本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
随着大型语言模型(LLM)的发展,为模型配备外部知识库成为提升其能力的关键手段之一。所谓知识库,可以理解为模型的"外部记忆":将海量文档、资料以某种形式提供给模型,帮助它回答超出训练范围的问题。
这通常采用检索增强生成 (Retrieval-Augmented Generation, RAG)的方案,即向量检索 * + LLM *生成。简单来说,RAG流程如下:
向量嵌入:先将知识库中的每篇文档切分成段落,并用算法将每段文字转换成向量(一串数字),使机器能"理解"其语义。
语义检索 :用户提问时,也将问题转换为向量,在向量数据库中寻找"距离"最近的文档段落,即语义上最相关的内容。这种向量检索不依赖关键字精确匹配,而是通过embedding捕捉文本语义,能找到包含同义表达的内容。例如,搜索代码库里的"用户认证",向量检索可返回包含"login"、"authenticate"等词的相关函数,即使没有出现精确的"用户认证"字样。
增强生成:将检索出的相关文本段一起附加到用户提问上,发送给LLM。模型在这些"提示"基础上生成答案,从而引用知识库信息,提高准确性。
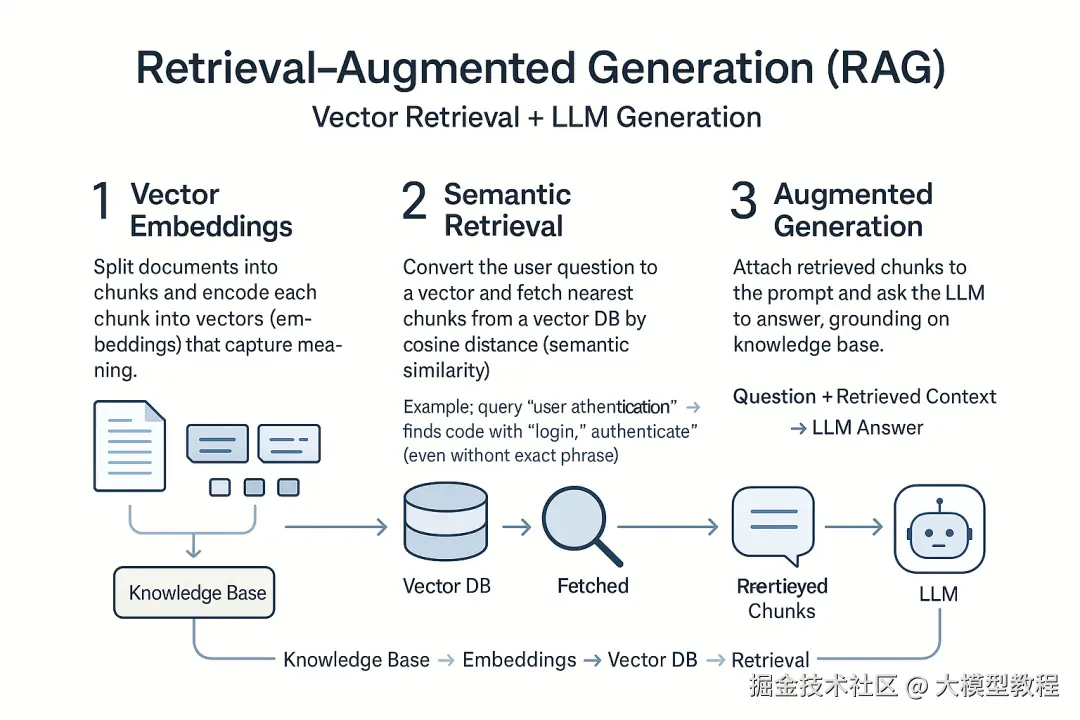
上述流程将LLM与知识库结合,弥补了纯LLM易胡编乱造、知识截止等缺点 。它让AI像搜索引擎一样查资料,又能用自然语言生成结果,已被广泛用于问答助手、代码助手等产品。
传统 RAG 方法的优势与局限
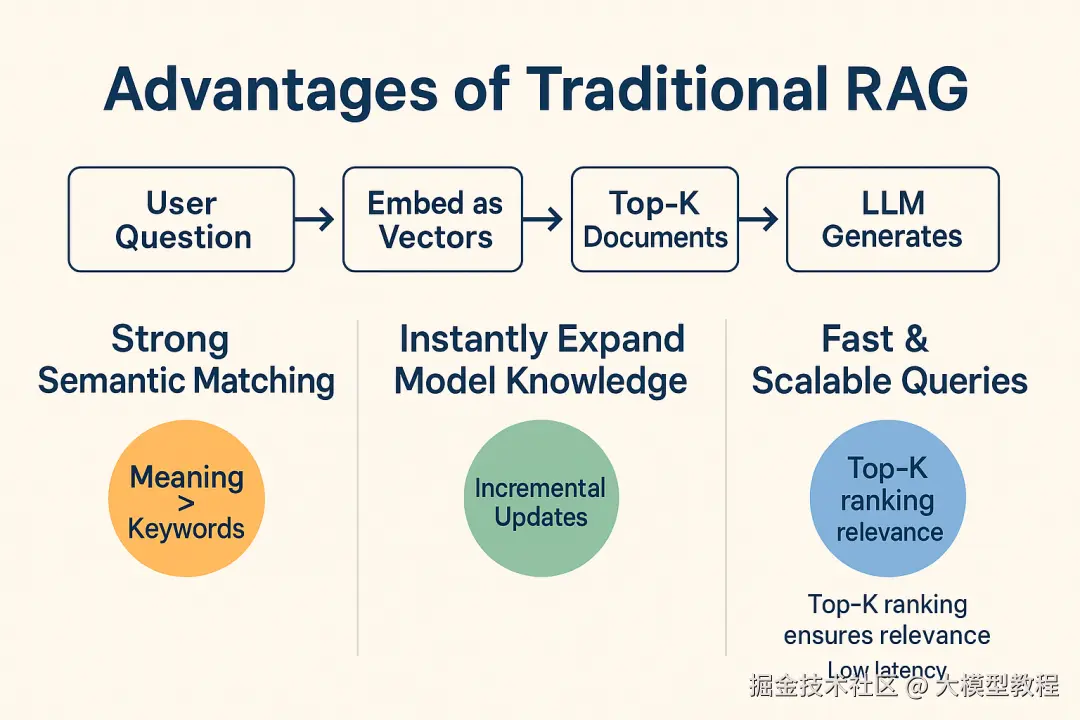
优势: 传统RAG方法简单有效,是当前业界应用最广的方案。其优点在于:首先,语义匹配能力强 。通过向量表示,模型能基于含义 而非关键词找到相关内容。这使用户不必精确记忆知识库里的措辞,用自己的语言提问也能检索到答案。例如,上述向量检索能跨越不同表述找到同一概念的资料。其次,RAG可以即时扩充模型知识 。当有新文档加入,只需更新向量索引,模型就能检索并利用最新信息回答问题,这解决了LLM训练后知识固化的问题。此外,向量数据库经过优化,查询速度快,能应对大规模知识库,并支持Top-K排序确保返回最相关内容。
