1.中文分词方法
中文分词,即 Chinese Word Segmentation,即将一个汉字序列进行切分,得到一个个单独的词。表面上看,分词其实就是那么回事,但分词效果好不好对信息检索、实验结果还是有很大影响的,同时分词的背后其实是涉及各种各样的算法的。
中文分词与英文分词有很大的不同,对英文而言,一个单词就是一个词,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,需要人为切分。根据其特点,可以把分词算法分为四大类:
基于规则的分词方法
基于统计的分词方法
基于语义的分词方法
基于理解的分词方法1.1 基于规则的分词方法
这种方法又叫作机械分词方法、基于字典的分词方法,它是按照一定的策略将待分析的汉字串与一个"充分大的"机器词典中的词条进行匹配。若在词典中找到某个字符串,则匹配成功。该方法有三个要素,即分词词典、文本扫描顺序和匹配原则。文本的扫描顺序有正向扫描、逆向扫描和双向扫描。匹配原则主要有最大匹配、最小匹配、逐词匹配和最佳匹配。
(1)最大匹配法(MM)。基本思想是:假设自动分词词典中的最长词条所含汉字的个数为 i,则取被处理材料当前字符串序列中的前i个字符作为匹配字段,查找分词词典,若词典中有这样一个i字词,则匹配成功,匹配字段作为一个词被切分出来;若词典中找不到这样的一个i字词,则匹配失败,匹配字段去掉最后一个汉字,剩下的字符作为新的匹配字段,再进行匹配,如此进行下去,直到匹配成功为止。统计结果表明,该方法的错误率为 1/169.
(2)逆向最大匹配法(RMM)。该方法的分词过程与 MM 法相同,不同的是从句子(或文章)末尾开始处理,每次匹配不成功时去掉的是前面的一个汉字。统计结果表明,该方法的错误率为 1/245。
(3)逐词遍历法。把词典中的词按照由长到短递减的顺序逐字搜索整个待处理的材料,一直到把全部的词切分出来为止。不论分词词典多大,被处理的材料多么小,都得把这个分词词典匹配一遍。
(4)设立切分标志法。切分标志有自然和非自然之分。自然切分标志是指文章中出现的非文字符号,如标点符号等;非自然标志是利用词缀和不构成词的词(包 括单音词、复音节词以及象声词等)。设立切分标志法首先收集众多的切分标志,分词时先找出切分标志,把句子切分为一些较短的字段,再用 MM、RMM 或其它的方法进行细加工。这种方法并非真正意义上的分词方法,只是自动分词的一种前处理方式而已,它要额外消耗时间扫描切分标志,增加存储空间存放那些非 自然切分标志。
(5)最佳匹配法(OM)。此法分为正向的最佳匹配法和逆向的最佳匹配法,其出发点是:在词典中按词频的大小顺序排列词条,以求缩短对分词词典的检索时 间,达到最佳效果,从而降低分词的时间复杂度,加快分词速度。实质上,这种方法也不是一种纯粹意义上的分词方法,它只是一种对分词词典的组织方式。OM 法的分词词典每条词的前面必须有指明长度的数据项,所以其空间复杂度有所增加,对提高分词精度没有影响,分词处理的时间复杂度有所降低。
此种方法优点是简单,易于实现。但缺点有很多:匹配速度慢;存在交集型和组合型歧义切分问题;词本身没有一个标准的定义,没有统一标准的词集;不同词典产生的歧义也不同;缺乏自学习的智能性。
1.2 基于统计的分词方法
该方法的主要思想:词是稳定的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。因此字与字相邻出现的概率或频率能较好地反映成词的可信度。可以对训练文本中相邻出现的各个字的组合的频度进行统计,计算它们之间的互现信息。互现信息体现了汉字之间结合关系的紧密程度。当紧密程 度高于某一个阈值时,便可以认为此字组可能构成了一个词。该方法又称为无字典分词。
该方法所应用的主要的统计模型有:N 元文法模型(N-gram)、隐马尔可夫模型(Hiden Markov Model,HMM)、最大熵模型(ME)、条件随机场模型(Conditional Random Fields,CRF)等。
在实际应用中此类分词算法一般是将其与基于词典的分词方法结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
1.3 基于语义的分词方法
语义分词法引入了语义分析,对自然语言自身的语言信息进行更多的处理,如扩充转移网络法、知识分词语义分析法、邻接约束法、综合匹配法、后缀分词法、特征词库法、矩阵约束法、语法分析法等。
