图像分类项目:Fashion-MNIST 分类
一、数据加载模块:Fashion-MNIST 数据集加载与预处理
在模型训练流程中,数据加载是基础且关键的一步。该模块的核心功能是自动下载、预处理 Fashion-MNIST 数据集,并构建可迭代的数据加载器(DataLoader),为后续模型训练和测试提供标准化的输入数据。
模块核心功能说明
-
跨操作系统的多进程适配
数据加载时使用多进程可以加速数据读取,但不同操作系统对多进程的支持存在差异(Windows 和 MacOS 在多进程处理上有兼容性限制)。get_dataloader_workers函数通过判断当前操作系统,自动设置合适的进程数:Linux 系统使用 4 个进程加速加载,Windows 和 MacOS 则使用单进程(避免多进程报错)。
-
数据集加载与预处理
load_data_fashion_mnist函数实现了完整的数据加载逻辑:
-
数据变换(Transform) 使用ToTensor将图像从 PIL 格式转为张量(Tensor),并自动将像素值归一化到 0, 1 区间;支持通过resize参数调整图像尺寸(默认保持 28x28 原始大小)。
-
数据集下载与加载: 通过paddle.vision.datasets.FashionMNIST分别加载训练集(mode="train")和测试集(mode="test"),download=True确保本地无数据时自动从官方源下载。
-
DataLoader 构建: 将数据集封装为可迭代的DataLoader,通过batch_size控制每次迭代返回的样本数量;训练集启用shuffle=True打乱样本顺序(增强泛化能力),测试集则保持顺序不变;num_workers参数调用前面的进程数适配函数,确保跨系统兼容性。
- 数据验证逻辑
测试代码(if name == "main":部分)用于验证数据加载的正确性:
-
检查训练集(60000 样本)和测试集(10000 样本)的样本数量是否符合预期。
-
验证单个样本的形状(灰度图通道数为 1,尺寸 28x28,即(1,28,28))。
-
确认标签范围为 0~9(对应 Fashion-MNIST 的 10 个类别)。
-
检查 DataLoader 输出的批次数据形状是否匹配设置的batch_size(如批次数据(16,1,28,28)和标签(16,))。
详细代码:
python
import paddle
from paddle.vision import datasets, transforms
import paddle.io as io
import sys # 导入sys模块判断操作系统
def get_dataloader_workers():
"""根据操作系统设置数据加载的进程数(Windows/MacOS用单进程)"""
# 判断当前系统:Windows含'win',MacOS含'darwin',Linux含'linux'
if sys.platform.startswith(('win', 'darwin')):
return 0 # Windows/MacOS用单进程
else:
return 4 # Linux用多进程加速
def load_data_fashion_mnist(batch_size, resize=None):
trans = [transforms.ToTensor()] # 转为张量并归一化到[0,1]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
# 加载数据集
mnist_train = datasets.FashionMNIST(mode="train", transform=trans, download=True)
mnist_test = datasets.FashionMNIST(mode="test", transform=trans, download=True)
# 构建DataLoader
train_iter = io.DataLoader(
mnist_train, batch_size=batch_size, shuffle=True,
return_list=True, num_workers=get_dataloader_workers()
)
test_iter = io.DataLoader(
mnist_test, batch_size=batch_size, shuffle=False,
return_list=True, num_workers=get_dataloader_workers()
)
return train_iter, test_iter, mnist_train, mnist_test
# 测试代码
if __name__ == "__main__":
# 超参数(测试用,批量设小一点)
batch_size = 16
# 加载数据
train_iter, test_iter, mnist_train, mnist_test = load_data_fashion_mnist(batch_size)
# 验证1:数据集基本信息
print(f"训练集样本数:{len(mnist_train)}, 测试集样本数:{len(mnist_test)}") # 预期:60000, 10000
print(f"单个样本形状:{mnist_train[0][0].shape}") # 预期:(1,28,28)(通道数, 高, 宽)
