目录
- 点云是什么
- 点云深度学习领域的任务
-
- [1. 点云分类(Point Cloud Classification)](#1. 点云分类(Point Cloud Classification))
-
- [🧭 任务定义](#🧭 任务定义)
- [⚙️ 应用场景](#⚙️ 应用场景)
- [2. 点云分割(Point Cloud Segmentation)](#2. 点云分割(Point Cloud Segmentation))
-
- [🧭 任务定义](#🧭 任务定义)
- [⚙️ 应用场景](#⚙️ 应用场景)
- [3. 目标检测(3D Object Detection)](#3. 目标检测(3D Object Detection))
-
- [🧭 任务定义](#🧭 任务定义)
- [⚙️ 检测流程一般包括:](#⚙️ 检测流程一般包括:)
- [🚗 典型应用](#🚗 典型应用)
- [✨ 总结](#✨ 总结)
- 点云特征提取的流派
-
- [🕰️ 早期阶段(2014--2017)](#🕰️ 早期阶段(2014–2017))
-
- [1. 体素派(Grid-based Methods)](#1. 体素派(Grid-based Methods))
- [2. 2.5D派(Projection-based Methods)](#2. 2.5D派(Projection-based Methods))
- [💠 点集门派(Point-based Methods)](#💠 点集门派(Point-based Methods))
-
- [**1️⃣ PointNet (CVPR 2017)(https://arxiv.org/pdf/1612.00593)**](#1️⃣ PointNet (CVPR 2017))
- [**2️⃣ PointNet++ (NeurIPS 2017)(https://arxiv.org/abs/1706.02413)**](#2️⃣ PointNet++ (NeurIPS 2017))
- [**3️⃣ 后续发展方向**](#3️⃣ 后续发展方向)
- [🧱 体素化门派(Voxel-based Methods)](#🧱 体素化门派(Voxel-based Methods))
-
- [**1️⃣ VoxelNet (Zhou \& Tuzel, CVPR 2018)(https://arxiv.org/abs/1711.06396)**](#1️⃣ VoxelNet (Zhou & Tuzel, CVPR 2018))
- [**2️⃣ SparseConv 与 MinkowskiNet**](#2️⃣ SparseConv 与 MinkowskiNet)
- [**3️⃣ 体素化代表工作**](#3️⃣ 体素化代表工作)
- [🕸️ 图神经网络派(Graph-based Methods)](#🕸️ 图神经网络派(Graph-based Methods))
-
- [**1️⃣ DGCNN (Wang et al., TOG 2019)**](#1️⃣ DGCNN (Wang et al., TOG 2019))
- [**2️⃣ 其他代表**](#2️⃣ 其他代表)
- [🔶 Transformer 派(Attention-based Methods)](#🔶 Transformer 派(Attention-based Methods))
