k8s的优缺点
优点:部署应用方便,具有高可用、负载均衡功能,能自动扩容、对Pod进行监控
缺点:需要很多机器,成本投入大
安装
服务器准备
首先安装三台虚拟机,一台主节点,两台从节点,规划如下
操作系统:Rocky_linux9.6
配置: 4核cpu +/8Gib 内存/20G磁盘
网卡模式:NAT
| 角色 | IP | 主机名 |
|---|---|---|
| 主节点master | 192.168.52.131 | k8s1 |
| 从节点node1 | 192.168.52.132 | k8s2 |
| 从节点node2 | 192.168.52.133 | k8s3 |
初始化环境
安装必要软件包
yum install vim psmisc tree net-tools -y
关闭防火墙和selinux
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i '/^SELINUX=/ s/enforcing/disabled/' /etc/selinux/config
AI运行代码
建立集群通信
cat >>/etc/hosts <<EOF
192.168.52.131 k8s1
192.168.52.132 k8s2
192.168.52.133 k8s3
EOF
互相配置免密通道
ssh-keygen
cd /root/.ssh
ssh-copy-id -i id_rsa.pub 主机名
关闭交换分区
#临时
swapoff -a
#永久
sed -i '/swap/s/^/#/' /etc/fstab
Swap是交换分区,如果机器内存不够,会使用swap分区,但是swap分区的性能较低,k8s设计的时候为了能提升性能,默认是不允许使用交换分区的。Kubeadm初始化的时候会检测swap是否关闭,如果没关闭,那就初始化失败。如果不想要关闭交换分区,安装k8s的时候可以指定--ignore-preflight-errors=Swap来解决
修改机器内核参数
cat <<EOF | tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
modprobe overlay
modprobe br_netfilter
cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl -p /etc/sysctl.d/k8s.conf
#在运行时配置内核参数
#-p 从指定的文件加载系统参数,如不指定即从/etc/sysctl.conf中加载
lsmod | egrep "br_netfilter|overlay"
net.ipv4.ip_forward是数据包转发:
出于安全考虑,Linux系统默认是禁止数据包转发的。所谓转发即当主机拥有多于一块的网卡时,其中一块收到数据包,根据数据包的目的ip地址将数据包发往本机另一块网卡,该网卡根据路由表继续发送数据包。这通常是路由器所要实现的功能。
要让Linux系统具有路由转发功能,需要配置一个Linux的内核参数net.ipv4.ip_forward。这个参数指定了Linux系统当前对路由转发功能的支持情况;其值为0时表示禁止进行IP转发;如果是1,则说明IP转发功能已经打开。
安装docker,执行docker info出现如下警告:
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
解决办法(上述已经操作):
vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
添加防火墙模块到内核
#modprobe -- nf_conntrack_ipv4
#新版本nf_conntrack_ipv4已被nf_conntrack模块替代
cat <<EOF > /etc/sysconfig/modules/ipvs.modules
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
chmod +x /etc/sysconfig/modules/ipvs.modules
#建议此条命令写入/etc/rc.local,这样每次重启都有
/bin/bash /etc/sysconfig/modules/ipvs.modules
配置时间同步:
安装ntpdate命令
yum install chrony -y
#启动并设置开机启动
systemctl start chronyd
systemctl enable chronyd
#使用阿里云NTP服务器同步
chronyc add server ntp.aliyun.com iburst
chronyc -a makestep
安装docker
具体操作可以参照:https://blog.csdn.net/2403_89445694/article/details/151315316
安装时不要安装最新版的docker,可以使用下面的命令
dnf install -y docker-ce-3:23.0.0-1.el9 docker-ce-cli-1:23.0.0-1.el9 containerd.io docker-buildx-plugin docker-compose-plugin
安装K8S
安装需要的依赖
yum install -y yum-utils device-mapper-persistent-data lvm2 wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack telnet ipvsadm
配置k8s的源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
kubernetes
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
安装
yum install -y kubeadm-1.23.17-0 kubelet-1.23.17-0 kubectl-1.23.17-0 --disableexcludes=kubernetes
安装完成后设置开机自启动
systemctl enable --now kubelet
安装完成后进行集群初始化,此代码只在master节点执行
kubeadm init \
--kubernetes-version=v1.23.17 \
--pod-network-cidr=10.224.0.0/16 \
--service-cidr=10.96.0.0/12 \
--apiserver-advertise-address=192.168.52.131 \ #k8s master的地址
--image-repository=registry.aliyuncs.com/google_containers
看到以下代码即为初始化成功
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown (id -u):(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f podnetwork.yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.52.131:6443 --token kvcfwz.txauoih4a8ibc6a5 \
--discovery-token-ca-cert-hash sha256:5b2e15dd0261e70dd55c73acbd577f285475ec18cf5499d1bb9b5060537cdc0a
然后执行以下命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
将节点加入集群,此命令在各个节点运行
kubeadm join 192.168.52.131:6443 --token kvcfwz.txauoih4a8ibc6a5 \
--discovery-token-ca-cert-hash sha256:5b2e15dd0261e70dd55c73acbd577f285475ec18cf5499d1bb9b5060537cdc0a
在主节点可以查看集群节点信息
kubectl get nodes
将k8s2和k8s3设置为worker
kubectl label node k8s3 node-role.kubernetes.io/worker=worker
kubectl label node k8s3 node-role.kubernetes.io/worker=worker
在node节点上执行kubectl
mkdir -p $HOME/.kube
scp k8s-master-1:/etc/kubernetes/admin.conf /root/.kube/config
chown (id -u):(id -g) $HOME/.kube/config
安装Calico插件
目前各个节点都是NotReady状态,这是因为k8s节点需要用到overlay,这里我们使用calico来实现
calico是k8s集群里网络通信的一个组件(软件),实现集群内部不同的机器之间的容器的通信(大的网络规模)。k8s集群节点可以到5000节点,1亿个容器
flannel 也是一个网络插件(适合小规模的集群,节点服务器的数量比较小,例如:10台左右)
terway 是阿里云自己研发的一个网络插件
安装
kubectl apply -f https://docs.projectcalico.org/archive/v3.25/manifests/calico.yaml
安装完成后,再看集群节点就会发现已经处于ready状态,但是由于这个插件的下载速度非常慢,甚至可能下不动,所以在这里建议去找资源包,然后使用导入镜像的方式导入进去
IPVS负载均衡
ipvs 是linux里的一个负载均衡软件,默认在linux内核里就安装了,修改k8s里的一个配置,负载均衡的时候使用ipvs做为默认的负载均衡软件,如果不修改默认是iptables
只需要修改主节点即可
kubectl edit configmap kube-proxy -n kube-system
修改配置
mode: "ipvs"
删除所有kube-proxy pod使之重启
kubectl delete pods -n kube-system -l k8s-app=kube-proxy
Dashboard
以下所有操作只需要在master节点即可
安装
yum install -t wget
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml\\
然后安装pod
kubectl apply -f recommended.yaml
#查看安装状态
kubectl get pods,svc -n kubernetes-dashboard
#running即为安装完成
root@k8sma \~# kubectl get pods,svc -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