(1)扩充转移网络法。该方法以有限状态机概念为基础。有限状态机只能识别正则语言,对有限状态机作的第一次扩充使其具有递归能力,形成递归转移网络 (RTN)。在RTN 中,弧线上的标志不仅可以是终极符(语言中的单词)或非终极符(词类),还可以调用另外的子网络名字分非终极符(如字或字串的成词条件)。这样,计算机在 运行某个子网络时,就可以调用另外的子网络,还可以递归调用。词法扩充转移网络的使用, 使分词处理和语言理解的句法处理阶段交互成为可能,并且有效地解决了汉语分词的歧义。
(2)矩阵约束法。其基本思想是:先建立一个语法约束矩阵和一个语义约束矩阵, 其中元素分别表明具有某词性的词和具有另一词性的词相邻是否符合语法规则, 属于某语义类的词和属于另一词义类的词相邻是否符合逻辑,机器在切分时以之约束分词结果。
1.4 基于理解的分词方法
基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。目前基于理解的分词方法主要有专家系统分词法和神经网络分词法等。
(1)专家系统分词法。从专家系统角度把分词的知识(包括常识性分词知识与消除歧义切分的启发性知识即歧义切分规则)从实现分词过程的推理机中独立出来,使知识库的维护与推理机的实现互不干扰,从而使知识库易于维护和管理。它还具有发现交集歧义字段和多义组合歧义字段的能力和一定的自学习功能。
(2)神经网络分词法。该方法是模拟人脑并行,分布处理和建立数值计算模型工作的。它将分词知识所分散隐式的方法存入神经网络内部,通过自学习和训练修改内部权值,以达到正确的分词结果,最后给出神经网络自动分词结果,如使用 LSTM、GRU 等神经网络模型等。
(3)神经网络专家系统集成式分词法。该方法首先启动神经网络进行分词,当神经网络对新出现的词不能给出准确切分时,激活专家系统进行分析判断,依据知识库进行推理,得出初步分析,并启动学习机制对神经网络进行训练。该方法可以较充分发挥神经网络与专家系统二者优势,进一步提高分词效率。
2.分词工具
我们再介绍几个比较实用的分词 Python 库及它们的使用方法。
2.1 jieba分词
专用于分词的 Python 库,GitHub:https://github.com/fxsjy/jieba
支持三种分词模式:
精确模式,试图将句子最精确地切开,适合文本分析。
全模式,将句子中所有的可能成词的词语都扫描出来,速度非常快,但是不能解决歧义。
搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适用于搜索引擎分词。另外 jieba 支持繁体分词,支持自定义词典。
其使用的算法是基于统计的分词方法,主要有如下几种:
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG);
采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法另外 jieba 还支持词性标注,可以输出分词后每个词的词性。
2.2 SnowNLP
SnowNLP: Simplified Chinese Text Processing,可以方便的处理中文文本内容,是受到了 TextBlob 的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和 TextBlob 不同的是,这里没有用 NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。GitHub地址:https://github.com/isnowfy/snow
另外 SnowNLP 还支持很多功能,例如词性标注(HMM)、情感分析、拼音转换(Trie树)、关键词和摘要生成(TextRank)。
2.3 THULAC
THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,GitHub 链接:https://github.com/thunlp/THULAC-Python,
具有中文分词和词性标注功能。THULAC具有如下几个特点:
能力强。利用集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。
准确率高。该工具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%,与该数据集上最好方法效果相当。
