种方式是一种悲观锁机制,用于防止数据冲突。
区别:
- MVCC 是一种乐观锁机制,不会阻塞其他事务的操作。
FOR UPDATE是一种悲观锁机制,可能会导致其他事务被阻塞,直到当前事务完成。
5. InnoDB 和 MyISAM 区别
| 特性 | InnoDB | MyISAM |
|---|---|---|
| 事务支持 | 支持事务(ACID) | 不支持事务 |
| 锁机制 | 支持行级锁 | 只支持表级锁 |
| 外键约束 | 支持外键约束 | 不支持外键约束 |
| 性能 | 在高并发写操作中更优 | 读取操作性能更好 |
| 崩溃恢复 | 支持崩溃恢复 | 不支持崩溃恢复 |
6. B+树前世今生以及所有
-
前世 :B+ 树是一种平衡树数据结构,常用于文件系统和数据库索引的实现。B+ 树的每个节点可以有多个子节点,所有叶子节点存储实际数据或数据的指针,而非叶子节点仅存储索引值。B+ 树的特点是查询效率高,并且能够高效地进行范围查询。
-
今生:B+ 树广泛应用于数据库和文件系统中,尤其在 MySQL 中被用作默认的索引结构。它通过有序的链表结构连接所有叶子节点,方便范围查询。
-
所有 :B+ 树的主要特点包括:
-
平衡性 :每个叶子节点到根节点的距离相同。
-
多路查找 :每个节点可以有多个子节点。
-
有序:叶子节点按键值顺序排列,适合范围查询。
-
7. ACID
ACID 是数据库事务的四个基本特性:
- 原子性(Atomicity):事务中的操作要么全部成功,要么全部失败。
- 一致性(Consistency):事务执行前后,数据库的一致性规则不被破坏。
- 隔离性(Isolation):事务的执行不应受其他事务的干扰,事务之间是独立的。
- 持久性(Durability):事务一旦提交,其对数据库的修改就会永久保存。
8. 联合索引底层结构
联合索引是由多个列组成的索引,其底层是 B+ 树。联合索引会按照索引列的顺序对数据进行排序,查询时可以提高多个条件下的查询效率。使用联合索引时,查询时必须从左到右依次使用索引列,才能发挥其最大效能。
