06 租约:如何检测你的客户端存活?
今天我要跟你分享的主题是租约(Lease)。etcd的一个典型的应用场景是Leader选举,那么etcd为什么可以用来实现Leader选举?核心特性实现原理又是怎样的?
今天我就和你聊聊Leader选举背后技术点之一的Lease, 解析它的核心原理、性能优化思路,希望通过本节让你对Lease如何关联key、Lease如何高效续期、淘汰、什么是checkpoint机制有深入的理解。同时希望你能基于Lease的TTL特性,解决实际业务中遇到分布式锁、节点故障自动剔除等各类问题,提高业务服务的可用性。
什么是Lease
在实际业务场景中,我们常常会遇到类似Kubernetes的调度器、控制器组件同一时刻只能存在一个副本对外提供服务的情况。然而单副本部署的组件,是无法保证其高可用性的。
那为了解决单副本的可用性问题,我们就需要多副本部署。同时,为了保证同一时刻只有一个能对外提供服务,我们需要引入Leader选举机制。那么Leader选举本质是要解决什么问题呢?
首先当然是要保证Leader的唯一性,确保集群不出现多个Leader,才能保证业务逻辑准确性,也就是安全性(Safety)、互斥性。
其次是主节点故障后,备节点应可快速感知到其异常,也就是活性(liveness)检测。实现活性检测主要有两种方案。
方案一为被动型检测,你可以通过探测节点定时拨测Leader节点,看是否健康,比如Redis Sentinel。
方案二为主动型上报,Leader节点可定期向协调服务发送"特殊心跳"汇报健康状态,若其未正常发送心跳,并超过和协调服务约定的最大存活时间后,就会被协调服务移除Leader身份标识。同时其他节点可通过协调服务,快速感知到Leader故障了,进而发起新的选举。
我们今天的主题,Lease,正是基于主动型上报模式,提供的一种活性检测机制。Lease顾名思义,client和etcd server之间存在一个约定,内容是etcd server保证在约定的有效期内(TTL),不会删除你关联到此Lease上的key-value。
若你未在有效期内续租,那么etcd server就会删除Lease和其关联的key-value。
你可以基于Lease的TTL特性,解决类似Leader选举、Kubernetes Event自动淘汰、服务发现场景中故障节点自动剔除等问题。为了帮助你理解Lease的核心特性原理,我以一个实际场景中的经常遇到的异常节点自动剔除为案例,围绕这个问题,给你深入介绍Lease特性的实现。
在这个案例中,我们期望的效果是,在节点异常时,表示节点健康的key能被从etcd集群中自动删除。
Lease整体架构
在和你详细解读Lease特性如何解决上面的问题之前,我们先了解下Lease模块的整体架构,下图是我给你画的Lease模块简要架构图。
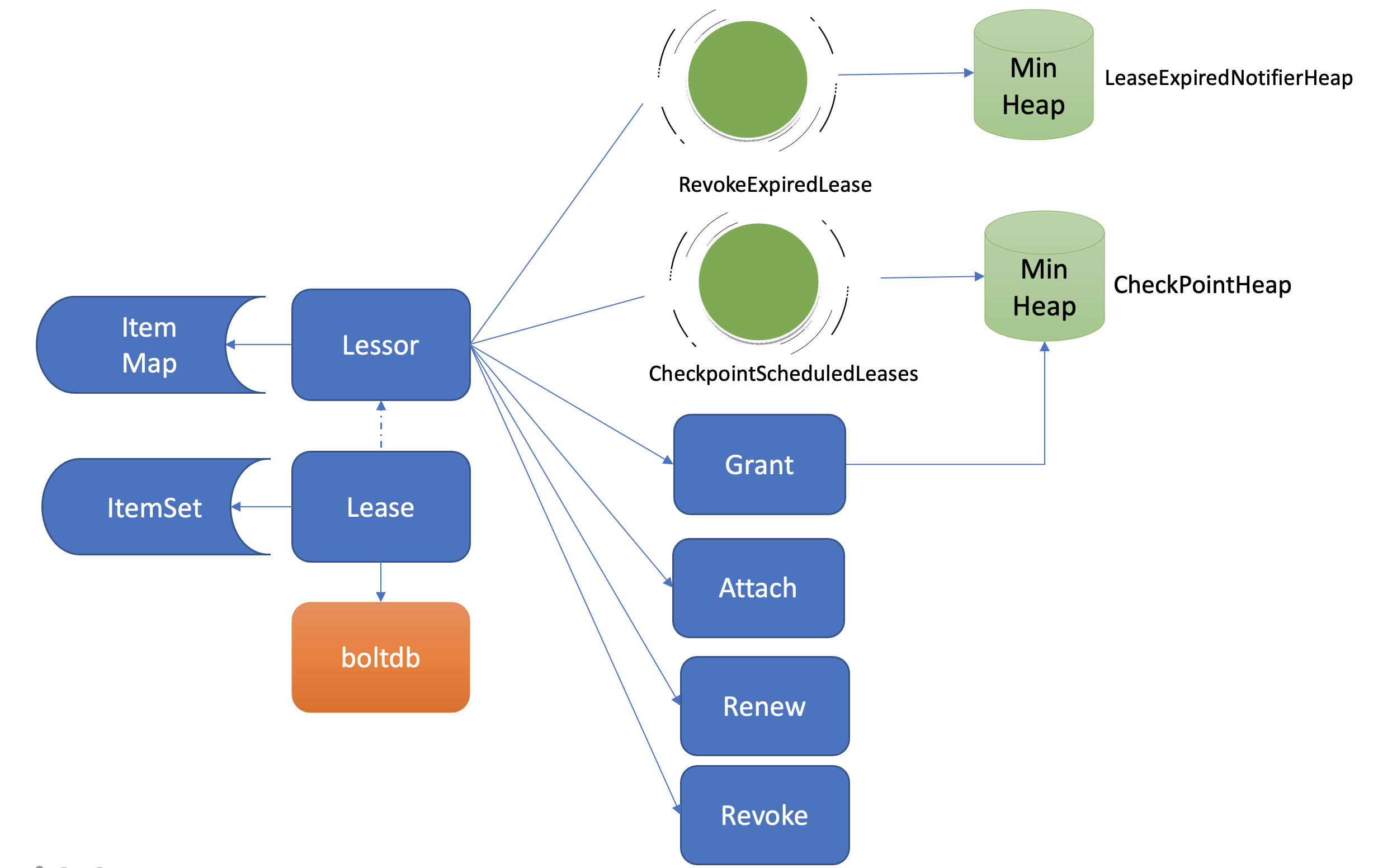
etcd在启动的时候,创建Lessor模块的时候,它会启动两个常驻goroutine,如上图所示,一个是RevokeExpiredLease任务,定时检查是否有过期Lease,发起撤销过期的Lease操作。一个是CheckpointScheduledLease,定时触发更新Lease的剩余到期时间的操作。
Lessor模块提供了Grant、Revoke、LeaseTimeToLive、LeaseKeepAlive API给client使用,各接口作用如下:
- Grant表示创建一个TTL为你指定秒数的Lease,Lessor会将Lease信息持久化存储在boltdb中;
- Revoke表示撤销Lease并删除其关联的数据;
- LeaseTimeToLive表示获取一个Lease的有效期、剩余时间;
- LeaseKeepAlive表示为Lease续期。
key如何关联Lease
了解完整体架构后,我们再看如何基于Lease特性实现检测一个节点存活。
首先如何为节点健康指标创建一个租约、并与节点健康指标key关联呢?
如KV模块的一样,client可通过clientv3库的Lease API发起RPC调用,你可以使用如下的etcdctl命令为node的健康状态指标,创建一个Lease,有效期为600秒。然后通过timetolive命令,查看Lease的有效期、剩余时间。
bash
# 创建一个TTL为600秒的lease,etcd server返回LeaseID
$ etcdctl lease grant 600
lease 326975935f48f814 granted with TTL(600s)
# 查看lease的TTL、剩余时间
$ etcdctl lease timetolive 326975935f48f814
lease 326975935f48f814 granted with TTL(600s), remaining(590s)当Lease server收到client的创建一个有效期600秒的Lease请求后,会通过Raft模块完成日志同步,随后Apply模块通过Lessor模块的Grant接口执行日志条目内容。
首先Lessor的Grant接口会把Lease保存到内存的ItemMap数据结构中,然后它需要持久化Lease,将Lease数据保存到boltdb的Lease bucket中,返回一个唯一的LeaseID给client。
通过这样一个流程,就基本完成了Lease的创建。那么节点的健康指标数据如何关联到此Lease上呢?
很简单,KV模块的API接口提供了一个"--lease"参数,你可以通过如下命令,将key node关联到对应的LeaseID上。然后你查询的时候增加-w参数输出格式为json,就可查看到key关联的LeaseID。
bash
$ etcdctl put node healthy --lease 326975935f48f818
OK
$ etcdctl get node -w=json | python -m json.tool
{
"kvs":[
{
"create_revision":24,
"key":"bm9kZQ==",
"Lease":3632563850270275608,
"mod_revision":24,
"value":"aGVhbHRoeQ==",
"version":1
}
]
}以上流程原理如下图所示,它描述了用户的key是如何与指定Lease关联的。当你通过put等命令新增一个指定了"--lease"的key时,MVCC模块它会通过Lessor模块的Attach方法,将key关联到Lease的key内存集合ItemSet中。
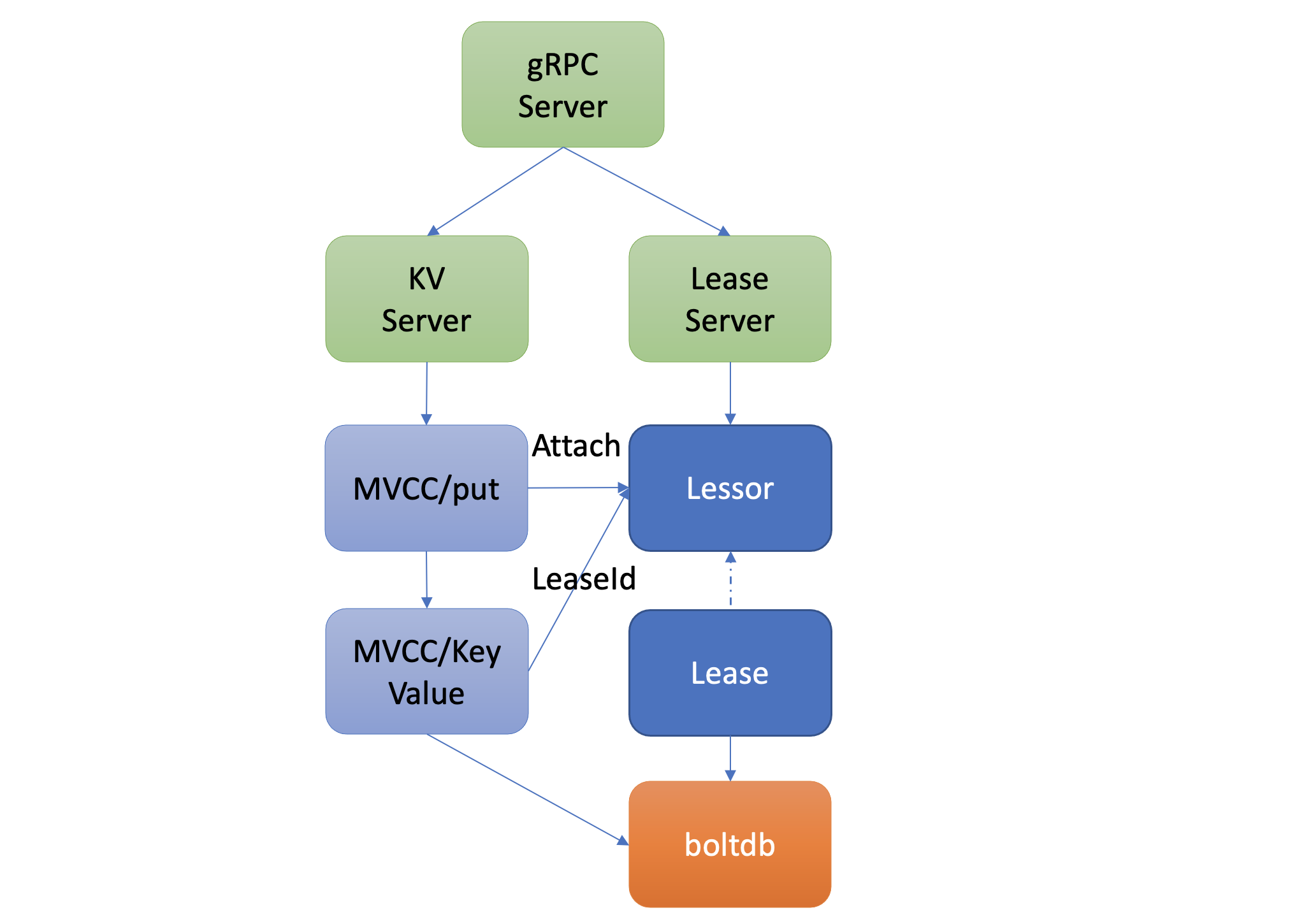
一个Lease关联的key集合是保存在内存中的,那么etcd重启时,是如何知道每个Lease上关联了哪些key呢?
答案是etcd的MVCC模块在持久化存储key-value的时候,保存到boltdb的value是个结构体(mvccpb.KeyValue), 它不仅包含你的key-value数据,还包含了关联的LeaseID等信息。因此当etcd重启时,可根据此信息,重建关联各个Lease的key集合列表。
如何优化Lease续期性能
通过以上流程,我们完成了Lease创建和数据关联操作。在正常情况下,你的节点存活时,需要定期发送KeepAlive请求给etcd续期健康状态的Lease,否则你的Lease和关联的数据就会被删除。
那么Lease是如何续期的? 作为一个高频率的请求API,etcd如何优化Lease续期的性能呢?
Lease续期其实很简单,核心是将Lease的过期时间更新为当前系统时间加其TTL。关键问题在于续期的性能能否满足业务诉求。
然而影响续期性能因素又是源自多方面的。首先是TTL,TTL过长会导致节点异常后,无法及时从etcd中删除,影响服务可用性,而过短,则要求client频繁发送续期请求。其次是Lease数,如果Lease成千上万个,那么etcd可能无法支撑如此大规模的Lease数,导致高负载。
如何解决呢?
首先我们回顾下早期etcd v2版本是如何实现TTL特性的。在早期v2版本中,没有Lease概念,TTL属性是在key上面,为了保证key不删除,即便你的TTL相同,client也需要为每个TTL、key创建一个HTTP/1.x 连接,定时发送续期请求给etcd server。
很显然,v2老版本这种设计,因不支持连接多路复用、相同TTL无法复用导致性能较差,无法支撑较大规模的Lease场景。
etcd v3版本为了解决以上问题,提出了Lease特性,TTL属性转移到了Lease上, 同时协议从HTTP/1.x优化成gRPC协议。
一方面不同key若TTL相同,可复用同一个Lease, 显著减少了Lease数。另一方面,通过gRPC HTTP/2实现了多路复用,流式传输,同一连接可支持为多个Lease续期,大大减少了连接数。
通过以上两个优化,实现Lease性能大幅提升,满足了各个业务场景诉求。
如何高效淘汰过期Lease
在了解完节点正常情况下的Lease续期特性后,我们再看看节点异常时,未正常续期后,etcd又是如何淘汰过期Lease、删除节点健康指标key的。
淘汰过期Lease的工作由Lessor模块的一个异步goroutine负责。如下面架构图虚线框所示,它会定时从最小堆中取出已过期的Lease,执行删除Lease和其关联的key列表数据的RevokeExpiredLease任务。
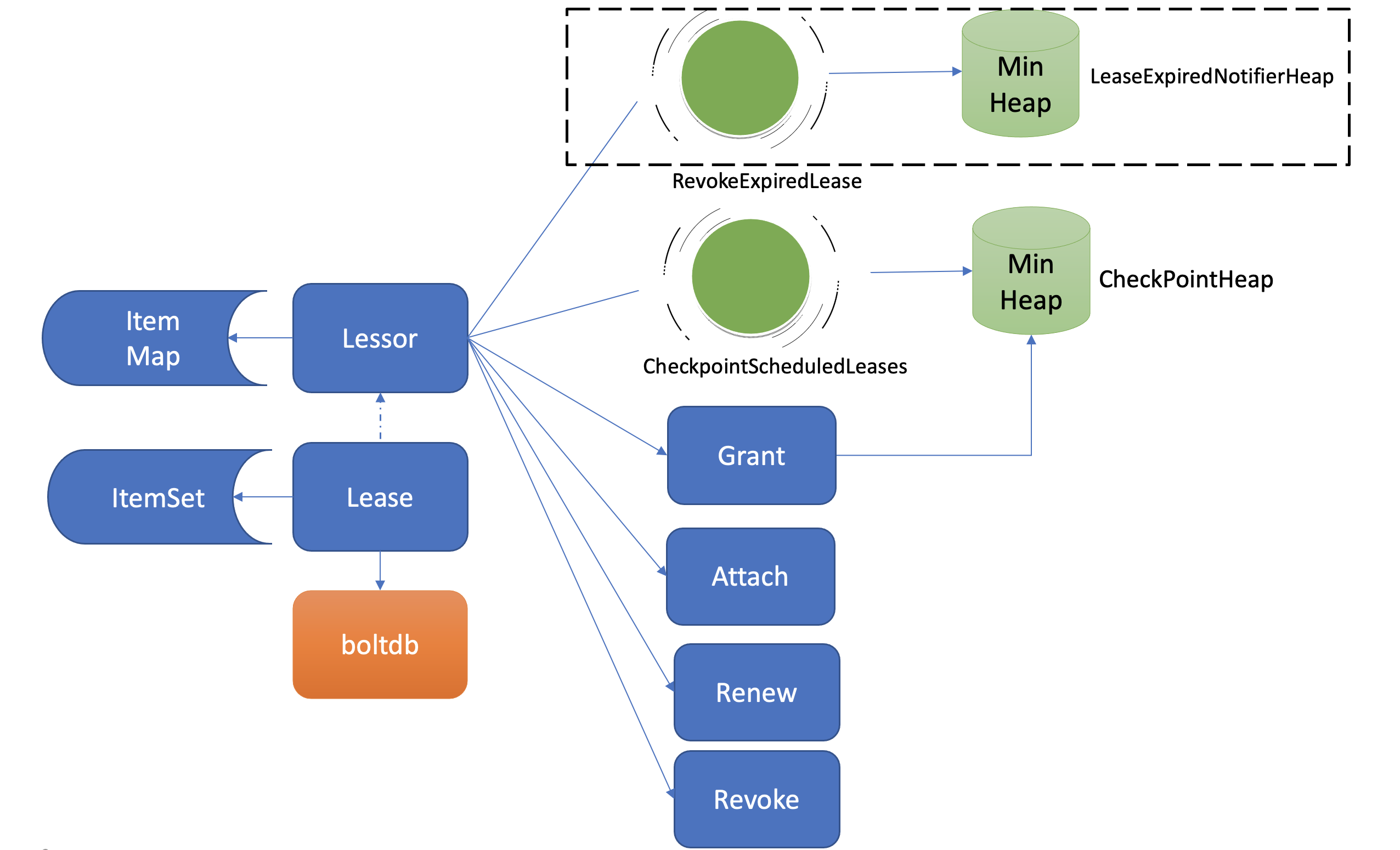
从图中你可以看到,目前etcd是基于最小堆来管理Lease,实现快速淘汰过期的Lease。
etcd早期的时候,淘汰Lease非常暴力。etcd会直接遍历所有Lease,逐个检查Lease是否过期,过期则从Lease关联的key集合中,取出key列表,删除它们,时间复杂度是O(N)。
然而这种方案随着Lease数增大,毫无疑问它的性能会变得越来越差。我们能否按过期时间排序呢?这样每次只需轮询、检查排在前面的Lease过期时间,一旦轮询到未过期的Lease, 则可结束本轮检查。
刚刚说的就是etcd Lease高效淘汰方案最小堆的实现方法。每次新增Lease、续期的时候,它会插入、更新一个对象到最小堆中,对象含有LeaseID和其到期时间unixnano,对象之间按到期时间升序排序。
etcd Lessor主循环每隔500ms执行一次撤销Lease检查(RevokeExpiredLease),每次轮询堆顶的元素,若已过期则加入到待淘汰列表,直到堆顶的Lease过期时间大于当前,则结束本轮轮询。
相比早期O(N)的遍历时间复杂度,使用堆后,插入、更新、删除,它的时间复杂度是O(Log N),查询堆顶对象是否过期时间复杂度仅为O(1),性能大大提升,可支撑大规模场景下Lease的高效淘汰。
获取到待过期的LeaseID后,Leader是如何通知其他Follower节点淘汰它们呢?
Lessor模块会将已确认过期的LeaseID,保存在一个名为expiredC的channel中,而etcd server的主循环会定期从channel中获取LeaseID,发起revoke请求,通过Raft Log传递给Follower节点。
各个节点收到revoke Lease请求后,获取关联到此Lease上的key列表,从boltdb中删除key,从Lessor的Lease map内存中删除此Lease对象,最后还需要从boltdb的Lease bucket中删除这个Lease。
以上就是Lease的过期自动淘汰逻辑。Leader节点按过期时间维护了一个最小堆,若你的节点异常未正常续期,那么随着时间消逝,对应的Lease则会过期,Lessor主循环定时轮询过期的Lease。获取到ID后,Leader发起revoke操作,通知整个集群删除Lease和关联的数据。
为什么需要checkpoint机制
了解完Lease的创建、续期、自动淘汰机制后,你可能已经发现,检查Lease是否过期、维护最小堆、针对过期的Lease发起revoke操作,都是Leader节点负责的,它类似于Lease的仲裁者,通过以上清晰的权责划分,降低了Lease特性的实现复杂度。
那么当Leader因重启、crash、磁盘IO等异常不可用时,Follower节点就会发起Leader选举,新Leader要完成以上职责,必须重建Lease过期最小堆等管理数据结构,那么以上重建可能会触发什么问题呢?
当你的集群发生Leader切换后,新的Leader基于Lease map信息,按Lease过期时间构建一个最小堆时,etcd早期版本为了优化性能,并未持久化存储Lease剩余TTL信息,因此重建的时候就会自动给所有Lease自动续期了。
然而若较频繁出现Leader切换,切换时间小于Lease的TTL,这会导致Lease永远无法删除,大量key堆积,db大小超过配额等异常。
为了解决这个问题,etcd引入了检查点机制,也就是下面架构图中黑色虚线框所示的CheckPointScheduledLeases的任务。
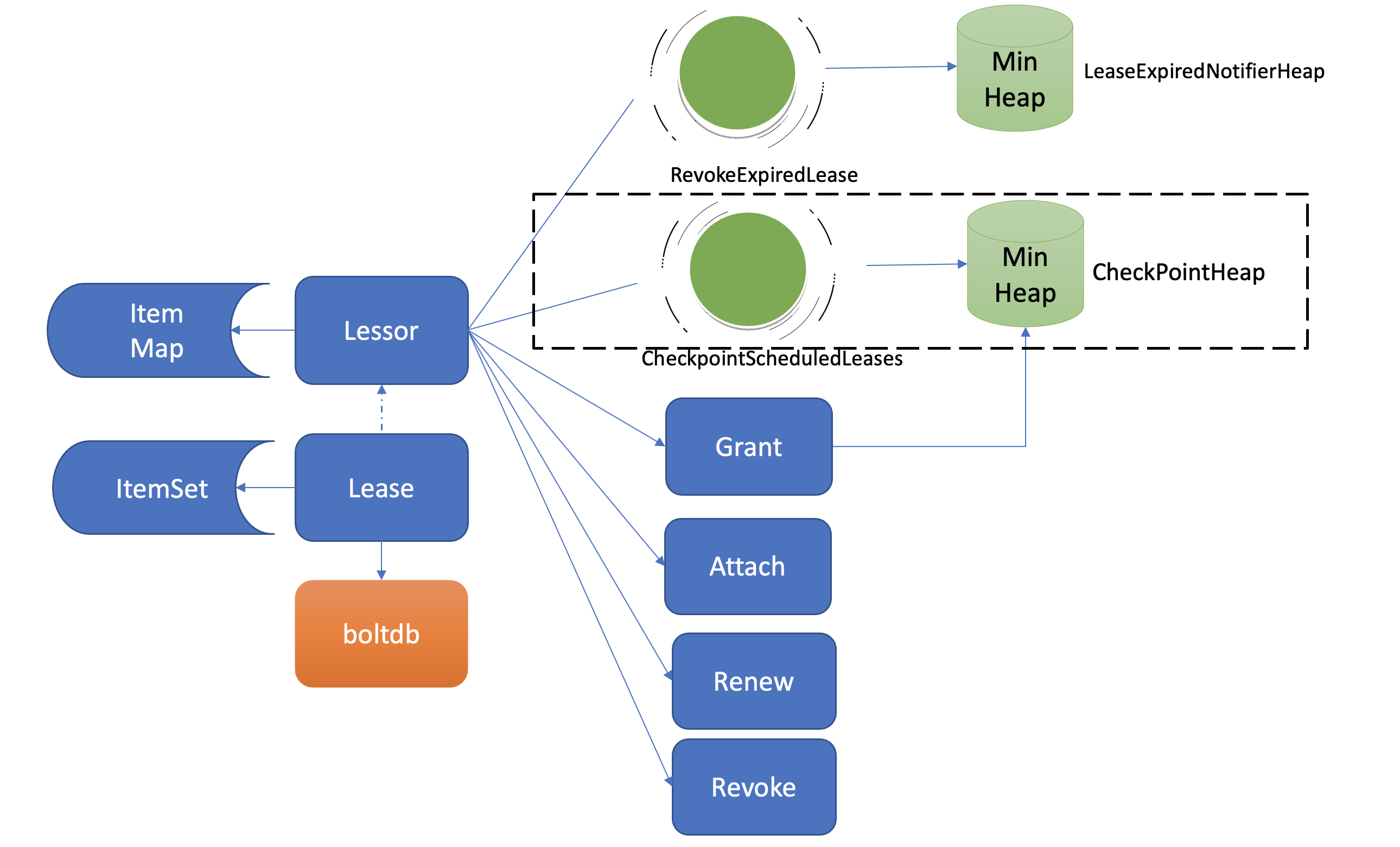
一方面,etcd启动的时候,Leader节点后台会运行此异步任务,定期批量地将Lease剩余的TTL基于Raft Log同步给Follower节点,Follower节点收到CheckPoint请求后,更新内存数据结构LeaseMap的剩余TTL信息。
另一方面,当Leader节点收到KeepAlive请求的时候,它也会通过checkpoint机制把此Lease的剩余TTL重置,并同步给Follower节点,尽量确保续期后集群各个节点的Lease 剩余TTL一致性。
最后你要注意的是,此特性对性能有一定影响,目前仍然是试验特性。你可以通过experimental-enable-lease-checkpoint参数开启。
小结
最后我们来小结下今天的内容,我通过一个实际案例为你解读了Lease创建、关联key、续期、淘汰、checkpoint机制。
Lease的核心是TTL,当Lease的TTL过期时,它会自动删除其关联的key-value数据。
首先是Lease创建及续期。当你创建Lease时,etcd会保存Lease信息到boltdb的Lease bucket中。为了防止Lease被淘汰,你需要定期发送LeaseKeepAlive请求给etcd server续期Lease,本质是更新Lease的到期时间。
续期的核心挑战是性能,etcd经历了从TTL属性在key上,到独立抽象出Lease,支持多key复用相同TTL,同时协议从HTTP/1.x优化成gRPC协议,支持多路连接复用,显著降低了server连接数等资源开销。
其次是Lease的淘汰机制,etcd的Lease淘汰算法经历了从时间复杂度O(N)到O(Log N)的演进,核心是轮询最小堆的Lease是否过期,若过期生成revoke请求,它会清理Lease和其关联的数据。
最后我给你介绍了Lease的checkpoint机制,它是为了解决Leader异常情况下TTL自动被续期,可能导致Lease永不淘汰的问题而诞生。
思考题
好了,这节课到这里也就结束了,我最后给你留了一个思考题。你知道etcd lease最小的TTL时间是多少吗?它跟什么因素有关呢?
07 MVCC:如何实现多版本并发控制?
在01课里,我和你介绍etcd v2时,提到过它存在的若干局限,如仅保留最新版本key-value数据、丢弃历史版本。而etcd核心特性watch又依赖历史版本,因此etcd v2为了缓解这个问题,会在内存中维护一个较短的全局事件滑动窗口,保留最近的1000条变更事件。但是在集群写请求较多等场景下,它依然无法提供可靠的Watch机制。
那么不可靠的etcd v2事件机制,在etcd v3中是如何解决的呢?
