深度学习的核心魅力之一,在于深层神经网络能处理复杂的多分类问题 ------ 比如经典的 MNIST 手写数字识别。今天我们会从 "多分类问题的核心逻辑" 到 "深层神经网络实战代码",把 MNIST 分类的全流程讲透,新手也能跟着跑通完整代码,理解深层网络的工作原理。
一、先搞懂:多分类问题和二分类有啥不一样?
之前我们学过二分类(比如判断苹果 / 橘子),而 MNIST 是10 分类问题(区分 0-9 手写数字),核心差异在于:
- 二分类:用 Sigmoid 函数输出 "属于某一类的概率"(0~1),loss 函数用二分类交叉熵;
- 多分类:需要知道 "属于每一类的概率"(比如数字 5 的概率 0.9,数字 3 的概率 0.05),这就需要两个关键工具 ------Softmax 函数和多分类交叉熵损失。
1. Softmax 函数:把输出变成 "概率分布"
Softmax 是 Sigmoid 的多分类升级版,核心作用是:将网络输出的任意数值,转换成 "和为 1 的概率"(每一项对应属于某一类的概率)。
公式逻辑
假设网络对某张手写数字图片的输出是 z1, z2, ..., z10(对应 0-9 的原始得分),Softmax 会做两步操作:
- 对每个输出取指数:
e^z1, e^z2, ..., e^z10(保证数值非负); - 每个指数值除以所有指数值的和:
p_i = e^zi / ∑(e^zj)(i 从 1 到 10)。
最终所有p_i的和为 1,比如p5=0.9就表示 "这张图有 90% 概率是数字 5"。
2. 交叉熵损失:衡量 "预测概率" 和 "真实标签" 的差距
交叉熵是衡量两个概率分布相似性的指标,多分类交叉熵是二分类的扩展:
- 核心公式:
cross_entropy(p, q) = -1/m * ∑(p(x) * log(q(x))); - 通俗理解:真实标签是 "one-hot 编码"(比如数字 5 对应
[0,0,0,0,0,1,0,0,0,0]),预测概率是 Softmax 输出的分布,交叉熵越小,说明预测越接近真实标签。
二、MNIST 数据集:深度学习的 "入门练手神器"
