一:__init__方法
参数
python
def __init__(self, args : ModelParams, gaussians : GaussianModel, load_iteration=None, shuffle=True, resolution_scales=[1.0]):定义 Scene 类的构造函数 __init__。当创建一个 Scene 对象时,这个方法会被调用。
-
args : ModelParams: 包含模型和数据路径相关参数的对象(实际上是GroupParams类型,但行为像ModelParams)。 -
gaussians : GaussianModel: 一个GaussianModel的实例,它将被这个场景所管理。 -
load_iteration=None: 一个可选参数,指定要加载的预训练模型的迭代次数。如果为None,则表示从头开始训练。 -
shuffle=True: 一个布尔值,决定是否在加载后打乱训练和测试相机的顺序。这在训练时有助于增加随机性。 -
resolution_scales=[1.0]: 一个浮点数列表,用于加载不同分辨率的图像。默认为[1.0],即只加载原始(或由-r参数缩放后的)分辨率的图像。
场景类型检测和数据加载
python
if os.path.exists(os.path.join(args.source_path, "sparse")):
scene_info = sceneLoadTypeCallbacks["Colmap"](args.source_path, args.images, args.depths, args.eval, args.train_test_exp)
elif os.path.exists(os.path.join(args.source_path, "transforms_train.json")):
print("Found transforms_train.json file, assuming Blender data set!")
scene_info = sceneLoadTypeCallbacks["Blender"](args.source_path, args.white_background, args.depths, args.eval)
else:
assert False, "Could not recognize scene type!"-
sceneLoadTypeCallbacks是一个在dataset_readers.py中定义的字典,它将字符串(如 "Colmap")映射到相应的数据读取函数(如readColmapSceneInfo)。 -
代码检查
args.source_path目录下是否存在sparse文件夹来判断是否是 COLMAP 格式的数据集。 -
如果不是,它会检查是否存在
transforms_train.json文件来判断是否是 Blender/NeRF Synthetic 格式的数据集。 -
根据判断结果,调用相应的读取函数加载所有场景信息(包括点云、相机等),并存入
scene_info变量中。
由于我们采用colmap产生初始点云,所以我们仔细分析
python
scene_info = sceneLoadTypeCallbacks["Colmap"](args.source_path, args.images, args.depths, args.eval, args.train_test_exp)sceneLoadTypeCallbacks是字典类型
python
sceneLoadTypeCallbacks = {
"Colmap": readColmapSceneInfo,
"Blender" : readNerfSyntheticInfo
}sceneLoadTypeCallbacks"Colmap"取出readColmapSceneInfo并且传参调用
readColmapSceneInfo
python
def readColmapSceneInfo(path, images, depths, eval, train_test_exp, llffhold=8):参数:
-
path: COLMAP 场景的根目录路径。 -
images: 存放图像的子目录名(例如 "images", "images_4")。 -
depths: 存放深度图的子目录名。 -
eval: 一个布尔值,True表示要为评估模式创建训练/测试集分割。 -
train_test_exp: 一个布尔值,用于处理曝光补偿的特殊训练/测试集分割。 -
llffhold=8: 一个整数,在eval模式下,用于 LLFF 类型的数据集分割,表示每隔llffhold张图像就选一张作为测试图像。
python
try:
cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.bin")
cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.bin")
cam_extrinsics = read_extrinsics_binary(cameras_extrinsic_file)
cam_intrinsics = read_intrinsics_binary(cameras_intrinsic_file)
except:
cameras_extrinsic_file = os.path.join(path, "sparse/0", "images.txt")
cameras_intrinsic_file = os.path.join(path, "sparse/0", "cameras.txt")
cam_extrinsics = read_extrinsics_text(cameras_extrinsic_file)
cam_intrinsics = read_intrinsics_text(cameras_intrinsic_file)读取相机的内外参数,colmap一般用二进制文件bin或者文本文件txt格式保存。
