流Stream类型
- 实现消息队列,支持消息的持久化、自动生成全局唯一ID、ack确认消息模式、消费组模式等,让消息队列更加的稳定和可靠
- 简言之就是Redis版的MQ消息中间件+阻塞队列
- 5.0版本新增功能,5.0版本之前通过发布和订阅实现消息队列功能
底层结构和原理
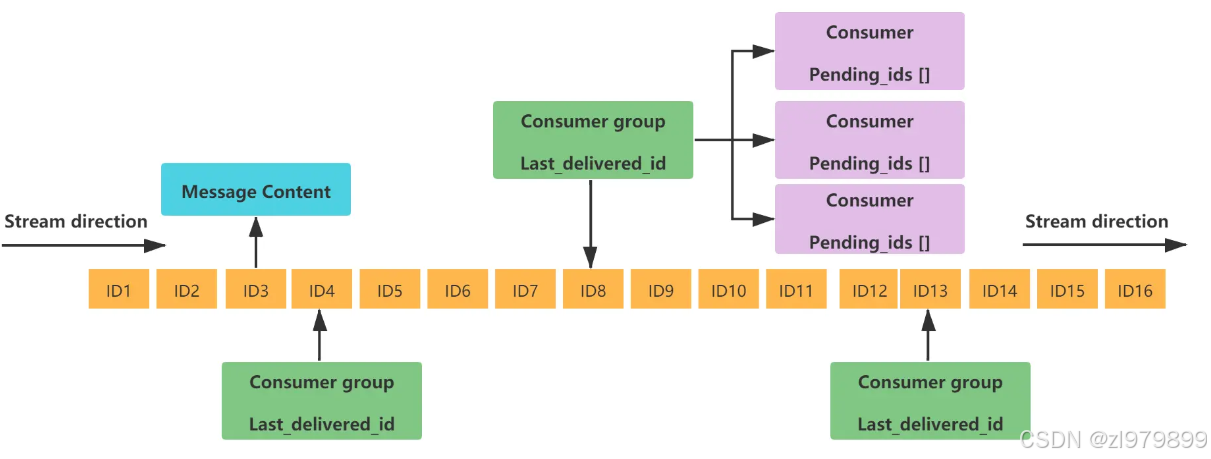
- 一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容
|-------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Message Content | 消息内容 |
| Consumer group | 消费组,通过XGROUP CREATE 命令创建,同一个消费组可以有多个消费者 |
| Last_delivered_id | 游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。 |
| Consumer | 消费者,消费组中的消费者 |
| Pending_ids | 消费者会有一个状态变量,用于记录被当前消费已读取但未ack的消息id,如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack它就开始减少。这个pending_ids变量在Redis官方被称之为 PEL(Pending Entries List),记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符),它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理 |
消息队列命令
- xadd:添加消息到队列末尾
- 如果指定的Stream 队列不存在,则该命令执行时会新建一个Stream 队列
- * 号表示服务器自动生成 MessageID(类似mysql里面主键auto_increment),后面顺序跟着一堆业务key/value

- xdel:删除消息
bash
xdel mystream 消息ID- xlen:获取stream队列的消息长度,返回消息ID的个数
bash
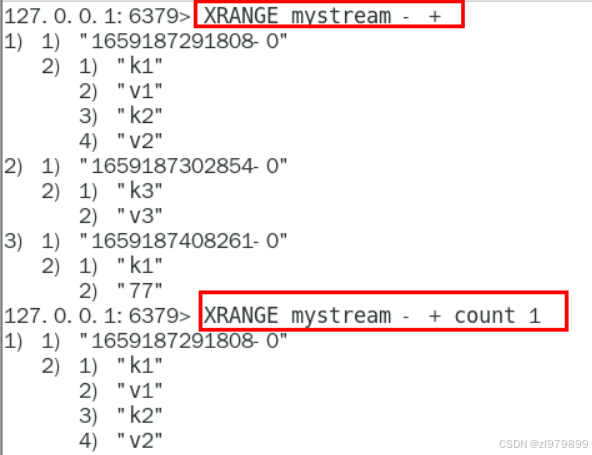
xlen mystream - xrange:获取消息列表
- start表示开始值,-表示ID最小值
- end表示结束值,+表示ID最大值
- count表示最大获取多少个值
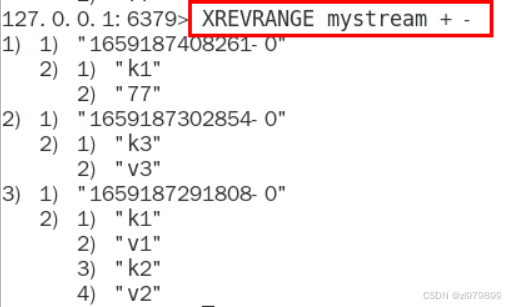
- xrevrange反向获取消息列表,ID从大到小
- 与xrange相反,end在前,start在后
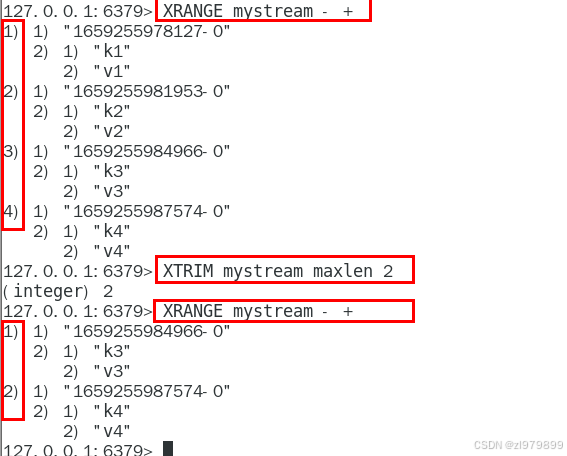
- xtrim:截取stream的长度
- maxlen:允许的最大长度,对流进行限制长度
- minid:允许的最小ID,从某个ID值开始比该ID值小的将会被舍弃
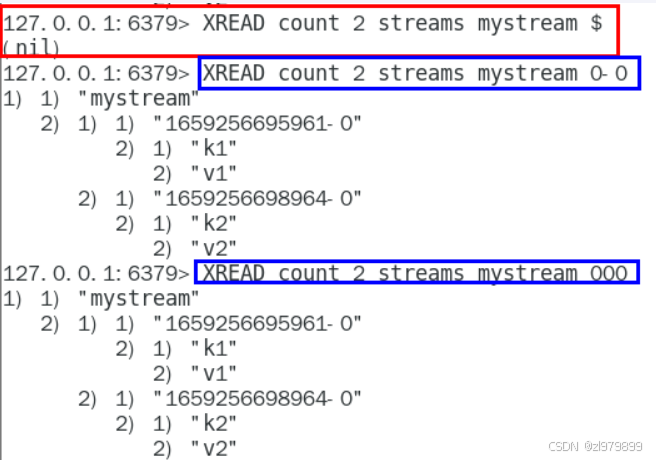
- xread:获取消息(阻塞和非阻塞),返回大于指定ID的消息
- $代表特殊ID,表示以当前Stream已经存储的最大的ID作为最后一个ID,当前Stream中不存在大于当前最大ID的消息,因此此时返回nil
- 0-0代表从最小的ID开始获取Stream中的消息,当不指定count,将会返回Stream中的所有消息,注意也可以使用0(00/000也都是可以的......)
