目录
- 一、索引简介
-
- [1.1 索引底层的数据结构](#1.1 索引底层的数据结构)
- 二、MySQL中的页
-
- [2.1 页文件 头/尾](#2.1 页文件 头/尾)
- [2.2 页主体](#2.2 页主体)
- [2.3 页目录](#2.3 页目录)
- [2.4 数据页头](#2.4 数据页头)
- 三、索引分类及使用
-
- 3.1主键索引
- [3.2. 普通索引](#3.2. 普通索引)
- [3.3. 唯⼀索引](#3.3. 唯⼀索引)
- [3.4 全⽂索引](#3.4 全⽂索引)
- [3.5 聚集索引](#3.5 聚集索引)
- [3.6 ⾮聚集索引](#3.6 ⾮聚集索引)
- [3.7 索引覆盖](#3.7 索引覆盖)
- 四、查看索引
-
- [4.1 `show keys from 表名`](#4.1
show keys from 表名) - [4.2 `show index from 表名`](#4.2
show index from 表名) - [4.3 `desc 表名`](#4.3
desc 表名)
- [4.1 `show keys from 表名`](#4.1
- 五、删除索引
-
- [5.1 删除主键索引`alter table 表名 drop primary key`](#5.1 删除主键索引
alter table 表名 drop primary key) - [5.2 删除其它索引`alter table 表名 drop index key`](#5.2 删除其它索引
alter table 表名 drop index key)
- [5.1 删除主键索引`alter table 表名 drop primary key`](#5.1 删除主键索引

一、索引简介
MySQL的索引是⼀种数据结构,它可以帮助数据库⾼效地查询、更新数据表中的数据。索引通过⼀定的规则排列数据表中的记录,使得对表的查询可以通过对索引的搜索来加快速度。(就像目录一样)。
1.1 索引底层的数据结构
使用的是B+树,解决了hash表不能范围搜索,二叉搜索树的时间复杂度最差情况O(N)和树高的问题,也解决了B树叶⼦节点中的数据非连续的,且相互不链接,减少了IO的次数。
B+树的特点:
- 能够保持数据稳定有序,插⼊与修改有较稳定的时间复杂度( O( logN ) )
- ⾮叶⼦节点仅具有索引作⽤,不存储数据,所有叶⼦节点保真实数据
- 所有叶⼦节点构成⼀个有序链表,可以按照key排序的次序依次遍历全部数据
B+树与B树的对⽐
- 叶⼦节点中的数据是连续的,且相互链接,便于区间查找和搜索。
- ⾮叶⼦节点的值都包含在叶⼦节点中。
- 对于B+树⽽⾔,在相同树⾼的情况下,查找任⼀元素的时间复杂度都⼀样,性能均衡。
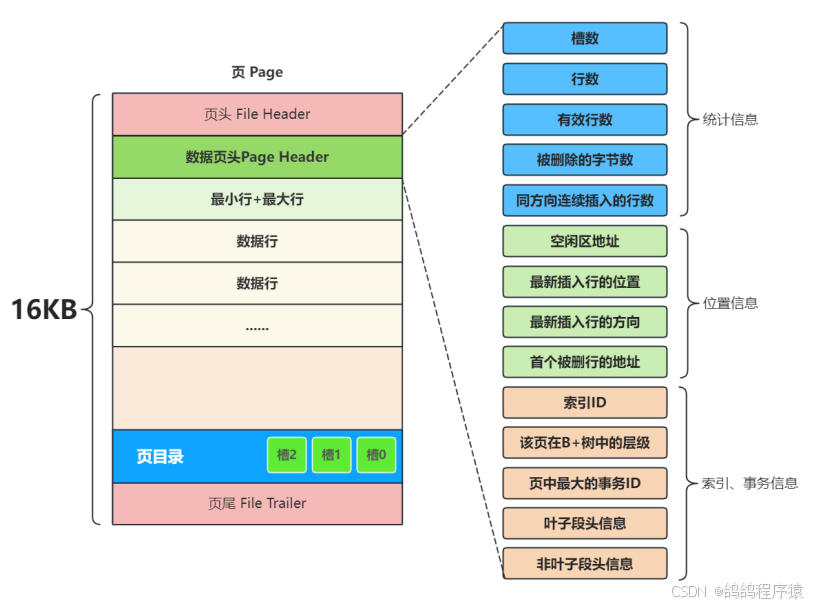
二、MySQL中的页
页(Page)是MySQL存储文件最重要的结构体,也是内存与磁盘交互的最小单元,默认大小16KB,内存与磁盘每次交互最少读一页。一页就是B+数中的一个节点。
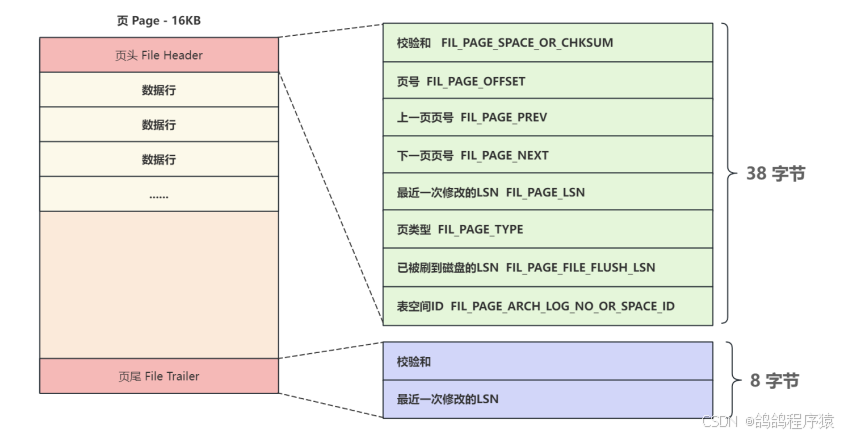
2.1 页文件 头/尾
上⼀⻚⻚号和下⼀⻚⻚号,通过这两个属性可以把⻚与⻚之间链接起来,形成⼀个双向链表,B+树中叶子结点的之间的连接。
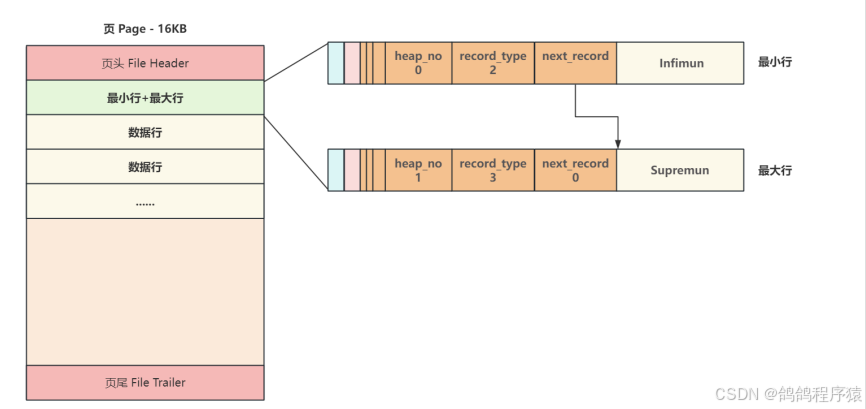
2.2 页主体
- ⼀个新⻚,都会⾃动分配两个⾏,⼀个是⻚内最⼩⾏ Infimun(相当于链表头) ,另⼀个是⻚内最⼤⾏ Supremun (链表尾),next_record :记录像一个数据行的位置。
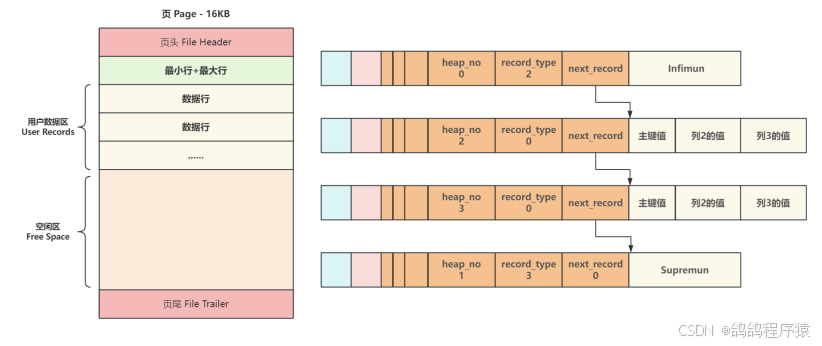
- ⼀个新⻚插⼊数据时,将 Infimun 连接第⼀个数据⾏,最后⼀⾏真实数据⾏连接 Supremun,这样在一个B+数的节点就是一个单向链表。
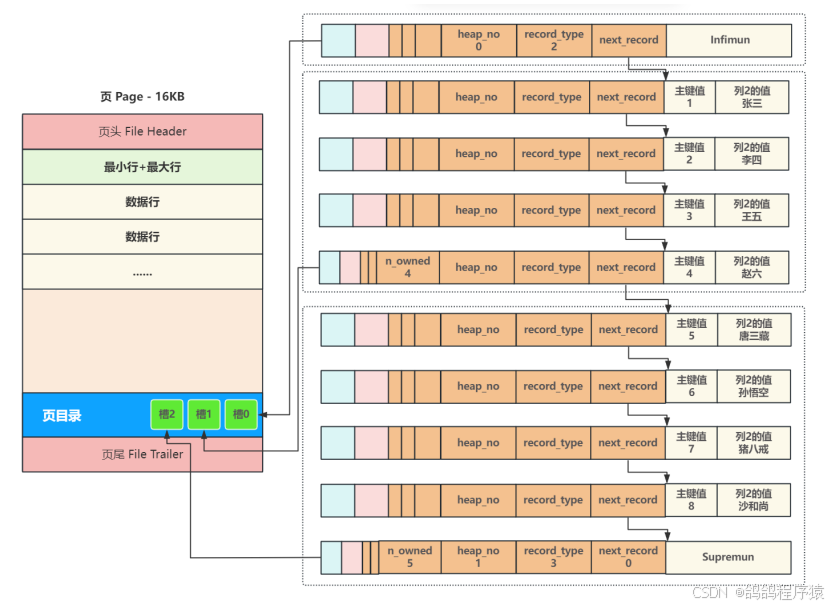
2.3 页目录
将⻚内包括头⾏、尾⾏在内的所有⾏进⾏分组,约定头⾏单独为⼀组,其他每个组最多8条数据,同时把每个组最后⼀⾏在⻚中的地址,按主键从⼩到⼤的顺序记录在⻚⽬录中在,⻚⽬录中的每⼀个位置称为⼀个槽,每个槽都对应了⼀个分组,⼀旦分组中的数据⾏超过分组的上限8个时,就会分裂出⼀个新的分组;
后续在查询某⾏时,就可以通过⼆分查找,先找到对应的槽,然后在槽内最多8个数据⾏中进⾏遍历即可,从⽽⼤幅提⾼了查询效率。
2.4 数据页头
数据⻚头记录了当前⻚保存数据相关的信息。
三、索引分类及使用
3.1主键索引
当在一张表上定义了primary key的时候,就会自动创建索引,索引值就是主键列的值,InnoDB使⽤它作为聚集索引。
- 创建表时直接指定主键
sql
create table test_pk1(
id bigint primary key auto_increment,
name varchar(20)
);- 创建表时指定列
sql
create table test_pk2(
id bigint auto_increment,
name varchar(20),
primary key(id)
);- 修改表中的列为主建索引
sql
create table test_pk3(
id bigint,
name varchar(20)
);
alter table test_pk3 add primary key(id);
alter table test_pk3 modify id bigint auto_increment;3.2. 普通索引
最基本的索引类型,没有唯⼀性的限制。通常为查询频繁的列创建。可为多列创建组合索引,称为复合索引或组全索引
- 创建表时指定索引列
sql
create table test_index1(
id bigint,
name varchar(20),
index(id)
);- 修改表中的列为普通索引
sql
create table test_index2(
id bigint,
name varchar(20)
);
alter table test_index2 add index(id);- 单独创建索引并指定索引名
语法:create index 指定索引名 on 表名(列名);
sql
create table test_index3(
id bigint,
name varchar(20)
);
create index index_id on test_index3(id);复合索引跟普通索引创建方式一样,只不过指定的列变多了。
3.3. 唯⼀索引
当在⼀个表上定义⼀个唯⼀键 UNQUE 时,⾃动创建唯⼀索引。比普通索引多一个唯一性,为频繁查询且列值重复度不高创建。
- 创建表时直接创建唯一键
sql
create table test_uk1(
id bigint unique,
name varchar(20)
);- 创建表时指定列为唯一索引
sql
create table test_uk2(
id bigint,
name varchar(20),
unique(id)
);- 修改表中的列为唯一索引
sql
create table test_uk3(
id bigint,
name varchar(20)
);
alter table test_uk3 add unique(id);3.4 全⽂索引
基于⽂本列(CHAR、VARCHAR或TEXT列)上创建,以加快对这些列中包含的数据查询和DML操作。⽤于全⽂搜索,仅MyISAM和InnoDB引擎⽀持。
3.5 聚集索引
与主键索引是同义词, 如果没有为表定义 PRIMARY KEY, InnoDB使⽤第⼀个 UNIQUE 和 NOT NULL 的列作为聚集索
引。如果都没有,InnoDB会为新插⼊的⾏⽣成⼀个⾏号并⽤6字节的 ROW_ID 字段记录, ROW_ID 单调递增,并使⽤ ROW_ID 做为索引。
3.6 ⾮聚集索引
聚集索引以外的索引称为⾮聚集索引或⼆级索引, ⼆级索引中的每条记录都包含该⾏的主键列,以及⼆级索引指定的列。 InnoDB使⽤这个主键值来搜索聚集索引中的⾏,这个过程称为回表查询。
3.7 索引覆盖
当⼀个select语句使⽤了普通索引且查询列表中的列刚好是创建普通索引时的所有或部分列,这时就可以直接返回数据,⽽不⽤回表查询,这样的现象称为索引覆盖。
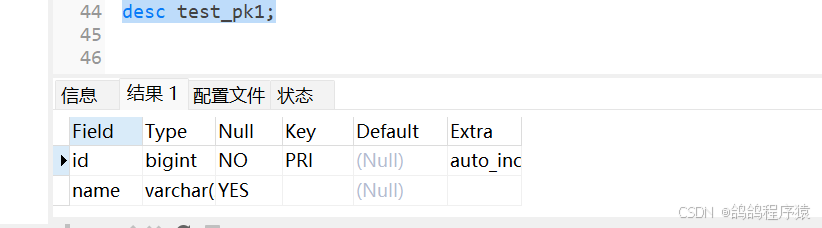
四、查看索引
4.1 show keys from 表名

4.2 show index from 表名

4.3 desc 表名
五、删除索引
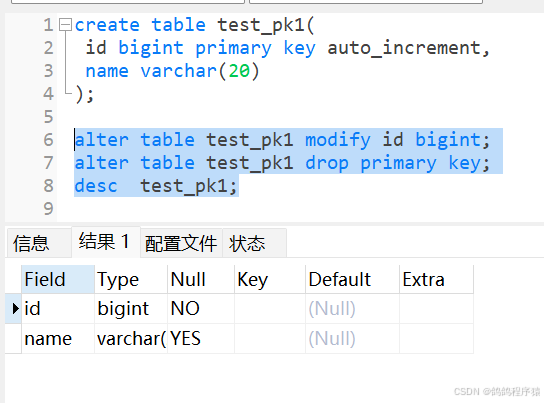
5.1 删除主键索引alter table 表名 drop primary key
5.2 删除其它索引alter table 表名 drop index key
