文章目录
-
-
- 1.搭建基础的springboot项目环境(依赖,启动类,端口)
- 2.引入大模型API学会基本使用
- 3.人工智能服务AIService
-
- [3.1 如何使用AIService](#3.1 如何使用AIService)
- [3.2 AIService实现聊天记忆](#3.2 AIService实现聊天记忆)
- 4.实现聊天记忆隔离
- 5.持久化聊天记忆
- [5.1 初步使用](#5.1 初步使用)
-
- [5.2 具体使用](#5.2 具体使用)
- 6.系统提示词
-
- [6.1 用户提示词](#6.1 用户提示词)
- 7.项目实战agent
- [8.function calling学习了解](#8.function calling学习了解)
- [9.项目实战agent+function calling实现](#9.项目实战agent+function calling实现)
-
- [9.1 创建数据库预约表及增删改查操作](#9.1 创建数据库预约表及增删改查操作)
- [9.2 实现Function calling](#9.2 实现Function calling)
- 10.检索增强RAG+项目
-
- [10.1 使用pipecone进行向量存储](#10.1 使用pipecone进行向量存储)
- 11.总结
-
1.搭建基础的springboot项目环境(依赖,启动类,端口)
2.引入大模型API学会基本使用
1.引入langchain4j的maven依赖(不同的大模型对应不同的依赖)
2.大模型的配置信息填写
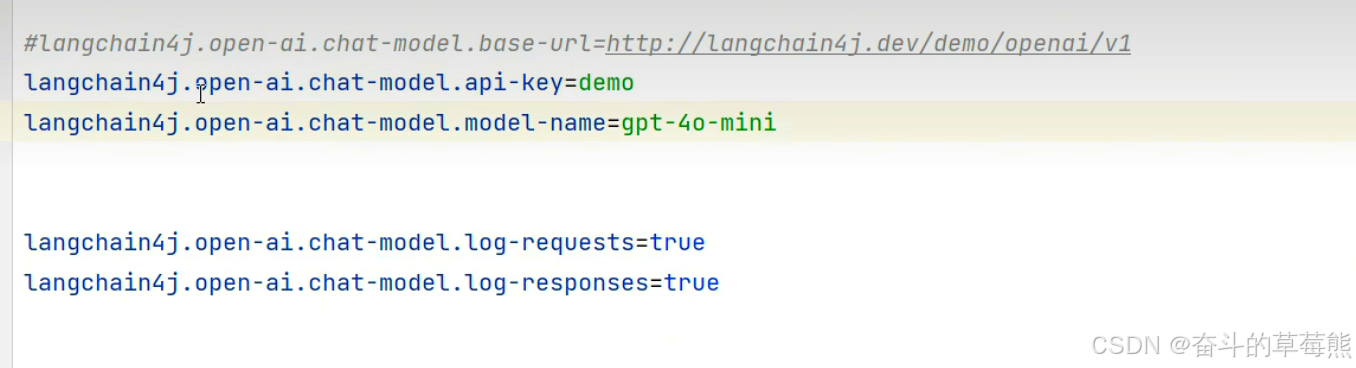
注意:如果是接入其他大模型,需要自己百度查找如何配置上述的这些信息
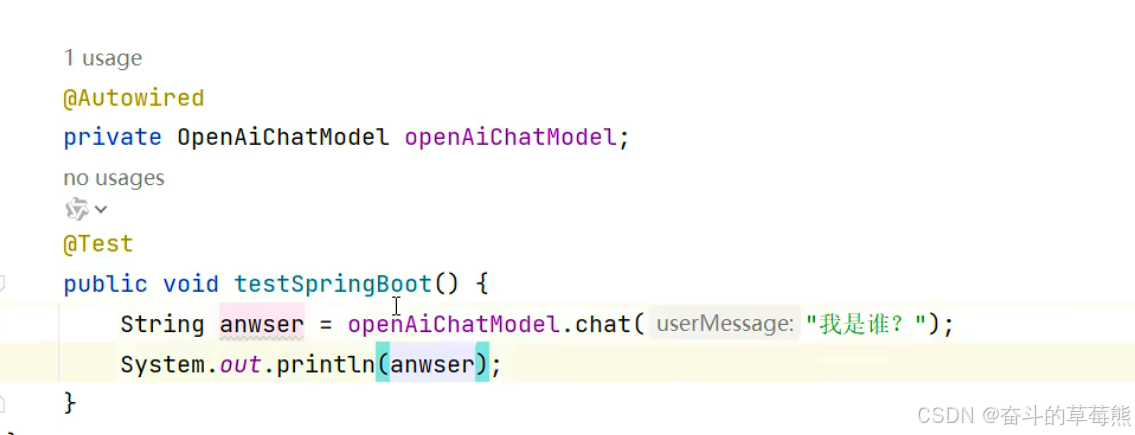
3.测试
3.人工智能服务AIService
使用面向接口和动态代理的方式代理用户的输入输出
主要实现增强功能
3.1 如何使用AIService
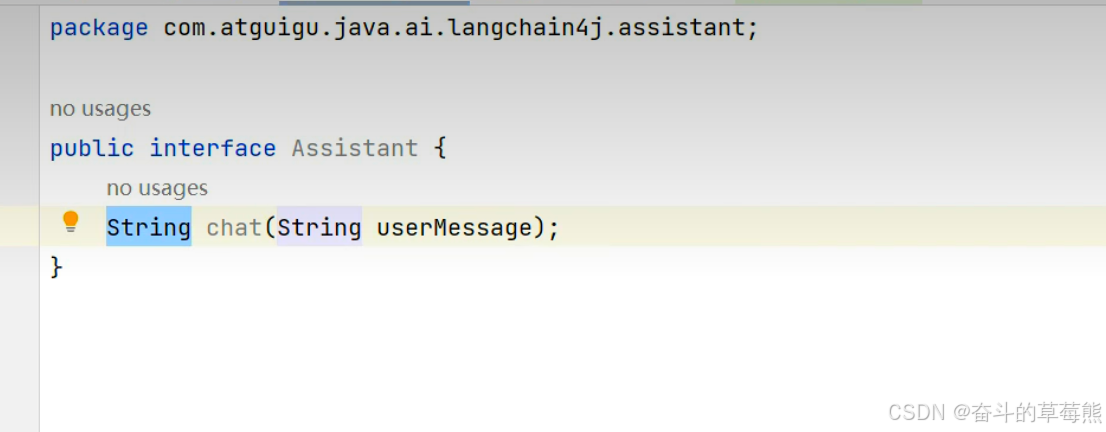
