文章目录
- 集群
- [高可用-Keepalived 全解析](#高可用-Keepalived 全解析)
集群
集群概念
集群是什么
集群(cluster)是由一组独立的计算机系统构成的一个松耦合的多处理器系统,作为一个整体向用户提供一组网络资源,这些单个的计算机系统就是集群的节点(node)。它们之间通过网络实现进程间的通信。
通俗一点来说,就是让若干台计算机联合起来工作(服务),可以是并行的,也可以是做备份。
集群类型
Load Balance cluster(负载均衡集群)
即把负载压力根据某种算法合理分配到集群中的每一台计算机上,以减轻主服务器的压力,降低对主服务器的硬件和软件要求。
例如:四兄弟开裁缝铺,生意特别多,一个人做不下来,老是延误工期,于是四个兄弟商量:老大接订单, 三个兄弟来干活。客户多起来之后,老大根据一定的原则(policy) 根据三兄弟手上的工作量来分派新任务。
High Availability cluster(高可用集群)
利用集群管理软件,当主服务器故障时,备份服务器能够自动接管主服务器的工作,并及时切换过去,以实现对用户的不间断服务。
例如:两兄弟开早餐铺,生意不大,但是每天早上7点到9点之间客户很多并且不能中断。为了保证2个小时内这个早餐铺能够保证持续提供服务,两兄弟商量几个方法:
方法一:平时老大做生意,老二这个时间段在家等候,一旦老大无法做生意了,老二就出来顶上,这个叫做 Active/Standby(双机冷备)
方法二:平时老大做生意,老二这个时候就在旁边帮工,一旦老大无法做生意,老二就马上顶上,这个叫做Active/Passive(双机热备)
方法三:平时老大卖包子,老二也在旁边卖豆浆,老大有问题,老二就又卖包子,又卖豆浆,老二不行了,老大就又卖包子,又卖豆浆。这个叫做Active/Active (dual Active)(双机互备)。
High Performance Computing clustering(高性能计算集群)
即充分利用集群中的每一台计算机的资源,实现复杂运算的并行处理,通常用于科学计算领域,比如基因分析、化学分析等。
例如:10个兄弟一起做手工家具生意,一个客户来找他们的老爹要求做一套非常复杂的仿古家具,一个人做也可以做,不过要做很久很久,为了1个星期就交出这一套家具,10个兄弟决定一起做。老爹把这套家具的不同部分分开交给儿子们作,然后每个儿子都在做木制家具的加工,最后拼在一起。老爹是scheduler任务调度器,儿子们是compute node. 他们做的工作叫做作业。
负载均衡集群
LB集群的主要功能就是解决如何在Real Servers前添加一台主机作为调度器,从而将客户端请求按照某种算法调度给后端主机。
实现方式
按照调度器通过硬件实现还是软件实现,可以分为:
硬件实现调度器:
- F5 Big-IP
- Citrix NetScaler
- A10
- Radware
- Array
软件实现调度器:
- Nginx
- LVS
- HAProxy
按照调度器工作在OSI协议的哪一层,可以分为:
传输层(内核空间,四层调度)
- LVS
- HAProxy(mode tcp)
应用层(用户空间,七层调度)
- HAProxy(mode http)
- Nginx
应用类型
HTTP 重定向负载均衡
当用户发来请求的时候,Web服务器通过修改HTTP响应头中的Location标记来返回一个新的url,然后浏览器再继续请求这个新url,实际上就是页面重定向。通过重定向,来达到"负载均衡"的目标。
优点:比较简单。