print(f"标签范围:{min([y for x,y in mnist_train])} ~ {max([y for x,y in mnist_train])}") # 预期:0~9
# 验证2:DataLoader可迭代,且输出形状正确
batch = next(iter(train_iter)) # 取第一个批次
X, y = batch[0], batch[1]
print(f"批次数据形状:{X.shape},标签形状:{y.shape}") # 预期:(16,1,28,28), (16,)
print("数据加载模块测试通过!")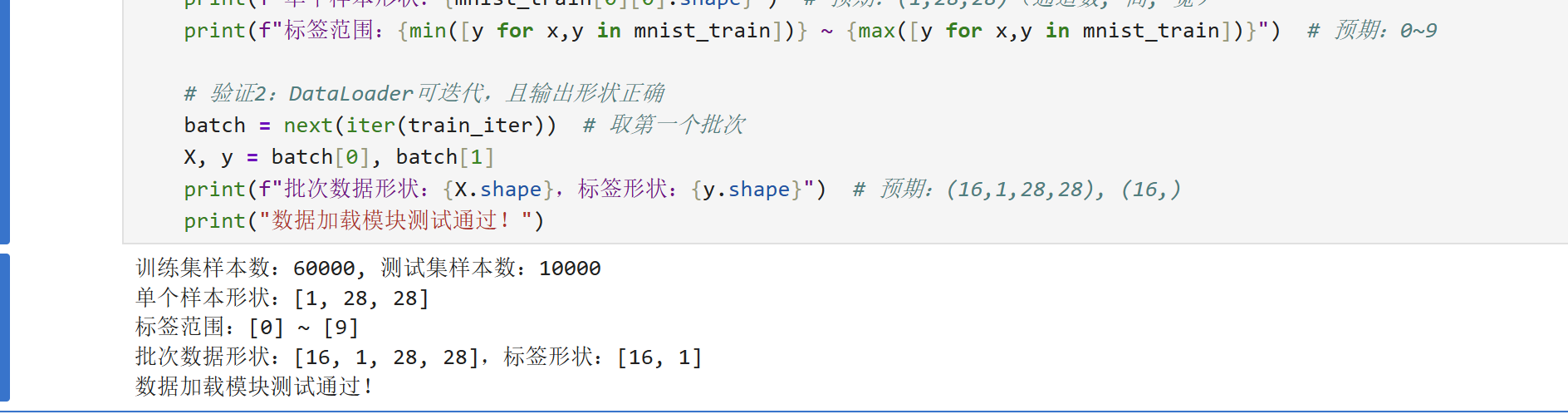
二、数据集可视化模块:Fashion-MNIST 样本与标签展示
在模型训练前,可视化数据集样本是理解数据分布和标签含义的重要步骤。该模块提供了两个核心函数:将数字标签转换为直观文本标签的工具,以及批量展示图像的可视化函数,帮助我们直观感受 Fashion-MNIST 数据集的内容。
模块核心功能说明
-
数字标签转文本标签:
get_fashion_mnist_labelsFashion-MNIST 数据集的原始标签是 0-9 的数字(对应 10 个服装类别),但数字标签不够直观。该函数通过定义一个与数字标签一一对应的文本标签列表(如
0→t-shirt、1→trouser等),将输入的数字标签列表转换为易于理解的文本标签列表。例如,若输入标签为[0, 2, 9],函数会返回['t-shirt', 'pullover', 'ankle boot']。 -
批量图像展示:
show_images该函数用于将多个图像按指定行列布局展示,并可添加对应标签作为标题,核心逻辑包括:
- 画布设置 :根据指定的行数(
num_rows)、列数(num_cols)和缩放比例(scale)计算画布大小,确保图像显示清晰。 - 子图创建 :使用
matplotlib创建对应行列数的子图,并将子图数组展平为一维(方便循环遍历)。 - 图像显示 :支持两种图像格式 ------ 若输入为 Paddle 张量(
paddle.Tensor),先转换为 NumPy 数组再显示;若为 PIL 图像则直接显示。同时隐藏子图的坐标轴(避免干扰视觉焦点)。 - 标题与布局 :若提供标题列表(如文本标签),为每个子图添加标题;通过
plt.tight_layout()自动调整子图间距,避免重叠。
- 画布设置 :根据指定的行数(
-
测试与可视化效果
最后一段代码是功能测试:从训练集中加载一个包含 18 个样本的批次(
batch_size=18),将图像数据X从原始形状(18, 1, 28, 28)重塑为(18, 28, 28)(去除通道维度,因为是灰度图),然后调用show_images以 2 行 9 列的布局展示,并使用get_fashion_mnist_labels将标签y转换为文本作为标题,直观展示样本与标签的对应关系。
注意事项
- 该模块依赖
matplotlib库,需提前导入(代码中隐含import matplotlib.pyplot as plt,实际使用时需显式添加,否则会报错)。 - 图像重塑(
X.reshape([18, 28, 28]))的目的是去除单通道维度(Fashion-MNIST 为灰度图,通道数为 1),符合matplotlib对 2D 图像(高 × 宽)的显示要求。
python
import matplotlib.pyplot as plt # 需显式导入matplotlib
import paddle
def get_fashion_mnist_labels(labels): #@save
"""返回Fashion-MNIST数据集的文本标签"""
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):
"""绘制图像列表"""
figsize = (num_cols * scale, num_rows * scale)
fig, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() # 将二维子图数组转为一维,方便遍历
for i, (ax, img) in enumerate(zip(axes, imgs)):
if paddle.is_tensor(img):
# 若为Paddle张量,先转为NumPy数组再显示
ax.imshow(img.numpy())
else:
# 若为PIL图像,直接显示
ax.imshow(img)
ax.axis('off') # 隐藏坐标轴,突出图像内容
if titles:
ax.set_title(titles[i]) # 添加标题(如文本标签)
plt.tight_layout() # 自动调整子图间距,避免重叠
plt.show() # 显示图像
return axes
# 测试:展示18个训练样本及其标签
# 注意:需先加载mnist_train(可通过前文load_data_fashion_mnist函数获取)
X, y = next(iter(paddle.io.DataLoader(mnist_train, batch_size=18)))
# 重塑图像形状:(18,1,28,28) → (18,28,28)(去除通道维度)
show_images(X.reshape([18, 28, 28]), 2, 9, titles=get_fashion_mnist_labels(y));
