最近有一些时间,想尝试下图数据库,看图数据库如何与人工智能相关结合,提供更高质量的语料,与提示词看如何结合,这个其中的第一步。
1、首先还是安装,我这里选择了neo4j,版本为neo4j的desktop,2.0.1。
这个使用中要用power shell,操作系统版本不能太低。
下载地址是这里:
https://neo4j.ac.cn/deployment-center/?desktop-gdb
具体地址:
https://neo4j.com/artifact.php?name=neo4j-desktop-offline-2.0.1-setup.exe
新版本不太好下,我下的是2.0.1
这里下载打开后,要用迅雷下载,不然不太好下。下载好后,安装很简单,能干预的很少,就不说了。
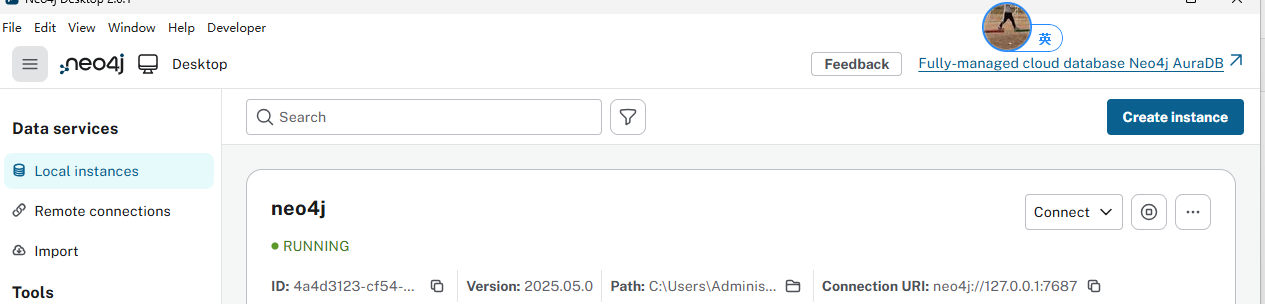
2、打开界面后,创建一个neo4j的实例:
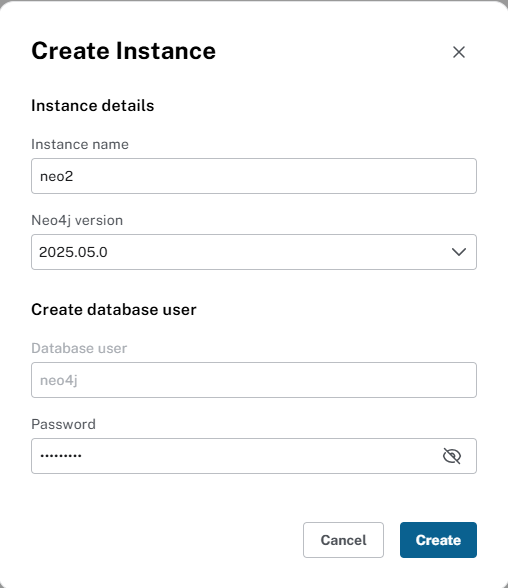
创建完后,就行了,注意这个密码不要忘了,当然忘了也可以重置。
3、写代码,开干。
我用的是neo4j这个扩展。
shell
pip install neo4j -i https://mirrors.ustc.edu.cn/pypi/web/simple/4、具体代码:
bash
# -*- coding: utf-8 -*-
from neo4j import GraphDatabase
import os
import sys
print("开始执行...")
print(sys.stdout.encoding)
# 连接参数
uri = "bolt://localhost:7687"
user = "neo4j"
password = "123123123"
def create_node(driver, label, properties_list, show_progress=True):
"""
创建节点,如果节点已存在则不重复创建
参数:
driver: Neo4j驱动实例
label: 节点标签
properties_list: 节点属性列表
show_progress: 是否显示进度信息
返回:
创建或找到的节点列表
"""
nodes = []
with driver.session() as session:
for properties in properties_list:
# 检查节点是否已存在
check_query = f"MATCH (n:{label} {{name: $name}}) RETURN n"
result = session.run(check_query, name=properties['name']).single()
if result is None:
# 创建新节点
create_query = f"CREATE (n:{label} $props) RETURN n"
node = session.run(create_query, props=properties).single()
nodes.append(node['n'])
else:
# 使用已存在的节点
nodes.append(result['n'])
if show_progress:
print(f"节点{label}处理完成。")
return nodes
def create_relationship(driver, start_node, end_node, relationship_type, show_progress=True):
"""
创建关系,如果关系已存在则不重复创建
参数:
driver: Neo4j驱动实例
start_node: 起始节点
end_node: 结束节点
relationship_type: 关系类型
show_progress: 是否显示进度信息
返回:
布尔值,表示操作是否成功
"""
if start_node and end_node:
with driver.session() as session:
# 检查关系是否已存在
check_query = """
MATCH (a {name: $start_name})-[r:%s]->(b {name: $end_name})
RETURN count(r) as count
""" % relationship_type
result = session.run(check_query, start_name=start_node['name'], end_name=end_node['name']).single()
if result['count'] > 0:
if show_progress:
print(f"关系{start_node['name']}-[:{relationship_type}]->{end_node['name']}已存在,不创建新关系。")
return True
# 创建新关系
create_query = """
MATCH (a {name: $start_name}), (b {name: $end_name})
CREATE (a)-[:%s]->(b)
RETURN a, b
""" % relationship_type
session.run(create_query, start_name=start_node['name'], end_name=end_node['name'])
if show_progress:
print(f"关系{start_node['name']}和{end_node['name']}已创建。")
return True
else:
if show_progress:
print(f"创建关系失败,{start_node['name'] if start_node else '节点'}或{end_node['name'] if end_node else '节点'}不存在。")
return False
def query_relationship(driver, start_node, end_node, relationship_type):
"""
查询指定的关系
参数:
driver: Neo4j驱动实例
start_node: 起始节点
end_node: 结束节点
relationship_type: 关系类型
返回:
查询结果
"""
if start_node and end_node:
with driver.session() as session:
query = """
MATCH (a {name: $start_name})-[r:%s]->(b {name: $end_name})
RETURN a, r, b
""" % relationship_type
results = session.run(query, start_name=start_node['name'], end_name=end_node['name'])
found = False
for record in results:
found = True
print(record["a"]["name"], "knows", record["b"]["name"])
if not found:
print(f"未找到{start_node['name']}和{end_node['name']}之间的{relationship_type}关系。")
# 重新执行查询以返回结果集
return session.run(query, start_name=start_node['name'], end_name=end_node['name'])
# 主程序
if __name__ == "__main__":
driver = None
try:
# 连接数据库
driver = GraphDatabase.driver(uri, auth=(user, password))
print("成功连接到Neo4j数据库!")