- [🌐 其他新兴派别(融合与混合流)](#🌐 其他新兴派别(融合与混合流))
- [🧭 总结](#🧭 总结)
点云是什么
点云是什么?这是一个熟悉又陌生的问题。熟悉则是做这方向相关的人基本都可视化地看过点云,大家都清楚点云是一系三维列坐标点组成的集合,打开一个pcd文件点云作为一系列晦涩难懂的数字出现在我们面前:
bash
# .PCD v0.7 - Point Cloud Data file format
VERSION 0.7
FIELDS x y z
SIZE 4 4 4
TYPE F F F
COUNT 1 1 1
WIDTH 124102
HEIGHT 1
VIEWPOINT 0 0 0 1 0 0 0
POINTS 124102
DATA ascii
-45.908447 8.347168 4.263931
-56.259033 18.980957 4.828049
-54.061523 18.535156 4.729858
-54.016846 18.664551 4.729820
-53.993652 18.801270 4.730843
-53.572021 18.943848 4.715347
-53.559326 19.083008 4.716888
-53.137939 19.078125 4.699203
-52.640381 19.043945 4.678040
-52.223633 19.178223 4.662720
-52.166504 19.298828 4.662163在自动驾驶领域点云数据一般会是四个维度的,除了x,y,z坐标外,另外还会有ri (反射率)这个指标。进一步地,如果把点云通过相机内外参投影到相机平面上,那么可以额外获得RGB 参数。
晦涩的数字可以通过可视化程序跃然纸上。我们可以看到下图面这样的点云视图。这是经典的激光雷达采集的点云数据的俯视图,一圈一圈的是由于360度激光雷达本身的结构特性导致的

如果是室内场景,往往会是这样的点云:

熟悉的事情到此为止,点云的一些重要特性是我们陌生的:
- 点云集合是无序的
前面我们清楚了,点云的本质是一系列坐标点组成的集合,任意改变坐标点的排列顺序表示的还是同一个点云。 - 点云的采样是稀疏不均匀的
稀疏这个特点很好理解,但是不均匀这个特性大家往往遗漏。这个不均匀说的是从传感器采集数据的角度上来说,点云是近密远疏的。
很多人在学习点云处理前一般都有学习图像检测的基础,这就会导致一种惯性思维:认为在点云上运用卷积是天经地义的,无非把卷积核换成3D的就行了。但事实上由于图像数据的采集是均匀的(CMOS传感分布是均匀的)图像数据天生就是网格化的,用卷积处理像素点,邻域尺寸都是固定的,因此卷积核可以捕捉到局部结构的特征。但如果用卷积直接处理点云数据的话,由于点云近密远疏的特性,在密集地方卷积到的点数多可以捕捉到特征,而在稀疏的地方卷积的点数少,特征则无法有效提取。因此早期卷积的方法效果并不是很好。
点云深度学习领域的任务
点云(Point Cloud)是三维空间中以离散点集合形式表示的几何数据。
随着深度学习的发展,研究者逐渐从2D影像分析转向对三维点云数据的直接学习。
点云深度学习的主要研究任务包括:分类(Classification) 、分割(Segmentation) 和 目标检测(Object Detection) 。
