锋哥原创的TensorFlow2 Python深度学习视频教程:
https://www.bilibili.com/video/BV1X5xVz6E4w/
课程介绍

本课程主要讲解基于TensorFlow2的Python深度学习知识,包括深度学习概述,TensorFlow2框架入门知识,以及卷积神经网络(CNN),循环神经网络(RNN),生成对抗网络(GAN),模型保存与加载等。
TensorFlow2 Python深度学习 - TensorFlow2框架入门 - Sequential顺序模型
Sequential顺序模型是Keras中最简单的线性堆叠模型,各层之间按顺序依次连接,前一层的输出作为后一层的输入。这种模型适合构建简单的神经网络结构。
先提前了解下Keras中常用模型
-
Sequential 模型:适用于简单的层按顺序堆叠的模型。
-
Functional API(函数式API):适用于多输入、多输出、共享权重等更复杂的结构。
-
子类化模型(Sub-classing Model):适用于极其自定义的网络结构,提供最大的灵活性。
-
预训练模型(Pre-trained Models):使用预训练模型进行迁移学习,特别适用于计算机视觉和自然语言处理。
-
共享层权重模型(Shared Weights Model):适用于需要在多个输入之间共享权重的场景,如Siamese 网络。
Keras Input层
Input层是Keras中用于明确指定模型输入张量形状和属性的特殊层。它在构建复杂模型(特别是函数式API)时非常重要。
# 基本用法
input_tensor = Input(shape=(input_shape,))
# 完整参数
input_tensor = Input(
shape=None,
batch_size=None,
name=None,
dtype=None,
sparse=None,
tensor=None,
ragged=None,
**kwargs
)核心参数:
-
shape: 输入形状元组,不包括batch大小
-
batch_size: 固定batch大小(可选)
-
name: 层的名称
-
dtype : 数据类型,如
tf.float32 -
sparse: 是否创建稀疏张量
-
tensor: 可选现有张量包装为Input层
Keras Dense层
Dense层(全连接层)是神经网络中最基本也是最常用的层类型。每个神经元与前一层的所有神经元相连接,实现特征的线性变换和非线性激活。
# 基本用法
dense_layer = Dense(units, activation=None, **kwargs)
# 完整参数
dense_layer = Dense(
units,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)核心参数
-
units: 指定该层神经元的个数,决定了该层的输出维度。
-
activation: 激活函数,如 'relu', 'sigmoid', 'softmax', 'tanh' 等
-
use_bias: 布尔值,是否使用偏置向量
初始化器
-
kernel_initializer: 权重矩阵初始化方法
-
bias_initializer: 偏置向量初始化方法
正则化
-
kernel_regularizer: 权重正则化(L1/L2)
-
bias_regularizer: 偏置正则化
-
activity_regularizer: 输出正则化
约束
-
kernel_constraint: 权重约束
-
bias_constraint: 偏置约束
在Keras中,除了Dense层(全连接层)之外,还有许多常用的层,用于构建各种神经网络结构。以下是一些常见的层及其功能:
- 卷积层 (Convolutional Layers)
-
Conv1D: 适用于一维数据(如时间序列数据)。常用于处理序列数据,如文本和音频。
-
Conv2D: 适用于二维数据(如图像)。常用于图像处理和计算机视觉任务。
-
Conv3D: 适用于三维数据(如视频或3D体积数据)。
- 池化层 (Pooling Layers)
-
MaxPooling1D: 适用于一维数据,执行最大池化操作。
-
MaxPooling2D: 适用于二维数据,执行最大池化操作。
-
MaxPooling3D: 适用于三维数据,执行最大池化操作。
-
AveragePooling1D: 适用于一维数据,执行平均池化操作。
-
AveragePooling2D: 适用于二维数据,执行平均池化操作。
-
AveragePooling3D: 适用于三维数据,执行平均池化操作。
- 循环层 (Recurrent Layers)
-
LSTM: 长短期记忆网络(Long Short-Term Memory),用于处理序列数据,解决传统RNN的梯度消失问题。
-
GRU: 门控循环单元(Gated Recurrent Unit),比LSTM简化,通常训练更快。
-
SimpleRNN: 基本的循环神经网络层,适用于简单的序列任务。
- 归一化层 (Normalization Layers)
-
BatchNormalization: 批量归一化,用于加速训练,稳定学习过程,减少内部协变量偏移。
-
LayerNormalization: 层归一化,主要用于对每一层的输入进行标准化。
-
GroupNormalization: 分组归一化,将特征分为小组进行归一化。
- Dropout层
- Dropout: 随机丢弃神经网络中的一部分神经元,用于防止过拟合。
- 激活函数层
-
Activation