三、模型训练核心模块:训练流程与评估逻辑实现
该模块是 Fashion-MNIST 模型训练的核心,包含了超参数配置、完整训练流程(模型 / 损失 / 优化器定义)、评估指标计算函数等,实现了从数据到模型训练、性能监控的全链路逻辑。
模块核心功能说明
1. 超参数与数据加载
超参数是控制模型训练过程的关键参数,直接影响训练效率和模型性能:
batch_size=256:每次迭代输入模型的样本数量(批量大小),增大批量可提升计算效率,但可能降低模型收敛精度(需权衡内存与性能)。lr=0.005:学习率(Learning Rate),控制参数更新的幅度(过大会导致不收敛,过小会导致训练缓慢)。num_epochs=10:训练轮次,即遍历完整训练集的次数(轮次太少可能欠拟合,太多可能过拟合)。- 数据加载复用前文定义的
load_data_fashion_mnist函数,获取训练集迭代器train_iter和测试集迭代器test_iter。
2. 模型、损失函数与优化器定义
-
模型(MLP):相比之前的简化版,这里定义了更深的三层全连接网络:
-
输入层:
nn.Flatten()将(1,28,28)图像展平为784维向量; -
隐藏层 1:
nn.Linear(784, 512)+ReLU,将 784 维映射到 512 维并引入非线性; -
隐藏层 2:
nn.Linear(512, 256)+ReLU,进一步压缩特征到 256 维; -
输出层:
nn.Linear(256, 10)输出 10 个类别的得分(对应 Fashion-MNIST 的 10 类服饰)。
更深的网络结构可学习更复杂的特征,但需注意过拟合风险。
-
-
损失函数(CrossEntropyLoss):
多类别分类任务的经典损失函数,内部集成了
softmax激活(将输出得分转为概率)和负对数似然损失计算,reduction='none'表示返回每个样本的损失(而非均值),方便后续批量累计。 -
优化器(Adam):
一种自适应学习率的优化器,相比基础的 SGD(随机梯度下降),能动态调整不同参数的学习率,收敛更稳定、速度更快,适合大多数深度学习任务。
3. 辅助函数:训练与评估的核心工具
-
accuracy(y_hat, y):计算预测准确率- 逻辑:先通过
y_hat.argmax(axis=1)取预测得分最高的类别(模型预测结果),再与真实标签y比较,统计一致的样本数占比。 - 处理:通过
squeeze()去除冗余维度,确保预测值与标签形状匹配。
- 逻辑:先通过
-
Accumulator类:指标累加器- 功能:方便在训练 / 评估中累计多个指标(如总损失、正确样本数、总样本数),避免频繁定义变量。
- 方法:
__init__(n)初始化长度为n的累加列表;add(*args)将输入的数值累加到列表中;__getitem__(idx)获取第idx个累加值。
-
evaluate_accuracy(net, data_iter):评估模型在数据集上的准确率- 逻辑:切换模型到评估模式(
net.eval(),关闭 dropout 等训练特有的层),通过paddle.no_grad()关闭梯度计算(节省内存),遍历测试集计算总正确数和总样本数,返回准确率(正确数 / 总样本数)。 - 注意:评估后切换回训练模式(
net.train()),不影响后续训练。
- 逻辑:切换模型到评估模式(
-
train_epoch(net, train_iter, loss_fn, optimizer):单轮训练逻辑-
逻辑:切换模型到训练模式(
net.train()),遍历训练集,对每个批次执行:
- 前向传播:计算模型输出
y_hat; - 计算损失:通过
loss_fn得到每个样本的损失; - 反向传播:清空历史梯度(
optimizer.clear_grad()),计算损失均值的梯度(l.mean().backward()),更新参数(optimizer.step()); - 指标累计:累计总损失、正确样本数、总样本数。
- 前向传播:计算模型输出
-
返回:当前轮次的平均损失(总损失 / 总样本数)和训练准确率(正确数 / 总样本数)。
-
注意事项
- 更深的网络(如这里的三层 MLP)可能需要配合正则化(如 Dropout)或早停策略,防止过拟合(后续可扩展)。
完整代码
python
import paddle
import paddle.nn as nn
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
from paddle.vision import datasets, transforms
from paddle.io import DataLoader
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# ---------------------- 1. 数据加载函数定义 ----------------------
def load_data_fashion_mnist(batch_size):
"""加载Fashion-MNIST数据集并返回训练/测试迭代器"""
# 数据预处理:转换为Tensor并归一化
transform = transforms.Compose([transforms.ToTensor()])
# 加载训练集和测试集
train_dataset = datasets.FashionMNIST(mode='train', transform=transform, download=True)
test_dataset = datasets.FashionMNIST(mode='test', transform=transform, download=True)
# 创建数据迭代器
train_iter = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
test_iter = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
# 返回类别名称(用于后续可视化)
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
return train_iter, test_iter, train_dataset, class_names
# ---------------------- 2. 超参数与数据加载 ----------------------
batch_size = 256 # 批量大小:每次训练的样本数
lr = 0.005 # 学习率:控制参数更新幅度
num_epochs = 10 # 训练轮次:完整遍历训练集的次数
# 加载数据
train_iter, test_iter, _, class_names = load_data_fashion_mnist(batch_size)
# ---------------------- 3. 模型定义 ----------------------
class MLP(nn.Layer):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten() # 展平图像:(1,28,28)→(784,)
self.fc1 = nn.Linear(784, 512) # 全连接层1:784→512
self.relu1 = nn.ReLU() # 激活函数1:引入非线性
self.fc2 = nn.Linear(512, 256) # 全连接层2:512→256
self.relu2 = nn.ReLU() # 激活函数2
self.fc3 = nn.Linear(256, 10) # 输出层:256→10(10个类别)
def forward(self, x):
x = self.flatten(x)
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
x = self.relu2(x)
x = self.fc3(x)
return x
net = MLP() # 初始化模型
# ---------------------- 4. 损失函数与优化器 ----------------------
# 损失函数:交叉熵损失(适合多分类,内置softmax)
loss_fn = nn.CrossEntropyLoss(reduction='none')
# 优化器:Adam(自适应学习率,收敛更稳定)
optimizer = paddle.optimizer.Adam(parameters=net.parameters(), learning_rate=lr)
# ---------------------- 5. 辅助函数 ----------------------
def accuracy(y_hat, y):
"""计算预测准确率(预测正确的样本数 / 总样本数)"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1) # 取得分最高的类别作为预测结果
y = y.squeeze() # 去除冗余维度,确保与y_hat形状一致
y_hat = y_hat.squeeze()
cmp = y_hat.astype(y.dtype) == y # 比较预测与真实标签是否一致
return float(cmp.astype(y.dtype).sum()) # 返回正确样本数
class Accumulator:
"""用于累计多个指标的工具类"""
def __init__(self, n):
self.data = [0.0] * n # 初始化n个累加器
def add(self, *args):
"""累加输入的指标"""
self.data = [a + float(b) for a, b in zip(self.data, args)]
def __getitem__(self, idx):
"""获取第idx个累加值"""
return self.data[idx]
def evaluate_accuracy(net, data_iter):
"""评估模型在数据集(如测试集)上的准确率"""
net.eval() # 切换到评估模式(关闭训练特有的层)
metric = Accumulator(2) # 累计:[正确样本数, 总样本数]
with paddle.no_grad(): # 关闭梯度计算,节省内存
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel()) # y.numel():当前批次总样本数
net.train() # 切换回训练模式
return metric[0] / metric[1] # 准确率 = 正确数 / 总数
def train_epoch(net, train_iter, loss_fn, optimizer):
"""单轮训练:遍历训练集并更新模型参数"""