pod/dashboard-metrics-scraper-6f669b9c9b-zxmkc 1/1 Running 0 14m
pod/kubernetes-dashboard-758765f476-gdjnn 1/1 Running 0 5m52s
然后创建账号
vim dashboard-access-token.yaml
填入内容:
Creating a Service Account
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
Creating a ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
Getting a long-lived Bearer Token for ServiceAccount
apiVersion: v1
kind: Secret
metadata:
name: admin-user
namespace: kubernetes-dashboard
annotations:
kubernetes.io/service-account.name: "admin-user"
type: kubernetes.io/service-account-token
Clean up and next steps
kubectl -n kubernetes-dashboard delete serviceaccount admin-user
kubectl -n kubernetes-dashboard delete clusterrolebinding admin-user
执行文件
kubectl apply -f dashboard-access-token.yaml
获取token
kubectl get secret admin-user -n kubernetes-dashboard -o jsonpath={".data.token"} | base64 -d
然后查看端口
kubectl get svc -n kubernetes-dashboard
root@k8sma \~# kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.108.198.151 <none> 8000/TCP 23m
kubernetes-dashboard NodePort 10.110.135.115 <none> 443:30088/TCP 23m
#端口就是30088
然后去浏览器访问 https://IP:PORT
在出现的界面使用我们上面命令获得的token登录即可
二进制安装
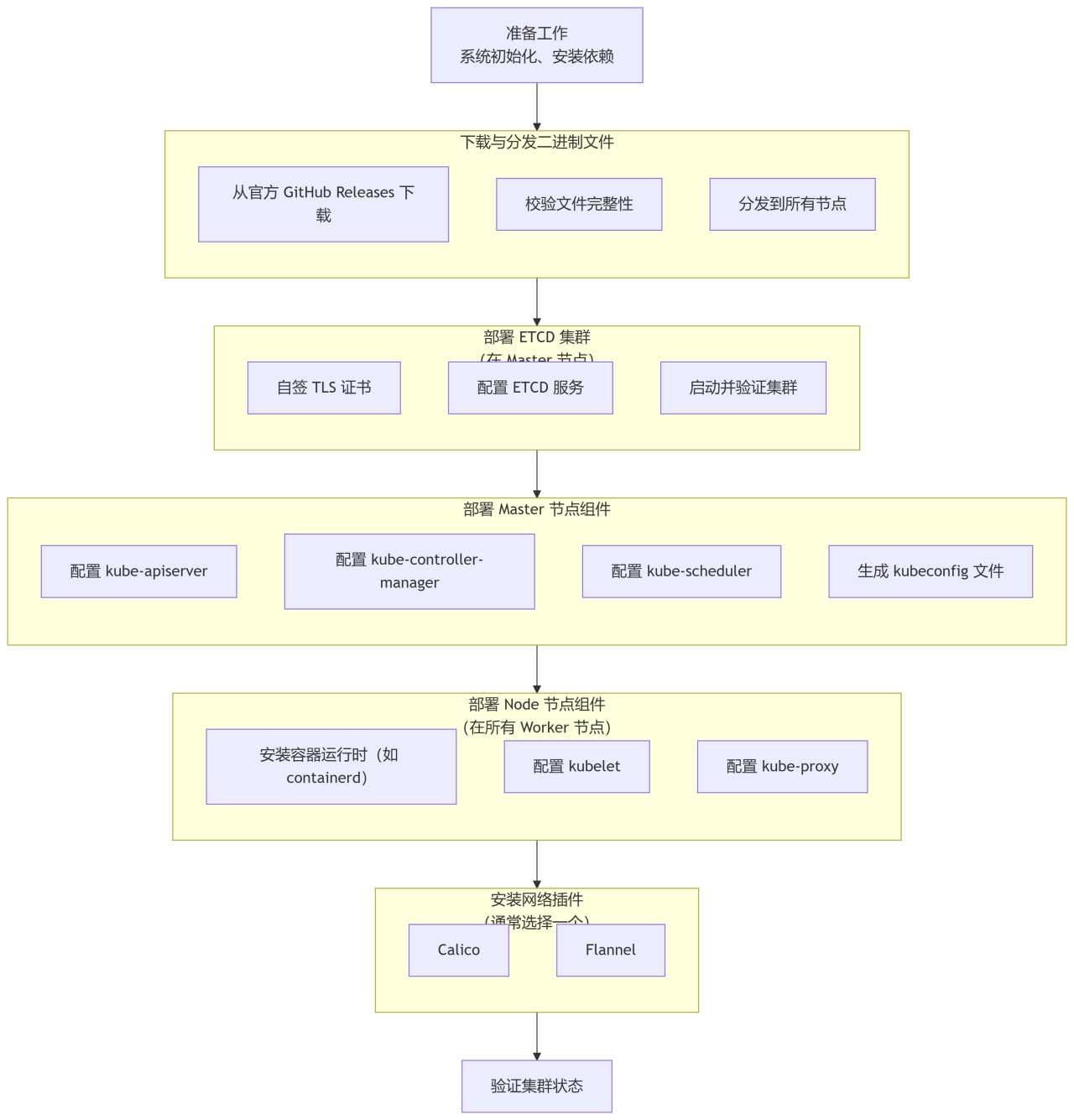
K8S组件
控制平面组件
kube-apiserver:公开k8s api,负责处理接受请求的工作
#查看api接口
kubectl api-resources
etcd:一致且高可用的键值存储,用作k8s所有集群数据的后台数据库
kube-scheduler:查找尚未绑定到节点的pod,并将每个Pod分配到合适的节点
kube-controller-manager:运行控制器来实现k8s API行为
cloud-controller-manager:与底层云驱动集成
节点组件
kubelet:用于在节点上启动容器,如果kubelet没有启动,会导致节点起不来
kube-proxy:每个节点上所运行的网络代理,实现k8s服务概念的一部分,提供网络通信功能
pod
pod就是一堆容器组成的集合,起pod就相当于起容器,是k8s里创建和管理、最小的可部署的计算单元
查看命名空间
kubectl get nsAI运行代码bash
查看对应命名空间Pod
kubectl get pod -n 命名空间名称启动pods
部署控制器启动pod
创建nginx pod
kubectl create deployment k8s-nginx --image=nginx -r 3
#--image 指定使用的镜像
#-r 指定起几个容器
查看pod
kubectl get pod
NAME READY STATUS RESTARTS AGE
k8s-nginx-6d779d947c-m4xcr 0/1 ContainerCreating 0 2m45s
k8s-nginx-6d779d947c-rwh7s 1/1 Running 0 2m45s
k8s-nginx-6d779d947c-t764t 0/1 ContainerCreating 0 2m45s
#查看pod在哪个节点运行
kubectl get pod -o wide
#查看所有pod的所有信息
kubectl get pod -A
查看部署控制器
kubectl get deploy
查看副本控制器
kubectl get rs
如果之中某个节点突然下线,副本控制器会将pod会调度到其他node节点上,一般需要5分钟左右,如果副本控制器下线,那么部署控制器会马上部署一个新的副本控制器
标准启动pod
创建一个yaml文件,并填入内容
apiVersion: v1 #k8s里规定的api接口版本,不同的k8s支持的版本不同
kind: Pod #k8s里的对象的类型,一切皆对象
metadata: #元数据=》描述数据的数据,对pod进行描述
name: nginx #pod的名字
spec: #对象的详细信息
containers: #容器
- name: nginx #容器的名字