这两行代码的作用就像是**"数据搬运工"**。它们的任务非常单纯:打开 COLMAP 的 .bin 文件,按照文件格式把里面的二进制数据一个字节一个字节地读出来,然后存放到 cam_extrinsics 和 cam_intrinsics 这两个字典里。
此时,字典里的数据还是**"原材料"**状态:
-
旋转是以四元数 (
qvec) 的形式存储的,而不是渲染器需要的 3x3 旋转矩阵。 -
内参是以焦距 (
fx,fy) 的形式存储的,而不是渲染器需要的视场角 (FoV)。 -
内外参是分离的,程序还不知道哪张图片对应哪个相机内参
cam_extrinsics
cam_extrinsics 这个字典存储了 COLMAP 重建出的每一张输入图像(相机)的外部参数和相关信息。
-
键 (Key) :字典的键是
image_id,这是一个整数,是 COLMAP 为每张图像分配的唯一标识符。 -
值 (Value) :字典的值是一个
Image对象(具体来说是一个namedtuple),这个对象里包含了这张图像的所有外参信息。
一个 Image 对象包含以下关键数据字段:
-
id:-
数据 :整数,就是这张图像的
image_id,与字典的键相同。 -
含义:图像的唯一ID。
-
-
qvec:-
数据 :一个包含4个浮点数的 NumPy 数组 (
[qw, qx, qy, qz])。 -
含义 :表示相机旋转 的四元数 (quaternion)。它定义了相机坐标系相对于世界坐标系的方向。
-
-
tvec:-
数据 :一个包含3个浮点数的 NumPy 数组 (
[tx, ty, tz])。 -
含义 :表示相机平移 的向量 (translation vector)。它定义了相机中心在世界坐标系中的位置。
-
-
camera_id:-
数据:一个整数。
-
含义 :这是一个外键 ,指向
cam_intrinsics字典。它告诉程序这张图像使用的是哪个相机的内部参数(如焦距、分辨率等)。通过这个 ID,可以将外参和内参关联起来。
-
-
name:-
数据:一个字符串。
-
含义 :这张图像的文件名 ,例如
"image001.jpg"。
-
-
xys:-
数据 :一个
[N, 2]的 NumPy 数组。 -
含义 :一个二维点列表,记录了在这张图像上被成功匹配并用于三维重建的所有特征点的 2D 像素坐标 (x, y)。
-
-
point3D_ids:-
数据 :一个长度为
N的 NumPy 数组。 -
含义 :与上面的
xys列表一一对应。这个数组里的每个元素是一个整数 ID,指向了重建出的三维点云中的一个 3D 点。 -
关联 :
xys中的第 i 个 2D 特征点,对应的是三维空间中 ID 为point3D_ids[i]的那个 3D 点。这个信息对于将 2D 图像和 3D 场景联系起来至关重要
-
由于输入79张图片,所以返回79个对象
cam_intrinsics
cam_intrinsics 描述的就是相机自身的物理属性。它定义了三维空间中的点是如何通过相机镜头投影到二维图像平面上的。
-
键 (Key) :字典的键是
camera_id,这是一个整数,是 COLMAP 为每一种相机型号或配置分配的唯一标识符。 -
值 (Value) :字典的值是一个
Camera对象(同样是一个namedtuple),这个对象里包含了该相机型号的所有内部参数。
一个 Camera 对象包含以下关键数据字段:
-
id:-
数据 :整数,就是这个相机的
camera_id,与字典的键相同。 -
含义:相机型号的唯一ID。
-
-
model:-
数据 :一个字符串,例如
"PINHOLE"或"SIMPLE_PINHOLE"。 -
含义 :相机的数学模型 。这个项目明确指出,虽然加载器支持多种模型,但后续代码假设使用的是理想的针孔相机模型 (PINHOLE),这意味着输入的图像应该是没有畸变的。
-
-
width:-
数据:一个整数。
-
含义 :图像的宽度(以像素为单位)。
-
-
height:-
数据:一个整数。
-
含义 :图像的高度(以像素为单位)。
-
-
params:-
数据:一个包含浮点数的 NumPy 数组。
-
含义 :相机的核心内参 。对于
PINHOLE模型,这个数组通常包含4个值:[fx, fy, cx, cy]。-
fx,fy:相机的焦距,分别表示在 x 和 y 方向上的焦距(以像素为单位)。它决定了相机的视场角 (Field of View)。 -
cx,cy:主点 (Principal Point) 的坐标,即相机光轴与图像平面的交点,通常接近图像的中心点。
-
-

python
depth_params_file = os.path.join(path, "sparse/0", "depth_params.json")
## if depth_params_file isnt there AND depths file is here -> throw error
depths_params = None
if depths != "":
try:
with open(depth_params_file, "r") as f:
depths_params = json.load(f)
all_scales = np.array([depths_params[key]["scale"] for key in depths_params])
if (all_scales > 0).sum():
med_scale = np.median(all_scales[all_scales > 0])
else:
med_scale = 0
for key in depths_params:
depths_params[key]["med_scale"] = med_scale
except FileNotFoundError:
print(f"Error: depth_params.json file not found at path '{depth_params_file}'.")