缺点:浏览器需要两次请求服务器才能完成一次访问,性能较差。重定向服务自身的处理能力有可能成为瓶颈,整个集群的伸缩性规模有限;使用HTTP302响应码重定向,有可能使搜索引擎判断为SEO作弊,降低搜索排名。
反向代理负载均衡
反向代理服务可以缓存资源以改善网站性能。实际上,在部署位置上,反向代理服务器处于Web服务器前面(这样才可能缓存Web相应,加速访问),这个位置也正好是负载均衡服务器的位置,所以大多数反向代理服务器同时提供负载均衡的功能,管理一组Web服务器,将请求根据负载均衡算法转发到不同的Web服务器上。Web服务器处理完成的响应也需要通过反向代理服务器返回给用户。由于web服务器不直接对外提供访问,因此Web服务器不需要使用外部ip地址,而反向代理服务器则需要配置双网卡和内部外部两套IP地址。
优点:和反向代理服务器功能集成在一起,部署简单。
缺点:反向代理服务器是所有请求和响应的中转站,其性能可能会成为瓶颈。
DNS 域名解析负载均衡
DNS(Domain Name System)负责域名解析的服务,域名url实际上是服务器的别名,实际映射是一个IP地址,解析过程,就是DNS完成域名到IP的映射。而一个域名是可以配置成对应多个IP的。因此,DNS也就可以作为负载均衡服务。事实上,大型网站总是部分使用DNS域名解析,利用域名解析作为第一级负载均衡手段,即域名解析得到的一组服务器并不是实际提供Web服务的物理服务器,而是同样提供负载均衡服务的内部服务器,这组内部负载均衡服务器再进行负载均衡,将请求分发到真是的Web服务器上。
优点:将负载均衡的工作转交给DNS,省掉了网站管理维护负载均衡服务器的麻烦,同时许多DNS还支持基于地理位置的域名解析,即会将域名解析成举例用户地理最近的一个服务器地址,这样可以加快用户访问速度,改善性能。
缺点:不能自由定义规则,而且变更被映射的IP或者机器故障时很麻烦,还存在DNS生效延迟的问题。而且DNS负载均衡的控制权在域名服务商那里,网站无法对其做更多改善和更强大的管理。
调度算法简介
- 轮询,按客户端请求顺序把客户端的请求逐一分配到不同的后端节点服务器。
- 加权轮询,**在轮询算法的基础上加上权重。**当使用该算法时,权重和用户访问成正比,权重值越大,被转发的请求也就越多。 可以根据服务器的配置和性能指定权重值大小,有效解决新旧服务器性能不均带来的请求分配问题。
- 最少连接数 ,将请求分发给后端节点服务器连接数最少的那个机器。
- 最快响应,根据后端节点服务器的响应时间来分配请求,响应时间短的优先分配。
- Hash 法,对客户端IP或者访问的URL做hash运算,根据hash结果来分配请求的,让每个请求定向到同一个后端服务器,后端服务器为缓存服务器时效果显著。
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 轮询 | 静态、稳定 | 不关心服务端负载,服务端处理能力的波动可能产生堵塞 | 服务端处理能力相同且稳定性高 |
| 加权轮询 | 静态、稳定,允许服务端性能差异 | 不关心服务端负载,服务端处理能力的波动可能产生堵塞 | 服务端处理能力符合预期且稳定性高 |
| 最少连接 | 动态、实时变化 | 复杂度提升,每次开关连接时需要计数 | 服务端处理能力有波动 |
| 最快响应 | 动态、实时变化,支持到请求级别,比最少连接更灵敏 | 复杂度提升,需要计算请求的响应时间 | 服务端处理能力有波动 |
| Hash | 算法稳定 | 由客户端决定分布,可能导致分布不均 | 同一个客户端和服务端需要会话保持 |
高可用-Keepalived 全解析
HA 集群能解决哪些问题?
当计划使用HA集群时候,有一个重要的问题需要回答:服务放到HA集群中,可用性是否会增加?
