前言
在现代应用开发中,我们无时无刻不在与"对象"打交道------用户信息、商品详情、配置项、会话数据......如何高效、清晰地在缓存或数据库中存储这些结构化数据,是每一个开发者都需要面对的课题。
你可能会想到将一个对象序列化成 JSON 字符串,然后用一个简单的 Key-Value 方式存入 Redis。这确实是一种方法,但当你只想修改对象的某一个属性(比如用户的积分)时,就不得不读取整个 JSON 字符串,反序列化成对象,修改属性,再序列化回 JSON,最后整个写回 Redis。这个过程不仅繁琐,而且在并发环境下极易引发数据覆盖问题,性能开销也相当可观。
那么,有没有一种更原生、更高效的方式来处理这种"对象"存储呢?答案是肯定的。Redis 为我们提供了一种强大的数据结构,它天生就是为了解决这类问题而生------Hash(哈希/散列)。
本文将带领你深入探索 Redis Hash 的世界,通过 C++ 语言(借助 redis-plus-plus 库)的实际代码示例,从最基础的单个字段操作,到高效的批量处理,全面掌握 Hash 的使用技巧和底层逻辑,让你在数据存储方案设计上如虎添翼。
什么是 Redis Hash?------不止是键值对那么简单
Redis 本身是一个 Key-Value 数据库,而 Hash 类型则是在这个基础上构建的"二级"键值对集合。你可以把它想象成一个特殊的值(Value),这个值本身又是一个微型的、独立的键值对数据库。
- 外部 Key:整个 Hash 对象的唯一标识符。
- 内部 Field-Value 对:Hash 对象内部存储着多个字段(Field)和它们对应的值(Value)。
打个比方,如果说普通的 Redis Key-Value 像是一个文件柜,每个抽屉(Key)里只能放一份文件(Value)。那么,Redis Hash 就像是一个抽屉(Key),里面放了一个分门别类的文件夹,文件夹里有多个标签(Field)和对应的文件(Value)。
这种结构带来的好处是显而易见的:
- 数据组织性强:将一个对象的所有相关属性聚合在一个 Key 下,逻辑清晰,便于管理。
- 节约内存 :当 Hash 内的字段数量不多时,Redis 会采用一种称为
ziplist的紧凑编码方式,相比为每个属性都创建一个独立的顶级 Key,能极大地节省内存空间。 - 操作粒度更细:可以直接对 Hash 内的单个或多个字段进行增、删、改、查,而无需操作整个对象,这大大提升了性能并降低了网络开销。
- 原子性:所有对单个字段的操作都是原子性的,保证了数据的一致性。
接下来,让我们通过代码,亲手揭开 Redis Hash 的神秘面纱。
第一章:基础 CRUD ------ Hash 的核心操作
我们将从最基本的"增删改查"(CRUD - Create, Read, Update, Delete)开始,这些是构建一切复杂应用的基础。
1.1 HSET 与 HGET:单个字段的读写艺术
HSET 是向 Hash 中设置单个字段值的命令,而 HGET 则是获取单个字段的值。它们是 Hash 操作中最核心、最常用的两个命令。
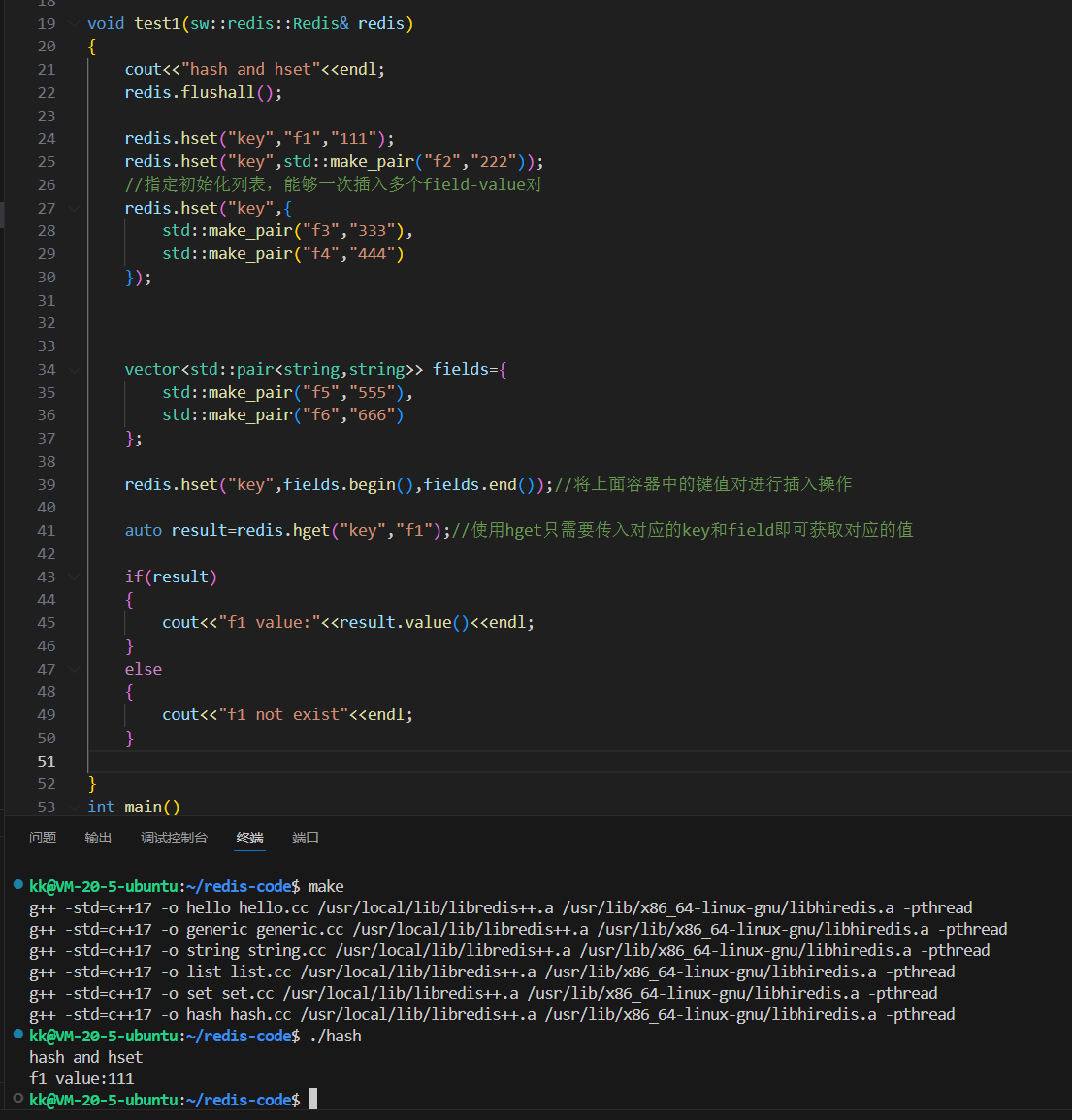
让我们来详细解读一下这段代码:
cpp
void test1(sw::redis::Redis& redis)
{