这三类任务分别关注点云的全局识别、局部理解与实例级空间定位,是3D视觉领域的三大核心任务。
1. 点云分类(Point Cloud Classification)
🧭 任务定义
点云分类任务旨在对整个点云对象进行语义类别的判别 ,即判断输入点云属于哪个类别(如椅子、桌子、车、人等)。
该任务是点云深度学习的基础,通常假设输入是一个完整、干净的单个物体点云。
⚙️ 应用场景
- 3D物体识别(ShapeNet, ModelNet)
- 工业零件分类
- 医学3D结构识别(CT点云)
- 机器人抓取物体类型识别
2. 点云分割(Point Cloud Segmentation)
🧭 任务定义
点云分割是在点级别进行语义或实例标签预测的任务,分为两种类型:
- 语义分割(Semantic Segmentation):为每个点分配类别标签(如地面、建筑、行人、车等)。
- 实例分割(Instance Segmentation):区分同类中不同个体(例如两辆车的点)。
⚙️ 应用场景
- 自动驾驶环境理解(道路、行人、车体)
- 室内场景解析(地板、墙、家具)
- 工业缺陷检测 / 建筑信息建模(BIM)
- 医学结构分割(血管、器官三维形态)
3. 目标检测(3D Object Detection)
🧭 任务定义
3D目标检测的目标是在点云中检测并定位目标对象的三维边界框(3D bounding boxes) ,包括中心位置、尺寸、朝向和类别。
与2D检测不同,3D检测必须考虑物体的深度、朝向与尺度变化。
⚙️ 检测流程一般包括:
- 特征提取:点或体素层级的特征编码;
- 候选生成(Region Proposal) 或中心点预测;
- 3D框回归(位置、尺寸、旋转角);
- 多模态融合 / 后处理。
🚗 典型应用
- 自动驾驶目标检测(车辆、行人、自行车)
- 无人机三维识别与跟踪
- 机器人导航障碍检测
- 安全监控与AR/VR场景理解
✨ 总结
点云深度学习的三大任务(分类、分割、检测)构成了三维理解的完整层级:
- 分类:理解"是什么";
- 分割:理解"哪些点属于什么";
- 检测:理解"它在哪里"。
研究的发展方向正从单任务向**多任务联合与多模态融合(LiDAR + Camera + IMU)**演化,
从2.5D投影到直接3D空间特征学习,再到4D时空动态理解,
推动着机器人感知、自动驾驶与数字孪生等领域的智能化进程。
点云特征提取的流派
前面介绍的是完整的任务,这些任务看似割裂,实则可以被统一为:
特征提取网络(BackBone) + 任务头(classification / segmentation / detection) 。
这里忽略任务头的内容,只介绍特征提取网络的门派分类。
🕰️ 早期阶段(2014--2017)
1. 体素派(Grid-based Methods)
这里介绍的都是基于深度学习(Deep Learning)的早期方法。在那个阶段,研究者一般直接照搬图像领域的CNN思路。
在点云中使用CNN的方法我们一般称之为 体素化 (Voxelization)。
核心思路:
把连续的三维空间划分成规则的栅格(体素,Voxel),并记录每个体素是否被点云占据。
实现方式:
- 把空间切割成 X × Y × Z X\times Y\times Z X×Y×Z 的小方块;
- 如果小方块内包含有点云点,则标记为 1,否则为 0;
- 得到一个三维二值网格;