回答这个问题,需要弄清楚服务的能力和该服务的客户端如何配置。
-
取决于解决方案,例如DNS和LDAP自带故障转移或者负载均衡,放到HA集群中没什么好处。DNS或者LDAP服务使用多个服务,具备master/slave角色,或者多个master关系。该服务可在多个服务器之间配置数据冗余。DNS和LDAP的客户端也可以使用多个服务器,这里就没有故障转移,因此,这种服务放置到HA集群中不会增加服务的可用性。
-
那些未自带Failover或者LB的服务,如果配置为HA集群,将会有很多好处。例如在 Openstack 平台解决方案中,将 RabbitMQ 和 Galera 放置到HA集群中,可以带来很多好处。
并不是每个可用性问题都可以通过HA集群解决:
-
如果应用程序存因bug导致crash,即使配置为HA集群,应用同样会crash。这种情况下,服务将会转移到其他节点。但是其他节点上的应用也存在相同的bug问题,同样会导致crash。
-
HA集群同样不提供端到端的冗余。集群本身可以正常提供服务,但是网络架构存在问题,导致集群不可达,客户端仍然无法访问服务。因此需要慎重考虑集群架构,避免单点故障,包括集群中的任何组件。
Keepalived 介绍
Keepalived 是一个用 C 语言编写的路由软件。这个项目的主要目标是为 Linux 系统和基于 Linux 的基础设施的负载平衡和高可用性提供简单而健壮的设施。
Keepalived 起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态,它根据TCP/IP参考模型的第三、第四层、第五层机制检测每个服务节点的状态,如果某个服务器节点出现异常,或者工作出现故障,Keepalived将检测到,并将出现的故障的服务器节点从集群系统中剔除,这些工作全部是自动完成的,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点。
后来Keepalived又加入了VRRP的功能,VRRP(Vritrual Router Redundancy Protocol,虚拟路由冗余协议)出现的目的是解决静态路由出现的单点故障问题,通过VRRP可以实现网络不间断稳定运行,因此Keepalvied 一方面具有服务器状态检测和故障隔离功能,另外一方面也有HA cluster功能。
VRRP 协议
在现实的网络环境中,主机之间的通信都是通过配置静态路由或者(默认网关)来完成的,而主机之间的路由器一旦发生故障,通信就会失效。因此这种通信模式当中,路由器就成了一个单点瓶颈,为了解决这个问题,就引入了VRRP协议。
VRRP协议是一种主备模式的协议,通过VRRP可以在网络发生故障时透明的进行设备切换而不影响主机之间的数据通信。
VRRP可以将两台或者多台物理路由器 设备虚拟成一个虚拟路由,这个虚拟路由器通过虚拟IP(一个或者多个)对外提供服务,而在虚拟路由器内部十多个物理路由器协同工作,同一时间只有一台物理路由器对外提供服务,这台物理路由设备被成为:主路由器(Master角色),一般情况下Master是由选举算法产生,它拥有对外服务的虚拟IP,提供各种网络功能,如:ARP请求,ICMP 数据转发等,而且其它的物理路由器不拥有对外的虚拟IP,也不提供对外网络功能,仅仅接收MASTER的VRRP状态通告信息,这些路由器被统称为"BACKUP的角色",当主路由器失败时,处于BACKUP角色的备份路由器将重新进行选举,产生一个新的主路由器进入MASTER角色,继续提供对外服务,整个切换对用户来说是完全透明的。
每个虚拟路由器都有一个唯一的标识号,称为VRID,一个VRID与一组IP地址构成一个虚拟路由器,在VRRP协议中,所有的报文都是通过IP多播方式发送的,而在一个虚拟路由器中,只有处于Master角色的路由器会一直发送VRRP数据包,处于BACKUP角色的路由器只会接受Master角色发送过来的报文信息,用来监控Master运行状态,一般不会发生BACKUP抢占的情况,除非它的优先级更高,而当MASTER不可用时,BACKUP也就无法收到Master发过来的信息,于是就认定Master出现故障,接着多台BAKCUP就会进行选举,优先级最高的BACKUP将称为新的MASTER,这种选举角色切换非常之快,因而保证了服务的持续可用性。
工作原理
Keepalived通过VRRP实现高可用性,它还能实现对集群中服务器运行状态的监控以及故障隔离。
Keepalived工作在TCP/IP 参考模型的 三层、四层、七层,也就是分别为:网络层,传输层和应用层。