cout << "hash and hset" << endl;
redis.flushall(); // 清空数据库,确保一个干净的测试环境
// --- HSET 操作的多种方式 ---
// 方式一:最基础的调用,设置一个字段 "f1",值为 "111"
redis.hset("key", "f1", "111");
// 方式二:使用 std::make_pair,更符合 C++ 风格
redis.hset("key", std::make_pair("f2", "222"));
// 方式三:使用初始化列表,一次性设置多个字段,效率更高
// 这会被 redis-plus-plus 智能地打包成一条命令发往 Redis 服务器
redis.hset("key", {
std::make_pair("f3", "333"),
std::make_pair("f4", "444")
});
// 方式四:使用迭代器,从容器中批量设置
// 适用于动态构建字段列表的场景
vector<std::pair<string, string>> fields = {
std::make_pair("f5", "555"),
std::make_pair("f6", "666")
};
redis.hset("key", fields.begin(), fields.end()); // 将容器中的键值对进行插入操作
// --- HGET 操作 ---
// 使用 hget 传入 key 和 field 获取对应的值
// 返回值是 sw::redis::Optional<std::string> 类型
auto result = redis.hget("key", "f1");
// Optional 类型可以优雅地处理"值可能不存在"的情况
if (result)
{
// 如果字段存在,通过 .value() 方法获取值
cout << "f1 value:" << result.value() << endl;
}
else
{
cout << "f1 not exist" << endl;
}
}深度分析与洞察:
- 命令的演进 :在 Redis 4.0.0 之前,
HSET只能设置单个字段。若要设置多个,需要使用HMSET。但从 4.0.0 开始,HSET得到了增强,可以一次性接收多个field-value对,从而统一了接口。我们上面看到的redis-plus-plus库的初始化列表和迭代器重载,正是利用了HSET的这一新特性,将多次网络请求合并为一次,极大地提升了效率。 Optional的妙用 :hget查询一个不存在的字段时,Redis 会返回nil。在 C++ 中,这通常需要通过指针或特殊返回值来处理。redis-plus-plus库巧妙地使用了Optional模板类,它就像一个可能为空的容器。通过if(result)或result.has_value()来判断是否有值,避免了空指针异常,让代码更安全、更具表达力。
执行 test1 函数,经过一系列 hset 操作后,我们名为 "key" 的 Hash 中已经包含了从 f1 到 f6 的六个字段。随后的 hget 操作成功获取了 f1 的值,因此控制台的输出会是:
hash and hset
f1 value:1111.2 HEXISTS、HDEL 与 HLEN:管理与维护 Hash 结构