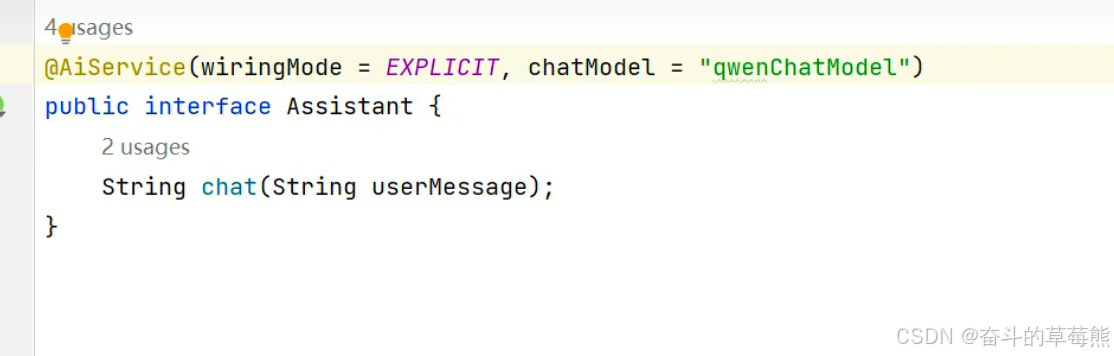
1.定义接口
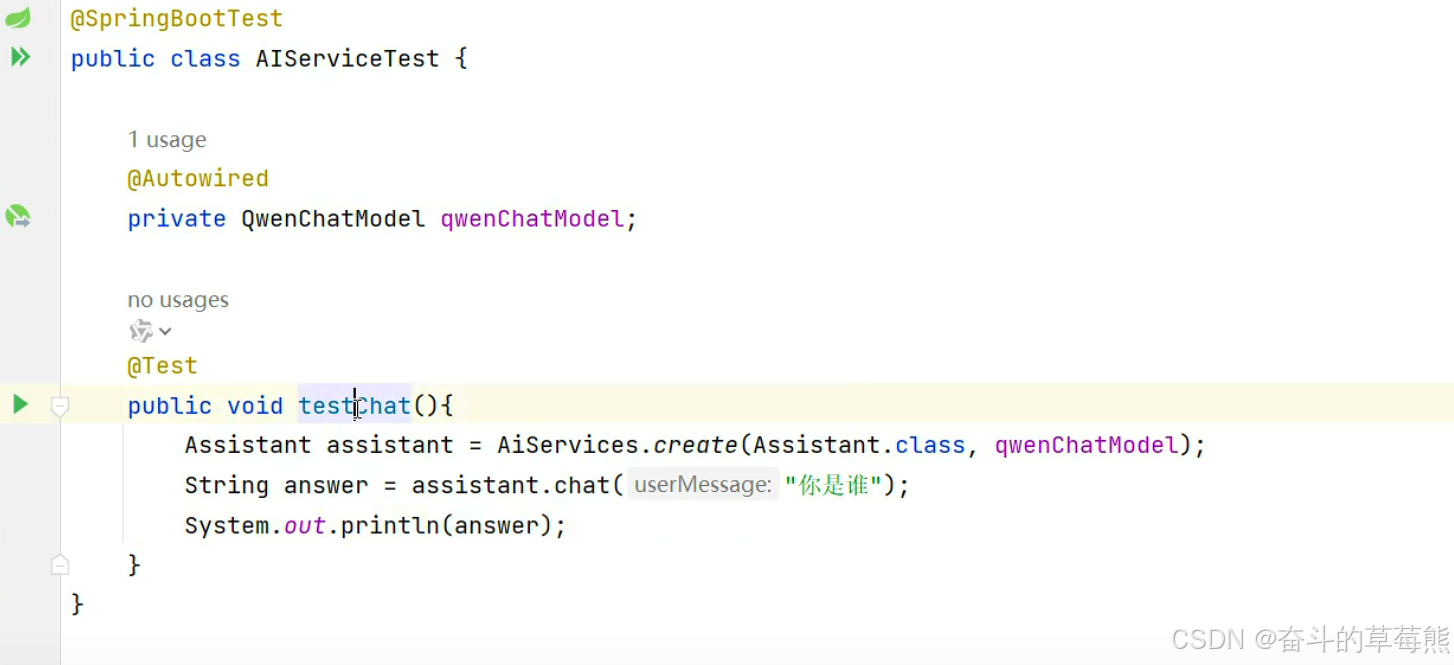
2.使用方式
方式1
方式2
或者通过注入方式再使用(接口指定使用的大模型)
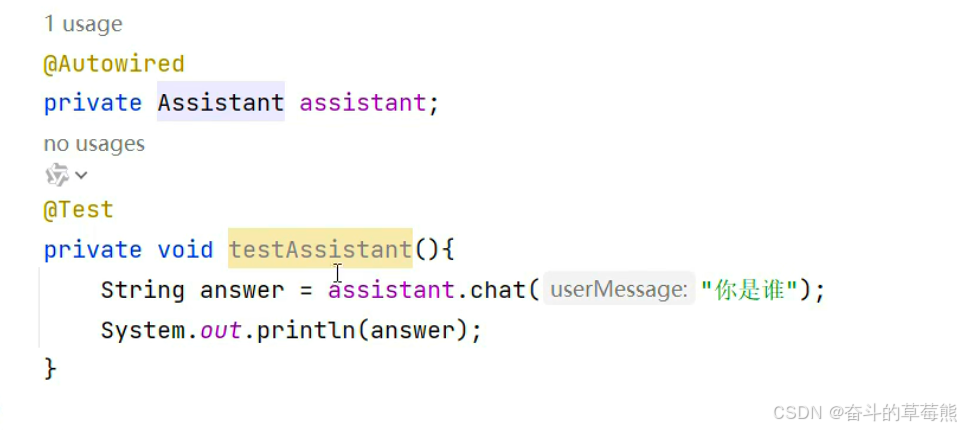
3.2 AIService实现聊天记忆
方式1:类似上述方式1的方式
10代表会话记录的论述为10次
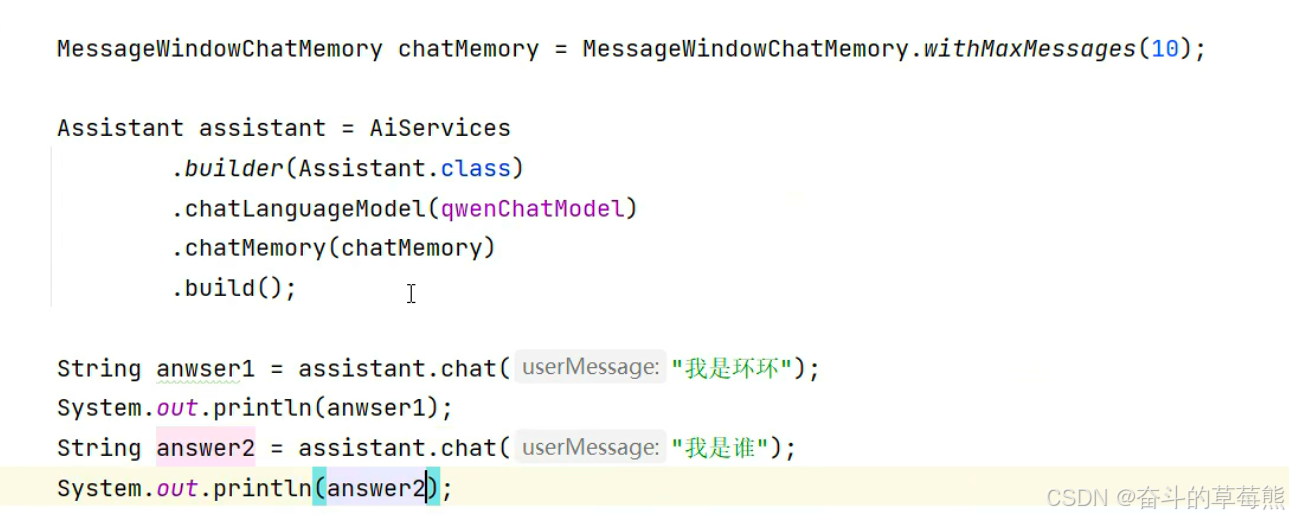
方式2:简化方式1
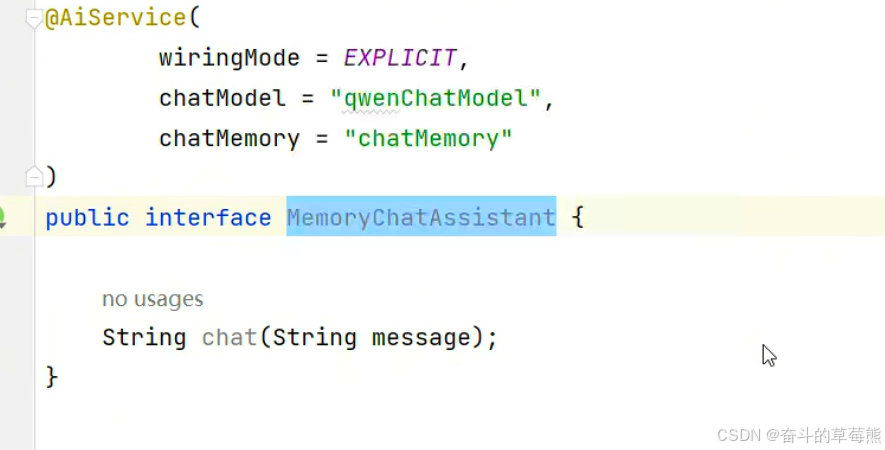
chatMemory通过注入到bean中,这样上面就能够自动引用
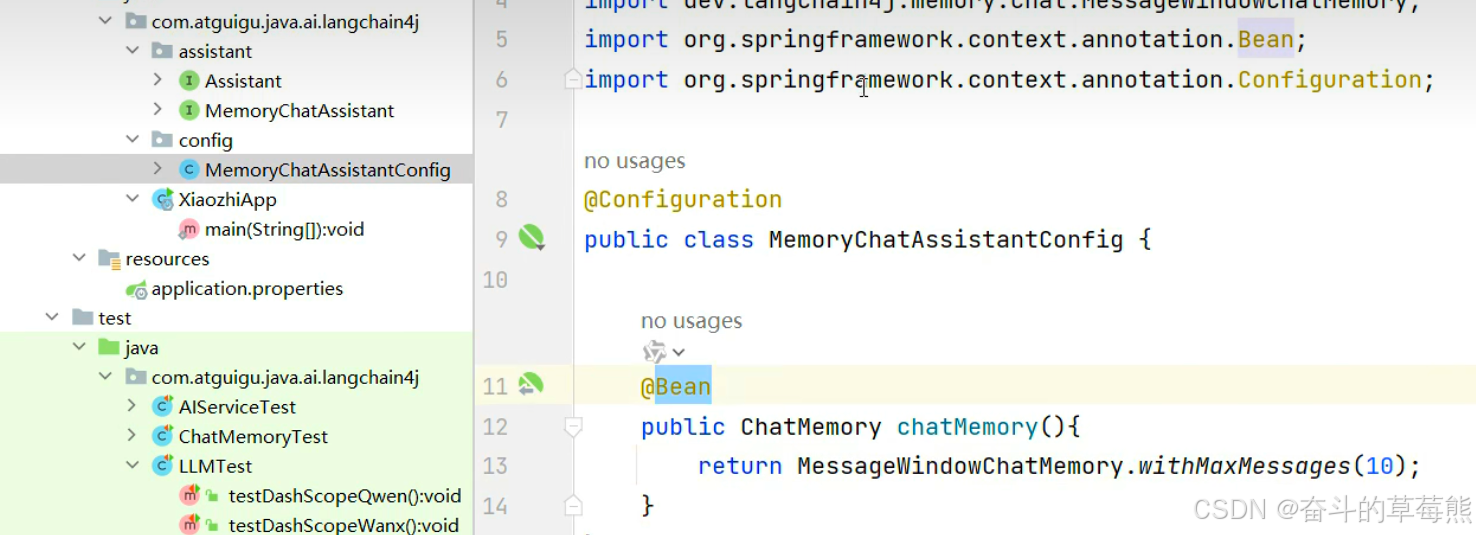
使用
流程梳理:AIService中注解定义好对应的指定模型,聊天记忆。聊天基于通过单独写一个Bean自动注入,外部使用直接调用这个Aiserivice就可以实现聊天记忆
4.实现聊天记忆隔离
