LLaVA 于 2023 年提出,通过低成本对齐高效连接开源视觉编码器与大语言模型,使「看图 --- 理解 --- 对话」的多模态能力在开放生态中得以普及,明显缩小了与顶级闭源模型的差距,标志着开源多模态范式的重要里程碑。

LLaVA 用低成本对齐打通「视觉编码器 + 大语言模型」起步,LLaVA‑1.5 以更大更干净的数据与高分辨率输入强化理解,LLaVA‑NeXT 拓展 OCR / 数理与多场景任务;随后分支为 LLaVA‑NeXT‑Video 处理时序视频、多帧推理,及 LLaVA-NeXT-Interleave 支持交替多图文与跨图联推;最终在 LLaVA‑OneVision 汇聚为统一接口,覆盖图像 / 文档 / 图表 / 多图 / 视频,兼顾效果与效率。
尽管多模态对齐的接口与架构趋于收敛,真正「可复现」的开源路径仍与「仅开放权重」存在间距。Qwen2.5‑VL、InternVL3.5 在 OCR、文档理解、数理与跨图推理上树立高基线,但完整的数据清单、清洗与混合比例,以及对齐 / 采样与训练日程多为部分披露,难以端到端重现。Molmo 以更干净的数据流水线与精细化设计,在多项评测与偏好中逼近闭源强基线;Open‑Qwen2VL 则表明在更高效范式下,即便原始多模态 token 占比较低亦能取得强对比性能。当前主要鸿沟在于 「配方与工程细节的可复现性」,而非单一的模型架构选择。
灵感实验室团队联合 LMMs-Lab 围绕「高性能 --- 低成本 --- 强复现」三大目标,在 LLaVA-OneVision 体系上推出完整开放的概念均衡 85M 预训练数据集(LLaVA-OV-1.5-Mid-Training-85M)与精筛 22M 指令数据集(LLaVA-OV-1.5-Instruct-22M),并沿用紧凑的三阶段流程(语言--图像对齐 Stage‑1、概念均衡与高质量知识注入 Stage‑1.5、指令微调 Stage‑2),结合离线并行数据打包(最高约 11× padding 压缩)与 Megatron‑LM + 分布式优化器,将 8B 规模 VL 模型的 Stage‑1.5 预训练在 128 张 A800 上控制在约 4 天内完成,预算控制在 1.6 万美元。
在此基础上,我们提出 LLaVA‑OneVision‑1.5,继承并扩展 LLaVA 系列:引入 RICE‑ViT 支持原生分辨率与区域级细粒度语义建模、强化图表 / 文档 / 结构化场景理解,延续紧凑三阶段范式以避免冗长 curriculum,构建并强调「质量 --- 覆盖 --- 均衡」的 85M 预训练与 22M 指令集合,并真正意义上实现全链条透明开放(数据、训练与打包工具链、配置脚本、日志与可复现评测命令及其构建与执行细节),以确保社区低成本复现与可验证拓展。
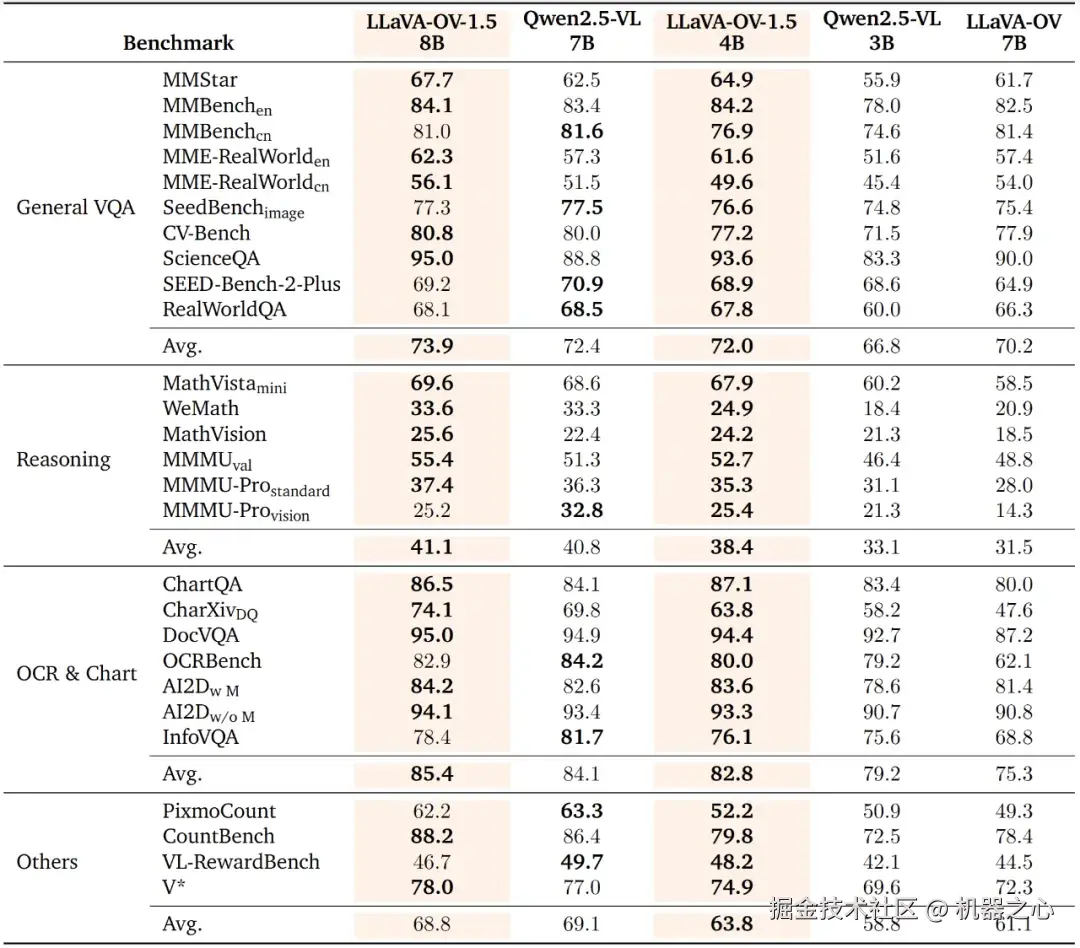
实验结果显示,LLaVA‑OneVision 在多项公开多模态基准上较 Qwen2.5‑VL 展现出竞争性乃至更优性能(详见技术报告)。

-
论文标题:LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
-
代码地址:
-
技术报告地址:
-
数据 / 模型地址:
-
Demo:
数据构建要点
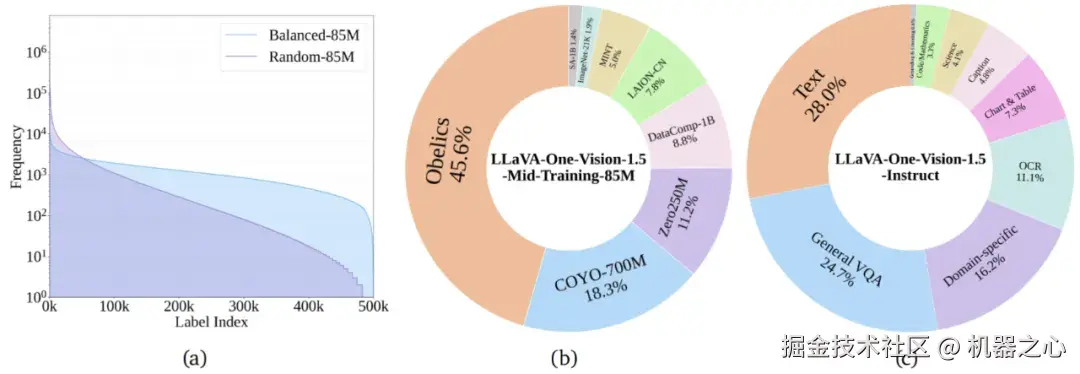
用于通用视觉语言的预训练集(85M)与指令微调数据集(22M)。其中 85M 预训练数据融合 COYO-700M、Obelics、DataComp-1B、LAION-CN、ImageNet-21K、SAM-1B、MINT、Zero250M 等 8 大异构来源,形成约 2,000 万中文与 6,500 万英文图文对。
为破解长尾概念稀疏与原始 caption 噪声 / 缺失问题,我们不再依赖原始文本词频,而是采用特征驱动的「概念均衡」策略:利用 MetaCLIP 编码器将全部图像与 50 万规模概念词嵌入共享向量空间,对每张图像检索 Top-K 最相似概念,统计概念频次后按逆频加权重采样,抑制高频背景类并提升罕见细粒度实体、属性与场景占比,显著平坦化长尾分布;随后使用高质量 Captioner 生成对齐的中英文增强描述。系统实验表明,在相同或更低 token 预算下,扩大高质量数据规模并结合概念均衡采样,可在多模态理解、长尾识别与指令泛化等核心指标上获得显著且可复现的性能提升。
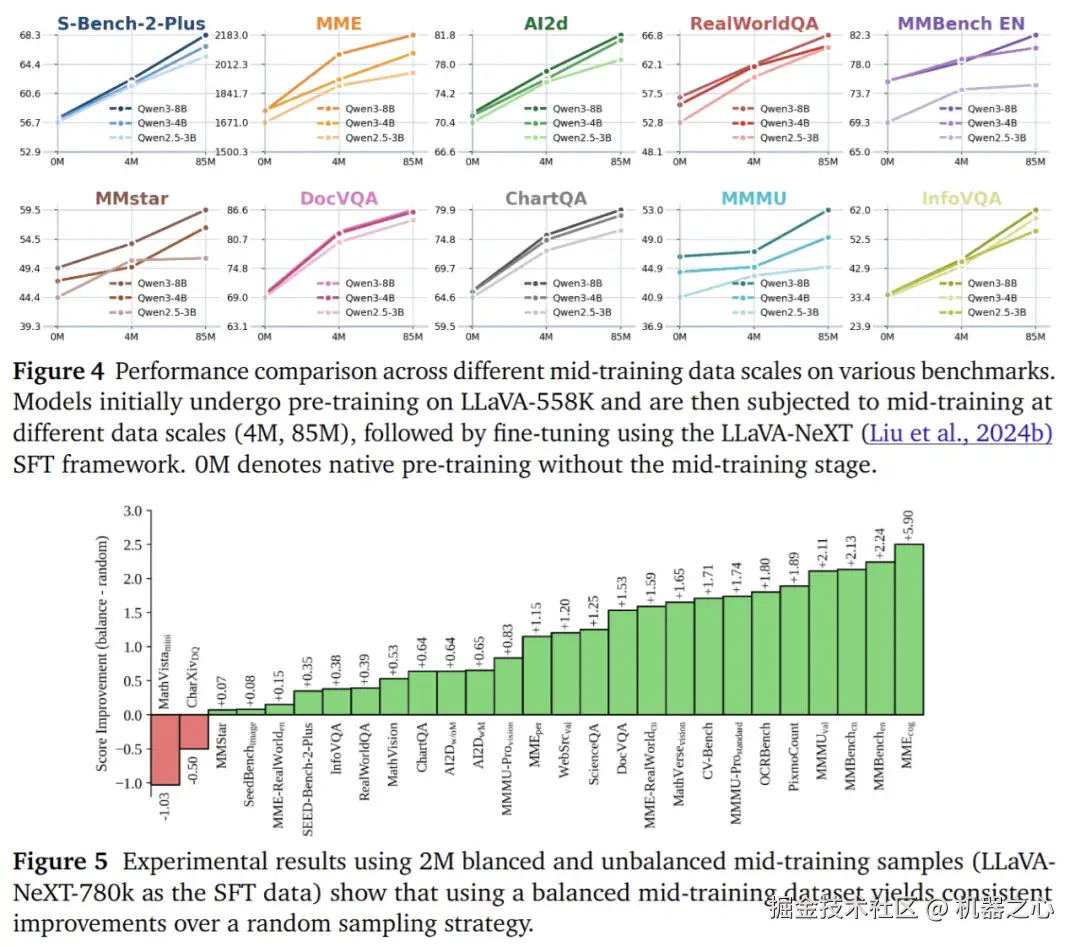
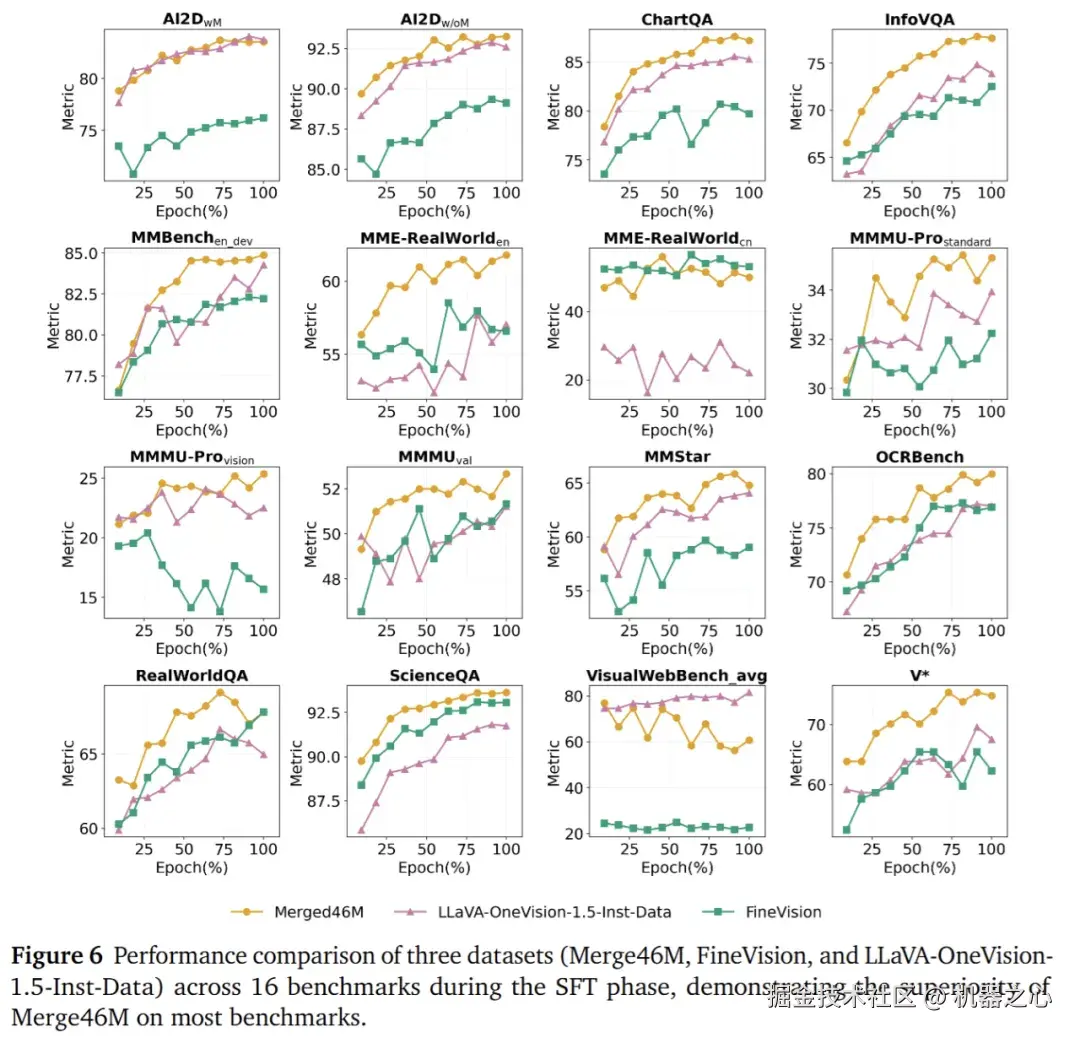
指令数据 22M 覆盖八大类别:Caption、Chart & Table、Code & Math、Domain-specific、General VQA、Grounding & Counting、OCR、Science。通过多源聚合、格式统一、指令重写、双语互转、模板去同质化与安全筛除,保持类别与难度分布均衡。并且我们的指令数据叠加 FineVision 数据集之后,结果会继续增加。
训练策略
- 视觉编码器预训练
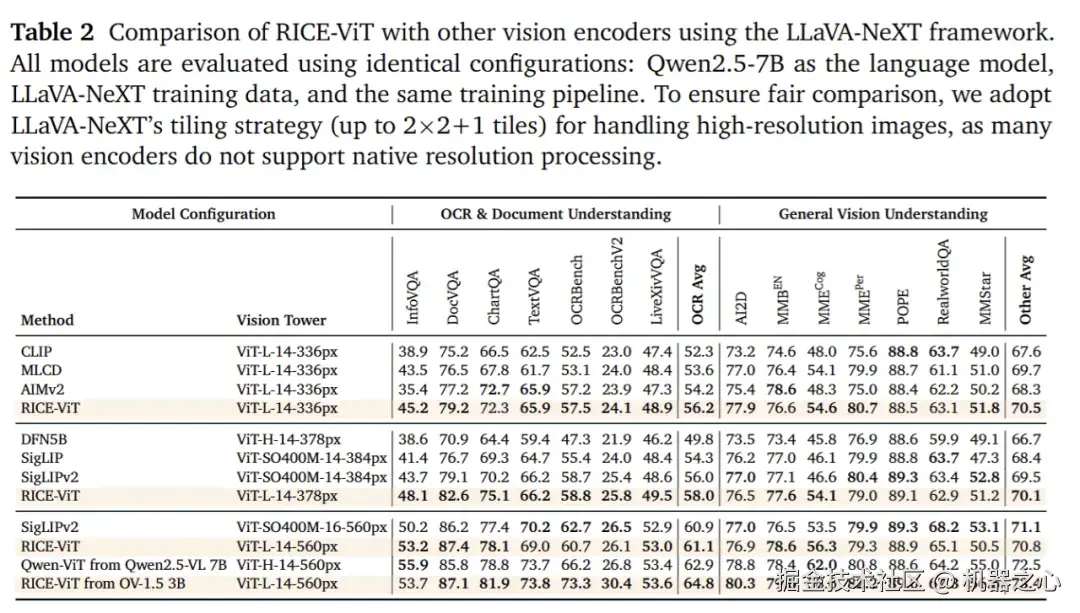