仅仅能读写是不够的,我们还需要检查字段是否存在、删除指定字段以及获取 Hash 的大小。这三个命令为我们提供了必要的管理能力。
HEXISTS:精准判断,避免无效操作
在执行更新或读取操作前,先判断一个字段是否存在,是一种良好的编程习惯。HEXISTS 就是为此而生。
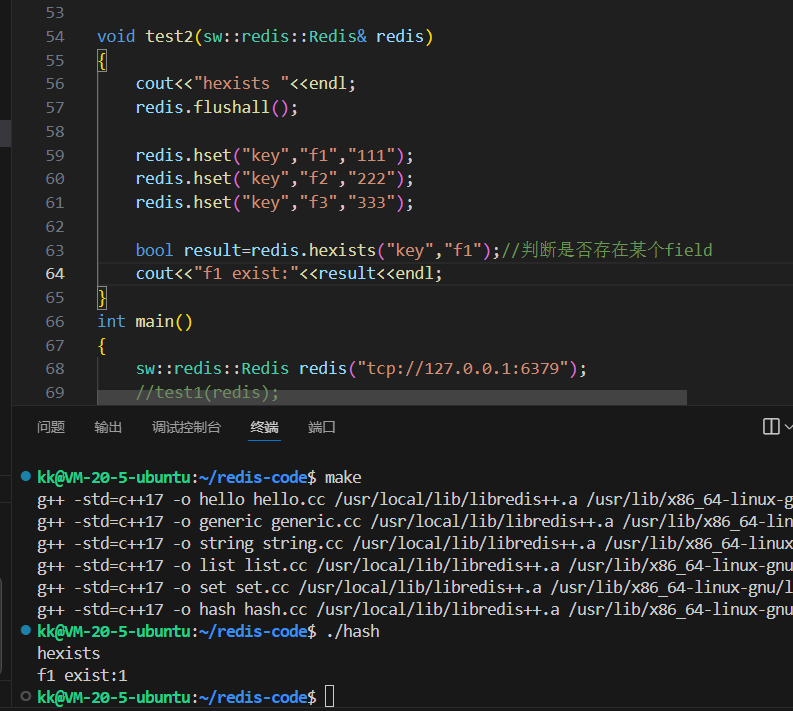
cpp
void test2(sw::redis::Redis& redis)
{
cout << "hexists " << endl;
redis.flushall();
redis.hset("key", "f1", "111");
redis.hset("key", "f2", "222");
redis.hset("key", "f3", "333");
// 判断 "key" 这个 Hash 中是否存在名为 "f1" 的字段
// Redis 返回 1 (存在) 或 0 (不存在),库将其转换为 bool 类型
bool result = redis.hexists("key", "f1");
// C++ 中 bool 类型的 true 输出时默认为 1
cout << "f1 exist:" << result << endl;
}这段代码的逻辑非常直白。我们先设置了 f1,然后用 hexists 检查,结果必然是存在的。因此,result 变量的值为 true,控制台输出 1。
hexists
f1 exist:1HDEL 与 HLEN:像手术刀一样增删字段,用标尺测量大小
HDEL 负责删除一个或多个字段,而 HLEN 则返回 Hash 中字段的总数。
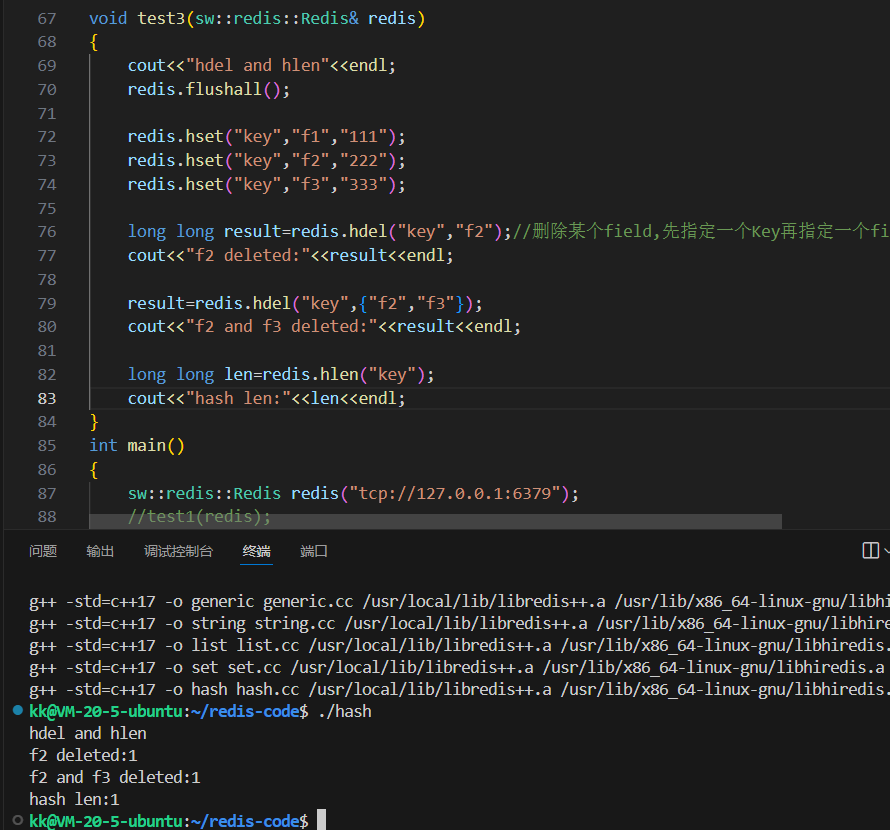
cpp
void test3(sw::redis::Redis& redis)
{
cout << "hdel and hlen" << endl;
redis.flushall();
redis.hset("key", "f1", "111");
redis.hset("key", "f2", "222");
redis.hset("key", "f3", "333");
// 初始状态: Hash "key" 包含 {f1, f2, f3},长度为 3
// 第一次删除:删除单个存在的字段 "f2"
// HDEL 的返回值是 *实际被删除* 的字段数量
long long result = redis.hdel("key", "f2");
cout << "f2 deleted:" << result << endl;
// 此刻状态: Hash "key" 包含 {f1, f3},长度为 2
// 第二次删除:尝试删除 "f2" 和 "f3"
// "f2" 已不存在,将被忽略;"f3" 存在,将被删除
result = redis.hdel("key", {"f2", "f3"});
// 只有一个字段 "f3" 被实际删除了,所以返回值是 1
cout << "f2 and f3 deleted:" << result << endl;
// 此刻状态: Hash "key" 包含 {f1},长度为 1
// 获取最终的字段数量
long long len = redis.hlen("key");