局限: 然而,基础RAG系统也存在不少不足。首先,忽视文档结构 。经典RAG将文档机械地切成独立片段,丢失了章节层次和上下文连贯性。如果答案涉及多个段落关联或跨章节的信息,简单的相似度检索往往顾及不到。将长文档硬切会破坏其自然逻辑flow,导致模型生成时缺乏重要上下文。其次,检索精度依赖嵌入质量 。当向量匹配失灵时,调试问题常变成噩梦------究竟是嵌入向量没表示出关键细节?语义空间偏差?还是索引过期未包含最新内容?。向量检索有时匹配的是大致相关的段落,却未必包含问题所需的具体事实。相反,传统关键字搜索(如grep)行为简单可预期:搜索不到某关键词,就说明文档里没有,这种确定性在诊断检索问题时非常宝贵。再次,段落截断与顺序问题 也会影响效果。RAG常按固定长度截断文本,可能把紧密关联的信息分散在不同片段中,导致检索返回的碎片各自孤立,模型难以拼凑完整答。而当检索返回多个片段时,如何排序放入Prompt也有讲究。如果关键内容被排在中间,模型注意力可能不足,出现"中段遗失"现象,大幅降低答案准确率。最后,维护大规模向量索引也有成本与隐私问题:定期嵌入新数据、监控向量库性能都增加复杂度;向量可能泄露原文信息,需要防范embedding反推原文的风险。
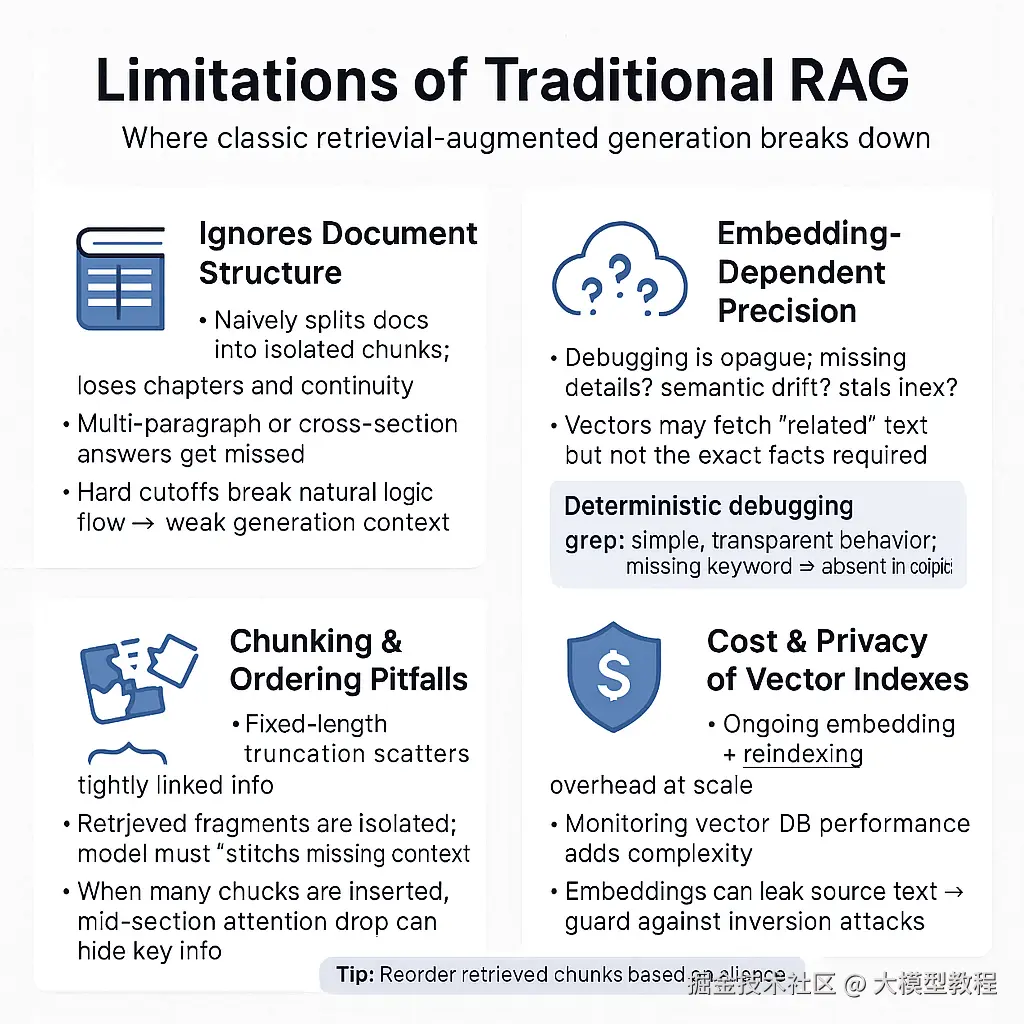
概括来说,传统RAG扩展了LLM知识却引入新的挑战------ "聪明"的向量索引有时反而带来不可控性。这促使业界探索替代方案,来缓解RAG在文档结构利用和检索可靠性方面的不足。
智能 Agent 方案:让模型主动理解与检索
针对上述局限,我们发现利用智能 * Agent*(智能体)的方法构建知识库,即赋予大模型类似人类研究员的能力:让它主动"阅读"文档结构,自己决定去哪里查找信息,而非被动依赖向量匹配。其核心思想包括:
·利用LLM理解文档结构: 让大型模型(如DeepSeek/GPT-4/5)预先获取知识库的目录、大纲或摘要信息,对资料的组织结构形成全局认识。比如,提供给模型某份手册的目录树或章节摘要,模型便知道答案可能在哪一章。这就像图书管理员先告诉AI每本书有哪些章节,每章讲什么。这一步赋予模型上下文导航能力,弥补了向量检索对结构视野的缺失。
·生成关键词指令(grep * 搜索):模型在理解结构后,可以基于用户问题语义,生成更精细的检索指令,而不只是笼统匹配embedding。例如,模型推理出需要在"第3章安全规范"中查找关于"密码重置"的描述,它可以构造一个grep命令,如grep -R "密码重置"第3章文档.txt,去精确搜索包含相关关键词的句子。这一步相当于模型 自主决策检索策略 :当简单关键词足够,它就直接用;若需要更复杂模式(正则表达式)也能尝试。相比纯向量相似度,LLM生成的grep指令结合了人类先验*(例如可能的措辞、关键字段),往往更聚焦。