: 将某种激活函数应用到输入。常见的激活函数有:
-
relu:线性整流单元 -
sigmoid:Sigmoid函数 -
tanh:双曲正切函数 -
softmax:常用于分类任务的输出层
-
- Flatten层
- Flatten: 将多维输入展平为一维数据,通常用于将卷积层或池化层的输出展平,以连接到全连接层。
- 全连接层 (Fully Connected Layers)
- Dense: 前向传播过程中常用的全连接层。可以有多个神经元,通常用于模型的最终分类或回归任务。
- Embedding层
- Embedding: 用于将离散数据(如词索引)映射到稠密的向量空间,常用于自然语言处理任务。
- Reshape层
- Reshape: 用于改变输入数据的形状。
- 自定义层
- Lambda: 创建自定义操作,可以用于实现一些复杂的数学操作或将某些操作封装到一个层中。
- Global池化层
-
GlobalMaxPooling1D/2D/3D: 全局最大池化,减少维度,保留全局特征。
-
GlobalAveragePooling1D/2D/3D: 全局平均池化,减少维度,保留全局特征。
- Separable卷积层
- SeparableConv2D: 分离卷积,使用深度可分离卷积提高计算效率,尤其在移动设备上很常用。
- UpSampling层
- UpSampling1D/2D/3D: 上采样层,用于增大输入的尺寸,通常用于生成模型和上采样任务。
Keras 激活函数
激活函数是神经网络中的非线性变换函数,它决定了神经元的输出。没有激活函数,神经网络就只是线性回归模型,无法学习复杂模式。常用激活函数,如 'relu', 'sigmoid', 'softmax', 'tanh'
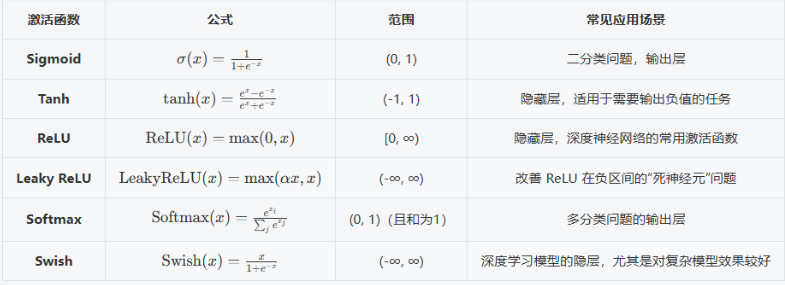
说明:
-
Sigmoid 和 Softmax 主要用于分类问题的输出层,尤其是二分类和多分类任务。
-
Tanh 通常用于需要输出负值的任务,且它的输出范围较对称。
-
ReLU 和 Leaky ReLU 常用于隐藏层,尤其是深度神经网络中,后者通过为负数部分引入斜率,避免了 ReLU 的"死神经元"问题。
-
Swish 是 Google 提出的新型激活函数,近年来在一些深度学习模型中取得了不错的效果,尤其是在深层网络中。
Keras模型编译方法model.compile()
model.compile()是Keras中配置模型学习过程的关键方法,它在模型构建后、训练前调用,用于指定模型的优化器、损失函数和评估指标。
model.compile(optimizer, loss=None, metrics=None, loss_weights=None, weighted_metrics=None, run_eagerly=None, steps_per_execution=None, **kwargs)核心参数:
- optimizer(优化器)
-
作用:定义模型参数更新的算法
-
常用选项:
-
'adam'- 自适应矩估计(最常用) -
'sgd'- 随机梯度下降 -
'rmsprop'- 适用于RNN -
'adagrad'- 自适应学习率
-
- loss(损失函数)
-
作用:定义模型训练中要最小化的目标函数
-
常用选项:
-
分类问题:
-
'binary_crossentropy'- 二分类 -
'categorical_crossentropy'- 多分类 适用于标签采用one-hot编码的情况(如1,0,0表示类别1) -
'sparse_categorical_crossentropy'- 整数标签多分类 适用于标签为整数编码的情况(如直接使用类别序号3、1等)。
-
-
回归问题:
-
'mean_squared_error'- 均方误差 -
'mean_absolute_error'- 平均绝对误差
-
-
- metrics(评估指标)
-
作用:监控训练和测试过程的性能指标
-
常用选项:
-
'accuracy'- 准确率(分类) -
'precision','recall'- 精确率、召回率 -
'mae','mse'- 回归指标
-
我们看下示例代码:
import tensorflow as tf
from keras import Input, layers
# 正确的权重和偏置
TRUE_W = 3.0
TRUE_B = 2.0
NUM_EXAMPLES = 201
# 在区间[-2, 2]内生成NUM_EXAMPLES个均匀分布的数值点
x = tf.linspace(-2, 2, NUM_EXAMPLES)
x = tf.cast(x, tf.float32)
def f(x):
return x * TRUE_W + TRUE_B
# 生成随机噪声数据
noise = tf.random.normal(shape=[NUM_EXAMPLES])
# 计算y
y = f(x) + noise
# 定义一个顺序模型
model = tf.keras.Sequential([
Input(shape=(1,)),
layers.Dense(units=1)
])
# 打印模型结构
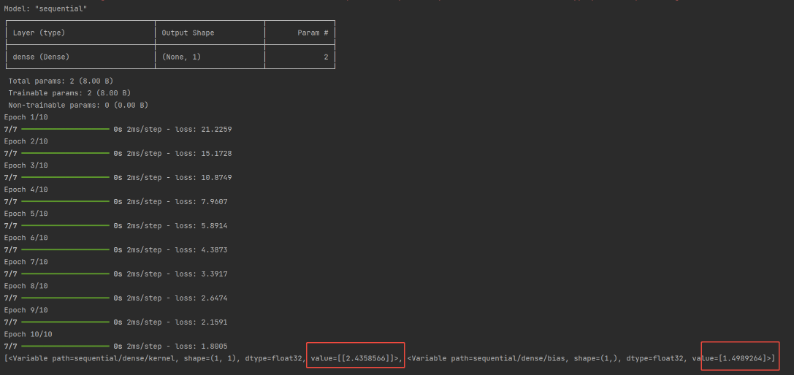
model.summary()
# 编译配置模型 使用SGD(随机梯度下降)优化器,均方误差损失函数
model.compile(optimizer='sgd', loss='mean_squared_error')
# 训练模型
model.fit(x, y, epochs=10)
# 打印模型参数
print(model.variables)运行结果: