一、整体背景与目标
以 MNIST 手写数字数据集为对象,借助 PyTorch 框架搭建神经网络,完成 "手写数字分类识别" 任务,同时熟悉nn等工具箱的使用,建立对神经网络流程的直观认知。
二、核心步骤与关键操作
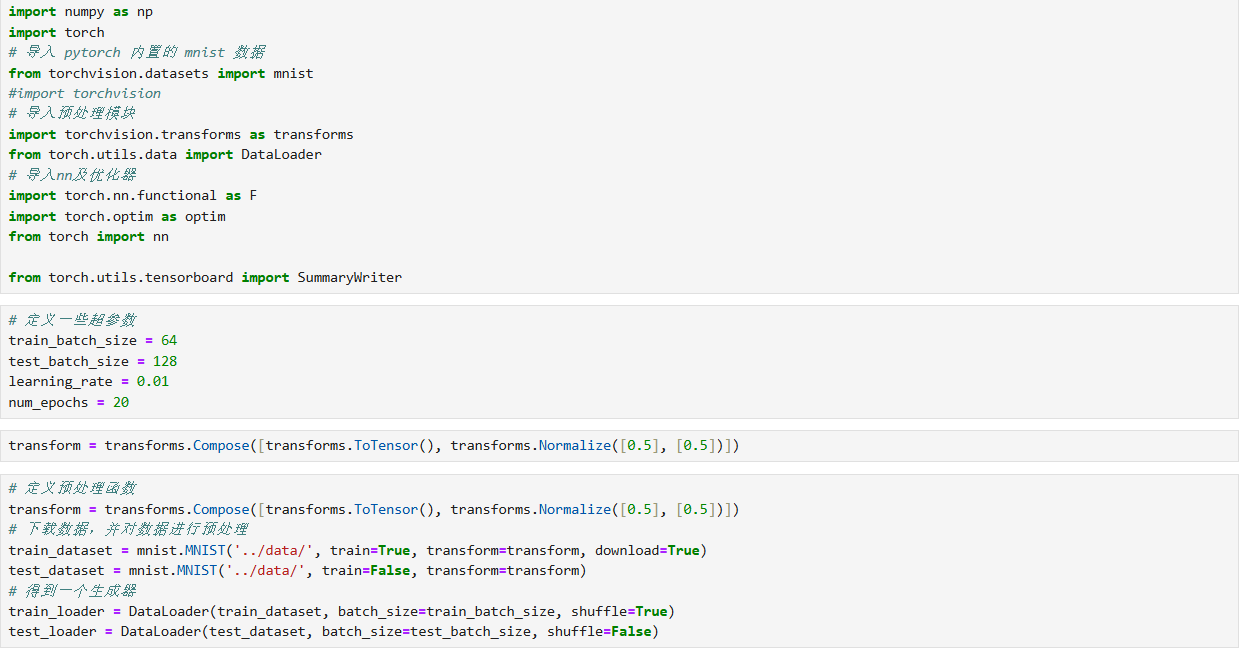
1. 数据准备:从下载到迭代器构建
- 库与超参数 :导入
numpy、torch、torchvision等库,定义batch_size(训练 64、测试 128)、learning_rate(0.01)、num_epochs(20)等超参数。 - 预处理与加载 :通过
transforms将图像转张量(ToTensor)并归一化(Normalize);利用MNIST数据集类下载数据,再通过DataLoader创建 "批量读取 + 打乱" 的训练 / 测试数据迭代器,为后续训练提供数据输入。