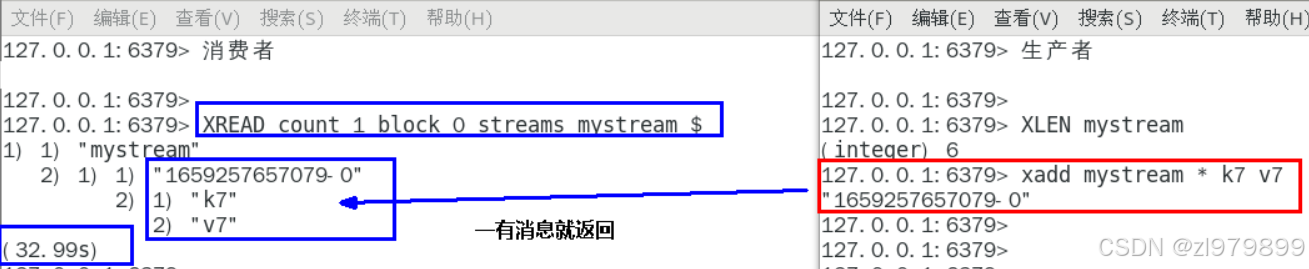
- 阻塞增加关键字block
消费组命令
- xgroup create:创建消费者组
- 创建消费者组的时候必须指定 ID, 0或者$
- $表示从Stream尾部开始消费
- 0表示从Stream头部开始消费

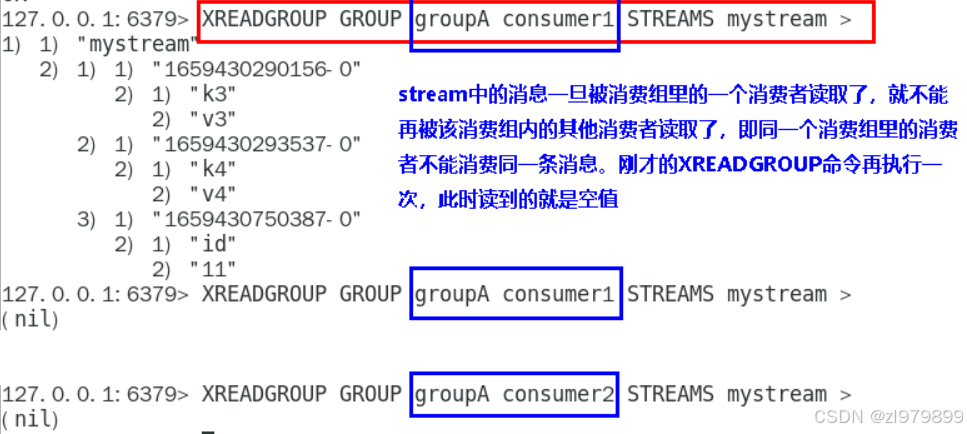
- xreadgroup group:消费者组读取消息队列
- >表示从第一条尚未被消费的消息开始读取
- 消费组groupA内的消费者consumer1从mystream消息队列中读取所有消息
- 不同消费组的消费者可以消费同一条消息
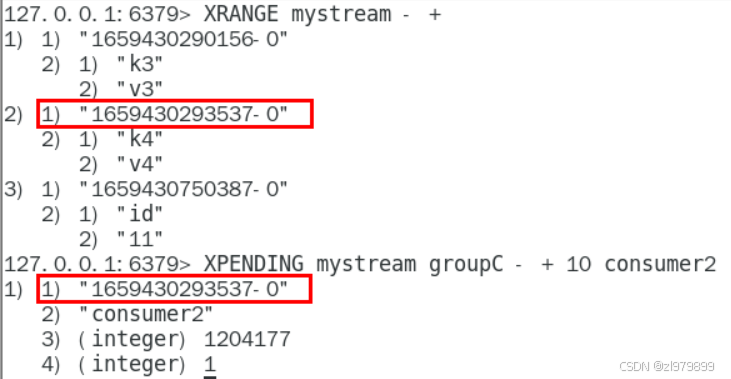
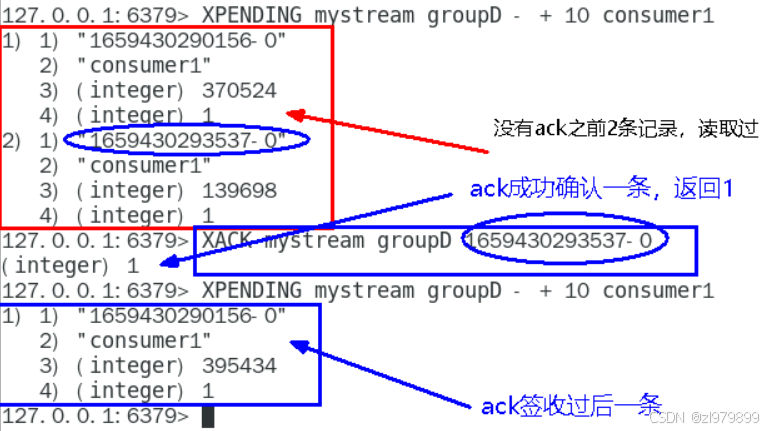
- xpnding
- 查询某个消费组内所有消费者对某个队列已读取但未确认的消息

- 查看某个消费者在某个消息队列中具体读了哪些数据
- xack:向消息队列确认消息已经处理完成
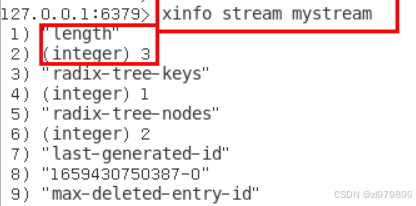
- xinfo:用于打印stream/consumer/group的详细信息
位域bitfield类型