sys.exit(1)
except Exception as e:
print(f"An unexpected error occurred when trying to open depth_params.json file: {e}")
sys.exit(1)这段代码负责处理深度图的缩放和平移参数,这对于深度正则化功能是必需的。
-
它构建
depth_params.json文件的路径。 -
如果用户提供了深度图目录 (
depths != ""),它会尝试打开并加载这个 JSON 文件。 -
depth_params.json文件中存储了每张深度图需要应用的缩放 (scale) 和偏移 (offset) 值,以使其与 COLMAP 重建的 3D 点云的尺度对齐
这里我有个问题,就是我发现colmap并没有产生depth_params.json文件,原因如下:
depth_params.json 文件不是 由标准的 COLMAP 初始化过程(即运行 convert.py)生成的。这是一个需要额外手动步骤 才能创建的文件,并且它只在使用深度正则化 (depth regularization) 这个新功能时才需要。
根本原因
convert.py 脚本的核心作用是调用 COLMAP 来处理你的输入图像,并生成相机位姿和稀疏点云 (sparse/0 目录下的文件)。它本身并不知道任何关于深度图的信息。
depth_params.json 文件的作用是建立外部生成的深度图与 COLMAP 场景尺度之间的联系。由于从单个图像预测的深度(单目深度估计)通常只有一个相对的尺度,我们需要一个方法来将它对齐到 COLMAP 重建出的真实世界尺度上。
正确的生成流程
要生成 depth_params.json 文件,你需要遵循 README.md 中"Depth regularization"部分描述的流程,这分为两个主要阶段:
-
为你的每一张输入图片生成深度图:
-
你需要使用一个第三方的深度估计算法。
README.md推荐使用 Depth Anything v2。 -
你需要为
/input文件夹中的每一张图片都生成一张对应的深度图,并把它们保存在一个单独的文件夹里(例如,/depths)。
-
-
运行
make_depth_scale.py脚本:-
在生成了所有深度图之后,你需要运行项目提供的
utils/make_depth_scale.py脚本。 -
这个脚本会读取你的 COLMAP 数据(
sparse/0)和你刚刚生成的深度图。 -
它会比较 COLMAP 的 3D 点在每张图像上的投影深度和你的深度图在相应位置的深度值,然后计算出将两者对齐所需的缩放 (scale) 和偏移 (offset) 参数。
-
最后,它会将计算出的这些参数写入到
sparse/0/depth_params.json文件中。
-
如何产生depth_params.json文件?
-
确保你已经有了每张图片的深度图。
-
运行
python utils/make_depth_scale.py脚本来计算对齐参数并生成depth_params.json文件。
只有完成了这些步骤,你才能在运行 train.py 时通过 -d <path_to_depths> 参数来成功启用深度正则化功能。
python
if eval:
if "360" in path:
llffhold = 8
if llffhold:
print("------------LLFF HOLD-------------")
cam_names = [cam_extrinsics[cam_id].name for cam_id in cam_extrinsics]
cam_names = sorted(cam_names)
test_cam_names_list = [name for idx, name in enumerate(cam_names) if idx % llffhold == 0]
else:
with open(os.path.join(path, "sparse/0", "test.txt"), 'r') as file:
test_cam_names_list = [line.strip() for line in file]
else:
test_cam_names_list = []eval 标志来决定哪些相机图片属于测试集。
-
如果
eval为False,则test_cam_names_list为空,所有图片都用于训练。 -
如果
eval为True:-
对于 Mip-NeRF 360 数据集,采用
llffhold的方式,即每隔8张图片选1张作为测试图。 -
对于其他数据集,它会尝试读取一个名为
test.txt的文件,该文件明确列出了所有测试图片的名称。
-
python
reading_dir = "images" if images == None else images
cam_infos_unsorted = readColmapCameras(
cam_extrinsics=cam_extrinsics, cam_intrinsics=cam_intrinsics, depths_params=depths_params,
