🍋🍋大数据学习🍋🍋
🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博主哦🤞
GPT系列
GPT 系列(GPT-1→GPT-2→GPT-3)的演进是 "规模扩张→能力涌现→范式革新" 的递进过程,每一代的改进都围绕 "提升模型通用能力" 展开,核心差异体现在模型规模、训练数据、核心能力、技术细节 四个维度。以下是具体对比:
一、GPT-1(2018):Transformer 解码器的首次 "语言建模" 验证
核心定位:
证明 "仅用 Transformer 解码器做语言建模" 的可行性,奠定 "预训练 + 微调" 的基础范式。
关键特点:
-
模型规模:
-
参数:1.17 亿
-
Transformer 层数:12 层,隐藏层维度 768,12 头注意力
-
-
训练数据:
- 仅用BooksCorpus(约 7000 本未出版书籍,共 8 亿 token),数据单一(以故事类文本为主)。
-
核心能力:
-
采用 "预训练(无监督)+ 微调(有监督)" 范式:
-
预训练:通过 "预测下一个 token" 的因果语言模型(CLM)学习通用语言规律;
-
微调:在特定任务(如情感分析、问答)的标注数据上微调,适配具体场景。
-
-
能力局限:仅在 10 个 NLP 任务上验证,性能弱于同期的 BERT(因 BERT 用双向注意力更适合理解任务)。
-
-
技术意义:
首次将 Transformer 解码器用于语言建模,证明 "自回归生成" 的潜力,但受限于规模和数据,通用能力较弱。
二、GPT-2(2019):规模扩张与 "零样本能力" 的突破
核心定位:
通过扩大模型和数据规模,探索 "不微调也能处理新任务" 的零样本(Zero-Shot)能力。
相对于 GPT-1 的改进:
-
模型规模翻倍:
-
参数:15 亿(是 GPT-1 的 13 倍)
-
Transformer 层数:48 层,隐藏层维度 1600,24 头注意力
-
训练优化:采用Pre-Norm(将 LayerNorm 移至残差连接前),解决深层训练的梯度不稳定问题。
-
-
训练数据升级:
-
数据量:从 8 亿 token 增至400 亿 token(50 倍提升);
-
数据多样性:引入 WebText(从 Reddit 高赞链接爬取的网页文本,包含新闻、博客、论坛等),覆盖更广泛的语言场景(如技术文档、对话、代码片段)。
-
-
核心能力革新:
-
放弃 "微调",提出 "零样本学习":通过 "自然语言指令" 让模型理解任务,无需任务特定数据。
例:输入 "Translate English to French: Hello world →",模型直接生成 "Bonjour le monde",无需翻译数据微调。
-
生成能力跃升:能生成更长、更连贯的文本(如小说章节、新闻报道),且逻辑一致性显著提升。
-
-
技术突破:
- 首次证明 "模型规模 + 数据多样性" 可催生 "跨任务迁移能力",为后续 GPT-3 的上下文学习奠定基础。
三、GPT-3(2020):"参数爆炸" 与 "上下文学习" 的涌现
核心定位:
通过超大规模参数和数据,实现 "仅靠提示词(Prompt)就能完成复杂任务" 的通用能力,彻底颠覆 "预训练 + 微调" 范式。
相对于 GPT-2 的改进:
-
模型规模 "指数级扩张":
-
参数:1750 亿(是 GPT-2 的 117 倍)
-
Transformer 层数:96 层,隐藏层维度 12288,96 头注意力
-
计算效率优化:采用稀疏注意力机制(Sparse Transformer),通过局部敏感哈希(LSH)动态选择相关 token 计算注意力,将长文本处理成本从 O (n²) 降至 O (n log n),支持 2048 token 的上下文窗口。
-
-
训练数据 "质与量双升":
-
数据量:45TB 文本(约 1.7 万亿 token,是 GPT-2 的 42 倍);
-
数据来源:混合 BooksCorpus、WebText、维基百科、学术论文等,且通过去重(LSH 算法)和过滤(逻辑回归剔除低质量内容)提升纯净度;
-