我今天要和你分享的MVCC(Multiversion concurrency control)机制,正是为解决这个问题而诞生的。
MVCC机制的核心思想是保存一个key-value数据的多个历史版本,etcd基于它不仅实现了可靠的Watch机制,避免了client频繁发起List Pod等expensive request操作,保障etcd集群稳定性。而且MVCC还能以较低的并发控制开销,实现各类隔离级别的事务,保障事务的安全性,是事务特性的基础。
希望通过本节课,帮助你搞懂MVCC含义和MVCC机制下key-value数据的更新、查询、删除原理,了解treeIndex索引模块、boltdb模块是如何相互协作,实现保存一个key-value数据多个历史版本。
什么是MVCC
首先和你聊聊什么是MVCC,从名字上理解,它是一个基于多版本技术实现的一种并发控制机制。那常见的并发机制有哪些?MVCC的优点在哪里呢?
提到并发控制机制你可能就没那么陌生了,比如数据库中的悲观锁,也就是通过锁机制确保同一时刻只能有一个事务对数据进行修改操作,常见的实现方案有读写锁、互斥锁、两阶段锁等。
悲观锁是一种事先预防机制,它悲观地认为多个并发事务可能会发生冲突,因此它要求事务必须先获得锁,才能进行修改数据操作。但是悲观锁粒度过大、高并发场景下大量事务会阻塞等,会导致服务性能较差。
MVCC机制正是基于多版本技术实现的一种乐观锁机制,它乐观地认为数据不会发生冲突,但是当事务提交时,具备检测数据是否冲突的能力。
在MVCC数据库中,你更新一个key-value数据的时候,它并不会直接覆盖原数据,而是新增一个版本来存储新的数据,每个数据都有一个版本号。版本号它是一个逻辑时间,为了方便你深入理解版本号意义,在下面我给你画了一个etcd MVCC版本号时间序列图。
从图中你可以看到,随着时间增长,你每次修改操作,版本号都会递增。每修改一次,生成一条新的数据记录。当你指定版本号读取数据时,它实际上访问的是版本号生成那个时间点的快照数据。当你删除数据的时候,它实际也是新增一条带删除标识的数据记录。
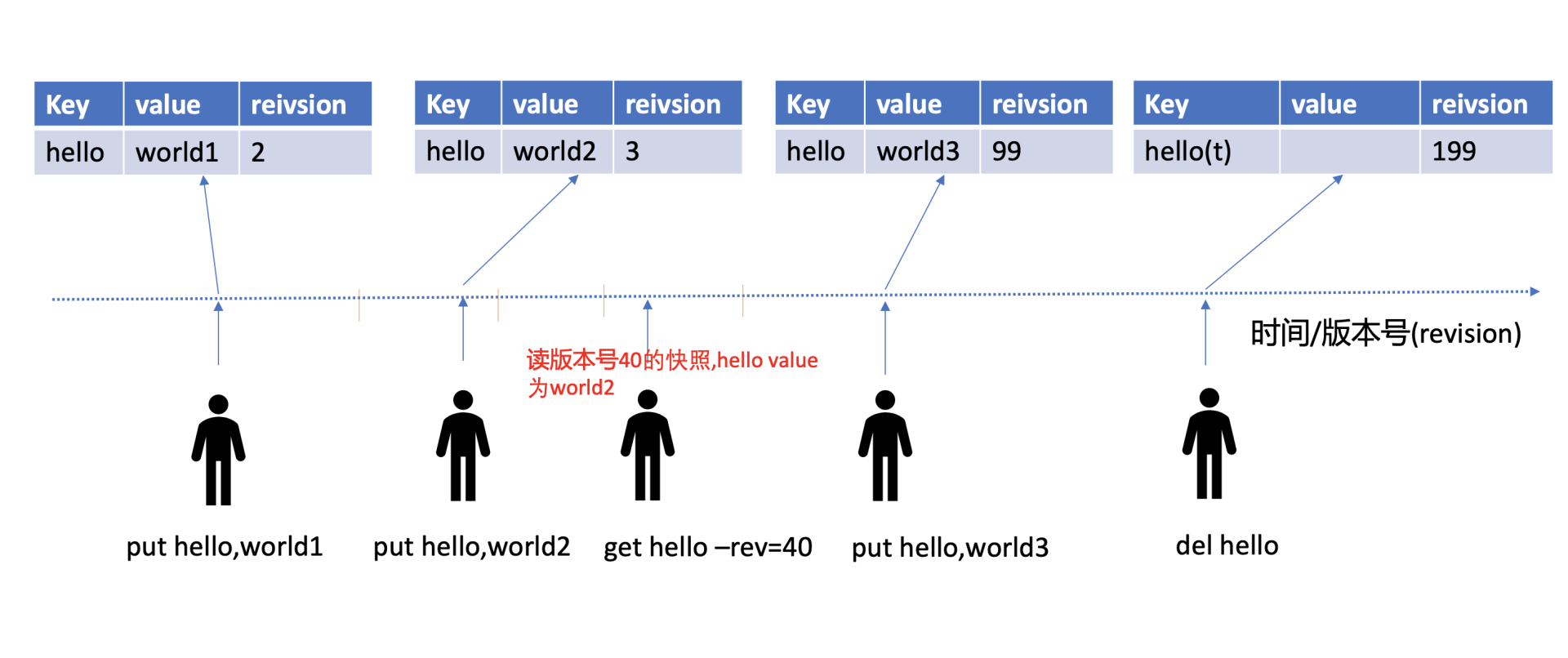
MVCC特性初体验
了解完什么是MVCC后,我先通过几个简单命令,带你初体验下MVCC特性,看看它是如何帮助你查询历史修改记录,以及找回不小心删除的key的。
启动一个空集群,更新两次key hello后,如何获取key hello的上一个版本值呢? 删除key hello后,还能读到历史版本吗?
如下面的命令所示,第一次key hello更新完后,我们通过get命令获取下它的key-value详细信息。正如你所看到的,除了key、value信息,还有各类版本号,我后面会详细和你介绍它们的含义。这里我们重点关注mod_revision,它表示key最后一次修改时的etcd版本号。
当我们再次更新key hello为world2后,然后通过查询时指定key第一次更新后的版本号,你会发现我们查询到了第一次更新的值,甚至我们执行删除key hello后,依然可以获得到这个值。那么etcd是如何实现的呢?
bash
# 更新key hello为world1
$ etcdctl put hello world1
OK
# 通过指定输出模式为json,查看key hello更新后的详细信息
$ etcdctl get hello -w=json
{
"kvs":[
{
"key":"aGVsbG8=",
"create_revision":2,
"mod_revision":2,
"version":1,
"value":"d29ybGQx"
}
],
"count":1
}
# 再次修改key hello为world2
$ etcdctl put hello world2
OK
# 确认修改成功,最新值为wolrd2
$ etcdctl get hello
hello
world2
# 指定查询版本号,获得了hello上一次修改的值
$ etcdctl get hello --rev=2
hello
world1
# 删除key hello
$ etcdctl del hello
1
# 删除后指定查询版本号3,获得了hello删除前的值
$ etcdctl get hello --rev=3
hello
world2整体架构
在详细和你介绍etcd如何实现MVCC特性前,我先和你从整体上介绍下MVCC模块。下图是MVCC模块的一个整体架构图,整个MVCC特性由treeIndex、Backend/boltdb组成。
当你执行MVCC特性初体验中的put命令后,请求经过gRPC KV Server、Raft模块流转,对应的日志条目被提交后,Apply模块开始执行此日志内容。
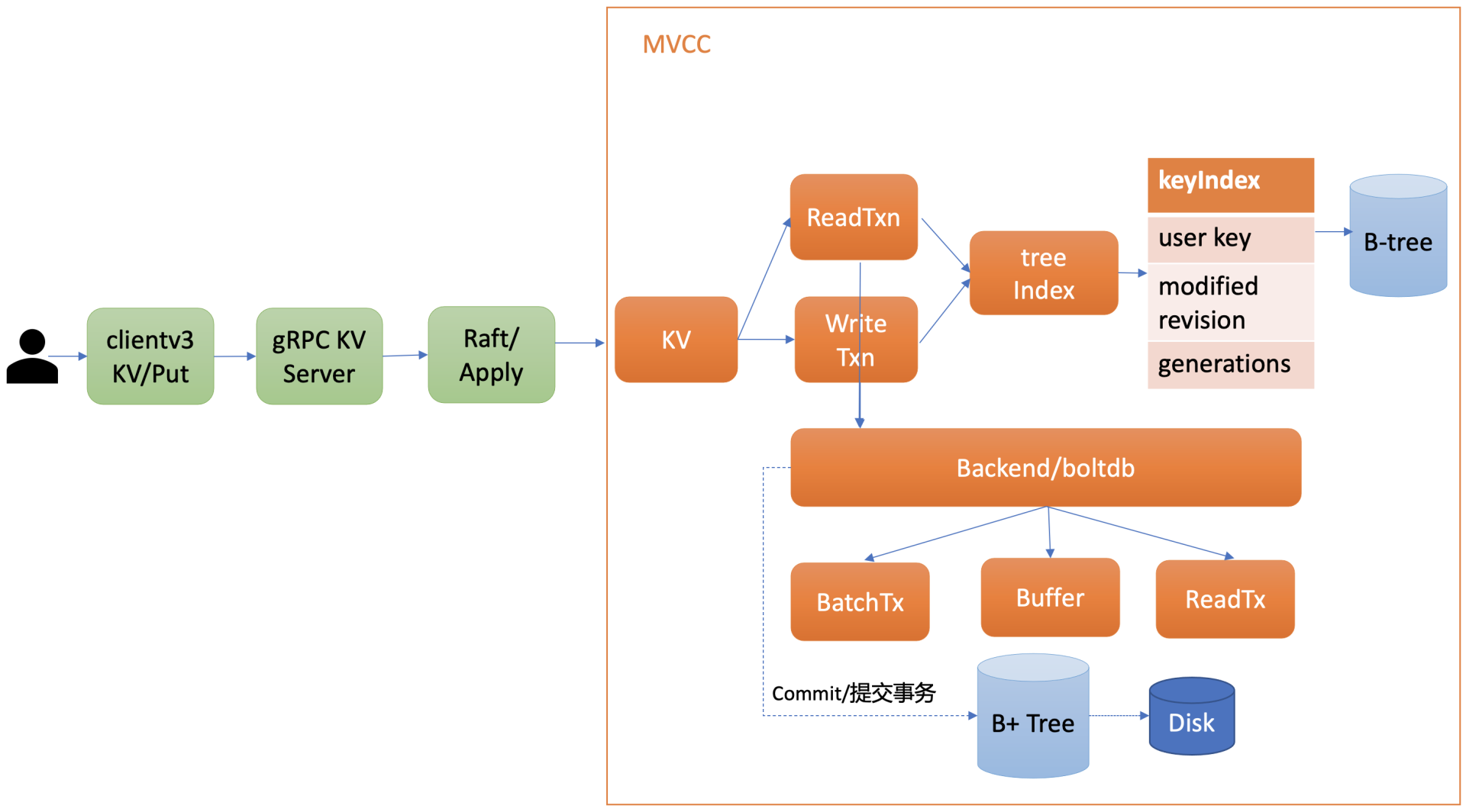
Apply模块通过MVCC模块来执行put请求,持久化key-value数据。MVCC模块将请求请划分成两个类别,分别是读事务(ReadTxn)和写事务(WriteTxn)。读事务负责处理range请求,写事务负责put/delete操作。读写事务基于treeIndex、Backend/boltdb提供的能力,实现对key-value的增删改查功能。
treeIndex模块基于内存版B-tree实现了key索引管理,它保存了用户key与版本号(revision)的映射关系等信息。
Backend模块负责etcd的key-value持久化存储,主要由ReadTx、BatchTx、Buffer组成,ReadTx定义了抽象的读事务接口,BatchTx在ReadTx之上定义了抽象的写事务接口,Buffer是数据缓存区。
etcd设计上支持多种Backend实现,目前实现的Backend是boltdb。boltdb是一个基于B+ tree实现的、支持事务的key-value嵌入式数据库。
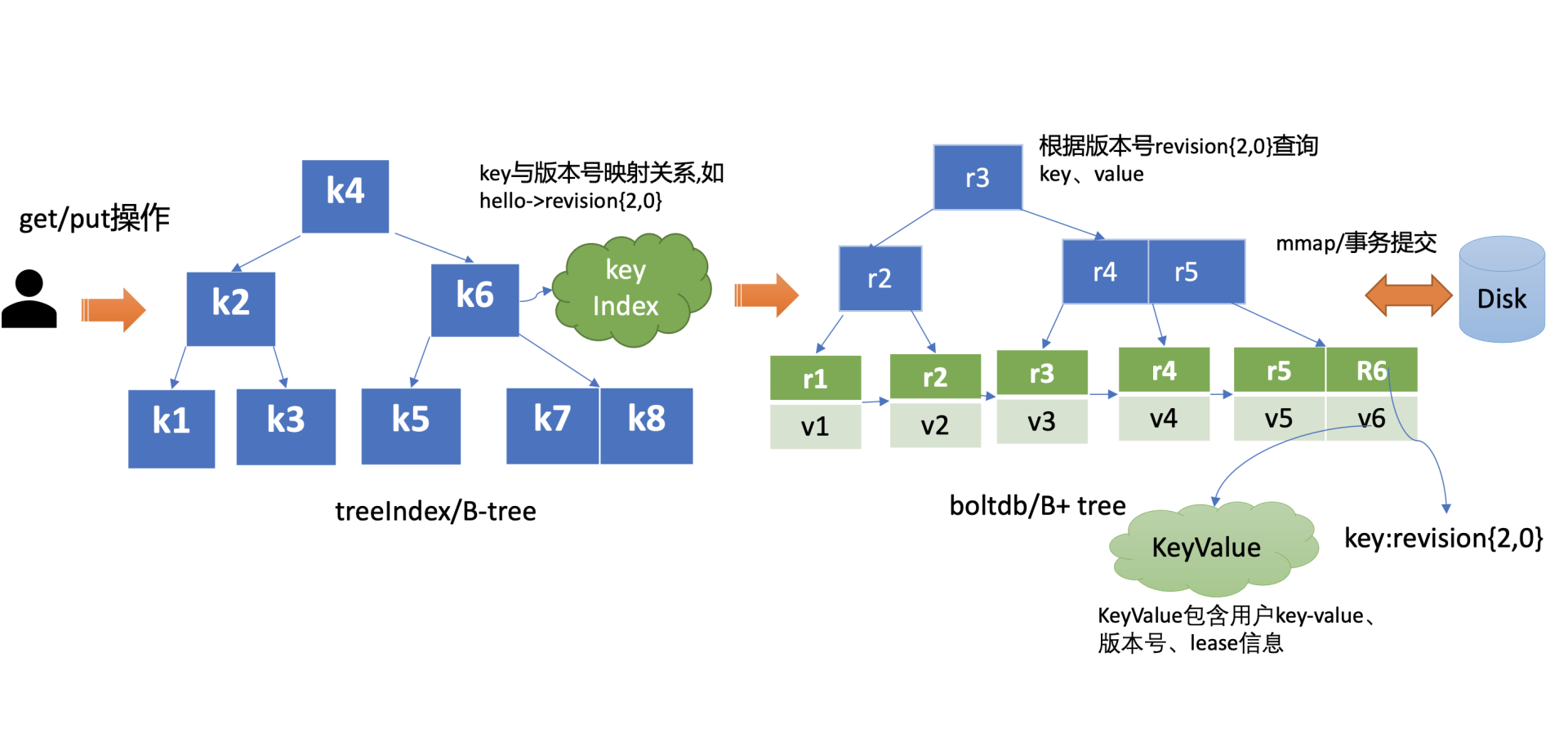
treeIndex与boltdb关系你可参考下图。当你发起一个get hello命令时,从treeIndex中获取key的版本号,然后再通过这个版本号,从boltdb获取value信息。boltdb的value是包含用户key-value、各种版本号、lease信息的结构体。
接下来我和你重点聊聊treeIndex模块的原理与核心数据结构。
treeIndex原理
为什么需要treeIndex模块呢?
对于etcd v2来说,当你通过etcdctl发起一个put hello操作时,etcd v2直接更新内存树,这就导致历史版本直接被覆盖,无法支持保存key的历史版本。在etcd v3中引入treeIndex模块正是为了解决这个问题,支持保存key的历史版本,提供稳定的Watch机制和事务隔离等能力。
那etcd v3又是如何基于treeIndex模块,实现保存key的历史版本的呢?
在02节课里,我们提到过etcd在每次修改key时会生成一个全局递增的版本号(revision),然后通过数据结构B-tree保存用户key与版本号之间的关系,再以版本号作为boltdb key,以用户的key-value等信息作为boltdb value,保存到boltdb。
下面我就为你介绍下,etcd保存用户key与版本号映射关系的数据结构B-tree,为什么etcd使用它而不使用哈希表、平衡二叉树?
从etcd的功能特性上分析, 因etcd支持范围查询,因此保存索引的数据结构也必须支持范围查询才行。所以哈希表不适合,而B-tree支持范围查询。
从性能上分析,平横二叉树每个节点只能容纳一个数据、导致树的高度较高,而B-tree每个节点可以容纳多个数据,树的高度更低,更扁平,涉及的查找次数更少,具有优越的增、删、改、查性能。
Google的开源项目btree,使用Go语言实现了一个内存版的B-tree,对外提供了简单易用的接口。etcd正是基于btree库实现了一个名为treeIndex的索引模块,通过它来查询、保存用户key与版本号之间的关系。
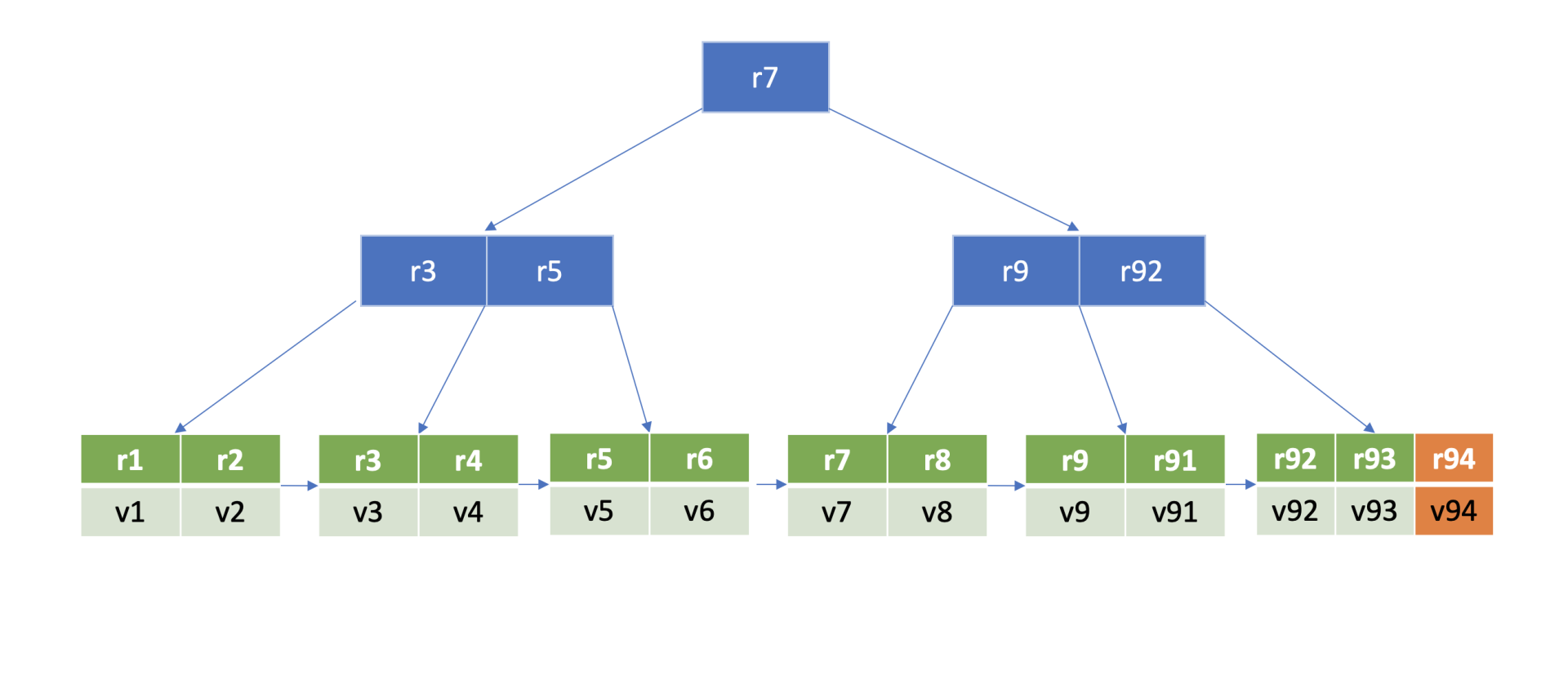
下图是个最大度(degree > 1,简称d)为5的B-tree,度是B-tree中的一个核心参数,它决定了你每个节点上的数据量多少、节点的"胖"、"瘦"程度。
从图中你可以看到,节点越胖,意味着一个节点可以存储更多数据,树的高度越低。在一个度为d的B-tree中,节点保存的最大key数为2d - 1,否则需要进行平衡、分裂操作。这里你要注意的是在etcd treeIndex模块中,创建的是最大度32的B-tree,也就是一个叶子节点最多可以保存63个key。
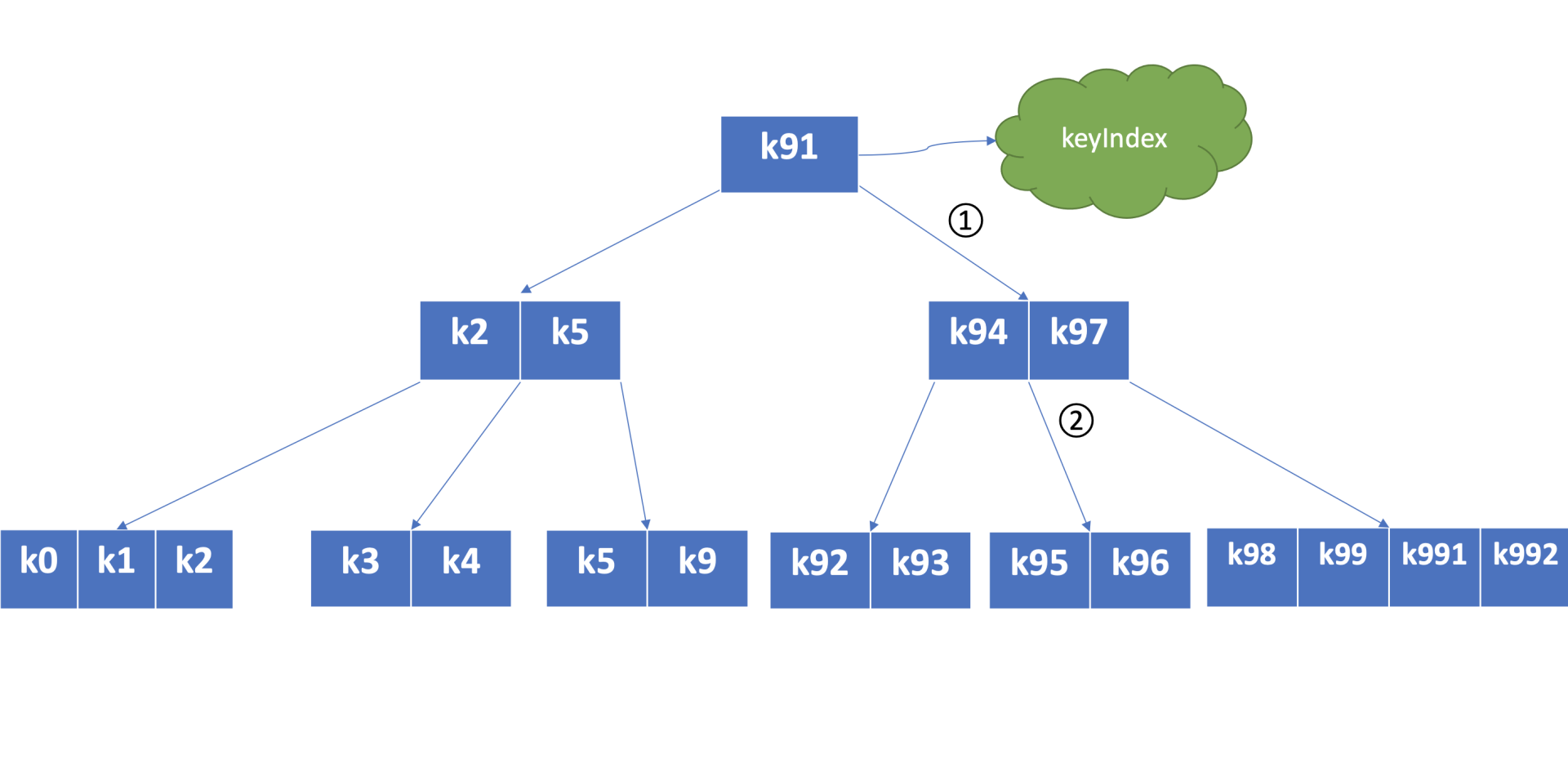
从图中你可以看到,你通过put/txn命令写入的一系列key,treeIndex模块基于B-tree将其组织起来,节点之间基于用户key比较大小。当你查找一个key k95时,通过B-tree的特性,你仅需通过图中流程1和2两次快速比较,就可快速找到k95所在的节点。
在treeIndex中,每个节点的key是一个keyIndex结构,etcd就是通过它保存了用户的key与版本号的映射关系。
那么keyIndex结构包含哪些信息呢?下面是字段说明,你可以参考一下。
go
type keyIndex struct {
key []byte //用户的key名称,比如我们案例中的"hello"
modified revision //最后一次修改key时的etcd版本号,比如我们案例中的刚写入hello为world1时的,版本号为2
generations []generation //generation保存了一个key若干代版本号信息,每代中包含对key的多次修改的版本号列表
}keyIndex中包含用户的key、最后一次修改key时的etcd版本号、key的若干代(generation)版本号信息,每代中包含对key的多次修改的版本号列表。那我们要如何理解generations?为什么它是个数组呢?
generations表示一个key从创建到删除的过程,每代对应key的一个生命周期的开始与结束。当你第一次创建一个key时,会生成第0代,后续的修改操作都是在往第0代中追加修改版本号。当你把key删除后,它就会生成新的第1代,一个key不断经历创建、删除的过程,它就会生成多个代。
generation结构详细信息如下:
go
type generation struct {
ver int64 //表示此key的修改次数
created revision //表示generation结构创建时的版本号
revs []revision //每次修改key时的revision追加到此数组
}generation结构中包含此key的修改次数、generation创建时的版本号、对此key的修改版本号记录列表。
你需要注意的是版本号(revision)并不是一个简单的整数,而是一个结构体。revision结构及含义如下:
go
type revision struct {
main int64 // 一个全局递增的主版本号,随put/txn/delete事务递增,一个事务内的key main版本号是一致的
sub int64 // 一个事务内的子版本号,从0开始随事务内put/delete操作递增
}revision包含main和sub两个字段,main是全局递增的版本号,它是个etcd逻辑时钟,随着put/txn/delete等事务递增。sub是一个事务内的子版本号,从0开始随事务内的put/delete操作递增。
比如启动一个空集群,全局版本号默认为1,执行下面的txn事务,它包含两次put、一次get操作,那么按照我们上面介绍的原理,全局版本号随读写事务自增,因此是main为2,sub随事务内的put/delete操作递增,因此key hello的revison为{2,0},key world的revision为{2,1}。
bash
$ etcdctl txn -i
compares:
success requests (get,put,del):
put hello 1
get hello
put world 2介绍完treeIndex基本原理、核心数据结构后,我们再看看在MVCC特性初体验中的更新、查询、删除key案例里,treeIndex与boltdb是如何协作,完成以上key-value操作的?