MNIST 是手写数字数据集,堪称深度学习的 "Hello World",先搞懂它的基本信息:
1. 数据集构成
- 训练集:60000 张手写数字图片,来自 250 个不同人手写(50% 高中生、50% 人口普查局工作人员);
- 测试集:10000 张手写数字图片,比例与训练集一致;
- 每张图片:28×28 像素的灰度图(像素值 0 = 黑色,255 = 白色),任务是判断图片属于 0-9 中的哪一个数字。

2. 数据预处理:从 "图片" 到 "网络能认的格式"
原始 MNIST 数据是 PIL 图片格式,必须转换成 Tensor 才能输入神经网络,核心步骤:
- 标准化:
x = (x - 0.5) / 0.5(把像素值从 0-255 压缩到 - 1~1,让梯度更稳定); - 拉平:28×28 的二维图片→784 维一维向量(神经网络第一层输入需要一维特征);
- 批量加载:用
DataLoader按批次加载数据(避免一次性加载 60000 张图片占满内存)。
三、深层神经网络实战:MNIST 分类全代码解析
我们用 PyTorch 搭建一个 4 层全连接神经网络(输入层 + 3 个隐藏层 + 输出层),完成 MNIST 分类,每一步都标注清楚逻辑。
1. 导入工具包
import numpy as np
import torch
from torchvision.datasets import mnist
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt2. 加载并预处理 MNIST 数据集
# 数据变换函数:标准化+拉平+转Tensor
def data_tf(x):
x = np.array(x, dtype='float32') / 255 # 像素值归一化到0~1
x = (x - 0.5) / 0.5 # 标准化到-1~1
x = x.reshape((-1,)) # 28×28→784维一维向量
x = torch.from_numpy(x)
return x
# 加载数据集(自动下载,应用数据变换)
train_set = mnist.MNIST('./data', train=True, transform=data_tf, download=True)