领域覆盖:新增代码、数学公式、多语言文本(如法语、西班牙语),减少单一语言偏见。
-
-
核心能力 "范式革命":
-
提出 "上下文学习(In-Context Learning)":通过在提示中加入少量示例(Few-Shot),让模型自动理解任务逻辑,无需参数更新。
例:输入 "2+2=4;3+3=6;5+5=?",模型直接输出 "10",无需数学数据微调。
-
能力边界扩展:从文本生成延伸至代码编写(如生成 Python 函数)、逻辑推理(如解数学题)、多语言翻译等,甚至能模拟简单工具使用(如计算器)。
-
-
应用范式转变:
从 "为每个任务微调模型" 变为 "用提示词适配所有任务",推动 "提示工程(Prompt Engineering)" 成为新的技术方向,降低了大模型的应用门槛。
总结:三代模型的核心演进逻辑
| 维度 | GPT-1(2018) | GPT-2(2019) | GPT-3(2020) |
|---|---|---|---|
| 核心目标 | 验证 Transformer 解码器的可行性 | 探索零样本能力 | 实现通用上下文学习 |
| 参数规模 | 1.17 亿 | 15 亿(×13) | 1750 亿(×117 vs GPT-2) |
| 训练数据 | 8 亿 token(单一书籍) | 400 亿 token(WebText) | 1.7 万亿 token(多源混合) |
| 能力范式 | 预训练 + 微调(任务特定) | 零样本学习(无微调) | 上下文学习(Few-Shot / 提示驱动) |
| 技术突破 | 首次用 Transformer 做自回归生成 | Pre-Norm + 数据多样性提升 | 稀疏注意力 + 能力涌现 |
四、模型参数量与数据量关系
可以用 "大脑神经元(参数)与学习的知识(数据) " 的比喻来理解:参数量是模型 "能记住多少、能理解多复杂规律" 的 "容器大小",训练数据量是 "喂给容器的知识总量"------ 两者必须匹配,否则要么 "容器装不满浪费空间",要么 "知识太多装不下导致混乱",最终都影响模型能力。
参数量的作用:决定 "能学什么复杂度的规律"
参数是模型的 "可调节变量"(类似大脑里的神经元连接),核心作用是存储数据中的语言规律、常识、逻辑:
-
少参数(如 GPT-1 的 1.17 亿):"容器小",只能学简单规律(比如语法、基础词关联,如 "天空" 对应 "蓝色");
-
多参数(如 GPT-3 的 1750 亿):"容器大",能学复杂规律(比如跨句子的逻辑推理、多领域知识关联,如 "下雨→路面湿→容易打滑→开车要减速" 的因果链)。
如果参数太少,就算给再多数据,模型也 "记不住、理不清" 复杂规律 ------ 就像用小 U 盘(少参数)存一部 4K 电影(多数据),根本装不下,只能丢失信息。
训练数据量的作用:决定 "能学多少领域的知识"
训练数据是模型的 "学习素材",核心作用是给模型提供足够多的 "例子",让它从例子中总结规律:
-
少数据(如 GPT-1 的 8 亿 token):"素材少",模型只能学单一领域的浅层知识(比如只学了几千本故事书,就只会写故事,不会处理新闻、代码);
-
多数据(如 GPT-3 的 1.7 万亿 token):"素材多",模型能学跨领域的海量知识(覆盖书籍、新闻、代码、论文,既能写小说也能编代码)。
如果数据太少,就算参数再多,模型也 "没东西可学"------ 就像给一个超大容量的硬盘(多参数)只存几篇短文(少数据),硬盘大部分空间是空的,自然发挥不了作用。
参数量和数据量不是 "越多越好",而是要 "对应量级",否则会出现两种典型问题:
1. 问题 1:参数量 "过剩",数据量 "不足"→ 模型 "学歪"(过拟合)
当 "容器太大,内容太少" 时,模型会把数据里的 "噪声(无用信息)" 当成 "规律" 来学,导致 "只会死记硬背,不会灵活应用":
-
例子:用 GPT-3(1750 亿参数)只训练 10 篇短文(约 1 万 token),模型会把这 10 篇文章背得一字不差,但你让它写一篇新短文,它要么重复背诵内容,要么生成逻辑混乱的句子 ------ 因为它没学过足够多的 "语言规律",只能抓着少量数据里的细节瞎猜。
-
