点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年10月07日更新到: Java-141 深入浅出 MySQL Spring事务失效的常见场景与解决方案详解(3) MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成了如下的内容:
- 滑动窗口:时间驱动、事件驱动
- 会话窗口:时间驱动、事件驱动

Time
在Flink的流式处理中,会涉及到时间的不同概念, 如下图所示: 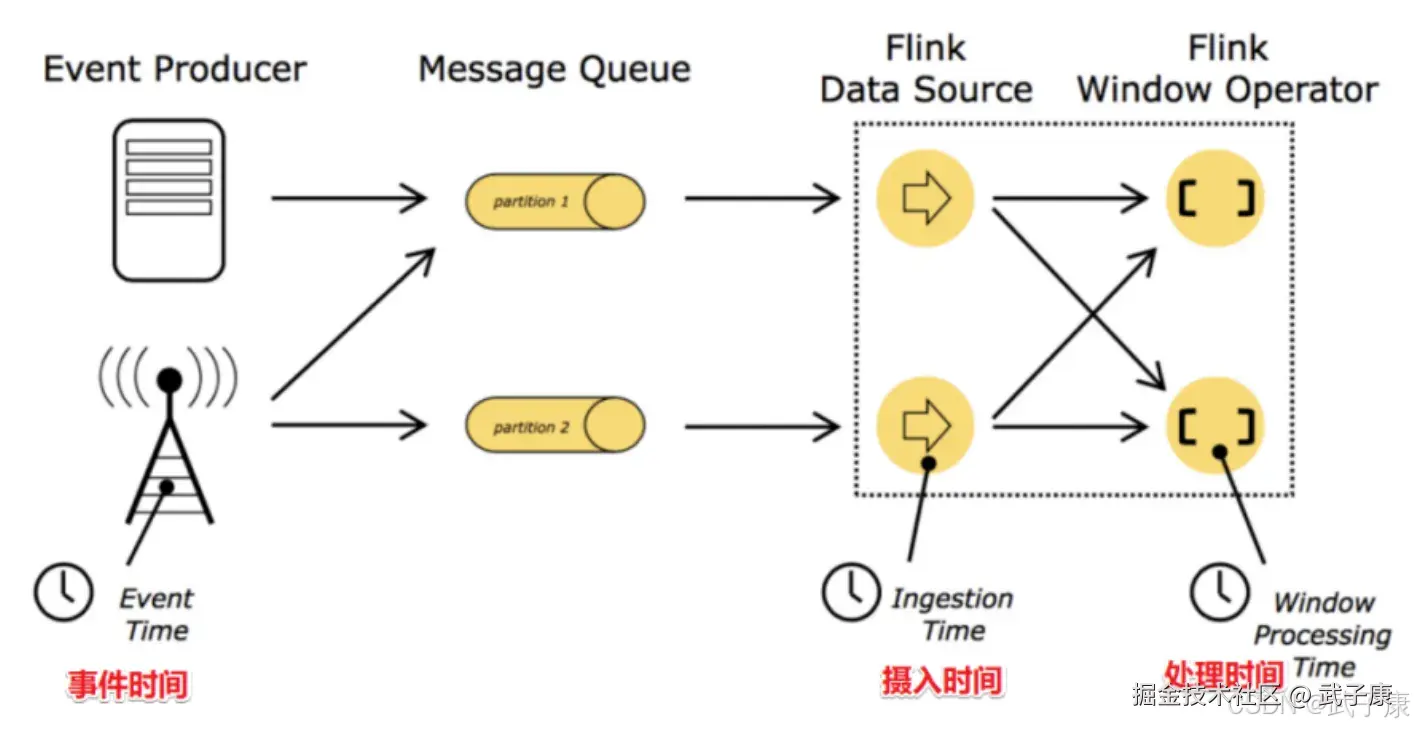
- EventTime事件时间:事件发生的时间,例如:点击网站上的某个链接的时间,每一条日志都会记录自己的生成时间,如果EventTime为基准来定义时间窗口那将形成EventTimeWindow,要求消息本身就应该携带EventTime
- IngestionTime摄入时间:数据进入Flink时间,如某个Flink节点SourceOperator接收到数据的时间,例如:某个Source消费到Kafka中的数据,如果以IngesingTime为基准来定义时间窗口那将形成IngestingTimeWindow,以Source的SystemTime为准
- ProcessingTime处理时间:某个Flink节点执行某个Operation的时间,例如:TimeWindow处理数据时的系统时间,默认时间的属性就是ProcessingTime。如果以ProcessingTime基准来定义时间窗口将形成ProcessingTimeWindow,以Operator的SystemTime为准
在Flink的流式处理中,绝大部分的业务都会使用EventTime,一般只在EventTime无法使用时,才会被迫使用ProcessingTime或者IngestionTime。 如果使用EventTime,那么需要引入EventTime的事件属性,引入方式如下所示:
java
# 设置使用事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)基本概念
在 Apache Flink 中,Time Watermark(时间水印)是处理事件时间(Event Time)流处理的核心概念之一。它用于解决乱序事件的问题,帮助系统正确地按照事件发生的时间顺序进行处理。下面是详细解释:
事件时间(Event Time)和处理时间(Processing Time)
事件时间(Event Time)
事件时间是指事件在现实世界中实际发生的时间,通常由数据源本身携带。这个时间戳通常嵌入在数据记录中,例如:
- IoT设备传感器读数的时间戳