cout << "hash len:" << len << endl;
}深度分析与洞察:
HDEL返回值的陷阱 :初学者最容易误解HDEL的返回值。它返回的是成功删除的字段个数 ,而不是你尝试删除的字段个数。在test3的第二次删除中,我们尝试删除{"f2", "f3"},但由于f2此时已经不存在,所以只有f3被成功删除,返回值是1,而不是2。这个特性对于需要精确了解操作结果的业务逻辑至关重要。- 原子性保证 :
hdel("key", {"f2", "f3"})这个操作是原子性的。要么都执行(成功的删除,不存在的忽略),要么都不执行。不会出现只删了f3的一半就中断的情况,这保证了数据状态的完整性。
根据代码的执行流程,最终的控制台输出将是:
hdel and hlen
f2 deleted:1
f2 and f3 deleted:1
hash len:1第二章:批量操作 ------ 追求极致性能的利器
当需要处理 Hash 中的大量字段时,逐个操作就像用勺子给泳池换水,效率低下。Redis 提供了一系列强大的批量操作命令,能将成百上千次网络通信的开销压缩为一次,这是性能优化的关键所在。
2.1 HKEYS 与 HVALS:一次性获取所有字段或所有值
有时候,我们需要遍历一个对象的所有属性名(HKEYS)或所有属性值(HVALS)。
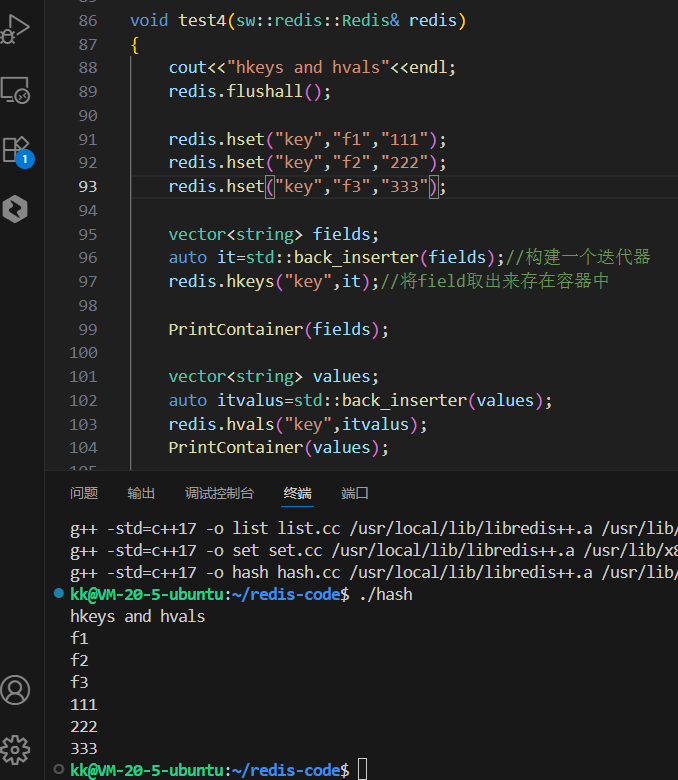
cpp
// 假设已有一个 PrintContainer 辅助函数用于打印容器内容
template<typename T>
void PrintContainer(const T& container) {
for (const auto& item : container) {
cout << item << " ";
}
cout << endl;
}
void test4(sw::redis::Redis& redis)
{
cout << "hkeys and hvals" << endl;
redis.flushall();
redis.hset("key", "f1", "111");
redis.hset("key", "f2", "222");
redis.hset("key", "f3", "333");
// --- 获取所有字段 (HKEYS) ---
vector<string> fields;
// std::back_inserter 是一个方便的工具,它创建一个迭代器,
// 对其赋值等同于在容器末尾调用 push_back
auto it_fields = std::back_inserter(fields);
redis.hkeys("key", it_fields); // 将所有 field 取出来存在容器中
PrintContainer(fields);
// --- 获取所有值 (HVALS) ---
vector<string> values;
auto it_values = std::back_inserter(values);
redis.hvals("key", it_values); // 将所有 value 取出来存在容器中
PrintContainer(values);
}深度分析与洞察:
- 顺序保证 :Redis 官方文档有一个非常重要的保证:
HKEYS返回的字段顺序和HVALS返回的值的顺序是完全一致的 。这意味着,你可以先用HKEYS获取所有字段,再用HVALS获取所有值,然后将这两个列表按索引一一对应,就能在客户端完整地重建整个 Hash 对象。 - 无序性 :虽然
HKEYS和HVALS之间的顺序是一致的,但 Hash 本身是无序数据结构。所以HKEYS返回的字段顺序不保证 与你插入时的顺序相同。例如,你按f1, f2, f3的顺序插入,返回的可能是f3, f1, f2。 - 性能警告 (O(N)) :
HKEYS和HVALS的时间复杂度都是 O(N),其中 N 是 Hash 中字段的数量。如果你的 Hash 包含数百万个字段,执行这两个命令可能会阻塞 Redis 服务器一段时间,影响其他客户端的请求。因此,在生产环境中,要对超大 Hash 谨慎使用这两个命令。
一个可能的输出结果是(顺序可能变化):
hkeys and hvals
f1 f2 f3
111 222 333 2.2 HMSET 与 HMGET:高效的批量读写双雄
HMSET 和 HMGET 是批量操作的典范。前者用于一次性设置多个字段,后者用于一次性获取多个指定字段的值。
cpp
void test5(sw::redis::Redis& redis)
{
cout << "hmset and hmget" << endl;
redis.flushall();
// --- HMSET (现在推荐用 HSET) ---
// 使用初始化列表批量设置
redis.hmset("key", {
std::make_pair("f1", "111"),
std::make_pair("f2", "222"),
std::make_pair("f3", "333")
});
// 使用迭代器从容器批量设置
vector<std::pair<string, string>> pairs = {
std::make_pair("f4", "444"),
std::make_pair("f5", "555"),
std::make_pair("f6", "666")
};
redis.hmset("key", pairs.begin(), pairs.end());
// 经过两次操作,"key" 中已有 f1 到 f6 六个字段
// --- HMGET ---
vector<string> values;
auto it = std::back_inserter(values);
// 按 "f1", "f2", "f3" 的顺序,批量获取它们的值
redis.hmget("key", {"f1", "f2", "f3"}, it);
PrintContainer(values); // 将容器中的数据打印出来
}深度分析与洞察:
HMSET的"退役" :如前所述,HMSET命令自 Redis 4.0.0 起被视为已废弃(deprecated),因为它能做的所有事情,新版的HSET都能做到。尽管老的客户端库和redis-plus-plus为了兼容性依然提供hmset接口,但我们应该在思想上将其与HSET的多参数版本视为一体。它们的核心价值在于------原子性地一次设置多个字段。HMGET的顺序与占位符 :HMGET最重要的特性是,它返回值的顺序与你请求字段的顺序严格对应。如果你请求hmget key f3 f99 f1,而f99并不存在,Redis 会返回一个包含三个元素的列表,第二个元素是nil,以作为占位符。redis-plus-plus在处理这种情况时,会向输出迭代器插入一个空的Optional对象,确保了位置的对应关系,这对于需要将结果与输入字段重新配对的场景极为有用。
