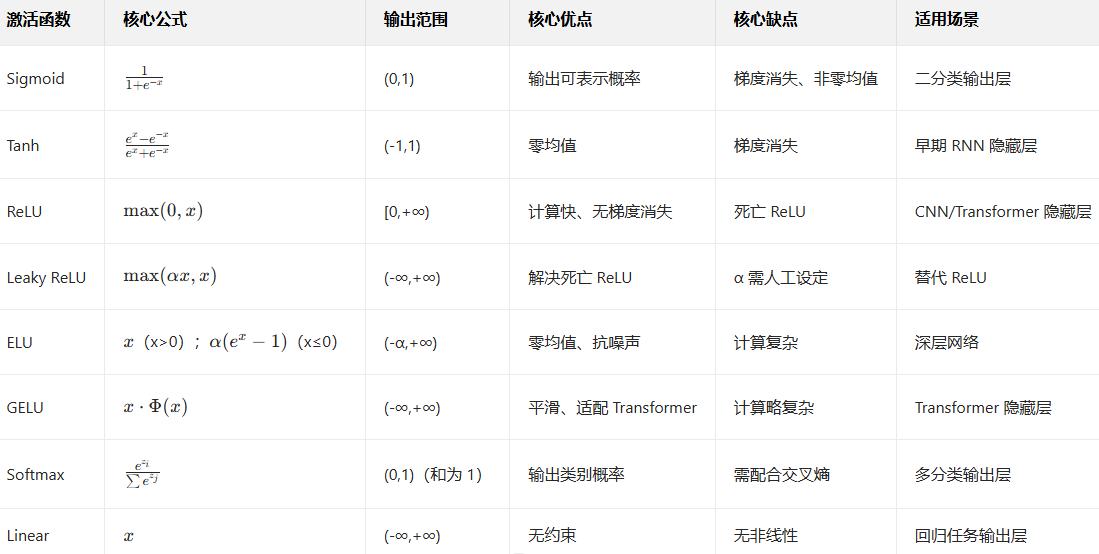
激活函数是神经网络的核心组件,负责为模型引入非线性能力,使其能够拟合复杂的数据分布(若没有激活函数,多层神经网络会退化为单层线性模型)。以下是深度学习中最常用的激活函数及其核心公式、特性与适用场景,按功能分类整理:
一、饱和激活函数(传统经典型)
"饱和" 指函数输出会趋近于固定值(如 0 或 1),早期神经网络中广泛使用,但因梯度消失问题逐渐被非饱和函数替代。
1. Sigmoid 函数
- 核心公式 :
- 输出范围:(0, 1)
- 特性 :
- 将任意输入映射到 (0,1) 区间,可模拟 "概率"(如二分类任务的输出层);
- 缺点 :输入绝对值较大时
,导数趋近于 0,导致梯度消失;输出非零均值(均值约 0.5),会导致后续层输入偏移,影响训练效率。
- 适用场景:二分类任务的输出层(配合交叉熵损失)。
2. Tanh 函数(双曲正切函数)
- 核心公式 :
- 输出范围:(-1, 1)
- 特性 :
- 是 Sigmoid 的 "零中心化" 版本(输出均值接近 0),解决了 Sigmoid 的输入偏移问题;
- 缺点 :仍存在梯度消失 问题
- 适用场景:早期 RNN(如 LSTM)的隐藏层,或对输出范围有对称需求的场景。
二、非饱和激活函数(现代主流型)
"非饱和" 指函数在正区间(或部分区间)导数恒定(如 1),从根本上缓解了梯度消失问题,是当前 CNN、Transformer 等模型的首选。
1. ReLU 函数(Rectified Linear Unit,修正线性单元)
- 核心公式 :
- 输出范围 :
- 特性 :
- 优点:计算极快(仅需判断正负);x > 0 时导数为 1,完全避免梯度消失;稀疏激活 ( x < 0 时输出为 0,减少神经元冗余);
- 缺点 :存在死亡 ReLU 问题(若训练中某神经元输入长期为负,其权重会永久冻结,无法更新)。
- 适用场景:CNN、Transformer 的隐藏层(当前最广泛使用的激活函数)。
2. Leaky ReLU 函数(带泄漏的 ReLU)
- 核心公式 :
- 其中
- 输出范围 :
- 特性 :
- 解决了 "死亡 ReLU 问题"(x < 0时仍有微小梯度
- 缺点 :
- 解决了 "死亡 ReLU 问题"(x < 0时仍有微小梯度
- 适用场景:替代 ReLU,尤其适用于可能出现大量负输入的网络(如深层 CNN)。
3. ELU 函数(Exponential Linear Unit,指数线性单元)
- 核心公式 :
- 其中
- 输出范围 :
- 特性 :
- 兼具 Leaky ReLU 的优点(x < 0 时非零输出,避免死亡神经元);
- 输出更接近零均值(
- 缺点:计算复杂度高于 ReLU(需计算指数),训练速度略慢。
- 适用场景:对训练稳定性要求高的深层网络。
4. Swish 函数
- 核心公式 :
- 输出范围 :
- 特性 :
- 非线性更强(由 Sigmoid 的平滑特性引入),在深层模型(如 ResNet、Transformer)中表现常优于 ReLU;
- 处处可导(无 ReLU 的 "折点"),梯度传播更平滑;
- 缺点:计算复杂度高于 ReLU(需计算 Sigmoid)。
- 适用场景:大型 CNN、Transformer 的隐藏层(Google 提出,在 ImageNet 等任务中验证有效)。
5. GELU 函数(Gaussian Error Linear Unit,高斯误差线性单元)
- 核心公式 :
- 输出范围 :
- 特性 :
- 本质是 "概率加权的 ReLU"(将x乘以其大于 0 的概率
- 平滑性优于 ReLU,梯度传播更稳定,在 Transformer 模型中表现极佳;
- 本质是 "概率加权的 ReLU"(将x乘以其大于 0 的概率
- 适用场景:Transformer(如 BERT、GPT)的隐藏层(当前 Transformer 的默认激活函数)。
三、输出层专用激活函数
此类函数需配合特定损失函数,满足任务的输出约束(如概率、多分类、回归)。
1. Softmax 函数(多分类输出)
- 核心公式 (对K分类任务,输入为向量
- 输出范围 :每个输出值
- 特性 :将多维度输入映射为 "类别概率",配合交叉熵损失解决多分类问题。
2. Linear 函数(回归任务输出)
- 核心公式 :
- 输出范围 :
- 特性 :无非线性,直接输出模型预测值,配合MSE(均方误差) 损失解决回归任务(如房价预测、股价预测)。