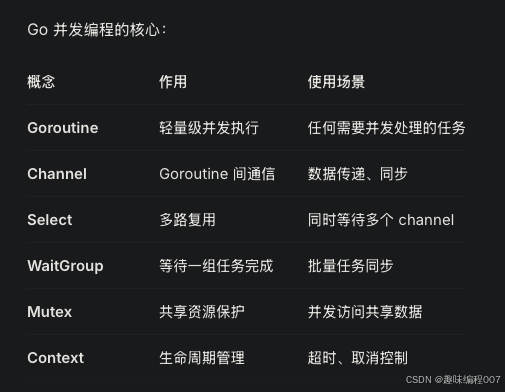
Go 语言的并发编程是其最强大的特性之一,它通过 goroutine 和 channel 提供了一种优雅且高效的并发模型。
Channel 和 Goroutine 是不同的概念
Goroutine:是 Go 的轻量级线程,是执行代码的实体
Channel:是 goroutine 之间的通信管道,是数据传输的通道
好比Goroutine = 工人(执行工作的实体)
Channel = 传送带(在工人之间传递物料)
有Goroutine不一定有Channel,
Channel 的典型用途是在多 goroutine 间通信
关键优势:
✅ 高性能:轻量级,可创建大量 goroutine
✅ 安全:通过通信共享内存,而非通过共享内存进行通信
✅ 灵活:多种并发模式可选
Go 的并发模型让编写高并发程序变得简单而安全,这是 Go 在云计算、网络服务等领域如此受欢迎的重要原因!
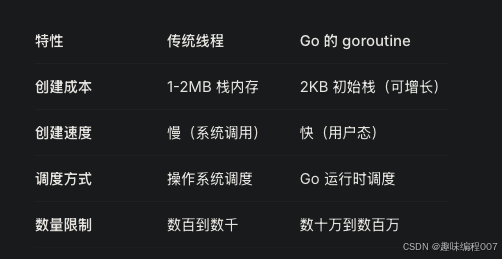
与传统的线程对比:
Goroutine - 轻量级线程
Goroutine 是 Go 语言的并发执行单元,你可以把它理解为超级轻量级的线程,传统线程 ≈ 重型卡车(载重大但耗油、速度慢、数量有限)
Goroutine ≈ 电动自行车(轻便、灵活、数量庞大、效率高)
(1),启动
// 使用 go 关键字启动 goroutine(并发执行)
go sayHello() // 在新的 goroutine 中运行
go + 方法,即可启动,很简洁
轻松创建大量 Goroutine,传统线程创建 太多个线程 - 很可能程序会崩溃或系统卡死
(2),Channel - Goroutine 间的通信
channel 分为无缓冲 channel 和带缓冲 channel
ch := make(chan int) // 无缓冲
// 等价于
ch := make(chan int, 0) // 明确指定缓冲大小为 0
区别:
// 无缓冲:发送-接收-发送-接收(交替进行)
// 有缓冲:发送-发送-发送... 接收-接收-接收...(批量操作)
接收方可以按自己的节奏接收
// 即使瞬间收到大量请求,也能先缓冲起来
// 然后工作goroutine按处理能力慢慢消费
缓冲的作用:让生产者不用等待消费者,可以连续生产
《1》无缓冲加同步的举例子
1,同步机制
// 等待任务完成
func worker(done chan bool) {
fmt.Println("working...")
time.Sleep(time.Second)
done <- true // 发送完成信号
}
func main() {
done := make(chan bool)
go worker(done)
<-done // 等待 worker 完成
fmt.Println("done")
}
1 done 是一个布尔类型的通道(channel)
1. <- 是 Go 语言中的通道发送操作符
2. done <- true 表示向 done 通道发送一个 true 值
<-done 表示从 done 通道中接收一个值,会阻塞外面的线程
同步机制:
* <-done 相当于在说:"我在这里等着,你完成工作后通知我"
1. ◦ done <- true 相当于在说:"我的工作完成了,通知等待的人"
没有
<-done 会导致死锁《2》有缓冲的举例子
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int, 2) // 缓冲大小为 2
// 发送方
go func() {
for i := 0; i < 4; i++ {
fmt.Printf("发送 %d\n", i)
ch <- i // 前两个不会阻塞,第三个会阻塞
fmt.Printf("发送完成 %d\n", i)
}
close(ch)
}()
time.Sleep(3 * time.Second) // 让发送方先发送一些数据
// 接收方
for i := range ch {
fmt.Printf("接收到: %d\n", i)
time.Sleep(1 * time.Second)
}
}
前2个不会阻塞,后面的会
当缓冲空且通道关闭时,range 循环会自动结束
如果没有 close(ch):
* 接收方的 for i := range ch 会一直等待新数据
* 即使所有数据都已接收完毕,循环也不会结束
* 最终导致 死锁,程序报错:(3)单向 Channel:
其实就是让通道,更加明确,安全,设计清晰
在 Go 语言中,单向 Channel 是对 Channel 使用方向的限制,用于在函数参数或返回值中明确指定 Channel 是只用于发送还是只用于接收。
两种类型的单向 Channel
- 只发送 Channel (chan<- T)
只能向这个 Channel 发送数据,不能从它接收数据。- 只接收 Channel (<-chan T)
只能从这个 Channel 接收数据,不能向它发送数据。
T应该是泛型的意思
作用与举例子
1. 提高代码安全性
// 明确的接口约束,防止误用
func ProcessData(input <-chan Data, output chan<- Result) {
for data := range input { // 只能从 input 读
result := compute(data)
output <- result // 只能向 output 写
}
close(output)
}
2. 更好的 API 设计
// 对外提供只读的数据流
func StartSensor() <-chan SensorData {
dataCh := make(chan SensorData)
go func() {
for {
data := readSensor()
dataCh <- data
time.Sleep(time.Second)
}
}()
return dataCh // 返回只读 channel
}
// 使用者只能读取数据,不能干扰传感器工作
func main() {
sensorData := StartSensor()
for data := range sensorData {
fmt.Printf("温度: %.2f\n", data.Temperature)
}
}
3. 管道模式 (Pipeline)
// 每个阶段都有明确的输入输出方向
func stage1(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * 2
}