速度较快。同时进行分词和词性标注速度为300KB/s,每秒可处理约15万字。只进行分词速度可达到1.3MB/s。2.4 NLPIR
NLPIR 分词系统,前身为2000年发布的 ICTCLAS 词法分析系统,GitHub 链接:https://github.com/NLPIR-team/NLPIR 是由北京理工大学张华平博士研发的中文分词系统,经过十余年的不断完善,拥有丰富的功能和强大的性能。NLPIR是一整套对原始文本集进行处理和加工的软件,提供了中间件处理效果的可视化展示,也可以作为小规模数据的处理加工工具。主要功能包括:中文分词,词性标注,命名实体识别,用户词典、新词发现与关键词提取等功能。另外对于分词功能,它有 Python 实现的版本,GitHub 链接:https://github.com/tsroten/pynlpir
2.5 NLTK
NLTK,Natural Language Toolkit,是一个自然语言处理的包工具,各种多种 NLP 处理相关功能,GitHub 链接:https://github.com/nltk/nltk。
但是 NLTK 对于中文分词是不支持的
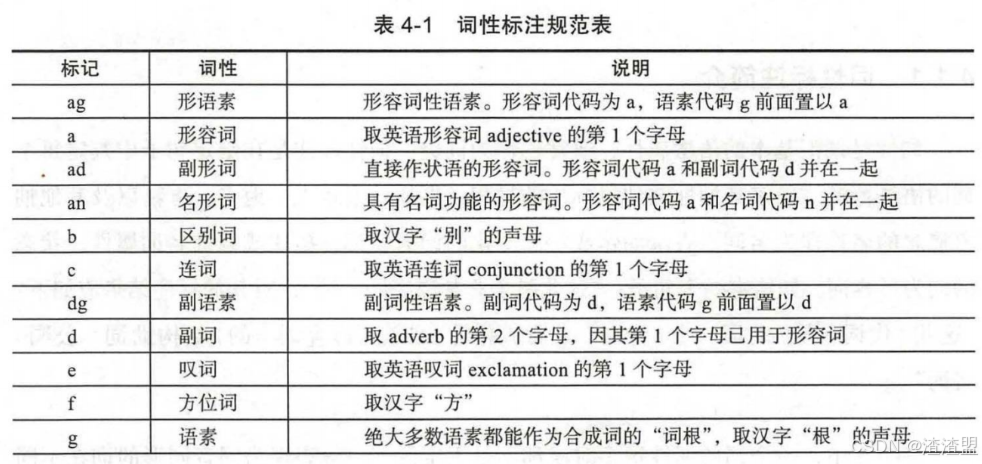
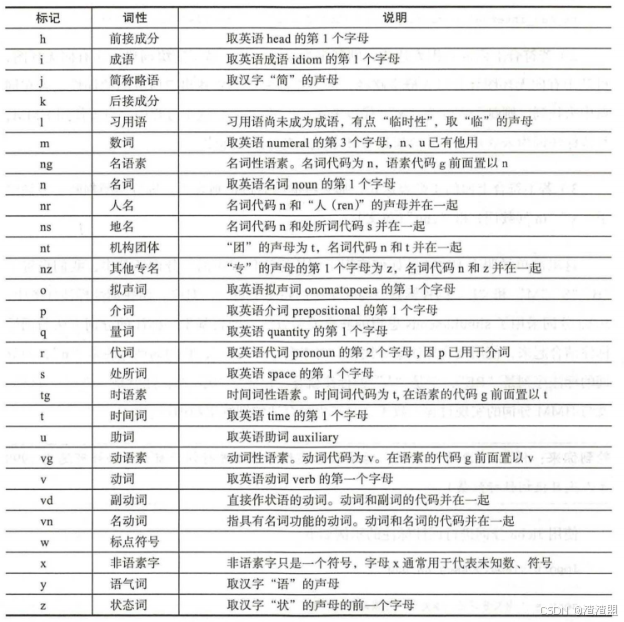
3. 词性标注
词性标注需要有一定的标注规范,如将词分为名词、形容词、动词,然后用"n"、"adj"、"v"等来进行表示。中文领域中尚无统一的标注标准,较为主流的主要为北大的词性标注集和宾州词性标注集两大类。两类标注方式各有千秋,一般我们任选一种方式即可。下表为北大词性标注集的部分内容:
任务实施:
!pip install jieba==0.42.1
1.基于规则的分词方法
基于规则的分词是一种机械分词方法,主要是通过维护词典,在切分语句时,将语句的每个字符串与词表中的词进行逐一-匹配,找到则切分,否则不予切分。按照匹配切分的方式,主要有正向最大匹配法、逆向最大匹配法以及双向最大匹配法三种方法。
#导入字典
def load_dictionary():
dic = set()
# 按行读取字典文件,每行第一个空格之前的字符串提取出来。
for line in open("./data/CoreNatureDictionary.mini.txt","r"):
dic.add(line[0:line.find(' ')])
return dicload_dictionary()
1.1 正向最大匹配
考虑到越长的单词表达的意义越丰富,于是我们定义单词越长优先级越高。具体来说,就是在以某个下标为起点递增查词的过程中,优先输出更长的单词,这种规则被称为最长匹配算法。该下标的扫描顺序如果从前往后则称正向最大匹配,反之则称逆向最大匹配。
正向最大匹配
def forward_segment(text, dic):
word_list = \[\]
i = 0
while i < len(text):
longest_word = texti # 当前扫描位置的单字
for j in range(i + 1, len(text) + 1): # 所有可能的结尾
word = texti:j # 从当前位置到结尾的连续字符串
if word in dic: # 在词典中
if len(word) > len(longest_word): # 并且更长
longest_word = word # 则更优先输出
word_list.append(longest_word) # 输出最长词
i += len(longest_word) # 正向扫描
return word_list
dic = load_dictionary()
print(forward_segment('就读北京大学', dic))
print(forward_segment('研究生命起源', dic))
第二句话就会产生误差了,我们是需要把"研究"提取出来,结果按照正向最长匹配算法就提取出了"研究生",所以人们就想出了逆向最长匹配。
1.2 逆向最大匹配
动手练习1
尝试模仿上述正向最大匹配代码,在<>处填写代码,设计逆向最大匹配算法。
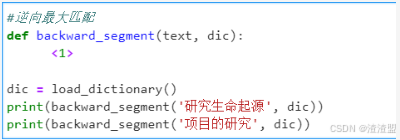