MVCC更新key原理
当你通过etcdctl发起一个put hello操作时,如下面的put事务流程图流程一所示,在put写事务中,首先它需要从treeIndex模块中查询key的keyIndex索引信息,keyIndex中存储了key的创建版本号、修改的次数等信息,这些信息在事务中发挥着重要作用,因此会存储在boltdb的value中。
在我们的案例中,因为是第一次创建hello key,此时keyIndex索引为空。
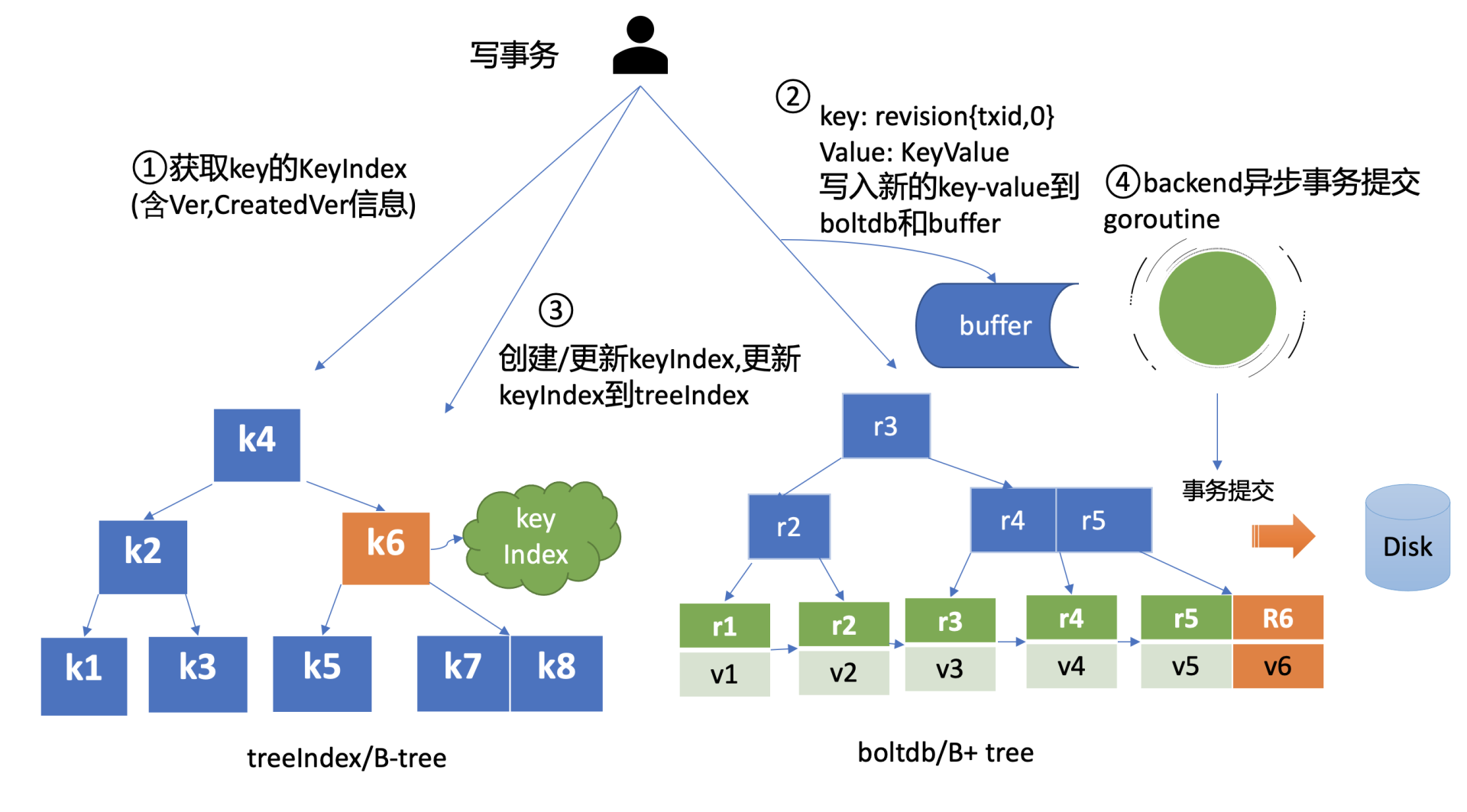
其次etcd会根据当前的全局版本号(空集群启动时默认为1)自增,生成put hello操作对应的版本号revision{2,0},这就是boltdb的key。
boltdb的value是mvccpb.KeyValue结构体,它是由用户key、value、create_revision、mod_revision、version、lease组成。它们的含义分别如下:
- create_revision表示此key创建时的版本号。在我们的案例中,key hello是第一次创建,那么值就是2。当你再次修改key hello的时候,写事务会从treeIndex模块查询hello第一次创建的版本号,也就是keyIndex.generationsi.created字段,赋值给create_revision字段;
- mod_revision表示key最后一次修改时的版本号,即put操作发生时的全局版本号加1;
- version表示此key的修改次数。每次修改的时候,写事务会从treeIndex模块查询hello已经历过的修改次数,也就是keyIndex.generationsi.ver字段,将ver字段值加1后,赋值给version字段。
填充好boltdb的KeyValue结构体后,这时就可以通过Backend的写事务batchTx接口将key{2,0},value为mvccpb.KeyValue保存到boltdb的缓存中,并同步更新buffer,如上图中的流程二所示。
此时存储到boltdb中的key、value数据如下:

然后put事务需将本次修改的版本号与用户key的映射关系保存到treeIndex模块中,也就是上图中的流程三。
因为key hello是首次创建,treeIndex模块它会生成key hello对应的keyIndex对象,并填充相关数据结构。
keyIndex填充后的结果如下所示:
key hello的keyIndex:
key: "hello"
modified: <2,0>
generations:
[{ver:1,created:<2,0>,revisions: [<2,0>]} ]我们来简易分析一下上面的结果。
- key为hello,modified为最后一次修改版本号<2,0>,key hello是首次创建的,因此新增一个generation代跟踪它的生命周期、修改记录;
- generation的ver表示修改次数,首次创建为1,后续随着修改操作递增;
- generation.created表示创建generation时的版本号为<2,0>;
- revision数组保存对此key修改的版本号列表,每次修改都会将将相应的版本号追加到revisions数组中。
通过以上流程,一个put操作终于完成。
但是此时数据还并未持久化,为了提升etcd的写吞吐量、性能,一般情况下(默认堆积的写事务数大于1万才在写事务结束时同步持久化),数据持久化由Backend的异步goroutine完成,它通过事务批量提交,定时将boltdb页缓存中的脏数据提交到持久化存储磁盘中,也就是下图中的黑色虚线框住的流程四。
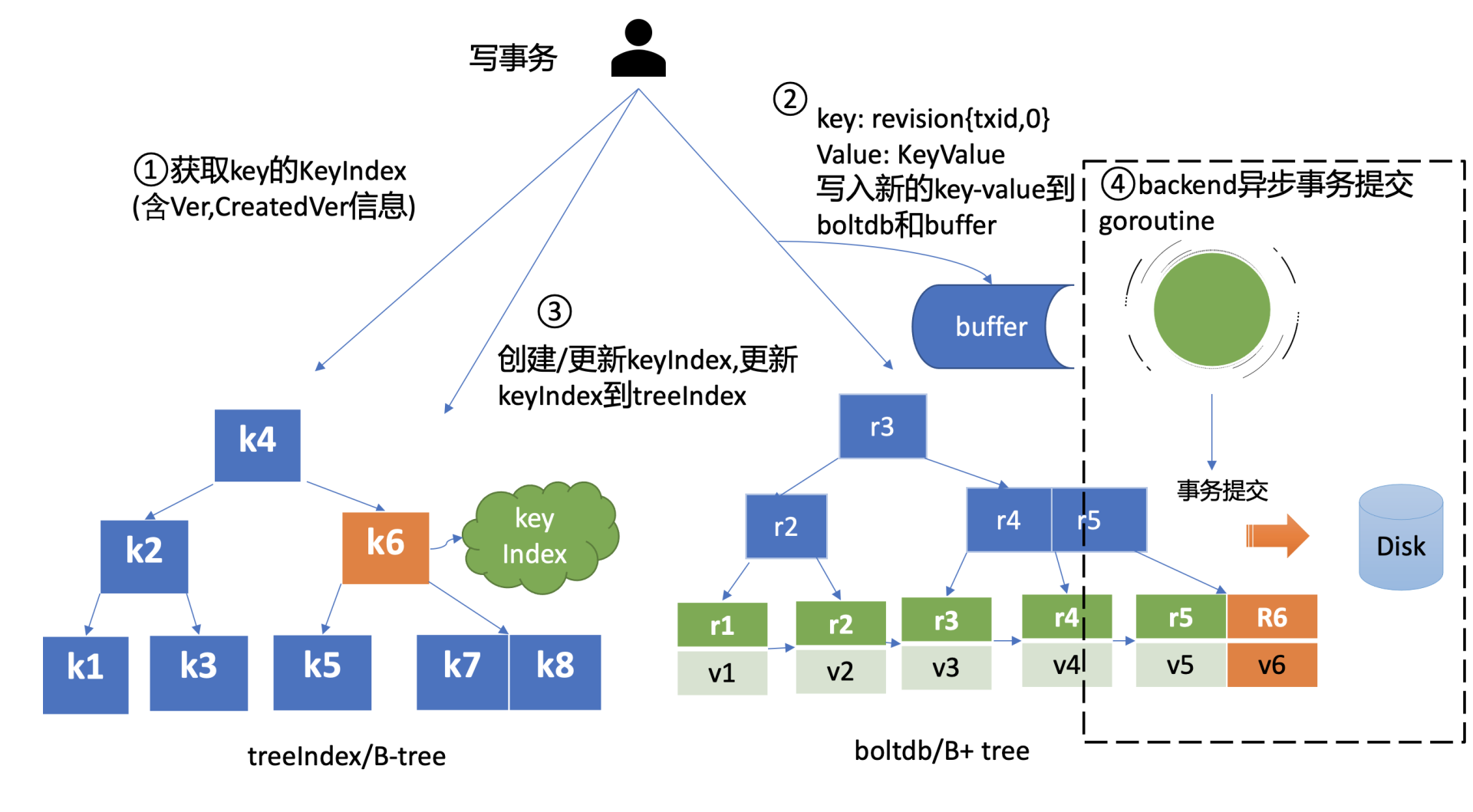
MVCC查询key原理
完成put hello为world1操作后,这时你通过etcdctl发起一个get hello操作,MVCC模块首先会创建一个读事务对象(TxnRead),在etcd 3.4中Backend实现了ConcurrentReadTx, 也就是并发读特性。
并发读特性的核心原理是创建读事务对象时,它会全量拷贝当前写事务未提交的buffer数据,并发的读写事务不再阻塞在一个buffer资源锁上,实现了全并发读。
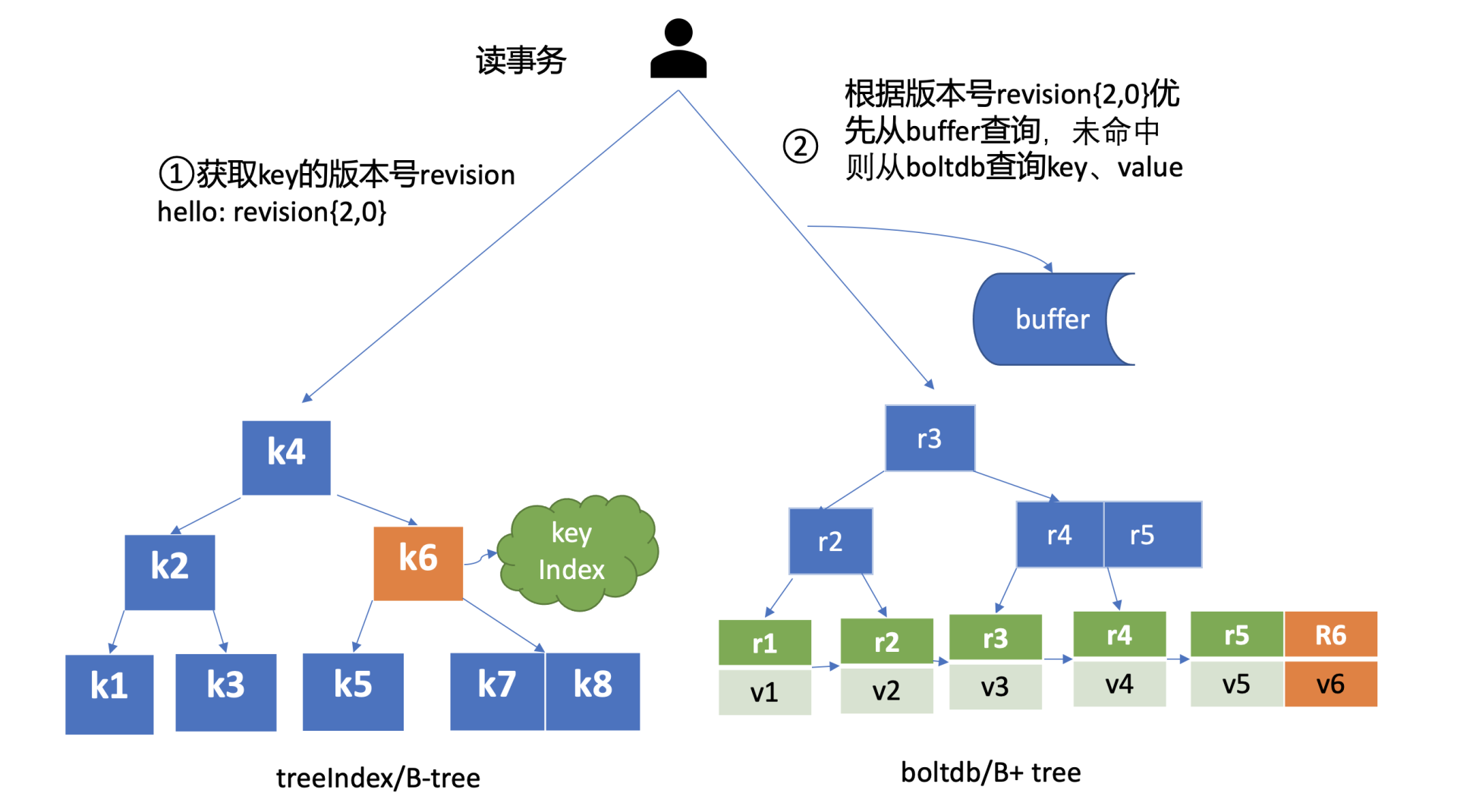
如上图所示,在读事务中,它首先需要根据key从treeIndex模块获取版本号,因我们未带版本号读,默认是读取最新的数据。treeIndex模块从B-tree中,根据key查找到keyIndex对象后,匹配有效的generation,返回generation的revisions数组中最后一个版本号{2,0}给读事务对象。
读事务对象根据此版本号为key,通过Backend的并发读事务(ConcurrentReadTx)接口,优先从buffer中查询,命中则直接返回,否则从boltdb中查询此key的value信息。
那指定版本号读取历史记录又是怎么实现的呢?
当你再次发起一个put hello为world2修改操作时,key hello对应的keyIndex的结果如下面所示,keyIndex.modified字段更新为<3,0>,generation的revision数组追加最新的版本号<3,0>,ver修改为2。
key hello的keyIndex:
key: "hello"
modified: <3,0>
generations:
[{ver:2,created:<2,0>,revisions: [<2,0>,<3,0>]}]boltdb插入一个新的key revision{3,0},此时存储到boltdb中的key-value数据如下:

这时你再发起一个指定历史版本号为2的读请求时,实际是读版本号为2的时间点的快照数据。treeIndex模块会遍历generation内的历史版本号,返回小于等于2的最大历史版本号,在我们这个案例中,也就是revision{2,0},以它作为boltdb的key,从boltdb中查询出value即可。
MVCC删除key原理
介绍完MVCC更新、查询key的原理后,我们接着往下看。当你执行etcdctl del hello命令时,etcd会立刻从treeIndex和boltdb中删除此数据吗?还是增加一个标记实现延迟删除(lazy delete)呢?
答案为etcd实现的是延期删除模式,原理与key更新类似。
与更新key不一样之处在于,一方面,生成的boltdb key版本号{4,0,t}追加了删除标识(tombstone,简写t),boltdb value变成只含用户key的KeyValue结构体。另一方面treeIndex模块也会给此key hello对应的keyIndex对象,追加一个空的generation对象,表示此索引对应的key被删除了。
当你再次查询hello的时候,treeIndex模块根据key hello查找到keyindex对象后,若发现其存在空的generation对象,并且查询的版本号大于等于被删除时的版本号,则会返回空。
etcdctl hello操作后的keyIndex的结果如下面所示:
key hello的keyIndex:
key: "hello"
modified: <4,0>
generations:
[
{ver:3,created:<2,0>,revisions: [<2,0>,<3,0>,<4,0>(t)]},
{empty}
]boltdb此时会插入一个新的key revision{4,0,t},此时存储到boltdb中的key-value数据如下:

那么key打上删除标记后有哪些用途呢?什么时候会真正删除它呢?
一方面删除key时会生成events,Watch模块根据key的删除标识,会生成对应的Delete事件。
另一方面,当你重启etcd,遍历boltdb中的key构建treeIndex内存树时,你需要知道哪些key是已经被删除的,并为对应的key索引生成tombstone标识。而真正删除treeIndex中的索引对象、boltdb中的key是通过压缩(compactor)组件异步完成。
正因为etcd的删除key操作是基于以上延期删除原理实现的,因此只要压缩组件未回收历史版本,我们就能从etcd中找回误删的数据。
小结
最后我们来小结下今天的内容,我通过MVCC特性初体验中的更新、查询、删除key案例,为你分析了MVCC整体架构、核心模块,它由treeIndex、boltdb组成。
treeIndex模块基于Google开源的btree库实现,它的核心数据结构keyIndex,保存了用户key与版本号关系。每次修改key都会生成新的版本号,生成新的boltdb key-value。boltdb的key为版本号,value包含用户key-value、各种版本号、lease的mvccpb.KeyValue结构体。
当你未带版本号查询key时,etcd返回的是key最新版本数据。当你指定版本号读取数据时,etcd实际上返回的是版本号生成那个时间点的快照数据。
删除一个数据时,etcd并未真正删除它,而是基于lazy delete实现的异步删除。删除原理本质上与更新操作类似,只不过boltdb的key会打上删除标记,keyIndex索引中追加空的generation。真正删除key是通过etcd的压缩组件去异步实现的,在后面的课程里我会继续和你深入介绍。
基于以上原理特性的实现,etcd实现了保存key历史版本的功能,是高可靠Watch机制的基础。基于key-value中的各种版本号信息,etcd可提供各种级别的简易事务隔离能力。基于Backend/boltdb提供的MVCC机制,etcd可实现读写不冲突。
思考题
你认为etcd为什么删除使用lazy delete方式呢? 相比同步delete,各有什么优缺点?当你突然删除大量key后,db大小是立刻增加还是减少呢?
08 Watch:如何高效获取数据变化通知?
在Kubernetes中,各种各样的控制器实现了Deployment、StatefulSet、Job等功能强大的Workload。控制器的核心思想是监听、比较资源实际状态与期望状态是否一致,若不一致则进行协调工作,使其最终一致。
那么当你修改一个Deployment的镜像时,Deployment控制器是如何高效的感知到期望状态发生了变化呢?
要回答这个问题,得从etcd的Watch特性说起,它是Kubernetes控制器的工作基础。今天我和你分享的主题就是etcd的核心特性Watch机制设计实现,通过分析Watch机制的四大核心问题,让你了解一个变化数据是如何从0到1推送给client,并给你介绍Watch特性从etcd v2到etcd v3演进、优化过程。
希望通过这节课,你能在实际业务中应用Watch特性,快速获取数据变更通知,而不是使用可能导致大量expensive request的轮询模式。更进一步,我将帮助你掌握Watch过程中,可能会出现的各种异常错误和原因,并知道在业务中如何优雅处理,让你的服务更稳地运行。
Watch特性初体验
在详细介绍Watch特性实现原理之前,我先通过几个简单命令,带你初体验下Watch特性。
启动一个空集群,更新两次key hello后,使用Watch特性如何获取key hello的历史修改记录呢?
如下所示,你可以通过下面的watch命令,带版本号监听key hello,集群版本号可通过endpoint status命令获取,空集群启动后的版本号为1。
执行后输出如下代码所示,两个事件记录分别对应上面的两次的修改,事件中含有key、value、各类版本号等信息,你还可以通过比较create_revision和mod_revision区分此事件是add还是update事件。
watch命令执行后,你后续执行的增量put hello修改操作,它同样可持续输出最新的变更事件给你。
bash
$ etcdctl put hello world1
$ etcdctl put hello world2
$ etcdctl watch hello -w=json --rev=1
{
"Events":[
{
"kv":{
"key":"aGVsbG8=",
"create_revision":2,
"mod_revision":2,
"version":1,
"value":"d29ybGQx"
}
},
{
"kv":{
"key":"aGVsbG8=",
"create_revision":2,
"mod_revision":3,
"version":2,
"value":"d29ybGQy"
}
}
],
"CompactRevision":0,
"Canceled":false,
"Created":false
}从以上初体验中,你可以看到,基于Watch特性,你可以快速获取到你感兴趣的数据变化事件,这也是Kubernetes控制器工作的核心基础。在这过程中,其实有以下四大核心问题:
第一,client获取事件的机制,etcd是使用轮询模式还是推送模式呢?两者各有什么优缺点?
第二,事件是如何存储的? 会保留多久?watch命令中的版本号具有什么作用?
第三,当client和server端出现短暂网络波动等异常因素后,导致事件堆积时,server端会丢弃事件吗?若你监听的历史版本号server端不存在了,你的代码该如何处理?
第四,如果你创建了上万个watcher监听key变化,当server端收到一个写请求后,etcd是如何根据变化的key快速找到监听它的watcher呢?
接下来我就和你分别详细聊聊etcd Watch特性是如何解决这四大问题的。搞懂这四个问题,你就明白etcd甚至各类分布式存储Watch特性的核心实现原理了。
轮询 vs 流式推送
首先第一个问题是client获取事件机制,etcd是使用轮询模式还是推送模式呢?两者各有什么优缺点?
答案是两种机制etcd都使用过。
在etcd v2 Watch机制实现中,使用的是HTTP/1.x协议,实现简单、兼容性好,每个watcher对应一个TCP连接。client通过HTTP/1.1协议长连接定时轮询server,获取最新的数据变化事件。
然而当你的watcher成千上万的时,即使集群空负载,大量轮询也会产生一定的QPS,server端会消耗大量的socket、内存等资源,导致etcd的扩展性、稳定性无法满足Kubernetes等业务场景诉求。
etcd v3的Watch机制的设计实现并非凭空出现,它正是吸取了etcd v2的经验、教训而重构诞生的。
在etcd v3中,为了解决etcd v2的以上缺陷,使用的是基于HTTP/2的gRPC协议,双向流的Watch API设计,实现了连接多路复用。
HTTP/2协议为什么能实现多路复用呢?
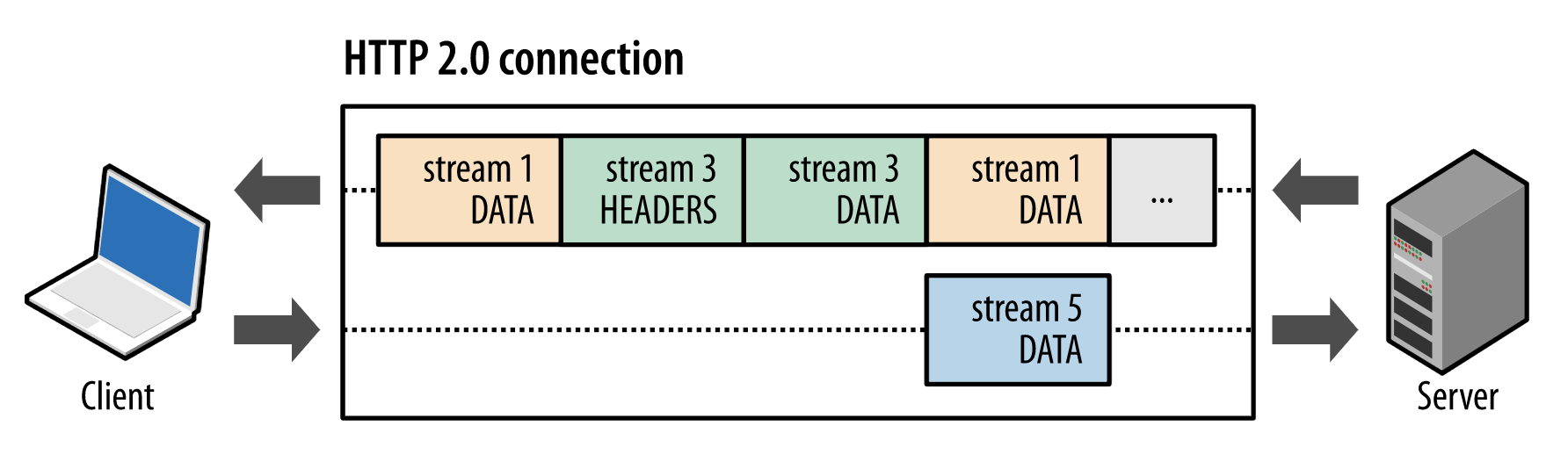
在HTTP/2协议中,HTTP消息被分解独立的帧(Frame),交错发送,帧是最小的数据单位。每个帧会标识属于哪个流(Stream),流由多个数据帧组成,每个流拥有一个唯一的ID,一个数据流对应一个请求或响应包。
如上图所示,client正在向server发送数据流5的帧,同时server也正在向client发送数据流1和数据流3的一系列帧。一个连接上有并行的三个数据流,HTTP/2可基于帧的流ID将并行、交错发送的帧重新组装成完整的消息。
通过以上机制,HTTP/2就解决了HTTP/1的请求阻塞、连接无法复用的问题,实现了多路复用、乱序发送。
etcd基于以上介绍的HTTP/2协议的多路复用等机制,实现了一个client/TCP连接支持多gRPC Stream, 一个gRPC Stream又支持多个watcher,如下图所示。同时事件通知模式也从client轮询优化成server流式推送,极大降低了server端socket、内存等资源。
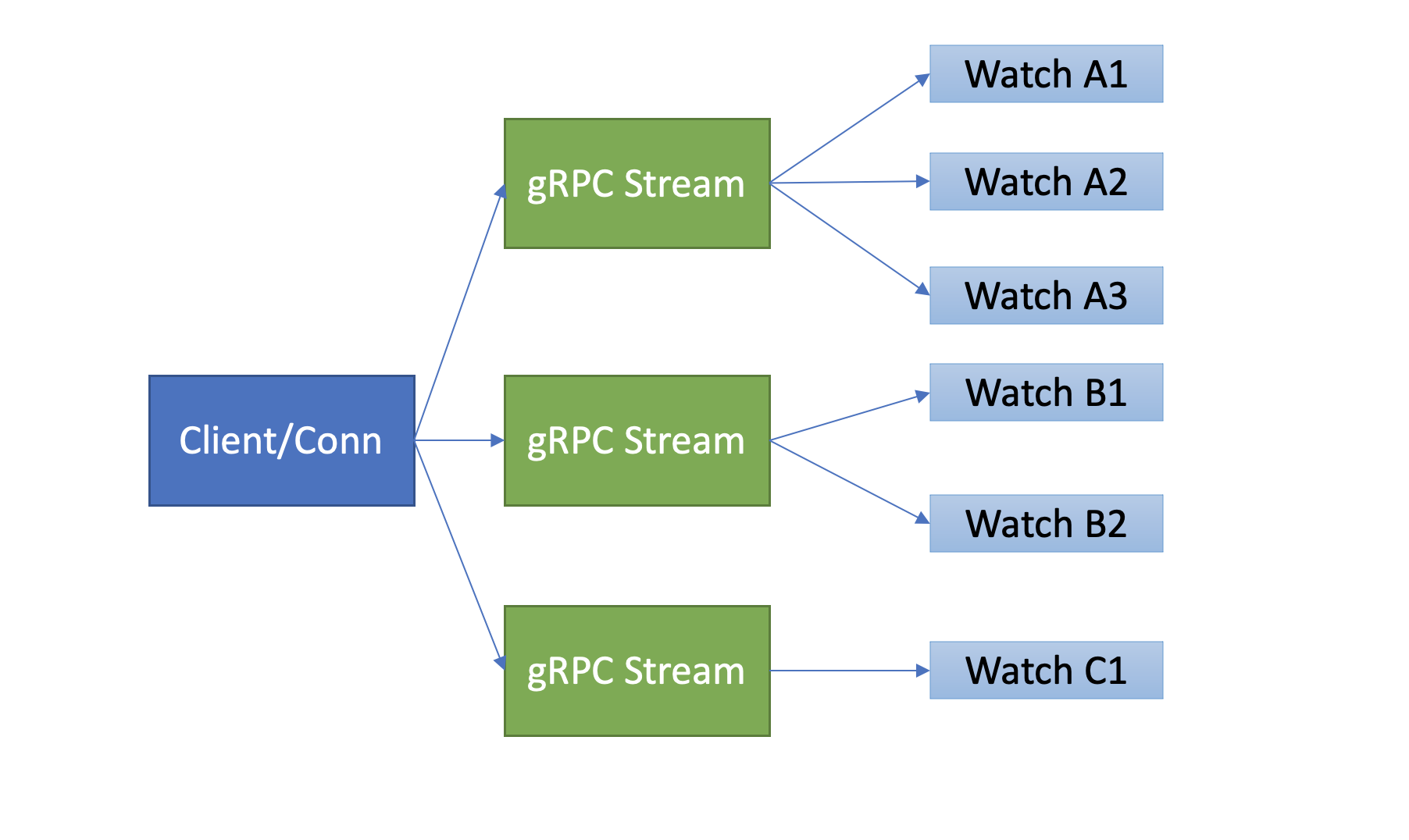
当然在etcd v3 watch性能优化的背后,也带来了Watch API复杂度上升, 不过你不用担心,etcd的clientv3库已经帮助你搞定这些棘手的工作了。
在clientv3库中,Watch特性被抽象成Watch、Close、RequestProgress三个简单API提供给开发者使用,屏蔽了client与gRPC WatchServer交互的复杂细节,实现了一个client支持多个gRPC Stream,一个gRPC Stream支持多个watcher,显著降低了你的开发复杂度。
同时当watch连接的节点故障,clientv3库支持自动重连到健康节点,并使用之前已接收的最大版本号创建新的watcher,避免旧事件回放等。
滑动窗口 vs MVCC
介绍完etcd v2的轮询机制和etcd v3的流式推送机制后,再看第二个问题,事件是如何存储的? 会保留多久呢?watch命令中的版本号具有什么作用?