9. SQL 里 WHERE 和 HAVING 分别是做什么的,有什么区别,什么时候用
- WHERE:用于在查询结果中筛选记录,适用于筛选单行记录的条件。
- HAVING:用于对分组后的结果进行筛选,适用于聚合函数(如 COUNT、SUM)等操作后的结果。
区别:
WHERE用于筛选数据行,HAVING用于筛选聚合结果。
使用场景:
- 使用
WHERE时对数据行进行筛选;使用HAVING时对聚合数据进行筛选。
10. MySQL索引类别
- 主键索引:表的主键是唯一的,自动创建主键索引。
- 唯一索引:确保索引列的值唯一。
- 普通索引:没有唯一性要求,适用于检索。
- 全文索引:适用于全文搜索,索引文本内容。
- 组合索引:由多个列组成的索引。
11. 左连接和内连接的区别
- 内连接(INNER JOIN):只返回两个表中匹配的记录。
- 左连接(LEFT JOIN):返回左表的所有记录,即使右表没有匹配的记录,右表的字段会显示为 NULL。
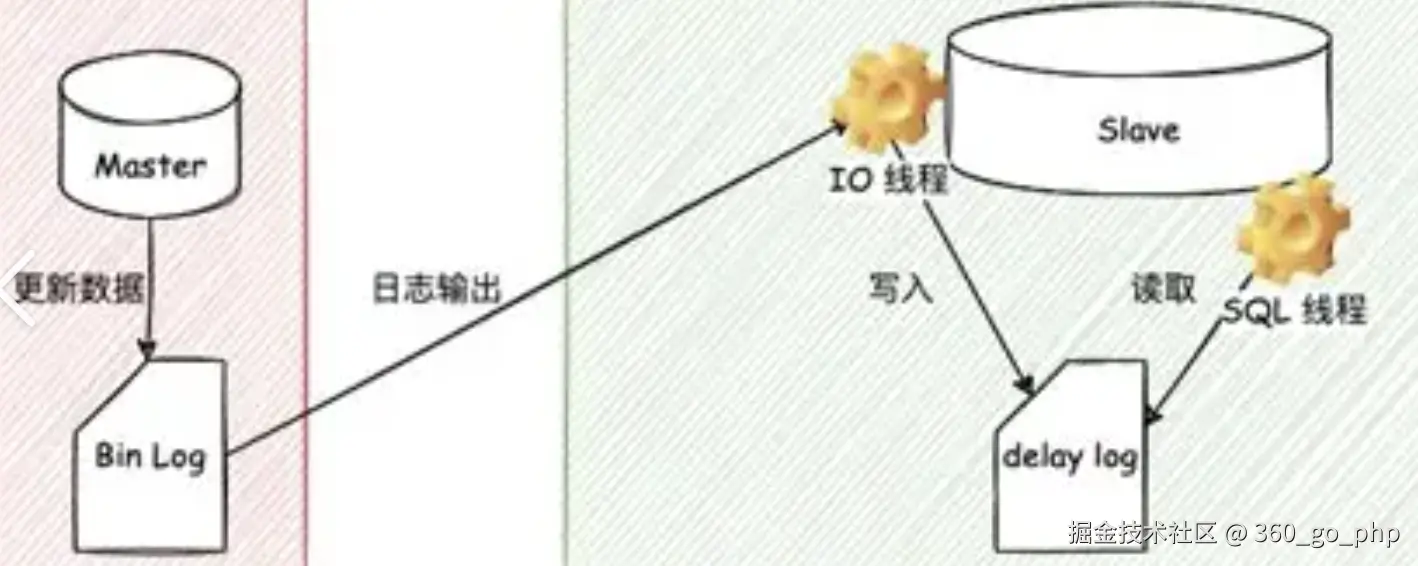
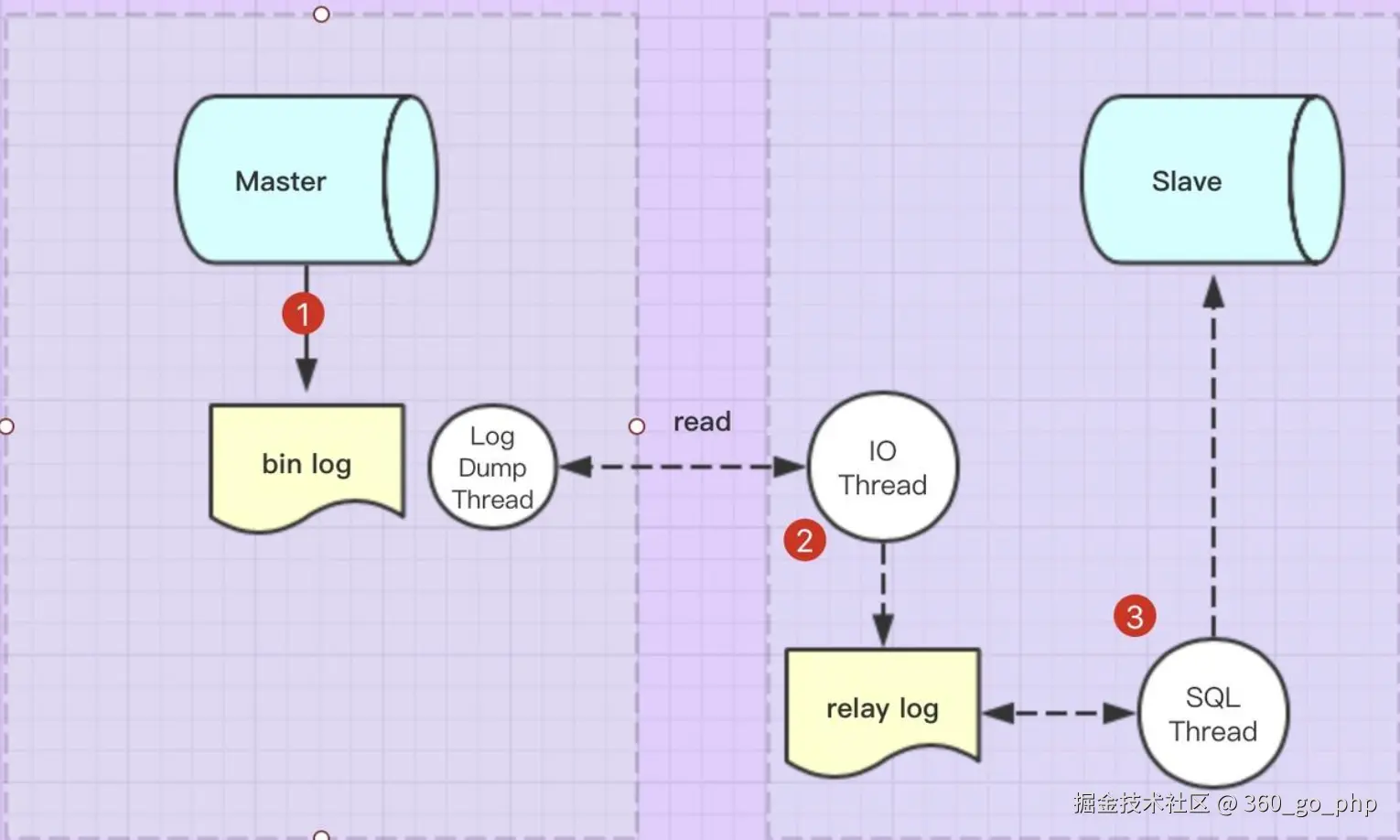
12. 谈谈 binlog 和 redo log
- binlog:用于记录数据库中所有修改操作的日志文件,它是逻辑日志(记录 SQL 语句)。用于数据恢复和主从复制。
- redo log :用于记录 InnoDB 存储引擎事务提交前对数据页的修改操作,是物理日志。用于崩溃恢复。
 编辑
编辑
13. 获取所有课程得分均大于80分的学生的平均得分
假设有 student_scores 表,包含 student_id, course_id, 和 score 字段。要求查询得分均大于 80 分的学生的平均得分:
sql
SELECT student_id, AVG(score) AS avg_score
FROM student