#在这里手敲上面代码并填补缺失代码
若输出为以下内容,说明填写正确。
['研究', '生命', '起源']
['项', '目的', '研究']可以看到输出的内容第一句正确了,但下一句又出错了,可谓拆东墙补西墙。另一些人提出综合两种规则,期待它们取长补短,称为双向最长匹配。
1.3 双向最大匹配
这是一种融合两种匹配方法的复杂规则集,流程如下:
- 同时执行正向和逆向最长匹配,若两者的词数不同,则返回词数更少的那一个。
- 否则,返回两者中单字更少的那一个。当单字数也相同时,优先返回逆向最长匹配的结果。
#双向最大匹配
def count_single_char(word_list: list): # 统计单字成词的个数
return sum(1 for word in word_list if len(word) == 1)
def bidirectional_segment(text, dic):
f = forward_segment(text, dic)
b = backward_segment(text, dic)
if len(f) < len(b): # 词数更少优先级更高
return f
elif len(f) > len(b):
return b
else:
if count_single_char(f) < count_single_char(b): # 单字更少优先级更高
return f
else:
return b # 都相等时逆向匹配优先级更高
print(bidirectional_segment('研究生命起源', dic))
print(bidirectional_segment('项目的研究', dic))
通过以上几种切分算法,我们可以做一个对比:
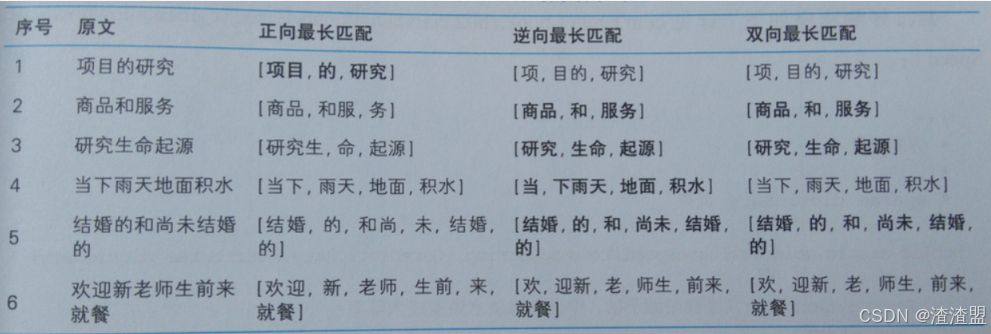
上图显示,双向最长匹配的确在2、3、5这3种情况下选择出了最好的结果,但在4号句子上选择了错误的结果,使得最终正确率 3/6 反而小于逆向最长匹配的 4/6 , 由此,规则系统的脆弱可见一斑。规则集的维护有时是拆东墙补西墙,有时是帮倒忙。
2. jieba分词
事实上,目前不管是基于规则的算法、还是基于HMM、CRF或者deep learning 等的方法,其分词效果在具体任务中,其实差距并没有那么明显。在实际工程应用中,多是基于一种分词算法,然后用其他分词算法加以辅助。最常用的方式就是先基于词典的方式进行分词,然后再用统计分词方法进行辅助。如此,能在保证词典分词准确率的基础上,对未登录词和歧义词有较好的识别,Jieba分词工具便是基于这种方法的实现。
2.1 jieba分词的三种模式
Jieba提供了三种分词模式:
- 精确模式:试图将句子最精确地切开,适合文本分析。
- 全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义。
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
jieba.cut与jieba.cut_for_search的用法:jieba.cut以及jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用for循环来获得分词后得到的每一个词语(unicode)
jieba.cut方法接受三个输入参数:
1.需要分词的字符串
2.cut_all参数用来控制是否采用全模式
3.HMM参数用来控制是否使用 HMM 模型jieba.cut_for_search方法接受两个参数
1.需要分词的字符串
2.是否使用HMM模型。 该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("【全模式】: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("【精确模式】: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print("【新词识别】:" + ", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print("【搜索引擎模式】:" + ", ".join(seg_list))
