大家好,最近在开发一个 AI 多模态项目时,需要实现 AI 回复内容的语音朗读功能。经过一番摸索和踩坑,终于做出了一个体验还不错的实时语音播放功能 ------ 播放延迟能控制在 0.5-1 秒,用户几乎感觉不到等待。
今天就把这个功能的实现过程分享出来,包括技术选型、核心代码、踩过的坑和优化经验,希望能帮到有类似需求的朋友。
一、技术选型与架构设计
1.1 为什么选火山引擎 的豆包TTS?
做语音合成首先要选合适的 TTS 服务,我对比了几个主流平台后,最终选了火山引擎平台的豆包 TTS,主要原因是它支持 WebSocket 流式传输(这对实时性很重要),而且音质不错、延迟低,文档也写得比较清楚,集成起来没那么费劲。
在调用豆包TTS需要到平台上先开通语音合成模型:
到火山引擎平台,管理页面 开通:console.volcengine.com/ark/region:... 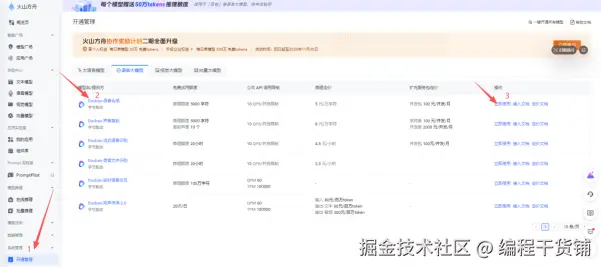
开通后需要到平台上获取认证信息:
获取APP ID 和 Access Token (放入环境变量文件.env) 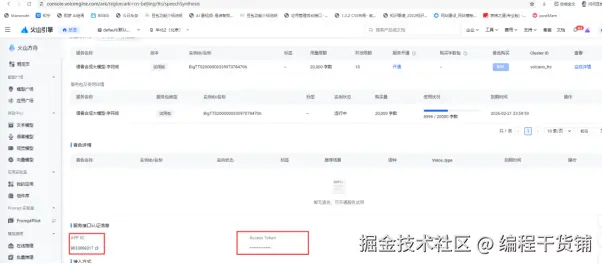
豆包单向流式语音接入文档 :www.volcengine.com/docs/6561/1...
1.2 整体架构设计
整个功能的数据流大概是这样的:
用户点击播放 → 前端调用后端API → 后端连接TTS服务(WebSocket) → 接收音频流 → HTTP流式传输给前端 → 前端Audio元素实时播放
这里有几个关键设计点需要说明:
- 后端做 "中继":为什么不直接让前端连 TTS 的 WebSocket?主要是考虑到 API 密钥安全和跨域问题,后端中转一下更稳妥
- 用 HTML5 Audio:原生就支持流式加载,不用等完整文件下载完就能播,这是低延迟的基础
- 单例管理器:全局统一管理播放状态,避免点了多个消息后音频一起响的尴尬情况
二、后端实现:WebSocket 转 HTTP 流
后端的核心工作是把 TTS 服务的 WebSocket 音频流转换成 HTTP 流式响应,传给前端。
2.1 TTS 协议解析
火山引擎 TTS 用的是自定义二进制协议,帧结构是这样的:
[4字节头部] + [4字节事件类型] + [4字节会话ID长度] + [会话ID] + [4字节数据长度] + [数据内容]
为了处理这个协议,我封装了一个 TTSProtocol 类:
javascript
class TTSProtocol {
constructor() {
// 定义事件类型常量,方便后续判断
this.EVENT_TYPE = {
SESSION_FINISHED: 152, // 会话完成事件
AUDIO_DATA: 352, // 音频数据事件
}
}
// 构建请求帧:把请求参数转换成符合协议的二进制数据
buildRequestFrame(payload) {
// 把请求参数转换成JSON字符串,再转成Buffer
const payloadBuf = Buffer.from(JSON.stringify(payload))
// 协议头:固定格式,根据文档要求填写
const header = Buffer.from([0x11, 0x10, 0x10, 0x00])
// 4字节存储 payload 长度(大端序)
const sizeBuf = Buffer.alloc(4)
sizeBuf.writeUInt32BE(payloadBuf.length, 0)
// 拼接所有部分,形成完整请求帧
return Buffer.concat([header, sizeBuf, payloadBuf])
}
// 解析响应帧:把二进制响应转换成易于处理的对象
parseResponseFrame(frame) {
// 帧长度不足16字节,不符合协议,直接返回null
if (frame.length < 16) {
return null
}
// 读取事件类型(从第4字节开始,4字节长度)
const event = frame.readUInt32BE(4)
// 读取会话ID长度(从第8字节开始,4字节长度)
const sessionIdLen = frame.readUInt32BE(8)
// 计算数据长度的偏移量:12字节(前3个字段) + 会话ID长度
const dataLenOffset = 12 + sessionIdLen
// 读取数据长度(4字节)
const dataLen = frame.readUInt32BE(dataLenOffset)
// 计算音频数据的偏移量:16字节(前4个字段) + 会话ID长度
const dataOffset = 16 + sessionIdLen
// 提取音频数据
const data = frame.slice(dataOffset, dataOffset + dataLen)
return {
event,
isAudio: event === this.EVENT_TYPE.AUDIO_DATA, // 是否为音频数据
isFinished: event === this.EVENT_TYPE.SESSION_FINISHED, // 是否会话结束
data, // 音频数据
}
}
}这里踩了个坑:一开始没注意字节序(大端序 vs 小端序),用了 readUInt32LE(小端序),结果解析出来的事件类型完全不对。后来查文档才发现火山引擎用的是大端序,得用 readUInt32BE 才行,大家集成时也注意下这个细节。
2.2 WebSocket 连接与流式合成
接下来是 TTSService 类,负责和 TTS 服务建立 WebSocket 连接,并处理音频流:
javascript
async synthesize(options, onAudioData, onComplete, onError) {
const { text, speaker, encoding, speed_ratio, volume_ratio } = options
// 建立WebSocket连接,带上认证信息(根据平台要求填写 headers)
const ws = new WebSocket(this.wsUrl, {
headers: {
'X-Api-App-Id': this.appId, // 应用ID
'X-Api-Access-Key': this.accessKey, // 访问密钥
'X-Api-Resource-Id': this.resourceId, // 资源ID
'X-Api-Request-Id': uuidv4(), // 唯一请求ID,用于追踪
},
})
const protocol = new TTSProtocol()
// 连接成功后,发送合成请求
ws.on('open', () => {
// 构建请求参数
const request = {
user: { uid: uuidv4() }, // 用户唯一标识
req_params: {
text: text.trim(), // 需要合成的文本
speaker, // 发音人
audio_params: {
format: encoding, // 音频格式(如mp3)
sample_rate: 24000, // 采样率
speed_ratio, // 语速
volume_ratio, // 音量
},
},
}
// 转换成协议要求的帧格式并发送
const requestFrame = protocol.buildRequestFrame(request)
ws.send(requestFrame)
})
// 接收TTS服务返回的音频流
ws.on('message', (frame) => {
const message = protocol.parseResponseFrame(frame)
if (!message) return
if (message.isAudio) {
// 收到音频数据,通过回调传给外层处理
onAudioData(message.data)
} else if (message.isFinished) {
// 会话结束,关闭WebSocket连接
ws.close()
}
})
// 连接关闭时,触发完成回调
ws.on('close', () => {
onComplete()
})
// 处理错误
ws.on('error', (err) => {
onError({ error: 'WebSocket连接失败: ' + err.message })
})
// 返回控制对象,允许外部中断连接
return { ws, abort: () => ws.close() }
}这个类的核心是通过回调函数把接收到的音频数据实时传递出去,不做任何缓存,这样才能保证低延迟。
2.3 HTTP 流式传输
有了 WebSocket 的音频流,还需要通过 HTTP 流式接口传给前端。用 Express 实现的控制器代码如下:
javascript
async speechSynthesis(req, res) {
// 从请求参数中获取配置
const { text, speaker, encoding = 'mp3', speed_ratio, volume_ratio } = req.query
const ttsService = new TTSService()
// 设置HTTP响应头,关键是声明分块传输
res.setHeader('Content-Type', 'audio/mpeg') // 音频类型
res.setHeader('Transfer-Encoding', 'chunked') // 分块传输
res.setHeader('Cache-Control', 'no-cache, no-store, must-revalidate') // 不缓存
res.setHeader('Accept-Ranges', 'bytes')
let totalSize = 0
// 音频数据回调:收到一块就立即发给前端
const onAudioData = (audioBuffer) => {
res.write(audioBuffer) // 写入响应流
totalSize += audioBuffer.length
}
// 合成完成回调:结束响应
const onComplete = () => {
console.log(`语音合成完成,总大小: ${(totalSize / 1024).toFixed(2)} KB`)
res.end()
}
// 错误处理回调
const onError = (errorInfo) => {
// 如果还没发送响应头,返回错误信息
if (!res.headersSent) {
return res.cc(1, errorInfo.error || '语音合成失败')
}
// 已经发送了部分数据,直接结束响应
res.end()
}
// 开始合成
const connection = await ttsService.synthesize(
{ text, speaker, encoding, speed_ratio, volume_ratio },
onAudioData,
onComplete,
onError
)
// 监听客户端断开连接事件,及时清理资源
req.on('close', () => {
if (connection && connection.abort) {
connection.abort() // 中断TTS连接
}
})
}这里的关键是 Transfer-Encoding: chunked 这个响应头,它告诉浏览器这是分块传输的数据,不需要等完整内容,收到一块就可以处理一块。配合 res.write() 实时写入音频数据,就能实现前端的流式播放了。
另外,监听 req.on('close') 很重要,当用户关闭页面或中断请求时,我们可以及时断开和 TTS 服务的连接,避免资源浪费。
三、前端实现:流式播放与状态管理
前端的核心是实现音频的实时播放,并做好状态管理,让用户体验更流畅。
3.1 全局语音管理器
我设计了一个单例的 aiVoiceManager,统一管理所有语音播放相关的操作:
javascript
class AiVoiceManager {
constructor() {
this.currentItem = null // 当前播放的消息对象
this.isPlaying = false // 是否正在播放
this.isPaused = false // 是否处于暂停状态
this.currentAudio = null // 当前的Audio对象
this.pausedTime = 0 // 暂停时的播放位置(秒)
}
async playVoice(item) {
// 如果点击的是当前正在处理的消息
if (this.currentItem === item) {
if (this.isPlaying) {
this.pauseVoice() // 正在播放 -> 暂停
return
} else if (this.isPaused) {
this.resumeVoice() // 已暂停 -> 继续播放
return
}
}
// 切换到新消息,先停止当前播放
if (this.isPlaying || this.isPaused) {
this.stopVoice()
}
// 更新状态
this.currentItem = item
this.isPlaying = true
// 构建音频流URL
const streamUrl = this.buildStreamUrl(item.content)
// 开始播放
await this.playFromUrl(streamUrl)
}
// 暂停播放
pauseVoice() {
if (this.currentAudio && this.isPlaying) {
this.currentAudio.pause()
this.pausedTime = this.currentAudio.currentTime // 记录暂停位置
this.isPlaying = false
this.isPaused = true
}
}
// 继续播放
resumeVoice() {
if (this.currentAudio && this.isPaused) {
this.currentAudio.currentTime = this.pausedTime // 恢复到暂停位置
this.currentAudio.play()
this.isPlaying = true
this.isPaused = false
}
}
// 停止播放
stopVoice() {
if (this.currentAudio) {
this.currentAudio.pause()
this.currentAudio.src = '' // 清空源,释放资源
this.currentAudio = null
}
this.currentItem = null
this.isPlaying = false
this.isPaused = false
this.pausedTime = 0
}
}单例模式在这里很关键,它能保证同一时间只有一个音频在播放,避免了多个音频重叠的问题。同时统一管理播放状态,让组件之间的状态同步更简单。
3.2 流式播放实现
播放功能的核心是利用 HTML5 的 Audio 元素,配合流式 URL 实现实时播放:
javascript
async playFromUrl(audioUrl) {
return new Promise((resolve, reject) => {
// 创建Audio对象
this.currentAudio = new Audio()
this.currentAudio.preload = 'auto' // 自动预加载,加速播放
this.currentAudio.crossOrigin = 'use-credentials' // 跨域请求携带凭证
this.currentAudio.src = audioUrl // 设置流式音频URL
let playStarted = false
// 播放尝试函数:解决缓冲不足导致的播放失败
const tryPlay = async () => {
if (playStarted) return // 已经开始播放,不再尝试
try {
// 尝试播放
await this.currentAudio.play()
playStarted = true
resolve()
} catch (error) {
// 播放失败(可能是缓冲不足),50ms后重试
setTimeout(tryPlay, 50)
}
}
// 当音频缓冲到可以播放时,立即尝试播放
this.currentAudio.addEventListener('canplay', tryPlay, { once: true })
// 播放结束时,更新状态
this.currentAudio.addEventListener('ended', () => {
this.handlePlayEnd()
}, { once: true })
// 处理播放错误
this.currentAudio.addEventListener('error', () => {
reject(new Error('音频播放失败'))
}, { once: true })
// 开始加载音频
this.currentAudio.load()
})
}
// 播放结束处理
handlePlayEnd() {
this.currentItem = null
this.isPlaying = false
this.isPaused = false
this.pausedTime = 0
this.currentAudio = null
}这里有几个关键的技术点:
canplay事件:当浏览器缓冲了足够的数据可以开始播放时触发,利用这个事件可以在第一时间开始播放,减少等待感- 自动重试机制 :
play()方法可能因为缓冲不足而失败,设置一个短间隔(50ms)自动重试,能显著提升播放成功率 preload="auto":让浏览器自动预加载音频数据,进一步缩短从点击到播放的延迟
3.3 文本预处理
AI 回复的内容经常包含 Markdown 格式(比如代码块、链接、标题等),直接拿去合成语音会很奇怪(比如会读出 "星号星号")。所以需要先做一下预处理:
javascript
preprocessText(text) {
let cleanText = text
// 去除代码块(```包裹的内容)
.replace(/```[\s\S]*?```/g, '')
// 去除行内代码(`包裹的内容),保留文本
.replace(/`([^`]+)`/g, '$1')
// 去除标题标记(#)
.replace(/^#{1,6}\s+/gm, '')
// 去除粗体(**)和斜体(*)标记,保留文本
.replace(/\*\*([^*]+)\*\*/g, '$1')
.replace(/\*([^*]+)\*/g, '$1')
// 去除链接,保留链接文本
.replace(/\[([^\]]+)\]\([^)]+\)/g, '$1')
// 去除图片
.replace(/!\[[^\]]*\]\([^)]+\)/g, '')
// 清理多余空白(多个换行或空格)
.replace(/\n{2,}/g, '\n')
.replace(/\s{2,}/g, ' ')
.trim()
// 限制长度,避免合成过长的音频
if (cleanText.length > 1000) {
cleanText = cleanText.substring(0, 1000) + '...'
}
return cleanText
}这个处理能让合成的语音更自然,用户体验更好。大家可以根据自己的需求调整正则表达式。
3.4 Vue 组件集成
最后把语音播放功能集成到 Vue 组件中(以聊天消息组件为例):
vue
<template>
<div class="message-actions">
<el-icon
@click="toggleVoice"
class="action-icon"
:class="{ playing: voiceStatus === 'playing' }"
:title="getVoiceTitle()">
<VideoPause v-if="voiceStatus === 'playing'" /> <VideoPlay v-else-if="voiceStatus === 'paused'" /> <Microphone v-else /> </el-icon>
</div>
</template>
<script setup>
import { ref, onMounted, onBeforeUnmount } from 'vue'
import aiVoiceManager from '@/utils/aiVoiceManager'
import { VideoPause, VideoPlay, Microphone } from '@element-plus/icons-vue'
// 接收消息对象作为props
const props = defineProps({
message: { type: Object, required: true },
})
// 语音播放状态(idle/playing/paused)
const voiceStatus = ref('idle')
let statusCheckInterval = null
// 更新语音状态
const updateVoiceStatus = () => {
// 从全局管理器获取当前消息的播放状态
voiceStatus.value = aiVoiceManager.getPlayStatus(props.message)
}
// 切换播放状态(点击事件)
const toggleVoice = async () => {
// 调用全局管理器的播放方法
await aiVoiceManager.playVoice(props.message)
updateVoiceStatus()
}
// 获取按钮提示文本
const getVoiceTitle = () => {
switch (voiceStatus.value) {
case 'playing': return '暂停播放'
case 'paused': return '继续播放'
default: return '播放语音'
}
}
// 组件挂载时,启动状态检查定时器
onMounted(() => {
// 每100ms检查一次状态,保证UI和实际状态一致
statusCheckInterval = setInterval(updateVoiceStatus, 100)
})
// 组件卸载时清理
onBeforeUnmount(() => {
// 清除定时器
clearInterval(statusCheckInterval)
// 如果当前消息正在播放,停止播放
if (aiVoiceManager.currentItem === props.message) {
aiVoiceManager.stopVoice()
}
})
</script>
<style scoped>
.action-icon {
cursor: pointer;
font-size: 18px;
margin-left: 8px;
transition: color 0.2s;
}
.action-icon:hover {
color: #409eff;
}
.action-icon.playing {
color: #409eff;
animation: pulse 1.5s infinite;
}
@keyframes pulse {
0% { opacity: 1; }
50% { opacity: 0.6; }
100% { opacity: 1; }
}
</style>这段代码实现了完整的交互逻辑:
- 第一次点击:开始播放,图标变成暂停状态并添加呼吸动画
- 播放中点击:暂停播放,图标变成继续播放
- 暂停时点击:恢复播放,图标变回暂停状态
- 组件卸载时:自动停止播放并清理定时器
通过定时检查状态(100ms 一次),能保证 UI 显示和实际播放状态一致,避免用户 confusion。
四、性能优化与最佳实践
4.1 延迟优化
经过优化,我把从点击到听到声音的延迟控制在了 0.5-1 秒,主要做了这几件事:
- 端到端流式传输:后端收到第一块音频就立即发给前端,不做任何缓冲等待
- Audio 预加载 :设置
preload="auto"让浏览器主动预加载数据 - 尽早播放 :利用
canplay事件,一有足够数据就开始播放,不等完整音频
4.2 用户体验优化
- 断点续播:暂停后继续播放时,能从暂停的位置开始,而不是从头播放
- 状态可视化:用不同图标和动画清晰展示播放状态(未播放 / 播放中 / 暂停)
- 错误处理:播放失败时给出明确提示,比如 "网络不佳,播放失败"
- 操作反馈:点击按钮后有即时反馈(图标变化),让用户知道操作生效了
4.3 资源管理
- 单例模式:全局只有一个音频播放器,避免资源浪费和冲突
- 及时清理:组件卸载、切换播放内容时,及时停止当前播放并释放资源
- 连接中断:用户离开页面或主动停止时,后端能及时断开 TTS 连接
五、踩过的坑与解决方案
分享几个我在开发中遇到的问题和解决方法,希望能帮大家少走弯路:
坑 1:CORS 跨域问题
- 问题:前端 Audio 元素请求后端接口时,出现跨域错误。
- 解决 :
- 后端设置正确的 CORS 响应头(
Access-Control-Allow-Origin、Access-Control-Allow-Credentials等) - 前端 Audio 元素设置
crossOrigin="use-credentials",允许跨域请求携带 Cookie - 确保认证方式兼容跨域场景(我用的是 Cookie+JWT,需要配置 CORS 允许 credentials)
- 后端设置正确的 CORS 响应头(
坑 2:音频播放延迟高
- 问题:最初实现时,用户点击后要等 3-5 秒才能听到声音。
- 原因:后端错误地等待接收完整音频后,才一次性返回给前端。
- 解决 :改成流式传输,收到一块音频数据就立即用
res.write()发给前端,让前端边接收边播放。
坑 3:Audio 自动播放失败
- 问题 :调用
audio.play()时经常失败,报NotAllowedError。 - 原因:现代浏览器有自动播放策略,不允许在没有用户交互的情况下自动播放音频。
- 解决 :
- 确保
play()方法是在用户点击事件中调用的(用户主动操作) - 捕获
play()的错误,设置短间隔自动重试(因为有时是缓冲不足导致的失败)
- 确保
坑 4:音频重叠播放
- 问题:快速点击多个消息的播放按钮,会导致多个音频同时播放。
- 解决:用单例管理器统一管理播放状态,切换播放内容时,先停止当前播放,再开始新的播放。
坑 5:组件卸载后仍播放
- 问题:用户切换页面后,音频还在后台播放。
- 解决 :在组件的
onBeforeUnmount钩子中检查,如果当前组件的消息正在播放,就调用stopVoice()停止。
六、总结与展望
通过这次实践,我对实时语音合成和流式传输有了更深的理解。总结下来,有几个关键点:
- 流式传输是核心:无论是 WebSocket 还是 HTTP 分块传输,流式处理是实现低延迟的基础
- 协议细节要注意:二进制协议的解析容易出错(比如字节序),一定要仔细对照文档
- 用户体验无小事:播放、暂停、状态展示这些细节处理不好,会严重影响用户感受
- 资源管理要重视:及时清理和释放资源,能避免很多难以排查的问题
后续计划优化的方向:
- 增加音频缓存功能,重复内容不用重复合成
- 支持更多语音参数调节(如音调、情感)
- 实现文本分段合成,进一步降低首包延迟
希望这篇文章能帮到有类似需求的朋友,大家如果有更好的实现方式,欢迎在评论区交流~