读完感觉文章的贡献:
-
开源:此前开源的模型效果明显落后闭源的
-
三阶段训练方案
-
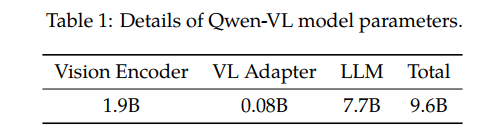
网络架构: ViT+VL Adapter + LLM
-
Qwen-VLs are a series of highly performant and versatile vision-language foundationmodels based on Qwen-7B (Qwen, 2023) language model.
We empower the LLM basement with visualcapacity by introducing a new visual receptor including a language-aligned visual encoder and a position-aware adapter.
一些有趣的点:
- 文章说用的是QWen-7B的中间版本,不是最终版本,原因是QWen-7B和QWen-VL是几乎同步研发的,哈哈哈,好现实的原因
一些疑问:
- 不同任务有不同数据,怎么决定这些数据训练的顺序?随机打乱?竟然还有纯文本数据,纯文本只训练Qwen-7B?
个人感觉不足的地方:
对于方法的介绍部分比较少,以及对于网络框架为什么这么设计的说明。不过可能文章本身定位也是technical report?
一些训练细节:
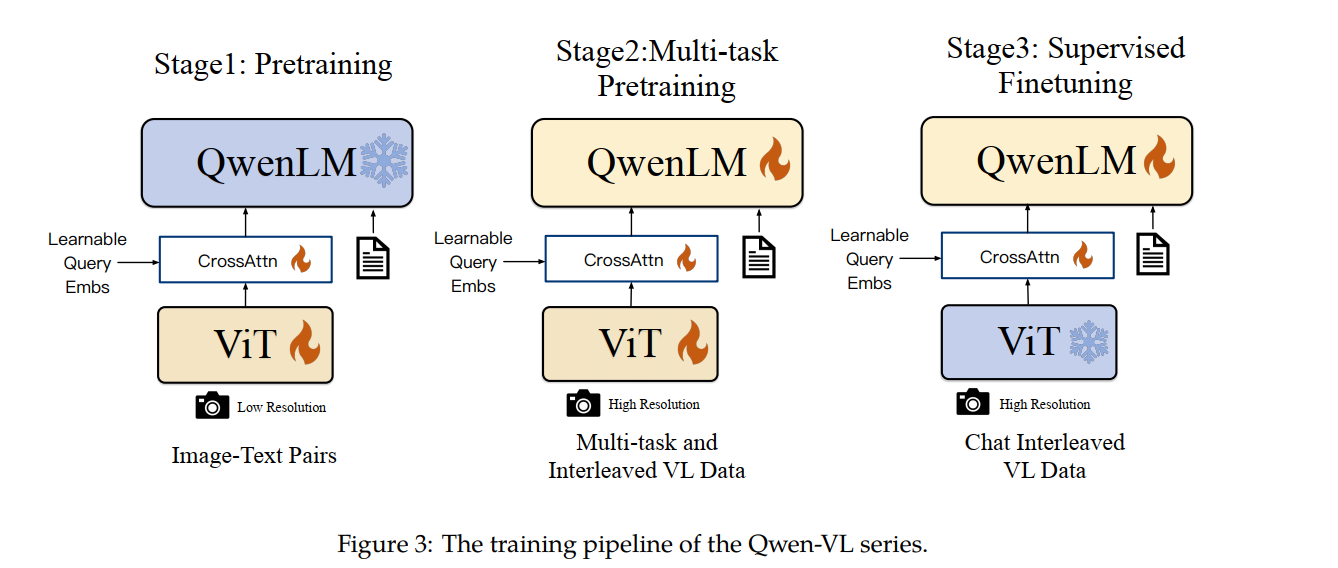
一共分为三个训练阶段,如下图所示,火代表参数可更新,冰代表冷冻住了不可更新。
第一个阶段-预训练:训练损失函数是生成的文本的交叉熵,本质是一个图生文任务感觉不直接训练三个模块是为了降低训练难度?QwenLM里面7B的参数是不动的,这样只需要训剩下的1.98B