·本地文档搜索及阅读: 执行模型生成的grep指令,在本地文档库中快速查找匹配内容。grep属于成熟的文本搜索工具,哪怕在百万行文本中定位关键词也只需秒级时间,而且无需预建索引。找到的相关段落将反馈给LLM,作为新增上下文。模型再结合这些段落进行深度分析与回答生成。这一步类似AI让计算机"打开书翻到某页并摘录几行",然后AI自阅自答。
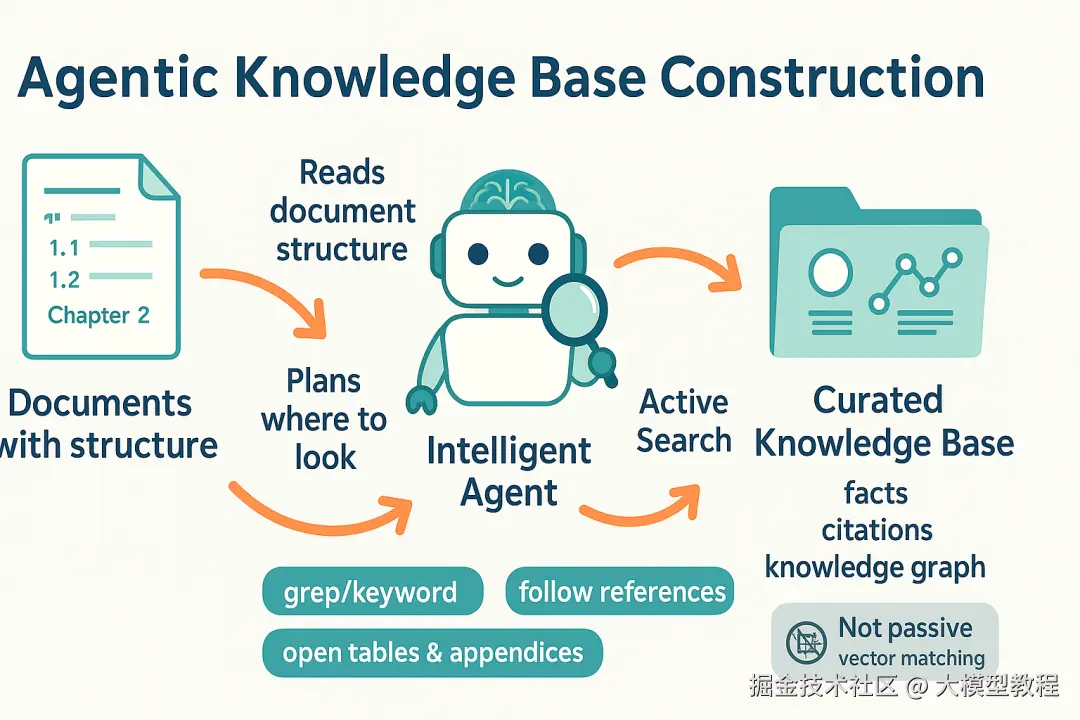
上述过程可以由Agent自动循环进行:如果初次搜索结果不充分,模型可基于已有信息继续提出新的搜索指令,逐步逼近答案。这种方法本质上是让模型参与检索回路:LLM不再仅是终点,而是置身检索过程的中间,发挥其语言理解和推理优势来指导检索。它突破了单轮向量搜索的限制,使检索更像人类专家查资料的过程。
智能Agent方法的数据流:LLMAgent先获取文档目录/摘要,从而确定检索范围,接着生成 grep 等搜索指令在本地文档中查找相关内容,找到文本片段后再反馈给模型用于回答。
这种Agent方案被证明在一些场景下效果惊人。例如,Anthropic的 Boris Cherny(Claude Code 项目负责人)分享,他们尝试了向量索引等多种方案,最终选择了每次实时抓取文档内容的"agentic * *search"方案,性能"大幅超越"其他方案 。具体而言,Claude的编程助手不预先构建代码索引,而是在需要时用glob、grep等Unix工具搜索代码。虽然听起来"倒退",却因其简洁直接,在代码生成任务上效果极佳。Lance Martin 今年的一项实验也支持了这一思路:他让AIAgent从一个含300万标记的多语言文档库中找答案,结果显示让Agent基于文档描述自主选择并逐步打开文件阅读**的方案效果最佳,优于一次性向量搜索整个知识库。这说明,大模型只需配备基础文件访问能力并给予必要的结构线索,往往就能取得不错效果。同时,还避免了复杂索引带来的高成本和高维护负担。

通过智能Agent方法,模型可以"按需取用"知识:该看的文件看,该找的关键词找,从而更充分地利用文档结构和上下文细节。相比之下,传统RAG那种对文档片段静态、盲目的召回,显得缺乏灵活性和深度。Agent不仅提升了检索召回的准确性,也让回答过程更可控、更透明------因为每一步搜索和内容引用都有迹可循,这对产品的可靠性尤为重要。