第二个问题的本质是历史版本存储,etcd经历了从滑动窗口到MVCC机制的演变,滑动窗口是仅保存有限的最近历史版本到内存中,而MVCC机制则将历史版本保存在磁盘中,避免了历史版本的丢失,极大的提升了Watch机制的可靠性。
etcd v2滑动窗口是如何实现的?它有什么缺点呢?
它使用的是如下一个简单的环形数组来存储历史事件版本,当key被修改后,相关事件就会被添加到数组中来。若超过eventQueue的容量,则淘汰最旧的事件。在etcd v2中,eventQueue的容量是固定的1000,因此它最多只会保存1000条事件记录,不会占用大量etcd内存导致etcd OOM。
go
type EventHistory struct {
Queue eventQueue
StartIndex uint64
LastIndex uint64
rwl sync.RWMutex
}但是它的缺陷显而易见的,固定的事件窗口只能保存有限的历史事件版本,是不可靠的。当写请求较多的时候、client与server网络出现波动等异常时,很容易导致事件丢失,client不得不触发大量的expensive查询操作,以获取最新的数据及版本号,才能持续监听数据。
特别是对于重度依赖Watch机制的Kubernetes来说,显然是无法接受的。因为这会导致控制器等组件频繁的发起expensive List Pod等资源操作,导致APIServer/etcd出现高负载、OOM等,对稳定性造成极大的伤害。
etcd v3的MVCC机制,正如上一节课所介绍的,就是为解决etcd v2 Watch机制不可靠而诞生。相比etcd v2直接保存事件到内存的环形数组中,etcd v3则是将一个key的历史修改版本保存在boltdb里面。boltdb是一个基于磁盘文件的持久化存储,因此它重启后历史事件不像etcd v2一样会丢失,同时你可通过配置压缩策略,来控制保存的历史版本数,在压缩篇我会和你详细讨论它。
最后watch命令中的版本号具有什么作用呢?
在上一节课中我们深入介绍了它的含义,版本号是etcd逻辑时钟,当client因网络等异常出现连接闪断后,通过版本号,它就可从server端的boltdb中获取错过的历史事件,而无需全量同步,它是etcd Watch机制数据增量同步的核心。
可靠的事件推送机制
再看第三个问题,当client和server端出现短暂网络波动等异常因素后,导致事件堆积时,server端会丢弃事件吗?若你监听的历史版本号server端不存在了,你的代码该如何处理?
第三个问题的本质是可靠事件推送机制,要搞懂它,我们就得弄懂etcd Watch特性的整体架构、核心流程,下图是Watch特性整体架构图。
整体架构
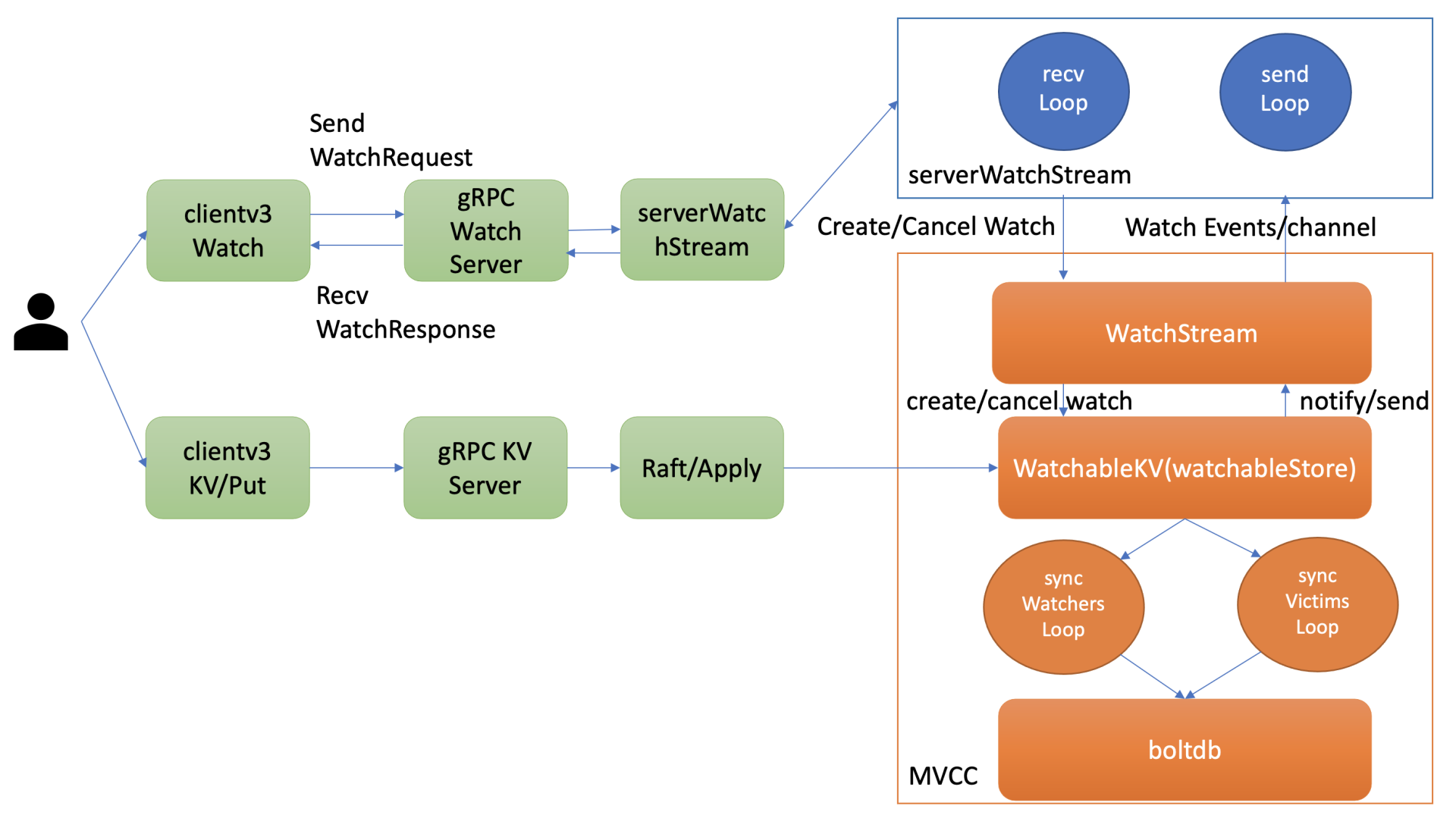
我先通过上面的架构图,给你简要介绍下一个watch请求流程,让你对全流程有个整体的认识。
当你通过etcdctl或API发起一个watch key请求的时候,etcd的gRPCWatchServer收到watch请求后,会创建一个serverWatchStream, 它负责接收client的gRPC Stream的create/cancel watcher请求(recvLoop goroutine),并将从MVCC模块接收的Watch事件转发给client(sendLoop goroutine)。
当serverWatchStream收到create watcher请求后,serverWatchStream会调用MVCC模块的WatchStream子模块分配一个watcher id,并将watcher注册到MVCC的WatchableKV模块。
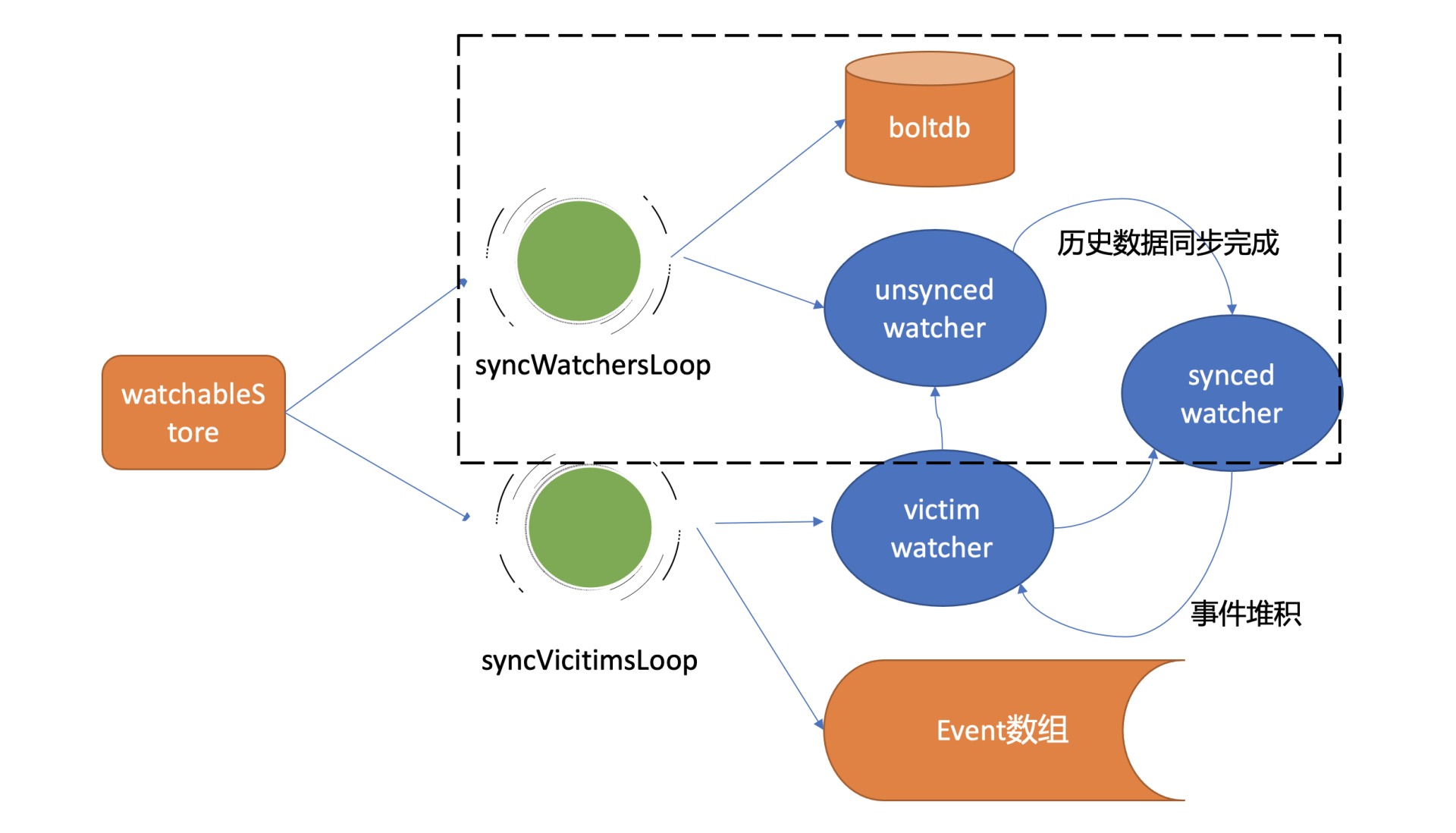
在etcd启动的时候,WatchableKV模块会运行syncWatchersLoop和syncVictimsLoop goroutine,分别负责不同场景下的事件推送,它们也是Watch特性可靠性的核心之一。
从架构图中你可以看到Watch特性的核心实现是WatchableKV模块,下面我就为你抽丝剥茧,看看"etcdctl watch hello -w=json --rev=1"命令在WatchableKV模块是如何处理的?面对各类异常,它如何实现可靠事件推送?
etcd核心解决方案是复杂度管理,问题拆分。
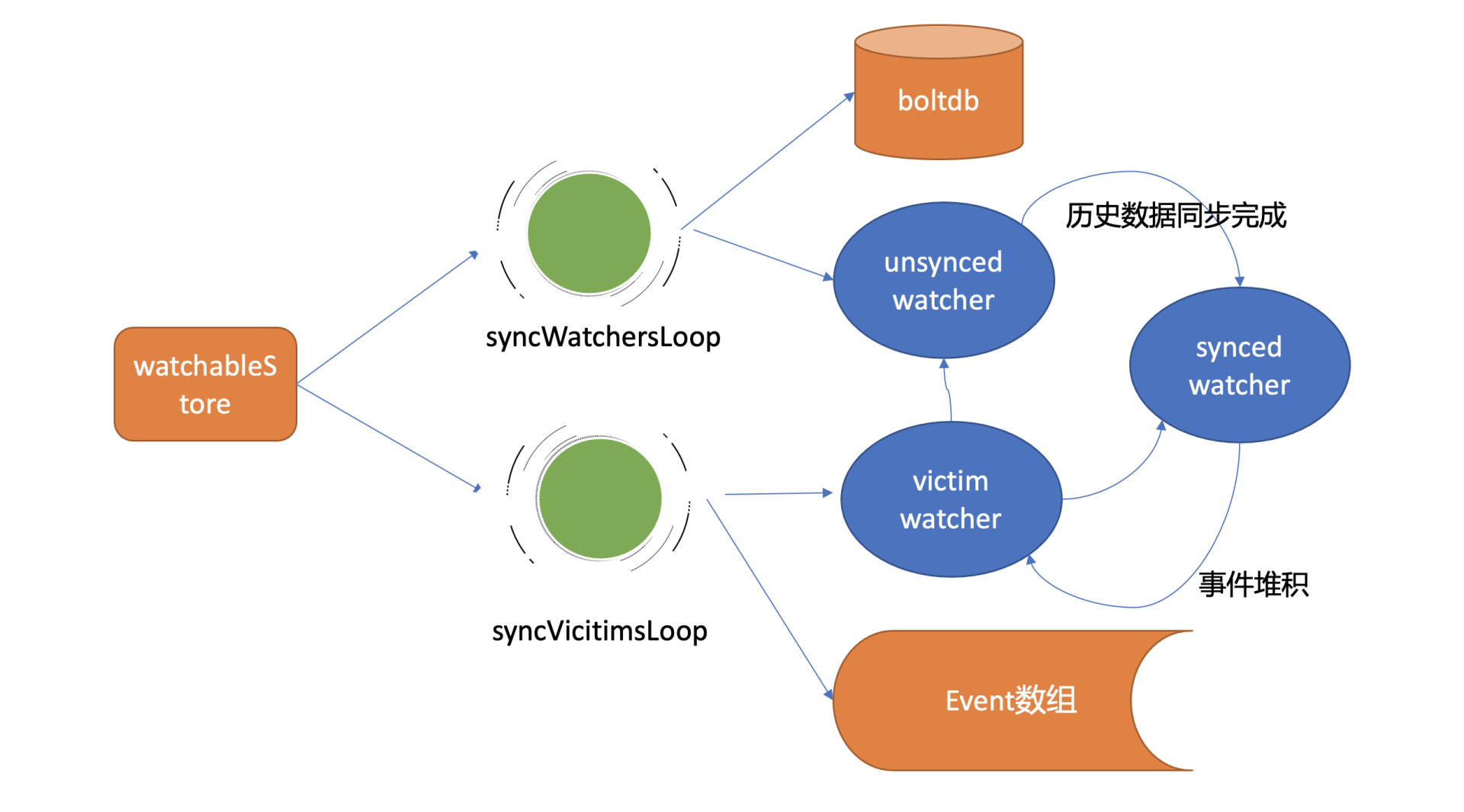
etcd根据不同场景,对问题进行了分解,将watcher按场景分类,实现了轻重分离、低耦合。我首先给你介绍下synced watcher、unsynced watcher它们各自的含义。
synced watcher,顾名思义,表示此类watcher监听的数据都已经同步完毕,在等待新的变更。
如果你创建的watcher未指定版本号(默认0)、或指定的版本号大于etcd sever当前最新的版本号(currentRev),那么它就会保存到synced watcherGroup中。watcherGroup负责管理多个watcher,能够根据key快速找到监听该key的一个或多个watcher。
unsynced watcher,表示此类watcher监听的数据还未同步完成,落后于当前最新数据变更,正在努力追赶。
如果你创建的watcher指定版本号小于etcd server当前最新版本号,那么它就会保存到unsynced watcherGroup中。比如我们的这个案例中watch带指定版本号1监听时,版本号1和etcd server当前版本之间的数据并未同步给你,因此它就属于此类。
从以上介绍中,我们可以将可靠的事件推送机制拆分成最新事件推送、异常场景重试、历史事件推送机制三个子问题来进行分析。
下面是第一个子问题,最新事件推送机制。
最新事件推送机制
当etcd收到一个写请求,key-value发生变化的时候,处于syncedGroup中的watcher,是如何获取到最新变化事件并推送给client的呢?
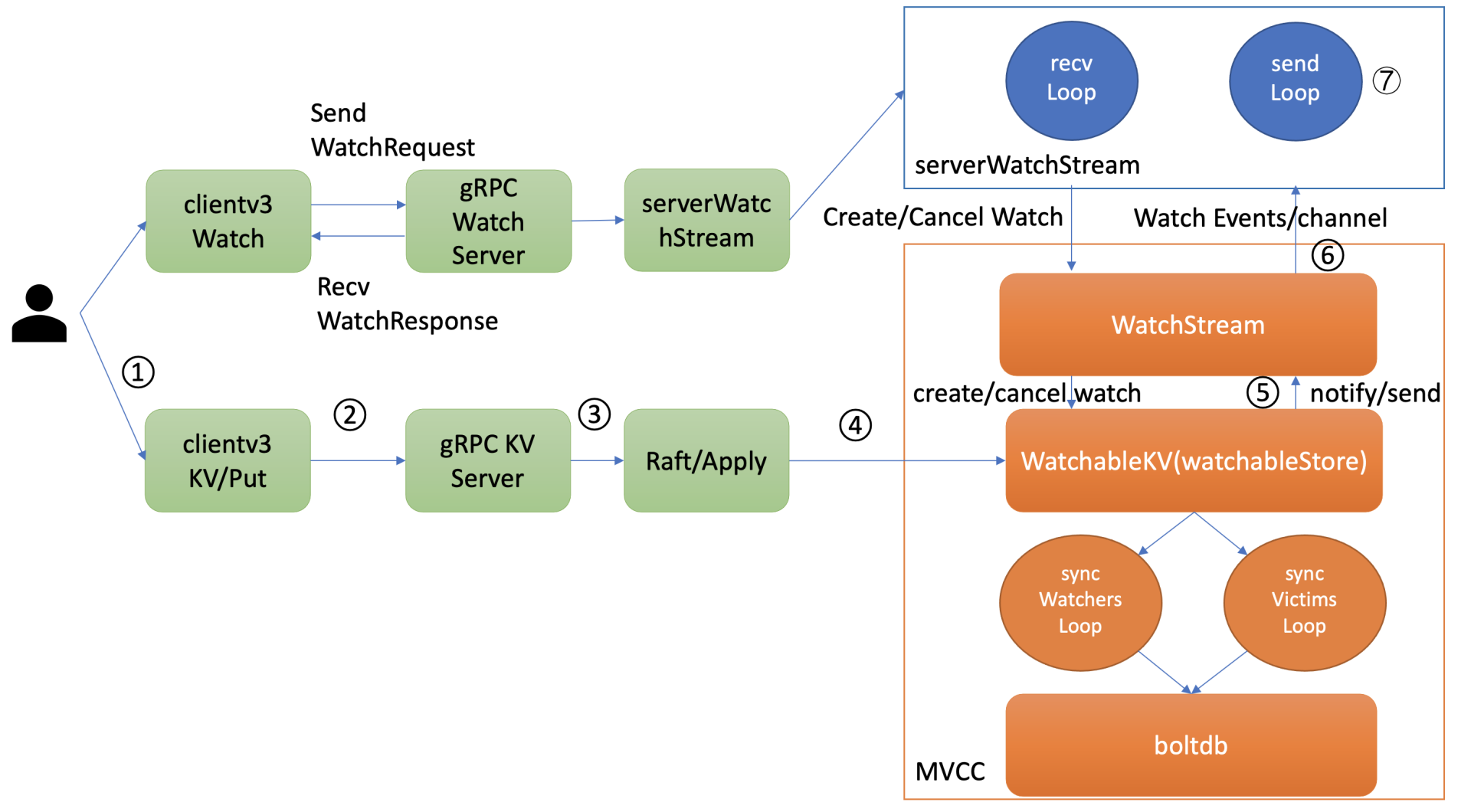
当你创建完成watcher后,此时你执行put hello修改操作时,如上图所示,请求经过KVServer、Raft模块后Apply到状态机时,在MVCC的put事务中,它会将本次修改的后的mvccpb.KeyValue保存到一个changes数组中。
在put事务结束时,如下面的精简代码所示,它会将KeyValue转换成Event事件,然后回调watchableStore.notify函数(流程5)。notify会匹配出监听过此key并处于synced watcherGroup中的watcher,同时事件中的版本号要大于等于watcher监听的最小版本号,才能将事件发送到此watcher的事件channel中。
serverWatchStream的sendLoop goroutine监听到channel消息后,读出消息立即推送给client(流程6和7),至此,完成一个最新修改事件推送。
go
evs := make([]mvccpb.Event, len(changes))
for i, change := range changes {
evs[i].Kv = &changes[i]
if change.CreateRevision == 0 {
evs[i].Type = mvccpb.DELETE
evs[i].Kv.ModRevision = rev
} else {
evs[i].Type = mvccpb.PUT
}
}
tw.s.notify(rev, evs)注意接收Watch事件channel的buffer容量默认1024(etcd v3.4.9)。若client与server端因网络波动、高负载等原因导致推送缓慢,buffer满了,事件会丢失吗?
这就是第二个子问题,异常场景的重试机制。
异常场景重试机制
若出现channel buffer满了,etcd为了保证Watch事件的高可靠性,并不会丢弃它,而是将此watcher从synced watcherGroup中删除,然后将此watcher和事件列表保存到一个名为受害者victim的watcherBatch结构中,通过异步机制重试保证事件的可靠性。
还有一个点你需要注意的是,notify操作它是在修改事务结束时同步调用的,必须是轻量级、高性能、无阻塞的,否则会严重影响集群写性能。
那么若因网络波动、CPU高负载等异常导致watcher处于victim集合中后,etcd是如何处理这种slow watcher呢?
在介绍Watch机制整体架构时,我们知道WatchableKV模块会启动两个异步goroutine,其中一个是syncVictimsLoop,正是它负责slower watcher的堆积的事件推送。
它的基本工作原理是,遍历victim watcherBatch数据结构,尝试将堆积的事件再次推送到watcher的接收channel中。若推送失败,则再次加入到victim watcherBatch数据结构中等待下次重试。
若推送成功,watcher监听的最小版本号(minRev)小于等于server当前版本号(currentRev),说明可能还有历史事件未推送,需加入到unsynced watcherGroup中,由下面介绍的历史事件推送机制,推送minRev到currentRev之间的事件。
若watcher的最小版本号大于server当前版本号,则加入到synced watcher集合中,进入上面介绍的最新事件通知机制。
下面我给你画了一幅图总结各类watcher状态转换关系,希望能帮助你快速厘清之间关系。
介绍完最新事件推送、异常场景重试机制后,那历史事件推送机制又是怎么工作的呢?
历史事件推送机制
WatchableKV模块的另一个goroutine,syncWatchersLoop,正是负责unsynced watcherGroup中的watcher历史事件推送。
在历史事件推送机制中,如果你监听老的版本号已经被etcd压缩了,client该如何处理?
要了解这个问题,我们就得搞清楚syncWatchersLoop如何工作,它的核心支撑是boltdb中存储了key-value的历史版本。
syncWatchersLoop,它会遍历处于unsynced watcherGroup中的每个watcher,为了优化性能,它会选择一批unsynced watcher批量同步,找出这一批unsynced watcher中监听的最小版本号。
因boltdb的key是按版本号存储的,因此可通过指定查询的key范围的最小版本号作为开始区间,当前server最大版本号作为结束区间,遍历boltdb获得所有历史数据。
然后将KeyValue结构转换成事件,匹配出监听过事件中key的watcher后,将事件发送给对应的watcher事件接收channel即可。发送完成后,watcher从unsynced watcherGroup中移除、添加到synced watcherGroup中,如下面的watcher状态转换图黑色虚线框所示。
若watcher监听的版本号已经小于当前etcd server压缩的版本号,历史变更数据就可能已丢失,因此etcd server会返回ErrCompacted错误给client。client收到此错误后,需重新获取数据最新版本号后,再次Watch。你在业务开发过程中,使用Watch API最常见的一个错误之一就是未处理此错误。
高效的事件匹配
介绍完可靠的事件推送机制后,最后我们再看第四个问题,如果你创建了上万个watcher监听key变化,当server端收到一个写请求后,etcd是如何根据变化的key快速找到监听它的watcher呢?一个个遍历watcher吗?
显然一个个遍历watcher是最简单的方法,但是它的时间复杂度是O(N),在watcher数较多的场景下,会导致性能出现瓶颈。更何况etcd是在执行一个写事务结束时,同步触发事件通知流程的,若匹配watcher开销较大,将严重影响etcd性能。
那使用什么数据结构来快速查找哪些watcher监听了一个事件中的key呢?