images_folder=os.path.join(path, reading_dir),
depths_folder=os.path.join(path, depths) if depths != "" else "", test_cam_names_list=test_cam_names_list)
cam_infos = sorted(cam_infos_unsorted.copy(), key = lambda x : x.image_name)-
它调用了本文件中的另一个函数
readColmapCameras。 -
readColmapCameras会遍历所有从.bin或.txt文件中读取的相机内外参,并将它们整合成一个CameraInfo对象的列表。每个CameraInfo对象包含了每个图片的相机的旋转、平移、视场角、图像路径等所有信息。 -
最后,它根据图像名称对这个列表进行排序,以保证一个确定的顺序
python
train_cam_infos = [c for c in cam_infos if train_test_exp or not c.is_test]
test_cam_infos = [c for c in cam_infos if c.is_test]根据 is_test 标志,将 cam_infos 列表分割为训练相机列表和测试相机列表。
getNerfppNorm(cam_info)
python
nerf_normalization = getNerfppNorm(train_cam_infos)调用 getNerfppNorm 函数,该函数会计算所有训练相机的位置中心 ,并确定一个包围所有相机的球体的半径。这个信息 (nerf_normalization) 对于后续归一化场景坐标和设置致密化范围非常重要
python
for cam in cam_info:
#根据相机的旋转和平移矩阵求出世界坐标系到相机坐标系的变换矩阵
W2C = getWorld2View2(cam.R, cam.T)
# W2C 求逆,得到相机坐标系到世界坐标系的变换矩阵 C2W
C2W = np.linalg.inv(W2C)
#C2W 矩阵中第 3 列的前 3 个元素(相机在世界坐标系中的位置,即光心)
cam_centers.append(C2W[:3, 3:4])
python
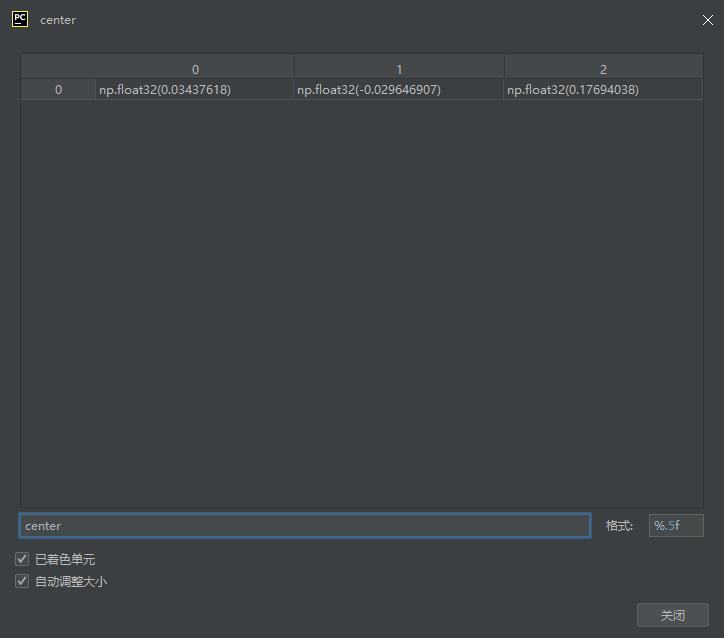
#传入所有相机光心,得到场景中心点和包围球直径
center, diagonal = get_center_and_diag(cam_centers)
#计算包围球半径,为直径的 1.1 倍
radius = diagonal * 1.1
translate = -center示例中心点坐标如下:
在 3D 高斯渲染(3D Gaussian Splatting)的场景加载逻辑中,场景中心点(center) 和包围球直径(diagonal) 是用于场景归一化的核心参数,主要作用是将 3D 场景坐标映射到一个标准化空间,提升模型训练的稳定性和效率。
概念解释
-
场景中心点(center):所有相机光心坐标的平均位置,代表场景在世界坐标系中的几何中心。计算方式是对所有相机光心(通过相机外参转换得到)取平均值,反映了场景中相机分布的中心位置。
-
包围球直径(diagonal):所有相机光心到场景中心点的最大距离的 2 倍(实际代码中取最大距离作为直径),用于描述场景中相机分布的空间范围。它定义了一个能包围所有相机光心的球体的直径,反映了场景的尺度大小。
translate的作用如下:
场景归一化的目标
3D 高斯渲染等 3D 重建任务中,需要将场景坐标映射到一个标准化空间(通常是以原点为中心的小范围空间),以避免因坐标数值过大或偏移导致的模型训练不稳定。实现这一目标的关键步骤是:
- 找到所有相机光心的几何中心(
center),作为场景的 "中心点"。 - 将整个场景平移,使这个中心点与世界坐标系的原点重合。
平移向量的计算逻辑
假设场景中心点的坐标为 center = [cx, cy, cz],要将其平移到原点 [0, 0, 0],需要对场景中所有点(包括相机光心、3D 点云等)施加一个平移向量 translate,满足:center + translate = [0, 0, 0]因此,translate 必须为 -center(即 translate = [-cx, -cy, -cz])

下面接着回到readColmapSceneInfo的代码
python
ply_path = os.path.join(path, "sparse/0/points3D.ply")
bin_path = os.path.join(path, "sparse/0/points3D.bin")
txt_path = os.path.join(path, "sparse/0/points3D.txt")
if not os.path.exists(ply_path):
print("Converting point3d.bin to .ply, will happen only the first time you open the scene.")