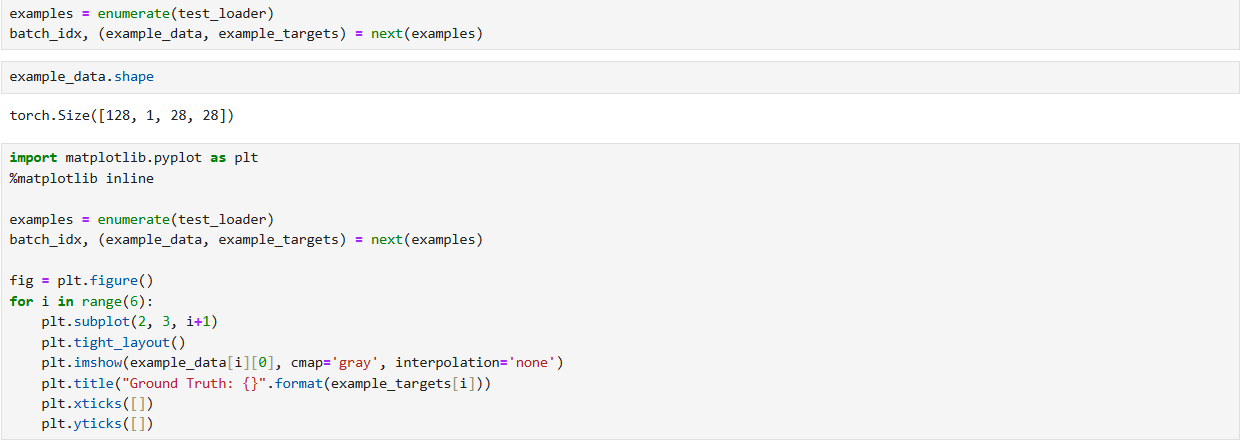
2. 数据可视化:直观验证数据形态
使用matplotlib绘制测试集样本,展示手写数字图像及其真实标签(如 "7""2""1" 等),直观确认 "图像 - 标签" 的对应关系,为后续模型效果提供 "直观参照"。
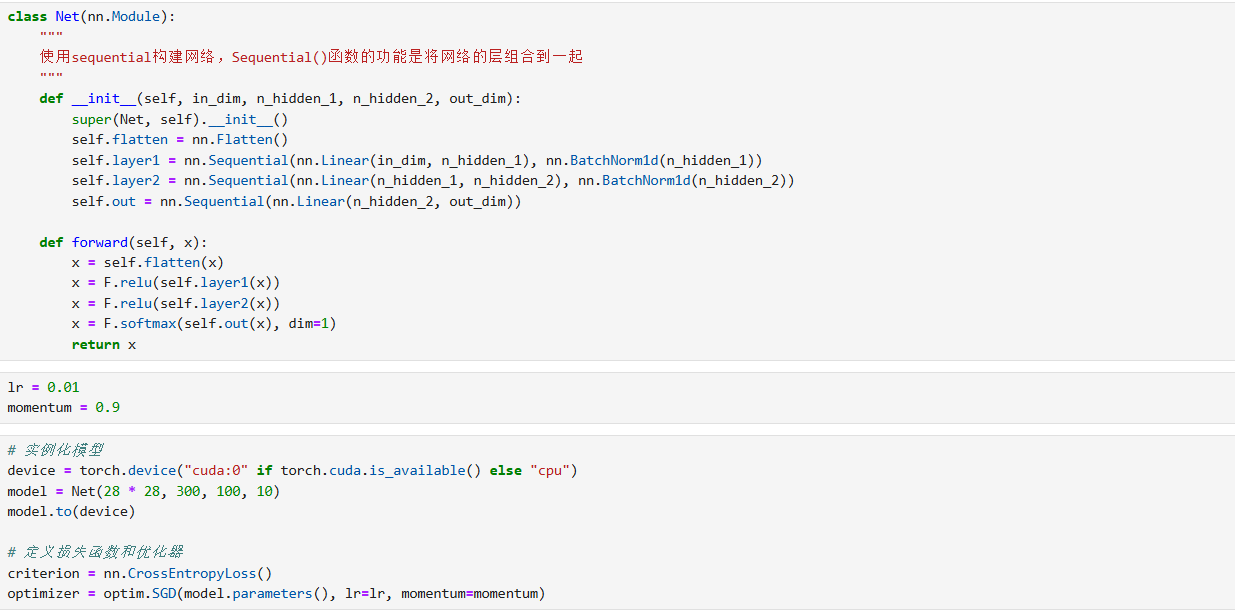
3. 模型构建:神经网络的层次设计
定义继承nn.Module的Net类,通过Sequential组合网络层:
- 输入处理 :用
Flatten将 28×28 的图像展平为一维向量(784 维)。 - 隐含层 :设计两层 "线性层 + 批归一化(
