这里使用containerd安装哦
🖥️ 环境准备与系统配置
1.节点规划
| 角色 | IP地址 | 操作系统 | 配置 |
|---|---|---|---|
| Master | 192.168.22.132 | Ubuntu22.04 基础设施服务器 | 2颗CPU 4G内存 50G硬盘 |
| Node1 | 192.168.22.133 | Ubuntu22.04基础设施服务器 | 2颗CPU 4G内存 50G硬盘 |
2.设置主机名与Hosts解析
2.1 设置主机名
sql
# 在Master节点执行
sudo hostnamectl set-hostname k8s-master
# 在Worker节点执行
sudo hostnamectl set-hostname k8s-node12.2 配置hosts文件
sql
#所有节点上编辑 /etc/hosts文件
sudo nano /etc/hosts
#添加Ip+主机名
192.168.22.132 k8s-master
192.168.22.133 k8s-node13.时间同步
kubernetes要求集群中的节点时间必须精确一致,这里直接使用chronyd服务从网络同步时间。企业中建议配置内部的时间同步服务器。
sql
# 1. 安装 Chrony
sudo apt update
sudo apt install -y chrony
# 2. 修改配置文件(使用阿里云 NTP 服务器)
sudo nano /etc/chrony/chrony.conf在配置文件中:
3.1 注释掉默认的 NTP 服务器(以 pool开头的行)
3.2 添加阿里云 NTP 服务器:
sql
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst修改后示例:
sql
# 默认服务器注释掉
# pool 0.ubuntu.pool.ntp.org iburst
# pool 1.ubuntu.pool.ntp.org iburst
# pool 2.ubuntu.pool.ntp.org iburst
# pool 3.ubuntu.pool.ntp.org iburst
# 添加阿里云 NTP 服务器
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
# 关键配置参数
pool 2.ubuntu.pool.ntp.org offline minpoll 8
driftfile /var/lib/chrony/chrony.drift
makestep 1.0 3
rtcsync
maxdistance 16.0
keyfile /etc/chrony/chrony.keys
logdir /var/log/chrony
maxupdateskew 100.0
# 允许本地网络同步(可选)
allow 192.168.0.0/16
# 其他保持默认
sql
# 3. 重启 Chrony 服务
sudo systemctl restart chrony
# 4. 设置开机自启
sudo systemctl enable chrony
# 5. 检查服务状态
sudo systemctl status chrony
# 6. 等待几秒后验证时间同步
date
# 7. 查看时间同步状态
chronyc tracking
#查看输出中的 Leap status和 System time确保显示正常同步
# 8. 查看 NTP 服务器状态
chronyc sources -v
#输出应显示阿里云的 NTP 服务器,状态为 ^*(已同步)
#正常输出应该类似:
#System clock synchronized: yes4.禁用iptables和firewalld服务
kubernetes和docker在运行中会产生大量的iptables规则,为了不让系统规则跟它们混淆,直接关闭系统的规则
4.1 关闭UFW(Ubuntu默认防火墙)
sql
# 停止 UFW 服务
sudo systemctl stop ufw
# 禁用 UFW 开机自启
sudo systemctl disable ufw
# 检查 UFW 状态
sudo ufw status正常输出:
sql
Status: inactive
4.2 关闭iptables
sql
# 停止 iptables 服务(如果使用传统 iptables)
sudo systemctl stop iptables 2>/dev/null || true
sudo systemctl stop iptables6 2>/dev/null || true
# 禁用 iptables 开机自启
sudo systemctl disable iptables 2>/dev/null || true
sudo systemctl disable iptables6 2>/dev/null || true
# 清空所有 iptables 规则
sudo iptables -F