test_set = mnist.MNIST('./data', train=False, transform=data_tf, download=True)
# 批量加载数据(训练集批次64,测试集128,训练集打乱顺序)
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
test_data = DataLoader(test_set, batch_size=128, shuffle=False)3. 搭建深层神经网络
用nn.Sequential快速搭建 4 层网络,激活函数用 ReLU(解决梯度消失问题,让深层网络能训练):
net = nn.Sequential(
nn.Linear(784, 400), # 输入层:784维(图片拉平)→隐藏层1:400维
nn.ReLU(), # 激活函数:引入非线性
nn.Linear(400, 200), # 隐藏层1→隐藏层2:200维
nn.ReLU(),
nn.Linear(200, 100), # 隐藏层2→隐藏层3:100维
nn.ReLU(),
nn.Linear(100, 10) # 输出层:100维→10维(对应0-9的得分)
)4. 定义损失函数和优化器
-
损失函数:
nn.CrossEntropyLoss()(PyTorch 内置多分类交叉熵,自动包含 Softmax 操作); -
优化器:SGD(随机梯度下降),学习率 0.1(深层网络学习率可适当大一点)。
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=1e-1)
5. 训练网络:核心是 "前向传播→算损失→反向传播→更新参数"
# 记录训练/测试的损失和准确率
losses = []
acces = []
eval_losses = []
eval_acces = []
# 训练20轮(epoch)
for e in range(20):
# 训练模式:启用Dropout/BatchNorm等训练相关层
net.train()