try:
xyz, rgb, _ = read_points3D_binary(bin_path)
except:
xyz, rgb, _ = read_points3D_text(txt_path)
storePly(ply_path, xyz, rgb)
try:
pcd = fetchPly(ply_path)
except:
pcd = None加载初始点云 (Point Cloud)。
-
它首先检查是否存在
points3D.ply文件。 -
如果
.ply文件不存在(通常是第一次加载该场景),它会尝试从points3D.bin或points3D.txt中读取点云数据,然后调用storePly函数将其转换并保存为.ply格式,以便下次快速加载。 -
最后,它调用
fetchPly函数从.ply文件中读取点云数据,并将其存储为BasicPointCloud对象pcd。
python
def fetchPly(path):
plydata = PlyData.read(path) # 读取 PLY 文件,返回 PlyData 对象,包含文件中的所有元素(如顶点、面等)
vertices = plydata['vertex'] # 提取 PLY 文件中的顶点数据('vertex' 是 PLY 格式中顶点信息的标准键名)
# 从顶点数据中提取三维坐标(x, y, z),并转置为 N×3 矩阵(N 为顶点数量)
positions = np.vstack([vertices['x'], vertices['y'], vertices['z']]).T
# 从顶点数据中提取 RGB 颜色值(0-255),转置为 N×3 矩阵,并归一化到 0-1 范围
colors = np.vstack([vertices['red'], vertices['green'], vertices['blue']]).T / 255.0
# 从顶点数据中提取法向量(nx, ny, nz),转置为 N×3 矩阵
normals = np.vstack([vertices['nx'], vertices['ny'], vertices['nz']]).T
# 返回封装了点云数据的 BasicPointCloud 对象,包含坐标、颜色和法向量
return BasicPointCloud(points=positions, colors=colors, normals=normals)BasicPointCloud
BasicPointCloud 的主要作用是作为一个标准化的数据容器 ,用来方便地存储和传递从 .ply 文件中读取的初始点云数据。
-
什么是命名元组 (NamedTuple)?
-
它就像一个普通的元组 (tuple),是不可变的(一旦创建,就不能修改里面的值)。
-
它的优点是,你可以通过名字来访问它的成员,而不仅仅是通过索引。这使得代码更具可读性。
-
例如,如果你有一个
BasicPointCloud的实例pcd,你可以通过pcd.points来访问点的位置,这比使用pcd[0]要清晰得多。
-
-
包含的字段
BasicPointCloud包含三个字段,分别存储了点云的核心信息:-
points: 一个 NumPy 数组,形状为[N, 3],存储了点云中N个点的三维坐标 (x, y, z)。 -
colors: 一个 NumPy 数组,形状为[N, 3],存储了每个点对应的 RGB 颜色,数值范围通常在 0 到 1 之间。 -
normals: 一个 NumPy 数组,形状为[N, 3],存储了每个点的法线向量 (nx, ny, nz)。法线向量描述了点所在表面的朝向。
-
在项目中的应用
BasicPointCloud 在数据加载流程中扮演着"中转站"的角色:
-
在
scene/dataset_readers.py文件中,fetchPly函数负责读取.ply文件。它会解析出点的位置、颜色和法线信息,然后将这些信息打包成一个BasicPointCloud对象并返回。 -
readColmapSceneInfo或readNerfSyntheticInfo函数调用fetchPly得到这个BasicPointCloud对象,并将其存入SceneInfo中。 -
最终,这个
BasicPointCloud对象被传递给GaussianModel类的create_from_pcd方法。create_from_pcd方法会使用这个对象中的points和colors数据来创建初始的 3D 高斯球集合。
python
scene_info = SceneInfo(point_cloud=pcd,
train_cameras=train_cam_infos,
test_cameras=test_cam_infos,
nerf_normalization=nerf_normalization,
ply_path=ply_path,
is_nerf_synthetic=False)
return scene_info打包并返回最终结果。
-
它将所有处理好的数据------点云、训练相机、测试相机、场景归一化信息等------打包到一个
SceneInfo命名元组 (NamedTuple) 中。 -
最后,返回这个包含了所有场景信息的
SceneInfo对象。
readColmapCameras
python
def readColmapCameras(cam_extrinsics, cam_intrinsics, depths_params, images_folder, depths_folder, test_cam_names_list):参数:
-
cam_extrinsics: 包含相机外参的字典。 -
cam_intrinsics: 包含相机内参的字典。 -