根据TCP/IP参数模型隔层所能实现的功能,Keepalived运行机制如下:
-
网络层 :提供四个重要的协议,互联网络IP 协议、互联网络可控制报文协议ICMP 、地址转换协议ARP 、反向地址转换协议RARP。
Keepalived在网络层采用最常见的工作方式是**通过ICMP协议向服务器集群中的每一个节点发送一个ICMP数据包(**有点类似与Ping的功能),如果某个节点没有返回响应数据包,那么认为该节点发生了故障,Keepalived将报告这个节点失效,并从服务器集群中剔除故障节点。
-
传输层:提供两个主要的协议:传输控制协议TCP和用户数据协议UDP。传输控制协议TCP可以提供可靠的数据输出服务、IP地址和端口,代表TCP的一个连接端,要获得TCP服务,需要在发送机的一个端口和接收机的一个端口上建立连接。
Keepalived在传输层里利用了TCP协议的端口连接和扫描技术来判断集群节点的端口是否正常,比如对于常见的WEB服务器80端口。或者SSH服务22端口,Keepalived一旦在传输层探测到这些端口号没有数据响应和数据返回,就认为这些端口发生异常,然后强制将这些端口所对应的节点从服务器集群中剔除掉。
-
应用层:可以运行FTP,TELNET,SMTP,DNS等各种不同类型的高层协议,Keepalived的运行方式也更加全面化和复杂化,用户可以通过自定义Keepalived工作方式,例如:可以通过编写程序或者脚本来运行Keepalived,而Keepalived将根据用户的设定参数检测各种程序或者服务是否允许正常,如果Keepalived的检测结果和用户设定的不一致时,Keepalived将把对应的服务器从服务器集群中剔除。
Keepalvied 高可用技术实践
网络拓扑
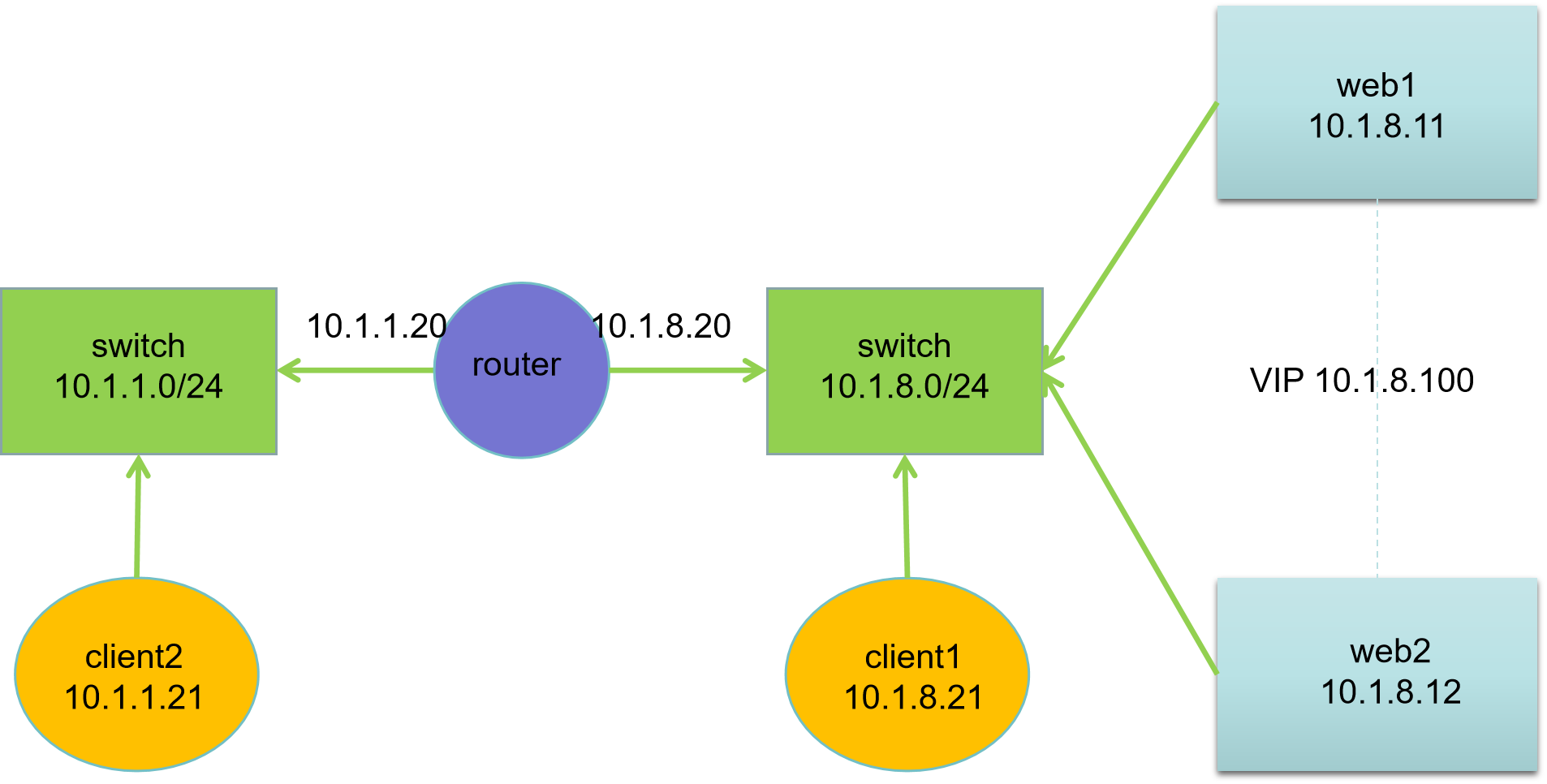
| 主机名 | IP地址 | 服务器角色 |
|---|---|---|
| client2.ghl.cloud | 10.1.1.21 | 客户端 |
| client1.ghl.cloud | 10.1.8.21 | 客户端 |
| router.ghl.cloud | 10.1.1.20, 10.1.8.20 | 路由器 |
| web1.ghl.cloud | 10.1.8.11 | Web 服务器 |
| web2.ghl.cloud | 10.1.8.12 | Web 服务器 |
网络说明:
- 所有主机:第一块网卡名为 ens33,第二块网卡名为 ens192
- 默认第一块网卡模式为 nat,第二块网卡模式为 hostonly
- 网关设置:10.1.1.0/24 网段网关为10.1.1.20,10.1.8.0/24 网段网关为10.1.8.20
配置集群的克隆模板
bash
# 1 命令提示符
# 2 关闭 selinux
# 3 关闭防火墙
# 4 配置本地仓库
# 5 安装基础软件包
# 6 配置 ssh
# 1 配置命令提示符
vi /etc/bashrc
# 文件末尾添加一行
PS1='[\[\e[91m\]\u\[\e[93m\]@\[\e[92;1m\]\h\[\e[0m\] \[\e[94m\]\W\[\e[0m\] \[\e[35m\]\t\[\e[0m\]]\[\e[93m\]\$\[\e[0m\] '
# 2 关闭 selinux
sed -i '/^SELINUX=/cSELINUX=disabled' /etc/selinux/config
# 3 关闭防火墙
systemctl disable firewalld --now
# 4 配置仓库
curl -s -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
curl -s -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
# 5 安装基础软件包
yum install -y bash-completion vim open-vm-tools lrzsz unzip rsync sshpass
# 6 优化 ssh 配置
echo 'StrictHostKeyChecking no' >> /etc/ssh/ssh_config
echo 'UseDNS no' >> /etc/ssh/sshd_config