# 创建节点
alice = create_node(driver, "Person", [{"name": "Alice"}])
bob = create_node(driver, "Person", [{"name": "Bob"}])
# 创建关系(测试重复创建)
create_relationship(driver, alice[0], bob[0], "KNOWS")
create_relationship(driver, alice[0], bob[0], "KNOWS") # 尝试重复创建,应该被检测到
# 查询关系
print("\n查询关系结果:")
results = query_relationship(driver, alice[0], bob[0], "KNOWS")
print("\n操作完成!")
except Exception as e:
print(f"发生错误:{e}")
finally:
# 确保关闭驱动连接
if driver:
driver.close()
print("数据库连接已关闭。")5、常用的neo4j的命令:
删除节点关系,类型为KNOWS
cypher
MATCH (a)-[r:KNOWS]->(b)删除节点关系,类型为KNOWS
cypher
MATCH (a)-[r:KNOWS]->(b)
DELETE r删除节点,类型为Person
cypher
MATCH (n:Person)
DELETE n删除所有节点:
cypher
MATCH (n)
DELETE n查询所有节点,类型为Person,返回节点的name属性,以及节点的id属性,限制返回25条记录
cypher
MATCH (n:Person) RETURN n.name, n.id LIMIT 25;创建节点,类型为Person,属性为name和id
cypher
CREATE (n:Person {name: "张三", id: 123456})创建关系,类型为KNOWS,关系两端的节点为n1和n2
cypher
MATCH (n1:Person {name: "张三"}), (n2:Person {name: "Bob"})
CREATE (n1)-[:KNOWS]->(n2)删除关系,通过指定关系类型和关系id
cypher
MATCH ()-[r:KNOWS]->()
WHERE r.id = 123456
DELETE r查看所有关系的id
cypher
MATCH ()-[r:KNOWS]-() RETURN r,elementId(r) limit 1;通过关系的ID的查询关系
cypher
MATCH ()-[r:KNOWS]->()
WHERE elementId(r) = '5:5ed65e88-85a1-43cb-9932-77b78a4c8ec8:1157425104234217504' return r ;通过关系的ID删除关系
cypher
MATCH ()-[r:KNOWS]->()
WHERE elementId(r) = '5:5ed65e88-85a1-43cb-9932-77b78a4c8ec8:1157425104234217504'
DELETE r6、乱码问题:
哪里都不避开这个乱码问题。。。
win11中,执行如果乱码,一定检查控制面板中,是否启用了utf-8的支持,位置:控制面板-区域-管理-更改系统区域设置-勾选:Beta版:使用Unicode UTF-8提供全球语言支持
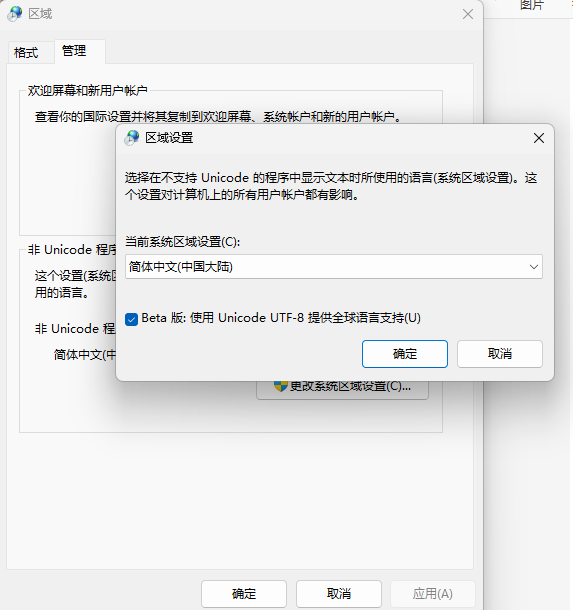
代码中:
第一行别忘了:
bash
# -*- coding: utf-8 -*-具体vscode中的扩展啥的也都不说了。。。