为了让模型在 OCR、表格 / 文档、区域理解与后续指令推理上具有更高的下限,我们在 LLaVA-OneVision-1.5 中采用自研的 MVT v1.5(RICE-ViT) 作为视觉主干。
相较仅做全局对齐的 CLIP / SigLIP 类对比模型,RICE-ViT 针对「实例只用单一全局向量」这一结构性瓶颈,引入统一的 Region Cluster Discrimination 机制:在 4.5 亿图像与 24 亿候选区域上训练,利用区域聚类判别 + 区域感知注意力显式建模局部实体 / 文本块与上下文关系,并结合 2D 旋转位置编码(2D RoPE)实现多分辨率原生支持。
与 SigLIP2 依赖多套专用损失(SILC、TIPS、LocCa 等)不同,我们用单一聚类判别范式同时强化通用语义、OCR 识别与定位能力,训练与推理链路更简洁、可维护性更高。在多模态融合阶段,通过轻量投影与后续全参数联合训练,将这一细粒度语义底座无缝接入语言模型,减少冗余适配模块并提升跨任务迁移效率。
- 三阶段学习流程
- Stage-1:语言--图像对齐
使用 LLaVA-1.5 558K 数据集训练视觉投影层,将视觉编码输出映射到语言模型词嵌入空间。此阶段控制参数更新范围以快速稳定收敛。
- Stage-1.5:高质量知识中期预训练
在概念均衡的 85M 预训练数据上进行全参数训练,注入广域视觉语义与世界知识,强调数据质量与覆盖而非盲目扩张 token 规模。
- Stage-2:视觉指令对齐
基于 22M 指令数据与 FineVision 等多源视觉指令语料继续全参数训练,提升任务泛化、推理组织与响应格式控制能力。
- 离线并行数据打包