"不检索"的极端设想:可行性与边界
有趣的是,Claude Code 团队的实践引出一个颇具争议的理念: "完全不做任何检索" 。所谓"不检索",并非指AI凭空作答,而是指不构建专门的检索索引和数据库 ,一切信息获取都依赖实时读取和模型自身。这在ClaudeCode中体现为:没有向量索引、没有代码片段Embedding,Claude每次回答问题时都现用grep从源码中查找需要的内容。换言之,零预处理,零缓存,一次一查。

这种近乎极端的"无状态"方案之所以被尝试,源于对效率与可靠性的追求。一方面,它简化系统架构 :无需维护庞大的索引和内存驻留数据,每次启动Agent时只要加载用户的代码仓库即可。对于中小型知识库(如一个中等规模的代码库或几百篇文档),现代硬件下全盘搜索几毫秒就能完成,完全可以忍受。另一方面,它将所有决策交给模型,使系统行为更可预测和可控。正如Boris所强调的优点:确定性 和即时最新。grep搜索是精确匹配,其失败的唯一原因就是文本不存在;并且每次都是访问最新文件内容,不会出现"索引陈旧"问题。这对要求绝对准确或实时更新的场景(如代码调试、安全日志监控)非常有价值。
"不做任何检索"的理念在特定领域展现了可行性 。Claude Code的成功证明,即使不用向量语义搜索,AI依然可以胜任复杂的代码解释和生成任务。这得益于代码本身结构严谨、语义清晰,grep已经足够定位相关函数定义或错误信息。而随着OpenAI GPT-5等模型支持的上下文窗口扩容到数十万Token,某种程度上也能实现"不检索":直接把大文档内容塞入模型,一步回答。新的GPT-5模型甚至提供了高达40万Token的上下文长度,理论上可一次性容纳数百页文档。这暗示,在未来一些场景,模型也许可以完全以"阅读长文档"方式作答,而无须传统意义的检索。
然而,"无检索"并非放之四海皆准。其边界 在于知识规模和模糊查询。当知识库扩展到海量规模,逐字搜索的代价将随之升高,响应延迟难以接受,此时引入向量索引等结构化加速手段仍有必要。另外,对于语义差异大的提问 ,完全基于关键词的grep可能漏掉答案。例如用户问"系统如何防止恶意登录?",而文档里答案措辞是"登录安全机制",直接grep"恶意登录"可能搜不到。这种情况下,向量检索的语义泛化能力会更占优。实际上,我们认为混合策略 或多阶段检索 是理想方案:先用LLM粗定位相关文档,再在文档内用精确工具搜索。