train_loss = 0
train_acc = 0
# 遍历训练集批次数据
for im, label in train_data:
im = Variable(im)
label = Variable(label)
# 1. 前向传播:输入图片,得到输出
out = net(im)
# 2. 计算损失
loss = criterion(out, label)
# 3. 清空梯度(避免累加)
optimizer.zero_grad()
# 4. 反向传播:计算梯度
loss.backward()
# 5. 更新参数
optimizer.step()
# 累计训练损失和准确率
train_loss += loss.data.item()
# 取输出最大值的索引(即预测的数字)
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / im.shape[0]
train_acc += acc
# 记录训练集平均损失和准确率
losses.append(train_loss / len(train_data))
acces.append(train_acc / len(train_data))
# 测试模式:关闭Dropout/BatchNorm,评估模型
net.eval()
eval_loss = 0
eval_acc = 0
for im, label in test_data:
im = Variable(im)
label = Variable(label)
out = net(im)
loss = criterion(out, label)
# 累计测试损失和准确率
eval_loss += loss.data.item()
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / im.shape[0]
eval_acc += acc
# 记录测试集平均损失和准确率
eval_losses.append(eval_loss / len(test_data))
eval_acces.append(eval_acc / len(test_data))
# 打印每轮训练结果
print('epoch: {}, Train Loss: {:.6f}, Train Acc: {:.6f}, Eval Loss: {:.6f}, Eval Acc: {:.6f}'.format(
e, train_loss / len(train_data), train_acc / len(train_data),
eval_loss / len(test_data), eval_acc / len(test_data)
))6. 可视化训练结果
训练完成后,用 matplotlib 画出损失和准确率的变化曲线,直观看到模型的学习效果:
# 训练损失曲线
plt.title('Train Loss')
plt.plot(np.arange(len(losses)), losses)
plt.show()
# 训练准确率曲线
plt.title('Train Acc')
plt.plot(np.arange(len(acces)), acces)
plt.show()
# 测试损失曲线
plt.title('Test Loss')
plt.plot(np.arange(len(eval_losses)), eval_losses)
plt.show()
# 测试准确率曲线
plt.title('Test Acc')
plt.plot(np.arange(len(eval_acces)), eval_acces)
plt.show()7. 预期结果
训练 20 轮后,你会看到:
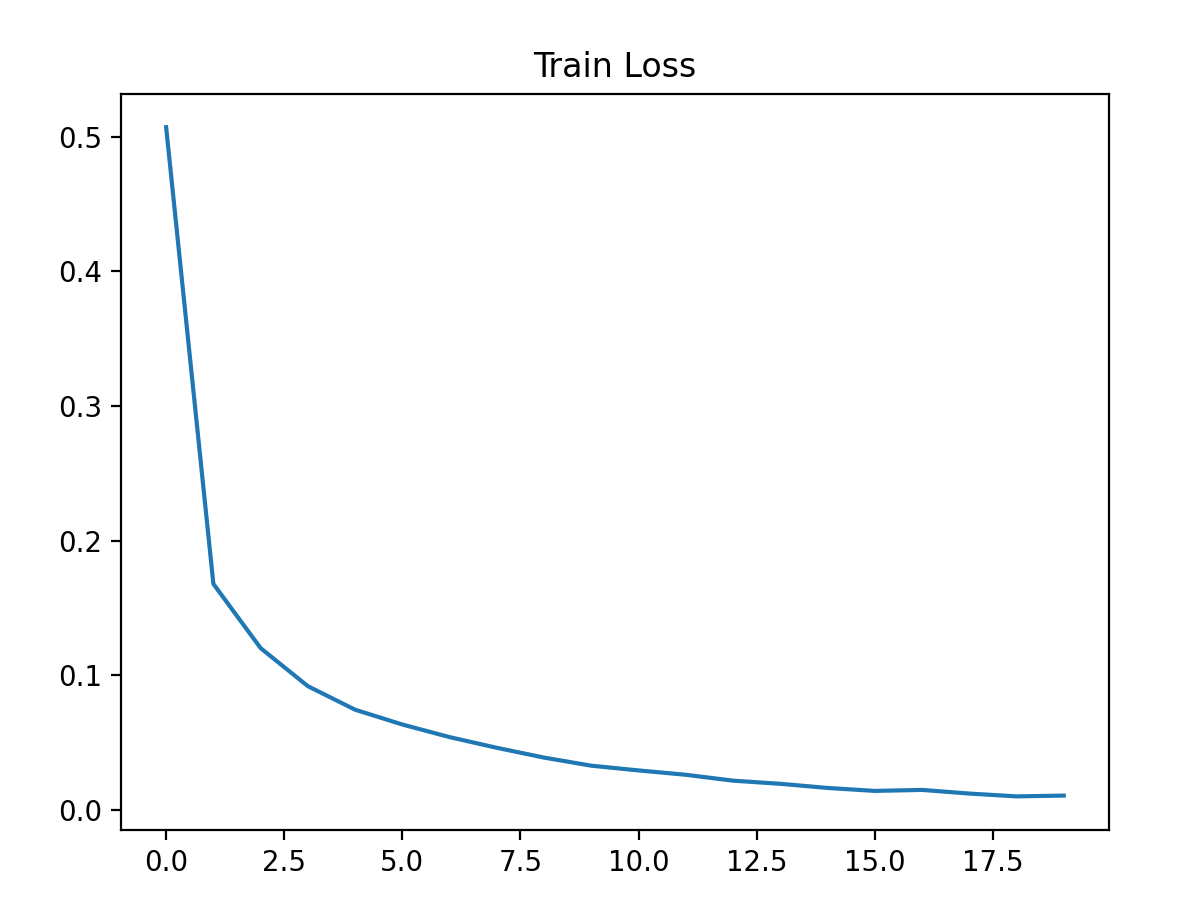
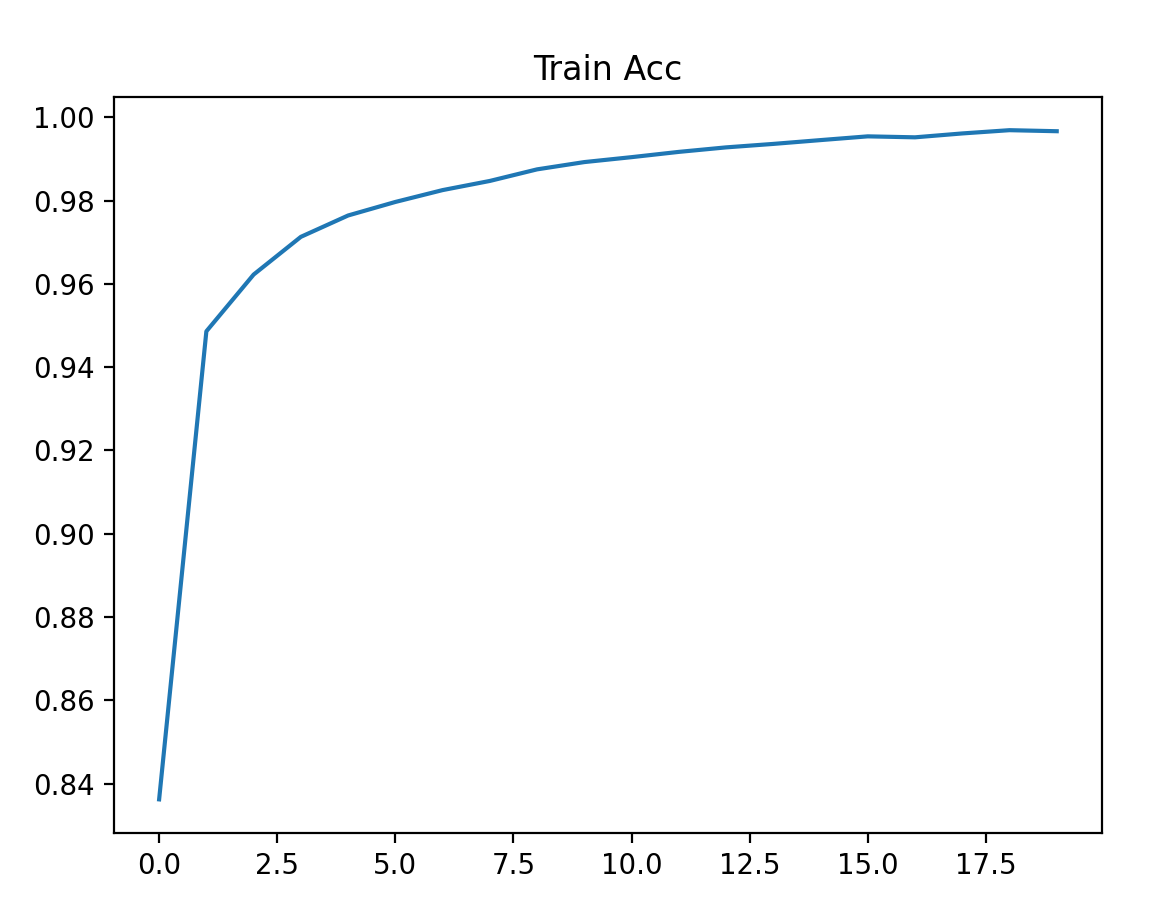
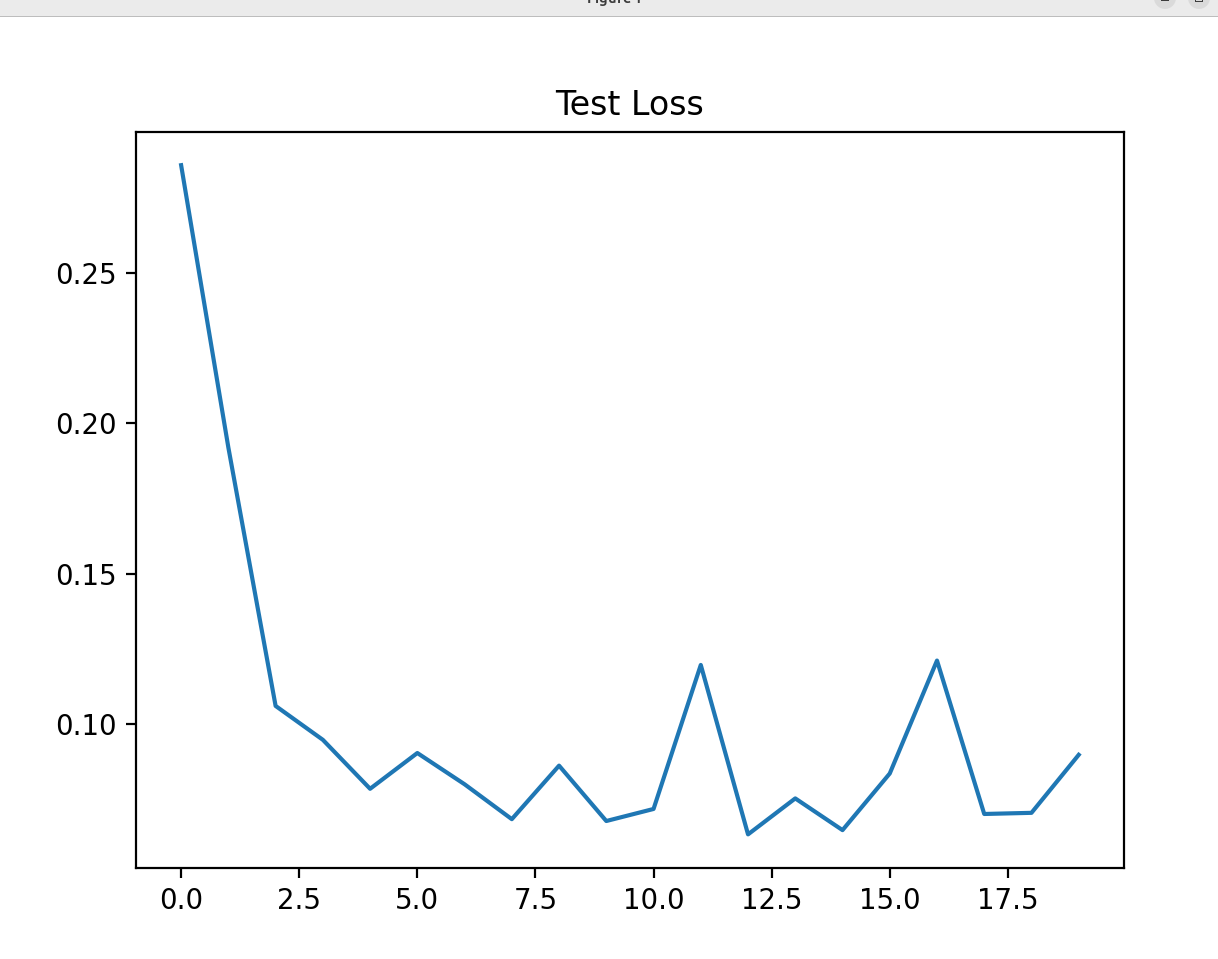
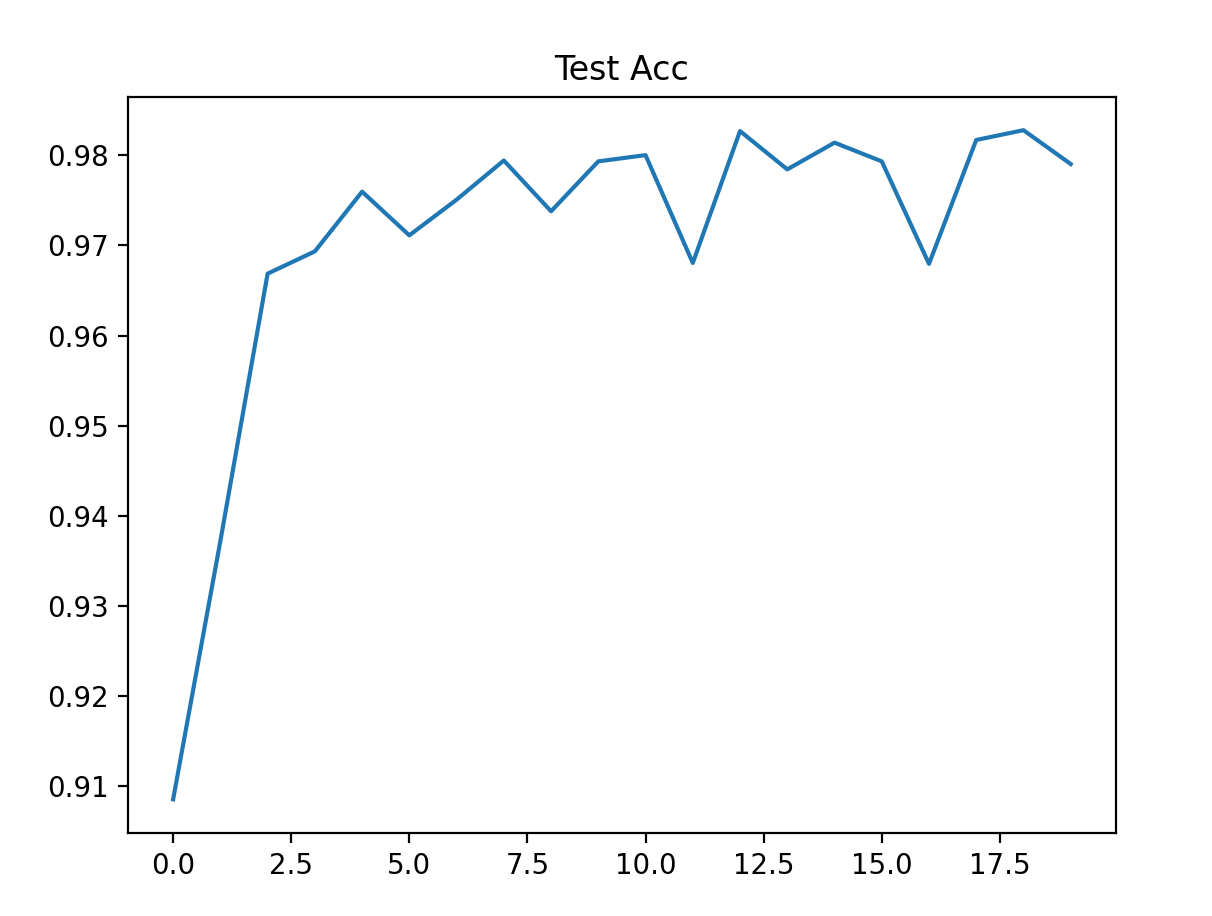

- 训练损失从 0.5 + 降到 0.01 左右,训练准确率从 83% 升到 99.8%+;
- 测试损失稳定在 0.07 左右,测试准确率达到 98%+;
- 曲线趋势:训练损失持续下降,测试准确率先升后稳(说明模型未过拟合)。