BatchNorm1d)" 结构,配合ReLU激活函数引入非线性。 - 输出层 :线性层输出 10 类(对应 0-9 数字),再通过
Softmax(dim=1)将输出转为 "每类的概率分布"。
4. 模型配置与训练:从初始化到迭代优化
- 实例化与设备适配 :根据硬件(GPU/CPU)选择计算设备,初始化模型并迁移到对应设备;定义损失函数(
CrossEntropyLoss,适配多分类任务)与优化器(SGD,带momentum=0.9加速收敛)。 - 训练流程 :每个
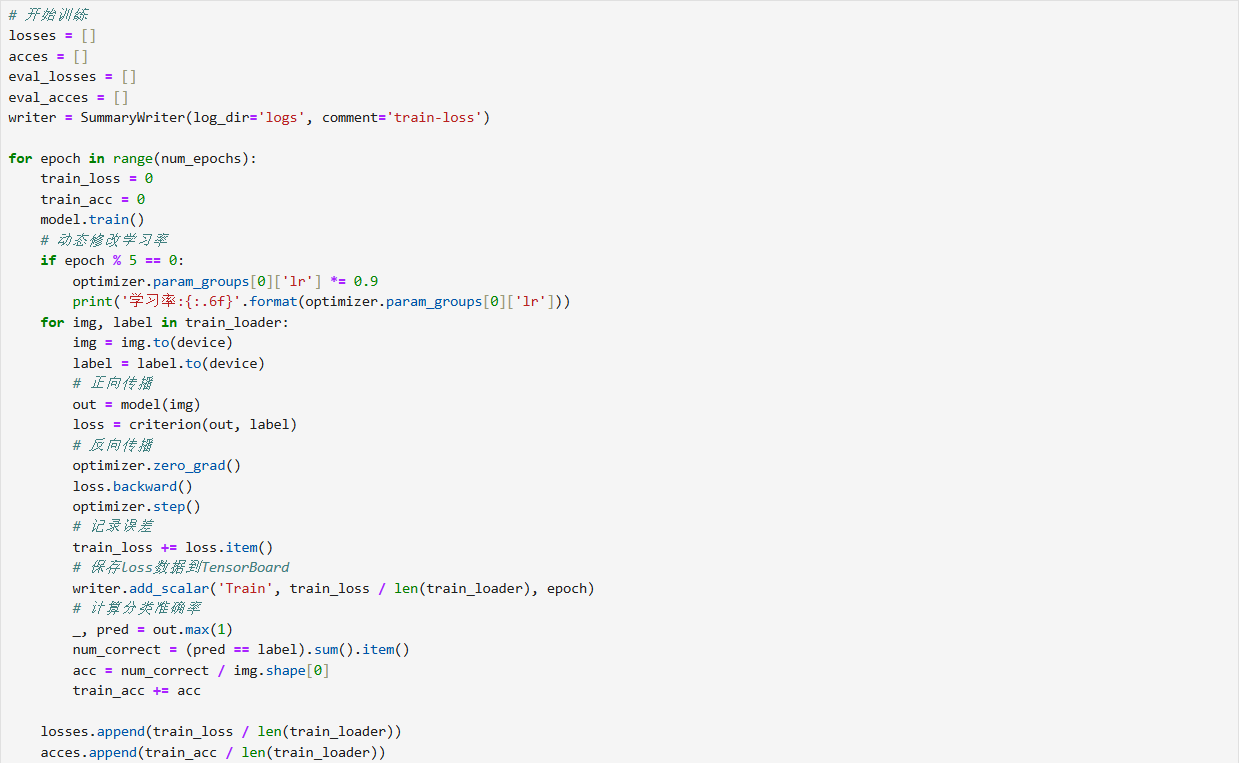
epoch分为 "训练" 与 "测试" 阶段:- 训练时,模型设为
train()模式,遍历训练数据,执行正向传播 (算预测与损失)、反向传播 (算梯度并更新参数),同时动态调整学习率(每 5 个epoch缩小为原 0.9 倍),记录训练损失与准确率。 - 测试时,模型设为