sudo iptables -X
sudo iptables -t nat -F
sudo iptables -t nat -X
sudo iptables -t mangle -F
sudo iptables -t mangle -X
sudo iptables -P INPUT ACCEPT
sudo iptables -P FORWARD ACCEPT
sudo iptables -P OUTPUT ACCEPT
# 对于 IPv6(如果使用)
sudo ip6tables -F
sudo ip6tables -X
sudo ip6tables -t nat -F
sudo ip6tables -t nat -X
sudo ip6tables -t mangle -F
sudo ip6tables -t mangle -X
sudo ip6tables -P INPUT ACCEPT
sudo ip6tables -P FORWARD ACCEPT
sudo ip6tables -P OUTPUT ACCEPT4.3 验证
sql
# 检查 UFW 状态(应该显示 inactive)
sudo ufw status
# 检查 iptables 规则(应该显示空规则或默认 ACCEPT)
sudo iptables -L
# 检查防火墙服务状态
sudo systemctl status ufw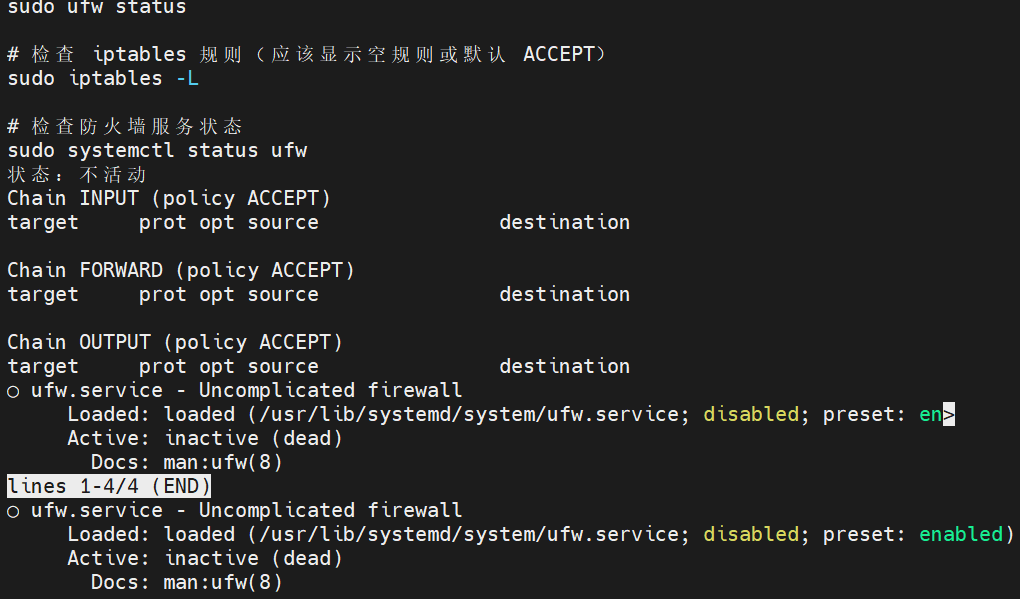
4.4 检查Kubernetes 所需端口
关闭防火墙后,确保 Kubernetes 所需端口可访问:
master
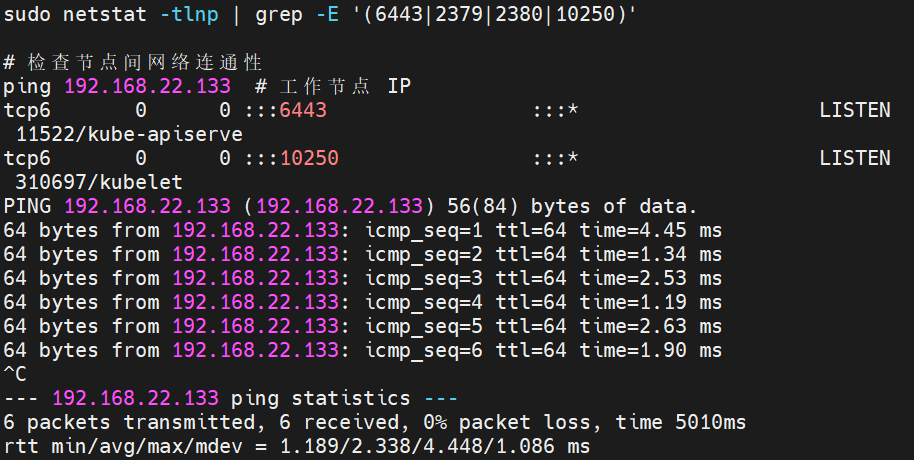
node
sql
# 检查本地端口监听
sudo netstat -tlnp | grep -E '(6443|2379|2380|10250)'
# 检查节点间网络连通性
ping 192.168.22.133 # 工作节点 IP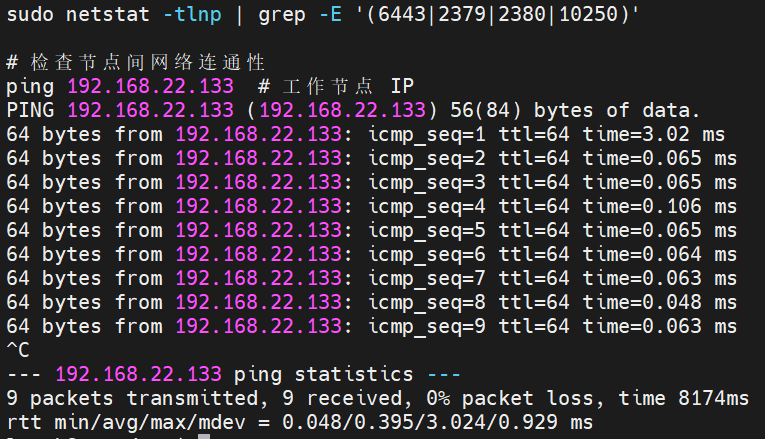
工作节点通常不会监听 6443、2379、2380 这些端口
✅ 6443 端口 - 只在主节点的 API Server 监听
✅ 2379、2380 端口 - 只在主节点的 etcd 监听
✅ 10250 端口 - 应该在所有节点上监听(kubelet)
5.关闭Swap分区
5.1 Kubernetes为了保证稳定性,需要禁用Swap。在所有节点上执行
sql
#修改前,备份/etc/fstab文件
sudo cp /etc/fstab /etc/fstab.bak
#编辑/etc/fstab文件
sudo nano /etc/fstab5.2注释掉 Swap 所在行,示例:
sql
# /dev/mapper/ubuntu--vg-swap_1 none swap sw 0 0
5.3 重启系统
sql
sudo reboot5.4 验证
sql
sudo swapon --show
free -h如果
swapon --show没有输出,且free -h中 Swap 一行显示为 0,则表示 Swap 已成功禁用
4.配置网桥过滤和内核转发
这些参数是Kubernetes网络工作所必需的。在所有节点上执行以下命令
4.1 安装必要工具
sql
sudo apt update
sudo apt install -y bridge-utils ipset4.2 创建并配置内核参数文件
sql
sudo tee /etc/sysctl.d/kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
EOF4.3 加载内核模块
sql
sudo modprobe br_netfilter
sudo modprobe overlay4.4 使配置永久生效
sql
sudo tee /etc/modules-load.d/k8s.conf <<EOF
overlay
br_netfilter
EOF4.5 应用内核参数
sql
sudo sysctl --system4.6 验证配置
sql
# 检查 br_netfilter 模块是否加载
lsmod | grep br_netfilter
# 检查关键内核参数值
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward4.7 为 Kubernetes 优化网络
sql
#加载 IPVS 模块
sudo modprobe ip_vs
sudo modprobe ip_vs_rr
sudo modprobe ip_vs_wrr
sudo modprobe ip_vs_sh
sudo modprobe nf_conntrack
#确保 IPVS 模块持久化
sudo tee /etc/modules-load.d/ipvs.conf <<EOF
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