image: nginx:1.14.2 #容器使用的镜像
ports: #端口
- containerPort: 80 #具体的端口号
然后启动pod
kubectl apply -f pod1.yaml
部署控制器启动pod
创建yaml文件,填入脚本内容
apiVersion: apps/v1 #接口的名字,不同类型资源,接口名字不一样
kind: Deployment #类型为部署控制器
metadata:
name: nginx-deployment #名字
labels: #标签
app: nginx #具体的标签
spec: #指定的信息
replicas: 3 #副本控制器,指定创建3个副本
selector: #选择器,选择哪些pod去控制
matchLabels: #匹配标签
app: nginx #具体匹配哪些pod什么标签
template: #模板,因为有多个副本,所以需要提供模板
metadata: #元数据
labels: #标签
app: nginx #具体标签,每个pod都会使用这个标签
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
然后开始部署
kubectl apply -f yaml文件名
pod中镜像的升级和回滚
如果使用的镜像没有改变,那么会在原来的副本控制器里面新增pod,如果使用的镜像发生了改变,部署控制器会新建一个副本控制器,然后在新的副本控制器里面新建pod,并逐步终止原来的副本控制器中的pod(建一个删一个)
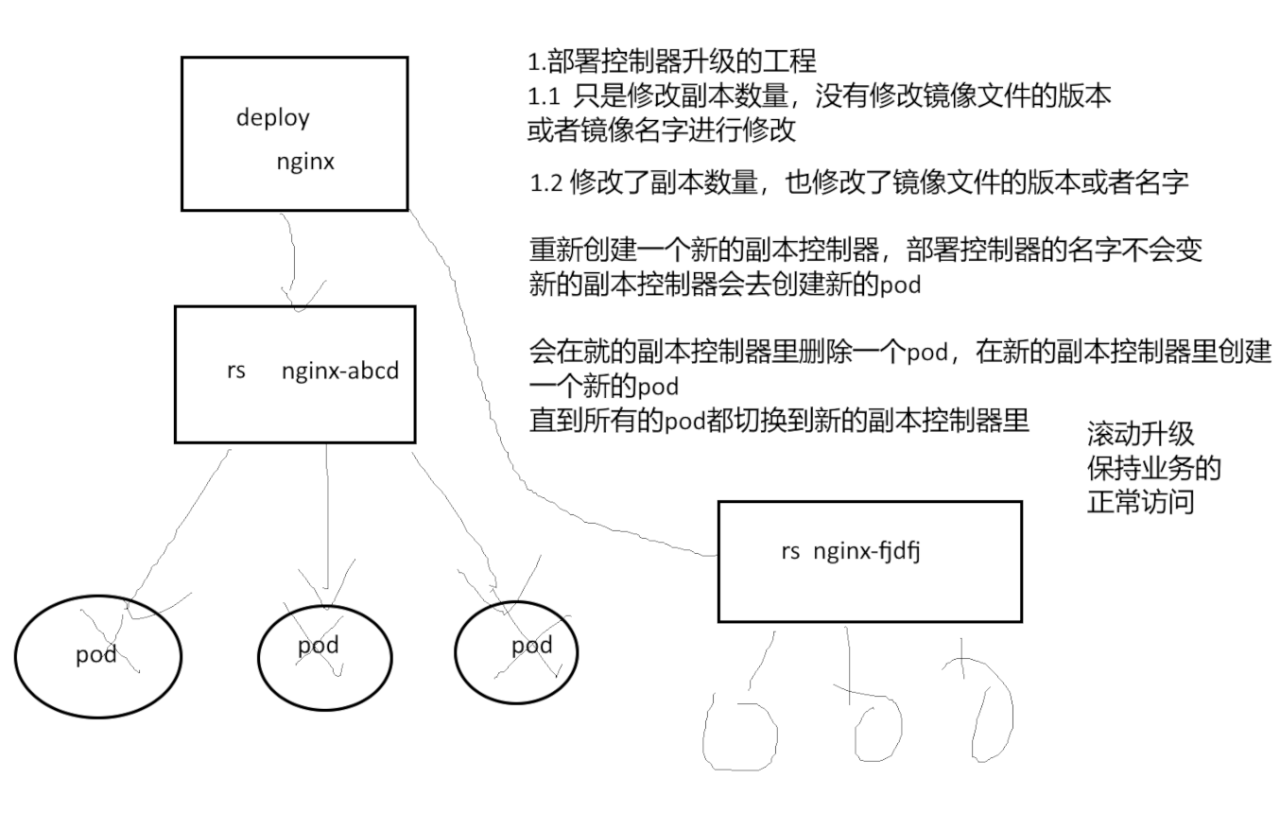
pod状态
名称 状态
running 运行状态
ImagePullBackOff 镜像拉取失败,网络不通或者网速很慢
ErrImagePull 如果长期拉取不下来,就会报这个错
Terminating
正在终止
Pending pod还没有被调度到某个节点上
Failed
completed pod里面的容器主进程已经退出,但是容器没有退出,容器的状态是Exited
Susseeded 停止容器成功,里面的容器全部退出
init:0/2
ContainerCreting 目前正在创建容器
CrashLoopBackOff pod进入了循环启动被杀死,然后又启动又被杀死
OOMKilled 使用的内存超过了范围被杀死
pod启动流程
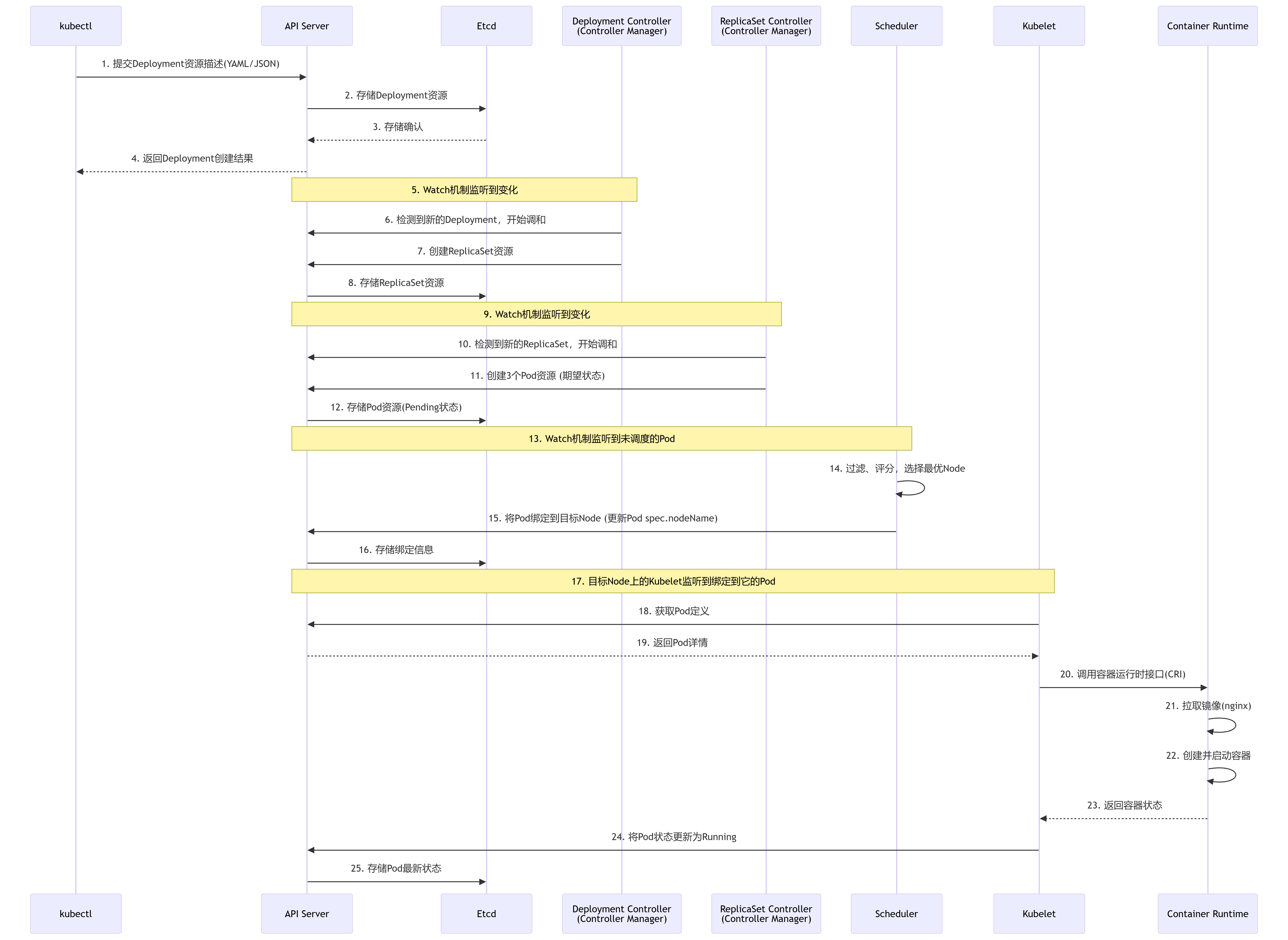
1.管理员使用kubectl给api server发起请求,执行相关操作
2.api server接受请求,将相关数据存入etcd数据库
3.通过watch机制,api server通知控制器管理器,去创建相关的副本控制器,副本控制器根据yaml文件去创建pod,然后将相关信息返回给api server,再写入到etcd数据库
4..通过watch机制,通知调度器生成相关的调度信息,选择好哪个节点服务器去启动pod,在把这些调度信息返回给api server ,写到ETCD数据库
5.通过watch机制,api server会通知被选中执行启动pod的节点服务器上的kubelet去启动pod,kubelet就会通知宿主机上的docer去启动容器。
6.kube-proxy配置pod的网络信息,返回告诉api server,写到ETCD数据库里
7.kubelet启动pod完成后,再返回信息给api server,api server写到ETCD数据库里
8.kube-proxy配置好pod的网络信息,将信息返回给api server,api server将信息存入etcd数据库
静态Pod和动态Pod
静态 Pod
由kubelet 直接管理的 Pod,不通过 Kubernetes API Server,也不受控制平面(如 Controller Manager)的管理
特点
创建方式:由节点上的 kubelet 通过配置文件(通常是 YAML/JSON)直接创建,配置文件通常放在/etc/kubernetes/manifests目录(可通过 kubelet 参数--pod-manifest-path指定)。
生命周期:完全由所在节点的 kubelet 管理,与 kubelet 同生命周期(kubelet 启动时创建,kubelet 停止时销毁)。
API Server 可见性:静态 Pod 会在 API Server 上显示,但无法通过kubectl delete等命令删除(删除后 kubelet 会重新创建)。
节点绑定:固定运行在特定节点上,无法被调度到其他节点。
动态 Pod
通过Kubernetes API Server 创建和管理的 Pod,受控制平面组件(如调度器、控制器)的协调
特点
创建方式:通过kubectl create、API 调用或控制器(如 Deployment、StatefulSet)间接创建,定义存储在 etcd 中。
生命周期:由 API Server 和控制器管理,可被动态调度、扩缩容、更新或删除。
调度机制:由 kube-scheduler 根据节点资源、亲和性等策略自动调度到合适节点。
自愈能力:若 Pod 所在节点故障,控制器(如 Deployment)会在其他节点重建 Pod。
特性 静态 Pod 动态 Pod
管理主体 节点的 kubelet Kubernetes API Server + 控制器
创建方式 节点本地配置文件 API 调用、kubectl、控制器
调度能力 固定在单个节点,无调度 由 scheduler 调度到任意节点
生命周期独立性 依赖所在节点的 kubelet 独立于节点,可在集群内迁移