- 最后输入 3D CNN 进行卷积特征提取。
代表作:
🧱 VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition
IEEE IROS 2015
这是第一个真正把体素化点云输入 3D CNN 端到端训练的工作,被视为 3D 深度学习的起点。
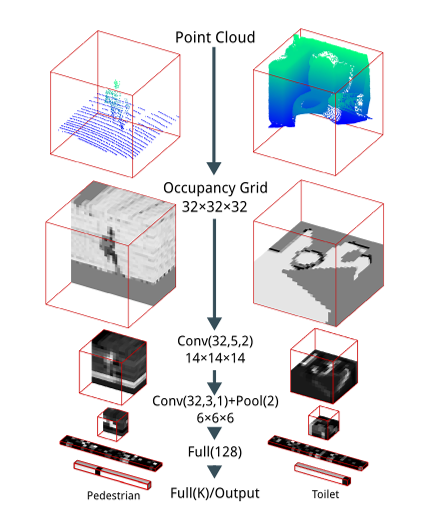
经典流程:
点云 (x, y, z)
│
▼
空间划分 (X×Y×Z)
│
├─ 有点 → 1
├─ 无点 → 0
▼
二值体素网格 (Occupancy Grid)
│
└─ 3D CNN / SparseConvNet
体素派的早期问题:
- 信息损失 :体素化意味着降采样。近密远疏的点云导致密集区域丢失细节特征。
→ 后续由 VoxelNet (CVPR 2018) 提出体素内PointNet特征解决。 - 计算量爆炸 :3D卷积复杂度为 O ( N 3 ) O(N^3) O(N3),体素稀疏时空计算浪费严重。
→ 后续由 SparseConvNet (CVPR 2017) 提出的 稀疏卷积 (Sparse Convolution) 解决。
2. 2.5D派(Projection-based Methods)
与体素派不同,2.5D派不直接在3D空间操作,而是通过投影 将点云转换为二维形式,再用成熟的2D CNN处理。
这一思路既能利用图像网络的高效性,又能保留一定的深度信息。
核心思想:
"把点云投影到一个或多个二维平面(深度图、鸟瞰图、球面图等),然后在二维空间中学习特征。"
常见视角:
- BEV(鸟瞰图) :将3D点云投影到XY平面,每格记录高度/密度/反射率等特征。
👉 典型方法:MV3D (CVPR 2017), PIXOR (CVPR 2018),自动驾驶检测核心思路。 - Range Image(球面投影) :将激光雷达扫描角度(θ, φ)映射为2D图像。
👉 典型方法:SqueezeSeg (ICRA 2018), RangeNet++ (IROS 2018)。 - Multi-View Projection :从多个相机视角渲染点云,再融合。
👉 典型方法:MVCNN (ICCV 2015)。 - Depth Map :记录每个像素到相机的深度。
👉 常用于RGB-D分类 (Eitel et al., IROS 2015)。
代表作:
🖼️ Multi-View CNN (Su et al., ICCV 2015)
论文链接
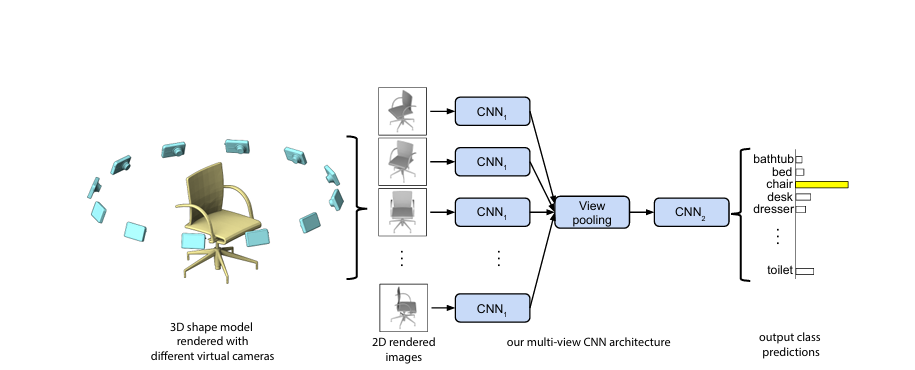
该方法将3D模型从不同角度渲染为多个2D视图,再用共享CNN提取各视角特征,通过View Pooling 融合。
它奠定了"用2D特征学习3D结构"的2.5D范式。
📌 注:
本文所说的"2.5D方法"核心在于 使用2D特征去解决3D问题 。
像 CenterPoint 虽在 BEV 平面检测,但特征由3D稀疏卷积提取,本质上属于3D方法。
💠 点集门派(Point-based Methods)
点集门派是点云深度学习最具革命性的流派,开山之作是 PointNet (Qi et al., CVPR 2017) 。 它首次打破了"点云必须体素化或投影"的思想,实现了直接在无序点集上进行深度学习。后续的PointNet++则弥补了Point-net无法提取局部特征的缺陷 ,进一步将点集门派发扬光大。此两篇文章是研究点云的必读之作