# 开发系统主机名和IP地址设置脚本
# 该脚本配置网段为10.1.8.0网段,10.1.1.0网段需另行配置
[root@centos7 ~ 14:42:19]# touch /usr/local/bin/sethost && chmod +x /usr/local/bin/sethost
[root@centos7 ~ 14:42:19]# cat > /usr/local/bin/sethost <<'EOF'
#!/bin/bash
num=$1
case $num in
11)
HOSTNAME=web1.ghl.cloud
IP=10.1.8.11
GATEWAY=10.1.8.20
;;
12)
HOSTNAME=web2.ghl.cloud
IP=10.1.8.12
GATEWAY=10.1.8.20
;;
20)
HOSTNAME=router.ghl.cloud
IP=10.1.8.20
GATEWAY=10.1.8.2
;;
21)
HOSTNAME=client1.ghl.cloud
IP=10.1.8.21
GATEWAY=10.1.8.20
;;
*)
echo "Usage: $0 11|12|20|21"
exit
;;
esac
# set hostname
hostnamectl set-hostname $HOSTNAME
# network
nmcli connection modify ens33 ipv4.addresses $IP/24 ipv4.gateway $GATEWAY ipv4.dns 223.5.5.5 +ipv4.dns 223.6.6.6
nmcli connection up ens33
EOF
[root@centos7 ~ 14:42:35]# sethost 20
[root@centos7 ~ 14:42:35]# bash
[root@router ~ 14:42:35]# cat > /etc/hosts <<EOF
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.1.8.11 web1.ghl.cloud web1
10.1.8.12 web2.ghl.cloud web2
10.1.8.21 client1.ghl.cloud client1
10.1.1.21 client2.ghl.cloud client2
10.1.8.20 router.ghl.cloud router
EOFHA集群环境准备:
-
创建一个目录cluster,专门由于存储集群虚拟机,例如D:\VmWare17\cluster。
-
设置 vmware 选项,虚拟机默认位置为该目录 E:\VmWare17\cluster,每个虚拟机存放到自己的目录,例如client1存放到E:\VmWare17\cluster\client1。
-
连接克隆出需要的虚拟机。
-
根据拓扑图修改虚拟机网卡模式:
例如,router 添加一块10.1.1.0/0 网段网卡
修改 client2 网卡模式为hostonly vmnet1
-
设置主机名和IP地址
bashweb1 设置 sethost 11 web2 设置 sethost 12 client1 设置 sethost 21 router 网络设置 [root@router ~ 15:12:09]# sethost 20 # 半图形化配置 [root@router ~ 15:12:09]# nmtui # 或者 # [root@router ~ 15:12:09]# nmcli connection modify 59acc699-e9be-3b13-a476-ba5217abd299 con-name ens37 ipv4.method manual ipv4.addresses 10.1.1.20/24 [root@router ~ 15:12:09]# nmcli connection up ens37 client2 设置 # 半图形化配置 [root@router ~ 15:12:09]# nmtui # 或者 # [root@client2 ~ 15:16:23]# hostnamectl set-hostname client2.ghl.cloud [root@client2 ~ 15:16:23]# nmcli connection modify ens33 ipv4.addresses 10.1.1.21/24 ipv4.gateway 10.1.1.20 ipv4.dns 223.5.5.5 +ipv4.dns 223.6.6.6 [root@client2 ~ 15:16:23]# nmcli connection up ens33 -