自愈能力 仅在本节点重启 Pod 控制器可在其他节点重建 Pod
适用场景 集群核心组件、节点级服务 业务应用、需要弹性伸缩的服务
总结
静态 Pod 适用于节点级、与集群生命周期强绑定的组件,提供最基础的启动保障。
动态 Pod 是业务应用的主要形式,借助 Kubernetes 的控制器实现高可用、弹性伸缩等高级特性。
静态Pod如果节点发生异常,那么pod会直接宕机,动态pod在节点宕机后可以转移到其他节点
静态Pod不依赖控制器,而动态Pod依赖控制器来创建和管理
控制器
deployment 部署控制器
Replicaset 副本控制器
damonset 守护进程控制器:在每个node上都调度一个pod
DaemonSet 的一些典型用法:
在每个节点上运行集群守护进程
在每个节点上运行日志收集守护进程
在每个节点上运行监控守护进程
案例:在每个节点上面创建一个日志收集程序
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
these tolerations are to have the daemonset runnable on control plane nodes
remove them if your control plane nodes should not run pods
operator: Exists
effect: NoSchedule
operator: Exists
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v5.0.1
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
it may be desirable to set a high priority class to ensure that a DaemonSet Pod
preempts running Pods
priorityClassName: important
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
cronjob 计划任务控制器:可以定制一个计划任务放在k8s里面去执行
案例:每分钟打印出当前时间
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent #设置拉取策略,当镜像不存在时才去仓库拉取,有的话直接使用
command:
/bin/sh
-c
date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
.spec.schedule 字段是必需的。该字段的值遵循 Cron 语法
┌───────────── 分钟 (0 - 59)
│ ┌───────────── 小时 (0 - 23)
│ │ ┌───────────── 月的某天 (1 - 31)
│ │ │ ┌───────────── 月份 (1 - 12)
│ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周六)
│ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
│ │ │ │ │
│ │ │ │ │
* * * * *
job 批处理控制器:同时处理多个任务
statefullSet 状态控制器
资源限制
内存限制
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: mem-example
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
requests: #限制该容器的请求内存,也就是一开始最多能申请多少
memory: "100Mi"
limits: #限制该容器的最大内存,也就是一直能申请到多少内存
memory: "200Mi"
command: "stress"
args: "--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"
当节点拥有足够的可用内存时,容器可以使用其请求的内存。 但是,容器不允许使用超过其限制的内存。 如果容器分配的内存超过其限制,该容器会成为被终止的候选容器。 如果容器继续消耗超出其限制的内存,则终止容器。 如果终止的容器可以被重启,则 kubelet 会重新启动它,就像其他任何类型的运行时失败一样。
如果申请的内存超过了节点的内存,调度控制器回去查看那个节点能满足条件,在满足条件的节点上创建pod,如果都不能满足,则pid不会被创建
CPU限制
CPU单位,一个核心一般代表1000m,也可以用小数来表示,比如0.1就代表100m
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo
namespace: cpu-example
spec:
containers:
- name: cpu-demo-ctr
image: vish/stress
resources:
limits:
cpu: "1"
requests:
cpu: "0.5"
args:
-cpus
"2"
容器的CPU使用会被限制在1,与内存不同的是,当容器尝试超过限制时,不会杀死容器,而是将容器一直限制在范围内
pod和卷
挂载完卷后就可以去对应的节点查看相关容器的详细信息就可看到挂在的卷对应宿主机的文件夹
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts: #定义卷挂载
- name: redis-storage #卷名
mountPath: /data/redis #定义映射的路径
volumes: #定义一个卷
- name: redis-storage #定义卷名
emptyDir: {} #让docker宿主机-》k8s节点服务器创建一个空文件夹,用来存放数据
容器类型
init容器
初始化容器,一开始创建pod的时候就会启动的容器
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app.kubernetes.io/name: MyApp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: 'sh', '-c', 'echo The app is running! \&\& sleep 3600'
initContainers: #定义初始化容器
- name: init-myservice
image: busybox:1.28
command: 'sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"
- name: init-mydb
image: busybox:1.28
command: 'sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"
然后创建pod,pod创建好后,会去监听mydb和myservice服务,如果有这两个服务,初始化容器才会启动,如果没有,就会持续等待两个服务的注册(代码实现的)
kubectl apply -f myapp.yaml
注册服务
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
apiVersion: v1
kind: Service
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
启动服务
kubectl apply -f service.yaml
查看服务
kubectl get svc
服务起来后,我们就能看到myapp这个容器才是真正的running状态
pause容器
pause容器主要为每个容器创建命名空间(比Init容器还要优先创建)
sidecar容器
挂斗容器,伴随容器,一般用在日志服务上面
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
/bin/sh
-c
>
i=0;
while true;
do
echo "i: (date)" >> /var/log/1.log;
echo "(date) INFO i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox:1.28
args: /bin/sh, -c, 'tail -n+1 -F /var/log/1.log'
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox:1.28
args: /bin/sh, -c, 'tail -n+1 -F /var/log/2.log'
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
创建了一个主程序,用来写入日志,然后创建两个伴生容器,用来读取日志,三个容器使用相同的卷挂载,这样就能访问同一个文件,实现日志的写入和读取
容器起来之后,可以使用下面的命令来查看日志
kubectl logs counter count-log-1
kubectl logs counter count-log-2
如果想要进入伴生容器,可以使用下面的命令
kubectl exec counter -c 容器名 --sh
探针
探针(Probes)是用于监控容器健康状态的机制,Kubernetes 通过探针来确定容器是否正常运行、是否可以接收请求,以及是否需要重启容器
Kubernetes 提供了三种类型的探针:
1、存活探针(Liveness Probe)
作用:检测容器是否处于 "存活" 状态
如果探测失败,kubelet 会杀死该容器并根据重启策略进行处理
主要用于解决容器 "卡死" 但进程仍在运行的情况
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: registry.k8s.io/busybox:1.27.2
args:
/bin/sh
-c
touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe: #启动存活探针探测
exec: #探测方式为exec
command:
cat #exec进入后将会执行cat /tmp/healthy 命令
/tmp/healthy
initialDelaySeconds: 5 #第一次启动后延迟5S进行探测
periodSeconds: 5 #没过5S探测一次
http
apiVersion: v1
kind: Namespace #创建一个命名空间
metadata:
name: sc2
apiVersion: v1
kind: Pod
metadata:
name: sc-nginx-redis
namespace: sc2
spec:
containers:
- name: sc-nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