对于要求极高召回率的任务,纯Agent方法可能需要辅以简单索引或Embedding作为备份。正如ShawnWang所说:"简单方法能解决80%的问题,剩下20%极端场景才需要复杂索引"。因此,"不检索"的理念虽新颖,其适用范围仍有局限,工程上应根据实际需求权衡取舍。在注重隐私、安全、可控 的场景,放弃复杂索引换取透明简单是值得的;但在强调广覆盖、高召回的应用,经典RAG的一些要素仍不可或缺。
技术实现:GPT-5 接口调用与 Agent 结合
工程角度,将智能Agent检索融入产品,需要解决两个关键问题:大模型接口调用 和工具使用编排。下面我们分别介绍实现细节。
调用 OpenAI GPT-5 API 的示例(JavaScript)
OpenAI 最新提供的 GPT-5 模型拥有更强的推理和编程能力,我们可以通过API将其用作Agent的大脑。以下是使用Node.js调用 GPT-5 接口的一个简单示例代码:
php
//
使用
OpenAI
官方
Node.js
库(
openai
npm
包)
import { Configuration, OpenAIApi } from"openai";
constconfig = newConfiguration({ apiKey: process.env.OPENAI_API_KEY });
constopenai = newOpenAIApi(config);
//
准备对话消息,系统提示可包括工具使用说明
constmessages = [
{ role: "system", content:
"
你是一个智能
Agent
,可以阅读文档目录并使用
grep
搜索工具来回答问题。
"
},
{ role: "user", content:
"
用户的具体提问
..."
}
];
//
发起请求调用
GPT-5
模型
openai.createChatCompletion({
model: "gpt-5", // GPT-5
主力模型
messages: messages,
temperature: 0.2, //
略低的随机度,保证回答更严谨
functions: [
{
name: "search_documents", //
定义一个自定义工具函数接口
description:
"
在本地知识库中搜索关键词
",
parameters: {
type: "object",
properties: {