eval()模式(关闭梯度计算),遍历测试数据,评估模型在 "unseen 数据" 上的损失与准确率,验证泛化能力。
- 训练时,模型设为
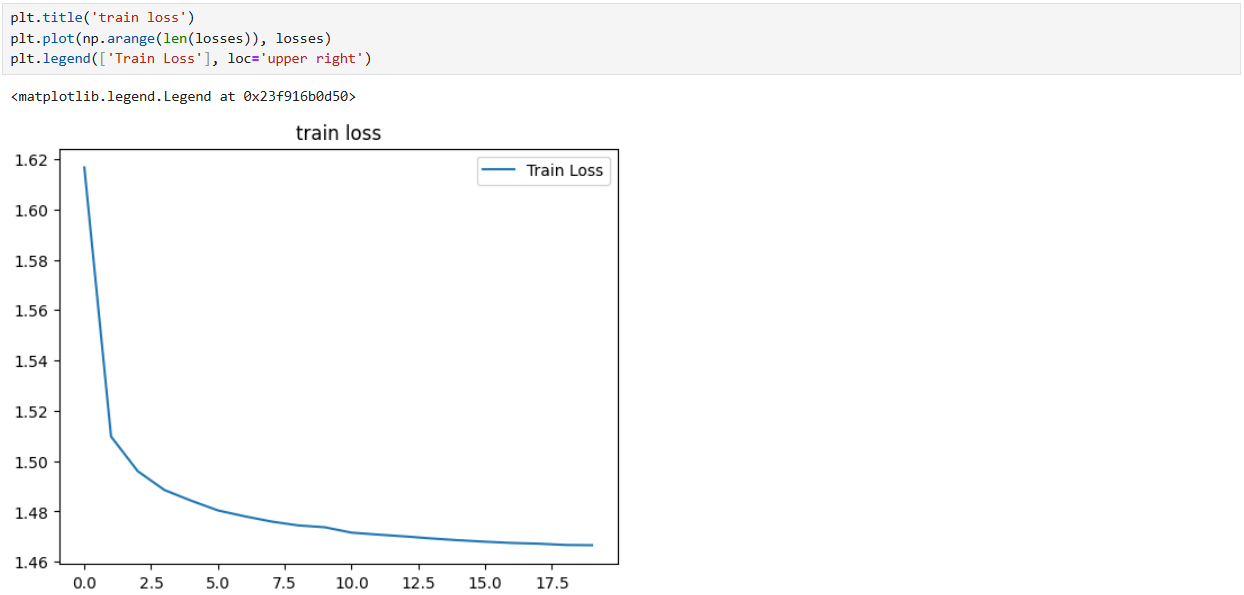
5. 结果可视化:训练效果的直观呈现
绘制 "训练损失曲线",可见损失随epoch增加逐渐下降,说明模型通过训练持续学习、拟合数据,分类能力逐步提升。
三、流程价值与总结
整个过程完整覆盖 "数据处理 - 模型构建 - 训练评估 - 结果可视化" 的深度学习核心环节,既展示了 PyTorch 在神经网络开发中的便捷性,也通过 MNIST 实例直观呈现了 "神经网络如何学习手写数字特征并完成分类" 的过程。从损失曲线与测试准确率可验证:模型有效学习了数据模式,实现了手写数字的准确识别。
四、代码示例