1️⃣ PointNet (CVPR 2017)
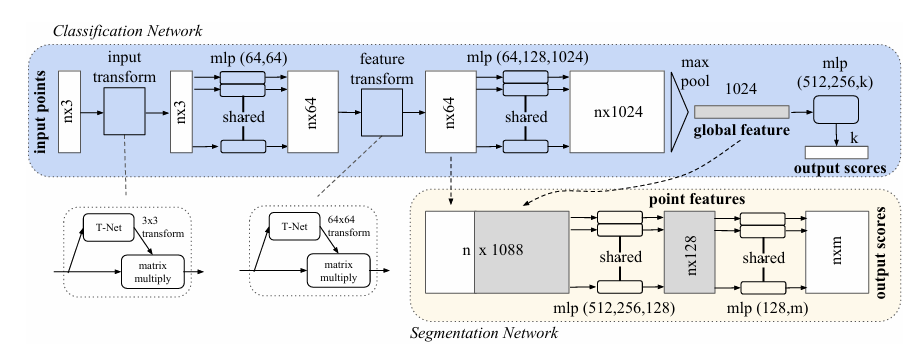
核心思想:
使用共享 MLP 提取每个点的特征(将x,y,z三维的特征丰富到上百维),再用对称函数(max pooling)聚合全局特征,实现对输入点顺序的不变性。
创新点:
- 直接处理点集无需体素化,避免了特征的损失。
- 利用点云的置换不变性,创新性的提出了对称函数方法,成功提取了点云的整体特征。
- 引入 T-Net 学习空间对齐;
- 第一次实现端到端点云分类与分割,为点云特征提取提供了一个简洁高效的范式。
缺点:
- 对称函数能够成功提取点云的整体特征,但是对于局部细节特征的提取欠缺(这是CNN最擅长的)。
后续有空我还会写一篇关于point-net的感悟。
2️⃣ PointNet++ (NeurIPS 2017)
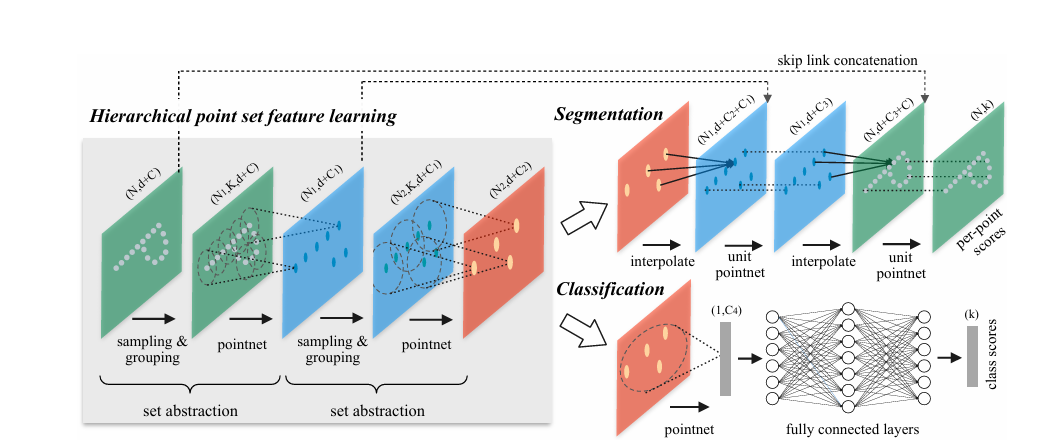
核心贡献:
- 提出"层次化抽样与局部特征学习"(Set Abstraction),这一操作类似卷积能够提取不同层次的点云局部特征,即点集门派中的卷积方法;
- 使用球形邻域(Ball Query)提取局部几何关系;点集门派中的卷积核
- 捕获局部到全局的空间结构;点集门派中的金字塔结构
3️⃣ 后续发展方向
| 方向 | 代表方法 | 核心创新 |
|---|---|---|
| 邻域动态图结构 | DGCNN (2019) | EdgeConv:动态邻接关系 |
| 权重学习 | PointConv (2019) | 学习连续卷积核 |
| 局部Transformer | PointTransformer (2021) | 自注意力建模空间依赖 |
| 状态空间建模 | PointMamba (2025) | 用状态空间模型高效建模长程关系 |
| 大规模预训练 | Point-BERT / PointNeXt (2022--2023) | 引入自监督与ViT式架构 |
🧱 体素化门派(Voxel-based Methods)
前面介绍了早期的体素化门派,并提出了两个关键性问题:
- 体素化导致点云特征损失。
- 点云卷积计算量庞大。
这里介绍的体素化门派是对早期体素CNN的延续与革新,重点解决了上述两个问题。
1️⃣ VoxelNet (Zhou & Tuzel, CVPR 2018)
Point-Net的提出不仅一举创立了点集门派,表面上是对体素化门派的一次致命打击,但无意中却为体素化门派解决了一个困扰很久的问题,那就是如何在体素化的情况下不丢失体素内的点的特征?Voxel-Net给出了答案。
核心思路:
每个体素内部用 PointNet 提取特征 (Voxel Feature Encoding, VFE),再用3D CNN提取空间上下文。
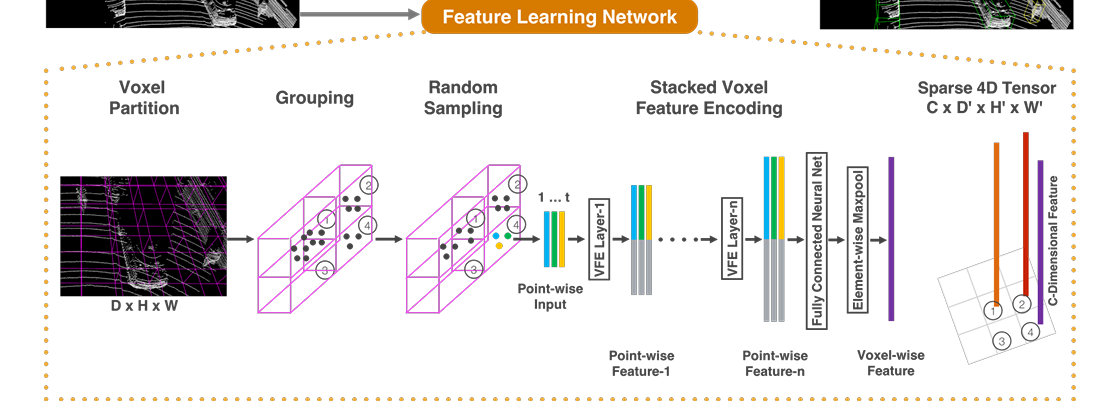
创新点:
- 提出了VFE方法,能够在体素化的同时保留体素内部点结构特征;
- 大大减少了体素化过程中几何信息的损失;
- 端到端学习特征 → 检测框回归。
2️⃣ SparseConv 与 MinkowskiNet
&emspl;当然,仅仅是解决了特征难题体素化流派还不能在工业领域大放异彩,后续稀疏卷积的提出真正意义上让体素化门派GreatAgain!
