1. 内存
1.1 简介

孙悟空象征躁动的"心猿",需历事以悟"空";
猪八戒象征贪欲的"水猪",需持戒以悟"能";
沙和尚居于二者之间,象征调和的"脾土",以静制动、以中正化偏,悟"净"而不染。
内存,一种优化存储效率而诞生的产物,为了缓和cpu与磁盘之间工作效率的不对等。
先来了解一些基本的东西吧。
- RAM: 随机访问存储器,计算机的"工作区"。 可以在任意地址进行读写操作,速度快,但断电后数据丢失。 是所有程序运行的基础内存。
- DRAM: 动态随机存储器,系统主内存的核心。通过电容存储信息,需要定期刷新来维持数据。 容量大、成本低,但速度较慢。
- SRAM:静态随机存储器,通过晶体管保持数据,不需刷新。 速度极快,但成本高、容量小。常用于 CPU Cache(L1/L2/L3) 。
- DDR:DDR 是 DRAM 的改进型,在时钟信号的上升沿和下降沿都能传输数据。 带宽翻倍、功耗更低,是现代主内存的主流技术(DDR4、DDR5 等)。
1.2 内存的基本原理
设想这样一个场景:
我们有一个很大的数组,用来存放大量数据。最直觉的做法,当然是------从头到尾,顺序地写入。
但问题来了。
如果系统中有多个进程,每个进程都希望拥有自己独立的数组空间 ,那这块连续的内存就必须被切分成若干小块,分配给不同的进程使用。
然而, "切块"远没有看上去那么简单。
切多大?------要不要分页、分段,还是页段结合?
怎么分?------是按先进先出(FIFO)回收,还是更灵活的算法?