EOF注:在 Ubuntu 22.04 中,默认没有安装 SELinux ,而是使用 AppArmor 作为安全模块。因此,您不需要执行这些 SELinux 相关的命令。
🔧基础环境
1.配置Kubernetes APT源
首先需要添加 Kubernetes 的官方 APT 仓库和 GPG 密钥
sql
# 安装必要的工具
sudo apt update
sudo apt install -y apt-transport-https ca-certificates curl
# 下载 Kubernetes 官方 GPG 密钥
sudo curl -fsSLo /etc/apt/keyrings/kubernetes-archive-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg
# 添加 Kubernetes APT 仓库
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
# 更新软件包列表
sudo apt update2.安装k8s组件
安装 kubeadm、kubelet 和 kubectl,并锁定它们的版本以防止自动升级
sql
# 安装指定版本(推荐,例如安装 1.24.4)
sudo apt install -y kubelet=1.24.4-00 kubeadm=1.24.4-00 kubectl=1.24.4-00
# 或者安装最新稳定版
# sudo apt install -y kubelet kubeadm kubectl
# 锁定版本,防止意外升级
sudo apt-mark hold kubelet kubeadm kubectl
# 查看 kubeadm 版本确认安装成功
kubeadm version3.配置Cgroup驱动
3.1 配置containerd
sql
sudo containerd config default | sudo tee /etc/containerd/config.toml然后,找到
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]部分,将SystemdCgroup设置为true
sql
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true重启 containerd 服务以应用配置:
sql
sudo systemctl restart containerd
sudo systemctl enable containerd3.2 (备选)配置 kubelet
sql
# 编辑 /etc/default/kubelet
sudo tee /etc/default/kubelet <<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
EOF🔄 启动并设置开机自启
sql
sudo systemctl enable kubelet安装版本推荐(为避免后续版本不兼容)
| 工具类别 | 核心工具 | 版本选择要点 | 备注 |
|---|---|---|---|
| 容器编排核心 | Kubernetes | 推荐 v1.29.x 等稳定版或长期支持版(LTS) ;控制平面与节点组件版本差不宜超过2个小版本。 | 关注社区支持周期 。 |
| 容器运行时 | containerd | 与所选 Kubernetes 版本兼容。Kubernetes v1.24+ 默认不再支持 Docker Engine ,建议使用 containerd。 | 需配置 systemdcgroup 驱动 。 |
| 操作系统 | Ubuntu / CentOS | 例如,Ubuntu 22.04 LTS 或 CentOS 7/8 与 Kubernetes 新版本有较好兼容性 。 | 确保系统版本与 K8s 版本匹配 。 |
| 网络插件 | Calico / Flannel等 | 选用与 Kubernetes 版本兼容的插件版本,例如 Calico 3.26.x 支持 K8s v1.29 。 | 关注网络插件的发布说明。 |
使用国内镜像源 :为了加速镜像拉取,可以考虑使用国内镜像源。例如,在初始化集群时可以使用**
--image-repository registry.aliyuncs.com/google_containers**参数。
版本一致性:在将节点加入集群时,确保工作节点上安装的 kubelet、kubeadm 版本与主节点一致,以避免兼容性问题
。
关键配置 :在 Ubuntu 上成功部署 Kubernetes 的关键之一,是确保容器运行时(如 containerd)的 cgroup 驱动正确配置为**
systemd**,并与 kubelet 保持一致
📦 安装containerd
🔧 安装 Docker CE 与配置 Containerd
1.更新系统并安装依赖工具
sql
sudo apt update
sudo apt install -y apt-transport-https ca-certificates curl gnupg lsb-release software-properties-common2.添加Docker CE的阿里云镜像源
sql
# 添加 Docker 的官方 GPG 密钥(阿里云镜像站也提供密钥)
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# 添加稳定的 Docker CE 阿里云镜像源
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 更新软件包列表
sudo apt update3.安装Docker CE(包含containerd)
sql
sudo apt install -y docker-ce docker-ce-cli containerd.io4.配置containerd
sql
# 生成 containerd 的默认配置文件
sudo mkdir -p /etc/containerd
sudo containerd config default | sudo tee /etc/containerd/config.toml
# 修改配置:启用 systemd cgroup 驱动
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
# (可选)修改配置:使用国内镜像源拉取 Kubernetes 相关镜像
sudo sed -i 's#registry.k8s.io#registry.aliyuncs.com/google_containers#g' /etc/containerd/config.toml5.配置crictl工具
sql
sudo tee /etc/crictl.yaml <<'EOF'
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF6.启动并设置服务开机自启
sql
sudo systemctl daemon-reload
sudo systemctl restart docker containerd
sudo systemctl enable docker containerd7.验证安装
sql
# 验证 Docker 安装
sudo docker run --rm hello-world
# 验证 crictl 能否与 containerd 通信
sudo crictl version💡 为 Kubernetes 优化 Docker/Containerd
1.配置Docker镜像加速器
创建或修改 **/etc/docker/daemon.json**文件,使用国内镜像加速器以大幅提升拉取镜像的速度
sql
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://do.nark.eu.org",
"https://dc.j8.work",
"https://docker.m.daocloud.io",
"https://dockerproxy.com",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.nju.edu.cn"
]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
systemctl status docker验收:
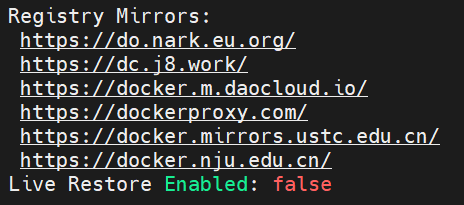
sql
docker run hello-world验收:
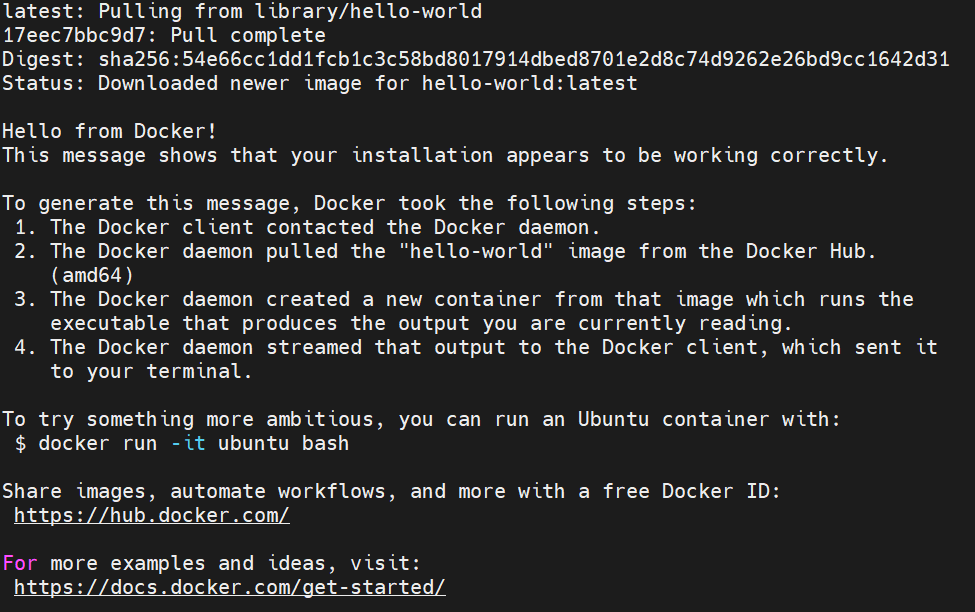
2.将当前用户加入docker组(可选但推荐)
sql
sudo groupadd docker 2>/dev/null || true # 如果 docker 组已存在则忽略错误
sudo usermod -aG docker $USER重要提示 :执行此命令后,你需要完全注销当前会话并重新登录,或者重启系统,才能使组权限更改生效。
⚙️初始化Master节点
1.导出当前集群配置
sql
# 从集群的ConfigMap中导出当前配置
kubectl -n kube-system get configmap kubeadm-config -o jsonpath='{.data.ClusterConfiguration}' > kubeadm-config.yaml2.生成默认文件模板
对于新集群,可以从头生成一个包含默认值的配置文件模板
sql
# 生成初始化默认配置
kubeadm config print init-defaults > kubeadm-config.yaml
# 或者生成加入集群的默认配置(用于工作节点)
kubeadm config print join-defaults > kubeadm-config.yaml3.修改Containerd的Sandbox镜像