livenessProbe: #创建一个存活探针
httpGet: #探针策略为httpGet
path: / #http访问根目录
port: 8080 #探测端口为8080
initialDelaySeconds: 3 #第一次探测过3秒再探测
periodSeconds: 3 #每3秒探测一次
readinessProbe: #创建一个就绪探针
tcpSocket: #探针策略为tcpSocket
port: 8090 #探测端口为8090
initialDelaySeconds: 5
periodSeconds: 10
- name: sc-redis
image: redis:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379
nodeName: node-2 #指定部署到哪个节点
restartPolicy: Always #每次启动失败后都重启
查看pod的事件
kubectl describe pod liveness-exec
2、就绪探针(Readiness Probe)
作用:检测容器是否已准备好接收请求
如果探测失败,容器会被从服务的端点列表中移除
主要用于容器启动后需要初始化的场景(如加载配置、连接数据库等)
3、启动探针(Startup Probe)
作用:检测容器内的应用是否已经启动完成
适用于启动时间较长的应用,避免存活探针在启动过程中误判
启动探针成功后,存活探针和就绪探针才开始工作
探测的4中方法
exec--直接进入容器运行某个命令
httpGet--使用http访问容器的某个端口,看返回值是不是200
tcpSocket--去访问容器的某个端口看能否访问
gRPC
启动探针只在启动阶段执行,启动探针启动时,会屏蔽就绪探针和存活探针,直到启动探针探测成功
在运行阶段,就绪探针和启动探针会并行运行
探针是为了增强业务的稳健性,让监控快速响应
服务发布
将创建的pod发布出去,让别人能够通过端口访问pod
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app.kubernetes.io/name: proxy #定义一个Pod的标签
spec:
containers:
- name: nginx
image: nginx:stable
ports:
- containerPort: 80
name: http-web-svc #给端口设置一个名字
apiVersion: v1
kind: Service #发布的服务就相当于一个负载均衡器
metadata:
name: nginx-service
spec:
selector: #选择器
app.kubernetes.io/name: proxy #选择本次发布是在标签app.kubernetes.io/name为proxy的pod
ports:
- name: name-of-service-port #发布的端口的名字
protocol: TCP #端口类型
port: 80 #发布的端口
targetPort: http-web-svc #要发布的容器的端口
服务类型
ClusterIP:集群内部的公开服务,只能在集群内部访问
NodePort:通过每个节点上的 IP 和静态端口(NodePort)公开 Service,这样就能通过宿主机的ip+静态端口进行访问
apiVersion: v1
kind: Service
metadata:
name: nginx-nfs-svc
spec:
selector:
app: nginx-nfs #选择要发布的pod,通过label筛选,这个会创建一个endpoints
type: NodePort #指定服务类型
ports:
- port: 80 #发布的服务的端口
targetPort: http-server #使用的容器的端口
nodePort: 30080 #宿主机对外的静态端口
protocol: TCP
LoadBalancer:使用云平台的负载均衡器向外部公开 Service
ExternalName:将服务映射到 externalName 字段的内容(例如,映射到主机名 api.foo.bar.example)
流程
为什么使用ipvs而不是iptables
iptables采用的是顺序存储结构,这意味着如果pod的数量越来越多,那么iptables表的长度会越来越大,导致查找困难
而ipvs采用的是hash表进行存储,这样就能解决存储与查找的问题
Endpoint
创建一个service就会创建一个endpoint,endpoint会映射服务和pod的关系,删除service的时候也
查看endpoint
kubectl get endpoints
HPA-VPA
hpa:自动水平扩缩:根据负载情况,自动增加或减少pod的数量,每个pod的内存和cpu资源不变
vpa:自动垂直扩缩:根据负载情况,自动增加或减少pod的资源,pod的数量不变
创建一个pod,限制它的cpu
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: k8s.gcr.io/hpa-example
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
然后给部署控制器创建一个hpa
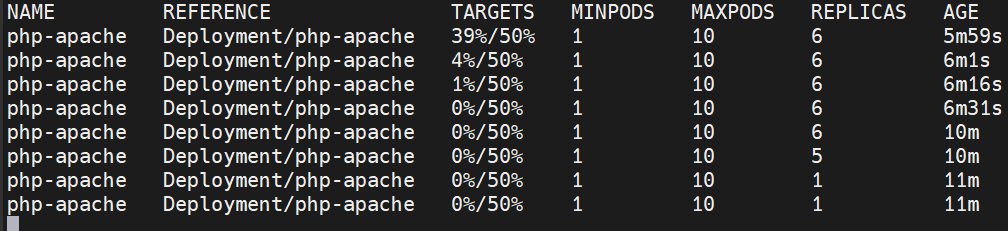
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