- 用户点击行为发生的时间
- 交易记录的交易时间
- 日志记录中的日志生成时间
在Flink中,可以通过TimestampAssigner接口从数据记录中提取事件时间。典型的事件时间提取方式包括:
- 从JSON/XML格式的数据字段中解析时间戳
- 从数据库记录的创建时间字段获取
- 从Kafka消息的元数据中获取
处理时间(Processing Time)
处理时间是指事件被流处理系统实际处理时的系统时间。它完全取决于处理节点的系统时钟,与事件本身无关。处理时间的特点是:
- 不需要从数据中提取时间戳
- 处理延迟最低
- 实现简单,不需要考虑乱序问题
两种时间的对比与选择
在实际应用中,事件时间和处理时间的主要区别体现在:
| 特性 | 事件时间 | 处理时间 |
|---|---|---|
| 准确性 | 高,反映真实发生时间 | 低,依赖处理时间 |
| 延迟 | 需要处理乱序,可能引入延迟 | 无额外延迟 |
| 实现复杂度 | 高,需水印机制 | 低,自动处理 |
| 适用场景 | 需要精确时间语义的分析 | 低延迟处理 |
典型应用场景:
-
事件时间适用场景:
- 计算用户行为分析中的会话窗口
- 生成精确的每日/每小时报表
- 检测异常事件的时间序列模式
-
处理时间适用场景:
- 需要极低延迟的监控告警
- 近似实时统计
- 不需要严格时间精确性的场景
乱序问题及其解决方案
在实际的流处理中,由于以下原因可能导致事件乱序:
- 网络延迟和抖动
- 分布式系统各节点时钟不同步
- 数据分区和并行处理
- 数据重传和故障恢复
Flink提供了完整的事件时间处理机制来解决乱序问题:
- 水印(Watermark)机制:跟踪事件时间进度,指示"时间已经推进到哪一点"
- 窗口触发策略:允许延迟数据在一定时间范围内加入计算
- 侧输出(Side Output):收集延迟太严重的数据单独处理
例如,在电商订单分析中,使用事件时间可以确保:
- 双11零点产生的订单被正确统计在双11当天的销售额中
- 即使用户手机时间设置错误,仍能按正确时间分析
- 网络延迟导致的晚到订单能被正确处理
乱序事件
乱序事件指的是数据流中的事件没有按照事件时间的顺序进入流处理系统。例如,事件A的事件时间是 12:00:01,事件B是 12:00:02,但事件B可能会比事件A先到达处理系统。
为了处理这种乱序问题,Flink 引入了 Watermark 机制。
什么是 Watermark
Watermark 是一个特殊的标志,它用于告诉 Flink 数据流中事件的进展情况。简单来说,Watermark 是 Flink 中估计的"当前时间",表示所有早于该时间戳的事件都已经到达。
Watermark 的定义与工作机制
核心概念