- Submanifold SparseConvNet (Graham, CVPR 2017)
首次提出稀疏卷积 (Sparse Convolution) 概念,稀疏卷积即仅在非空体素上进行卷积计算。

这种卷积方式给点云卷积处理带来了启发,由于点云数据采集的原理导致了其实大部分的点云点都集中在物体的*表面,其实点云的大部分区域都是空的。
创新点:
- 第一个提出稀疏卷积的人:Benjamin Graham (Oxford University),2017 年 CVPR 论文 Submanifold Sparse Convolutional Networks
- 第一个用稀疏卷积提取点云特征的网络:SparseConvNet (CVPR 2017) ------ 同一篇论文中提出并实现。它为之后的 VoxelNet (2018)、SECOND (2018)、MinkowskiNet (2019)、CenterPoint (2021) 奠定了底层结构基础。
- Minkowski Engine (ICCV 2019) 则将其扩展到4D时空稀疏卷积。
优点:
- 计算复杂度从 O ( N 3 ) O(N^3) O(N3) 降为 O ( K ) O(K) O(K);
- 内存消耗大幅降低;
- 适合大规模户外场景(自动驾驶)。
3️⃣ 体素化代表工作
| 年份 | 方法 | 特点 |
|---|---|---|
| 2018 | VoxelNet | 体素内PointNet特征 |
| 2019 | SECOND | 稀疏卷积检测 |
| 2020 | CenterPoint | BEV中心检测范式 |
| 2021 | Voxel R-CNN | 双阶段体素检测 |
| 2023 | VoxelNeXt | 高效轻量化体素骨干 |
🕸️ 图神经网络派(Graph-based Methods)
点云天然是非欧几里得结构,适合用图来建模点与点之间的关系。 图神经网络(GNN)为点云提供了局部邻域结构建模能力 。图神经流派是pointnet提出后,体素化大规模应用前这段时间流行的派别
1️⃣ DGCNN (Wang et al., TOG 2019)
核心思想:
动态构建点云邻接图(k-NN),在特征空间而非坐标空间更新邻域关系。
提出 EdgeConv 操作,捕捉边(点对)特征。
2️⃣ 其他代表
| 方法 | 特色 |
|---|---|
| GraphConv (2018) | 静态图卷积 |
| RS-CNN (2019) | 基于局部相对坐标的图卷积 |
| RandLA-Net (2020) | 随机采样 + 局部聚合 |
| PointGNN (2020) | 图节点即物体候选,检测专用 |
图神经网络增强了点云的局部结构建模能力,但计算复杂度高,不易并行。
🔶 Transformer 派(Attention-based Methods)
随着 Transformer 在视觉领域崛起,研究者开始探索自注意力机制在点云特征提取中的作用。
| 方法 | 核心思想 | 特征 |
|---|---|---|
| Point Transformer (2021) | 引入自注意力机制计算点间依赖关系 | 全局建模能力强 |
| PCT (2021) | 用Transformer替代PointNet的MLP结构 | 高效轻量 |
| Point-BERT (2022) | 自监督预训练 + Transformer骨干 | 大规模点云预训练 |
| PointMamba (2025) | 状态空间替代注意力,提高效率 | 长程依赖捕捉更稳健 |
🌐 其他新兴派别(融合与混合流)
| 流派 | 核心方向 | 代表方法 |
|---|---|---|
| 混合派 (Hybrid) | 点+体素联合编码 | PV-RCNN, PointVoxelNet |
| BEV融合派 | 3D→2D再检测 | BEVFusion, BEVDepth |
| 多模态派 | Camera+LiDAR融合 | AVOD, TransFusion |
| 序列/时空派 | 连续点云建模 | 4D MinkowskiNet, PointMamba4D |
🧭 总结
| 流派 | 表示维度 | 代表方法 | 优势 | 局限 |
|---|---|---|---|---|
| 体素派 | 规则3D栅格 | VoxNet, VoxelNet | 结构规整,兼容CNN | 计算量大,信息损失 |
| 2.5D派 | 投影2D视图 | MV3D, SqueezeSeg | 高效,可用2D网络 | 几何连续性缺失 |
| 点集派 | 原生点集 | PointNet++, DGCNN | 保留几何精度 | 稀疏、难并行 |
| 图派 | 邻域图结构 | DGCNN, PointGNN | 局部结构丰富 | 计算复杂度高 |
| Transformer派 | 注意力全局建模 | PointTransformer | 长程依赖强 | 训练成本高 |
| 稀疏体素派 | 稀疏卷积结构 | MinkowskiNet | 计算高效,适合大场景 | 实现复杂 |
📘 一句话总结:
点云特征提取网络的发展,从最初的体素化与投影(2.5D)
→ 到点级学习(PointNet++)
→ 再到稀疏卷积、图卷积、Transformer、状态空间等多流派共存,
最终正朝着 高效三维建模 + 多模态融合 + 大模型预训练 的方向演进。
希望大家能够通过这篇文章,对点云特征提取有一个宏观的梳理。我在这里把Backbon这件事分成了几个派别,但事实上各种方法之间往往是相互融合的,没有各个武林门派那种非你即他的边界,一定要灵活看待。我本人也是一个初入武林的新手,对这方面的理解也不一定充分,希望武林大佬看到不足之处能给予斧正!