query: { type: "string", description:
"
待搜索的关键词或正则表达式
"
},
file: { type: "string", description:
"
限定搜索的文件(可选)
"
}
}
}
}
]
}).then(response => {
const result = response.data;
console.log(result.choices[0].message.content);
});上述代码片段展示了调用 GPT-5 Chat Completion 接口的基本步骤:
配置 * API*:使用API密钥初始化OpenAI客户端。可以通过环境变量或配置文件安全地提供密钥。
构建消息:我们在系统角色消息中说明了Agent的行为(它可以浏览目录和使用grep搜索)。然后将用户提问作为user消息传入。
定义函数工具:利用GPT-5的函数调用机制,我们预先定义一个名为search_documents的工具,描述其功能和参数结构。这相当于告诉模型:它可以请求调用一个搜索函数,并提供查询词和文件名。
创建 * Completion*:指定模型为"gpt-5",提交消息列表和可用函数列表。我们也将temperature设置较低以提高答案稳定性。
处理响应:OpenAI接口会返回模型的回复。如果模型决定调用search_documents函数,返回消息中会包含function_call字段,指明函数名和参数。我们的应用收到此调用请求后,需要编写相应代码执行实际的grep搜索,将结果再作为模型的新输入(以assistant角色附带函数返回值)继续对话。最终,当模型返回message.content时,即是完成问题的回答。
通过上述API机制,GPT-5可以像Agent那样自主调用我们定义的search_documents工具。这意味着模型在生成答案过程中,如果觉得需要从知识库检索信息,会以函数调用形式要求执行grep搜索 (这正是智能Agent检索的关键) 。我们只需实现好search_documents对应的后端逻辑,例如用Node.js的子进程运行grep命令或查询预先加载的文本索引,将匹配结果返回给模型即可。OpenAI的新功能让这种人机协作式流程变得顺畅安全:模型不会直接访问文件系统,而是通过受控的函数接口请求所需数据,开发者可以严格过滤它能读取的范围。
技术实现:目录结构、grep 工具与 Agent 推理的结合