sql
# 备份原始配置(可选,建议操作)
sudo cp /etc/containerd/config.toml /etc/containerd/config.toml.bak
# 编辑配置文件
sudo nano /etc/containerd/config.toml配置文件中找到 sandbox_image项并进行修改。如果找不到,可以在 [plugins."io.containerd.grpc.v1.cri"]部分下添加
sql
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"注:最新的 Kubernetes 版本可能要求使用 pause:3.9或更高版本,请确保与您 kubeadm.yml中定义的 Kubernetes 版本兼容
4.重启Containerd服务
sql
sudo systemctl restart containerd
sudo systemctl status containerd # 检查服务状态,确认是否正常运行5.拉取 Kubernetes 镜像并初始化集群
sql
# 查看所需镜像列表,验证配置是否正确
kubeadm config images list --config kubeadm.yml
# 提前拉取所有必需的镜像,避免初始化过程因网络问题中断
sudo kubeadm config images pull --config kubeadm.yml
# 使用 verbose 日志级别进行初始化,便于排查问题
sudo kubeadm init --config=kubeadm.yml --upload-certs --v=6这里经常会出现问题,是正常的
问题1: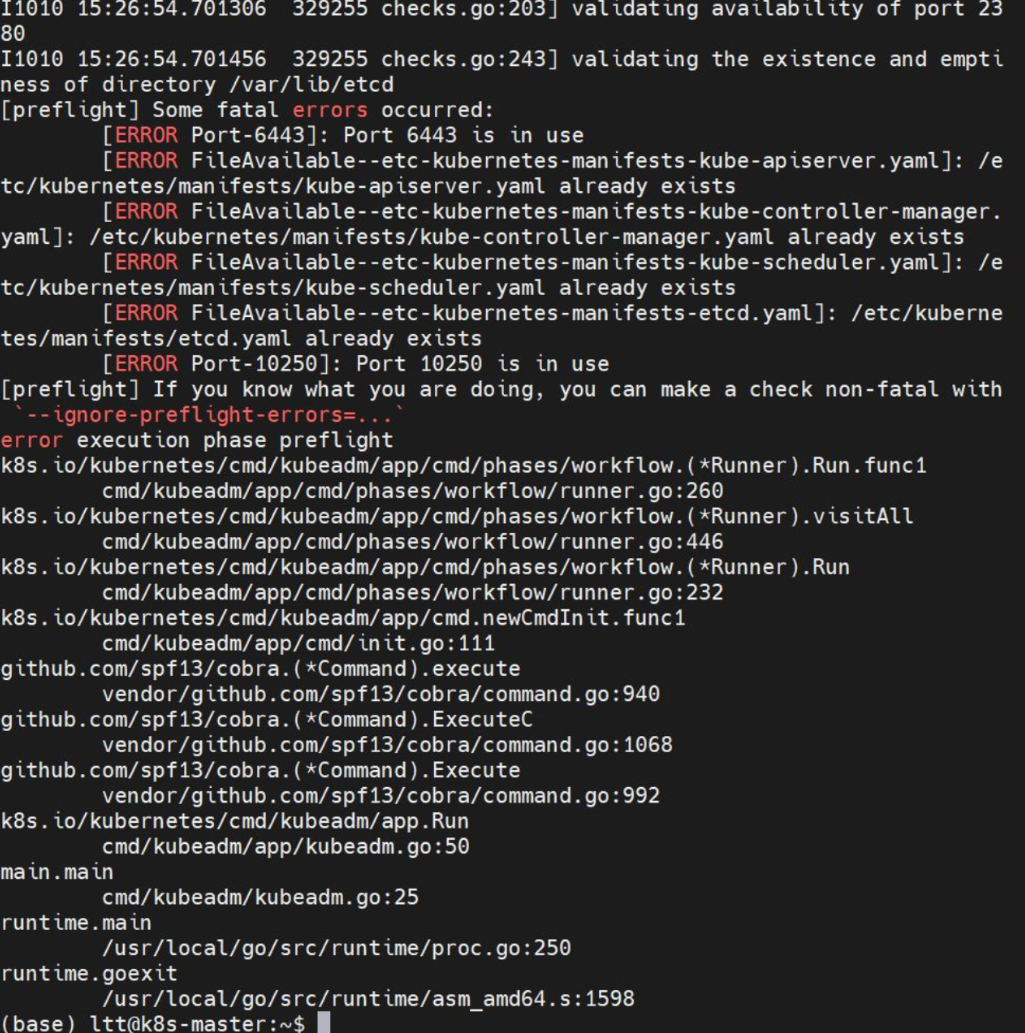
分析:
1. 端口被占用错误
Port 6443 is in use- Kubernetes API Server 端口被占用
Port 10250 is in use- kubelet API 端口被占用2. 文件已存在错误
/etc/kubernetes/manifests/目录下的所有核心组件配置文件都已存在:
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
etcd.yaml
这表明之前已经运行过 kubeadm init 或者没有彻底清理残留文件。需要执行彻底清理。
解决:
1.重置k8s环境
sql
# 1. 重置 kubeadm(在主节点执行)
sudo kubeadm reset -f
# 2. 清理所有残留文件和目录
sudo rm -rf /etc/kubernetes/
sudo rm -rf /var/lib/etcd/
sudo rm -rf $HOME/.kube
sudo rm -rf /var/lib/cni/
# 3. 清理网络接口和 iptables 规则
sudo ip link delete cni0 2>/dev/null || true
sudo ip link delete flannel.1 2>/dev/null || true
sudo iptables -F && sudo iptables -t nat -F
sudo iptables -X && sudo iptables -t nat -X
# 4. 清理容器运行时残留
sudo crictl rm -fa 2>/dev/null || true
sudo crictl rmi -a 2>/dev/null || true2.检查并释放被占用的端口
sql
# 检查哪些进程占用了关键端口
sudo netstat -tlnp | grep -E '(6443|10250|2379|2380)'
# 如果发现有进程占用,停止相关服务
sudo systemctl stop kubelet 2>/dev/null || true
sudo pkill -f kube-apiserver 2>/dev/null || true3.重新初始化
sql
# 1. 再次检查环境是否干净
sudo kubeadm init phase preflight --config kubeadm.yml
# 2. 如果预检查通过,执行初始化
sudo kubeadm init --config=kubeadm.yml --upload-certs --v=6master
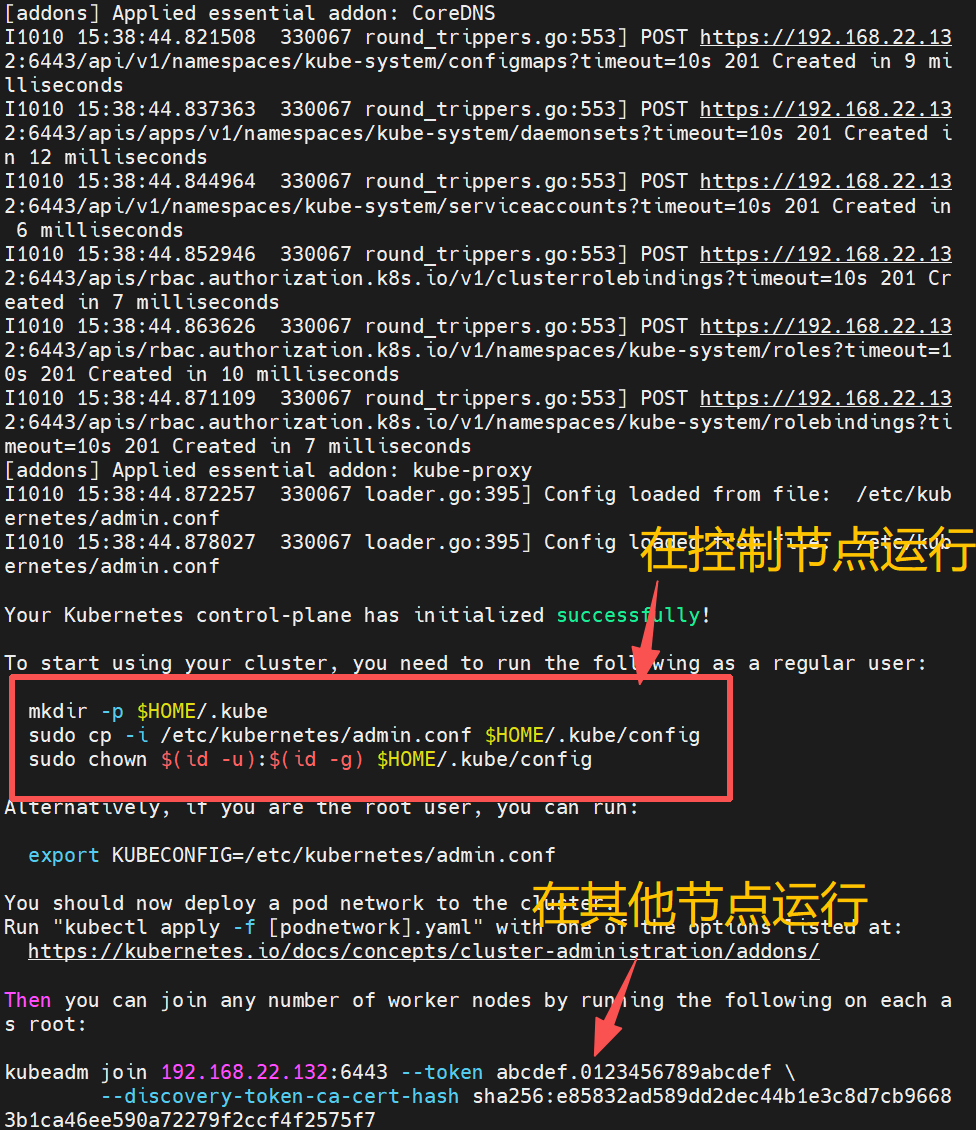
🎉 恭喜!Kubernetes 控制平面已经初始化成功了!
master

node(加入主节点)
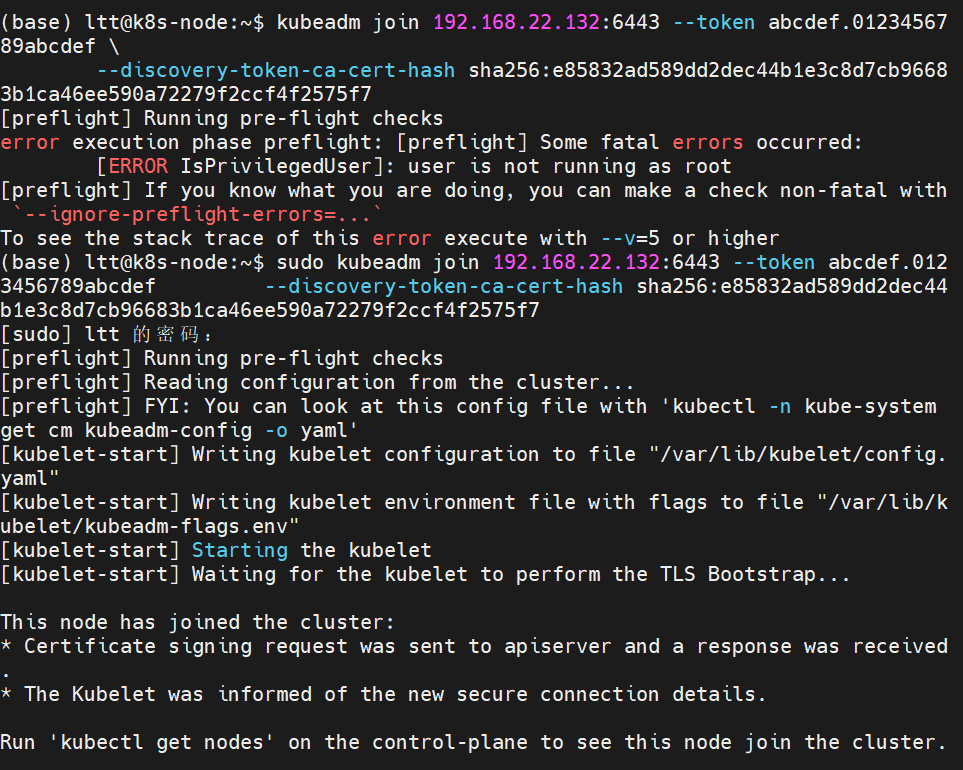
master运行
sql
# 验证配置(应该能看到节点信息)
kubectl get nodes检查主节点

成功加入主节点!!!