可以看到,全模式和搜索引擎模式下,Jieba 将会把分词的所有可能都打印出来。一般直接使用精确模式即可,但是在某些模糊匹配场景下,使用全模式或搜索引擎式更适合。
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,"杭研"并没有在词典中,但是也被Viterbi算法识别出来了)
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造2.2 jieba词典使用
添加自定义词典
开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
用法:
jieba.load_userdict(file_name) 参数说明:
file_name:为文件类对象或自定义词典的路径词典格式:
1.一个词占一行;每一行分三部分:
2.词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。
3.file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。例如:
1号店3 n
1號店3n
4S店3n
4s店3n
AA制3 n
AB型3n
AT&T 3 nz
词频省略时使用自动计算的能保证分出该词的词频。
#自定义词典使用
import jieba
#加载系统词典
jieba.set_dictionary('./data/userdict-big.txt')
print('自定义词典内容:')
with open('./data/userdict.txt', 'r') as f:
for l in f:
print(l)
print('------华丽的分割线-------')
sent = 'jieba分词非常好用,可以自定义金融词典!'
seg_list = jieba.cut(sent)
print('加载词典前:', '/ '.join(seg_list))
jieba.load_userdict('./data/userdict.txt')
seg_list = jieba.cut(sent)
print('加载词典后:', '/ '.join(seg_list))
动手练习2
- 打开自定义词典
./data/userdict.txt,并添加jieba分词到词典中; - 尝试模仿上述添加自定义词典代码,在<1>处填写代码,完成加载词典前的分词;
- 尝试模仿上述添加自定义词典代码,在<2>处填写代码,完成加载词典后的分词。

#在这里手敲上面代码并填补缺失代码
若出现以下结果,则说明填写正确。

调整词典
很多时候我们需要针对自己的场景进行分词,会有一些领域内的专有词汇。少量的词汇可以自己用下面方法手动添加:
add_word(word, freq=None, tag=None):添加词汇
del_word(word):删除词汇
suggest_freq(segment, tune=True):可调节单个词语的词频,使其能(或不能)被分出来。注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
下面例子中,jieba分词器认为"中将"是一个名词,切词后将其放到了一起,这是我们就可以利用suggest_freq函数分别调节词频,使得"中"、"将"能够被分别分出来。
import jieba
print("旧字典的结果:" + '/'.join(jieba.cut('如果放到旧字典中将出错。', HMM=False)))
jieba.suggest_freq(('中','将'), True)
print("新字典的结果:" + '/'.join(jieba.cut('如果放到旧字典中将出错。', HMM=False)))
动手练习3
1.在<1>处填写代码,将"人类智能"分为一个词;
2.在<2>处填写代码,删除词汇"人类智能"。
#在这里手敲上面代码并填补缺失代码
若出现以下结果,说明填写正确。
旧字典的结果:人工智能/ 可以/ 生产/ 出/ 一种/ 新/ 的/ 能/ 以/ 人类/ 智能/ 相似/ 的/ 方式/ 做出/ 反应/ 的/ 智能/ 机器/ 。
新字典的结果:人工智能/ 可以/ 生产/ 出/ 一种/ 新/ 的/ 能/ 以/ 人类智能/ 相似/ 的/ 方式/ 做出/ 反应/ 的/ 智能/ 机器/ 。
