设计模式-迭代器模式
迭代器模式(Iterator Design Pattern),也叫作游标模式(Cursor Design Pattern),用来给类实例提供一种遍历对象的方式。
案例分析
首先写一个经典的 User 类
java
@Data
@ToString
public class User {
private String uuid;
private String name;
private Integer age;
}通常我们遍历一个对象有三种方式
java
public class Main {
public static void main(String[] args) {
List<User> userList = IntStream.rangeClosed(1, 10).mapToObj(i -> {
User user = new User();
user.setUuid(i + "");
user.setAge(i);
user.setName("name" + i);
return user;
}).collect(Collectors.toList());
for (int i = 0; i < userList.size(); i++) {
User temp = userList.get(i);
System.out.println(temp);
}
for (User temp : userList) {
System.out.println(temp);
}
Iterator<User> iterator = userList.iterator();
while (iterator.hasNext()) {
User temp = iterator.next();
System.out.println(temp);
}
}
}不过如果分析上述这段代码编译出的字节码文件,其实方法二和方法三最终的实现是一样的
java
for (User temp : userList) {
System.out.println(temp);
}
Iterator<User> iterator = userList.iterator();
while (iterator.hasNext()) {
User temp = iterator.next();
System.out.println(temp);
}实现一个迭代器其实并不复杂,我们可能会好奇一个问题,为什么 userList 可以放在增强 for 循环的位置
java
for (User temp : userList) {
System.out.println(temp);
}而 User 对象本身不能放在增强 for 循环的位置
java
for (String temp : User) {
System.out.println(temp);
}结合标题迭代器模式我们很容易想到这个因为 userList 对应的 ArrayList 类实现了迭代器接口
java
public interface Iterable<T> {
/**
* Returns an iterator over elements of type {@code T}.
*
* @return an Iterator.
*/
Iterator<T> iterator();
} 所以如果想让 User 类也可以放到增强 for 循环的位置,也需要实现这个接口
java
public class User implements Iterable<String>{
private String uuid;
private String name;
private Integer age;
@Override
public Iterator<String> iterator() {
return new UserIte();
}
private class UserIte implements Iterator<String> {
@Override
public boolean hasNext() {
return false;
}
@Override
public String next() {
return null;
}
}
}所以实现一个迭代器类只需要两步:
- 类实现 Iterable,代表是可迭代的
- 在类中创建一个内部类实现迭代器接口,实现其中的是否还有下一个元素接口和获取下一个元素接口
由于我们需要记录是否遍历完成,所以 UserIte 中需要使用属性记录当前遍历到的位置
java
@Data
@ToString
public class User implements Iterable<String> {
private String uuid;
private String name;
private Integer age;
@Override
public Iterator<String> iterator() {
return new UserIte();
}
private class UserIte implements Iterator<String> {
private Integer index;
private List<String> propertyList = new ArrayList<>();
public UserIte() {
index = 0;
propertyList.add(User.this.uuid);
propertyList.add(User.this.name);
propertyList.add(User.this.age + "");
}
@Override
public boolean hasNext() {
return index < propertyList.size();
}
@Override
public String next() {
if (index >= propertyList.size()) {
throw new NoSuchElementException("没有" + index + "对应的元素");
}
return propertyList.get(index++);
}
}
}这样就可以对 User 的对象进行遍历了
java
public class Main {
public static void main(String[] args) {
List<User> userList = IntStream.rangeClosed(1, 10).mapToObj(i -> {
User user = new User();
user.setUuid(i + "");
user.setAge(i);
user.setName("name" + i);
return user;
}).collect(Collectors.toList());
User temp = userList.get(0);
for (String s : temp) {
System.out.println(s);
}
}
}实现一个迭代器并不是很复杂,但是如果你仔细看上面的实现就会有疑问,如果在遍历的过程中对元素进行了变化,那么迭代过程中会出现什么问题呢?