也许你会说使用map记录下哪些watcher监听了什么key不就可以了吗? etcd的确使用map记录了监听单个key的watcher,但是你要注意的是Watch特性不仅仅可以监听单key,它还可以指定监听key范围、key前缀,因此etcd还使用了如下的区间树。
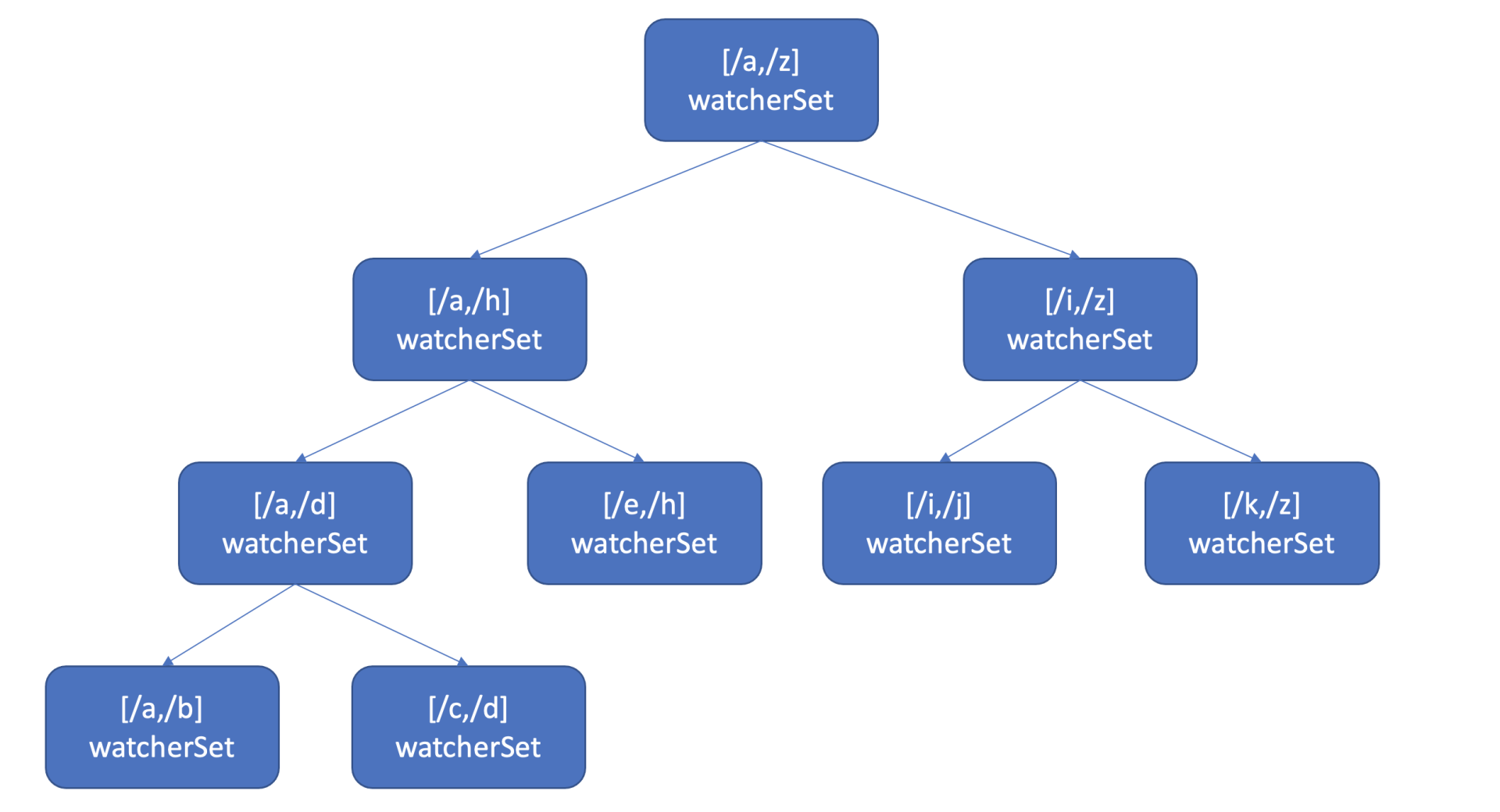
当收到创建watcher请求的时候,它会把watcher监听的key范围插入到上面的区间树中,区间的值保存了监听同样key范围的watcher集合/watcherSet。
当产生一个事件时,etcd首先需要从map查找是否有watcher监听了单key,其次它还需要从区间树找出与此key相交的所有区间,然后从区间的值获取监听的watcher集合。
区间树支持快速查找一个key是否在某个区间内,时间复杂度O(LogN),因此etcd基于map和区间树实现了watcher与事件快速匹配,具备良好的扩展性。
小结
最后我们来小结今天的内容,我通过一个Watch特性初体验,提出了Watch特性设计实现的四个核心问题,分别是获取事件机制、事件历史版本存储、如何实现可靠的事件推送机制、如何高效的将事件与watcher进行匹配。
在获取事件机制、事件历史版本存储两个问题中,我给你介绍了etcd v2在使用HTTP/1.x轮询、滑动窗口时,存在大量的连接数、丢事件等问题,导致扩展性、稳定性较差。
而etcd v3 Watch特性优化思路是基于HTTP/2的流式传输、多路复用,实现了一个连接支持多个watcher,减少了大量连接数,事件存储也从滑动窗口优化成稳定可靠的MVCC机制,历史版本保存在磁盘中,具备更好的扩展性、稳定性。
在实现可靠的事件推送机制问题中,我通过一个整体架构图带你了解整个Watch机制的核心链路,数据推送流程。
Watch特性的核心实现模块是watchableStore,它通过将watcher划分为synced/unsynced/victim三类,将问题进行了分解,并通过多个后台异步循环 goroutine负责不同场景下的事件推送,提供了各类异常等场景下的Watch事件重试机制,尽力确保变更事件不丢失、按逻辑时钟版本号顺序推送给client。
最后一个事件匹配性能问题,etcd基于map和区间树数实现了watcher与事件快速匹配,保障了大规模场景下的Watch机制性能和读写稳定性。
思考题
好了,这节课到这里也就结束了。我们一块来做一下思考题吧。
业务场景是希望agent能通过Watch机制监听server端下发给它的任务信息,简要实现如下,你认为它存在哪些问题呢? 它一定能监听到server下发给其的所有任务信息吗?欢迎你给出正确的解决方案。
go
taskPrefix := "/task/" + "Agent IP"
rsp, err := cli.Get(context.Background(), taskPrefix, clientv3.WithPrefix())
if err != nil {
log.Fatal(err)
}
// to do something
// ....
// Watch taskPrefix
rch := cli.Watch(context.Background(), taskPrefix, clientv3.WithPrefix())
for wresp := range rch {
for _, ev := range wresp.Events {
fmt.Printf("%s %q : %q\n", ev.Type, ev.Kv.Key, ev.Kv.Value)
}
}09 事务:如何安全地实现多key操作?
在软件开发过程中,我们经常会遇到需要批量执行多个key操作的业务场景,比如转账案例中,Alice给Bob转账100元,Alice账号减少100,Bob账号增加100,这涉及到多个key的原子更新。
无论发生任何故障,我们应用层期望的结果是,要么两个操作一起成功,要么两个一起失败。我们无法容忍出现一个成功,一个失败的情况。那么etcd是如何解决多key原子更新问题呢?
这正是我今天要和你分享的主题------事务,它就是为了简化应用层的编程模型而诞生的。我将通过转账案例为你剖析etcd事务实现,让你了解etcd如何实现事务ACID特性的,以及MVCC版本号在事务中的重要作用。希望通过本节课,帮助你在业务开发中正确使用事务,保证软件代码的正确性。
事务特性初体验及API
如何使用etcd实现Alice向Bob转账功能呢?
在etcd v2的时候, etcd提供了CAS(Compare and swap),然而其只支持单key,不支持多key,因此无法满足类似转账场景的需求。严格意义上说CAS称不上事务,无法实现事务的各个隔离级别。
etcd v3为了解决多key的原子操作问题,提供了全新迷你事务API,同时基于MVCC版本号,它可以实现各种隔离级别的事务。它的基本结构如下:
client.Txn(ctx).If(cmp1, cmp2, ...).Then(op1, op2, ...,).Else(op1, op2, ...)从上面结构中你可以看到,事务API由If语句、Then语句、Else语句组成,这与我们平时常见的MySQL事务完全不一样。
它的基本原理是,在If语句中,你可以添加一系列的条件表达式,若条件表达式全部通过检查,则执行Then语句的get/put/delete等操作,否则执行Else的get/put/delete等操作。
那么If语句支持哪些检查项呢?
首先是key的最近一次修改版本号mod_revision,简称mod。你可以通过它检查key最近一次被修改时的版本号是否符合你的预期。比如当你查询到Alice账号资金为100元时,它的mod_revision是v1,当你发起转账操作时,你得确保Alice账号上的100元未被挪用,这就可以通过mod("Alice") = "v1" 条件表达式来保障转账安全性。
其次是key的创建版本号create_revision,简称create。你可以通过它检查key是否已存在。比如在分布式锁场景里,只有分布式锁key(lock)不存在的时候,你才能发起put操作创建锁,这时你可以通过create("lock") = "0"来判断,因为一个key不存在的话它的create_revision版本号就是0。
接着是key的修改次数version。你可以通过它检查key的修改次数是否符合预期。比如你期望key在修改次数小于3时,才能发起某些操作时,可以通过version("key") < "3"来判断。
最后是key的value值。你可以通过检查key的value值是否符合预期,然后发起某些操作。比如期望Alice的账号资金为200, value("Alice") = "200"。
If语句通过以上MVCC版本号、value值、各种比较运算符(等于、大于、小于、不等于),实现了灵活的比较的功能,满足你各类业务场景诉求。
下面我给出了一个使用etcdctl的txn事务命令,基于以上介绍的特性,初步实现的一个Alice向Bob转账100元的事务。
Alice和Bob初始账上资金分别都为200元,事务首先判断Alice账号资金是否为200,若是则执行转账操作,不是则返回最新资金。etcd是如何执行这个事务的呢?这个事务实现上有哪些问题呢?
bash
$ etcdctl txn -i
compares: //对应If语句
value("Alice") = "200" //判断Alice账号资金是否为200
success requests (get, put, del): //对应Then语句
put Alice 100 //Alice账号初始资金200减100
put Bob 300 //Bob账号初始资金200加100
failure requests (get, put, del): //对应Else语句
get Alice
get Bob
SUCCESS
OK
OK整体流程
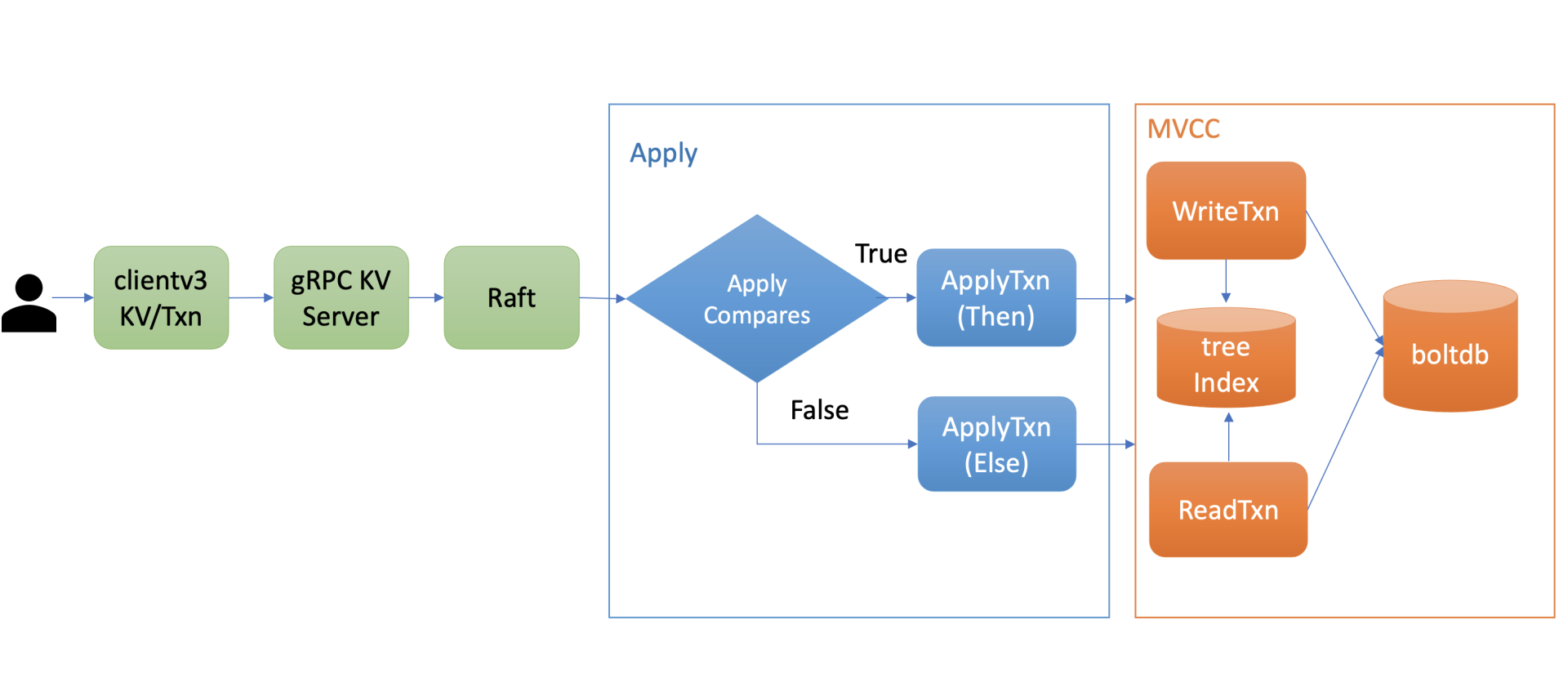
在和你介绍上面案例中的etcd事务原理和问题前,我先给你介绍下事务的整体流程,为我们后面介绍etcd事务ACID特性的实现做准备。
上图是etcd事务的执行流程,当你通过client发起一个txn转账事务操作时,通过gRPC KV Server、Raft模块处理后,在Apply模块执行此事务的时候,它首先对你的事务的If语句进行检查,也就是ApplyCompares操作,如果通过此操作,则执行ApplyTxn/Then语句,否则执行ApplyTxn/Else语句。
在执行以上操作过程中,它会根据事务是否只读、可写,通过MVCC层的读写事务对象,执行事务中的get/put/delete各操作,也就是我们上一节课介绍的MVCC对key的读写原理。
事务ACID特性
了解完事务的整体执行流程后,那么etcd应该如何正确实现上面案例中Alice向Bob转账的事务呢?别着急,我们先来了解一下事务的ACID特性。在你了解了etcd事务ACID特性实现后,这个转账事务案例的正确解决方案也就简单了。
ACID是衡量事务的四个特性,由原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)组成。接下来我就为你分析ACID特性在etcd中的实现。
原子性与持久性
事务的原子性(Atomicity)是指在一个事务中,所有请求要么同时成功,要么同时失败。比如在我们的转账案例中,是绝对无法容忍Alice账号扣款成功,但是Bob账号资金到账失败的场景。
持久性(Durability)是指事务一旦提交,其所做的修改会永久保存在数据库。
软件系统在运行过程中会遇到各种各样的软硬件故障,如果etcd在执行上面事务过程中,刚执行完扣款命令(put Alice 100)就突然crash了,它是如何保证转账事务的原子性与持久性的呢?
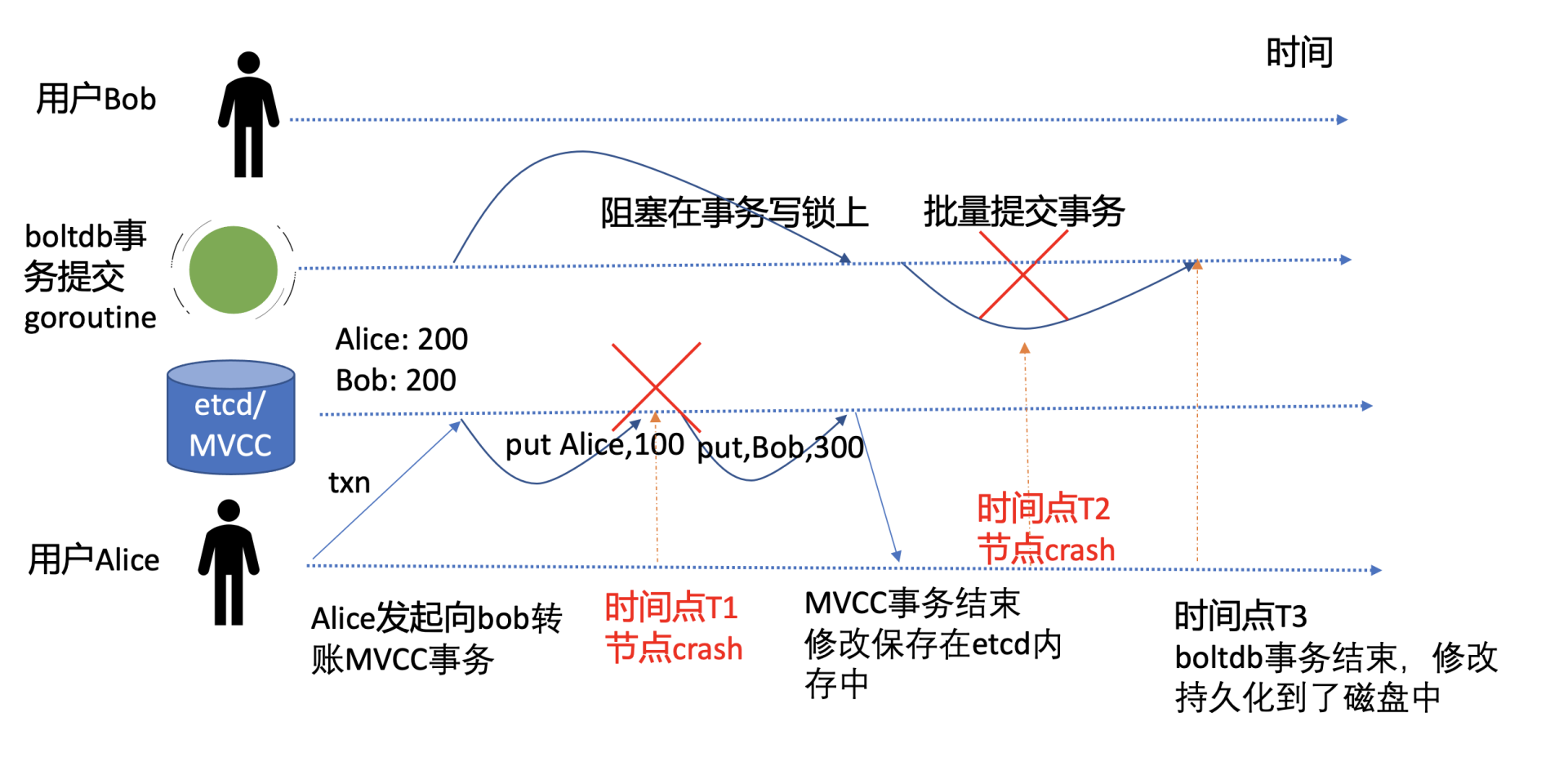
如上图转账事务流程图所示,etcd在执行一个事务过程中,任何时间点都可能会出现节点crash等异常问题。我在图中给你标注了两个关键的异常时间点,它们分别是T1和T2。接下来我分别为你分析一下etcd在这两个关键时间点异常后,是如何保证事务的原子性和持久性的。
T1时间点
T1时间点是在Alice账号扣款100元完成时,Bob账号资金还未成功增加时突然发生了crash。
从前面介绍的etcd写原理和上面流程图我们可知,此时MVCC写事务持有boltdb写锁,仅是将修改提交到了内存中,保证幂等性、防止日志条目重复执行的一致性索引consistent index也并未更新。同时,负责boltdb事务提交的goroutine因无法持有写锁,也并未将事务提交到持久化存储中。
因此,T1时间点发生crash异常后,事务并未成功执行和持久化任意数据到磁盘上。在节点重启时,etcd server会重放WAL中的已提交日志条目,再次执行以上转账事务。因此不会出现Alice扣款成功、Bob到帐失败等严重Bug,极大简化了业务的编程复杂度。
T2时间点
T2时间点是在MVCC写事务完成转账,server返回给client转账成功后,boltdb的事务提交goroutine,批量将事务持久化到磁盘中时发生了crash。这时etcd又是如何保证原子性和持久性的呢?
我们知道一致性索引consistent index字段值是和key-value数据在一个boltdb事务里同时持久化到磁盘中的。若在boltdb事务提交过程中发生crash了,简单情况是consistent index和key-value数据都更新失败。那么当节点重启,etcd server重放WAL中已提交日志条目时,同样会再次应用转账事务到状态机中,因此事务的原子性和持久化依然能得到保证。
更复杂的情况是,当boltdb提交事务的时候,会不会部分数据提交成功,部分数据提交失败呢?这个问题,我将在下一节课通过深入介绍boltdb为你解答。
了解完etcd事务的原子性和持久性后,那一致性又是怎么一回事呢?事务的一致性难道是指各个节点数据一致性吗?
一致性
在软件系统中,到处可见一致性(Consistency)的表述,其实在不同场景下,它的含义是不一样的。
首先分布式系统中多副本数据一致性,它是指各个副本之间的数据是否一致,比如Redis的主备是异步复制的,那么它的一致性是最终一致性的。
其次是CAP原理中的一致性是指可线性化。核心原理是虽然整个系统是由多副本组成,但是通过线性化能力支持,对client而言就如一个副本,应用程序无需关心系统有多少个副本。
然后是一致性哈希,它是一种分布式系统中的数据分片算法,具备良好的分散性、平衡性。
最后是事务中的一致性,它是指事务变更前后,数据库必须满足若干恒等条件的状态约束,一致性往往是由数据库和业务程序两方面来保障的。
在Alice向Bob转账的案例中有哪些恒等状态呢?
很明显,转账系统内的各账号资金总额,在转账前后应该一致,同时各账号资产不能小于0。
为了帮助你更好地理解前面转账事务实现的问题,下面我给你画了幅两个并发转账事务的流程图。
图中有两个并发的转账事务,Mike向Bob转账100元,Alice也向Bob转账100元,按照我们上面的事务实现,从下图可知转账前系统总资金是600元,转账后却只有500元了,因此它无法保证转账前后账号系统内的资产一致性,导致了资产凭空消失,破坏了事务的一致性。
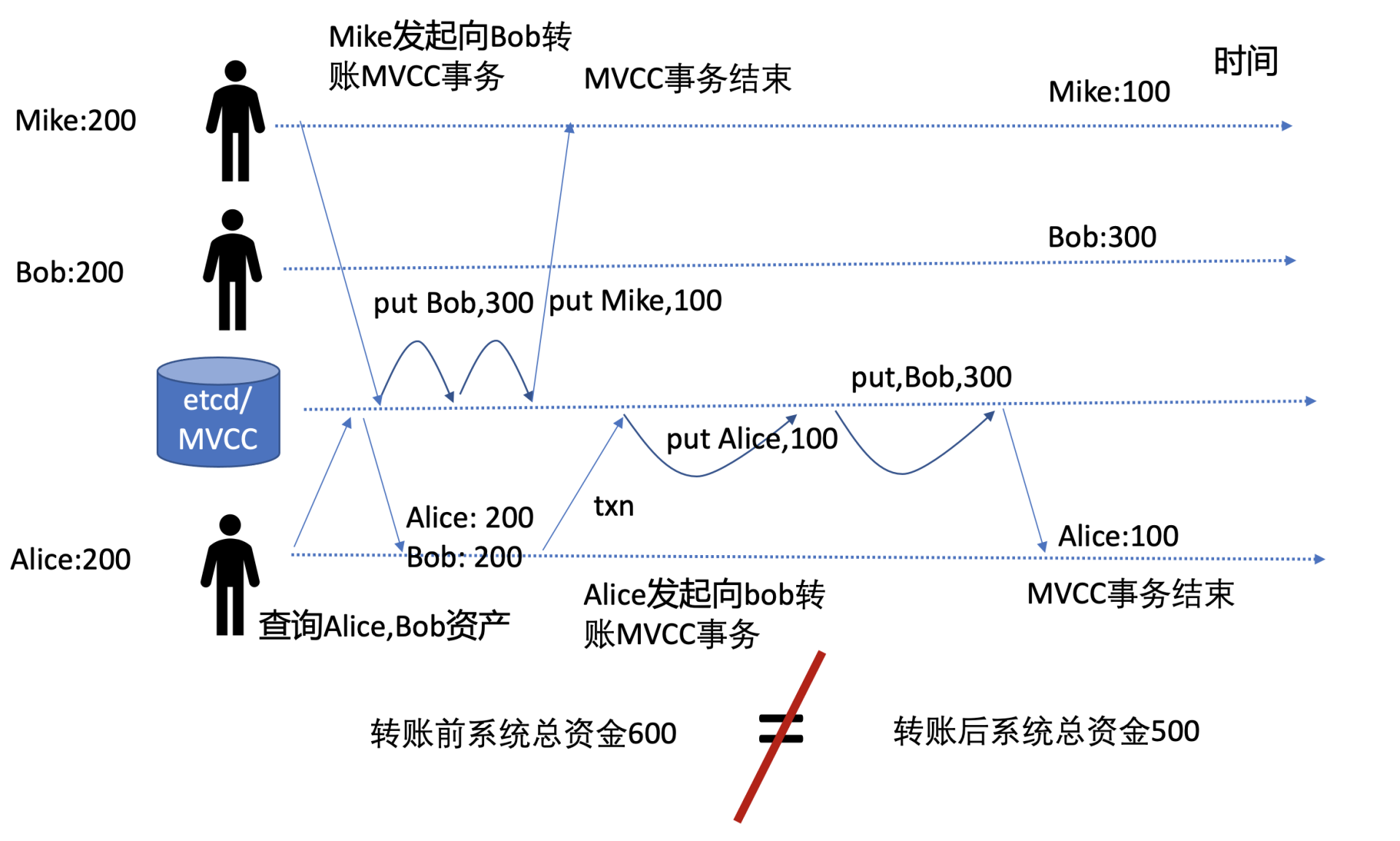
事务一致性被破坏的根本原因是,事务中缺少对Bob账号资产是否发生变化的判断,这就导致账号资金被覆盖。
为了确保事务的一致性,一方面,业务程序在转账逻辑里面,需检查转账者资产大于等于转账金额。在事务提交时,通过账号资产的版本号,确保双方账号资产未被其他事务修改。若双方账号资产被其他事务修改,账号资产版本号会检查失败,这时业务可以通过获取最新的资产和版本号,发起新的转账事务流程解决。
另一方面,etcd会通过WAL日志和consistent index、boltdb事务特性,去确保事务的原子性,因此不会有部分成功部分失败的操作,导致资金凭空消失、新增。
介绍完事务的原子性和持久化、一致性后,我们再看看etcd又是如何提供各种隔离级别的事务,在转账过程中,其他client能看到转账的中间状态吗(如Alice扣款成功,Bob还未增加时)?
隔离性
ACID中的I是指Isolation,也就是事务的隔离性,它是指事务在执行过程中的可见性。常见的事务隔离级别有以下四种。
首先是未提交读(Read UnCommitted),也就是一个client能读取到未提交的事务。比如转账事务过程中,Alice账号资金扣除后,Bob账号上资金还未增加,这时如果其他client读取到这种中间状态,它会发现系统总金额钱减少了,破坏了事务一致性的约束。
其次是已提交读(Read Committed),指的是只能读取到已经提交的事务数据,但是存在不可重复读的问题。比如事务开始时,你读取了Alice和Bob资金,这时其他事务修改Alice和Bob账号上的资金,你在事务中再次读取时会读取到最新资金,导致两次读取结果不一样。
接着是可重复读(Repeated Read),它是指在一个事务中,同一个读操作get Alice/Bob在事务的任意时刻都能得到同样的结果,其他修改事务提交后也不会影响你本事务所看到的结果。
最后是串行化 (Serializable),它是最高的事务隔离级别,读写相互阻塞,通过牺牲并发能力、串行化来解决事务并发更新过程中的隔离问题。对于串行化我要和你特别补充一点,很多人认为它都是通过读写锁,来实现事务一个个串行提交的,其实这只是在基于锁的并发控制数据库系统实现而已。为了优化性能,在基于MVCC机制实现的各个数据库系统中,提供了一个名为"可串行化的快照隔离"级别,相比悲观锁而言,它是一种乐观并发控制,通过快照技术实现的类似串行化的效果,事务提交时能检查是否冲突。
下面我重点和你介绍下未提交读、已提交读、可重复读、串行化快照隔离。
未提交读
首先是最低的事务隔离级别,未提交读。我们通过如下一个转账事务时间序列图,来分析下一个client能否读取到未提交事务修改的数据,是否存在脏读。
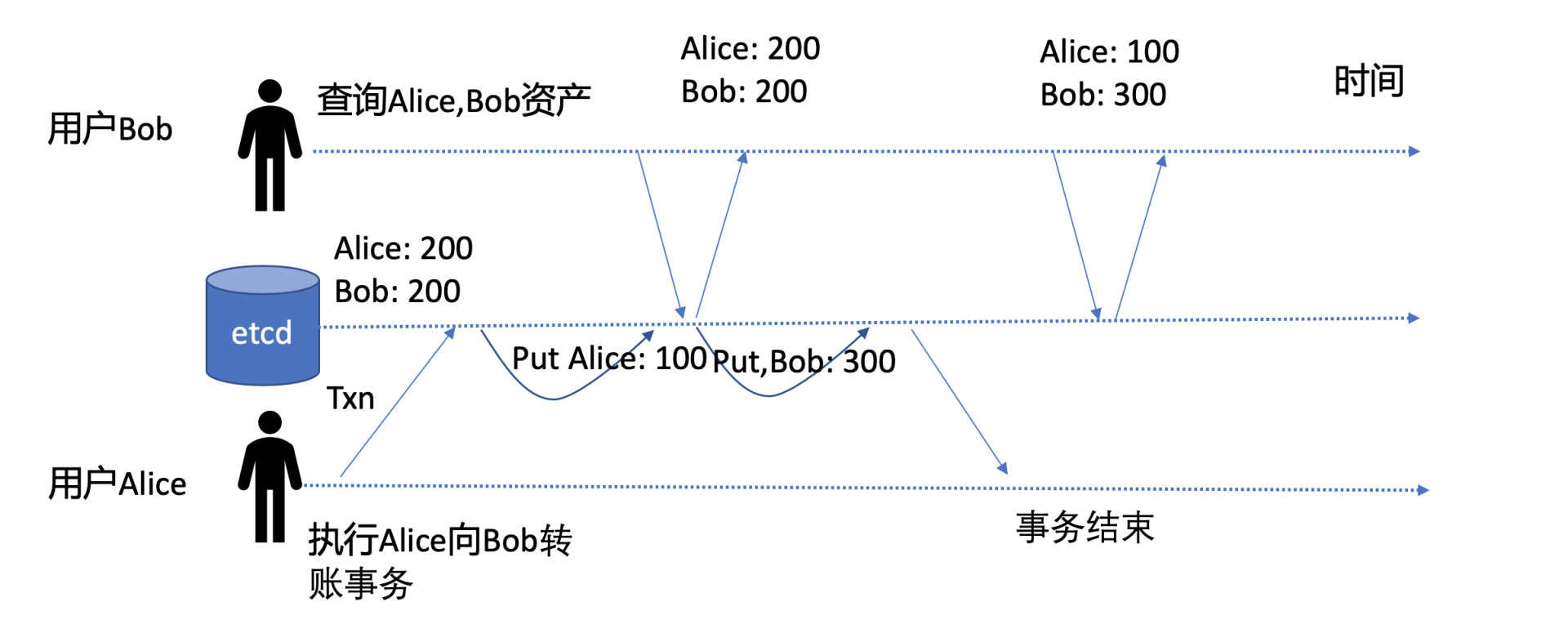
图中有两个事务,一个是用户查询Alice和Bob资产的事务,一个是我们执行Alice向Bob转账的事务。
如图中所示,若在Alice向Bob转账事务执行过程中,etcd server收到了client查询Alice和Bob资产的读请求,显然此时我们无法接受client能读取到一个未提交的事务,因为这对应用程序而言会产生严重的BUG。那么etcd是如何保证不出现这种场景呢?