第二个阶段-多任务预训练:训练损失函数还是生成的文本的交叉熵,和第一阶段很像。区别在于把QWen-7B解冻了,也会去训练。还有就是数据不一样。数据中还有纯文本数据。感觉是为了让ViT和Qwen-7B融合得更好
第三个阶段-微调:为了让模型有更好的指令跟随能力和推理能力。这里把ViT冻住了。没说损失函数。这里会用强化学习吗?这里叫微调感觉主要是数据量少(350k),且模型已经具备一定能力,这里是让输出更符合人的习惯。和前面两个阶段还有一个很大不同的是,数据格式不一样,会加上图片标识,且计算损失函数时候不会把人提问的内容加进去(前面两个阶段没有人提问的prompt)
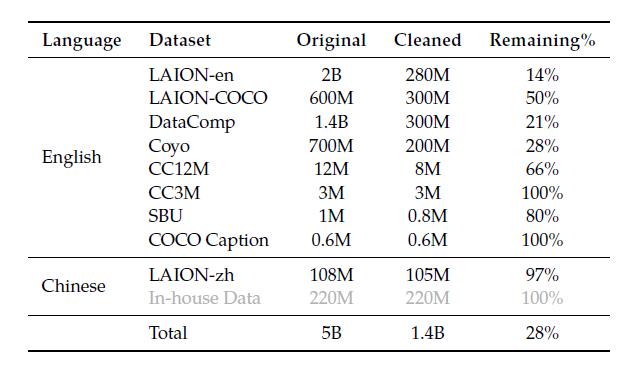
- 第一阶段预训练数据量:公开数据及+爬下来的图+内部数据50亿张图,清洗后保留到14亿张
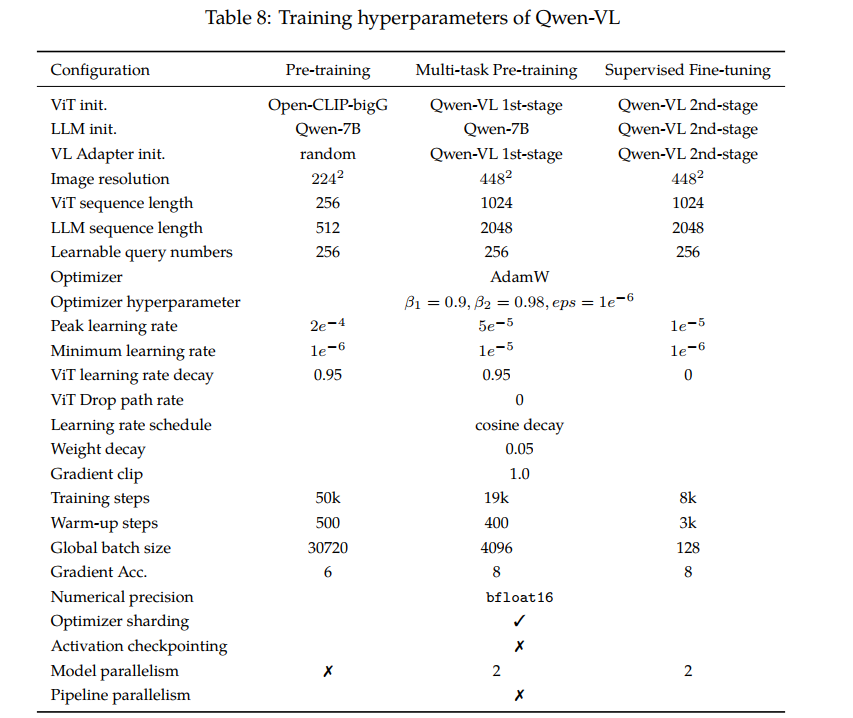
第一阶段训练超参:
图像被下采样成224*224的图片。
训练时batch_size是30720=3×5x2^11,step是50,000,乘起来恰好是15亿左右(15.36亿)
2第二阶段多任务预训练
数据量。不同任务有不同数据,怎么决定这些数量的顺序?随机打乱?竟然还有纯文本数据,纯文本只训练Qwen-7B?
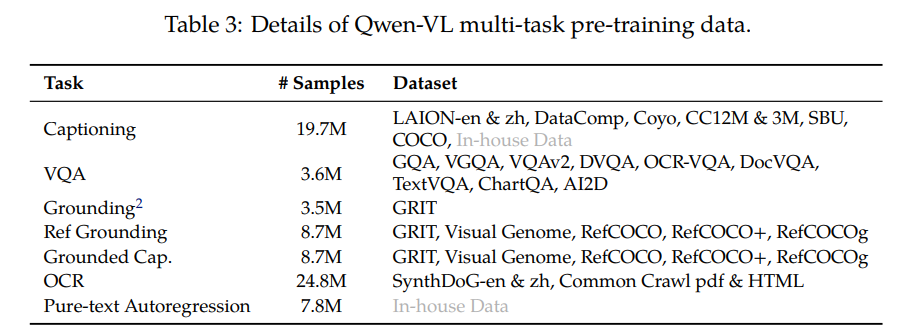
这里图片的大小变成448*448。并且为了降低模型数据量,附件3说采用了window attention。window attention会改变网络结构吗?感觉并没有采用window attention吧
- 第三阶段数据集