智能Agent方案的实现涉及预处理知识库 和编排Agent工作流两部分:
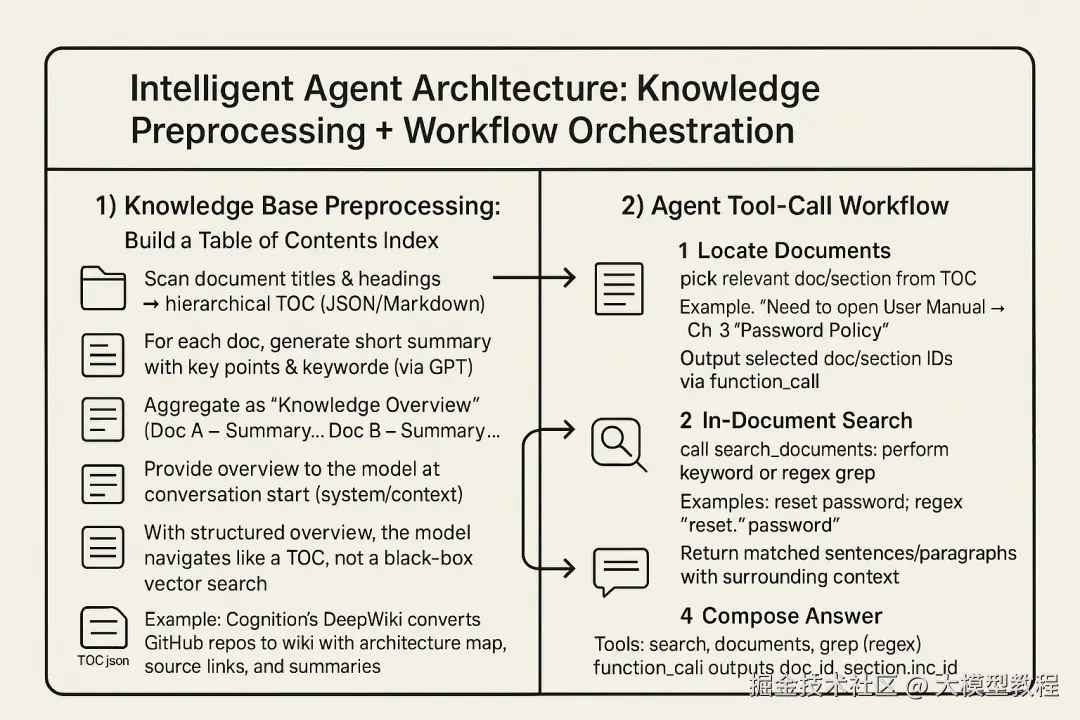
1. 知识库预处理:构建目录索引**。为了让模型理解文档结构,我们需要提前准备好知识库的目录或摘要信息。具体做法可以是:扫描所有文档的标题、章节,生成一个层次化的目录JSON或Markdown文件。对每个文档,我们也可以让GPT生成一段简要摘要,标注主要内容和关键词。这些信息汇总成"知识总览"(例如一个清单:文档A - 概要...,文档B - 概要...)。在对话一开始,将这个总览提供给模型(作为系统消息或上下文的一部分),让它对知识库"心中有数"。例如,Cognition的 DeepWiki 工具就会将GitHub仓库自动转换成带架构图、源代码链接和摘要的Wiki页面,帮助开发者(和AI)快速理解仓库结构。有了结构化总览,模型就能像翻目录一样快速定位可能相关的文档区域,而不是在黑箱向量空间里盲目搜索。
2. Agent工具调用流程:**当用户提出问题后,代理Agent需要按照一定顺序调用工具,完成检索到回答的全过程。典型的流程如下:
·步骤1:定位文档-- 模型先根据问题,从提供的目录中找出最相关的文档名称或章节。例如用户问"如何重置密码?",模型从目录中识别出某份"用户手册-安全章节"可能包含答案。它会在回复中提出:"需要查看《用户手册》第三章'密码策略'"。我们可以让模型以函数调用或特殊格式输出它选定的文档/章节标识。
·步骤2:文内搜索-- 确定目标文档后,Agent调用search_documents工具,在该文档文本中执行关键词搜索。模型可能会基于提问猜测关键词,如"重置密码"或"密码重置",甚至同时搜索相关措辞。我们的grep工具支持正则表达式搜索,这允许模型提出例如"搜索'重置.*密码'以涵盖不同措辞"。执行grep后,将匹配到的句子或段落(连同上下文)返回给模型。
·步骤3:阅读与追问-- 模型收到搜索结果,会将其纳入上下文一并分析。如果结果不完整或引发新疑问,模型可能提出进一步搜索请求。例如"在结果中看到提到'安全问题答案',需要搜索该关键词了解详情"。Agent由此进入下一轮工具调用,继续grep更多信息。这个循环一直持续到模型确信掌握了充分材料。
·步骤4:生成回答-- 最后,Agent整合从各轮搜索获得的内容,加上自身的语言组织能力,给出完整翔实的回答,并引用必要的细节出处。如果采用Chain-of-Thought技术,模型甚至会在回答前输出它推理的思路(对用户隐藏,仅日志记录),进一步提升可靠性。