四、关键知识点总结
- 多分类核心工具 :
- Softmax:把网络输出转成 "和为 1 的概率分布",对应每一类的概率;
- 多分类交叉熵:衡量预测概率与真实标签的差距,是多分类问题的标配损失函数。
- MNIST 数据预处理 :
- 拉平:28×28 图片→784 维向量(全连接网络只能处理一维输入);
- 标准化:把像素值压缩到 - 1~1,避免梯度过大导致训练不稳定。
- 深层神经网络设计 :
- 隐藏层:增加层数 / 神经元数,能拟合更复杂的特征(但层数过多易过拟合);
- 激活函数:ReLU 替代 Sigmoid,解决深层网络的梯度消失问题;
- 训练 / 测试模式:
net.train()/net.eval()必须切换,避免测试时激活训练相关层。
- 训练关键步骤 :
- 清空梯度:
optimizer.zero_grad()(梯度累加会导致参数更新错误); - 模式切换:训练用
net.train(),测试用net.eval()(影响 Dropout/BatchNorm); - 批量加载:
DataLoader避免内存溢出,同时打乱训练集提升泛化能力。
- 清空梯度:
五、拓展训练:试试调整网络参数
想要更深入理解深层网络,可尝试修改参数,观察结果变化:
- 改变隐藏层数目:比如去掉一层隐藏层(784→400→10),看准确率是否下降;
- 更换激活函数:把 ReLU 换成 Tanh,对比训练速度和准确率;
- 调整学习率:把 SGD 的学习率改成 0.01/0.5,看训练是否变慢 / 震荡;
- 增加训练轮数:训练 50 轮,看是否出现过拟合(测试准确率下降)。
六、最终结论
深层神经网络之所以能搞定 MNIST 这种复杂的多分类问题,核心是:
- 多层隐藏层能提取图片的 "层次化特征"(比如先提取边缘,再提取笔画,最后提取数字形状);
- Softmax + 交叉熵让模型能精准输出 "属于每一类的概率",梯度下降则不断优化参数,让预测越来越准。
跟着这篇文章跑通代码,你不仅能完成 MNIST 分类,还能理解深层神经网络的核心逻辑 ------ 这是后续学习卷积神经网络(CNN)、循环神经网络(RNN)的重要基础。