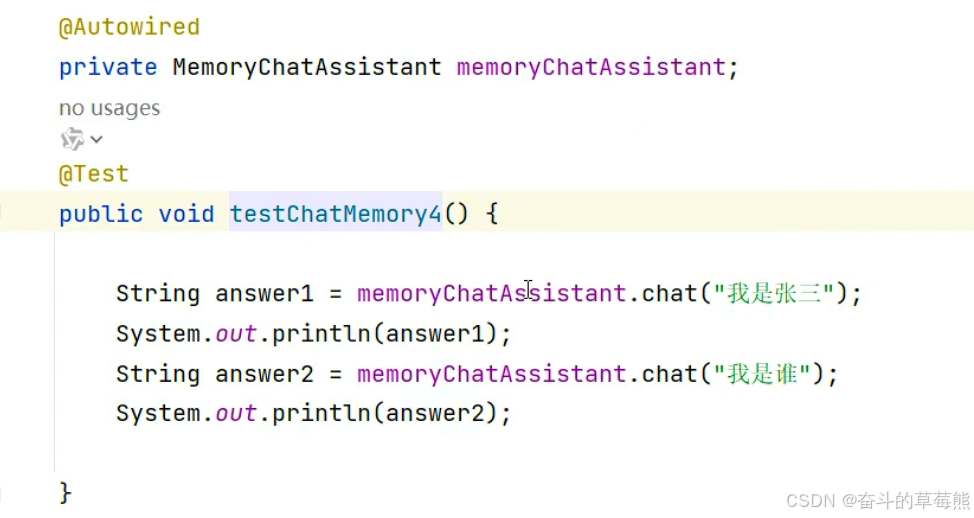
1.定义AiService(携带MemoryId参数即可)
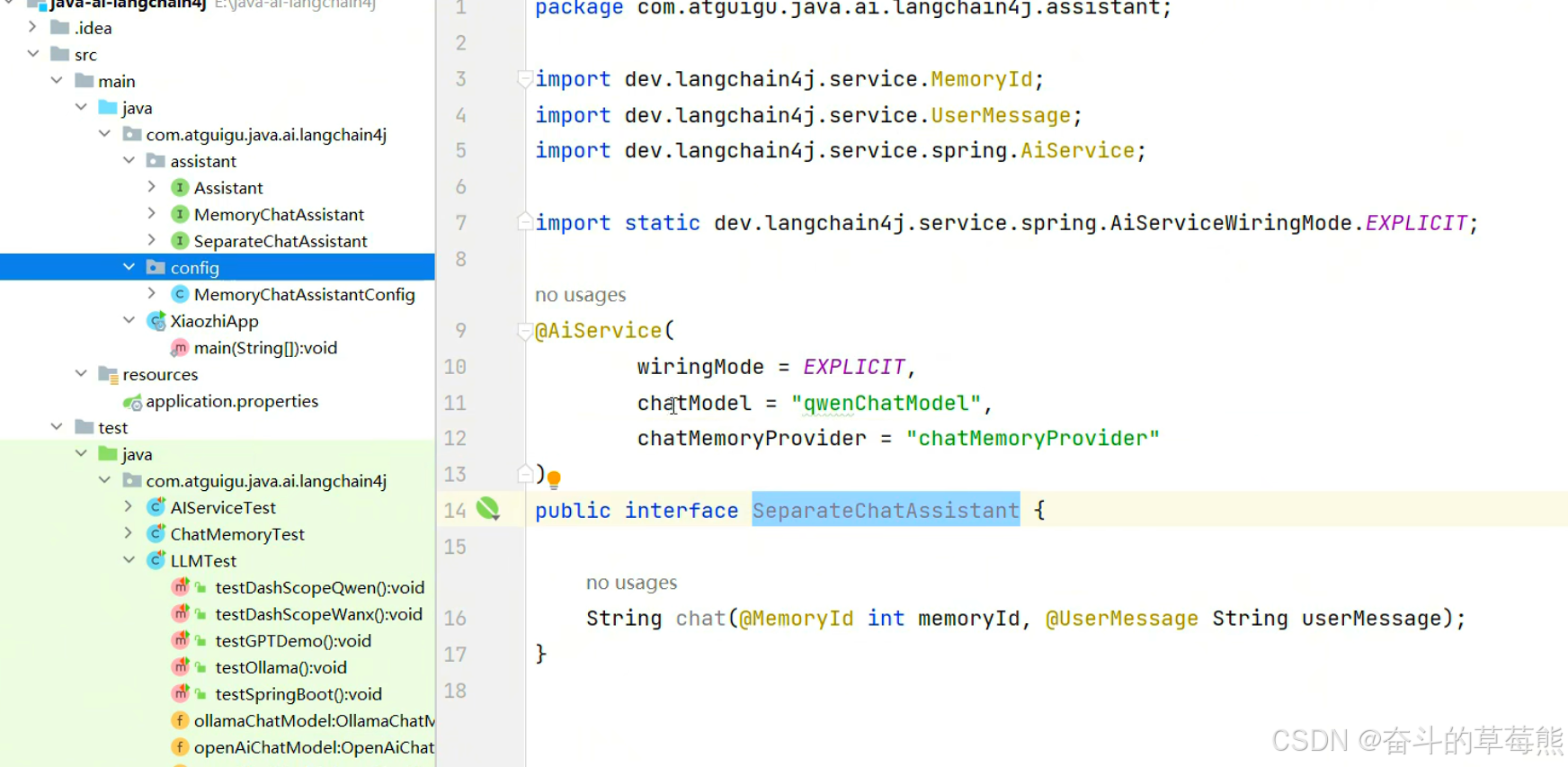
2.配置charMemoryProvider的bean对象

3.测试
5.持久化聊天记忆
5.1 初步使用
1.下载mongodb,并本地启动
2.引入mongodb依赖,并且写好对应的yaml配置
3.配置bean(映射mongodb中的字段,相当于实体类)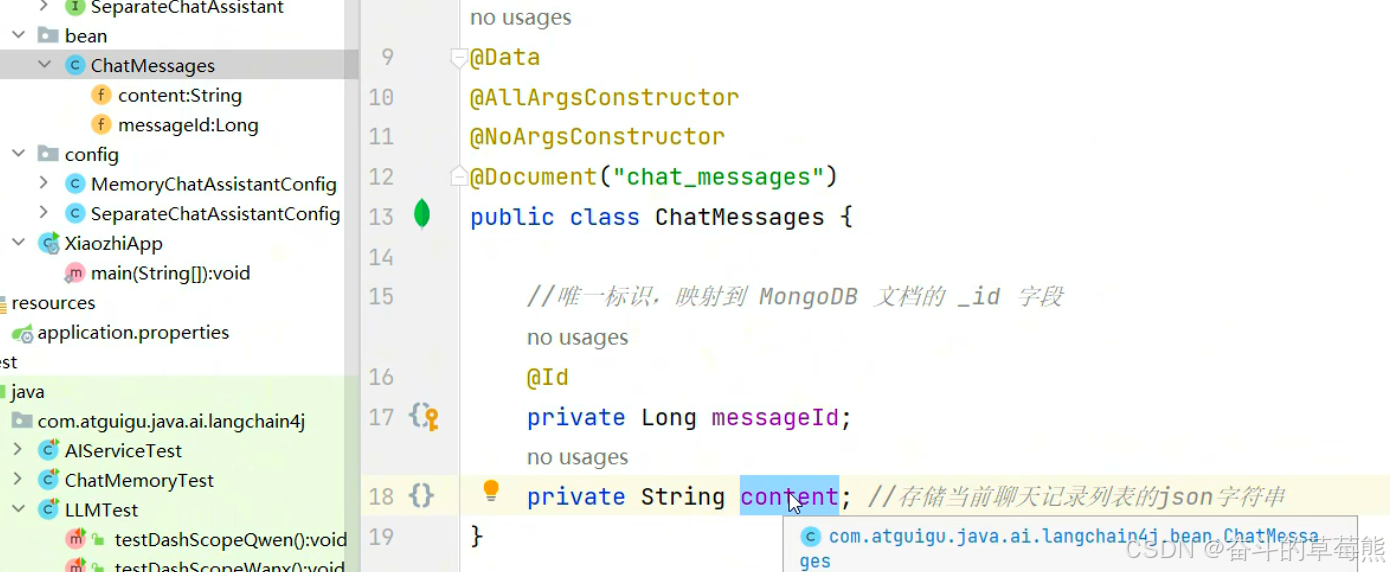
其中@Document注解表示的是创建数据库中的集合名称
5.2 具体使用
1.新增聊天记忆id,优化实体类
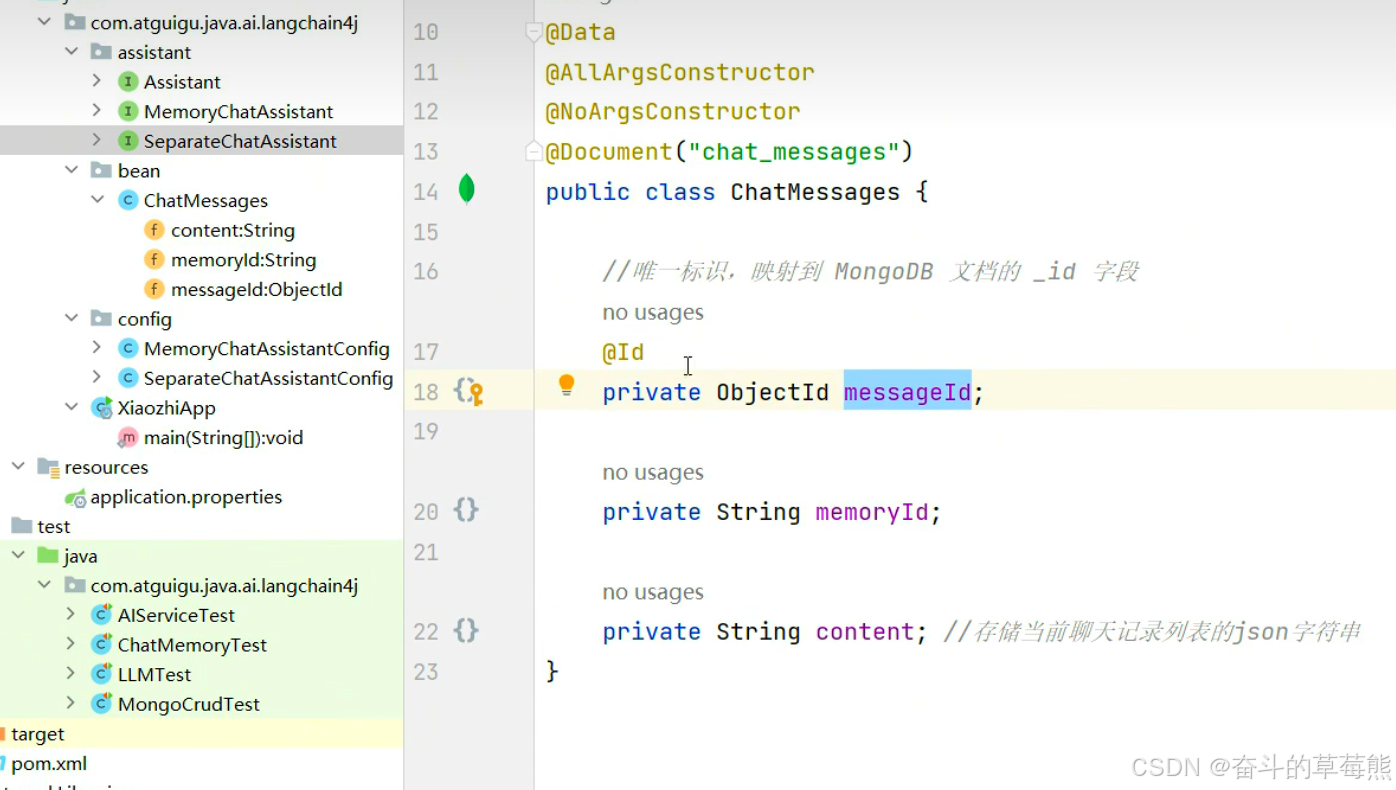
2.创建持久化类
参考原本基于内存实现方式,写自己存数据的实现逻辑,存储到本地数据库中
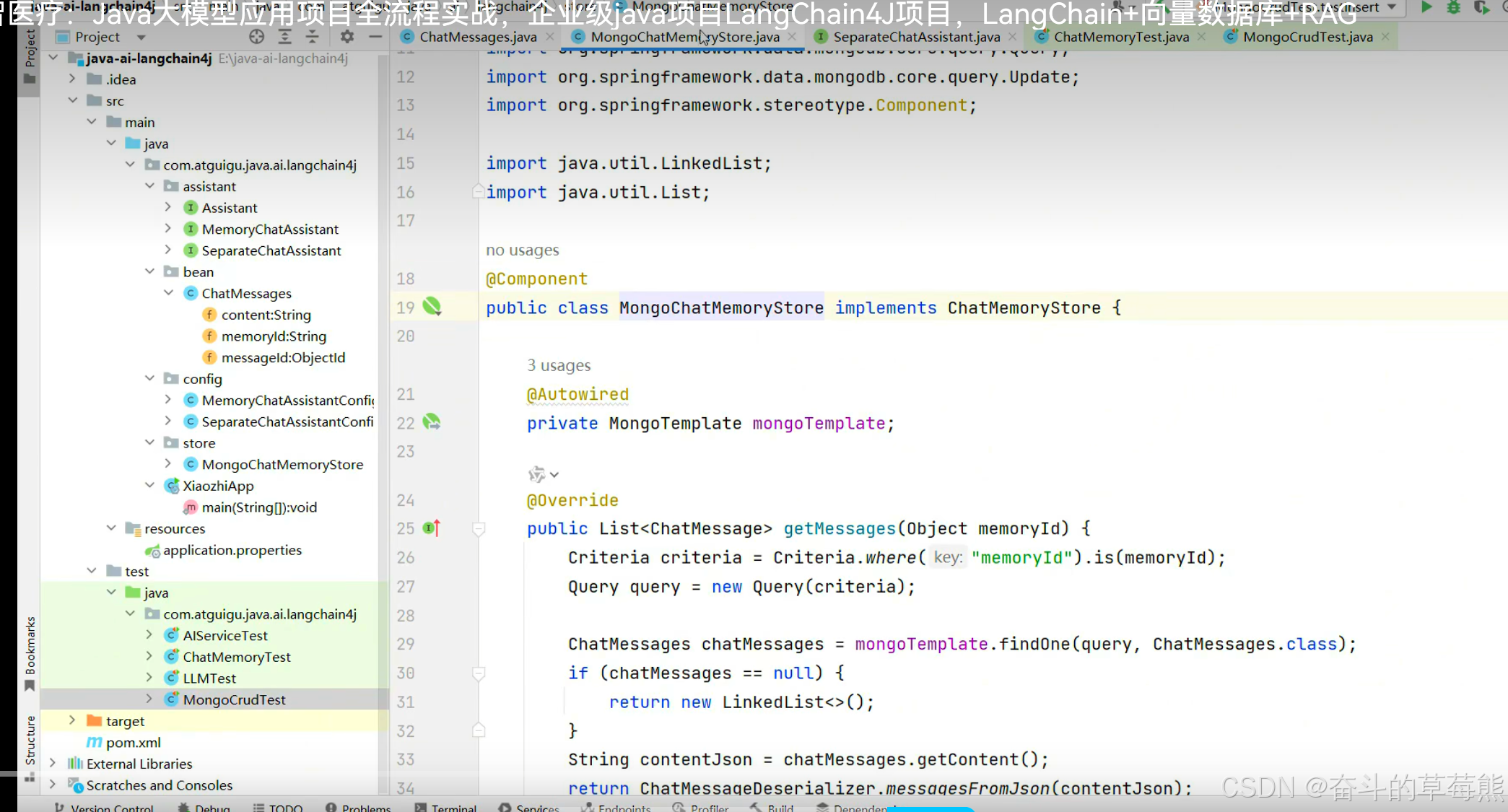
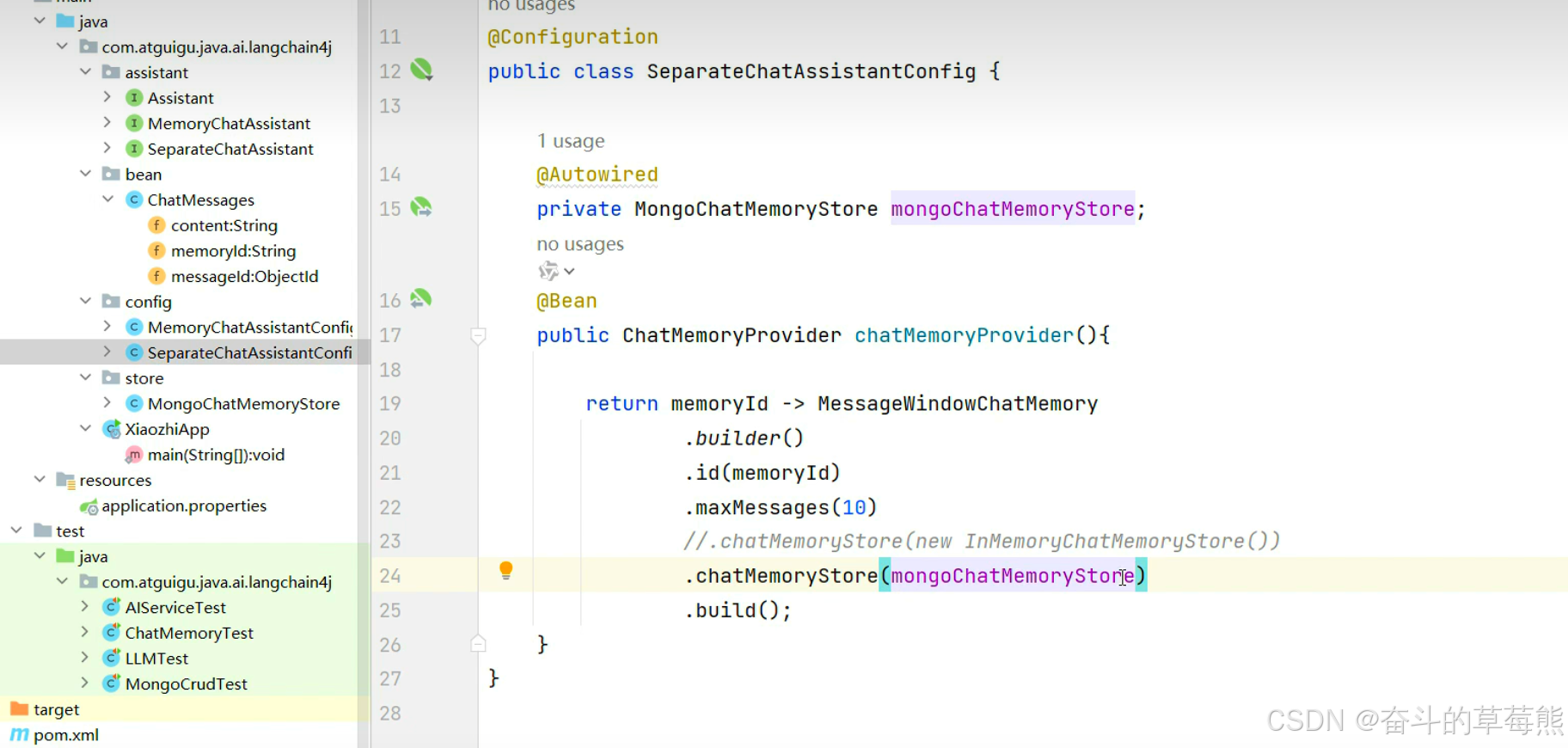
替换持久化存储的实现逻辑,使用自定义的mongoChatMemoryStore
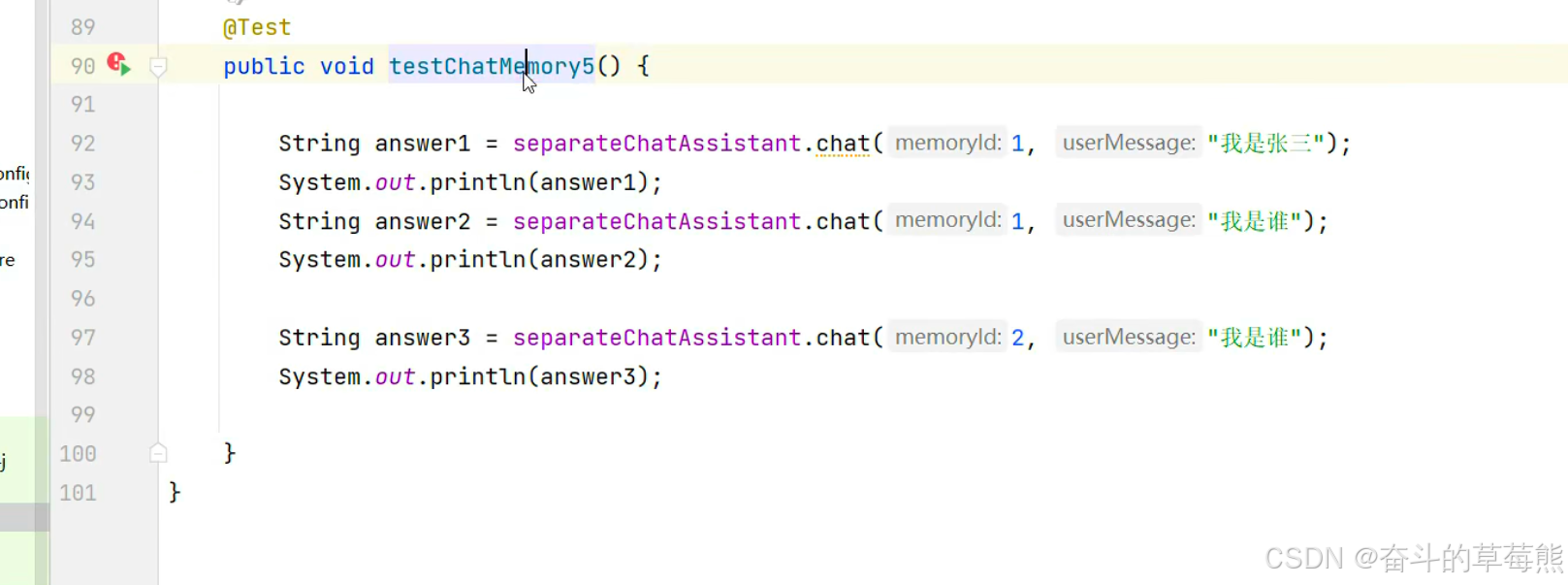
测试是否存储到Mongodb即可
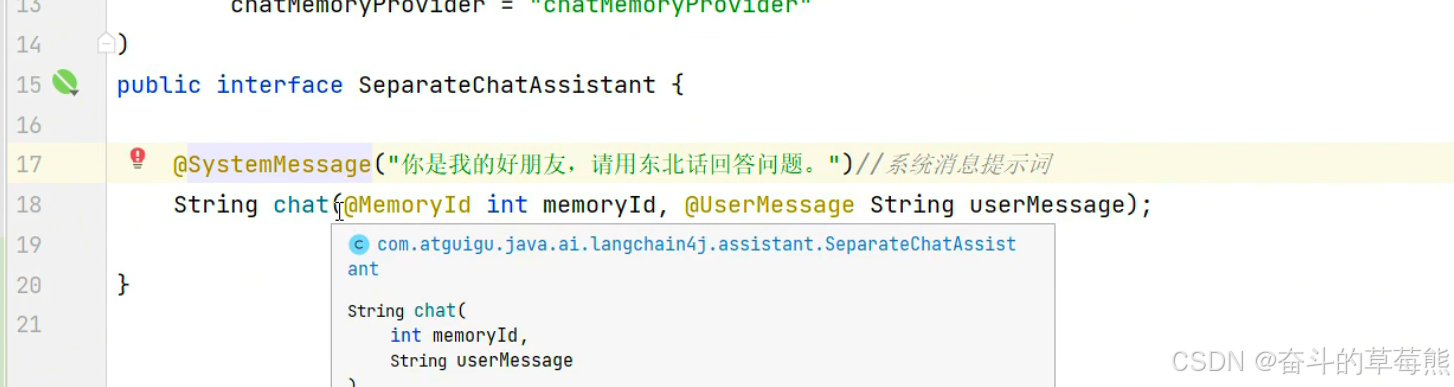
6.系统提示词
设置到chat方法上面就行
其中文字可以设置到一个txt文件中,再引用他也行
6.1 用户提示词
写在chat之上,每轮对话的记忆都会携带这个信息,但是多个参数情况下,需要用@V注解指定,否则会失效
7.项目实战agent
1.定义好AIService
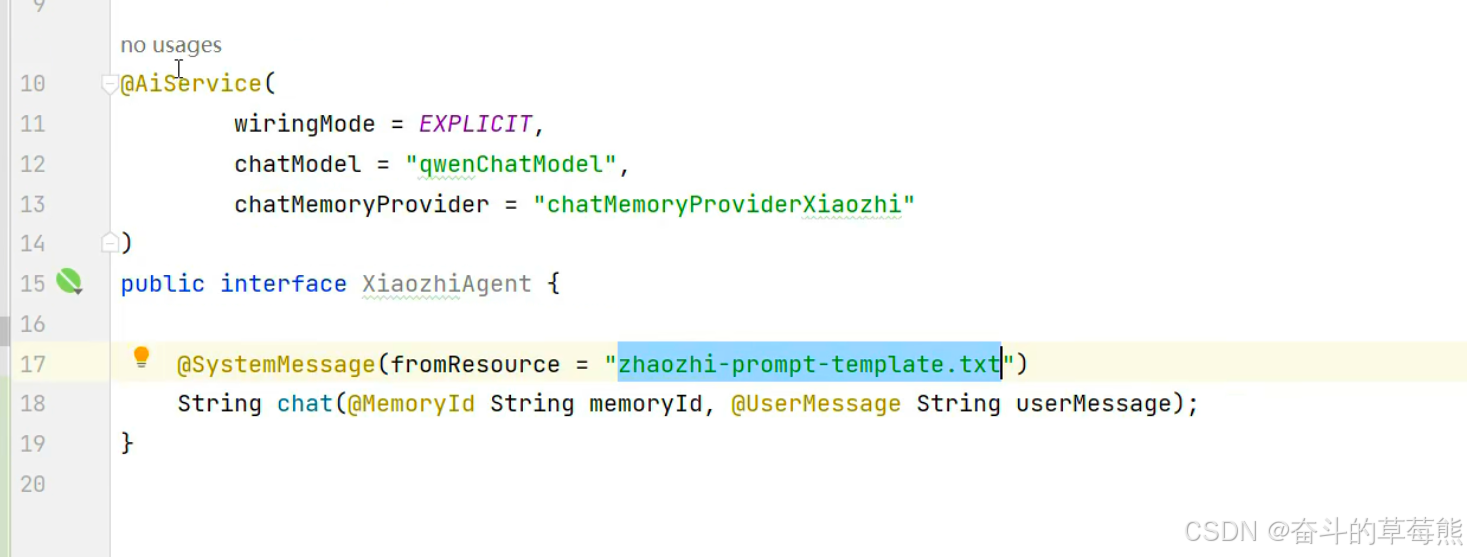
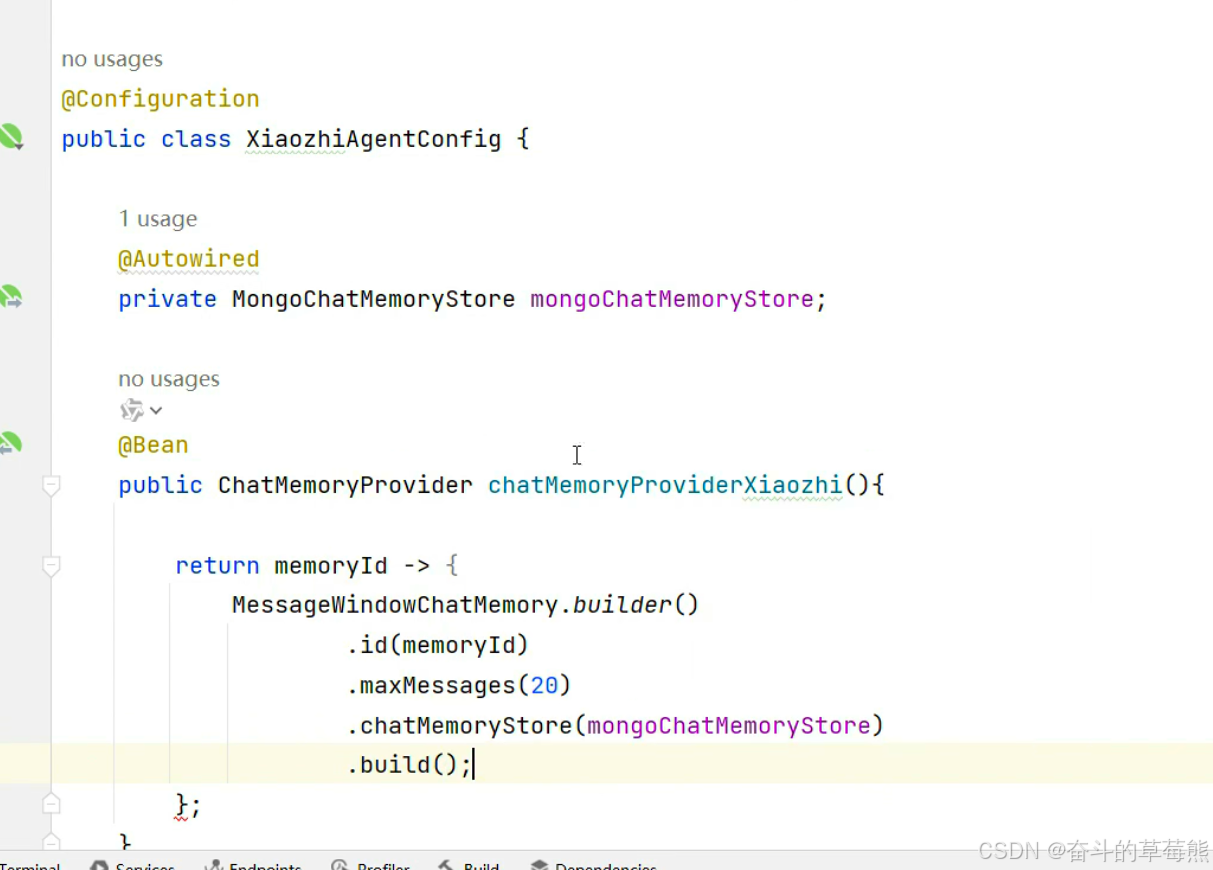
2.chatMemoryProviderXiaozhi里面配置持久化存储和聊天记忆隔离
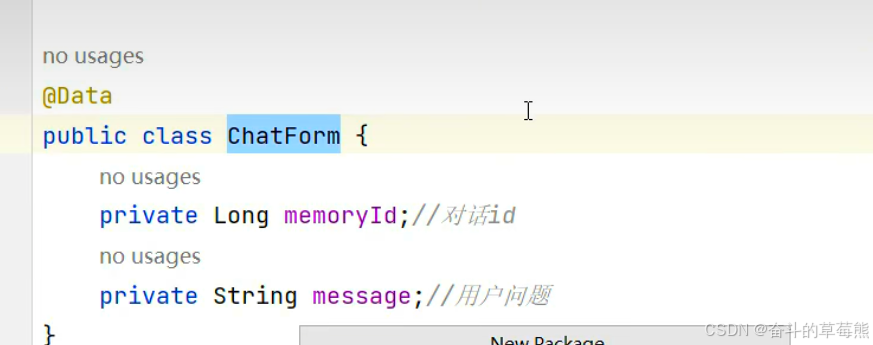
3.定义一个实体类,接收前端的请求
4.定义controller方法,并且调用配置好的智能体
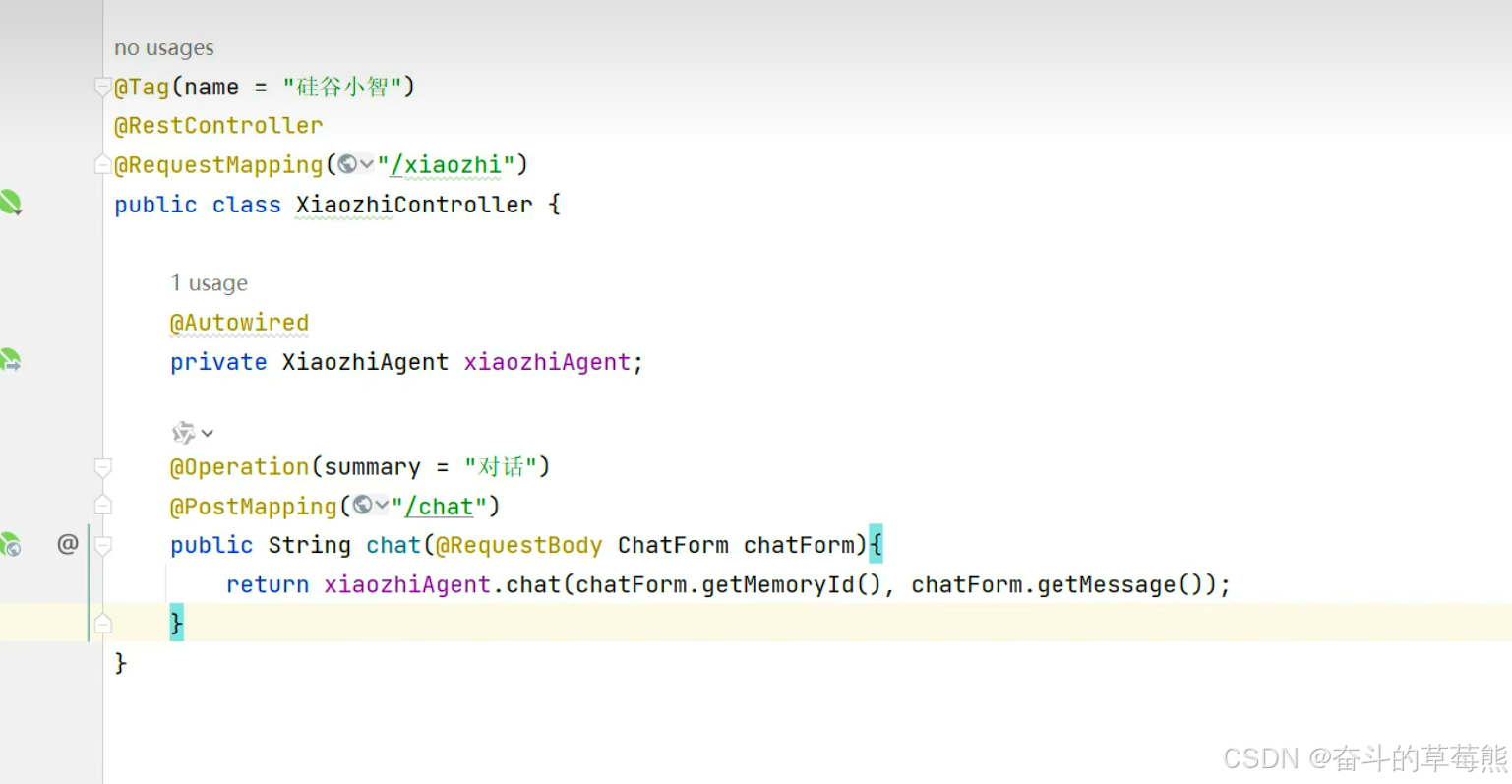
8.function calling学习了解
1.定义工具函数
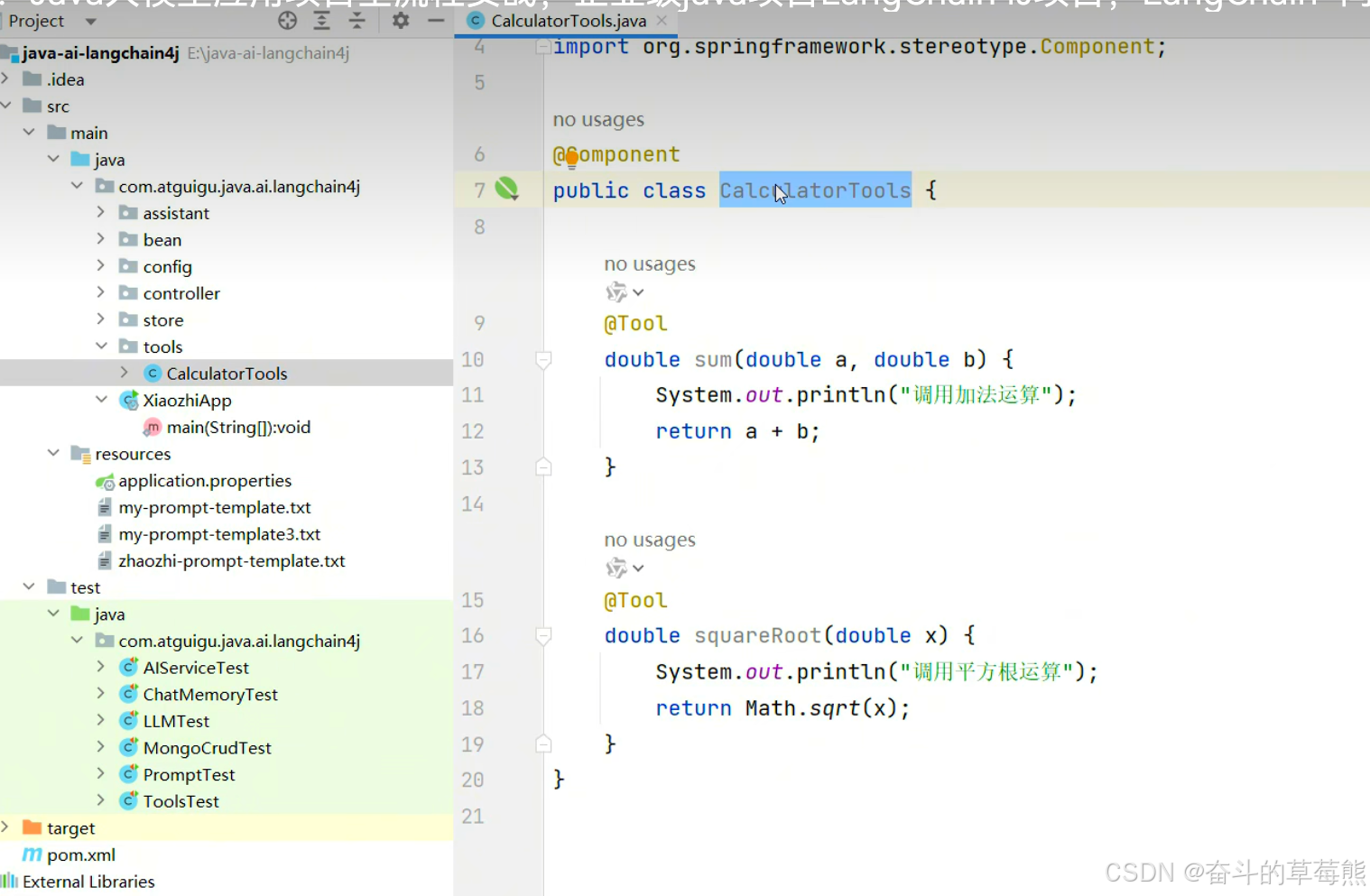
2.AiService中进行配置
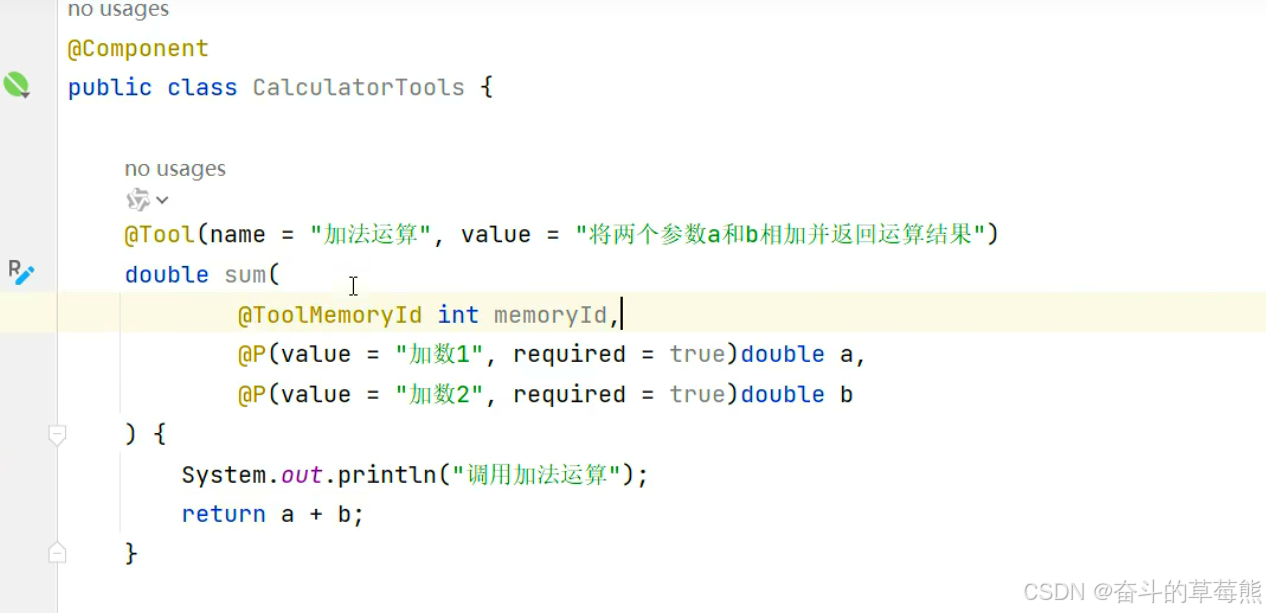
聊天记忆id可以传递到工具函数中,可能会用到
9.项目实战agent+function calling实现
9.1 创建数据库预约表及增删改查操作
1.创建数据库及对应的表
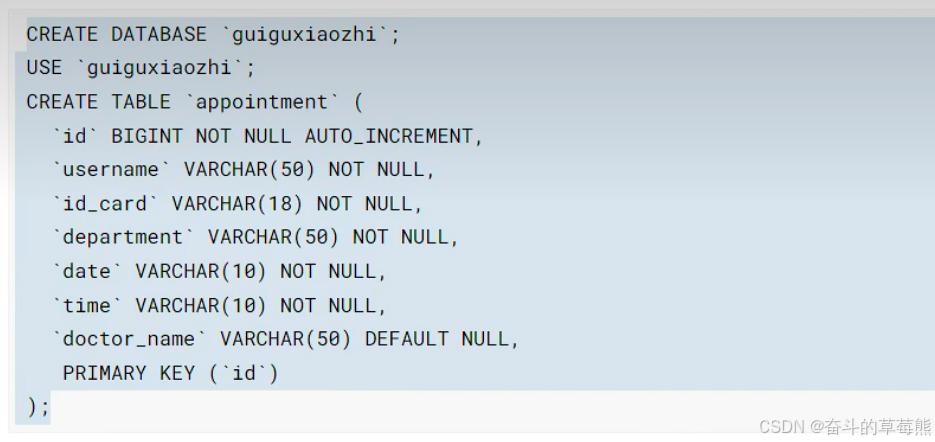
2.引入mysql和mybatisplus依赖,配置mysql信息
3.创建对应的实体类
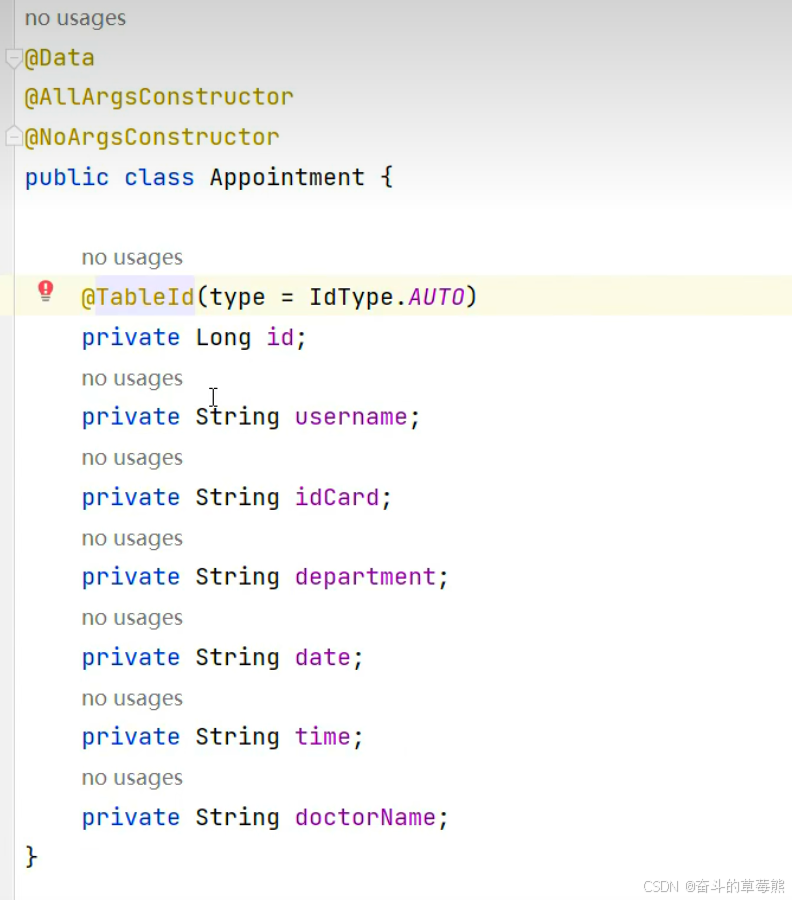
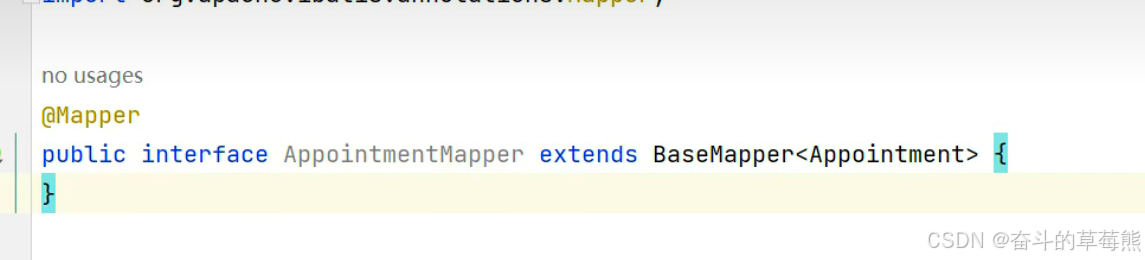
4.定义mapper层以及对应的xml文件
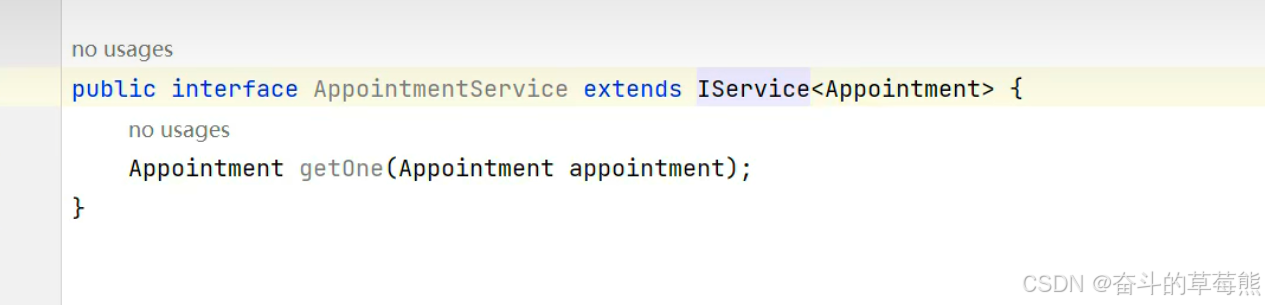
5.定义service层以及对应的实现类,实现表数据的增删改查
9.2 实现Function calling
代码放到tools下
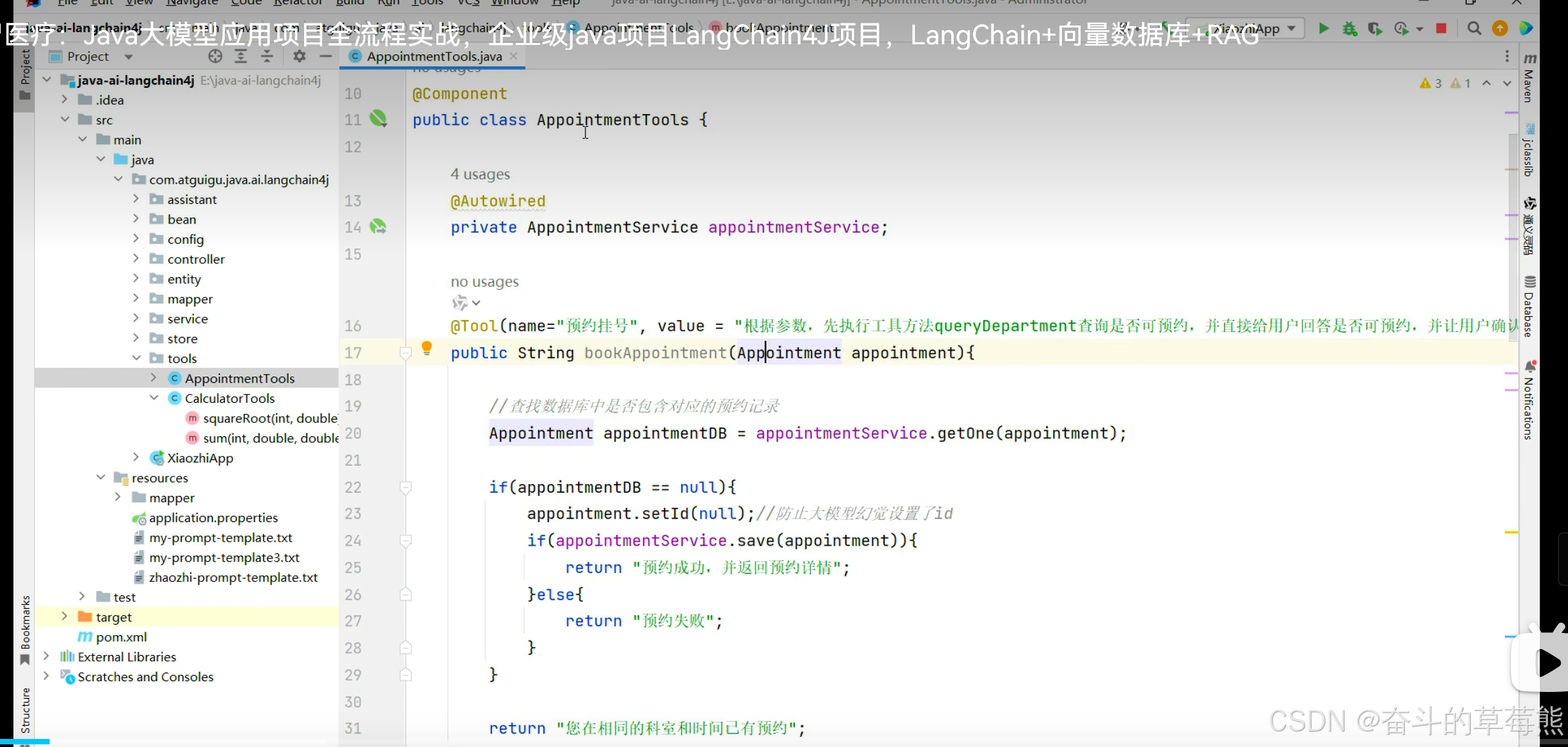
整理流程梳理首先接收用户信息用户,用户调用AIService配置好的大模型进行回复,AIService中配置了很多信息,包括指定的大模型是哪个,聊天记忆隔离功能,聊天记忆持久化,以及工具函数使用,工具函数中又涉及到了Mysql的数据存储,当用户的提问信息涉及到了工具函数,就会自动执行工具函数中设置的内容,实现mysql数据库信息的存储
10.检索增强RAG+项目
1.上面是RAG,如何和项目结合使用(先检索知识库,再结合大模型输出)

2.RAG常用方法

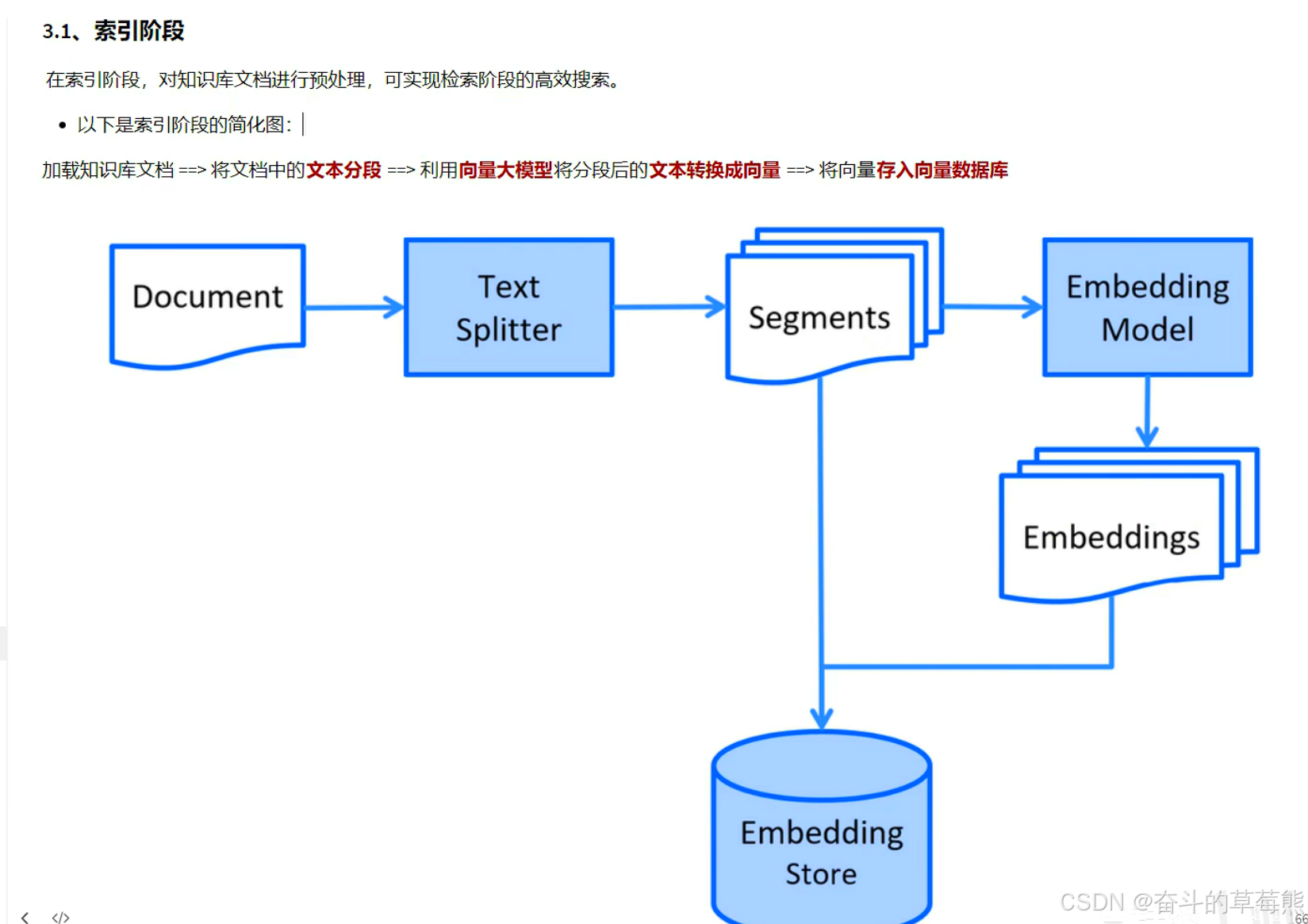
3.索引阶段,知识库转换
文档加载-->解析-->分割-->向量模型转换为向量-->存入向量大模型