删除词汇的结果:人工智能/ 可以/ 生产/ 出/ 一种/ 新/ 的/ 能/ 以/ 人类/ 智能/ 相似/ 的/ 方式/ 做出/ 反应/ 的/ 智能/ 机器/ 。3. 停用词
停用词(Stop Words)是自然语言处理领域的一个重要工具,通常被用来提升文本特征的质量,或者降低文本特征的维度。
当我们利用jieba进行中文分词时,只要是句子中出现的词语都会被划分,而有些词语是没有实际意思的,对于后续的关键词提取就会加大工作量,并且可能提取的关键词是无效的。所以在分词处理以后,我们便会引入停用词去优化分词的结果。
对于停用词,我们可以自己手动添加到一个txt文件中,然后在需要时导入文件,也可以利用已经整理好的停用词表,这样就会方便很多。当然,在已有的停用词表基础上,如果我们还有一些词语不需要,也可以自己完善停用词表。
3.1 创建停用词列表
在使用停用词之前,需要加载已经下载好的停用词txt文件,并将其转为列表的格式,以便后续使用。
import jieba
#定义函数创建停用词列表
def stopwordslist(filepath):
stopword = line.strip() for line in open(filepath, 'r').readlines() #以行的形式读取停用词表,同时转换为列表
return stopword
3.2 去除停用词
以下程序实现去除停用词的流程是先加载停用词列表,使用for循环遍历分词后的每一个词语,判断分词后的词语是否不在停用词表内,如果判断为真,即词语不在停用词表内,则添加该词到新列表中。
def cutsentences(sentences, filepath): #定义函数实现分词
print('原句子为:'+ sentences)
cutsentence = jieba.lcut(sentences.strip()) #精确模式
print ('\n'+'分词后:'+ "/ ".join(cutsentence))
stopwords = stopwordslist(filepath) # 这里加载停用词的路径
lastsentences = ''
for word in cutsentence: #for循环遍历分词后的每个词语
if word not in stopwords: #判断分词后的词语是否在停用词表内
if word != '\t':
lastsentences += word
lastsentences += "/ "
print('\n'+'去除停用词后:'+ lastsentences)
filepath= './data/stopwords_cn.txt'
sentences = '万里长城是中国古代劳动人民血汗的结晶和中国古代文化的象征和中华民族的骄傲'
cutsentences(sentences, filepath)
原句子为:万里长城是中国古代劳动人民血汗的结晶和中国古代文化的象征和中华民族的骄傲
分词后:万里长城/ 是/ 中国/ 古代/ 劳动/ 人民/ 血汗/ 的/ 结晶/ 和/ 中国/ 古代/ 文化/ 的/ 象征/ 和/ 中华民族/ 的/ 骄傲
去除停用词后:万里长城/ 中国/ 古代/ 劳动/ 人民/ 血汗/ 结晶/ 中国/ 古代/ 文化/ 象征/ 中华民族/ 骄傲/ 4. 词性标注
词性(词类)是词汇中剧本的语法属性,而词性标注是在给定句子中判定每个词的语法范畴,确定它的词性并加以标注的过程。比如给定句子 "她很漂亮" ,对应的词性标注结果就是 "她/名词 很/副词 漂亮/形容词" ,这就是一个简单的词性标注的例子。
词性标注的方法:词性标注这里基本可以照搬分词的工作,在汉语中,大多数词语只有一个词性,或者出现频次最高的词性远远高于第二位的词性。据说单纯选取最高频词性,就能实现80%准确率的中文词性标注程序。
主要可以分为基于规则和基于统计的方法,下面列举几种统计方法:
(1)基于最大熵的词性标注
(2)基于统计最大概率输出词性
(3)基于HMM的词性标注词性标注的应用:
(1)句法分析预处理
(2)词汇获取预处理
(3)信息抽取预处理jieba中文词性对照表

在上节分词中,我们介绍了Jieba 分词的分词功能,这里将介绍其词性标注功能。类似Jieba分词的分词流程,Jieba的词性标注同样是结合规则和统计的方式,具体为在词性标注的过程中,词典匹配和HMM共同作用。词性标注流程如下。
1)首先基于正则表达式进行汉字判断,正则表达式如下:
re_internal = re.compile("([\u4E00-\u9FD5a-zA-Z0-9+#&\. ]+)")2)若符合上面的正则表达式,则判定为汉字,然后基于前缀词典构建有向无环图,再基于有向无环图计算最大概率路径,同时在前缀词典中找出它所分出的词性,若在词典中未找到,则赋予词性为"x"(代表未知)。当然,若在这个过程中,设置使用HMM,且待标注词为未登录词,则会通过HMM方式进行词性标注。
3)若不符合上面的正则表达式,那么将继续通过正则表达式进行类型判断,分别赋予"x""m"(数词)和"eng"(英文)。
import re
re_internal = re.compile("(\\u4E00-\\u9FD5a-zA-Z0-9+#\&. +)")
引入词性标注接口
import jieba.posseg as psg
text = "我来到北京清华大学"
#词性标注
seg = psg.cut(text)
#将词性标注结果打印出来
for ele in seg:
print(ele)
对照上面的中文词性对照表,可以观察到"我"是代词,"来到"是动词,"北京"是地名,"清华大学"是机构名。
之前我们介绍过,Jieba 分词支持自定义词典,其中的词频和词性可以省略。然而需要注意的是,若在词典中省略词性,那么采用Jieba分词进行词性标注后,最终切分词的词性将变成"x",这在如语法分析或词性统计等场景下会对结果有一定的影响。因此,在使用Jieba分词设置自定义词典时,尽量在词典中补充完整的信息。
动手练习4
1.在<1>处填写代码,载入自定义词典"./data/userdict.txt";
2.在<2>处填写代码,进行词性标注。
#在这里手敲上面代码并填补缺失代码
若出现以下结果,则说明填写正确。

5. 提取高频词
高频词一般是指在文档中出现次数较多且有用的词语,在一定程度上表达了文档的关键词所在;高频词提取中我们主要用到了NLP中的TF策略。
停用词:像 "的"、"了" 这种没有任何意义的词语,我们不需要进行统计。
TF指的是某个词语在文章中出现的总次数,我们将文章进行分词,去掉停用词(包括标点符号),然后取统计每个词在文章中出现的次数即可。
-- coding: utf-8 - -
import glob
import random
import jieba
读取文章的函数
def get_content(content_path):
with open(content_path, 'r', encoding="utf-8", errors="ignore") as f:
content = ''
for i in f:
i = i.strip()
content += i
return content
提取topK个高频词的函数
TF:计算某个词在文章中出现的总次数
def get_TF(k,words):
tf_dic = {}
for i in words:
tf_dici = tf_dic.get(i, 0)+1
return sorted(tf_dic.items(), key=lambda x: x1, reverse=True):k
#获取停用词
def stop_words(path):
with open(path) as f:
return l.strip() for l in f
#cut函数,path是你的停用词表所放的位置
def cut(content,path):
split_words = x for x in jieba.cut(content) if x not in stop_words(path)
return split_words
files ="./data/TFdoc.txt"
corpus = get_content(files)
stopfile = "./data/stopwords.txt"
split_words = cut(corpus, stopfile)
print("top(k)个词为:" + str(get_TF(10, split_words)))
进行高频词提取后的结果为(列出了词频最高的十个词语):
[('治疗', 12),
('病人', 12),
('照射', 12),
('药物', 10),
('肿瘤', 8),
('部位', 6),
('放疗', 5),
('化疗', 5),
('头颈部', 5),
('张频', 4)]