过去二十年,Android Native(C/C++)的内存泄漏检测方案从未停下脚步。
从最早的Valgrind,到LLVM Sanitizer里的LSan(Leak Sanitizer),再到Android平台的libmemunreachable,每一个阶段都代表着工程师们在性能、准确性与可用性之间的取舍。
除了平台侧,App侧的方案也层出不穷,快手的KOOM、字节的MemoryLeakDetector、腾讯的Matrix等,都含有Native泄漏检测的功能。
工具之多,如恒河沙数。它们在不同的时间相继登场,各自闪耀。然而,在这纷繁的表象之下,其实隐约藏着一条清晰的技术脉络。本文试图把这条脉络给拎出来:看清了它,也就看懂了过去。
Valgrind
2000年,彼时互联网泡沫刚刚破裂,Linux世界仍缺乏一个可靠的、能够检测C/C++程序内存错误的工具。英国开发者Julian Seward希望搭建一个通用的动态分析框架,让开发者可以通过动态二进制插桩轻松编写自己的分析器。
他为这个工具取名Valgrind------在北欧神话里,Valgrind是通往英灵殿的大门,而英灵殿正是为阵亡勇士准备的天堂。Seward选择这个名字,带着一点黑色幽默:
"程序若想进入"天堂"(一个没有Bug的世界),就必须先通过Valgrind的考验。"
在Valgrind的初代版本中,他实现的第一个分析器就是Memcheck------一款专注于检测内存错误的工具。正因如此,很多人后来把Valgrind与Memcheck画上了等号。
从本质上看,Valgrind并不是一个普通的调试器,而是一个宿主进程+虚拟执行框架。它会加载目标可执行文件,把原生机器码翻译为统一的中间表示VEX IR(Valgrind EXecution Intermediate Representation),然后在IR层面插入各种检测逻辑------如读写检测、分配跟踪、shadow memory标记等。最后,它再将插过桩的IR重新编译回宿主平台机器码,由Valgrind的调度器执行这些代码块。
回到泄漏检测本身,它的工作分为两个时段:运行时和检测时。

运行时,Valgrind会拦截每一次malloc/new与对应的free/delete,为每个分配块建立元信息记录。这些元信息包括:地址区间、分配大小、内存状态(已初始化/未初始化)以及调用栈。这张"活跃分配表"相当于Native堆空间的实时账本,记录着所有存活的对象。
检测时,Valgrind会冻结整个程序的执行状态,获取每个线程的寄存器、栈、全局变量和TLS等信息,从而构建出一个一致性的"可达性根集"。这里的"一致性"指的是:在采样时所有线程都处于同一个冻结点上,不会出现某个线程正在修改指针,而另一个线程正在被扫描的非同步状态。
接着,Valgrind会从这些根出发,逐字(word,也即一个指针所占据的字节数)扫描它们所覆盖的内存区域,凡是看起来像是指针且落在活跃分配表中某个分配块的地址范围内,就将该块标记为"可达(reachable)",并递归扫描其内容。
这个过程相当于一个保守式的mark-and-sweep:标记所有可达对象,剩下未被标记的分配块则被视为潜在泄漏。
之所以称为"保守",是因为标记时并不知道哪些是指针,只是按照一个规则去找"看起来像的"。这样会把一些实际上不是指针、但是符合这个规则的字段判断为指针,从而标记更多的对象。所以"保守"的本质含义是:在不确定时,选择保留对象。对泄漏检测而言,它不会错判一个"仍在被引用的对象"为泄漏,但可能会把一些实际上已经没人用的内存误认为"仍在使用"。
最后,Valgrind会根据块的引用情况将泄漏标记出来,结合分配时记录的调用栈,这些泄漏块会被聚合、统计并输出成可读的报告。至此,一个完整的泄漏检测过程(记录分配→采集根集→可达性分析→分类报告)便完成了。
作为这一领域的开山鼻祖,Valgrind基本确立了内存泄漏检测的核心范式。此后出现的各种工具,本质上都是围绕这一框架,在性能、精度与可用性之间不断调优和取舍。
LSan(Leak Sanitizer)
Valgrind选择在运行时动态翻译并非偶然,而是时代的必然。2000年的开发环境里,还没有LLVM这样的中间表示(IR)框架,编译器插桩几乎不可行。而Valgrind想做的不只是一个内存泄漏检测器,而是一种通用的"动态分析平台"。它希望在二进制层面运行,做到黑盒分析:无需源码、不依赖编译器、可监控任意可执行文件。这种做法的代价是性能下降,但换来的却是语言的无关性和检测的精确性。
然而,随着软件规模的急剧膨胀,Valgrind的"完美世界"遇到了现实的反噬。它的虚拟化机制意味着几乎每条指令都要经过翻译和调度,程序往往慢上10~30倍,难以在大型C++服务或移动端场景中落地。更麻烦的是,它需要在运行时拦截系统调用,无法与多线程优化、JIT代码、内核接口良好配合。换句话说,Valgrind精确,但太"重"了。
2010年后,LLVM的兴起让另一条路变得可能:在编译器本身插入检测逻辑,而非在运行时模拟执行。Google在大规模C++服务中亟需一种"能常驻构建系统、不改代码、不拖慢十倍性能"的检测方式------于是2012年的USENIX ATC上,AddressSanitizer(ASan)登场。ASan把检测逻辑直接嵌入编译阶段生成的指令流中,用shadow memory模拟堆状态,开销从Valgrind的10~30倍降到2~3倍。
而LeakSanitizer(LSan)正是在这样的体系中自然生长出来的:既然ASan已经拦截了所有malloc/new与free/delete,又能在运行时维护分配元数据,那么只要在检测时扫描一遍活跃块,看哪些不可达,就能检测泄漏。
初版LSan直接作为ASan的一个组件出现,随后LLVM将它拆分为可独立使用的选项-fsanitize=leak。
从实现角度看,Valgrind与LSan的最大分歧,在于"分配追踪"的方式:前者是运行时动态插桩(动态二进制翻译后插入检测逻辑),后者是编译期静态插桩。而在根集合的获取上,Valgrind直接以进程的地址空间为准,因此能知道并扫描所有的映射区,而LSan为了更容易移植并减少依赖,主要通过ELF/loader的语义信息和线程API获取根集,这样的方式开销更小、集成更简单,但它不会把任意匿名mmap映射自动登记为被追踪的区域,所以默认不会报告这类泄漏,除非显式把那块内存注册给LSan。
总体而言,LSan延续了Valgrind的检测思路,却以编译期插桩取代了运行时虚拟执行,使工具的性能大幅提升,也让内存泄漏检测真正走入大规模工程化的应用场景。
libmemunreachable
如果说LSan让内存泄漏检测走入了工程体系,那么Android的libmemunreachable则把它推向了"零开销运行"的极限。
2016年,Google工程师开始在系统层面引入一套能直接运行在zygote与system_server等关键进程中的原生内存泄漏检测机制。当时他们面对的主要矛盾是:系统native组件(frameworks、HAL、媒体栈等)经常发生内存泄漏,而现有工具------无论是Valgrind还是LSan------都难以在真机或量产环境中落地。Valgrind太慢,LSan则需要重新编译系统并长期插桩运行。
于是,Android团队提出一个大胆的问题:
能否在不修改编译器、不常驻插桩、不影响运行性能的情况下,完成一次精确的泄漏检查?
libmemunreachable就诞生于这样的背景下。
它不依赖编译器,也不需要持续追踪分配,而是在运行时通过一次"冻结进程→克隆快照→标记扫描(mark--sweep)"的操作完成泄漏检测。整个过程只在触发检测的那一刻执行,且检测对于原进程的影响很小,因此被称为"zero-overhead native leak detector"。
它的零开销得益于两点改进。
一是不追踪分配,Valgrind和LSan都需要在运行时追踪每一次分配和释放,从而维持一张持续更新的"活跃分配表"。这张表是检测的依据,同时也是开销的来源,因为分配/释放远比我们想像的更加频繁。libmemunreachable完全摒弃了这一思路。它并不自己维护"活跃分配表",而是在检测瞬间直接向分配器(Scudo或jemalloc)索取。以Scudo为例,每个内存堆块都有一个chunk header,其中记录着分配大小、状态等信息。libmemunreachable会通过分配器提供的malloc_iterate接口遍历这些header,从而构建出"活跃分配表"。
二是把耗时的标记扫描过程从主进程迁移到子进程中完成,从而让主进程的暂停时间达到最短。
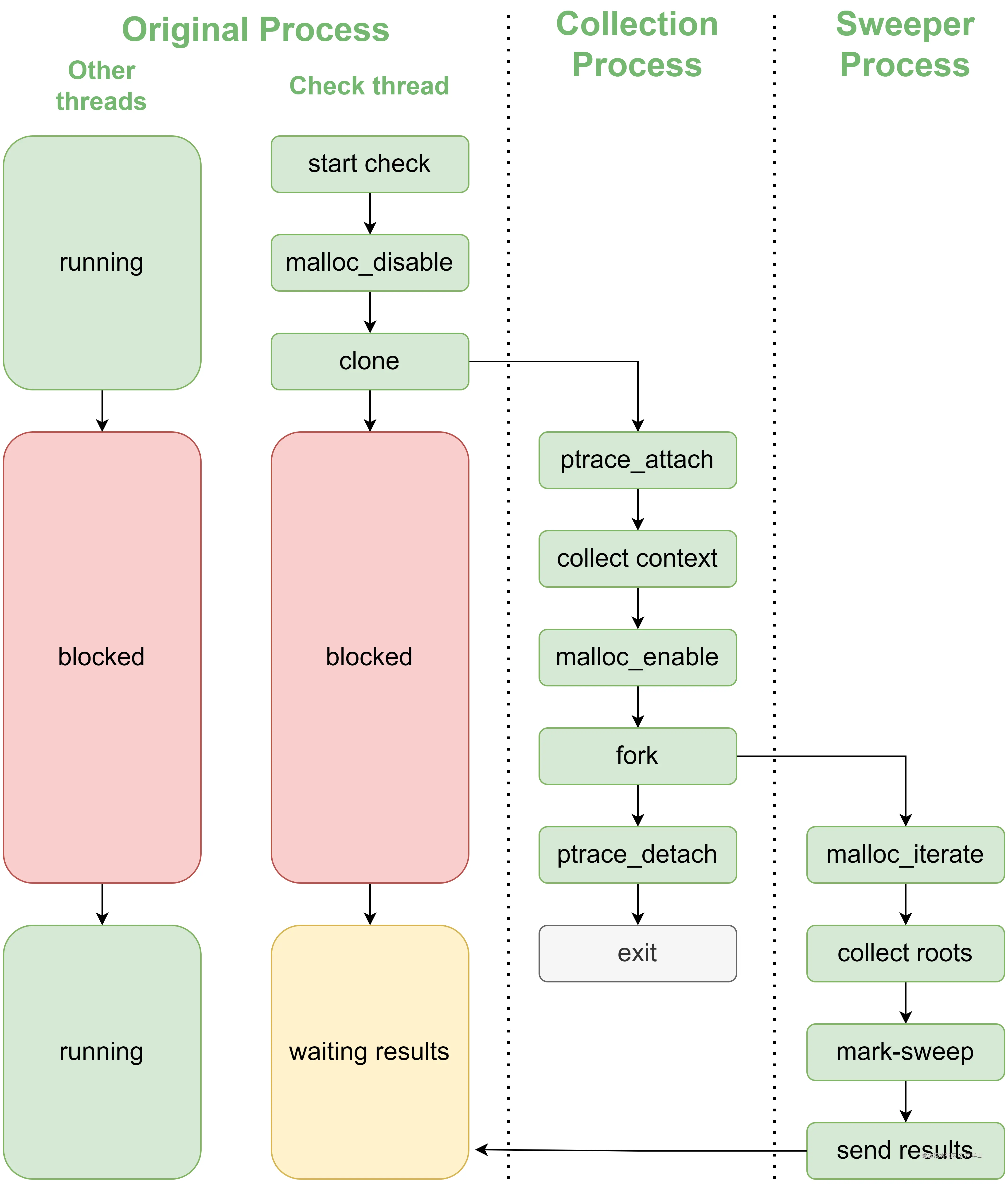
当检测触发时,负责检测的线程首先调用malloc_disable冻结分配器,确保堆中数据在采样期间保持一致。随后,通过clone(CLONE_VM)的方式创建出一个共享地址空间的collector进程。
进入collector进程后,它会依次执行以下动作:
- ptrace_attach:暂停父进程中所有线程,确保内存处于完全静止状态。
- collect context:逐线程采集寄存器和线程栈边界信息,并读取父进程的内存映射表。
- malloc_enable:采集完成,恢复分配器,使堆操作重新可用。
- fork:生成sweeper进程,由于写时复制(COW)机制的存在,sweeper拥有父进程在冻结时刻的完整内存快照。
- ptrace_detach/exit:让主进程恢复运行,自己退出。
至此,检测对于父进程的"停顿"结束,父进程恢复正常运行,而真正的分析工作则转移到sweeper中完成。
有人可能会好奇,为何collector进程采用clone的方式创建,而sweeper进程则采用fork。这是因为clone(CLONE_VM)会让子进程与父进程共享同一份地址空间,而fork会复制地址空间,导致的结果就是clone出来的子进程仍然可以观测到父进程对于内存的改动,而fork则不行。collector采用clone,可以保证ptrace真正暂停父进程之前的内存改动依然可以被观测到,从而保证最终内存的一致性。
在sweeper进程里,它看到的是一份静态的、不会再改变的内存空间,因此我们也叫它内存快照。针对这份内存快照,系统可以在子进程中从容地执行耗时的mark--sweep分析,而不会对原进程造成任何干扰。
如果反过来,在原进程中直接开启一个检测线程,那么在执行mark--sweep时仍必须暂停其他线程,以确保堆空间在遍历期间保持一致。这种方式虽然简单,却会引发明显的卡顿。
而fork出子进程在快照上完成检测的思路,早已被验证为一种高可靠的隔离式分析模式:它同样被应用在Android系统生成tombstone崩溃日志的机制中,以及快手KOOM在进行Java堆dump时的实现中。
App侧方案
我们讨论了这么久"泄漏",却还没有真正讨论过"泄漏"究竟是什么。事实上,很多争论和误解都源自对"泄漏"二字的理解不同。
从根本上看,内存泄漏可以有两种理解:语义层面的泄漏和业务层面的泄漏。
- 语义层面的泄漏是一种可达性定义:只要对象仍然能被程序访问------即从寄存器、栈、全局变量等根可达------它就不算泄漏。这种定义严格、客观,因此需要依赖可达性分析来判断。上面所分析的三种平台侧方案均检测的是这种泄漏。
- 业务层面的泄漏则站在程序设计的角度,从业务逻辑出发:某些对象虽然仍有引用,但如果按设计它们本该被释放------比如缓存长期不被清空、对象池不回收或引用忘了解除------那它们会被视为泄漏。这个理解和Java世界里的"内存泄漏"概念更接近,因此判断标准不在于"是否可达",而在于"是否合理地存在"。
换句话说:
语义泄漏关心"能不能找到它",业务泄漏关心"该不该还留着它"。
在系统侧方案逐步成熟之后,应用/业务侧的检测需求也随之快速增长,开发团队要面对长期运行的App、复杂的内存使用模式、碎片化的系统版本等现实因素。于是在随后的几年里,出现了一批App侧的方案。
App侧的方案根据对内存泄漏理解的不同,也分为了两类。语义泄漏的代表是快手的KOOM,它采用的方案和平台侧方案类似,需要对内存进行可达性分析。而字节的MemoryLeakDetector和腾讯的Matrix都属于业务泄漏的范畴,它们的主体目标是记录内存中存活的对象,通过栈聚合和趋势分析来定位潜在的泄漏热点,所以更像是统计学上的分析手段。
另外,在App侧方案中,开发者往往需要投入大量精力在Hook与调用栈收集上------既要保证对各种系统版本和ABI的兼容,又要尽量降低运行时开销。而这些在系统测方案中,由于具备统一的运行时和符号支持,通常不构成主要负担。
后记
回望这二十年,Native内存泄漏检测的历史几乎就是系统软件工程不断"向现实妥协"的过程。
Valgrind代表了理想主义的起点------在那个硬件性能尚不足以支撑重型动态分析的年代,它以近乎暴力的方式去追求精确;LSan则是工程化的中庸------把检测逻辑前移到编译期,用更温和的代价换取可持续的落地;而libmemunreachable的出现,则意味着检测终于成为系统运行时的一部分,不再是开发者的额外负担。
这条技术演进路径本质上是一场关于"可见性与代价"的博弈:
- 要想"看得见一切",就必须侵入得更深
- 要想"运行得轻",就必须接受某种模糊与局限
换句话说,内存泄漏检测从来不是一个单纯的技术问题,而是系统复杂性与工程现实之间的平衡艺术。