补充:这里只加一个节点,如果后续还要加其他节点
sql
# 生成新的加入令牌(在主节点)
kubeadm token create --print-join-command🚀安装网络插件
当前节点状态应该是 NotReady,因为还没有安装网络插件。
1.安装插件
选项1:安装 Flannel(推荐,简单稳定)
sql
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml选项2:安装 Calico(功能更丰富)
sql
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml这里我安装Calico
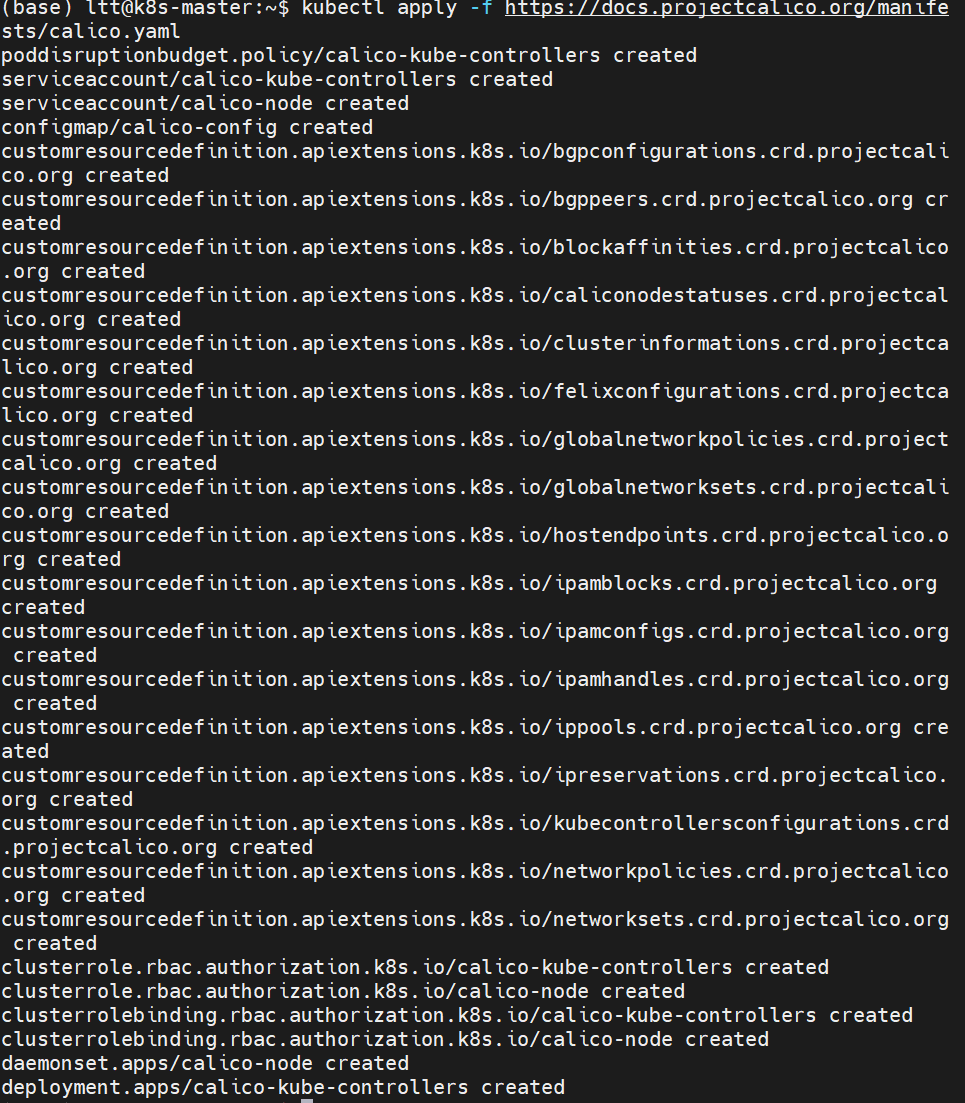
2. 验证集群状态
安装网络插件后,等待几分钟然后检查:
sql
# 检查节点状态(应该变为 Ready)
kubectl get nodes
# 检查所有系统 Pod 状态(应该都是 Running)
kubectl get pods --all-namespaces
# 检查集群组件健康状态
kubectl get componentstatuses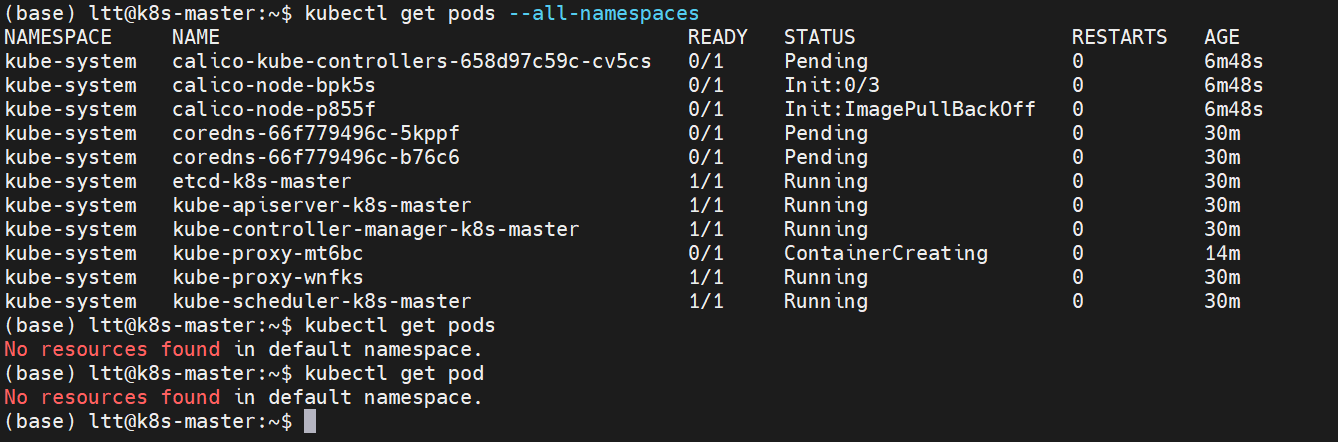
如果节点像上述一样一直没变化:
即
❌ Calico 网络插件启动失败:
calico-node-bpk5s:Init:ImagePullBackOff- 镜像拉取失败
calico-node-p8555f:Pending- 等待调度
calico-kube-controllers:Init:0/3- 初始化卡住❌ 节点网络未就绪:
两个节点都显示
NotReadyCoreDNS 和 kube-proxy 依赖网络,所以也处于异常状态
考虑:
sql
# 检查节点资源是否充足
kubectl describe node k8s-master
kubectl describe node k8s-node
# 查看资源使用情况
kubectl top nodes # 需要 metrics-server
# 查看具体 Pod 的错误详情
kubectl describe pod -n kube-system <problem-pod-name>
# 查看 Pod 日志
kubectl logs -n kube-system <problem-pod-name>
# 检查节点网络配置
ip addr show
route -n