depths_params: 包含深度图对齐参数的字典(如果可用)。 -
images_folder: 存放图像的文件夹路径。 -
depths_folder: 存放深度图的文件夹路径。 -
test_cam_names_list: 一个包含所有测试图像文件名的列表。
python
sys.stdout.write('\r')
sys.stdout.write("Reading camera {}/{}".format(idx+1, len(cam_extrinsics)))
sys.stdout.flush()这几行代码用于在命令行界面显示一个动态的进度提示,例如 "Reading camera 5/100",让用户知道程序正在处理数据,而不是卡住了
python
extr = cam_extrinsics[key]
intr = cam_intrinsics[extr.camera_id]-
extr = cam_extrinsics[key]: 从外参字典中获取当前image_id对应的Image对象。 -
intr = cam_intrinsics[extr.camera_id]: 使用从extr中获取的camera_id,去内参字典中找到并获取对应的Camera对象。这是关联内外参的关键一步
python
height = intr.height
width = intr.width
uid = intr.id
R = np.transpose(qvec2rotmat(extr.qvec))
T = np.array(extr.tvec)获取图像高度,宽度,相机id
-
R = np.transpose(qvec2rotmat(extr.qvec)): 这是一个核心的数学转换。它首先调用colmap_loader.py中的qvec2rotmat函数,将存储的四元数 (extr.qvec) 转换为一个 3x3 的旋转矩阵。然后对这个矩阵进行转置 (transpose)。进行转置是因为 COLMAP 的约定和项目内部使用的相机坐标系约定可能不同。 -
T = np.array(extr.tvec): 获取相机的平移向量
世界坐标 → 相机坐标 :通过旋转矩阵R和平移向量T,将 3D 高斯模型的世界坐标转换到相机的局部坐标系(视图变换),确保渲染时物体的位置与相机视角匹配
python
if intr.model=="SIMPLE_PINHOLE":
focal_length_x = intr.params[0]
FovY = focal2fov(focal_length_x, height)
FovX = focal2fov(focal_length_x, width)
elif intr.model=="PINHOLE":
focal_length_x = intr.params[0]
focal_length_y = intr.params[1]
FovY = focal2fov(focal_length_y, height)
FovX = focal2fov(focal_length_x, width)
else:
assert False, "Colmap camera model not handled: only undistorted datasets (PINHOLE or SIMPLE_PINHOLE cameras) supported!"处理相机内参,将其从焦距转换为视场角 (Field of View, FoV)。
-
它检查相机的模型,并根据不同的模型从
intr.params数组中提取焦距值。 -
然后,它调用
utils/graphics_utils.py中的focal2fov函数,根据焦距和图像的宽高计算出水平视场角 (FovX) 和垂直视场角 (FovY)。 -
assert False语句确保如果遇到不支持的相机模型,程序会报错退出 -
FovY(垂直视场角):通过垂直方向焦距focal_length_y和图像高度height计算,反映相机在垂直方向能捕捉的视野范围。 -
FovX(水平视场角):通过水平方向焦距focal_length_x和图像宽度width计算,反映相机在水平方向能捕捉的视野范围
python
n_remove = len(extr.name.split('.')[-1]) + 1
depth_params = None
if depths_params is not None:
try:
depth_params = depths_params[extr.name[:-n_remove]]
except:
print("\n", key, "not found in depths_params")-
extr.name是完整的文件名,如"img.png"。extr.name[:-n_remove]这部分操作是为了去掉文件的扩展名(如.png),得到基础文件名(如img)。 -
如果
depths_params字典存在,它会尝试用这个基础文件名作为键,去字典里查找对应的深度对齐参数。
python
image_path = os.path.join(images_folder, extr.name)
image_name = extr.name
depth_path = os.path.join(depths_folder, f"{extr.name[:-n_remove]}.png") if depths_folder != "" else ""构建当前相机对应的完整文件路径,包括彩色图像的路径和深度图的路径(如果存在)。
python
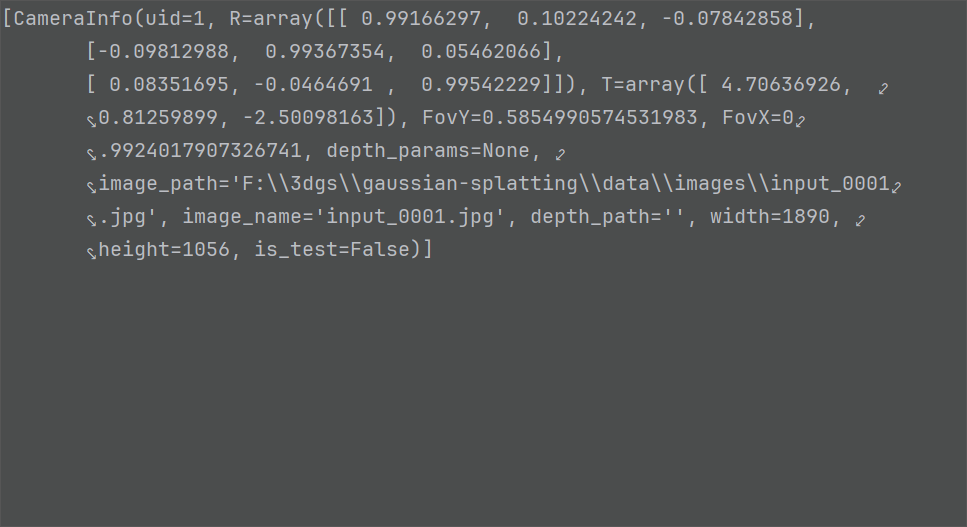