close(out)
}()
return out
}
func stage2(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n + 1
}
close(out)
}()
return out
}
func main() {
// 创建输入
input := make(chan int)
go func() {
for i := 0; i < 5; i++ {
input <- i
}
close(input)
}()
// 构建管道
result := stage2(stage1(input))
// 消费结果
for r := range result {
fmt.Println(r) // 输出: 1, 3, 5, 7, 9
}
}二,实际并发模式
(1). Worker Pool(工作池),属于是进一步优化性能了
工作池(Worker Pool)模式是 Go 中一种常见的并发模式,它使用固定数量的 goroutine(工作者)来处理任务队列中的任务。这种模式可以有效控制资源使用,避免创建过多的 goroutine。
package main
import (
"fmt"
"time"
)
// 任务结构
type Task struct {
ID int
Data string
}
// 结果结构
type Result struct {
TaskID int
Output string
WorkerID int
}
// 工作者函数
func worker(id int, tasks <-chan Task, results chan<- Result) {
// 从tasks channel接收任务
for task := range tasks {
fmt.Printf("Worker %d 开始处理任务 %d\n", id, task.ID)
// 模拟处理时间
time.Sleep(2 * time.Second)
// 处理任务
output := fmt.Sprintf("处理后的: %s", task.Data)
// // 向results channel发送结果
results <- Result{
TaskID: task.ID,
Output: output,
WorkerID: id,
}
fmt.Printf("Worker %d 完成任务 %d\n", id, task.ID)
}
}
func main() {
// 创建任务和结果通道
//缓冲容量:10个Task
通道类型:传输Task结构体
// 只创建了1个通道
tasks := make(chan Task, 10)
results := make(chan Result, 10)
// 创建工作者池(但是创建了3个worker,都共享这同一个通道)
// 将两个channel传递给worker函数
for i := 1; i <= 3; i++ {
go worker(i, tasks, results)
}
// 向tasks channel发送任务
for i := 1; i <= 10; i++ {
tasks <- Task{
ID: i,
Data: fmt.Sprintf("任务数据 %d", i),
}
}
close(tasks) // 关闭任务通道,表示没有更多任务
// 收集结果
for i := 1; i <= 10; i++ {
result := <-results
fmt.Printf("收到结果: 任务 %d, 工作者 %d, 输出: %s\n",
result.TaskID, result.WorkerID, result.Output)
}
}这里有几个理解点,
《1》tasks := make(chan Task, 10)
10缓冲就是说可以容纳10个任务量,因为一般来讲线程最终是要明确拿结果的,而且不希望卡线程,所以其实一般用有缓冲的channel比无缓冲的要普遍,
《2》写法解耦特别强
先worker,后面再把任务传进去,而不是先把任务实例好,后面再传进去worker,就好比,原本,先有顾客(任务),再有服务员,现在是先有服务员,再有顾客,据说这样处理会快一点,果然大自然才是最好的老师,这设计都能类比到,也是牛
-
Fan-out, Fan-in(扇出扇入)
-
多路复用(Select)
三,同步原语
. WaitGroup(等待组)
-
Mutex(互斥锁)
-
上下文(Context)
四,最佳实践与陷阱
-
避免 Goroutine 泄漏
-
Channel 使用原则
五,性能考虑
Goroutine 数量控制:
六,注意事项
- 主 Goroutine 退出问题
func main() {
go func() {
time.Sleep(time.Second)
fmt.Println("这个可能不会执行!")
}()
// 主 goroutine 立即退出,不会等待上面的 goroutine
fmt.Println("主程序退出")
// 程序结束,上面的 goroutine 被强制终止}
解决方法:使用同步机制
func main() {
var wg sync.WaitGroup
wg.Add(1) // 计数 +1
go func() {
defer wg.Done() // 完成时计数 -1
time.Sleep(time.Second)
fmt.Println("这个一定会执行!")
}()
wg.Wait() // 等待计数为 0
fmt.Println("主程序退出")}
2,闭包变量捕获问题func main() {
for i := 0; i < 3; i++ {
// 错误:所有 goroutine 可能都看到 i=3
go func() {
fmt.Println(i) // 可能输出 3, 3, 3
}()
}
time.Sleep(time.Second)
// 正确:传递参数
for i := 0; i < 3; i++ {
go func(id int) {
fmt.Println(id) // 输出 0, 1, 2
}(i)
}
time.Sleep(time.Second)}
七,调试 Goroutine
查看 Goroutine 信息:func main() {
// 查看当前 goroutine 数量
fmt.Println("当前 goroutine 数量:", runtime.NumGoroutine())
// 获取当前 goroutine 的 ID
fmt.Printf("当前 goroutine ID: %p\n", runtime.Getgoroutineid())
// 让出 CPU 时间片
runtime.Gosched()}