然后可以模拟一下负载
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
在负载情况上来之后,我们就能看到hpa开始给我们创建pod,会一直创建到cpu负载到我们指定的水平之下或者创建数量达到上限

在我们停止之后,就会看到hpa开始回收不需要的pod,直到负载接近我们设置的水平
Pod调度
自动调度
运行在哪个节点上完全由Scheduler经过一系列算法计算得出
kube-scheduler是k8s的核心组件之一,负责根据定义的pod的调度要求和节点的可用资源,将pod调度到适当的节点上,流程如下
1.监听新建的pod和更新的pod,当发现新建或更新的Pod时,会放入调度队列中
2.遍历队列中的pod,为其选择一个合适的节点
3.将pod绑定到指定的节点上
定向调度
nodeName:基于节点名字调度
apiVersion: v1
kind: Namespace
metadata:
name: yozi
apiVersion: v1
kind: Pod
metadata:
name: yoyezee
namespace: yozi
labels:
stu: good
spec:
containers:
- name: ye-nginx
image: nginx
ports:
- containerPort: 80
name: http-port
nodeName: k8s2 #根据节点名字定向调度,此处指定到k8s2节点
NodeSelector:基于节点的标签调度
打标签
kubectl label 类型 名称 k=v
#查看标签
kubectl get 类型 --show-labels
#删除标签
kubectl label 类型 名称 k-
创建pod
apiVersion: v1
kind: Pod
metadata:
name: pod-yoyezee
namespace: yozi
spec:
containers:
- name: yoyezee-nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: http-port
nodeSelector: #根据标签选择调度的节点
nodeenv: pro #具体的标签,k: v对应
亲和性调度
nodeAffinity(node亲和性):以node为目的,解决pod可以调度到哪些node的问题
apiVersion: v1
kind: Pod
metadata:
name: nginx-luobiao
spec:
affinity:
nodeAffinity: #指定node亲和性调度
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
matchExpressions:
key: disktype
operator: In #In 操作符表示标签的值需要匹配 values 列表中的任意一个值
values:
- ssd
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
#requiredDuringScheduling意味着这是调度时的硬性要求,如果没有满足条件的节点,Pod 会处于 Pending 状态
#IgnoredDuringExecution 表示当节点标签发生变化不再满足条件时,已经运行的 Pod 不会被驱逐
od亲和性:根据一个已有的Pod来选择调度到哪个node节点
创建一个pod
apiVersion: v1
kind: Pod
metadata:
name: nginx-lei
labels:
workcity: guangzhou
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
然后创建一个pod实施pod亲和性
apiVersion: v1
kind: Pod
metadata:
name: nginx-xiaoan
labels:
workcity: guangzhou
spec:
affinity:
podAffinity: #指定使用pod亲和性
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: workcity
operator: In
values: "guangzhou","changsha" #选择标签workcity在列表内的pod
topologyKey: kubernetes.io/hostname
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
pod反亲和性:调度到一个没有目标pod的节点上
apiVersion: v1
kind: Pod
metadata:
name: nginx-cj
labels:
workcity: shanghai
spec:
affinity:
podAntiAffinity: #指定为反亲和性调度
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: workcity
operator: In
values: "guangzhou","shenzhen" #将会调度到没有workcity在列表内的pod的节点上
topologyKey: kubernetes.io/hostname
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent