Ring-1T 已成长为可与闭源巨头正面对话的选手,也是开源体系下闭源级性能的又一次实证。
蚂蚁,又双叒叕开源万亿大模型了!
短短十余天,接连三弹。
10 月 9 日凌晨,蚂蚁官宣并开源通用语言大模型 Ling-1T ------迄今为止他们参数规模最大的语言模型。上线 HuggingFace 仅四天,下载量便突破千次。
Ling-1T开源,x网友也震惊于开源模型的体量
reddit上也有热烈讨论。有分析认为,蚂蚁的设计确实有让推理变强的合理机制,比如活跃参数更多、前几层全密集。
还没等业内缓过神来,10 月 14 日凌晨,万亿级思考模型 Ring-1T 又正式登场,这也是全球首个开源的万亿参数思考模型。
其实早在 9 月 30 日,蚂蚁就已放出 Ring-1T-preview 版本。彼时,它便在多项榜单上崭露头角,展现出出色的自然语言推理与思考能力,也率先把开源思考模型的「天花板」推至万亿级。

Ring-1T-preview刚出来,就有苹果工程师在自己的 M3 Ultra 上跑了起来。
此次正式发布,Ring-1T 完成了完整的训练流程,包括继续通过大规模可验证奖励强化学习(RLVR)进一步增强推理能力,并结合人类反馈强化学习(RLHF)提升通用表现,模型整体能力更均衡。
在高难度 IMO 测试中,Ring-1T 接入多智能体框架 AWorld,首次尝试便解出第1、3、4、5 题------ 4 题全对,达到 IMO 银牌水平,成为首个在国际奥数赛题上取得获奖级成绩的开源系统。
领先的复杂推理能力,开源SOTA再刷新
三连开源,频率之高令人瞩目。那问题来了------
这次正式版 Ring-1T,到底有多强?
从最新公布的成绩单来看,得益于完整强化学习训练流程的加持,Ring-1T 在其预览版的基础上几乎实现全面、显著的性能提升。
在数学、编程、逻辑推理、专业知识与创意写作等多维基准上全面开花,成绩稳居第一梯队,多项测试直接达到开源 SOTA 水平,部分测试表现可比肩最强闭源模型。
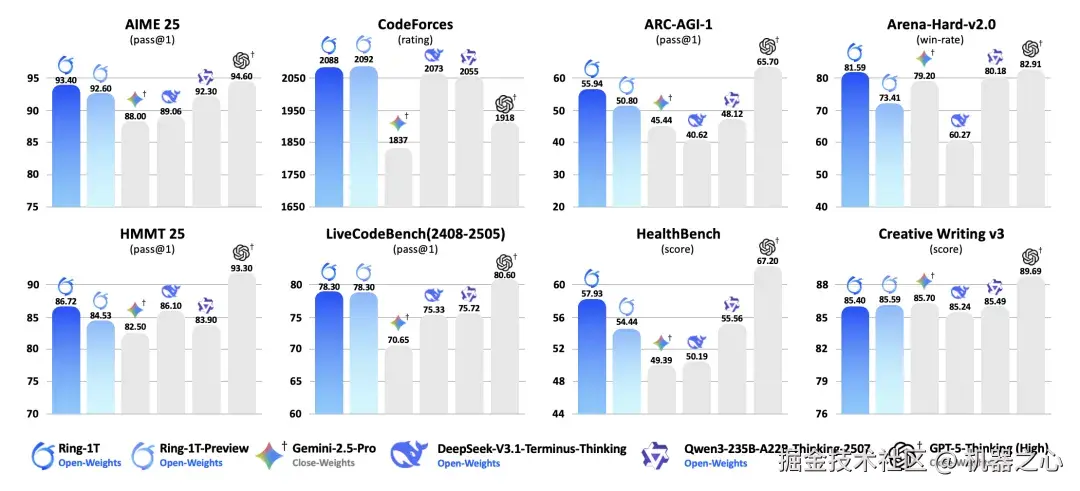
为了检验模型是否能在最具挑战性又最具实用价值的认知任务上达到全球顶尖水平,团队选取了八个重要基准测试:数学竞赛(AIME 25、HMMT 25)、代码生成(LiveCodeBench、CodeForce-Elo)、逻辑推理(ARC-AGI-v1)、综合榜单(Arena-Hard-v2)、健康医疗(HealthBench )以及创意写作(CreativeWriting-v3)。
团队选取了八个重要基准测试。参与对比的对手涵盖主流开源模型与闭源 API:
-
Ring-1T-preview*
*
-
Gemini-2.5-pro
-
Deepseek-V3.1-Terminus-Thinking
-
Qwen-235B-A22B-Thinking-2507
-
GPT-5-Thinking( High )
结果显示,与自己的 Preview 版本( Ring-1T-Preview )相比,Ring-1T 的性能提升几乎覆盖所有维度,整体能力更加均衡。
在ARC-AGI-v1、Arena-Hard-v2.0、HealthBench等涵盖复杂推理与跨领域挑战的高难度测试中,Ring-1T 表现尤为突出,推理稳定性与跨领域适应力实现了显著跃升。 (硬刚复杂难题,挺实在的。)
部分任务上(CodeForces、LiveCodeBench、CreativeWriting-v3),Ring-1T 与早期版本持平甚至略有回落,但整体波动极小,说明系统在追求更广泛平衡的同时,依然保持高水位表现。
横向来看,Ring-1T 在多项测试中不仅全面领跑开源模型阵列,不少项目更是逼近闭源旗舰 GPT-5 表现,展现出强大的综合竞争力。
尤其在逻辑推理任务 ARC-AGI-v1上,Ring-1T 不仅刷新开源 SOTA,还显著领先 Gemini-2.5-Pro,展现出超越业界顶级闭源模型的推理实力;虽然距离当前最强的 GPT-5-Thinking (High)仍有差距,但 Ring-1T 的表现非常接近。
在综合能力测试 Arena-Hard-v2.0中,Ring-1T 仅落后GPT-5-Thinking(High)1分多,已跻身行业最顶尖梯队。
为了更客观评估 Ring-1T 的深度思考能力,蚂蚁让它去挑战最新、尚无公开答案的顶级赛题------ IMO 2025 和 ICPC World Finals 2025(国际大学生程序设计竞赛总决赛) 。结果,Ring-1T 在高强度数学与编程推理任务上,展现出接近顶级闭源模型的实力。
在 IMO 2025 中,6 道题中,它首轮就解出第 1、3、4、5 题,成绩相当于人类银牌水平。在难度极高的第 2 题上,经过三次推理后也给出接近满分的几何证明。唯一未解的第 6 题,其最终答案与 Gemini 2.5 Pro 收敛一致。



在 ICPC World Finals 2025 中,Ring-1T 在三次尝试内成功解出5题(DFJKL),表现超越 Gemini-2.5-Pro(3题),逼近 GPT-5-Thinking(6题)。
总体来看,Ring-1T 已成长为可与闭源巨头正面对话的选手,也是开源体系下闭源级性能的又一次实证。
一手实测
除了榜单数据,团队还展示了多个交互 Demo,让外界得以直观感受 Ring-1T 的推理与生成实力。我们也在第一时间体验了 Ring-1T,去感受这款「万亿思考模型」在真实任务中的推理、创造与表达。
自从 Andrej Karpathy 带火 vibe coding 概念后,开发者开始把更多的创意和直觉带入AI编程过程中。这次,我们就先来测试一下 Ring-1T 的代码能力。
我们输入提示词「生成一款简单可玩的 Flappy Bird 小游戏」,Ring-1T 迅速生成了完整的游戏代码,虽然画风稍微抽象了点,但它成功实现了游戏的交互功能。

再比如让 Ring-1T 生成一个简单的贪吃蛇小游戏。
Ring-1T 能够精准理解和应用复杂的逻辑要求,生成的游戏界面简洁,贪吃蛇移动与生长的动画丝滑,碰撞检测、分数系统、开始与暂停等功能均可顺利运行。
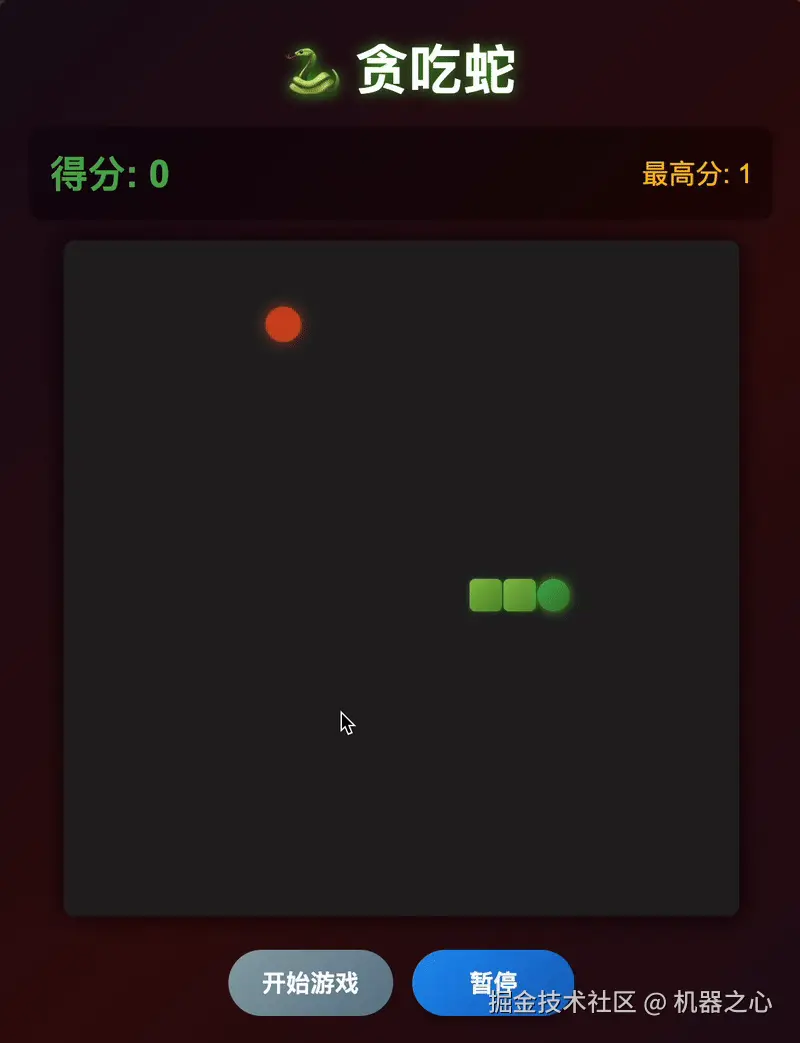 提示词:生成一个简单的贪吃蛇小游戏,要求包含以下功能:一个固定大小的网格,显示蛇和食物;蛇在网格上移动,玩家可以使用箭头键控制蛇的方向(上、下、左、右);每次蛇吃到食物后,蛇的长度增加,新的食物会出现在网格上的随机位置;当蛇撞到自己的身体或边界时,游戏结束,并显示最终得分;每吃到一块食物,分数增加,并显示当前分数;玩家可以开始和暂停游戏;蛇的移动应平滑,并显示蛇头和身体的不同部分;使用HTML、CSS和JavaScript实现游戏逻辑、动画效果,并确保游戏在桌面和移动设备上流畅运行。
提示词:生成一个简单的贪吃蛇小游戏,要求包含以下功能:一个固定大小的网格,显示蛇和食物;蛇在网格上移动,玩家可以使用箭头键控制蛇的方向(上、下、左、右);每次蛇吃到食物后,蛇的长度增加,新的食物会出现在网格上的随机位置;当蛇撞到自己的身体或边界时,游戏结束,并显示最终得分;每吃到一块食物,分数增加,并显示当前分数;玩家可以开始和暂停游戏;蛇的移动应平滑,并显示蛇头和身体的不同部分;使用HTML、CSS和JavaScript实现游戏逻辑、动画效果,并确保游戏在桌面和移动设备上流畅运行。
再比如让它编写一个 p5.js 脚本,模拟 25 个粒子在一个真空空间中的圆柱形容器内弹跳。

提示词:Write a p5.js script that simulates 25 particles in a vacuum space of a cylindrical container, bouncing within its boundaries. Use different colors for each ball and ensure they leave a trail showing their movement. Add a slow rotation of the container to give better view of what's going on in the scene. Make sure to create proper collision detection and physic rules to ensure particles remain in the container. Add an external spherical container. Add a slow zoom in and zoom out effect to the whole scene.
再来看看它的逻辑推理能力。
提示词:黑兔、灰兔和白兔三只兔子在赛跑。黑兔说:我跑的不是最快的,但比白兔快。请问谁跑的最快?谁跑的最慢?
这道推理题目相对简单,Ring-1T 的回答也没费多大劲,梳理题干信息、给出答案、验证答案,一气呵成。

提示词:地铁站内,一个女人大喊:「抢劫了!」罪犯拿着钱包跑的很快,保安追不到。经过一系列的工作,找到了四个嫌疑人。探长过来时,甲在椅子上昏昏欲睡,乙冷得缩成一团,丙不安的四处张望,丁在原地跑步取暖,请问谁的嫌疑最大?
Ring-1T准确识别出不同嫌疑人的行为与情境,并经过一系列推理,最终给出了正确答案。这种推理不仅依赖于对情境的理解,还考虑到了行为模式和心理状态的微妙差异。

提示词:在一个俱乐部里,只有老实人和骗子两类成员,老实人说真话,骗子说假话。一天,该俱乐部的四名成员在聊天。
甲说:我是老实人
乙说:我们当中有两个人是骗子
丙说:我们当中只有一个是骗子
丁说:我们四个都是骗子
谁一定是骗子?
这道逻辑题曲里拐弯,Ring-1T 颇费了些工夫,逐一分析四名成员的发言,并以表格的形式梳理出所有信息,最终得出正确答案。

此外,既然 Ring-1T 模型在数学竞赛方面达到了开源 SOTA 水平,我们就用2025 年全国中学生数学奥林匹克竞赛(预赛)中的一道题目考考它。
根据其思维链,我们发现 Ring-1T 思路非常清晰,先回顾奇函数和偶函数的定义,然后根据这两个条件列出方程,解出 f(x) 的表达式,最后准确求出最大值。

在创意写作方面,Ring-1T 模型的发挥很是稳定,尤其是讲故事的能力相当能打。
正好最近在听一些历史方面的播客,我们让它写一篇播客文案,介绍苏轼和章惇恩怨始末,为防止其胡说八道,还要求它引用相关的史实记载。
Ring-1T 能够灵活地把历史人物和事件融入生动的叙述中,生成的文案符合播客口语化风格,语言生动且具吸引力,甚至连音效都一一注明。

整体来说,Ring-1T是一款潜力很大的模型,在多个领域都展现出强大的实际应用价值。
在代码生成上,模型能够快速响应任务需求,生成符合逻辑的游戏代码,并确保交互性和功能完整;其推理能力精准且高效,能够理解复杂情境并给出合理解答;在创意写作领域,模型能够适应不同风格需求,生成引人入胜的内容。
当然,Ring-1T仍存在一些不足,特别是在身份认知、中英文混杂和重复等问题上。这些问题影响了模型的稳定性和一致性,未来的版本更新有望进一步优化。
小漏洞能沉船?
MoE大模型RL训练的「棒冰」救场
归根到底,数据背后体现的是强化学习算法 IcePop(「棒冰」) 与系统框架 ASystem 的深层合力。前者稳住长周期RL的基本盘,后者保证万亿规模的工程落地。
研发 Ring-1T 的最大硬骨头在后训练阶段,尤其是大规模强化学习「调教」。MoE 模型的常见「暗礁」,是训推不一致问题:
训练端与推理端在算子精度或实现上存在微小差异,但在多层路由、长序列自回归中被不断放大。结果就是------看似「正常训练」,实则已偏离策略,奖励信号混乱,梯度崩坏,训练翻车。
于是,IcePop 登场。
百灵大模型团队直接「抬走」坏梯度。它通过「双向截断 + Masked Clipping」 双重筛选机制,实时监控每个 token 在训推两端的概率差异,当信号「温度」过高或过低时立即打掩码------拒学坏信号,只更新稳定梯度。
不同于 TIS 的「调权继续学」,IcePop 的策略是「宁可不学,也不能学错」。它让模型只吸收「干净卡路里」,拒绝坏梯度输入。
结果立竿见影。在长周期训练下,GRPO 的训推差异曲线一路飙升,而 IcePop 曲线稳定、峰值显著下降------仿佛给过热的系统喂了一根「棒冰」。
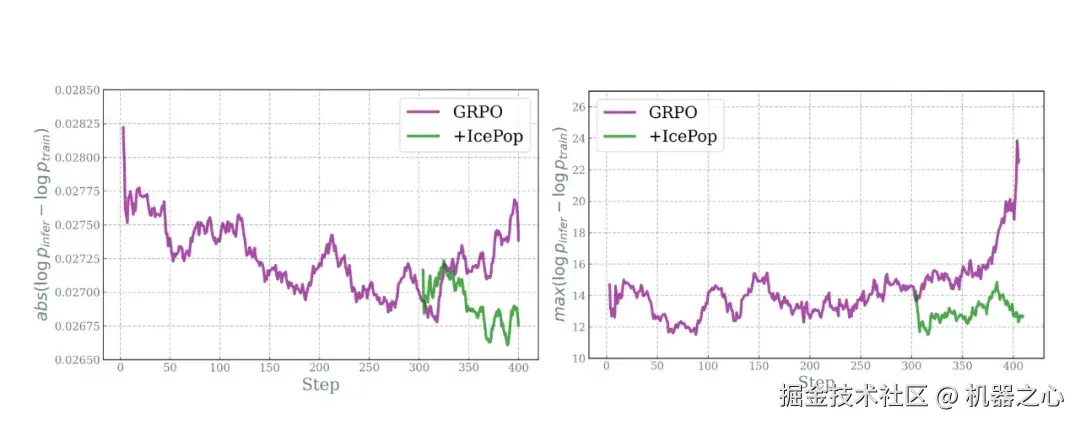
标准GRPO在短程还能稳住,但训练百步后很快「高烧」,奖励信号失真,梯度暴冲,训练直接翻车。图1:GRPO训推差异随着训练成指数上升,Icepop较为平稳; 图2:训推差异最大值,GRPO随着训练上升非常明显,Icepop维持在较低水位。
IcePop 不仅让 MoE 模型在 AIME25 等复杂推理任务上成绩更优,还让模型输出更稳、更具多样性,低概率 token 也有被探索的机会。
研究进一步发现,被 IcePop 剔除的往往是高熵、高纠结的 token------正是最容易被训推偏差污染的信号。IcePop 彻底切断了坏梯度的「感染链」,让训练更加健康可靠。
幕后英雄 :
自研RL框架,「拿捏」万亿规模训练
要让「棒冰」算法在超大规模训练中稳定、高速运行,离不开底层系统的支撑。为此,蚂蚁自研了强化学习基础框架 ASystem,解决硬件资源调度与效率瓶颈,为模型「自我调教」铺平道路。
它采用 SingleController + SPMD 架构:上层有「大脑」统一策略,下层海量执行单元并行推进,既保证训练一致性,又释放最大吞吐力。
在万亿参数的 MoE 训练中,强化学习频繁切换「训练---推理」模式,显存极易爆满,权重交换又耗时。ASystem 通过显存透明卸载与跨节点显存池化技术,把零碎显存整合成共享池,极大降低了 OOM 风险,让训练稳定性获得根本提升。
在权重交换与同步上,它用 GPU P2P直连 + 原地更新技术,绕过CPU中转------就像两艘船在海上直接交货,不必再靠岸,权重因此能实现秒级 交换,真正做到「零冗余切换」。
强化学习的另一瓶颈是奖励评估。模型要通过试错不断学习,每次动作都要经过评估与反馈。尤其在涉及执行代码或复杂逻辑的场景里,这些奖励评估必须在安全沙箱环境中完成,而传统沙箱启动缓慢,往往成为训练提速的最大拖尾。
ASystem 把**大规模 Serverless Sandbox **直接接入强化学习回路,打造出混合奖励平台。沙箱可以毫秒级冷启动,支持十余种语言环境即开即用,工具链随取随用。吞吐量能撑到 10K/s,评测不再卡脖子。
AI 的竞争,从来不只是「谁的模型更强」,而是路线进化之争。
9 月,蚂蚁用一场「开源风暴」将这场辩题推向高潮:百灵大模型团队密集上线 7 款新品,平均每 4 天一个新模型;进入 10 月,又连发两款。
更关键的是,蚂蚁开源的不止是模型,还有让模型能持续进化的底层能力。例如,ASystem 的强化学习框架 AReaL已在今年 3 月开源,让社区能直接复用蚂蚁在 RL 工程上的积累,加速强化学习研究与训练创新。
对蚂蚁而言,开源不仅是开放代码,更是一条让 AI 普惠落地的现实路径。当这些能力被广泛调用,AI 才能像电力与支付那样------无感,却又无处不在。