Watermark 是 Apache Flink 流处理框架中用于处理事件时间(event time)的核心机制。它本质上是一个特殊的时间戳,表示系统对事件流中数据完整性的判断标准。Flink 认为当前时间在 Watermark 时间戳之前的所有事件已经接收完毕,不再期待有早于该时间戳的事件。
工作原理
- 时间推进机制:当 Watermark 时间戳更新时,系统可以触发基于事件时间的窗口操作,比如窗口计算、聚合等。
- 延迟数据处理:Watermark 允许一定程度的延迟数据到达,但超过 Watermark 时间戳的数据会被视为迟到事件。
具体示例
假设一个订单处理场景:
- 当前 Watermark 值是 12:00:00
- 表示系统认为所有时间戳在 12:00:00 之前的订单数据已经全部到达
- 此时系统可以:
- 关闭时间窗口(如11:00-12:00的窗口)
- 触发该窗口的聚合计算
- 生成最终结果输出
- 如果之后收到时间戳为11:55:00的订单,这个订单会被视为迟到事件
应用场景
- 电商订单分析:统计每小时订单量
- IoT设备监控:分析设备每分钟的传感器读数
- 金融交易处理:计算每分钟的交易金额总和
配置参数
在实际应用中,通常需要配置:
- Watermark 生成间隔(默认200ms)
- 最大允许延迟时间(根据业务需求设置)
- 迟到数据处理策略(丢弃或侧输出)
Watermark 生成方式
Watermark 可以通过自定义来生成,也可以使用内置策略。在常见情况下,Watermark 生成方式有两种:
a. 固定延迟策略(Fixed Delay)
最简单的 Watermark 生成方式是引入固定的延迟。例如,假设延迟 5 秒生成 Watermark,那么每个事件时间戳减去 5 秒就是当前的 Watermark。
b. 周期性生成 Watermark
Flink 允许 Watermark 定期生成,可以通过定期检查数据流中的最大时间戳来生成新的 Watermark。
数据延迟问题
示例1
现在假设,你正在去往地下停车场的路上,并且打算用手机点一份外卖。 选好了外卖之后,你就用在线支付功能付款了,这个时候是 11点50分。 但是这时,你走进了地下停车库,而这里没有手机信号,因此外卖的在线支付并没有立刻成功,而支付系统一直在Retry这个操作。 当你找到了自己的车并开出停车场的时候,已经是 12点05分了,而支付数据的处理时间是 12点05 分。 一般在实际开发中会以事件时间作为计算标准。
示例2
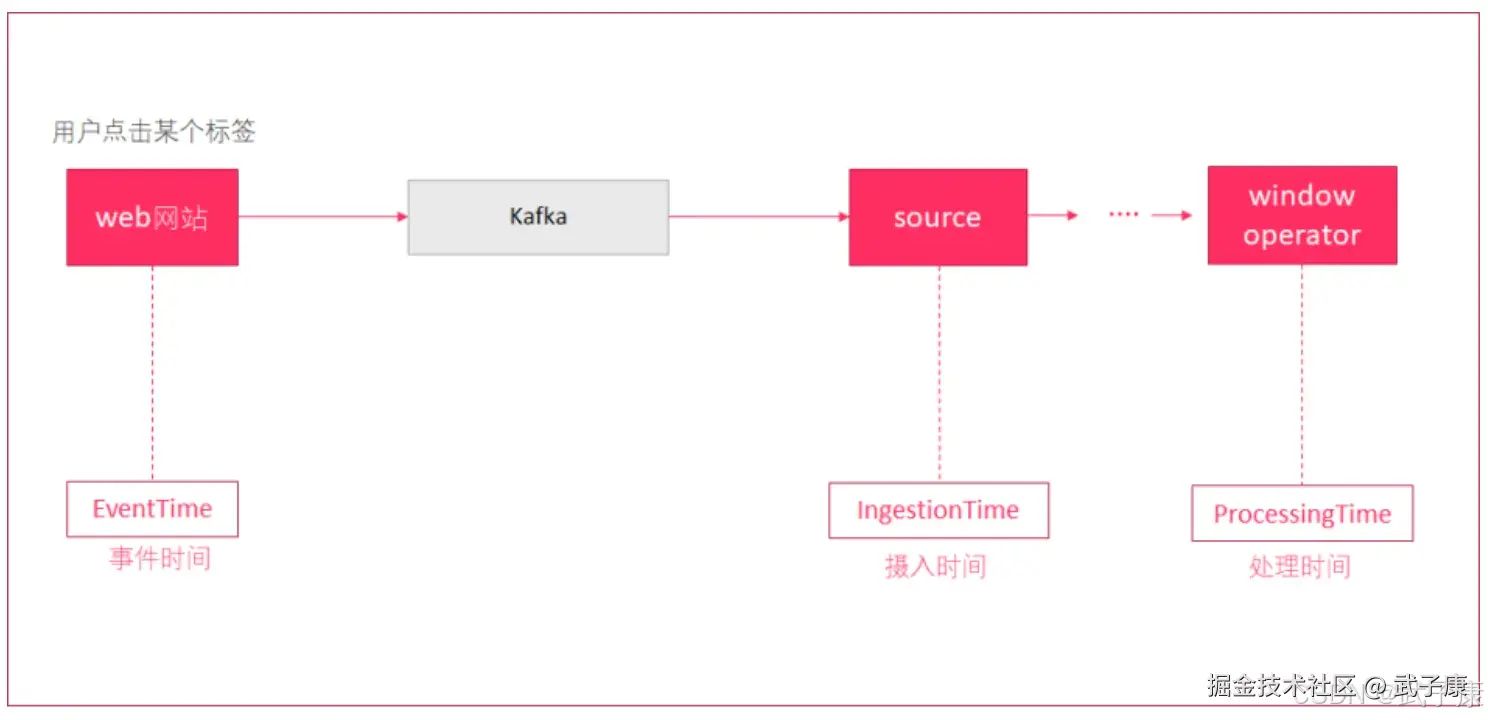
- 一条日志进入Flink的事件为 2024-07-27 10:00:01 摄入时间
- 到达Window系统的时间是 2024-07-27 10:00:02 处理时间