配置 router 免密登录所有节点
bash# 创建秘钥对 [root@router ~ 11:51:45]# ssh-keygen -f .ssh/id_rsa -t rsa -N '' # 安装 sshpass,自动填充 ssh 登录时使用的密码 [root@router ~ 13:50:40]# sshpass -p redhat ssh root@web1 hostname web1.ghl.cloud # 配置秘钥登录其他节点 [root@router ~ 11:51:47]# for host in web1 web2 client1 client2 router;do sshpass -p redhat ssh-copy-id root@$host;done [root@router ~ 11:51:47]# for host in web1 web2 client1 client2 router;do ssh root@$host hostname;done web1.ghl.cloud web2.ghl.cloud client1.ghl.cloud client2.ghl.cloud router.ghl.cloud # 验证主机名和网络配置 [root@router ~ 15:19:54]# for host in web1 web2 client1 client2 router;do ssh root@$host 'hostname;ip -br a |grep -v lo;ip r|grep default;echo';done
配置 router
bash
# 开启路由
[root@router ~ 15:29:00]# echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
# 或者
# [root@router ~ 15:29:00]# sed -i "s/ip_forward=0/ip_forward=1/g" /etc/sysctl.conf
[root@router ~ 15:43:37]# sysctl -p
net.ipv4.ip_forward = 1
#此时10.1.8.0/24网段可访问公网
# 设置防火墙,开启SNAT功能,实现不同网段也可以访问公网
[root@router ~ 15:43:50]# systemctl enable firewalld.service --now
[root@router ~ 15:47:46]# firewall-cmd --add-masquerade --permanent
[root@router ~ 15:48:05]# firewall-cmd --add-masquerade配置 web
bash
# 部署web1、web2,相同操作
[root@web1 ~ 15:44:39]# yum install -y nginx
[root@web1 ~ 15:51:35]# echo Welcome to $(hostname) > /usr/share/nginx/html/index.html
[root@web1 ~ 15:51:35]# systemctl enable nginx.service --now
# 访问后端 nginx
[root@router ~ 15:48:12]# curl 10.1.8.11
Welcome to web1.ghl.cloud
[root@router ~ 15:52:06]# curl 10.1.8.12
Welcome to web2.ghl.cloud配置 keepalived
配置 web2
web2 作为备节点。
bash
[root@web2 ~ 15:51:54]# yum install -y keepalived
[root@web2 ~ 15:55:04]# cp /etc/keepalived/keepalived.conf{,.ori}
[root@web2 ~ 16:03:50]# vim /etc/keepalived/keepalived.conf
bash
! Configuration File for keepalived
global_defs {
router_id web2
}
vrrp_instance nginx {
state BACKUP
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass Ghl@123