这里不再演示之间说结论,有可能出错也有可能不出错,迭代器中有一个 cursor 的概念,Mysql 中其实也有这个游标的概念。
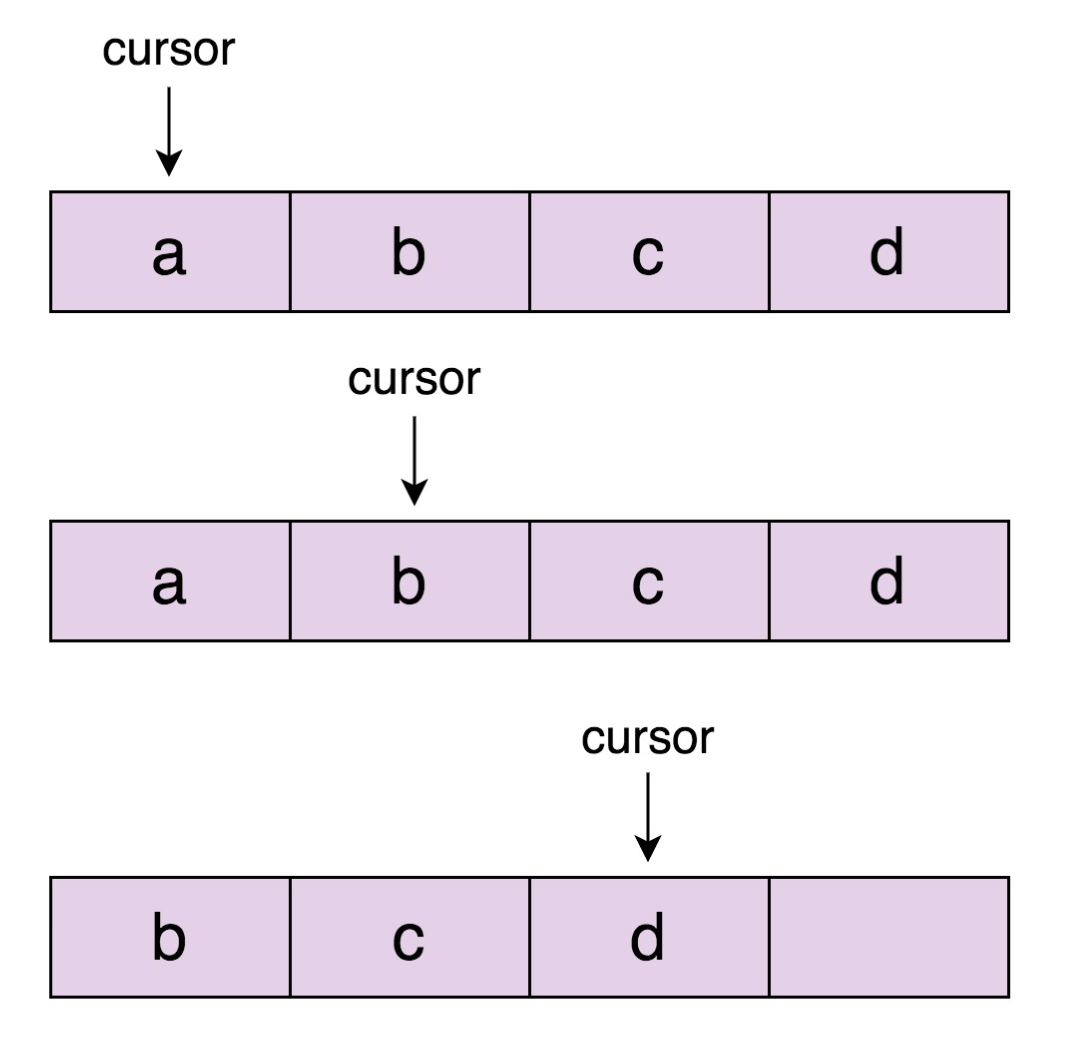
如上图所示:当游标指向 b 的时候,删除了数组中的 a 元素,由于数组会进行补齐,所以 cursor 会指向 d,元素 c 就会错过遍历。如果指向最后一个元素的时候被删了,那么可能会出现空指针。事实上,在计算机中,不可预知的结果(出错或不出错)比出错更让人头疼,因此最好的处理方式就是只要出现了预期之外的操作就报错,让开发人员尽快处理这样的操作。
如果你查看 ArrayList 的实现,会发现其在每次进行 add 或 remove 操作的时候,会对其中的 modCount 进行 +1,记录出现的更新次数,并在创建迭代器时将该次数传入,并在每次进行遍历时先判断迭代器中修改次数的和实例的修改次数是否相同,如果不同就抛出异常。
总结
所以,实现一个迭代器模式并不复杂,但是迭代器存在的意义是什么呢?为什么不都用 for i 类型的遍历呢?
对于复杂的数据结构(比如树、图)来说,有各种复杂的遍历方式。比如,树有前中后序、按层遍历,图有深度优先、广度优先遍历等等。如果由客户端代码来实现这些遍历算法,势必增加开发成本,而且容易写错。如果将这部分遍历的逻辑写到容器类中,也会导致容器类代码的复杂性。
前面也多次提到,应对复杂性的方法就是拆分。我们可以将遍历操作拆分到迭代器类中。比如,针对图的遍历,我们就可以定义 DFSIterator、BFSIterator 两个迭代器类,让它们分别来实现深度优先遍历和广度优先遍历。
其次,将游标指向的当前位置等信息,存储在迭代器类中,每个迭代器独享游标信息。这样,我们就可以创建多个不同的迭代器,同时对同一个容器进行遍历而互不影响。而且迭代器之间都实现了迭代器接口,可以利用多态特性很方便的互相替换,例如从前遍历转为从后遍历,体现了面向接口编程的思想。