顺序如何?------哪些块可以共享,哪些必须独立?
如何避免相互干扰?又如何让每一块都被充分利用?
切块与数据存放之间的对应关系,又该如何维持?
看似只是把一个大数组"分块",
但背后,正是操作系统在做的事------从物理内存到虚拟内存,从分配到回收,一切都围绕着"如何让每个进程都各得其所"展开。
本文的重点不在于此,所以不一一学习了,先来学学内存的物理地址与虚拟地址吧。

在 32 位系统中(本文也基于 32 位架构进行说明),
一个虚拟地址通常被划分为两部分:
- 高 12 位(页号) :表示页表中的偏移量,可以理解为"页表数组"的下标;
- 低 20 位(页内偏移) :表示数据在对应物理页中的具体位置。
因为页表在内存中是连续存放的,所以页号就像数组索引,通过它可以直接定位到对应的页表条目。
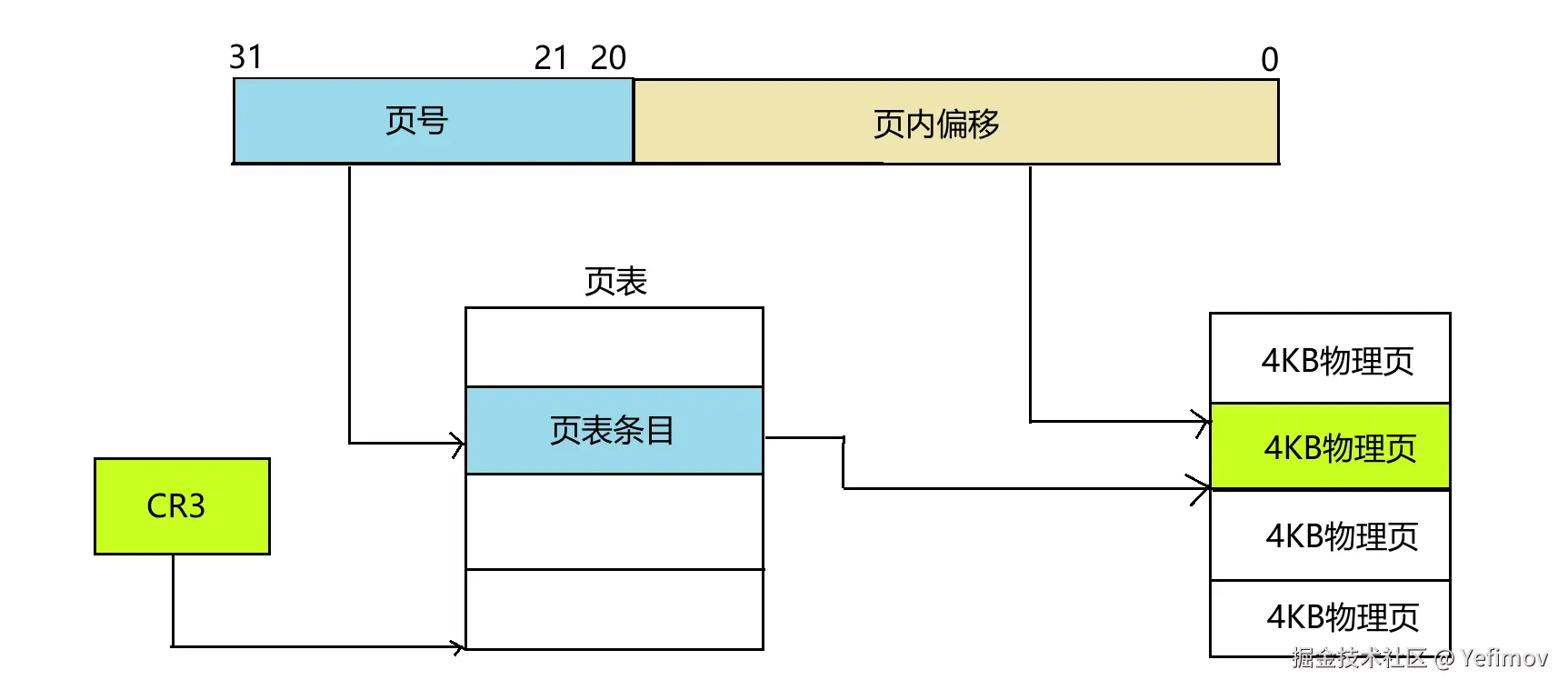
而 CPU 内部有一个特殊的寄存器------CR3 ,它保存了当前进程页表的起始地址。
当程序访问一个虚拟地址时,CPU 会做以下几步:
- 从 CR3 取得页表基地址;
- 结合虚拟地址的页号,定位到页表中的对应条目;
- 从该条目中读取出物理页的起始地址;
- 最后加上页内偏移量,得到数据的真实物理地址。
1.3 TLB
如前所述,CPU 访问一个虚拟地址 VA 时,通常需要 三次访存:
- 第一次访存:读取页目录项(PDE)
- 第二次访存:读取页表项(PTE)
- 第三次访存:访问实际的数据页
三次访存显然成本不低,那么有没有办法再快一些?