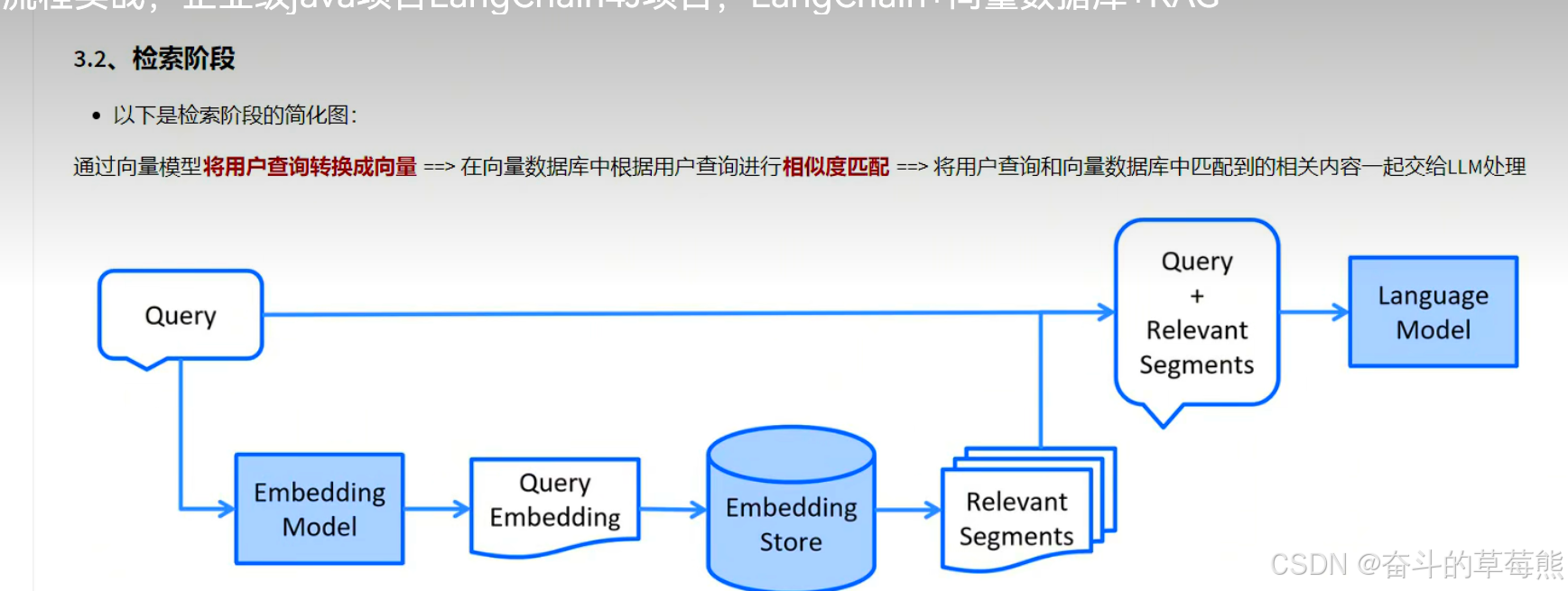
4.检索阶段
10.1 使用pipecone进行向量存储
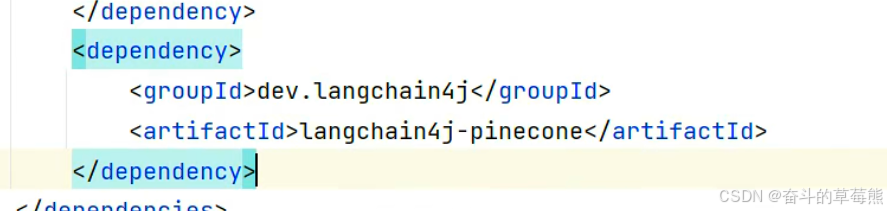
1.引入依赖
2.引入阿里向量模型(文本/图片向量化)

3.再pipecone中的向量存储(读取到向量库中的信息 )
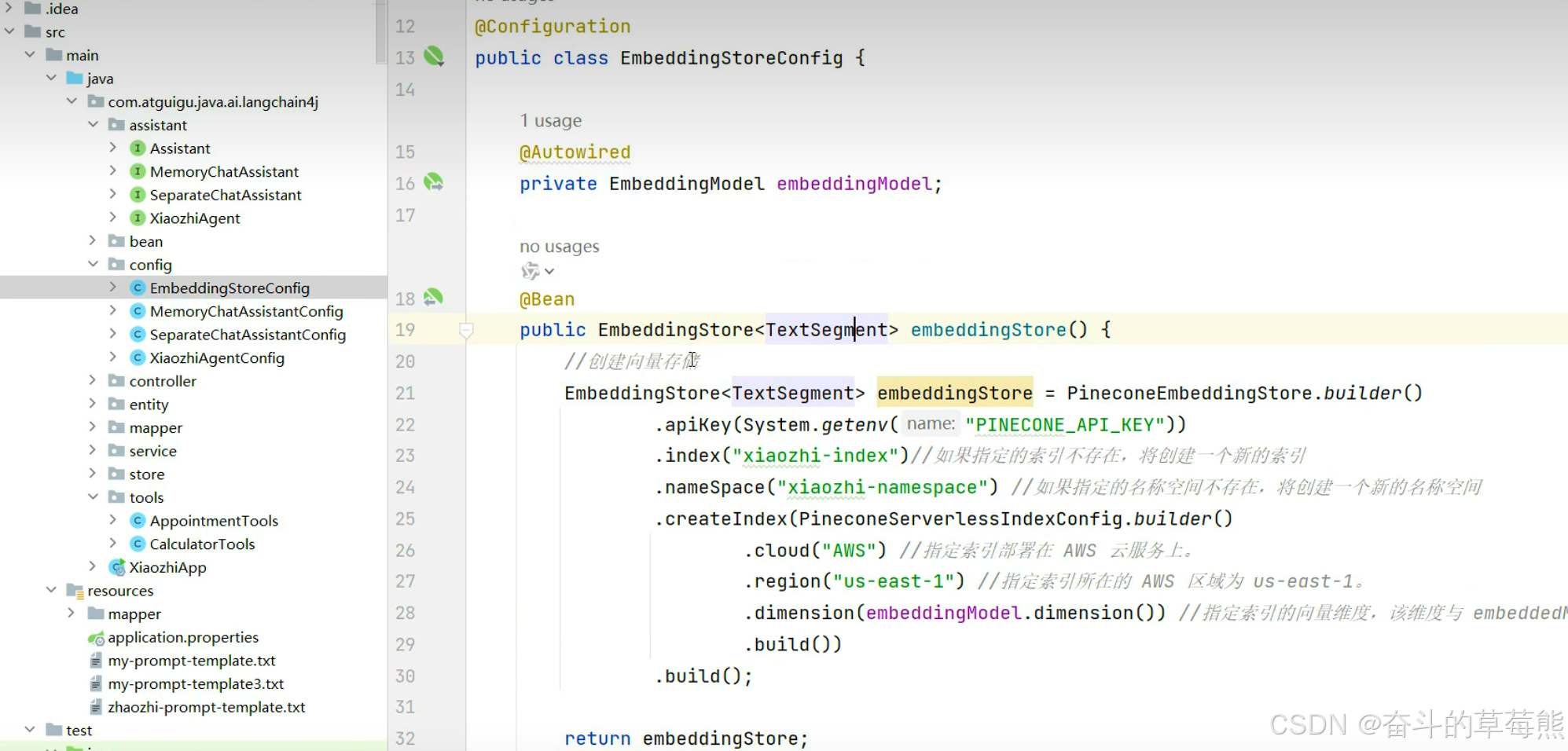
4.把知识库存入pipecone
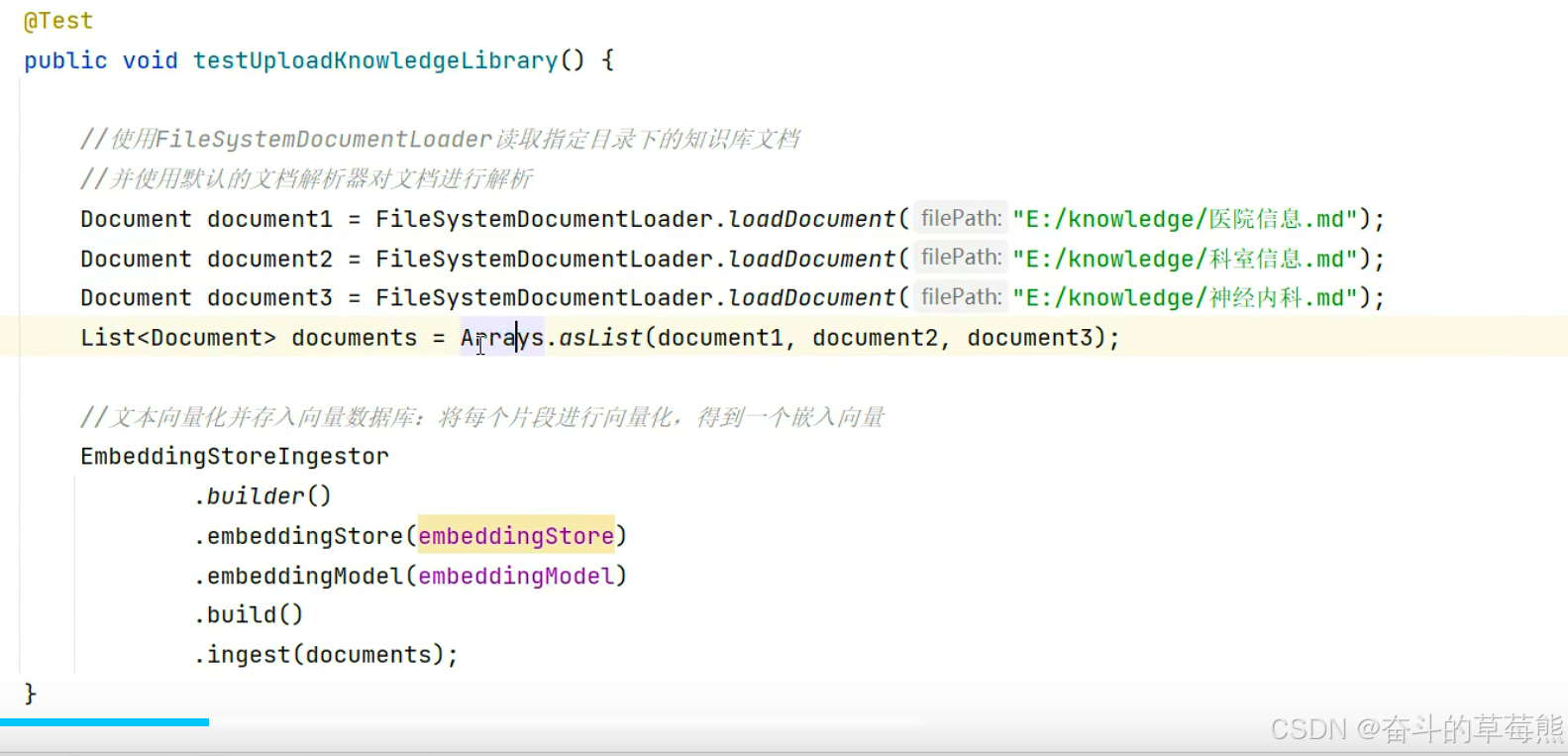
5.配置嵌入存储提供的检索信息
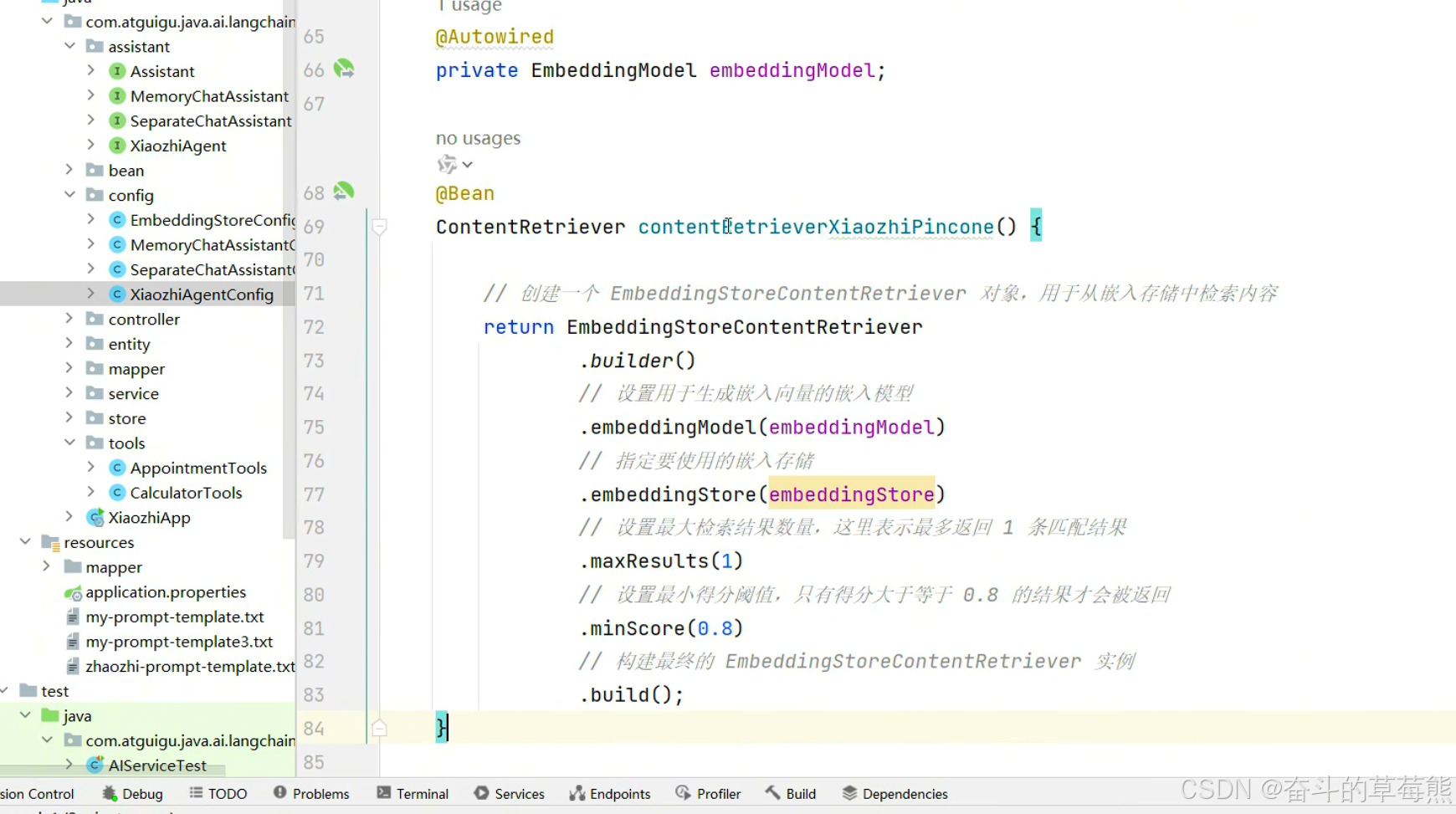
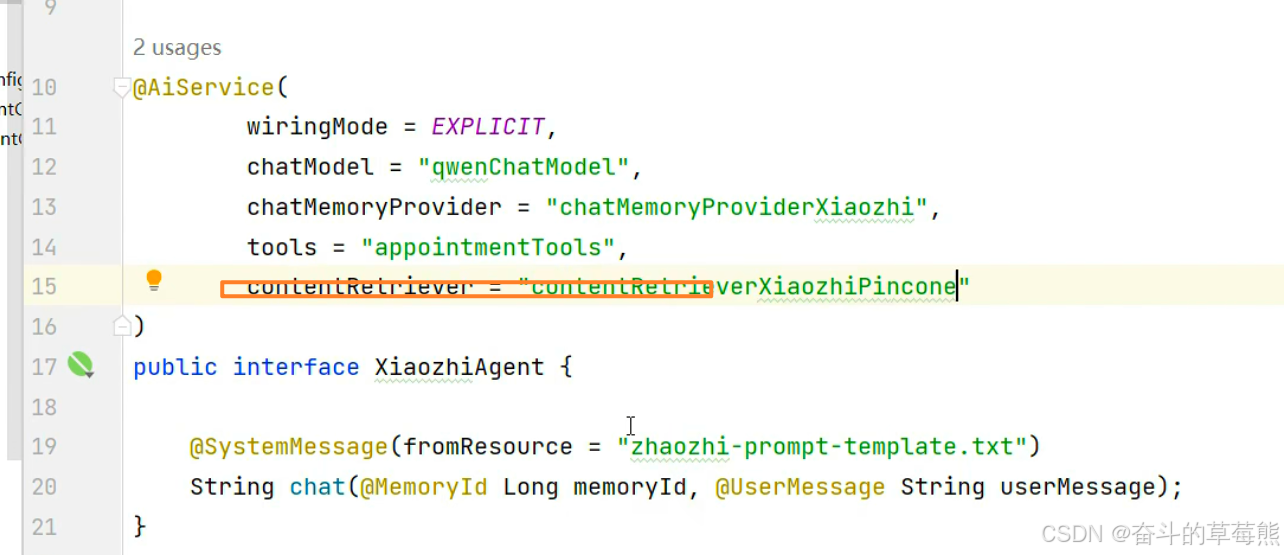
6.AIService中使用
11.总结
前端用户发起请求,请求调用大模型进行回复,大模型中配置了一些基本信息(聊天记忆隔离,聊天内容持久化,自动调用工具函数,使用的嵌入存储来源(RAG)),流式输出返回信息