# 检查防火墙
sudo ufw status
# 检查网络插件需要的端口是否开放
netstat -tlnp | grep -E '(6443|2379|2380|10250)'解决:
方案一:重新安装 Calico(推荐)
sql
# 1. 删除当前的 Calico 安装
kubectl delete -f https://docs.projectcalico.org/manifests/calico.yaml
# 2. 等待清理完成
sleep 10
# 3. 使用国内镜像源重新安装 Calico
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.3/manifests/calico.yaml
# 或者使用阿里云镜像源
# kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.3/manifests/calico.yaml方案二:如果 Calico 持续失败,换用 Flannel
sql
# 1. 清理 Calico
kubectl delete -f https://docs.projectcalico.org/manifests/calico.yaml
# 2. 安装 Flannel
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml验证修复结果:
sql
# 检查节点状态(应该变为 Ready)
kubectl get nodes
# 检查所有系统 Pod(应该都是 Running)
kubectl get pods --all-namespaces
# 检查网络插件状态
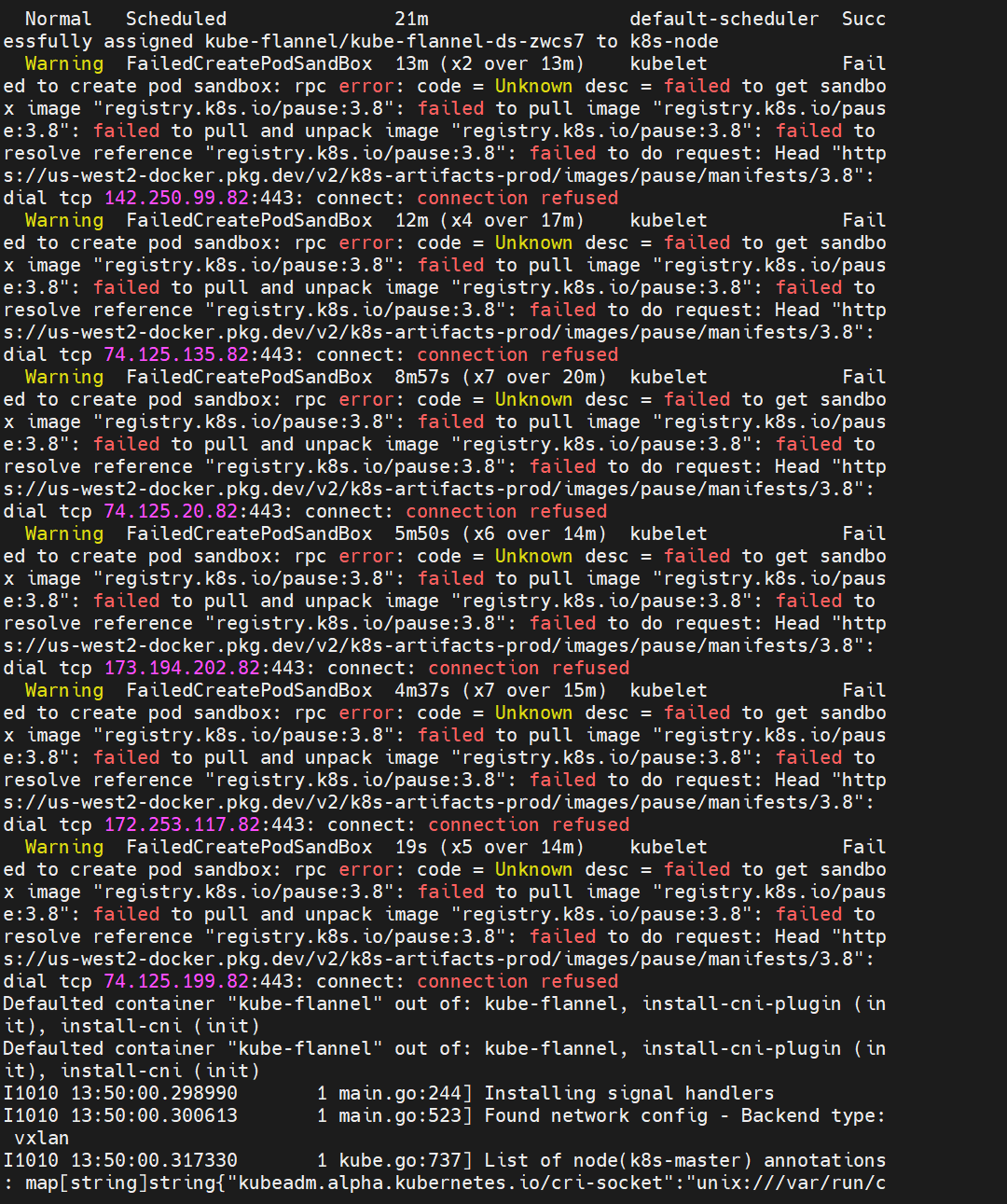
kubectl get pods -n kube-system | grep -E '(flannel|calico)'又遇到了问题:(CNI 插件没有正确初始化。)(心累~)
❌
NetworkReady: false❌
Reason: Network Plugin Not Ready❌
Message: Network plugin returns error: cni plugin not initialized
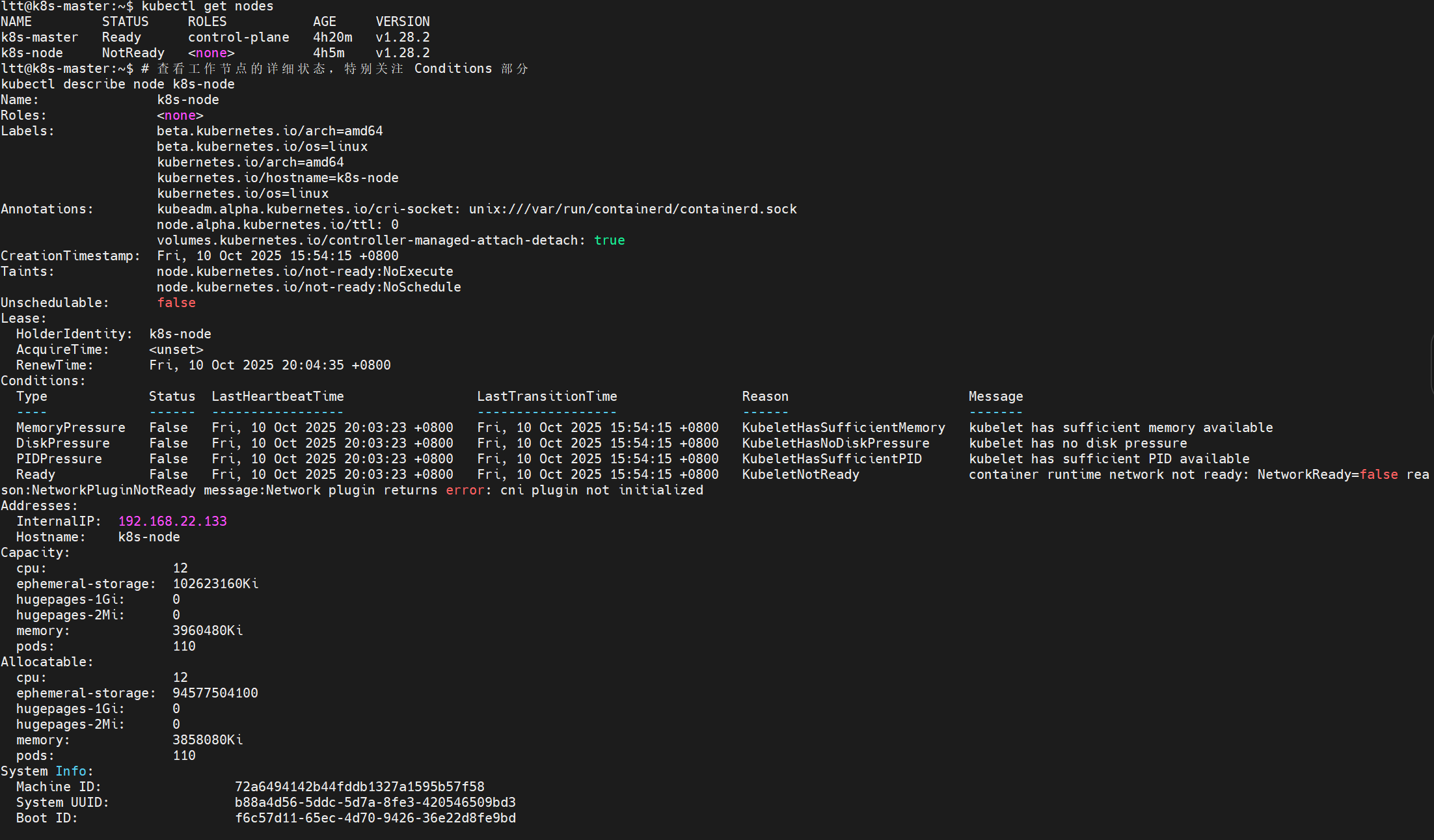
解决:
1.登录到工作节点(k8s-node)执行以下命令:
sql
# 1. 创建 CNI 插件目录
sudo mkdir -p /opt/cni/bin