我们知道etcd基于boltdb实现读写操作的,读请求由boltdb的读事务处理,你可以理解为快照读。写请求由boltdb写事务处理,etcd定时将一批写操作提交到boltdb并清空buffer。
由于etcd是批量提交写事务的,而读事务又是快照读,因此当MVCC写事务完成时,它需要更新buffer,这样下一个读请求到达时,才能从buffer中获取到最新数据。
在我们的场景中,转账事务并未结束,执行put Alice为100的操作不会回写buffer,因此避免了脏读的可能性。用户此刻从boltdb快照读事务中查询到的Alice和Bob资产都为200。
从以上分析可知,etcd并未使用悲观锁来解决脏读的问题,而是通过MVCC机制来实现读写不阻塞,并解决脏读的问题。
已提交读、可重复读
比未提交读隔离级别更高的是已提交读,它是指在事务中能读取到已提交数据,但是存在不可重复读的问题。已提交读,也就是说你每次读操作,若未增加任何版本号限制,默认都是当前读,etcd会返回最新已提交的事务结果给你。
如何理解不可重复读呢?
在上面用户查询Alice和Bob事务的案例中,第一次查出来资产都是200,第二次是Alice为100,Bob为300,通过读已提交模式,你能及时获取到etcd最新已提交的事务结果,但是出现了不可重复读,两次读出来的Alice和Bob资产不一致。
那么如何实现可重复读呢?
你可以通过MVCC快照读,或者参考etcd的事务框架STM实现,它在事务中维护一个读缓存,优先从读缓存中查找,不存在则从etcd查询并更新到缓存中,这样事务中后续读请求都可从缓存中查找,确保了可重复读。
最后我们再来重点介绍下什么是串行化快照隔离。
串行化快照隔离
串行化快照隔离是最严格的事务隔离级别,它是指在在事务刚开始时,首先获取etcd当前的版本号rev,事务中后续发出的读请求都带上这个版本号rev,告诉etcd你需要获取那个时间点的快照数据,etcd的MVCC机制就能确保事务中能读取到同一时刻的数据。
**同时,它还要确保事务提交时,你读写的数据都是最新的,未被其他人修改,也就是要增加冲突检测机制。**当事务提交出现冲突的时候依赖client重试解决,安全地实现多key原子更新。
那么我们应该如何为上面一致性案例中,两个并发转账的事务,增加冲突检测机制呢?
核心就是我们前面介绍MVCC的版本号,我通过下面的并发转账事务流程图为你解释它是如何工作的。
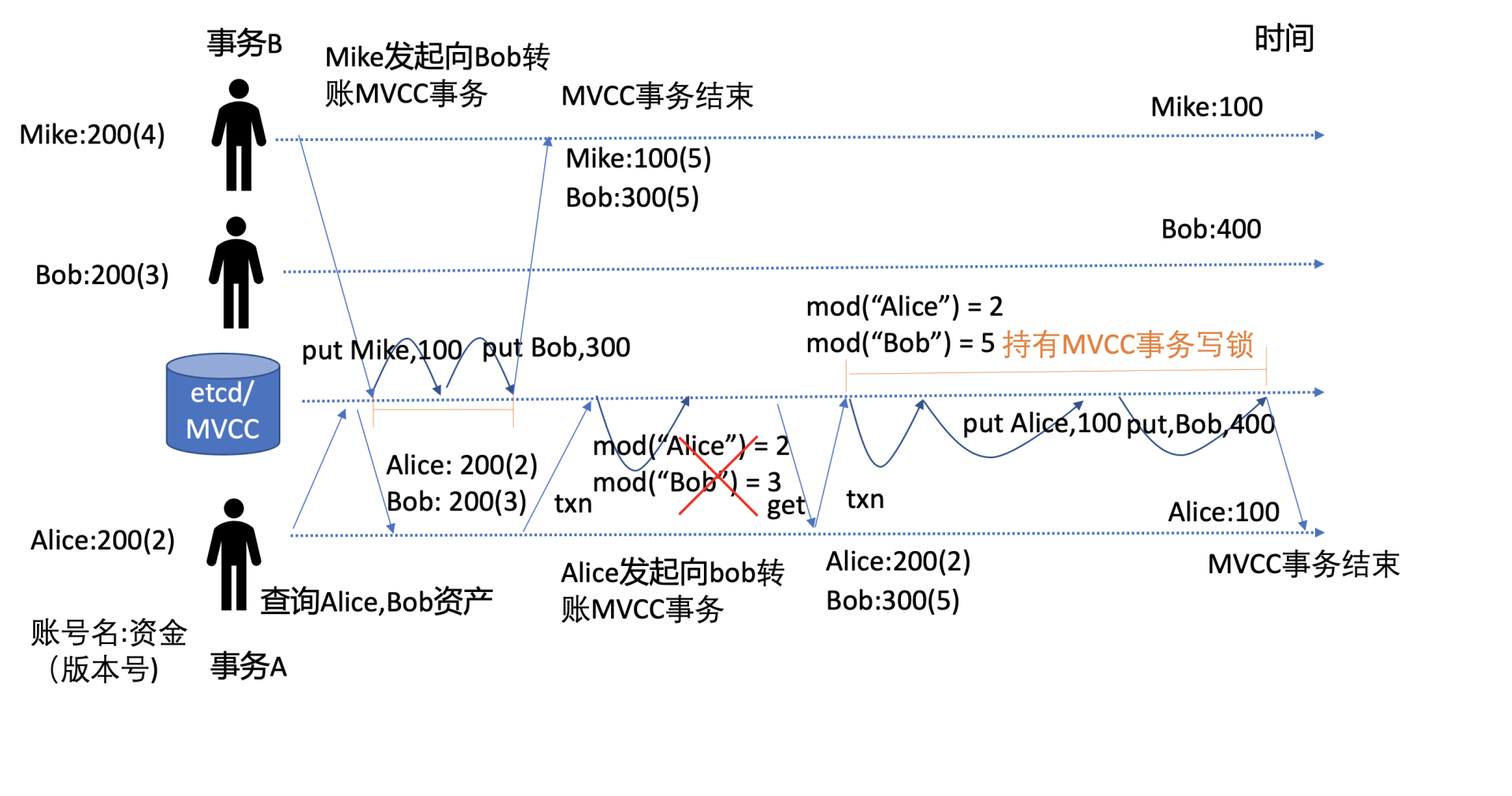
如上图所示,事务A,Alice向Bob转账100元,事务B,Mike向Bob转账100元,两个事务同时发起转账操作。
一开始时,Mike的版本号(指mod_revision)是4,Bob版本号是3,Alice版本号是2,资产各自200。为了防止并发写事务冲突,etcd在一个写事务开始时,会独占一个MVCC读写锁。
事务A会先去etcd查询当前Alice和Bob的资产版本号,用于在事务提交时做冲突检测。在事务A查询后,事务B获得MVCC写锁并完成转账事务,Mike和Bob账号资产分别为100,300,版本号都为5。
事务B完成后,事务A获得写锁,开始执行事务。
为了解决并发事务冲突问题,事务A中增加了冲突检测,期望的Alice版本号应为2,Bob为3。结果事务B的修改导致Bob版本号变成了5,因此此事务会执行失败分支,再次查询Alice和Bob版本号和资产,发起新的转账事务,成功通过MVCC冲突检测规则mod("Alice") = 2 和 mod("Bob") = 5 后,更新Alice账号资产为100,Bob资产为400,完成转账操作。
通过上面介绍的快照读和MVCC冲突检测检测机制,etcd就可实现串行化快照隔离能力。
转账案例应用
介绍完etcd事务ACID特性实现后,你很容易发现事务特性初体验中的案例问题了,它缺少了完整事务的冲突检测机制。
首先你可通过一个事务获取Alice和Bob账号的上资金和版本号,用以判断Alice是否有足够的金额转账给Bob和事务提交时做冲突检测。 你可通过如下etcdctl txn命令,获取Alice和Bob账号的资产和最后一次修改时的版本号(mod_revision):
bash
$ etcdctl txn -i -w=json
compares:
success requests (get, put, del):
get Alice
get Bob
failure requests (get, put, del):
{
"kvs":[
{
"key":"QWxpY2U=",
"create_revision":2,
"mod_revision":2,
"version":1,
"value":"MjAw"
}
],
......
"kvs":[
{
"key":"Qm9i",
"create_revision":3,
"mod_revision":3,
"version":1,
"value":"MzAw"
}
],
}其次发起资金转账操作,Alice账号减去100,Bob账号增加100。为了保证转账事务的准确性、一致性,提交事务的时候需检查Alice和Bob账号最新修改版本号与读取资金时的一致(compares操作中增加版本号检测),以保证其他事务未修改两个账号的资金。
若compares操作通过检查,则执行转账操作,否则执行查询Alice和Bob账号资金操作,命令如下:
bash
$ etcdctl txn -i
compares:
mod("Alice") = "2"
mod("Bob") = "3"
success requests (get, put, del):
put Alice 100
put Bob 300
failure requests (get, put, del):
get Alice
get Bob
SUCCESS
OK
OK到这里我们就完成了一个安全的转账事务操作,从以上流程中你可以发现,自己从0到1实现一个完整的事务还是比较繁琐的,幸运的是,etcd社区基于以上介绍的事务特性,提供了一个简单的事务框架STM,构建了各个事务隔离级别类,帮助你进一步简化应用编程复杂度。
小结
最后我们来小结下今天的内容。首先我给你介绍了事务API的基本结构,它由If、Then、Else语句组成。
其中If支持多个比较规则,它是用于事务提交时的冲突检测,比较的对象支持key的mod_revision 、create_revision、version、value值。随后我给你介绍了整个事务执行的基本流程,Apply模块首先执行If的比较规则,为真则执行Then语句,否则执行Else语句。
接着通过转账案例,四幅转账事务时间序列图,我为你分析了事务的ACID特性,剖析了在etcd中事务的ACID特性的实现。
- 原子性是指一个事务要么全部成功要么全部失败,etcd基于WAL日志、consistent index、boltdb的事务能力提供支持。
- 一致性是指事务转账前后的,数据库和应用程序期望的恒等状态应该保持不变,这通过数据库和业务应用程序相互协作完成。
- 持久性是指事务提交后,数据不丢失,
- 隔离性是指事务提交过程中的可见性,etcd不存在脏读,基于MVCC机制、boltdb事务你可以实现可重复读、串行化快照隔离级别的事务,保障并发事务场景中你的数据安全性。
思考题
在数据库事务中,有各种各样的概念,比如脏读、脏写、不可重复读与读倾斜、幻读与写倾斜、更新丢失、快照隔离、可串行化快照隔离? 你知道它们的含义吗?
10 boltdb:如何持久化存储你的key-value数据?
在前面的课程里,我和你多次提到过etcd数据存储在boltdb。那么boltdb是如何组织你的key-value数据的呢?当你读写一个key时,boltdb是如何工作的?
今天我将通过一个写请求在boltdb中执行的简要流程,分析其背后的boltdb的磁盘文件布局,帮助你了解page、node、bucket等核心数据结构的原理与作用,搞懂boltdb基于B+ tree、各类page实现查找、更新、事务提交的原理,让你明白etcd为什么适合读多写少的场景。
boltdb磁盘布局
在介绍一个put写请求在boltdb中执行原理前,我先给你从整体上介绍下平时你所看到的etcd db文件的磁盘布局,让你了解下db文件的物理存储结构。
boltdb文件指的是你etcd数据目录下的member/snap/db的文件, etcd的key-value、lease、meta、member、cluster、auth等所有数据存储在其中。etcd启动的时候,会通过mmap机制将db文件映射到内存,后续可从内存中快速读取文件中的数据。写请求通过fwrite和fdatasync来写入、持久化数据到磁盘。
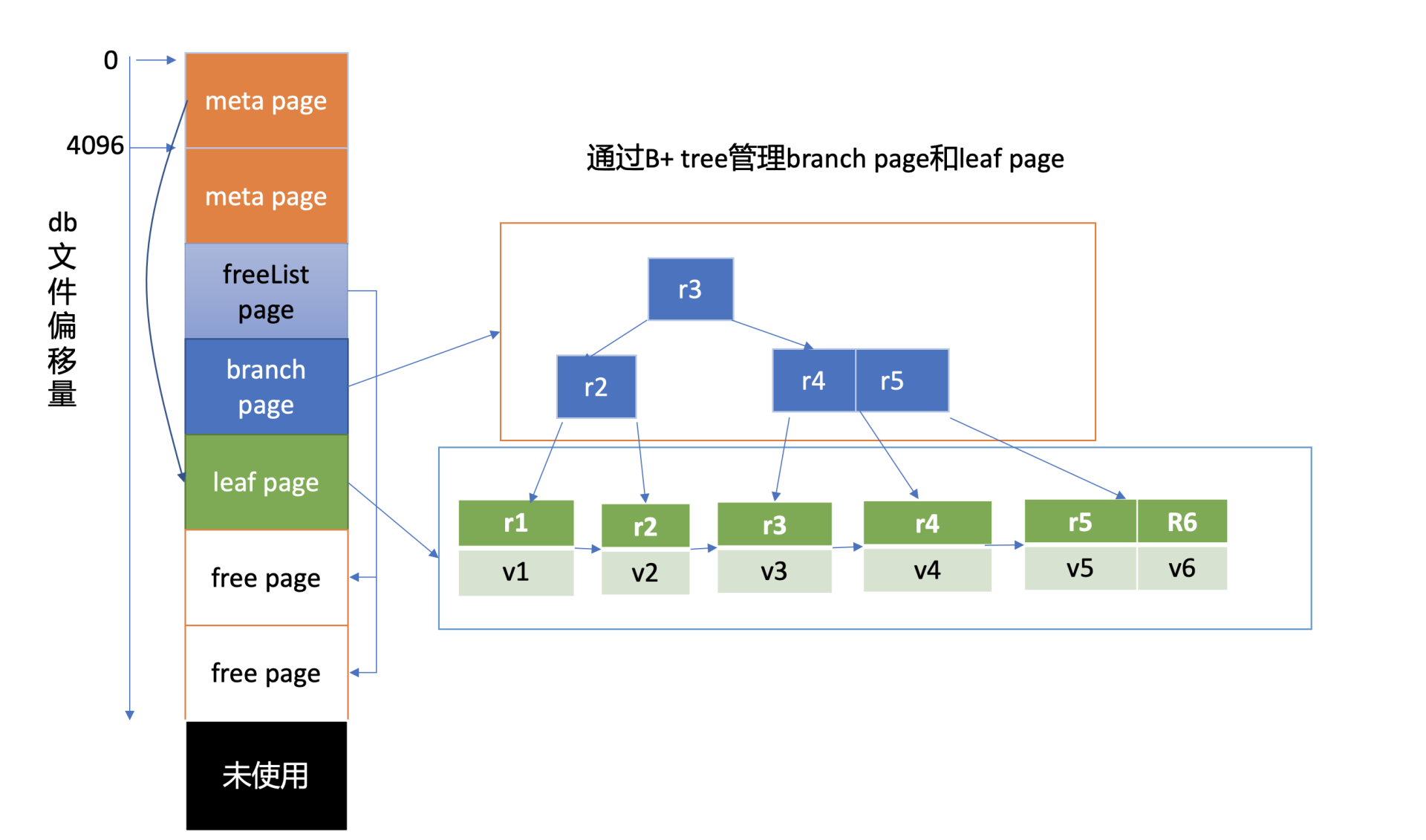
上图是我给你画的db文件磁盘布局,从图中的左边部分你可以看到,文件的内容由若干个page组成,一般情况下page size为4KB。
page按照功能可分为元数据页(meta page)、B+ tree索引节点页(branch page)、B+ tree 叶子节点页(leaf page)、空闲页管理页(freelist page)、空闲页(free page)。
文件最开头的两个page是固定的db元数据meta page,空闲页管理页记录了db中哪些页是空闲、可使用的。索引节点页保存了B+ tree的内部节点,如图中的右边部分所示,它们记录了key值,叶子节点页记录了B+ tree中的key-value和bucket数据。
boltdb逻辑上通过B+ tree来管理branch/leaf page, 实现快速查找、写入key-value数据。
boltdb API
了解完boltdb的磁盘布局后,那么如果要在etcd中执行一个put请求,boltdb中是如何执行的呢? boltdb作为一个库,提供了什么API给client访问写入数据?
boltdb提供了非常简单的API给上层业务使用,当我们执行一个put hello为world命令时,boltdb实际写入的key是版本号,value为mvccpb.KeyValue结构体。
这里我们简化下,假设往key bucket写入一个key为r94,value为world的字符串,其核心代码如下:
go
// 打开boltdb文件,获取db对象
db,err := bolt.Open("db", 0600, nil)
if err != nil {
log.Fatal(err)
}
defer db.Close()
// 参数true表示创建一个写事务,false读事务
tx,err := db.Begin(true)
if err != nil {
return err
}
defer tx.Rollback()
// 使用事务对象创建key bucket
b,err := tx.CreatebucketIfNotExists([]byte("key"))
if err != nil {
return err
}
// 使用bucket对象更新一个key
if err := b.Put([]byte("r94"),[]byte("world")); err != nil {
return err
}
// 提交事务
if err := tx.Commit(); err != nil {
return err
}如上所示,通过boltdb的Open API,我们获取到boltdb的核心对象db实例后,然后通过db的Begin API开启写事务,获得写事务对象tx。
通过写事务对象tx, 你可以创建bucket。这里我们创建了一个名为key的bucket(如果不存在),并使用bucket API往其中更新了一个key为r94,value为world的数据。最后我们使用写事务的Commit接口提交整个事务,完成bucket创建和key-value数据写入。
看起来是不是非常简单,神秘的boltdb,并未有我们想象的那么难。然而其API简单的背后却是boltdb的一系列巧妙的设计和实现。
一个key-value数据如何知道该存储在db在哪个page?如何快速找到你的key-value数据?事务提交的原理又是怎样的呢?
接下来我就和你浅析boltdb背后的奥秘。
核心数据结构介绍
上面我们介绍boltdb的磁盘布局时提到,boltdb整个文件由一个个page组成。最开头的两个page描述db元数据信息,而它正是在client调用boltdb Open API时被填充的。那么描述磁盘页面的page数据结构是怎样的呢?元数据页又含有哪些核心数据结构?
boltdb本身自带了一个工具bbolt,它可以按页打印出db文件的十六进制的内容,下面我们就使用此工具来揭开db文件的神秘面纱。
下图左边的十六进制是执行如下bbolt dump命令,所打印的boltdb第0页的数据,图的右边是对应的page磁盘页结构和meta page的数据结构。
bash
$ ./bbolt dump ./infra1.etcd/member/snap/db 0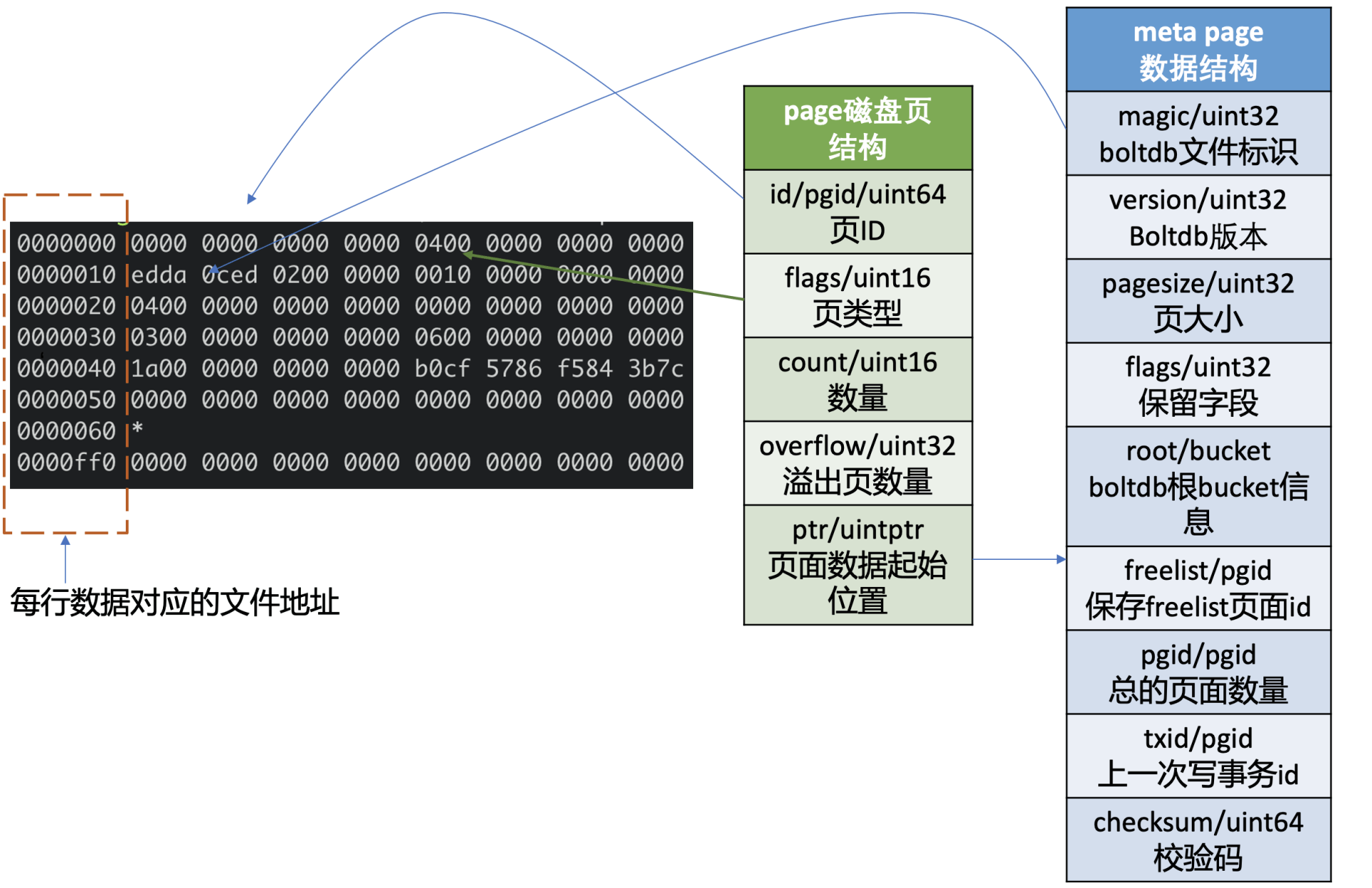
一看上图中的十六进制数据,你可能很懵,没关系,在你了解page磁盘页结构、meta page数据结构后,你就能读懂其含义了。
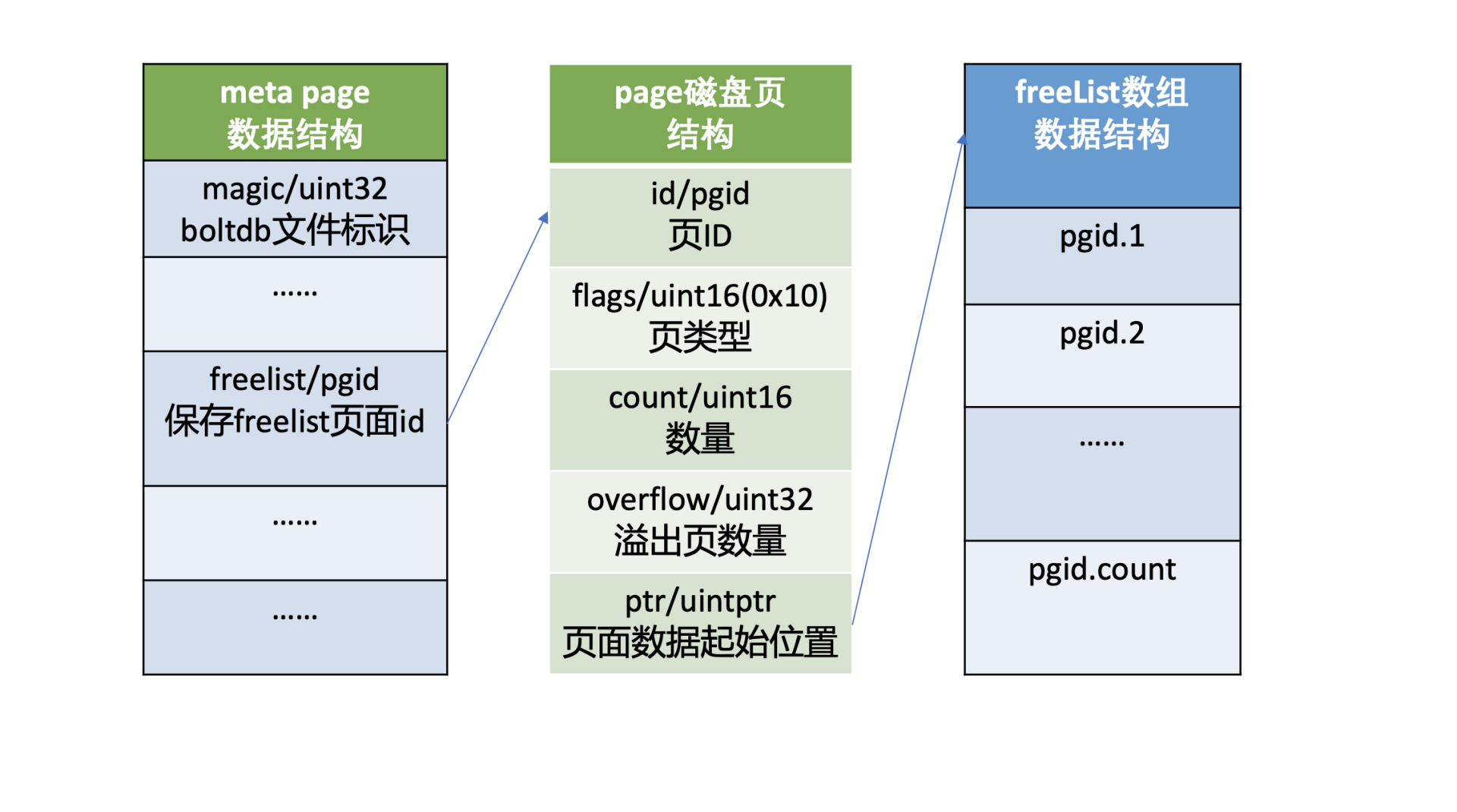
page磁盘页结构
我们先了解下page磁盘页结构,如上图所示,它由页ID(id)、页类型(flags)、数量(count)、溢出页数量(overflow)、页面数据起始位置(ptr)字段组成。
页类型目前有如下四种:0x01表示branch page,0x02表示leaf page,0x04表示meta page,0x10表示freelist page。
数量字段仅在页类型为leaf和branch时生效,溢出页数量是指当前页面数据存放不下,需要向后再申请overflow个连续页面使用,页面数据起始位置指向page的载体数据,比如meta page、branch/leaf等page的内容。
meta page数据结构
第0、1页我们知道它是固定存储db元数据的页(meta page),那么meta page它为了管理整个boltdb含有哪些信息呢?
如上图中的meta page数据结构所示,你可以看到它由boltdb的文件标识(magic)、版本号(version)、页大小(pagesize)、boltdb的根bucket信息(root bucket)、freelist页面ID(freelist)、总的页面数量(pgid)、上一次写事务ID(txid)、校验码(checksum)组成。
meta page十六进制分析
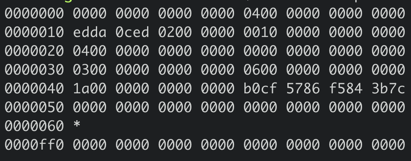
了解完page磁盘页结构和meta page数据结构后,我再结合图左边的十六进数据和你简要分析下其含义。
上图中十六进制输出的是db文件的page 0页结构,左边第一列表示此行十六进制内容对应的文件起始地址,每行16个字节。
结合page磁盘页和meta page数据结构我们可知,第一行前8个字节描述pgid(忽略第一列)是0。接下来2个字节描述的页类型, 其值为0x04表示meta page, 说明此页的数据存储的是meta page内容,因此ptr开始的数据存储的是meta page内容。
正如你下图中所看到的,第二行首先含有一个4字节的magic number(0xED0CDAED),通过它来识别当前文件是否boltdb,接下来是两个字节描述boltdb的版本号0x2, 然后是四个字节的page size大小,0x1000表示4096个字节,四个字节的flags为0。
第三行对应的就是meta page的root bucket结构(16个字节),它描述了boltdb的root bucket信息,比如一个db中有哪些bucket, bucket里面的数据存储在哪里。
第四行中前面的8个字节,0x3表示freelist页面ID,此页面记录了db当前哪些页面是空闲的。后面8个字节,0x6表示当前db总的页面数。
第五行前面的8个字节,0x1a表示上一次的写事务ID,后面的8个字节表示校验码,用于检测文件是否损坏。
了解完db元数据页面原理后,那么boltdb是如何根据元数据页面信息快速找到你的bucket和key-value数据呢?
这就涉及到了元数据页面中的root bucket,它是个至关重要的数据结构。下面我们看看它是如何管理一系列bucket、帮助我们查找、写入key-value数据到boltdb中。
bucket数据结构
如下命令所示,你可以使用bbolt buckets命令,输出一个db文件的bucket列表。执行完此命令后,我们可以看到之前介绍过的auth/lease/meta等熟悉的bucket,它们都是etcd默认创建的。那么boltdb是如何存储、管理bucket的呢?
bash
$ ./bbolt buckets ./infra1.etcd/member/snap/db
alarm
auth
authRoles
authUsers
cluster
key
lease
members
members_removed
meta在上面我们提到过meta page中的,有一个名为root、类型bucket的重要数据结构,如下所示,bucket由root和sequence两个字段组成,root表示该bucket根节点的page id。注意meta page中的bucket.root字段,存储的是db的root bucket页面信息,你所看到的key/lease/auth等bucket都是root bucket的子bucket。
go
type bucket struct {
root pgid // page id of the bucket's root-level page
sequence uint64 // monotonically incrementing, used by NextSequence()
}
上面meta page十六进制图中,第三行的16个字节就是描述的root bucket信息。root bucket指向的page id为4,page id为4的页面是什么类型呢? 我们可以通过如下bbolt pages命令看看各个page类型和元素数量,从下图结果可知,4号页面为leaf page。
bash
$ ./bbolt pages ./infra1.etcd/member/snap/db
ID TYPE ITEMS OVRFLW
======== ========== ====== ======
0 meta 0
1 meta 0
2 free
3 freelist 2
4 leaf 10
5 free通过上面的分析可知,当bucket比较少时,我们子bucket数据可直接从meta page里指向的leaf page中找到。
leaf page
meta page的root bucket直接指向的是page id为4的leaf page, page flag为0x02, leaf page它的磁盘布局如下图所示,前半部分是leafPageElement数组,后半部分是key-value数组。
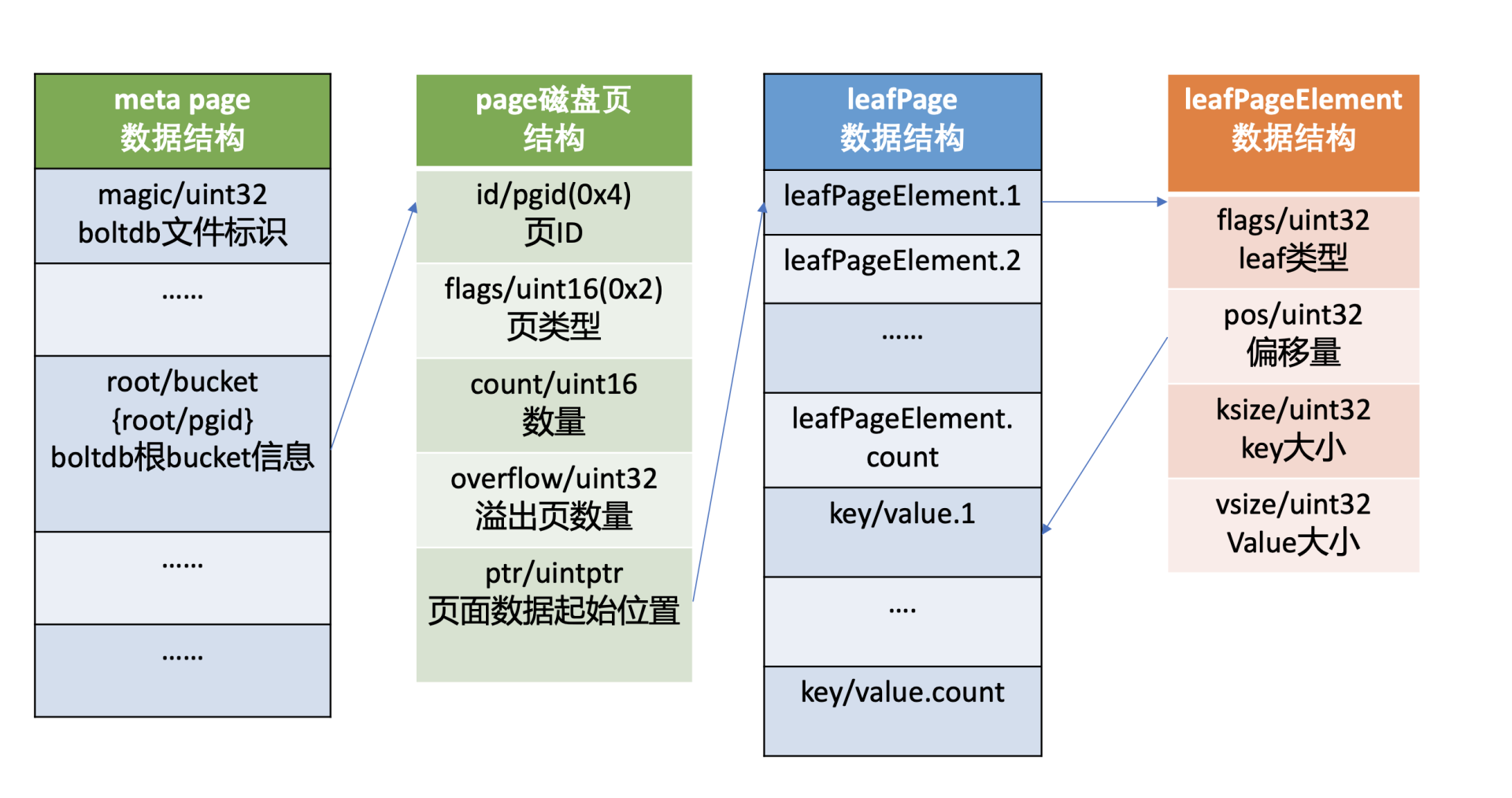
leafPageElement包含leaf page的类型flags, 通过它可以区分存储的是bucket名称还是key-value数据。
当flag为bucketLeafFlag(0x01)时,表示存储的是bucket数据,否则存储的是key-value数据,leafPageElement它还含有key-value的读取偏移量,key-value大小,根据偏移量和key-value大小,我们就可以方便地从leaf page中解析出所有key-value对。
当存储的是bucket数据的时候,key是bucket名称,value则是bucket结构信息。bucket结构信息含有root page信息,通过root page(基于B+ tree查找算法),你可以快速找到你存储在这个bucket下面的key-value数据所在页面。
从上面分析你可以看到,每个子bucket至少需要一个page来存储其下面的key-value数据,如果子bucket数据量很少,就会造成磁盘空间的浪费。实际上boltdb实现了inline bucket,在满足一些条件限制的情况下,可以将小的子bucket内嵌在它的父亲叶子节点上,友好的支持了大量小bucket。
为了方便大家快速理解核心原理,本节我们讨论的bucket是假设都是非inline bucket。
那么boltdb是如何管理大量bucket、key-value的呢?
branch page
boltdb使用了B+ tree来高效管理所有子bucket和key-value数据,因此它可以支持大量的bucket和key-value,只不过B+ tree的根节点不再直接指向leaf page,而是branch page索引节点页。branch page flags为0x01。它的磁盘布局如下图所示,前半部分是branchPageElement数组,后半部分是key数组。
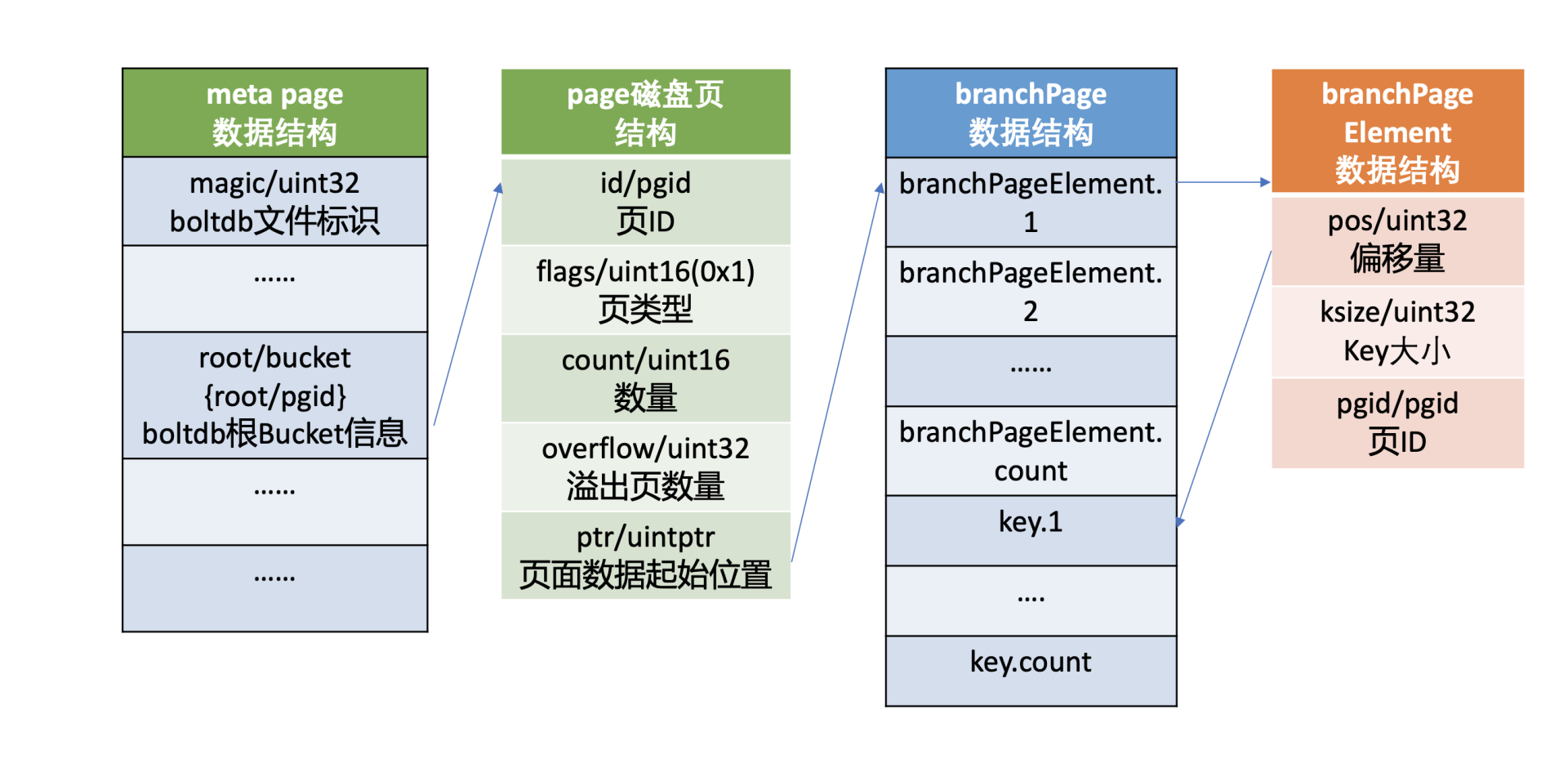
branchPageElement包含key的读取偏移量、key大小、子节点的page id。根据偏移量和key大小,我们就可以方便地从branch page中解析出所有key,然后二分搜索匹配key,获取其子节点page id,递归搜索,直至从bucketLeafFlag类型的leaf page中找到目的bucket name。
注意,boltdb在内存中使用了一个名为node的数据结构,来保存page反序列化的结果。下面我给出了一个boltdb读取page到node的代码片段,你可以直观感受下。
go
func (n *node) read(p *page) {
n.pgid = p.id
n.isLeaf = ((p.flags & leafPageFlag) != 0)
n.inodes = make(inodes, int(p.count))
for i := 0; i < int(p.count); i++ {
inode := &n.inodes[i]
if n.isLeaf {
elem := p.leafPageElement(uint16(i))
inode.flags = elem.flags
inode.key = elem.key()
inode.value = elem.value()
} else {
elem := p.branchPageElement(uint16(i))
inode.pgid = elem.pgid
inode.key = elem.key()
}
}从上面分析过程中你会发现,boltdb存储bucket和key-value原理是类似的,将page划分成branch page、leaf page,通过B+ tree来管理实现。boltdb为了区分leaf page存储的数据类型是bucket还是key-value,增加了标识字段(leafPageElement.flags),因此key-value的数据存储过程我就不再重复分析了。
freelist
介绍完bucket、key-value存储原理后,我们再看meta page中的另外一个核心字段freelist,它的作用是什么呢?
我们知道boltdb将db划分成若干个page,那么它是如何知道哪些page在使用中,哪些page未使用呢?
答案是boltdb通过meta page中的freelist来管理页面的分配,freelist page中记录了哪些页是空闲的。当你在boltdb中删除大量数据的时候,其对应的page就会被释放,页ID存储到freelist所指向的空闲页中。当你写入数据的时候,就可直接从空闲页中申请页面使用。
下面meta page十六进制图中,第四行的前8个字节就是描述的freelist信息,page id为3。我们可以通过bbolt page命令查看3号page内容,如下所示,它记录了2和5为空闲页,与我们上面通过bbolt pages命令所看到的信息一致。
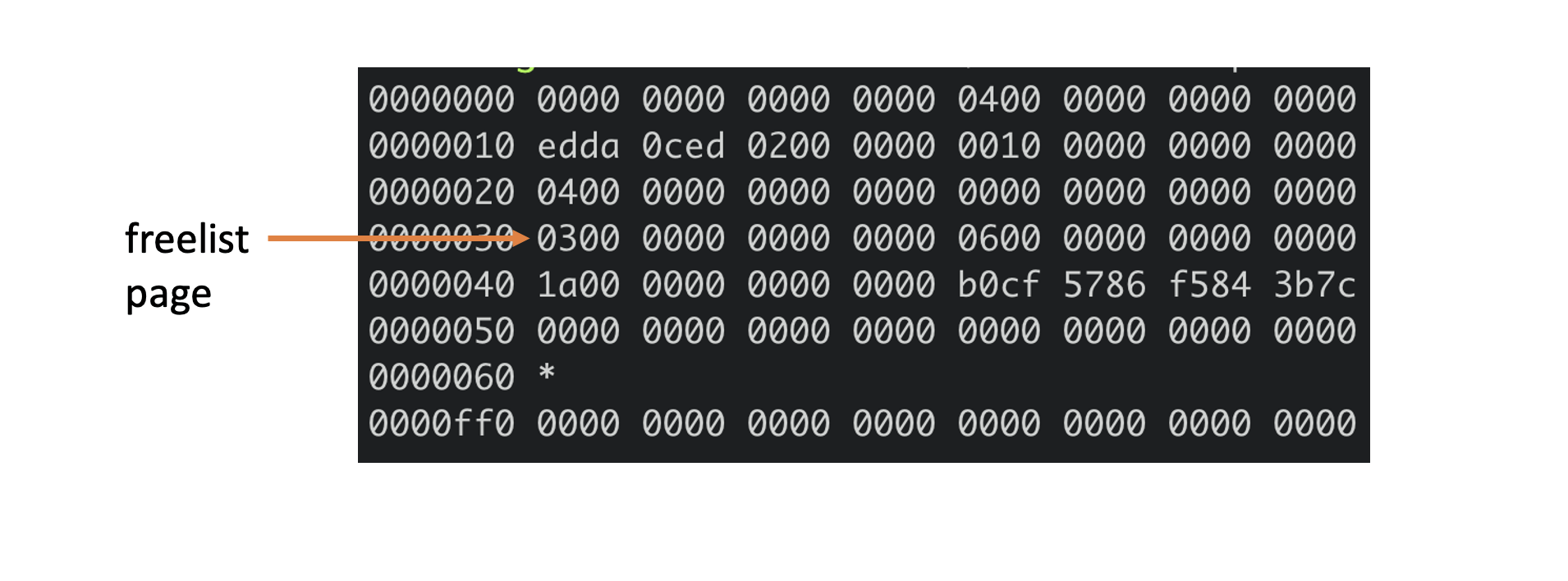
bash
$ ./bbolt page ./infra1.etcd/member/snap/db 3
page ID: 3
page Type: freelist
Total Size: 4096 bytes
Item Count: 2
Overflow: 0
2
5下图是freelist page存储结构,pageflags为0x10,表示freelist类型的页,ptr指向空闲页id数组。注意在boltdb中支持通过多种数据结构(数组和hashmap)来管理free page,这里我介绍的是数组。
Open原理
了解完核心数据结构后,我们就很容易搞懂boltdb Open API的原理了。
首先它会打开db文件并对其增加文件锁,目的是防止其他进程也以读写模式打开它后,操作meta和free page,导致db文件损坏。
其次boltdb通过mmap机制将db文件映射到内存中,并读取两个meta page到db对象实例中,然后校验meta page的magic、version、checksum是否有效,若两个meta page都无效,那么db文件就出现了严重损坏,导致异常退出。
Put原理
那么成功获取db对象实例后,通过bucket API创建一个bucket、发起一个Put请求更新数据时,boltdb是如何工作的呢?
根据我们上面介绍的bucket的核心原理,它首先是根据meta page中记录root bucket的root page,按照B+ tree的查找算法,从root page递归搜索到对应的叶子节点page面,返回key名称、leaf类型。
如果leaf类型为bucketLeafFlag,且key相等,那么说明已经创建过,不允许bucket重复创建,结束请求。否则往B+ tree中添加一个flag为bucketLeafFlag的key,key名称为bucket name,value为bucket的结构。
创建完bucket后,你就可以通过bucket的Put API发起一个Put请求更新数据。它的核心原理跟bucket类似,根据子bucket的root page,从root page递归搜索此key到leaf page,如果没有找到,则在返回的位置处插入新key和value。
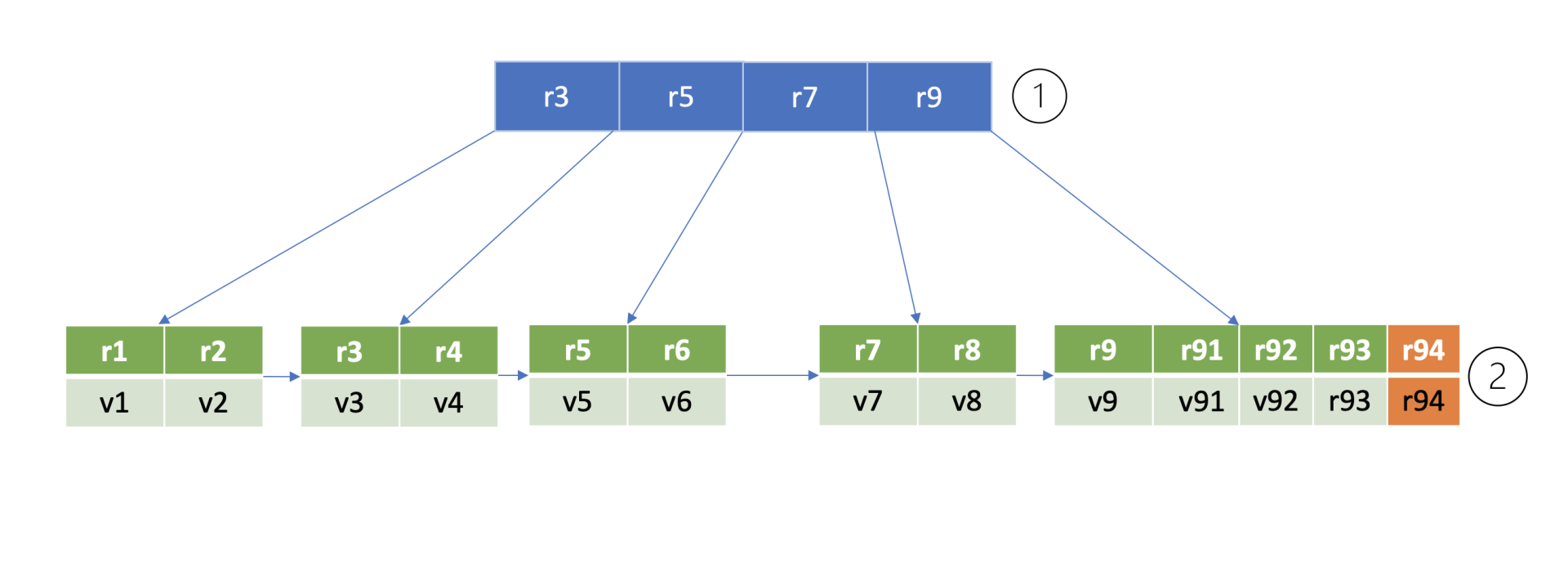
为了方便你理解B+ tree查找、插入一个key原理,我给你构造了的一个max degree为5的B+ tree,下图是key r94的查找流程图。
那么如何确定这个key的插入位置呢?
首先从boltdb的key bucket的root page里,二分查找大于等于r94的key所在page,最终找到key r9指向的page(流程1)。r9指向的page是个leaf page,B+ tree需要确保叶子节点key的有序性,因此同样二分查找其插入位置,将key r94插入到相关位置(流程二)。
在核心数据结构介绍中,我和你提到boltdb在内存中通过node数据结构来存储page磁盘页内容,它记录了key-value数据、page id、parent及children的node、B+ tree是否需要进行重平衡和分裂操作等信息。
因此,当我们执行完一个put请求时,它只是将值更新到boltdb的内存node数据结构里,并未持久化到磁盘中。
事务提交原理
那么boltdb何时将数据持久化到db文件中呢?
当你的代码执行tx.Commit API时,它才会将我们上面保存到node内存数据结构中的数据,持久化到boltdb中。下图我给出了一个事务提交的流程图,接下来我就分别和你简要分析下各个核心步骤。
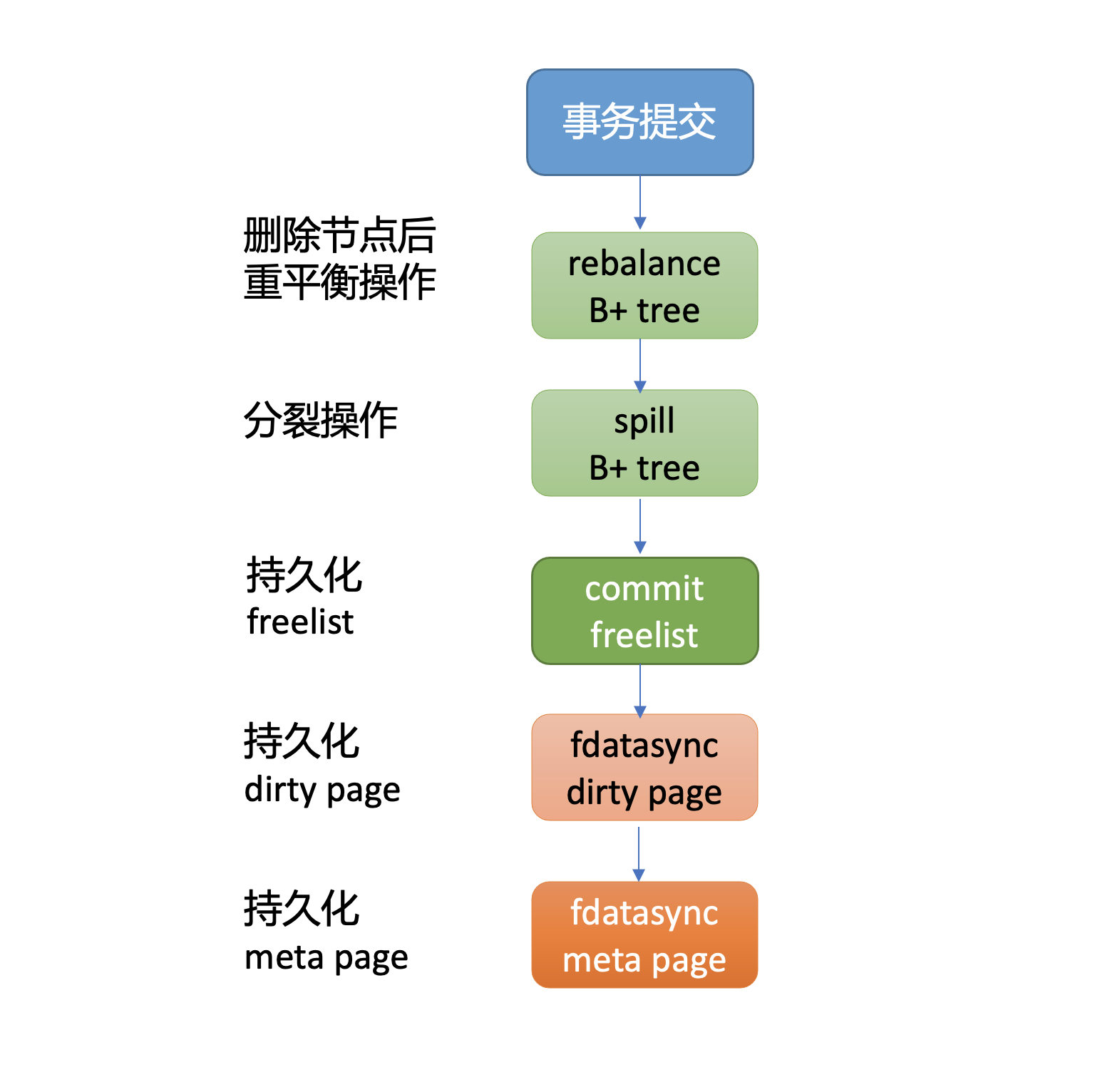
首先从上面put案例中我们可以看到,插入了一个新的元素在B+ tree的叶子节点,它可能已不满足B+ tree的特性,因此事务提交时,第一步首先要调整B+ tree,进行重平衡、分裂操作,使其满足B+ tree树的特性。上面案例里插入一个key r94后,经过重平衡、分裂操作后的B+ tree如下图所示。
在重平衡、分裂过程中可能会申请、释放free page,freelist所管理的free page也发生了变化。因此事务提交的第二步,就是持久化freelist。
注意,在etcd v3.4.9中,为了优化写性能等,freelist持久化功能是关闭的。etcd启动获取boltdb db对象的时候,boltdb会遍历所有page,构建空闲页列表。
事务提交的第三步就是将client更新操作产生的dirty page通过fdatasync系统调用,持久化存储到磁盘中。
最后,在执行写事务过程中,meta page的txid、freelist等字段会发生变化,因此事务的最后一步就是持久化meta page。
通过以上四大步骤,我们就完成了事务提交的工作,成功将数据持久化到了磁盘文件中,安全地完成了一个put操作。
小结
最后我们来小结下今天的内容。首先我通过一幅boltdb磁盘布局图和bbolt工具,为你解密了db文件的本质。db文件由meta page、freelist page、branch page、leaf page、free page组成。随后我结合bbolt工具,和你深入介绍了meta page、branch page、leaf page、freelist page的数据结构,帮助你了解key、value数据是如何存储到文件中的。
然后我通过分析一个put请求在boltdb中如何执行的。我从Open API获取db对象说起,介绍了其通过mmap将db文件映射到内存,构建meta page,校验meta page的有效性,再到创建bucket,通过bucket API往boltdb添加key-value数据。
添加bucket和key-value操作本质,是从B+ tree管理的page中找到插入的页和位置,并将数据更新到page的内存node数据结构中。
真正持久化数据到磁盘是通过事务提交执行的。它首先需要通过一系列重平衡、分裂操作,确保boltdb维护的B+ tree满足相关特性,其次需要持久化freelist page,并将用户更新操作产生的dirty page数据持久化到磁盘中,最后则是持久化meta page。
思考题
事务提交过程中若持久化key-value数据到磁盘成功了,此时突然掉电,元数据还未持久化到磁盘,那么db文件会损坏吗?数据会丢失吗? 为什么boltdb有两个meta page呢?