net.train() # 切换到训练模式
metric = Accumulator(3) # 累计:[总损失, 正确样本数, 总样本数]
for X, y in train_iter:
y_hat = net(X) # 前向传播:计算预测值
l = loss_fn(y_hat, y) # 计算损失
optimizer.clear_grad() # 清空历史梯度
l.mean().backward() # 反向传播:计算梯度(损失均值的梯度)
optimizer.step() # 更新参数
# 累计指标:总损失、正确数、总样本数
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回当前轮次的平均损失和训练准确率
return metric[0] / metric[2], metric[1] / metric[2]
# ---------------------- 6. 训练与测试过程 ----------------------
# 记录训练过程中的指标
train_losses = [] # 训练损失
train_accs = [] # 训练准确率
test_accs = [] # 测试准确率
# 执行训练
for epoch in range(num_epochs):
# 训练一轮并获取当前轮次的损失和准确率
train_loss, train_acc = train_epoch(net, train_iter, loss_fn, optimizer)
# 评估测试集准确率
test_acc = evaluate_accuracy(net, test_iter)
# 保存指标
train_losses.append(train_loss)
train_accs.append(train_acc)
test_accs.append(test_acc)
# 打印当前轮次结果
print(f"Epoch {epoch+1}/{num_epochs}")
print(f"训练损失: {train_loss:.4f} | 训练准确率: {train_acc:.4f} | 测试准确率: {test_acc:.4f}")
print("-" * 60)
# ---------------------- 7. 结果可视化 ----------------------
# 绘制训练损失和准确率曲线
plt.figure(figsize=(14, 5))
# 子图1:训练损失曲线
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs+1), train_losses, 'o-', color='b', label='训练损失')
plt.xlabel('轮次 (Epoch)')
plt.ylabel('损失值')
plt.title('训练损失变化曲线')
plt.legend()
plt.gca().xaxis.set_major_locator(MaxNLocator(integer=True)) # x轴只显示整数
# 子图2:准确率曲线
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs+1), train_accs, 'o-', color='g', label='训练准确率')
plt.plot(range(1, num_epochs+1), test_accs, 'o-', color='r', label='测试准确率')
plt.xlabel('轮次 (Epoch)')
plt.ylabel('准确率')
plt.title('准确率变化曲线')
plt.legend()
plt.gca().xaxis.set_major_locator(MaxNLocator(integer=True))
plt.tight_layout()
plt.show()
# ---------------------- 8. 预测示例展示 ----------------------
# 从测试集中获取一批数据
for X, y in test_iter:
break # 只取第一批数据
# 模型预测
net.eval() # 切换到评估模式
with paddle.no_grad(): # 关闭梯度计算
y_hat = net(X)
y_pred = y_hat.argmax(axis=1) # 获取预测类别
net.train() # 切回训练模式
# 展示前10个样本的预测结果
plt.figure(figsize=(12, 6))
for i in range(10):
plt.subplot(2, 5, i+1)
# 显示图像(Fashion-MNIST是单通道灰度图)
plt.imshow(X[i].numpy().squeeze(), cmap='gray')
# 标题显示真实标签和预测标签
true_label = class_names[y[i].item()]
pred_label = class_names[y_pred[i].item()]
plt.title(f"真实: {true_label}\n预测: {pred_label}", fontsize=9)
plt.axis('off') # 关闭坐标轴
plt.tight_layout()
plt.show()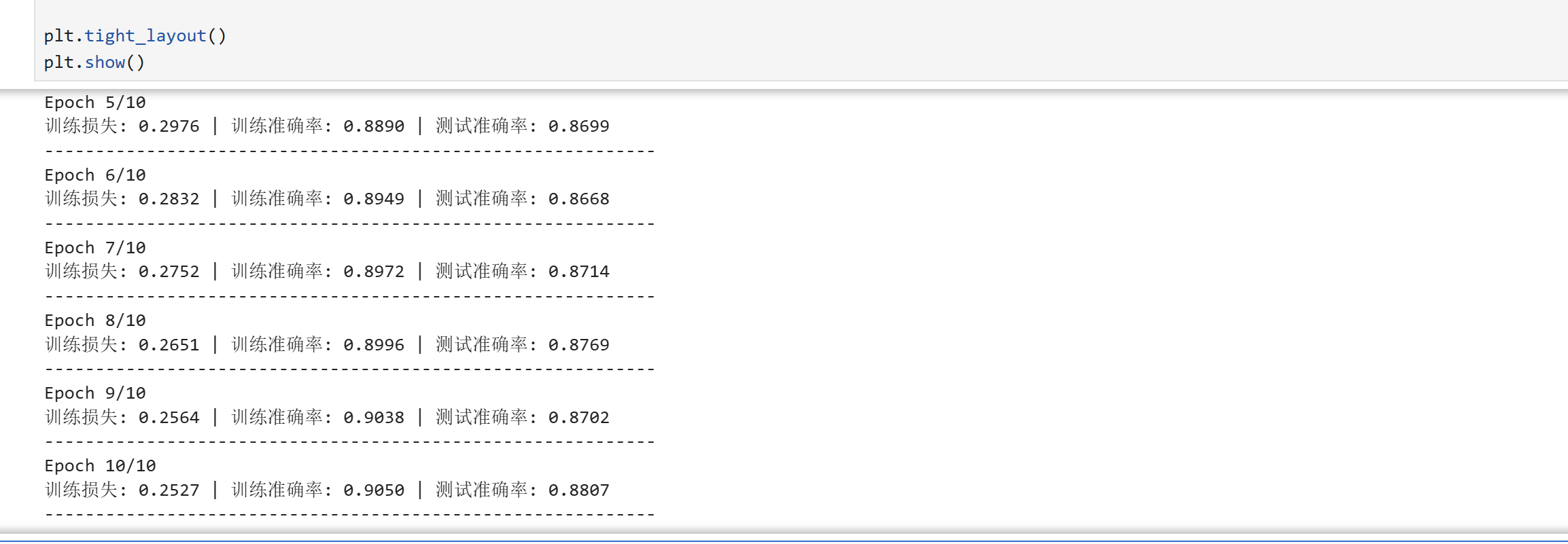
四、训练可视化与总控模块:指标记录、日志输出与结果可视化
该模块是 Fashion-MNIST 模型训练的 "总控中枢",包含两个核心组件:Animator类(用于训练指标的存储与最终可视化)和train函数(整合全流程训练逻辑,实现多轮训练、指标监控与日志输出),解决了 "训练过程如何跟踪" 和 "结果如何直观展示" 的问题。
模块核心功能说明
1. Animator类:训练指标的 "延迟可视化" 工具
传统实时绘图会占用训练资源、降低效率,Animator采用 "先存储数据,训练结束后一次性绘图" 的设计,兼顾可视化效果与训练效率,核心逻辑分为三部分:
-
初始化配置(
__init__)提前定义可视化的基础参数,不立即创建画布,仅存储配置:
- 坐标轴标签(
xlabel="epoch"、ylabel="value"):明确 x 轴为训练轮次,y 轴为指标值(损失 / 准确率)。 - 图例(
legend):支持多组曲线标注(如训练损失、训练准确率、测试准确率)。 - 坐标轴范围(
xlim、ylim):固定 x 轴为[1, num_epochs](匹配轮次),y 轴为[0, 1.0](损失通常小于 1,准确率最大为 1,统一范围更直观)。 - 数据容器(
self.X、self.Y):用二维列表存储多组指标的 "轮次 - 值" 对应关系(如self.X[0]存训练损失的轮次,self.Y[0]存对应损失值)。
- 坐标轴标签(
-
数据存储(
add_data)每轮训练后仅记录指标,不绘图:
- 兼容性处理:若输入的
y(指标值)是单个数值(如仅损失),自动转为列表,支持多组指标同时存储(如一次传入损失、训练准确率、测试准确率)。 - 数据匹配:确保
x(轮次)与y(指标)的长度一致(如多组指标对应同一轮次时,x自动复制为多份)。 - 安全存储:仅当
x和y非空时才追加数据,避免空值导致绘图错误。
- 兼容性处理:若输入的
-
最终绘图(
plot)所有训练轮次结束后,统一生成可视化图表:
- 画布与坐标轴配置:创建指定大小的画布,设置标签、范围、刻度(
xaxis.set_major_locator强制 x 轴显示整数,匹配 "轮次" 的整数属性)。 - 多曲线绘制:遍历存储的
X和Y,用不同格式(fmts,如实线-、虚线m--)绘制每组指标,避免曲线重叠混淆。 - 图例与显示:添加图例区分指标,调用
plt.show()展示最终图表,直观对比多组指标的变化趋势。
- 画布与坐标轴配置:创建指定大小的画布,设置标签、范围、刻度(
2. train函数:训练全流程的 "总控制器"
整合前文定义的train_epoch(单轮训练)、evaluate_accuracy(测试集评估)等函数,实现 "多轮训练→指标记录→日志输出→可视化" 的闭环:
-
流程拆解
:
-
初始化可视化工具 :创建
Animator实例,指定图例为 "train loss""train acc""test acc",固定坐标轴范围。 -
多轮训练循环
:遍历
num_epochs轮次,每轮执行:
- 单轮训练:调用
train_epoch得到当前轮的训练损失 和训练准确率。 - 测试集评估:调用
evaluate_accuracy得到当前轮的测试准确率(验证模型泛化能力)。 - 指标存储:用
animator.add_data记录 "轮次 + 3 组指标"(轮次从 1 开始,避免 0 轮次的视觉混淆)。 - 日志输出:打印每轮关键指标(保留 4 位小数),方便实时监控训练状态(如是否过拟合:训练准确率上升但测试准确率下降)。
- 单轮训练:调用
-
训练后可视化 :所有轮次结束后,调用
animator.plot()生成图表,直观展示指标变化(如损失是否下降、准确率是否收敛)。 -
返回结果:返回最终轮次的训练损失,便于后续模型保存或进一步分析。
-
3. 核心设计优势
- 效率优先:延迟绘图避免训练中频繁 IO 操作,尤其在多轮训练或大数据集场景下,显著提升训练速度。
- 直观监控:通过图表可快速判断训练状态(如损失是否稳定下降、是否出现过拟合),比纯日志更易分析。
- 通用性强 :支持任意多组指标的存储与可视化,只需调整
legend和add_data的输入,可适配分类、回归等不同任务。
注意事项
- 指标顺序一致性:
Animator的legend顺序需与add_data传入的指标顺序严格对应(如示例中legend=["train loss", "train acc", "test acc"],则add_data需按 "损失→训练准确率→测试准确率" 的顺序传入y)。 - 依赖前置函数:
train函数需依赖前文定义的train_epoch和evaluate_accuracy,使用前需确保这两个函数已导入或定义。
完整代码
python
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
class Animator:
def __init__(self, xlabel="epoch", ylabel="value", legend=None, xlim=None,
ylim=None, xscale="linear", yscale="linear",
fmts=("-", "m--", "g-.", "r:"), figsize=(7, 5)):
# 初始化可视化配置(仅存储参数,不创建画布)
self.xlabel = xlabel
self.ylabel = ylabel
self.legend = legend if legend is not None else [] # 多组指标的图例