本质:参数多意味着模型 "学习能力强",但数据少的话,这种能力会 "用错地方",把偶然的信息当成必然规律。
2. 问题 2:数据量 "过剩",参数量 "不足"→ 模型 "学不会"(欠拟合)
当 "内容太多,容器太小" 时,模型连数据里的 "核心规律" 都装不下,只能学些皮毛:
-
例子:用 GPT-1(1.17 亿参数)训练 GPT-3 的 1.7 万亿 token 数据,模型最终只会学些简单语法(比如 "主谓宾结构"),但完全无法理解 "代码逻辑""数学推理" 这些复杂知识 ------ 因为它的参数太少,记不下这么多领域的深层规律,就像用小本子记一本百科全书,只能记下几个词条,记不住整体逻辑。
-
本质:数据多意味着 "要学的知识多",但参数少的话,模型 "记忆力不够",无法存储所有知识,只能放弃复杂规律,只学最基础的内容。
ChatGPT:
GPT-3 与 ChatGPT 的核心关系是 "基础模型与应用型产品" ------ChatGPT 早期以 GPT-3 及其迭代版本(如 GPT-3.5)为技术核心,是在 GPT-3 基础上针对 "对话场景" 优化后的应用型产品,而非两个独立的 "竞争模型"。
ChatGPT 的核心原理是 "以 Transformer 为架构基础,通过'预训练 + 多阶段微调'赋予模型对话理解与生成能力,并借助人类反馈持续优化,最终实现符合人类偏好的自然对话"。
一、底层核心:基于 Transformer Decoder 的 "上下文理解架构"
ChatGPT 的基础骨架是 Transformer 模型的 Decoder 部分(仅用解码器,无编码器),这是它能理解上下文、生成连贯文本的核心 ------ 类似 "搭建对话能力的骨架",关键靠两个机制:
- 自注意力机制(Self-Attention):让模型 "读懂上下文关联"
自注意力机制是 Transformer 的核心,能让模型在生成每个词时,自动关注输入文本中 "相关的前后内容",避免 "断章取义"。
比如你问 "北京的气候如何?它适合春天去吗?",模型生成 "适合" 时,会通过自注意力关联前半句的 "北京气候" 和 "春天",判断 "北京春天温暖少雨,适合出行",而不是孤立生成 "适合"。
具体来说:模型会给输入文本的每个词分配 "注意力权重"------ 与当前生成词越相关的词,权重越高,模型会优先参考这些词的语义,从而保证对话的连贯性。
- 预训练(Pre-training):给模型 "通用语言能力"
在针对 "对话" 优化前,模型会先进行大规模 "预训练",类似 "让模型先学会通用语言,再专攻对话":
-
数据来源:海量公开文本(如书籍、网页、文章等,截至特定时间节点,如 GPT-4 预训练数据到 2023 年);
-
训练目标:让模型学会 "预测下一个词"------ 比如给 "今天天气很",模型要预测出 "好""晴朗" 等合理的下一个词;
-
结果:预训练后的模型(如 GPT-3.5/4 基础版)已具备通用的语言理解、生成、推理能力(能写文章、算简单数学、解释概念),但还不擅长 "对话"(比如不会主动追问模糊需求,多轮对话易断联)。
二、关键优化 1:监督微调(SFT)------ 让模型 "学会对话格式"
预训练后的模型像 "会说话但不懂对话规则的人",需要通过 监督微调(Supervised Fine-Tuning,SFT) 教它 "如何对话",类似 "给骨架加上'对话的肌肉'":
- 核心目的:让模型适应 "对话场景"
-
数据准备:人工标注大量 "高质量对话样本"------ 比如 "用户问:'怎么煮米饭?' 助手答:'1. 米和水按 1:1.2 比例放;2. 浸泡 30 分钟;3. 电饭锅煮饭模式......'",还包括 "模糊需求追问"(如用户说 "推荐电影",助手答:"你喜欢喜剧、科幻还是剧情片?");
-
训练过程:把这些对话样本喂给预训练模型,调整模型参数,让它学会 "用户输入→符合对话逻辑的输出" 的映射关系 ------ 比如看到 "推荐电影",不会像预训练时那样直接列电影名单,而是先追问偏好;
-
结果:SFT 后的模型已能进行基本对话,但可能存在 "回答不够优" 的问题(比如推荐的电影不符合主流偏好,或解释太复杂)。
三、关键优化 2:RLHF------ 让模型 "符合人类偏好"