# 2. 下载并安装 CNI 插件
wget https://github.com/containernetworking/plugins/releases/download/v1.3.0/cni-plugins-linux-amd64-v1.3.0.tgz
# 3. 解压 CNI 插件到系统目录
sudo tar -xzf cni-plugins-linux-amd64-v1.3.0.tgz -C /opt/cni/bin
# 4. 验证安装
ls -la /opt/cni/bin/
# 5. 重启 kubelet 服务
sudo systemctl restart kubelet
# 6. 等待 2-3 分钟让 CNI 插件生效
sleep 120
# 7. 检查 kubelet 状态
sudo systemctl status kubelet- 创建CNI配置文件(k8s-node)
sql
# 创建 CNI 配置目录(如果不存在)
sudo mkdir -p /etc/cni/net.d/
# 创建 Flannel 所需的 CNI 配置文件
sudo tee /etc/cni/net.d/10-flannel.conflist <<'EOF'
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
EOF
# 验证配置文件创建成功
sudo ls -la /etc/cni/net.d/
sudo cat /etc/cni/net.d/10-flannel.conflist3.重启相关 服务以识别新安装的CNI插件
sql
# 重启容器运行时和 kubelet
sudo systemctl restart containerd
sudo systemctl restart kubelet
# 检查服务状态
sudo systemctl status containerd --no-pager -l
sudo systemctl status kubelet --no-pager -l4.在主节点(k8s-master)上检查状态
sql
# 等待 2-3 分钟让配置生效
sleep 120
# 检查节点状态
kubectl get nodes
# 检查 Flannel Pod 状态
kubectl get pods -n kube-flannel -o wide
# 检查系统 Pod 状态
kubectl get pods -n kube-system -o wide
要鼠了