为降低多模态样本长度差异带来的 padding 浪费、提升有效 token 利用率,我们采用离线并行数据打包:先按样本长度或长度区间进行哈希桶聚类,减少全局排序与扫描成本;再在数据准备阶段以多线程将多条短样本拼接为接近目标长度的定长序列。该流程一次性处理全量语料,具备确定性与可复现性,避免在线动态打包引入的运行时不稳定与额外 CPU 开销。
在 85M 规模的预训练样本上,相比原始方案可实现最高约 11× 的 padding 有效压缩(定义:原始方案总 padding token / 打包后总 padding token)。
- 混合并行与长上下文高效训练,训练端采用混合并行与长上下文优化
张量并行(TP)+ 流水并行(PP)+ 序列 / 上下文并行(Sequence/Context Parallel)与分布式优化器协同,以在大规模集群中同时提升算力利用与显存效率;同时采用原生分辨率策略,保留图表、文档与密集文本区域的结构细节,避免统一缩放带来的信息损失。
在 128×A800 集群上,8B 规模模型的 Stage‑1.5(85M 样本、原生分辨率)约 3.7 天完成,兼顾吞吐与成本。
结论
LLaVA-OneVision-1.5 证明:依托概念均衡的 85M 预训练数据与高质量指令数据,结合 RICE‑ViT 细粒度视觉底座和紧凑的三阶段策略(对齐--高质量知识注入--指令泛化),再配合离线并行打包(最高约 11× padding 减少)与混合并行 / 原生分辨率等工程优化,8B 规模即可在更低 token 与算力成本下,对标乃至部分超越主流开源与部分闭源多模态模型,体现「高质量结构化数据 + 系统效率协同」相较单纯堆量的优势。
这是一次非常简单的复现工作:我们完整开放数据、工具链、脚本、配置、日志与评测配方,复现路径清晰、依赖明确,无需复杂调参即可跑通。