- 日志内容为:2024-07-27 09:59:5- INFO Fail Over 事件时间
对于业务来说,要统计1小时内的故障日志的个数,哪个时间最有意义?当然是事件时间。 EventTime,因为我们要根据日志的生成时间进行统计。
示例3
某APP记录用户的所有点击行为,并回传日志,(在网络不好的情况下,先保存本地,延后回传)。 A用户在 11:02 对APP进行操作,B用户在 11:03 操作了APP。 但是A用户的网络太不稳定,回传日志延迟了,导致我们服务端先接受到B的消息,再接收到A的消息,消息乱序了。
示例4
在实际环境中,经常会出现,因为网络原因,数据有可能会延迟一会儿才到达Flink实时处理系统,我们先来设想一下下面的场景: 
- 使用时间窗口来统计10分钟内的用户流量
- 有一个时间窗口:开始时间 2024-07-27 10:00:00,结束时间 2024-07-27 10:10:00
- 有一个数据,因为网络延迟:事件发生的时间为:2024-07-27 10:10:00,但进入到窗口的事件为:2024-07-27 10:10:02 延迟2秒
这种处理方式,根据消息进入到Window时间,来进行计算,在网络有延迟的时候,会引起计算误差。
如何解决
使用水印来解决网络延迟的问题。 通过上面的例子,我们知道,在进行数据处理的时候应该按照事件时间进行处理,也就是窗口应该要考虑到事件时间。 但是窗口不能无限的一直等待延迟数据的到来,需要有一个触发窗口计算的进制,也就是我们接下来要学的Watermark水位线/水印机制。
WaterMark
水印(Watermark)就是一个时间戳,Flink可以给数据流添加水印,可以理解为:
- 收到一条消息后,额外给这个消息添加一个时间字段,这就是添加水印。
- 水印并不影响原有EventTime事件时间
- 当数据流添加水印后,按照水印时间来触发窗口计算:也就是Watermark水印是用来触发窗口计算的
- 一般会设置水印时间,比事件时间小几秒钟,表示最大允许数据延迟到达多久(即水印时间 = 事件时间 - 允许延迟时间)
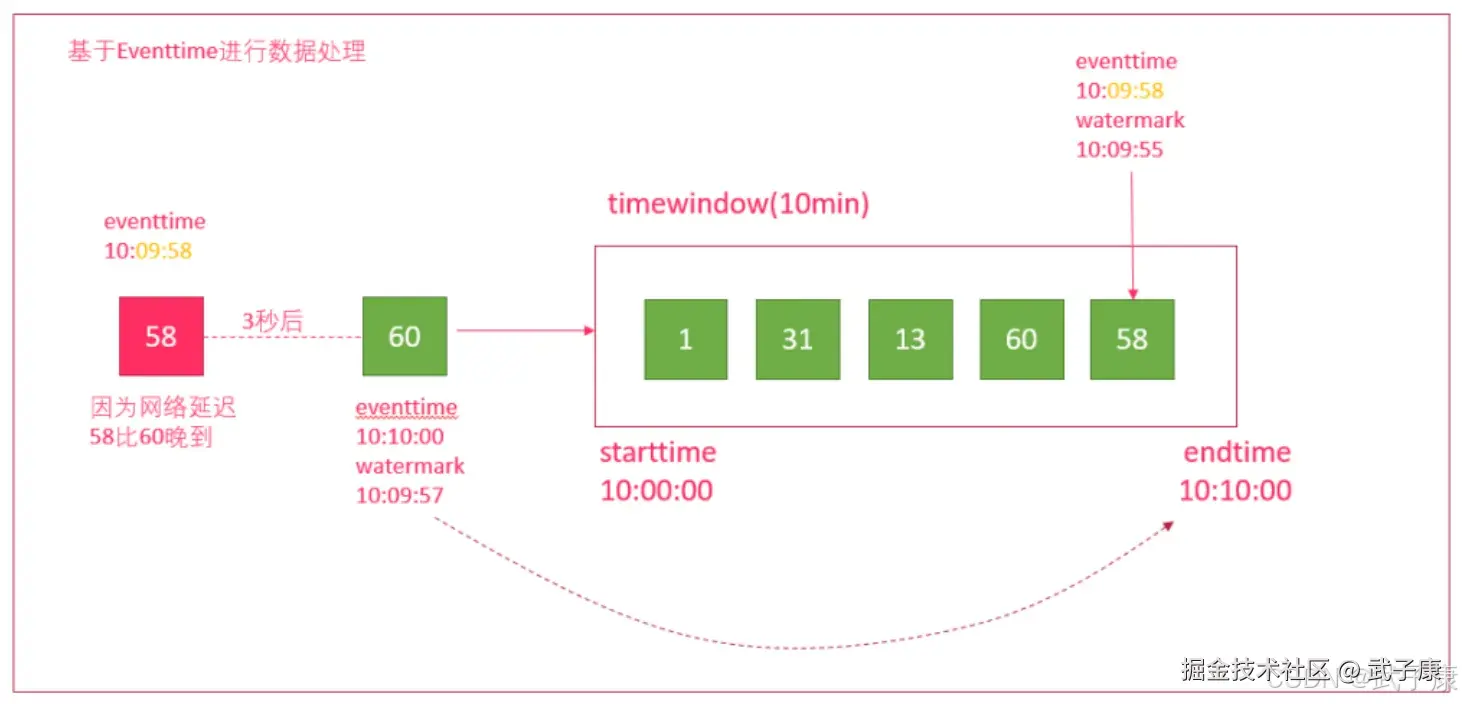
- 当接收到的 水印时间 >= 窗口结束时间,则触发计算,如等到一条数据的水印时间为 10:10:03 >= 10:10:00 才触发计算,也就是要等到事件为 10:10:03的数据到来才触发计算
解决总结