self.fmts = fmts # 不同曲线的绘制格式(如实线、虚线)
self.figsize = figsize # 画布大小
self.xlim = xlim # x轴范围
self.ylim = ylim # y轴范围
self.xscale = xscale # x轴缩放类型
self.yscale = yscale # y轴缩放类型
# 二维列表存储多组指标的"轮次-值"数据(如self.X[0]存训练损失的轮次)
self.X, self.Y = [], []
def add_data(self, x, y):
"""存储单轮训练的指标数据,不实时绘图"""
# 若y是单个数值(如仅损失),转为列表,支持多组指标
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
# 若x是单个轮次,复制n份,确保与y的长度匹配(多组指标对应同一轮次)
if not hasattr(x, "__len__"):
x = [x] * n
# 首次添加数据时,初始化二维列表(每组指标一个子列表)
if not self.X:
self.X = [[] for _ in range(n)]
self.Y = [[] for _ in range(n)]
# 安全追加数据(仅非空值)
for i, (xi, yi) in enumerate(zip(x, y)):
if xi is not None and yi is not None:
self.X[i].append(xi)
self.Y[i].append(yi)
def plot(self):
"""训练结束后,一次性绘制所有指标曲线"""
# 创建画布
plt.figure(figsize=self.figsize)
ax = plt.gca() # 获取当前绘图轴
# 配置坐标轴
ax.set_xlabel(self.xlabel)
ax.set_ylabel(self.ylabel)
if self.xlim is not None:
ax.set_xlim(self.xlim)
if self.ylim is not None:
ax.set_ylim(self.ylim)
ax.set_xscale(self.xscale)
ax.set_yscale(self.yscale)
# x轴强制显示整数(匹配"训练轮次"的整数属性)
ax.xaxis.set_major_locator(MaxNLocator(integer=True))
# 绘制每组指标曲线
for x_data, y_data, fmt, label in zip(self.X, self.Y, self.fmts, self.legend):
if x_data and y_data: # 避免空列表导致绘图错误
ax.plot(x_data, y_data, fmt, label=label, linewidth=1.5) # 线条宽度调整,更清晰
# 添加图例(区分不同指标)
if self.legend:
ax.legend(loc="lower right") # 图例放在右下角,避免遮挡曲线
# 自动调整子图间距,避免标签截断
plt.tight_layout()
# 显示图表
plt.show()
def train(net, train_iter, test_iter, loss_fn, optimizer, num_epochs):
"""训练总函数:整合多轮训练、指标记录、日志输出与可视化"""
# 初始化Animator,指定可视化的指标与范围
animator = Animator(
legend=["train loss", "train acc", "test acc"],
xlim=[1, num_epochs],
ylim=[0, 1.0], # 损失通常<1,准确率≤1,统一范围更直观
figsize=(8, 5) # 调整画布大小,避免图例拥挤
)
# 遍历每轮训练
for epoch in range(num_epochs):
# 1. 单轮训练:得到训练损失和训练准确率
train_loss, train_acc = train_epoch(net, train_iter, loss_fn, optimizer)
# 2. 测试集评估:得到测试准确率(验证泛化能力)
test_acc = evaluate_accuracy(net, test_iter)
# 3. 记录当前轮次的指标(轮次从1开始,符合直觉)
animator.add_data(epoch + 1, (train_loss, train_acc, test_acc))
# 4. 打印日志:实时监控训练状态(格式对齐,更易阅读)
print(f"epoch {epoch+1:2d} | loss: {train_loss:.4f} | train_acc: {train_acc:.4f} | test_acc: {test_acc:.4f}")
# 5. 所有轮次结束后,绘制指标变化曲线
animator.plot()
# 返回最终训练损失,便于后续模型保存或分析
return train_loss
train(net, train_iter, test_iter, loss_fn, optimizer, num_epochs=10)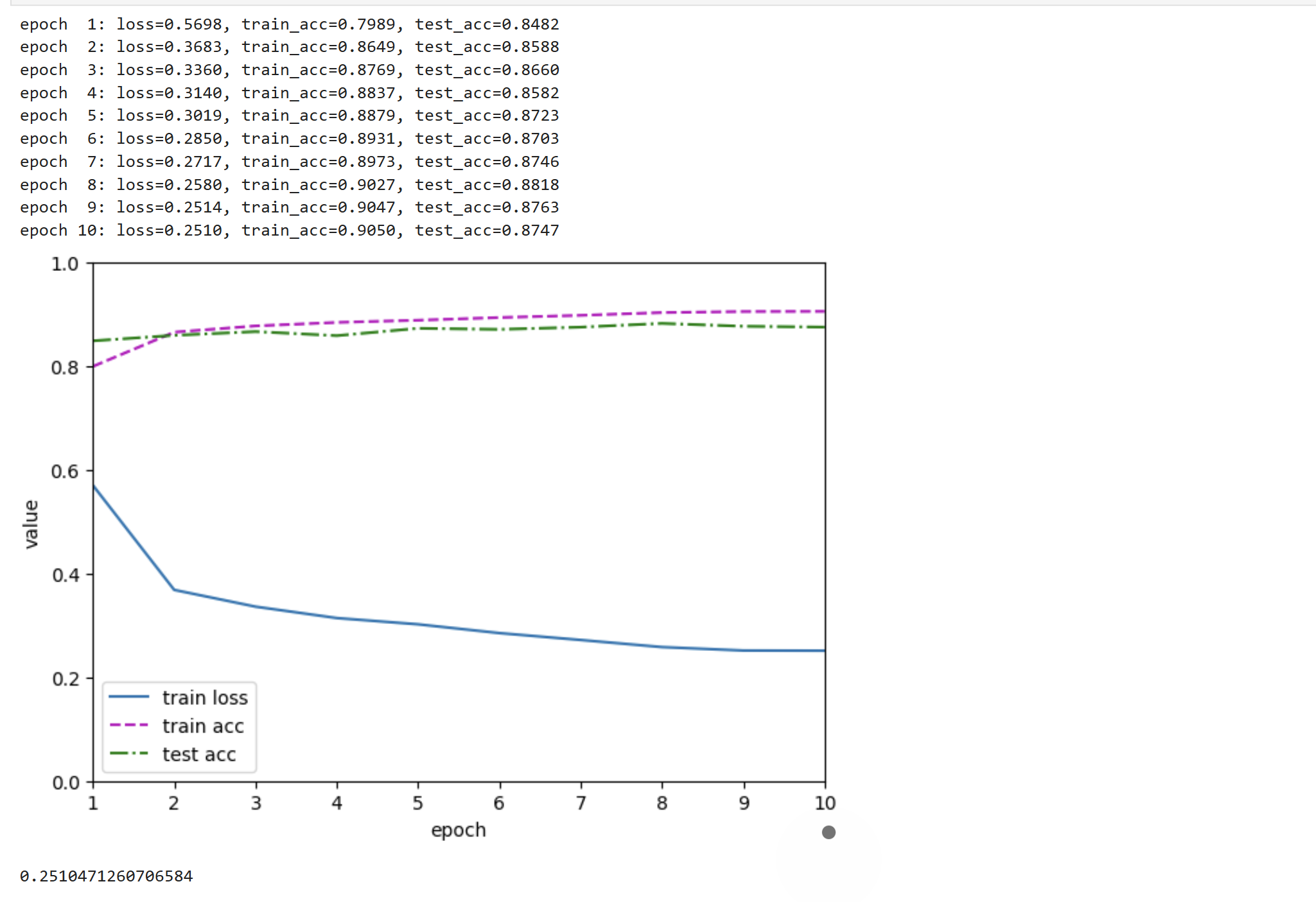