test5 的执行结果非常明确,它会按照 {"f1", "f2", "f3"} 的请求顺序,准确地取回对应的值并打印:
hmset and hmget
111 222 333 第三章:实战场景与最佳实践
理论终须结合实践。Redis Hash 在真实世界中的应用非常广泛。
经典应用场景:
-
用户个人信息缓存 :这是最典型的场景。用
User:1001作为 Key,Hash 内部存储username,email,avatar,points,last_login_time等字段。当用户登录时,用HMGET一次性获取需要展示的基本信息。当用户签到增加积分时,只需一个HINCRBY(一个未在本文示例中但非常有用的原子增减命令) 命令即可,无需任何读-改-写操作。 -
电商商品详情页 :用
Product:8080作为 Key,Hash 内部存储name,price,stock,description,image_url等。商品价格或库存变动时,可以直接HSET单个字段,效率极高。 -
小型计数器聚合 :假设需要统计一篇文章的各种数据,如
views(浏览量)、likes(点赞数)、shares(分享数)。可以创建一个Article:Stats:55的 Hash Key,内部有views,likes,shares三个字段,每次操作都通过HINCRBY来原子地增加计数值。
最佳实践:
- 选择合适的粒度 :不要创建一个包含成千上万个字段的"巨无霸"Hash。这会导致
HKEYS等 O(N) 命令性能下降。如果一个对象的属性可以被清晰地分为几组(如用户的基本信息、账户信息、社交信息),可以考虑将其拆分为多个 Hash,例如User:Info:1001,User:Account:1001,User:Social:1001。 - 善用批量操作 :只要你需要一次性操作多个字段,就果断使用
HSET的多参数形式或HMGET。这是降低网络延迟、提升吞吐量的关键。 - 利用原子性 :
HINCRBY和HINCRBYFLOAT(用于浮点数增减) 是实现高性能、无锁计数器的不二之选。 - 警惕大 Value:虽然 Hash 的字段值可以是任意字符串,但存储巨大的值(如长篇文章、Base64编码的大图片)通常不是一个好主意。这会增加网络传输负担和 Redis 内存压力。对于大对象,更适合存储其元数据在 Hash 中,而将对象本身存放在专门的对象存储服务中。
结语
Redis Hash 远不止是一个简单的"二级 Map"。它是一种经过精心设计、在性能和内存效率之间取得了精妙平衡的高级数据结构。通过本文的层层剖析和代码实践,我们不仅学会了 HSET, HGET, HDEL, HMGET 等核心命令的使用方法,更重要的是,我们理解了它们背后的设计哲学------通过提供细粒度的、原子性的、可批量处理的接口,来高效地建模和操作结构化数据。
掌握了 Redis Hash,你便拥有了一把解决无数对象存储难题的瑞士军刀。现在,就去用它来构建你下一个更快速、更健壮、更优雅的应用程序吧!