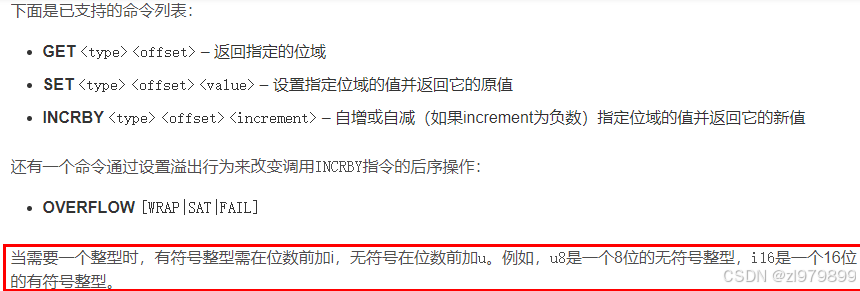
- 通过bitfield命令可以一次性操作多个比特位域(指的是连续的多个比特位)
- 完成执行一系列操作并返回一个响应数组,这个数组中的元素对应参数列表中相应操作的执行结果。
- 主要用来实现:位域修改和溢出控制
常用命令
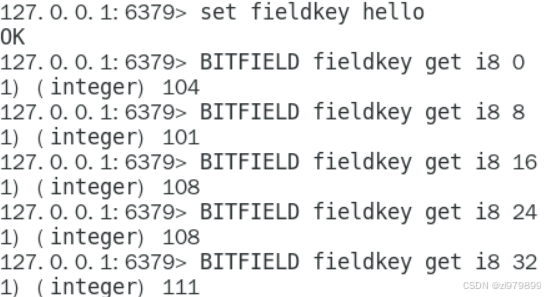
- get:将指定key对应的字符串转换成二进制,再取出指定偏移量和指定返回位数长度的数据,转换成10进制进行输出
- set:修改指定偏移量开始的数据,再将修改之前的值返回

- incrby:返回的是增加之后的新值
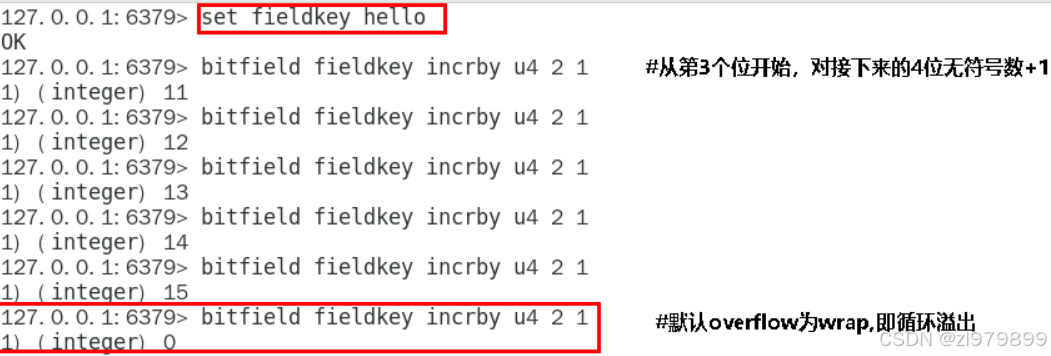
- 溢出控制
- WRAP: 使用回绕(wrap around)方法处理有符号整数和无符号整数的溢出情况

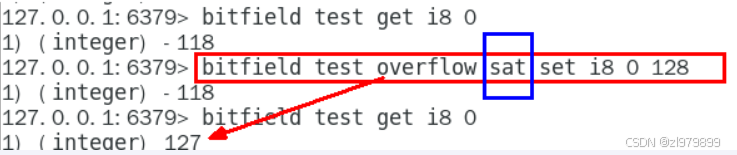
- SAT: 使用饱和计算(saturation arithmetic)方法处理溢出,下溢计算的结果为最小的整数值,而上溢计算的结果为最大的整数值
- FAIL: 命令将拒绝执行那些会导致上溢或者下溢情况出现的计算,并向用户返回空值表示计算未被执行