cam_info = CameraInfo(uid=uid, R=R, T=T, FovY=FovY, FovX=FovX, depth_params=depth_params,
image_path=image_path, image_name=image_name, depth_path=depth_path,
width=width, height=height, is_test=image_name in test_cam_names_list)
cam_infos.append(cam_info)-
is_test=image_name in test_cam_names_list: 这是一个布尔判断,检查当前图像的文件名是否存在于之前创建的测试集列表中,从而决定is_test标志是True还是False。 -
cam_info = CameraInfo(...): 将所有处理好的信息(ID, 旋转矩阵, 平移向量, 视场角, 路径, 宽高, 测试标志等)全部打包到一个CameraInfo命名元组中。 -
cam_infos.append(cam_info): 将这个封装好的CameraInfo对象添加到cam_infos列表中。

下面回到init方法中
复制参数到json
python
if not self.loaded_iter:
with open(scene_info.ply_path, 'rb') as src_file, open(os.path.join(self.model_path, "input.ply") , 'wb') as dest_file:
dest_file.write(src_file.read())
json_cams = []
camlist = []
if scene_info.test_cameras:
camlist.extend(scene_info.test_cameras)
if scene_info.train_cameras:
camlist.extend(scene_info.train_cameras)
for id, cam in enumerate(camlist):
json_cams.append(camera_to_JSON(id, cam))
with open(os.path.join(self.model_path, "cameras.json"), 'w') as file:
json.dump(json_cams, file)从头开始训练 时 (not self.loaded_iter) 执行。
-
它将原始的点云文件 (
scene_info.ply_path) 复制到模型输出目录,并重命名为input.ply,作为备份和参考。 -
它遍历所有相机(训练和测试),调用
camera_to_JSON函数(来自utils.camera_utils)将每个相机的信息转换成 JSON 格式。 -
最后,将所有相机的 JSON 信息写入到输出目录的
cameras.json文件中
python
self.cameras_extent = scene_info.nerf_normalization["radius"]从 scene_info 中获取场景的范围半径 (radius),并将其存储在 self.cameras_extent 中。这个值对于后续的致密化和剪枝操作非常重要
根据不同的分辨率缩放因子,加载并初始化训练集和测试集的相机数据
python
for resolution_scale in resolution_scales:
print("Loading Training Cameras")
self.train_cameras[resolution_scale] = cameraList_from_camInfos(scene_info.train_cameras, resolution_scale, args, scene_info.is_nerf_synthetic, False)
print("Loading Test Cameras")
self.test_cameras[resolution_scale] = cameraList_from_camInfos(scene_info.test_cameras, resolution_scale, args, scene_info.is_nerf_synthetic, True)遍历 resolution_scales 列表(默认为 [1.0]),为每个缩放比例加载相机。
-
调用
cameraList_from_camInfos函数(来自utils.camera_utils),该函数会读取图像,根据resolution_scale和-r参数进行缩放,并创建 **Camera**对象列表。 -
将加载好的训练和测试
Camera对象列表分别存入self.train_cameras和self.test_cameras字典中,以resolution_scale为键。
python
if self.loaded_iter:
self.gaussians.load_ply(os.path.join(self.model_path,
"point_cloud",
"iteration_" + str(self.loaded_iter),
"point_cloud.ply"), args.train_test_exp)
else:
self.gaussians.create_from_pcd(scene_info.point_cloud, scene_info.train_cameras, self.cameras_extent)初始化或加载 GaussianModel 的最后一步。
-
如果
