简介
在自然语言处理中分词是第一步,也是比较重要的。不同语言由于语言结构、词边界的差异,其分词策略和算法也不尽相同,我就专门补了一个博客来详细的介绍英文与中文中常见的分词方式。
之前我写了一个博客只是粗略的讲述了将中文语言转化为词向量的方法,并没有详细的介绍分词的具体知识点,可以结合这两篇博客进行学习
一、英文分词
按照分词粒度的大小,可分为词级(Word-Level)分词、字符级(CharacterLevel)分词和子词级(Subword‑Level)分词。下面逐一介绍
1、词级分词
词级分词是指将文本按词语进行切分,是最传统、最直观的分词方式。在英文中,空格和标点往往是天然的分隔符。
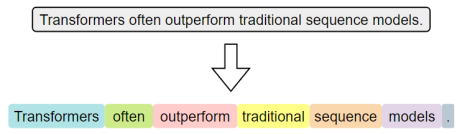
词级分词虽便于理解和实现,但在实际应用中容易出现 OOV(OutOfVocabulary,未登录词)问题。所谓 OOV,是指在模型使用阶段,输入文本中出现了不在预先构建词表中的词语,常见的包括网络热词、专有名词、复合词及拼写变体等。由于模型无法识别这些词,通常会将其统一替换为特殊标记(如 <UNK>),从而导致语义信息的丢失,影响模型的理解与预测能力。
2、字符级分词
字符级分词(Character-level Tokenization)是以单个字符为最小单位进行分词的方法,文本中的每一个字母、数字、标点甚至空格,都会被视作一个独立的 token。
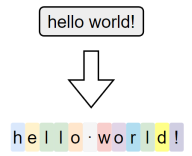
在这种分词方式下,词表仅由所有可能出现的字符组成,因此词表规模非常小,覆盖率极高,几乎不存在 OOV(Out-of-Vocabulary)问题。无论输入中出现什么样的新词或拼写变体,只要字符在词表中,都能被表示出来。
然而,由于单个字符本身语义信息极弱,模型必须依赖更长的上下文来推断词义和结构,这显著增加了建模难度和训练成本。此外,输入序列也会变得更长,影响模型效率。
3、子词级分词
子词级分词是一种介于词级分词与字符级分词之间的分词方法,它将词语切分为更小的单元------子词(subword),例如词根、前缀、后缀或常见词片段。与词级分词相比,子词分词可以显著缓解OOV问题;与字符级分词相比,它能更好地保留一定的语义结构。
子词分词的基本思想是:即使一个完整的词没有出现在词表中,只要它可以被拆分为词表中存在的子词单元,就可以被模型识别和表示,从而避免整体被替换为<UNK>。
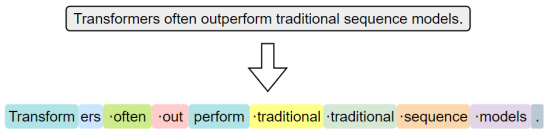
常见的子词分词算法包括 BPE(Byte Pair Encoding)、WordPiece 和 Unigram Language Model。
其中,BPE是最早被广泛应用的子词分词方法。其基本思想是,在训练阶段,首先将语料中的词汇拆分为单个字符,构建初始词表;然后迭代地统计语料中出现频率最高的相邻字符对,将其合并为新的子词单元,并加入词表。这个过程持续进行,直到词表大小达到预设上限。
在分词阶段,BPE 会根据构建好的词表和合并规则对新输入的文本进行处理。具体做法是:将文本拆分为最小单位(如字符或字节),然后按顺序应用训练中学习到的合并规则,逐步合并,直到无法继续。最终得到的就是由子词组成的分词结果。
详细的实现过程可参考Hugging Face提供的一篇优秀教程。
子词级分词已经成为现代英文 NLP 模型中的主流方法,如 BERT、GPT等模型均采用了基于子词的分词机制。
二、中文分词
1、 字符级分词
字符级分词是中文处理中最简单的一种方式,即将文本按照单个汉字进行切分,文本中的每一个汉字都被视为一个独立的 token。
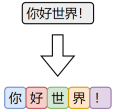
由于汉字本身通常具有独立语义,因此字符级分词在中文中具备天然的可行性。相比英文中的字符分词,中文的字符分词更加"语义友好"。
2、词级分词
词级分词是将中文文本按照完整词语进行切分的传统方法,切分结果更贴近人类阅读习惯。
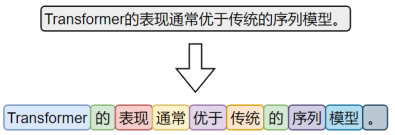
由于中文没有空格等天然词边界,词级分词通常依赖词典、规则或模型来识别词语边界。
3、子词级分词
虽然中文没有英文中的子词结构(如前缀、后缀、词根等),但子词分词算法(如 BPE)仍可直接应用于中文。它们以汉字为基本单位,通过学习语料中高频的字组合(如"自然"、"语言"、"处理"),自动构建子词词表。这种方式无需人工词典,具有较强的适应能力。
在当前主流的中文大模型(如通义千问、DeepSeek)中,子词分词已成为广泛采用的文本切分策略。
三、分词工具
目前市面上可用于中文分词的工具种类繁多,按照实现方式大致可以分为如下两类:
- 一类是基于词典 或模型的传统方法,主要以"词"为单位进行切分;
- 另一类是基于子词建模算法(如BPE)的方式,从数据中自动学习高频字组合,构建子词词表。
前者的代表工具包括 jieba、 HanLP等,这些工具广泛应用于传统 NLP 任务中。
后者的代表工具包括 Hugging Face Tokenizer、 SentencePiece、 tiktoken等,常用于大规模预训练语言模型中。
1、jieba分词器
之前我详细写过一篇专门讲述jieba库的博客,详细可以去参照下面这篇博客
2、One-hot编码
3、词嵌入word2vec
关于词嵌入word2vec在上面那个博客里面也讲述了,但是讲述的没有那么深,今天就深层次去讲述一下关于词嵌入word2vec
3.1、Word2Vec概述
Word2Vec的设计理念源自"分布假设"------即一个词的含义由它周围的词决定。
于这一假设,Word2Vec构建了一个简洁的神经网络模型,通过学习词与上下文之间的关系,自动为每个词生成一个能够反映语义特征的向量表示。
Word2Vec提供了两种典型的模型结构,用于实现对词向量的学习:
- CBOW(Continuous Bag-of-Words)模型
输入是一个词的上下文(即前后若干个词),模型的目标是预测中间的目标词。
- Skip-gram 模型
输入是一个中心词,模型的目标是预测其上下文中的所有词(即前后若干个词)。

只要按照上述目标训练模型,就能得到语义化的词向量。
3.2、Word2Vec原理
Word2Vec 不依赖人工标注,而是直接利用大规模原始文本(如书籍、新闻、网页等)作为数据源,从中自动构造训练样本。
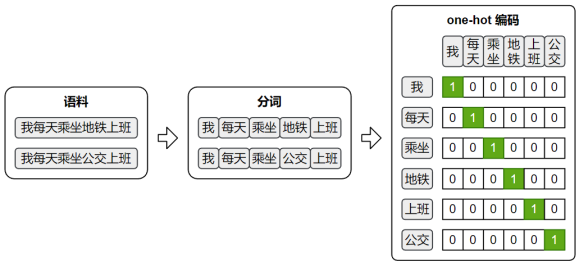
由于两种模型的输入和输出都是词语,因此首先需要对原始文本进行分词,将连续文本转换为 token 序列。
此外,模型无法直接处理文本符号,训练时仍需将词语转换为 one-hot 编码,以便作为模型的输入和输出进行计算。
Skip-Gram
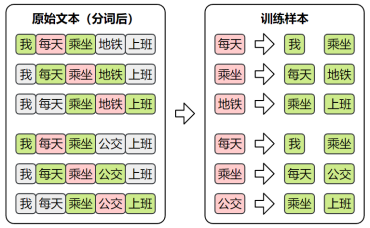
训练数据集
Skip-Gram的目标是根据中间词预测上下文,所以其训练样本为:
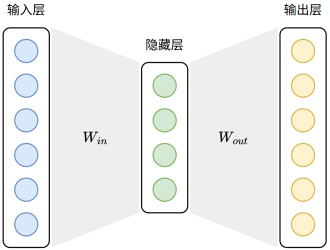
模型结构
Skip-Gram模型结构如下图所示:
Skip-Gram模型损失值的计算图如下图所示:
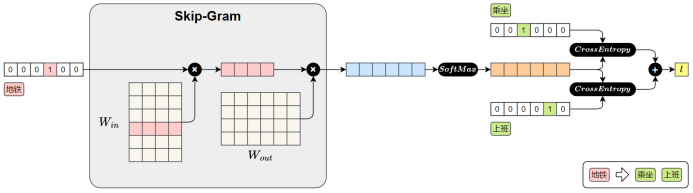
前向传播过程如下:
1.输入中心词(地铁)
"地铁"用 one-hot 向量表示
2.查找词向量()
与参数矩阵相乘,取出"地铁"对应的词向量。(实际上就是词向量矩阵,每一行表示一个词的向量)
3.预测上下文
将中心词向量与参数矩阵
相乘,得到对整个词表的预测得分。
4.Softmax 输出
得分通过 Softmax 转为概率分布,表示各词作为上下文的可能性。
5.计算损失
与真实上下文词"乘坐"、"上班"进行比对,计算交叉熵损失并求和,得到总损失。
之后在进行反向传播时,参数矩阵
中的"地铁"对应的词向量就会被更新,模型通过这个过程不断的进行学习,最终便能得到具有语义的词向量。
CBOW
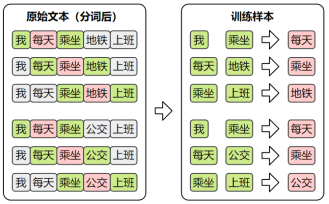
训练样本
CBOW的目标是根据上下文预测中间词,所以其训练样本为:
模型结构
CBOW模型的结构如下图所示:
CBOW模型损失值的计算图如下图所示:
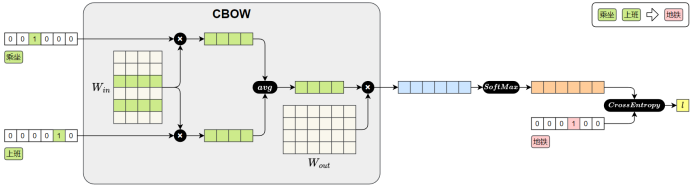
CBOW 模型的前向传播过程如下:
1.输入上下文词(乘坐、上班)
每个词用 one-hot 向量表示。
2.查找词向量( )
每个 one-hot 向量与参数矩阵
相乘,查出对应的词向量。( 实际上就是词向量矩阵,每一行表示一个词的向量)
3.平均上下文向量
将多个上下文词向量取平均,得到一个整体的上下文表示。
4.预测中心词
将平均后的上下文向量与参数矩阵
相乘,得到对整个词表的预测得分。
5.Softmax 输出
将得分输入Softmax,得到每个词作为中心词的概率分布。
6.计算损失
将预测结果与真实中心词"地铁"的one-hot向量进行比对,计算交叉熵损失。
之后在进行反向传播时,参数矩阵中"乘坐"和"上班"对应的词向量就会被更新。模型通过不断训练,逐步优化这些向量,最终便能得到具有语义的词向量。
3.3、获取Word2Vec词向量
词向量的获取通常有两种方式:一种是直接使用他人公开发布的词向量,另一种是在特定语料上自行训练。
在实际工作中,无论是加载已有模型还是从零训练,都可借助Gensim来完成,它提供了便捷的接口来加载 Word2Vec 格式的词向量,也支持基于自有语料训练属于自己的词向量模型。
一般我们都是使用国内一些大公司训练好的词向量
公开的中文词向量,可从https://github.com/Embedding/Chinese-Word-Vectors下载,其提供了基于多个数据集训练得到的词向量。
词向量文件的格式为:第一行记录基本信息,包括两个整数,分别表示总词数和词向量维度。从第二行起,每一行表示一个词及其对应的词向量,格式为:词 + 向量的各个维度值。所有内容通过空格分隔,该格式已成为自然语言处理领域中广泛接受的约定俗成的通用格式。具体格式如下
python
<词汇总数> <向量维度>
word1 val11 val12 ... val1N
word2 val21 val22 ... val2N
...可使用++++KeyedVectors.load_word2vec_format++++ ++++()++++ 加载上述词向量文件,具体代码如下。
python
from gensim.models import KeyedVectors
model_path = 'sgns.weibo.word.bz2'
model = KeyedVectors.load_word2vec_format(model_path)自行训练词向量
1.准备语料
Word2Vec的训练语料需要是已分词的文本序列,格式为:
python
sentences = [['我', '每天','乘坐', '地铁', '上班'], ['我','每天', '乘坐', '公交', '上班']]2.训练模型
gensim提供了十分方便的训练词向量的API------Word2Vec。
python
pip install gensim
python
from gensim.models import Word2Vec
model = Word2Vec(
sentences, # 已分词的句子序列
vector_size=100, # 词向量维度
window=5, # 上下文窗口大小
min_count=2, # 最小词频(低于将被忽略)
sg=1, # 1:Skip-Gram,0:CBOW
workers=4 # 并行训练线程数
)3.保存词向量
python
model.wv.save_word2vec_format('my_vectors.kv')4.加载词向量
python
from gensim.models import KeyedVectors
my_model = KeyedVectors.load_word2vec_format('my_vectors.kv')3.4、应用Word2Vec词向量
训练好的词向量,通常用于初始化下游NLP任务的嵌入层。
在现代深度学习的 NLP 模型中,大多数任务的输入第一层都是嵌入层。本质上,嵌入层就是一个查找表(lookup table):输入是词在词汇表中的索引;输出是该词对应的向量表示。
嵌入层的参数矩阵可以有两种典型的初始化方式:
- 随机初始化
模型训练开始时,嵌入向量是随机生成的,模型会通过反向传播逐步学习每个词的表示。
- 使用预训练词向量初始化
加载训练好的词向量(如 Word2Vec)到嵌入层中作为初始参数,这样可以为模型注入丰富的语言知识,尤其在低资源任务中优势明显。并且,加载预训练词向量后,可选择是否让嵌入层继续参与训练。
具体完整代码可以参照下面这篇博客一起学习
自然语言处理之第一课语言转换方法