}
virtual_ipaddress {
10.1.8.100
}
}说明:
router_id web2,定义路由器名称,每个节点使用不同的名称。state BACKUP,定义节点角色为备节点,MASTER则代表主节点。interface ens33,定义VIP配置到该接口。virtual_router_id 51,定义虚拟路由器ID,范围1-255,每个节点使用相同名称。priority 100,定义节点优先级,值越大优先级越高。authentication,定义心跳认证。virtual_ipaddress,定义虚拟VIP。
bash
# 启动 keepalived 服务
[root@web2 ~ 16:07:18]# systemctl enable keepalived.service --now
# 查看 IP
[root@web2 ~ 16:07:41]# ip -br a show ens33
ens33 UP 10.1.8.12/24 10.1.8.100/32 fe80::20c:29ff:fedf:1564/64
# 此时其他主机访问10.1.8.100
[root@router ~ 15:52:08]# curl http://10.1.8.100
Welcome to web2.ghl.cloud配置 web1
web1 作为主节点。
bash
[root@web1 ~ 15:51:38]# yum install -y keepalived
[root@web1 ~ 15:55:17]# cp /etc/keepalived/keepalived.conf{,.ori}
[root@web1 ~ 16:09:27]# vim /etc/keepalived/keepalived.conf
bash
! Configuration File for keepalived
global_defs {
router_id web1
}
vrrp_instance nginx {
state MASTER
interface ens33
virtual_router_id 51
priority 200
# master节点优先级要高于BACKUP节点
advert_int 1
authentication {
auth_type PASS
auth_pass Ghl@123
}
virtual_ipaddress {
10.1.8.100
}
}
bash
# 启动服务
[root@web1 ~ 16:11:32]# systemctl enable keepalived.service --now
# 查看 IP,VIP 切换到 web1
[root@web1 ~ 16:11:45]# ip -br a show ens33
ens33 UP 10.1.8.11/24 10.1.8.100/32 fe80::20c:29ff:fede:fc6d/64
# 此时web2的IP及VIP
[root@web2 ~ 16:07:55]# ip -br a show ens33
ens33 UP 10.1.8.12/24 fe80::20c:29ff:fedf:1564/64
# 此时其他主机访问10.1.8.100
[root@router ~ 16:09:12]# curl http://10.1.8.100
Welcome to web1.ghl.cloud高可用验证
bash
# 访问 web
[root@router ~ 16:09:12]# curl http://10.1.8.100
Welcome to web1.ghl.cloud
# 关闭 web1 的 keepalive服务,再次访问
[root@web1 ~ 16:11:57]# systemctl stop keepalived.service
# 再次启动 web1 的keepalive服务,再次访问
[root@web1 ~ 16:13:54]# systemctl start keepalived.service
# 持续监控web页面
[root@router ~ 16:12:03]# while true;do curl -s http://10.1.8.100;sleep 1;done
Welcome to web1.ghl.cloud
......
Welcome to web2.ghl.cloud
......
Welcome to web1.ghl.cloud
......