self.loaded_iter存在(即加载预训练模型),则调用self.gaussians.load_ply()方法从指定的迭代文件夹中加载.ply文件,恢复高斯球的所有属性。 -
否则(即从头训练),调用
self.gaussians.create_from_pcd()方法,使用从数据集中读取的初始点云 (scene_info.point_cloud) 来创建初始的 3D 高斯球集合。
create_from_pcd
此方法用于首次训练(未加载预训练模型)时,从初始点云数据创建 3D 高斯分布的初始状态。
当模型未加载预训练权重(self.loaded_iter 为 None,即首次训练)时,该方法会将输入的点云数据转换为初始的 3D 高斯集合:
- 每个点云中的点会被初始化为一个 3D 高斯分布,点的坐标作为高斯的均值(中心位置)。
- 点的颜色直接作为高斯的初始颜色。
- 点的法向量或相机视角信息可能用于初始化高斯的协方差矩阵(控制高斯的形状,如各向异性伸展方向)。
- 结合
self.cameras_extent缩放高斯的初始尺度,确保其覆盖范围与场景大小匹配。
python
def create_from_pcd(self, pcd : BasicPointCloud, cam_infos : int, spatial_lr_scale : float):
self.spatial_lr_scale = spatial_lr_scale
#将初始点云的坐标转化为tensor并移动到cuda上
fused_point_cloud = torch.tensor(np.asarray(pcd.points)).float().cuda()
#将RGB颜色转化为球谐系数SH
fused_color = RGB2SH(torch.tensor(np.asarray(pcd.colors)).float().cuda())
#形状为 (点数量, 3, SH系数总数),其中 3 对应 RGB 通道,(max_sh_degree + 1)^2 是球谐函数的总系数数(由最大阶数 max_sh_degree 决定
features = torch.zeros((fused_color.shape[0], 3, (self.max_sh_degree + 1) ** 2)).float().cuda()
features[:, :3, 0 ] = fused_color
features[:, 3:, 1:] = 0.0
print("Number of points at initialisation : ", fused_point_cloud.shape[0])
#计算点云中每个点与其最近邻的平方距离
dist2 = torch.clamp_min(distCUDA2(torch.from_numpy(np.asarray(pcd.points)).float().cuda()), 0.0000001)
#初始化高斯的缩放参数(控制高斯的大小)
scales = torch.log(torch.sqrt(dist2))[...,None].repeat(1, 3)
#初始化高斯的旋转参数(四元数形式):初始化为单位四元数([1, 0, 0, 0]),表示无旋转(各向同性
rots = torch.zeros((fused_point_cloud.shape[0], 4), device="cuda")
rots[:, 0] = 1
#初始化高斯的不透明度参数
opacities = self.inverse_opacity_activation(0.1 * torch.ones((fused_point_cloud.shape[0], 1), dtype=torch.float, device="cuda"))
#将高斯的u、缩放矩阵、旋转四元数、不透明度、球谐系数SH注册为可优化参数
self._xyz = nn.Parameter(fused_point_cloud.requires_grad_(True))
self._features_dc = nn.Parameter(features[:,:,0:1].transpose(1, 2).contiguous().requires_grad_(True))
self._features_rest = nn.Parameter(features[:,:,1:].transpose(1, 2).contiguous().requires_grad_(True))
self._scaling = nn.Parameter(scales.requires_grad_(True))
self._rotation = nn.Parameter(rots.requires_grad_(True))
self._opacity = nn.Parameter(opacities.requires_grad_(True))
#初始化每个高斯在 2D 图像上的最大投影半径(max_radii2D),用于后续渲染时快速剔除不可见的高斯
self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda")
self.exposure_mapping = {cam_info.image_name: idx for idx, cam_info in enumerate(cam_infos)}
self.pretrained_exposures = None
exposure = torch.eye(3, 4, device="cuda")[None].repeat(len(cam_infos), 1, 1)
self._exposure = nn.Parameter(exposure.requires_grad_(True))