答案是------在 CPU 与内存之间再加一层缓存:TLB(Translation Lookaside Buffer,快表) 。
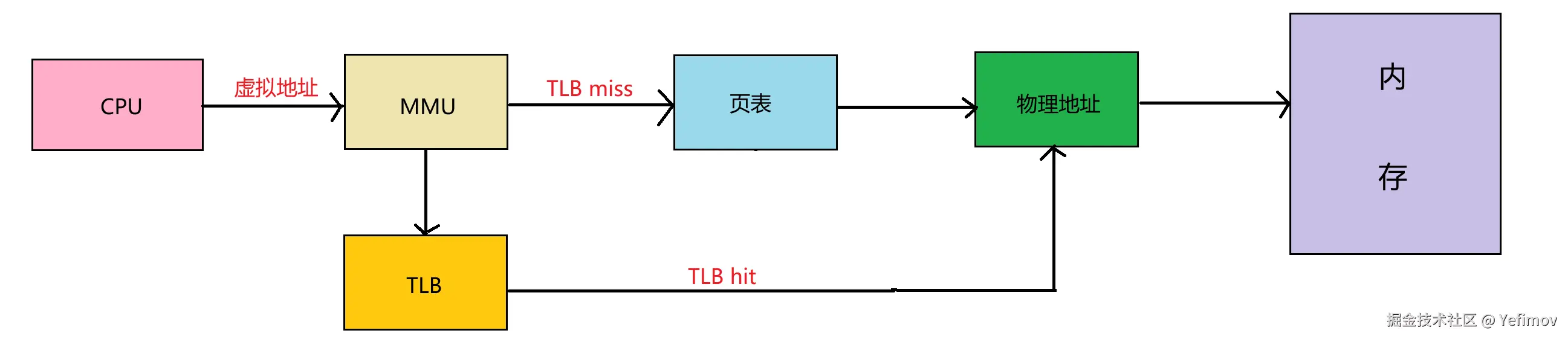
TLB 是 MMU(内存管理单元)中的高速缓存 ,用来加速虚拟地址到物理地址的转换。
它保存了最近使用过的页表项(PTE),这样 CPU 不必每次都访问内存中的页表,就能快速完成地址映射,从而显著降低访存延迟。
当 CPU 发出虚拟地址时:
- 若 TLB 命中(hit) ,即可直接获得对应的物理地址(只需一次访存);
- 若 TLB 未命中(miss) ,则需要访问内存中的页表完成转换,并将结果写回 TLB,以便下次快速命中(仍是三次访存)。
1.4 大页
从前面的逻辑地址到物理地址的转换可以看出,如果使用常规 4KB 页,并假设 TLB 总能命中,那么至少需要在 TLB 中存放两个表项。
在这种情况下,只要访问的内容都在同一页内,就无需额外查表。
然而,当程序规模扩大时,问题就来了。
例如,一个占用 2MB 空间的程序需要 512 个页(2MB / 4KB = 512),也就需要 512 个页表项才能保证完全命中。
由于 TLB 的容量有限,随着程序使用的内存增加,TLB 很容易被占满,从而导致频繁的 TLB Miss。
此时,大页(Huge Page)的优势就体现出来了。
如果以 2MB 作为分页单位,那么只需 一个 TLB 表项 就能覆盖相同的 2MB 地址空间;
对于使用 GB 级内存 的大型程序,更可采用 1GB 大页,进一步减少 TLB Miss,提高地址转换效率。
1.5 NUMA
 在早期的 SMP 系统中:
在早期的 SMP 系统中:
- 所有 CPU 通过 同一条总线 访问内存和外设;
- CPU 之间平等,无主从之分;
- 所有硬件资源共享,每个 CPU 都能访问任意内存、外设等;
- 内存结构统一,寻址一致(UMA,Uniform Memory Architecture)。
然而,随着 CPU 核心数量不断增加:
- 所有处理器共享同一条系统总线,总线成为瓶颈;
- CPU 与内存之间的访问延迟增大,整体性能提升受限。
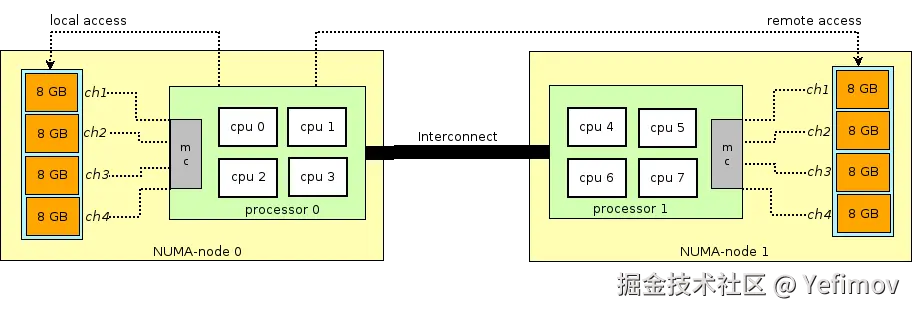
为了解决这一问题,NUMA 架构应运而生:
- CPU 被划分为多个 NUMA Node;
- 每个 Node 拥有独立的内存和 PCIe 总线系统;
- 节点之间通过 QPI 总线 或类似互连进行通信。
在 NUMA 系统中:
- 访问本地节点内存速度最快;
- 访问远端节点内存速度较慢;
- 访问延迟与 CPU 节点之间的距离(Node Distance)相关,因此称为 非一致性内存访问。
虽然 NUMA 大幅缓解了 SMP 架构下多核 CPU 扩展带来的瓶颈,但它也带来一些新的挑战:
- 当本地内存不足时,必须跨节点访问远端内存,访问延迟较高;
- 应用程序若频繁跨节点操作,会导致性能下降。
因此,在 NUMA 系统下开发应用时,应注意:
- 尽量让任务固定在 本地 CPU 节点,减少远程访问;
- 降低不同 CPU 模块之间的交互;
- 合理规划内存分配,提升整体性能。
2. Cache
2.1 简介
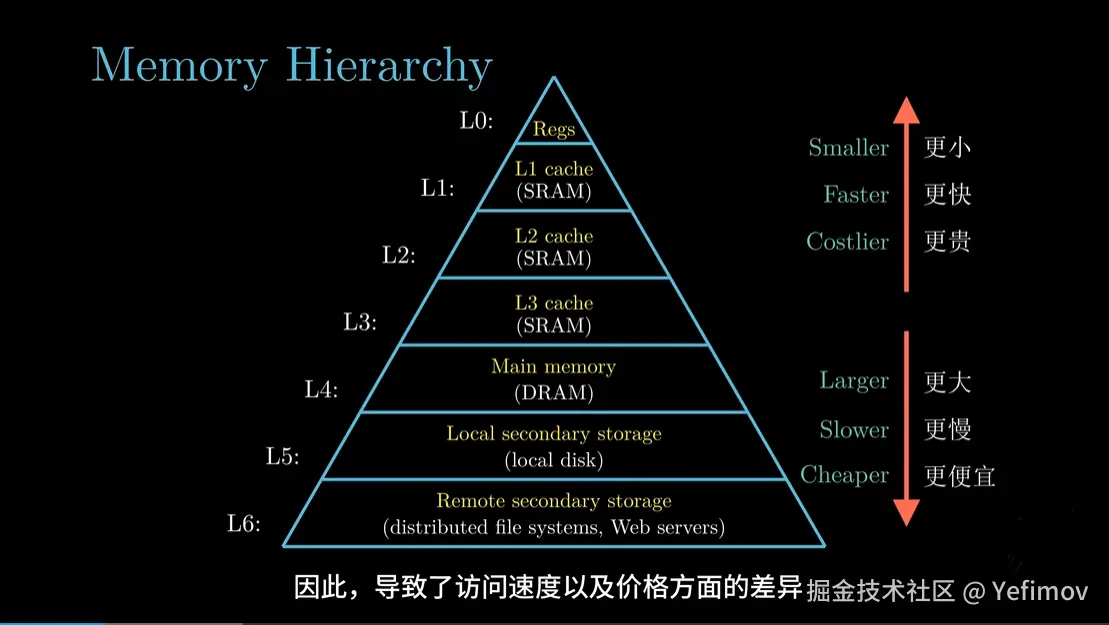 内存的速度,仍然赶不上 CPU。
内存的速度,仍然赶不上 CPU。
虽然 DRAM 的访问时间只有几十纳秒,但对 GHz 级的 CPU 来说,这仍然太慢了。
于是,为了让 CPU 不再"干等",人们又在内存和 CPU 之间,插入了一层更小、更快的存储层------Cache(高速缓存) 。
Cache 的核心思想,仍然是那句古老的真理:
"程序的局部性原理(Locality Principle)。"
即:
- 时间局部性(Temporal Locality) :如果某个数据被访问过,它很可能马上还会被访问。
- 空间局部性(Spatial Locality) :如果访问了某个地址,邻近地址也很可能被访问。
因此,CPU 不必每次都从内存中取数据,而是提前把可能要用的数据 放进 Cache 中。
下次用到时,直接命中,省去了高延迟的内存访问。
| 层级 | 名称 | 典型大小 | 延迟 | 特点 |
|---|---|---|---|---|
| L1 Cache | 一级缓存 | 32KB~64KB | 几个周期 | 每个核心独有,速度最快 |
| L2 Cache | 二级缓存 | 256KB~1MB | 十几周期 | 每个核心独有或半共享 |
| L3 Cache | 三级缓存 | 2MB~64MB | 数十周期 | 多核心共享,用于跨核心数据交换 |
| Memory | 主内存 | GB 级 | 上百周期 | 容量大,速度慢 |
2.2 Cache地址映射和变换
Cache 本质上是一张"小表"------
具体来说,就是把存放在内存中的内容按照某种规则装入到Cache中,并建立内存地址与Cache地址之间的对应关系。
Cache Line
Cache 不会按字节或页存取,而是以固定长度的块为单位,称为 Cache Line (通常为 64 字节)。
这也是 CPU 每次从内存中读取的最小单元。
例如:
当程序访问地址 0x1000 时,CPU 实际会把 0x1000~0x103F 的整块数据加载到 Cache 中。
为了解决"物理地址如何放进有限的 Cache"这个问题,CPU 通常采用以下三种映射方式:
-
直接映射(Direct Mapped)
- 每个物理地址只能映射到 Cache 的唯一一行;
- 优点:实现简单;
- 缺点:容易冲突(冲突失效)。
-
全相联映射(Fully Associative)
- 任意物理块可放入 Cache 的任意位置;
- 优点:灵活;
- 缺点:查找复杂(需并行比较标签)。
-
组相联映射(Set Associative)
- 折中方案:Cache 被分为若干"组",每组包含若干行(称为 n 路组相联);
- 地址中的一部分用于选择组号,一部分用于匹配标签。
例如,一个 4 路组相联的 32KB Cache,每行 64B:
- 共 32KB / 64B = 512 行;
- 512 / 4 = 128 组;
- 地址低 6 位是行内偏移;
- 接下来的 7 位是组号;
- 剩余高位为标签(Tag)。
这样,Cache 查找过程为:
scss
(1) 取地址的组号部分 -> 找到对应组;
(2) 比较组内每行的 Tag;
(3) 匹配成功则命中,否则 Miss。2.3 Cache的预取
即使有多级 Cache,访问内存仍可能花费上百个 CPU 周期。 而现代处理器的流水线是高度并行的:
当某个指令等待数据从内存取回时,整个流水线都可能被阻塞,这就叫做 Cache Miss Stall。
而Cache 预取(Prefetching) 主要是让 CPU 尽量提前把未来可能访问的数据 从内存取到 Cache 中,
从而在真正访问时无需等待,从"取用分离"变成"用即所得"。
预取的原理在于局部性原理,例如:
c++
for (i = 0; i < N; i++)
sum += a[i];CPU 观察到 a[i] 的地址在每次访问后都线性递增, 它就可以推断出:接下来很可能访问 a[i+1]、a[i+2] ......
于是它在后台提前把后续几个 Cache Line 从内存加载进来。 当真正访问时,这些数据已经"静静地等在那里"。
2.3.1 硬件预取
由 CPU 内部电路自动完成,不需要程序参与。 CPU 中有一个专门的"预取引擎"(Prefetch Engine), 它通过实时监控内存访问模式,自动判断是否值得提前加载。
硬件预取的常见算法:
| 名称 | 原理 | 特点 |
|---|---|---|
| Sequential Prefetch | 检测线性访问模式(如数组遍历),提前加载下一个 Cache Line | 最常见、最稳定 |
| Stride Prefetch | 检测固定步长访问模式(如 ai+4、ai+8) | 对规则性访问效果极好 |
| Stream Prefetch | 维护多个独立流的访问预测(例如多数组交替访问) | 适合多线程、流水线场景 |
| Adjacent Line Prefetch | 加载当前 Cache Line 的同时也加载相邻行 | 简单粗暴但命中率高 |
硬件预取的优势在于自动化、零侵入 ,但缺点是无法理解程序逻辑,容易"过度积极"。
例如程序访问一次性随机跳转的数据,会导致 CPU 白白加载一堆无用行------这叫 Cache 污染(Cache Pollution) 。
2.3.2 软件预取
软件预取是由程序员显式发出的指令 ,告诉 CPU:
"我稍后要用这个地址,你先帮我取一下。"
常见形式如:
arduino
#include <xmmintrin.h>
_mm_prefetch((const char*)&a[i+16], _MM_HINT_T0);这条指令不会立刻使用数据,也不会阻塞流水线,
只是悄悄发出一个"预加载请求",让数据在未来的某一时刻出现在 Cache 里。
_MM_HINT_T0表示加载到 L1 Cache;_MM_HINT_T1/T2可指定加载到更高层 Cache(如 L2/L3);_MM_HINT_NTA表示"非时间局部性"(no temporal locality),用于一次性数据。
软件预取的优势在于更精准 ,可以结合业务逻辑和数据结构调度。
但需要程序员对硬件特性非常熟悉,否则容易适得其反。
2.4 Cache的写策略
Cache 不只是读数据,还要写数据。
但写的地方可能在 CPU,也可能在主内存,于是出现了几种不同的策略:
| 策略 | 特点 | 优缺点 |
|---|---|---|
| Write Through | 同步写入内存(每次写 Cache 时同时写内存) | 数据一致性好,但速度慢 |
| Write Back | 仅写入 Cache,延迟写回内存(脏行标记) | 性能高,但需额外一致性控制 |
| Write Allocate | 写 Miss 时先加载到 Cache,再修改 | 适合 Write Back 策略 |
| No Write Allocate | 写 Miss 时直接写内存 | 适合 Write Through 策略 |
通常采用 Write Back + Write Allocate 的组合方案,以平衡速度与一致性。
2.5 Cache一致性
在多核系统中,每个核心都有自己的 Cache。
那么,当多个核心同时访问同一块内存时,如何保证数据一致?
这就是 Cache 一致性协议(Cache Coherency Protocol) 的职责。
最经典的方案是 MESI 协议:
| 状态 | 全称 | 含义 |
|---|---|---|
| M | Modified | 当前 Cache 拥有最新数据(脏行) |
| E | Exclusive | 数据仅在本 Cache 中,未修改 |
| S | Shared | 数据可能存在于多个 Cache 中 |
| I | Invalid | 数据无效(已被修改或替换) |
当一个核心修改了某行数据,其他核心的相同地址就会被标记为 Invalid ,
从而强制它们重新从内存或其他核心拉取最新数据。
2.6 DDIO
在传统的 I/O 模型中:
外设(如网卡)通过 DMA 将数据写入内存,
然后 CPU 再从内存中读入 Cache,参与处理。
这种"中转站式"流程会导致额外的内存带宽占用和延迟。
为此,Intel 在 Xeon 处理器中引入了 DDIO(Data Direct I/O) 技术。
DDIO 的核心思想:
让外设直接与 CPU 的 L3 Cache 交互。
当开启 DDIO 时,网卡的 DMA 不再写入主内存,而是直接写到 L3 Cache 的特定区域。
这样:
- CPU 处理网络数据时,可直接从 Cache 读取;
- 减少一次主内存访问;
- 显著降低延迟、提升吞吐。
DDIO 在高性能网络系统(如 DPDK、RDMA、TGW 等)中发挥着重要作用,
它让 Cache 与 I/O 协同 成为可能,也让"零拷贝(Zero-Copy)"真正接近理想状态。