SFT 解决了 "会不会对话",但没解决 "对话好不好"(比如模型可能答得正确但啰嗦,或语气生硬)。ChatGPT 用 基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF) 让模型 "学会说'人话',符合人类喜好",类似 "给肌肉加上'优化的神经'":
RLHF 是 ChatGPT 对话体验好的核心,分 3 步循环进行:
-
第一步:收集人类反馈(Reward Modeling)
让模型对同一个用户问题生成多个不同回答(比如 "怎么学 Python",模型生成 A、B、C 三个回答),再让人类标注者给这些回答 "打分"------ 比如 A 回答 "逻辑清晰,分步骤,适合新手" 打 5 分;B 回答 "太简略,只说'看视频'" 打 2 分;C 回答 "有错误,推荐过时教程" 打 1 分。
用这些 "问题 + 多个回答 + 分数" 训练一个 "奖励模型(Reward Model,RM)",让奖励模型能自动给 "模型回答" 打分(替代人工,提高效率)。
-
第二步:强化学习训练(Policy Optimization)
把 SFT 后的模型作为 "初始策略模型(Policy Model)",让它持续生成回答,再用第一步训练好的 "奖励模型" 给回答打分 ------ 如果回答得分高,就调整模型参数让它 "下次更倾向这么答";如果得分低,就 "惩罚" 模型,让它 "下次避免这么答"。
这个过程类似 "训练宠物:做对了给奖励(多吃一口),做错了给惩罚(不奖励)",模型会逐渐向 "人类偏好的回答" 靠拢(比如更简洁、更易懂、更贴心)。
-
第三步:循环迭代
重复 "生成回答→人类 / 奖励模型打分→强化学习调整" 的过程,不断优化模型 ------ 比如第一次 RLHF 后,模型回答还是有点啰嗦,第二次就重点优化 "简洁性",直到回答符合人类对 "好对话" 的期待(准确、简洁、自然、会追问)。
四、对话能力落地:多轮记忆与安全机制
有了架构和优化,还需要两个 "细节设计" 让对话落地:
- 多轮对话记忆:让模型 "记住之前说的话"
-
原理:ChatGPT 会把 "当前对话的所有历史内容"(用户的每一轮提问 + 模型的每一轮回答)打包成一个 "长输入",一起喂给模型 ------ 比如你先问 "北京有什么景点?",再问 "它们离得远吗?",模型会把 "北京景点列表 +'它们离得远吗'" 一起输入,从而知道 "它们" 指 "北京景点",不会答非所问;
-
限制:模型有 "上下文窗口长度" 限制(如 GPT-3.5 是 4k Token,约 3000 字;GPT-4 Turbo 是 128k Token,约 10 万字),超过长度会 "忘记" 早期对话内容(比如聊了 10 万字后,模型可能记不清开头说的 "喜欢喜剧电影")。
- 安全机制:避免 "有害输出"
-
原理:在预训练、SFT、RLHF 各阶段都加入 "安全过滤"------ 比如预训练时过滤违法、暴力文本;SFT 时不标注有害对话样本;RLHF 时给 "有害回答"(如教犯罪方法)打 0 分,让模型学会 "拒绝回答";
-
效果:当你问 "怎么制作危险物品",模型会回复 "抱歉,我无法提供此类信息",而不是生成有害内容。
强化学习
强化学习(Reinforcement Learning, RL), 又称再励学习、评价学习或增强学习, 是机器学习方法的一种, 用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题.
强化学习的关键信息:
-
一种机器学习方法
-
关注智能体与环境之间的交互
-
目标是追求最大回报
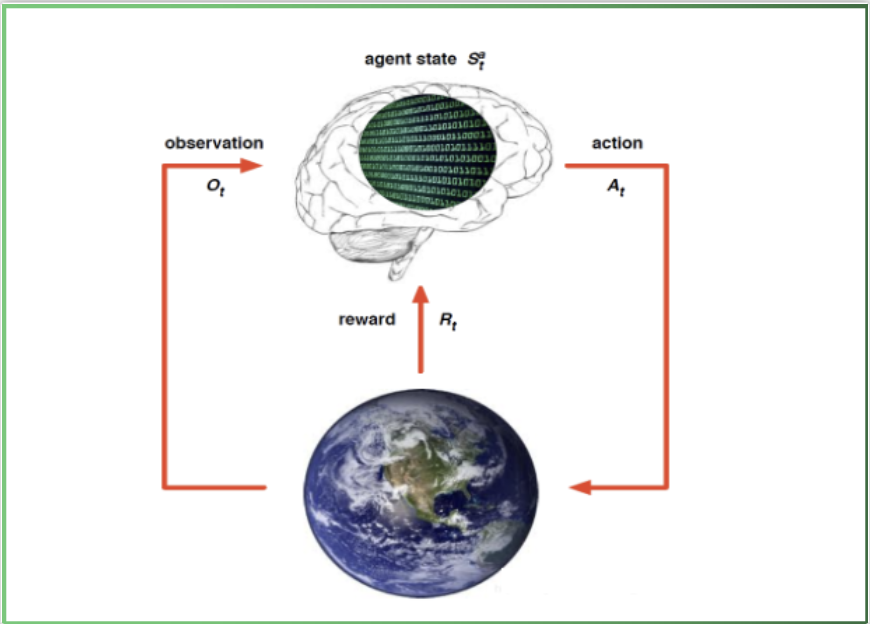
强化学习的架构
- 下图是强化学习的基本流程整体架构, 其中大脑指代智能体agent, 地球指代环境environment, 从当前的状态St出发, 在做出一个行为At 之后, 对环境产生了一些影响, 它首先给agent反馈了一个奖励信号Rt然后给agent反馈一个新的环境状态, 此处用Ot 表示, 进而融汇进入一个新的状态, agent再做出新的行为, 形成一个循环.