11 压缩:如何回收旧版本数据?
这节课是我们基础篇里的最后一节,正巧这节课的内容也是最轻松的。新年新气象,我们就带着轻松的心情开始吧!
在07里,我们知道etcd中的每一次更新、删除key操作,treeIndex的keyIndex索引中都会追加一个版本号,在boltdb中会生成一个新版本boltdb key和value。也就是随着你不停更新、删除,你的etcd进程内存占用和db文件就会越来越大。很显然,这会导致etcd OOM和db大小增长到最大db配额,最终不可写。
那么etcd是通过什么机制来回收历史版本数据,控制索引内存占用和db大小的呢?
这就是我今天要和你分享的etcd压缩机制。希望通过今天的这节课,能帮助你理解etcd压缩原理,在使用etcd过程中能根据自己的业务场景,选择适合的压缩策略,避免db大小增长失控而不可写入,帮助你构建稳定的etcd服务。
整体架构
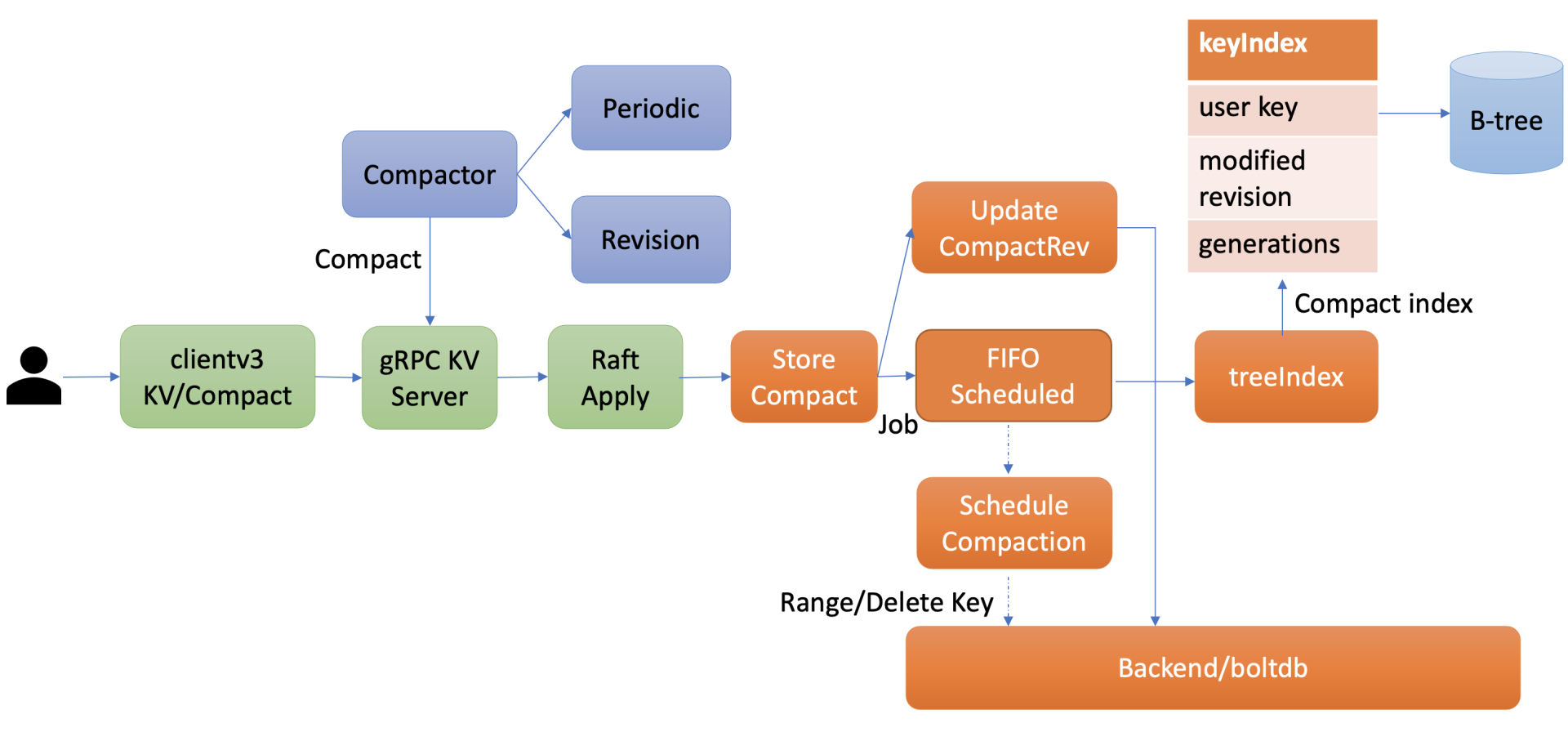
在了解etcd压缩模块实现细节前,我先给你画了一幅压缩模块的整体架构图。从图中可知,你可以通过client API发起人工的压缩(Compact)操作,也可以配置自动压缩策略。在自动压缩策略中,你可以根据你的业务场景选择合适的压缩模式。目前etcd支持两种压缩模式,分别是时间周期性压缩和版本号压缩。
当你通过API发起一个Compact请求后,KV Server收到Compact请求提交到Raft模块处理,在Raft模块中提交后,Apply模块就会通过MVCC模块的Compact接口执行此压缩任务。
Compact接口首先会更新当前server已压缩的版本号,并将耗时昂贵的压缩任务保存到FIFO队列中异步执行。压缩任务执行时,它首先会压缩treeIndex模块中的keyIndex索引,其次会遍历boltdb中的key,删除已废弃的key。
以上就是压缩模块的一个工作流程。接下来我会首先和你介绍如何人工发起一个Compact操作,然后详细介绍周期性压缩模式、版本号压缩模式的工作原理,最后再给你介绍Compact操作核心的原理。
压缩特性初体验
在使用etcd过程中,当你遇到"etcdserver: mvcc: database space exceeded"错误时,若是你未开启压缩策略导致db大小达到配额,这时你可以使用etcdctl compact命令,主动触发压缩操作,回收历史版本。
如下所示,你可以先通过endpoint status命令获取etcd当前版本号,然后再通过etcdctl compact命令发起压缩操作即可。
bash
# 获取etcd当前版本号
$ rev=$(etcdctl endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9].*')
$ echo $rev
9
# 执行压缩操作,指定压缩的版本号为当前版本号
$ etcdctl compact $rev
Compacted revision 9
# 压缩一个已经压缩的版本号
$ etcdctl compact $rev
Error: etcdserver: mvcc: required revision has been compacted
# 压缩一个比当前最大版号大的版本号
$ etcdctl compact 12
Error: etcdserver: mvcc: required revision is a future revision请注意,如果你压缩命令传递的版本号小于等于当前etcd server记录的压缩版本号,etcd server会返回已压缩错误("mvcc: required revision has been compacted")给client。如果版本号大于当前etcd server最新的版本号,etcd server则返回一个未来的版本号错误给client("mvcc: required revision is a future revision")。
执行压缩命令的时候,不少初学者有一个常见的误区,就是担心压缩会不会把我最新版本数据给删除?
压缩的本质是回收历史版本 ,目标对象仅是历史版本 ,不包括一个key-value数据的最新版本,因此你可以放心执行压缩命令,不会删除你的最新版本数据。不过我在08介绍Watch机制时提到,Watch特性中的历史版本数据同步,依赖于MVCC中是否还保存了相关数据,因此我建议你不要每次简单粗暴地回收所有历史版本。
在生产环境中,我建议你精细化的控制历史版本数,那如何实现精细化控制呢?
主要有两种方案,一种是使用etcd server的自带的自动压缩机制,根据你的业务场景,配置合适的压缩策略即可。
另外一种方案是如果你觉得etcd server的自带压缩机制无法满足你的诉求,想更精细化的控制etcd保留的历史版本记录,你就可以基于etcd的Compact API,在业务逻辑代码中、或定时任务中主动触发压缩操作。你需要确保发起Compact操作的程序高可用,压缩的频率、保留的历史版本在合理范围内,并最终能使etcd的db 大小保持平稳,否则会导致db大小不断增长,直至db配额满,无法写入。
在一般情况下,我建议使用etcd自带的压缩机制。它支持两种模式,分别是按时间周期性压缩和保留版本号的压缩,配置相应策略后,etcd节点会自动化的发起Compact操作。
接下来我就和你详细介绍下etcd的周期性和保留版本号压缩模式。
周期性压缩
首先是周期性压缩模式,它适用于什么场景呢?
当你希望etcd只保留最近一段时间写入的历史版本时,你就可以选择配置etcd的压缩模式为periodic,保留时间为你自定义的1h等。
如何给etcd server配置压缩模式和保留时间呢?
如下所示,etcd server提供了配置压缩模式和保留时间的参数:
--auto-compaction-retention '0'
Auto compaction retention length. 0 means disable auto Compaction.
--auto-compaction-mode 'periodic'
Interpret 'auto-Compaction-retention' one of: periodic|revision.auto-compaction-mode为periodic时,它表示启用时间周期性压缩,auto-compaction-retention为保留的时间的周期,比如1h。
auto-compaction-mode为revision时,它表示启用版本号压缩模式,auto-compaction-retention为保留的历史版本号数,比如10000。
注意,etcd server的auto-compaction-retention为'0'时,将关闭自动压缩策略,
那么周期性压缩模式的原理是怎样的呢? etcd是如何知道你配置的1h前的etcd server版本号呢?
其实非常简单,etcd server启动后,根据你的配置的模式periodic,会创建periodic Compactor,它会异步的获取、记录过去一段时间的版本号。periodic Compactor组件获取你设置的压缩间隔参数1h, 并将其划分成10个区间,也就是每个区间6分钟。每隔6分钟,它会通过etcd MVCC模块的接口获取当前的server版本号,追加到rev数组中。
因为你只需要保留过去1个小时的历史版本,periodic Compactor组件会通过当前时间减去上一次成功执行Compact操作的时间,如果间隔大于一个小时,它会取出rev数组的首元素,通过etcd server的Compact接口,发起压缩操作。
需要注意的一点是,在etcd v3.3.3版本之前,不同的etcd版本对周期性压缩的行为是有一定差异的,具体的区别你可以参考下官方文档。
版本号压缩
了解完周期性压缩模式,我们再看看版本号压缩模式,它又适用于什么场景呢?
当你写请求比较多,可能产生比较多的历史版本导致db增长时,或者不确定配置periodic周期为多少才是最佳的时候,你可以通过设置压缩模式为revision,指定保留的历史版本号数。比如你希望etcd尽量只保存1万个历史版本,那么你可以指定compaction-mode为revision,auto-compaction-retention为10000。
它的实现原理又是怎样的呢?
也很简单,etcd启动后会根据你的压缩模式revision,创建revision Compactor。revision Compactor会根据你设置的保留版本号数,每隔5分钟定时获取当前server的最大版本号,减去你想保留的历史版本数,然后通过etcd server的Compact接口发起如下的压缩操作即可。
# 获取当前版本号,减去保留的版本号数
rev := rc.rg.Rev() - rc.retention
# 调用server的Compact接口压缩
_,err := rc.c.Compact(rc.ctx,&pb.CompactionRequest{Revision: rev})压缩原理
介绍完两种自动化的压缩模式原理后,接下来我们就深入分析下压缩的本质。当etcd server收到Compact请求后,它是如何执行的呢? 核心原理是什么?
如前面的整体架构图所述,Compact请求经过Raft日志同步给多数节点后,etcd会从Raft日志取出Compact请求,应用此请求到状态机执行。
执行流程如下图所示,MVCC模块的Compact接口首先会检查Compact请求的版本号rev是否已被压缩过,若是则返回ErrCompacted错误给client。其次会检查rev是否大于当前etcd server的最大版本号,若是则返回ErrFutureRev给client,这就是我们上面执行etcdctl compact命令所看到的那两个错误原理。
通过检查后,Compact接口会通过boltdb的API在meta bucket中更新当前已调度的压缩版本号(scheduledCompactedRev)号,然后将压缩任务追加到FIFO Scheduled中,异步调度执行。
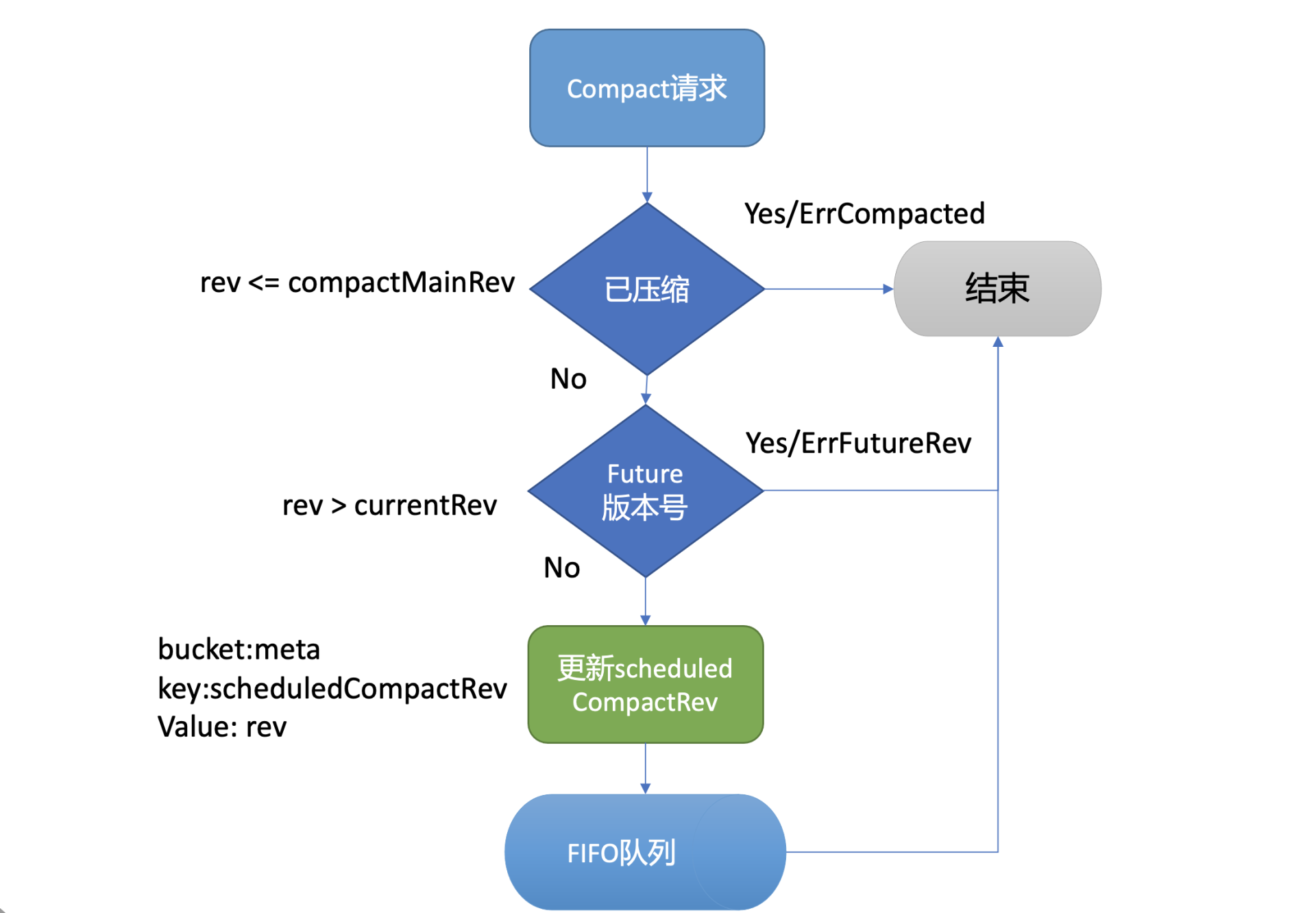
为什么Compact接口需要持久化存储当前已调度的压缩版本号到boltdb中呢?
试想下如果不保存这个版本号,etcd在异步执行的Compact任务过程中crash了,那么异常节点重启后,各个节点数据就会不一致。
因此etcd通过持久化存储scheduledCompactedRev,节点crash重启后,会重新向FIFO Scheduled中添加压缩任务,已保证各个节点间的数据一致性。
异步的执行压缩任务会做哪些工作呢?
首先我们回顾下07里介绍的treeIndex索引模块,它是etcd支持保存历史版本的核心模块,每个key在treeIndex模块中都有一个keyIndex数据结构,记录其历史版本号信息。
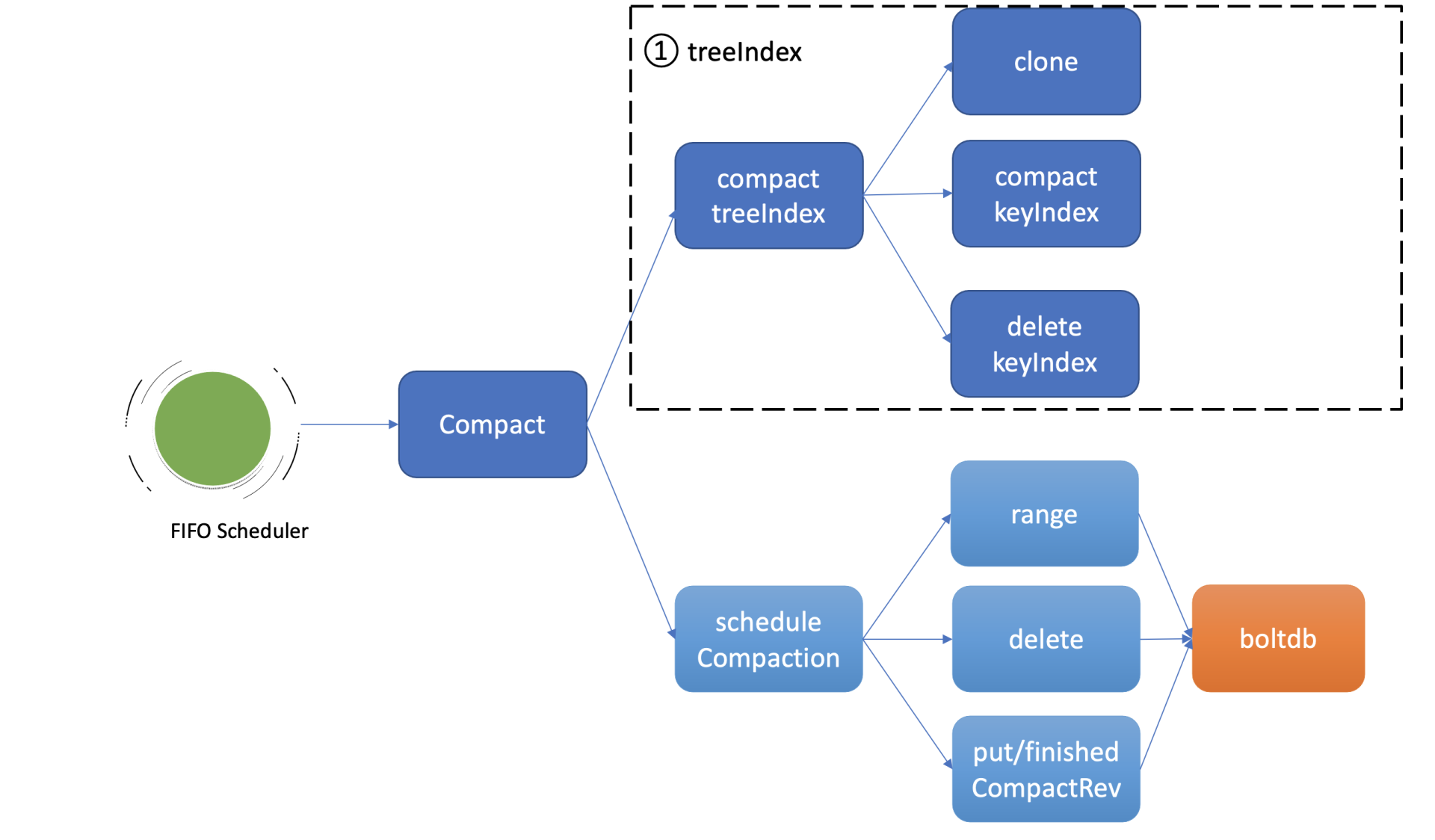
如上图所示,因此异步压缩任务的第一项工作,就是压缩treeIndex模块中的各key的历史版本、已删除的版本。为了避免压缩工作影响读写性能,首先会克隆一个B-tree,然后通过克隆后的B-tree遍历每一个keyIndex对象,压缩历史版本号、清理已删除的版本。
假设当前压缩的版本号是CompactedRev, 它会保留keyIndex中最大的版本号,移除小于等于CompactedRev的版本号,并通过一个map记录treeIndex中有效的版本号返回给boltdb模块使用。
为什么要保留最大版本号呢?
因为最大版本号是这个key的最新版本,移除了会导致key丢失。而Compact的目的是回收旧版本。当然如果keyIndex中的最大版本号被打了删除标记(tombstone), 就会从treeIndex中删除这个keyIndex,否则会出现内存泄露。
Compact任务执行完索引压缩后,它通过遍历B-tree、keyIndex中的所有generation获得当前内存索引模块中有效的版本号,这些信息将帮助etcd清理boltdb中的废弃历史版本。
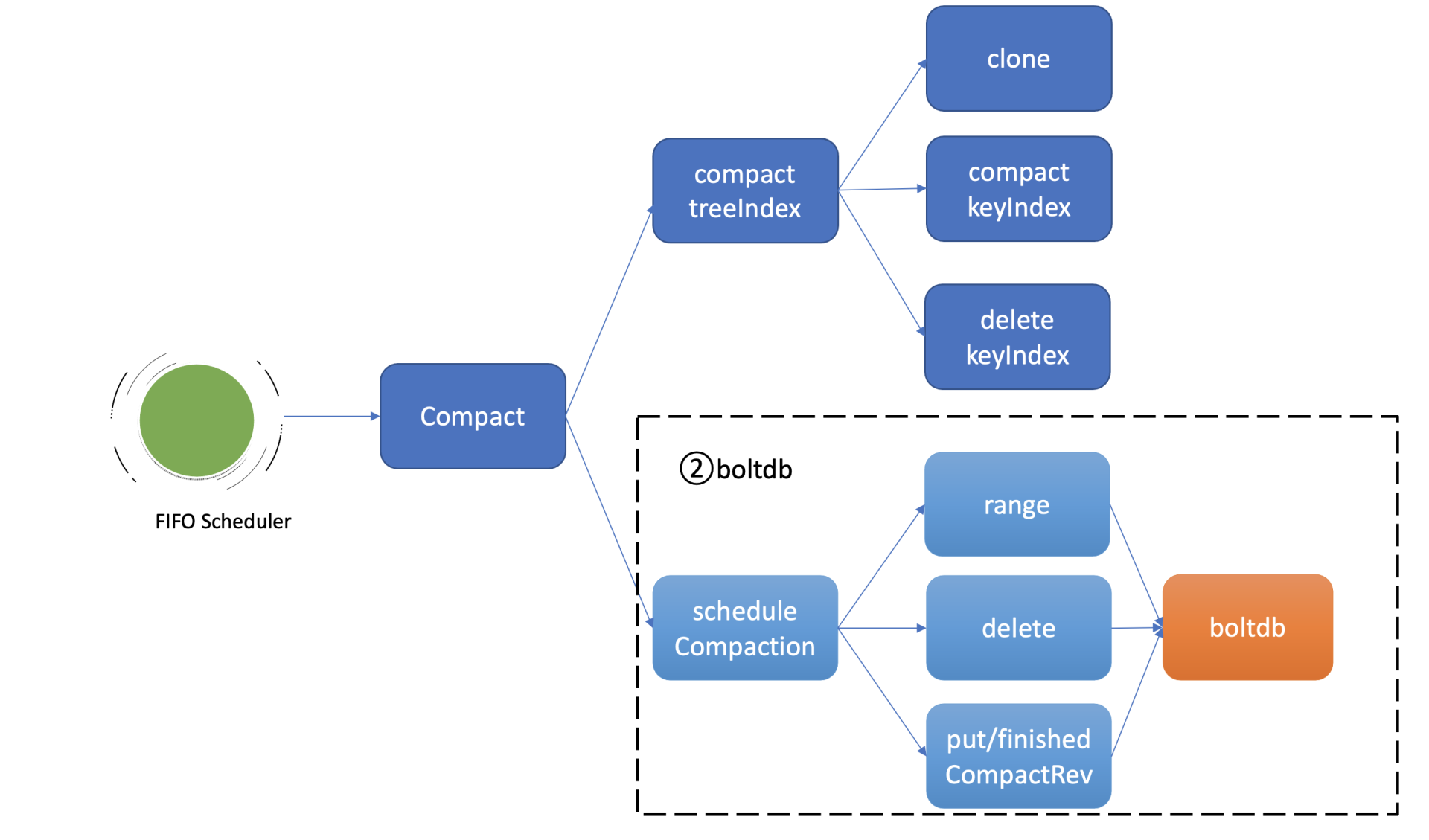
压缩任务的第二项工作就是删除boltdb中废弃的历史版本数据。如上图所示,它通过etcd一个名为scheduleCompaction任务来完成。
scheduleCompaction任务会根据key区间,从0到CompactedRev遍历boltdb中的所有key,通过treeIndex模块返回的有效索引信息,判断这个key是否有效,无效则调用boltdb的delete接口将key-value数据删除。
在这过程中,scheduleCompaction任务还会更新当前etcd已经完成的压缩版本号(finishedCompactRev),将其保存到boltdb的meta bucket中。
scheduleCompaction任务遍历、删除key的过程可能会对boltdb造成压力,为了不影响正常读写请求,它在执行过程中会通过参数控制每次遍历、删除的key数(默认为100,每批间隔10ms),分批完成boltdb key的删除操作。
为什么压缩后db大小不减少呢?
当你执行完压缩任务后,db大小减少了吗? 事实是并没有减少。那为什么我们都通过boltdb API删除了key,db大小还不减少呢?
上节课我们介绍boltdb实现时,提到过boltdb将db文件划分成若干个page页,page页又有四种类型,分别是meta page、branch page、leaf page以及freelist page。branch page保存B+ tree的非叶子节点key数据,leaf page保存bucket和key-value数据,freelist会记录哪些页是空闲的。
当我们通过boltdb删除大量的key,在事务提交后B+ tree经过分裂、平衡,会释放出若干branch/leaf page页面,然而boltdb并不会将其释放给磁盘,调整db大小操作是昂贵的,会对性能有较大的损害。
boltdb是通过freelist page记录这些空闲页的分布位置,当收到新的写请求时,优先从空闲页数组中申请若干连续页使用,实现高性能的读写(而不是直接扩大db大小)。当连续空闲页申请无法得到满足的时候, boltdb才会通过增大db大小来补充空闲页。
一般情况下,压缩操作释放的空闲页就能满足后续新增写请求的空闲页需求,db大小会趋于整体稳定。
小结
最后我们来小结下今天的内容。
etcd压缩操作可通过API人工触发,也可以配置压缩模式由etcd server自动触发。压缩模式支持按周期和版本两种。在周期模式中你可以实现保留最近一段时间的历史版本数,在版本模式中你可以实现保留期望的历史版本数。
压缩的核心工作原理分为两大任务,第一个任务是压缩treeIndex中的各key历史索引,清理已删除key,并将有效的版本号保存到map数据结构中。
第二个任务是删除boltdb中的无效key。基本原理是根据版本号遍历boltdb已压缩区间范围的key,通过treeIndex返回的有效索引map数据结构判断key是否有效,无效则通过boltdb API删除它。
最后在执行压缩的操作中,虽然我们删除了boltdb db的key-value数据,但是db大小并不会减少。db大小不变的原因是存放key-value数据的branch和leaf页,它们释放后变成了空闲页,并不会将空间释放给磁盘。
boltdb通过freelist page来管理一系列空闲页,后续新增的写请求优先从freelist中申请空闲页使用,以提高性能。在写请求速率稳定、新增key-value较少的情况下,压缩操作释放的空闲页就可以基本满足后续写请求对空闲页的需求,db大小就会处于一个基本稳定、健康的状态。
思考题
你知道压缩与碎片整理(defrag)有哪些区别吗?为什么碎片整理会影响服务性能呢? 你能想到哪些优化方案来降低碎片整理对服务性能的影响呢?