Watermark是用来解决延迟数据的问题,如窗口:10:00:00 ~ 10:10:00 而数据到达的顺序是:A 10:10:00,B 10:09:58 如果没有Watermark,那么A数据将会触发窗口计算,B数据来了窗口已经关闭,则该数据丢失。 如果有了 Watermark,设置允许数据迟到的阈值为3秒。 那么该窗口的结束条件则为水印:水印时间 >= 窗口结束时间 10:10:00,也就是需要一条数据的水印事件=10:10:00 而水印时间10:10:00 = 事件时间 - 延迟时间 3 秒 也就是需要有一条事件为10:10:03的数据到来,才会触发真正的计算。 而上面的A 10:10:00,B 10:09:58 都不会触发计算,也就是会被窗口包含,直到10:10:03的数据到来才会计算窗口 10:00:00 - 10:10:00 的数据。
Watermark
实现步骤
- 获取数据源
- 转化
- 声明水印(Watermark)
- 分组聚合,调用Window操作
- 保存处理结果
注意事项
当使用 EventTimeWindow时,所有的Window在EventTime的时间轴上进行划分,也就是说,在Window启动后,会根据初始的EventTime时间每隔一段时间划分一个窗口,如果Window大小是3秒,那么1分钟内会把Window划分为如下的形式:
shell
[00:00:00,00:00:03)
[00:00:03,00:00:06)
[00:00:03,00:00:09)
[00:00:03,00:00:12)
[00:00:03,00:00:15)
[00:00:03,00:00:18)
[00:00:03,00:00:21)
[00:00:03,00:00:24)- 窗口是左闭右开,形式为为:[window_start_time, window_end_time)
- Window的设定基于第一条消息的事件时间,也就是说,Window会一直按照指定的时间间隔进行划分,不论这个Window中没有数据,EventTime 在这个Window期间的数据会进入这个Window
- Window会不断产生,属于这个Window范围的数据会不断加入到Window中,所有未被触发的Window都会等待出发,只要Window还没出发,属于这个Window范围的数据就会一直被加入到Window中,直到Window被处罚才会停止数据的追加,而当Window触发之后才接收到属于被触发Window的数据会被丢弃。
- Window会在以下的条件满足时才会被处罚执行:(1)在[window_start_time, window_end_time)窗口中有数据存在,(2)Watermark时间 >= window_end_time
一般会设置水印时间,比事件时间小几秒钟,表示最大允许数据延迟到达是多久:水印时间=事件时间-允许延迟时间。 当接收到水印时间 >= 窗口结束时间 且 窗口内有数据,则触发计算:事件时间 - 允许延迟时间 >= 窗口结束时间 或 事件时间 >= 窗口结束时间 + 允许延迟时间