值得注意的是,在上述过程中Agent始终遵循"小步快跑"的原则,每次只搜索当前需要的东西,避免一次性塞入过多无关文本,减轻了LLM的负担。这种按需检索与逐步推理,使得即使知识库很大,每次交互中模型看到的上下文仍是相关且精炼的,从而保持回答的准确性和连贯性。
技术实现上,可以借助现有Agent开发框架来编排这些步骤。例如 LangChain、LlamaIndex 等支持定义自定义工具和多轮Agent对话流,开发者只需配置好文档加载和grep搜索功能,即可让GPT-5类模型自动按照设定逻辑检索和回答。实际应用中,Claude等AI助手的代码模式已经验证了这种方案的有效性:他们抛弃复杂索引,采用Unix风格的即用即搜,配合强大的LLM推理,反而取得更佳的性能和用户体验。
结论
向量检索+RAG曾是将知识引入AI的黄金标准,但它有先天不足:忽略结构、检索不稳,导致模型有时"看到了却没看懂"或压根找不到。智能Agent方法通过让大模型主动理解和探索知识库,实现了以人类方式利用知识:看目录、翻章节、精确搜索、逐步求解。这种方法在代码助理等领域已展现出巨大潜力,也为通用知识问答提供了新思路。
需要强调的是,新旧方案并非绝对对立。Agent方法未必完全取代向量索引,而更可能与其融合形成混合增强的知识库架构。在大部分常见场景下,Agent的简单策略就够用且更高效;在极端复杂场景下,传统索引仍可提供支撑。值得关注的是Agent方案能带来更灵活可控的AI能力:知识库更新后无需重建索引,哪怕实时数据也能即时被AI获取;模型每一步动作都透明可监控,方便调优和确保安全;系统架构更简洁,降低了开发和运维成本。对于普通用户而言,这意味着AI回答将更加精准贴切------它真的读懂了资料再回答,而不是凭相关度"猜"答案。
未来,随着GPT-5等模型接口对长上下文 和工具调用支持的增强,我们有理由相信智能Agent知识库将成为新范式。在这种范式下,AI不再只是被动检索的信息搬运工,而是主动探索知识的智能体。通过合理设计,我们可以让AI像一个勤奋的小助手那样,快速翻阅成百上千页资料,提炼出我们想要的答案。这无疑将把人机协作推向新的高度------让知识的价值得到最大化的发挥。我们正站在这一变革的起点,未来已来,现在就着手尝试吧!
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。