基于内容的过滤算法:
在之前分析的协同过滤算法中,讨论到如何进行推荐时,分为了两种推荐模式:用户协同与项目协同。在这两种模式中,它们的共同点是都更加关注用户的行为,而并非每一个项目的固有特性。
这样带来的弊端有:对于没有评分或其他信息的项目,我们无法获得相关的用户行为数据,也就无法进行推荐,即冷启动问题;同时,为了保证推荐的可行性,我们需要拥有大量的用户行为数据,即需要拥有足够多的用户行为才能够生成可靠的模式。
因此引入了基于内容的过滤算法,在此算法中,我们会更加关注项目的固有特性,即根据用户与项目的特征信息进行推荐。如果一个用户有一系列的喜欢和感兴趣的项目,则会给该用户推荐与其喜欢和感兴趣的项目相似的其他项目,所以称之为基于内容的过滤。

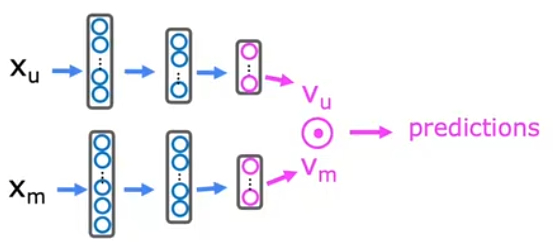
如上图所示,假设此时已经拥有了部分用户与电影特征数据,分别用和
来表示,这两个向量不一定是同维的,为了更加精准的提炼出用户偏好,
可能会很大。虽然原始的特征向量也可以反映出特征信息,但这些信息是较为表层的,可能没有考虑不同特征之间的复杂交互关系 以及它们的相对重要性。
综上,我们需要将原始的特征信息输入神经网络进行处理。由于此时的推荐只依赖于用户与电影的特征信息,我们可以将预测评分表示为:
如果输出是二元变量形式,则可以表示为:
因为要进行点积,式中的两个向量必须是同维 的,则可以构建出用户网络与项目网络。需要注意的是:用户网络与项目网络的输出层单元数必须保持一致。
为了得到神经网络中的参数,构建如下成本函数:
因为对于单个用户进行推荐时,考虑的是项目之间的相似性,而通过上图我们可以得到项目i的特征向量,则项目i与项目k之间的相似度可表示为:
由于项目的属性一般是很稳定的,如类别、年份、国家等等,因此对于所涉及的项目,我们可以预先通过项目网络计算得出一系列的特征向量,并且计算出项目之间的相似度,便于后续的推荐。
两种过滤算法比较:
| | 协同过滤 | 基于内容过滤 |
| 核心思想 | 根据用户过去喜欢的项目特征,推荐特征相似的其他项目。 | 找到与用户偏好相似的其他用户,然后推荐这些相似用户喜欢、但目标用户还未接触过的项目。 |
| 优点 | 不需要内容特征,可能可以推荐出新领域项目 | 无冷启动问题,且可解释性强 |
| 缺点 | 冷启动问题、要求较多的用户行为数据 | 较为依赖内容特征、一定程度上可能缺乏多样化 |
|---|
大目录推荐:
大目录推荐中项目数量很多,此时对于每一个用户及每一个项目都进行上图中的计算步骤,在计算上是很难实现的,因此实际的步骤大致分类两步:
检索:
对于一个用户,可能目前已经有了一些用户行为,因此我们可以根据这些行为来提供一个可能的推荐列表。以电影推荐为例,该列表中可能包括:与用户高评分电影相似度较高的其他电影、用户喜欢的电影类别中均分top10电影、用户喜欢的电影导演执导的电影中均分top10电影等等。在这个检索过程中,就会利用到前面提到的项目特征向量以及项目之间的相似度。
此列表中应尽可能地检索出较多的用户可能感兴趣的项目,即使列表中可能包含一些用户无感的内容。
排序:
得到了前面的检索列表后,我们则可以结合用户的特征信息来进一步的对所有项目进行排序,预测其得分,从而实现精准推荐。
该过程中可以直接利用之间计算得到的项目特征,但用户特征不能直接沿用。因为用户的行为是动态的,我们需要捕捉用户实时/近期的行为特征,以保证推荐的有效性。