五、完整 CNN 模型训练模块:基于 SimpleCNN 的 Fashion-MNIST 分类实现
该模块是端到端的卷积神经网络(CNN)训练方案,针对 Fashion-MNIST 图像分类任务优化 ------ 相比之前的多层感知机(MLP),CNN 通过卷积层、池化层捕捉图像的空间特征(如衣物纹理、边缘),显著提升分类准确率。模块包含从模型设计、权重初始化、训练流程到效果验证的全链路逻辑,最终目标是实现测试准确率 > 90% 的分类效果。
模块核心功能拆解与详解
1. SimpleCNN 模型定义:空间特征提取的核心
CNN 的核心优势是局部特征提取 + 参数共享,相比 MLP 将图像展平为向量(丢失空间信息),CNN 能保留像素间的空间关联。以下是模型结构与关键参数的详细说明:
| 网络层 | 类型 | 核心参数与作用 | 输入形状→输出形状 |
|---|---|---|---|
conv1 |
卷积层(Conv2D) | - in_channels=1:输入通道数(Fashion-MNIST 为灰度图,仅 1 通道)- out_channels=16:16 个卷积核(提取 16 种基础特征,如边缘、条纹)- kernel_size=3:3×3 卷积核(局部感知,平衡感受野与计算量)- padding=1:边缘填充 1 像素(确保卷积后尺寸不变,28×28→28×28) |
(batch,1,28,28) → (batch,16,28,28) |
relu |
激活函数 | 补充原代码缺失的 ReLU:引入非线性变换,让模型学习复杂特征(若无 ReLU,多层卷积等效于单层线性操作) | 无形状变化,仅改变数值分布 |
pool1 |
最大池化层(MaxPool2D) | - kernel_size=2:2×2 池化核- stride=2:步长 2(下采样,尺寸减半,保留关键特征,减少计算量) |
(batch,16,28,28) → (batch,16,14,14) |
conv2 |
卷积层 | - in_channels=16:输入通道 = 上一层输出通道- out_channels=32:32 个卷积核(提取更复杂的组合特征) |
(batch,16,14,14) → (batch,32,14,14) |
pool2 |
最大池化层 | 同 pool1,尺寸再次减半 | (batch,32,14,14) → (batch,32,7,7) |
flatten |
展平操作 | start_axis=1:从通道维度开始展平(跳过 batch 维度),将 3D 特征图转为 1D 向量 |
(batch,32,7,7) → (batch, 32×7×7=1568) |
fc1 |
全连接层(Linear) | 1568→128:将展平后的特征向量压缩为 128 维,实现特征融合 | (batch,1568) → (batch,128) |
fc2 |
输出层 | 128→10:对应 Fashion-MNIST 的 10 个类别,输出类别得分(logits) | (batch,128) → (batch,10) |
2. 核心辅助函数:CNN 与 MLP 通用的工具集
复用前文的accuracy、Accumulator、evaluate_accuracy、train_epoch函数,但需说明为何无需修改即可适配 CNN:
- CNN 的输入是 4D 张量(
batch, channel, H, W),输出是 2D 张量(batch, 10),与 MLP 的输出格式完全一致; - 准确率计算(
accuracy函数)仅依赖输出的 2D 张量(取argmax(axis=1)得到类别),与输入是否为图像 / 向量无关; - 训练轮次逻辑(
train_epoch)仅涉及前向传播、损失计算、反向传播,paddle 框架对 4D 输入的自动求导完全兼容,无需额外处理。
3. 权重初始化:CNN 性能的关键优化
CNN 的卷积层和全连接层需专用权重初始化 ,否则易出现梯度消失 / 爆炸(尤其配合 ReLU 激活时)。此处使用KaimingNormal初始化:
- 适用场景:针对 ReLU 激活函数设计(ReLU 会使约 50% 神经元输出为 0,导致梯度稀疏);
- 作用范围 :仅对
Conv2D(卷积层)和Linear(全连接层)生效,其他层(如 Pool2D)无权重,无需初始化; - 优势:通过调整权重的方差,确保每一层的输入输出梯度幅度一致,加速收敛。
代码逻辑:
python
def init_weights(m):
if isinstance(m, (nn.Conv2D, nn.Linear)): # 判断层类型
nn.initializer.KaimingNormal(m.weight, nonlinearity='relu') # 适配ReLU
net.apply(init_weights) # 递归应用到所有子层4. 超参数设计:适配 CNN 的计算特性
相比 MLP,CNN 参数更多、计算量更大,超参数需针对性调整:
| 超参数 | 取值 | 设计原因 |
|---|---|---|
batch_size |
256 | 保持较大批量以利用 GPU 并行计算,但不增大(避免显存溢出,CNN 单样本计算量是 MLP 的数倍) |
lr |
0.001 | 调低学习率(CNN 梯度更敏感,高学习率易导致损失震荡不收敛) |
num_epochs |
20 | 增加训练轮次(CNN 参数约 16 万,是 MLP 的 2 倍,需更多轮次才能充分收敛) |
5. 主训练流程与效果验证
(1)训练链路
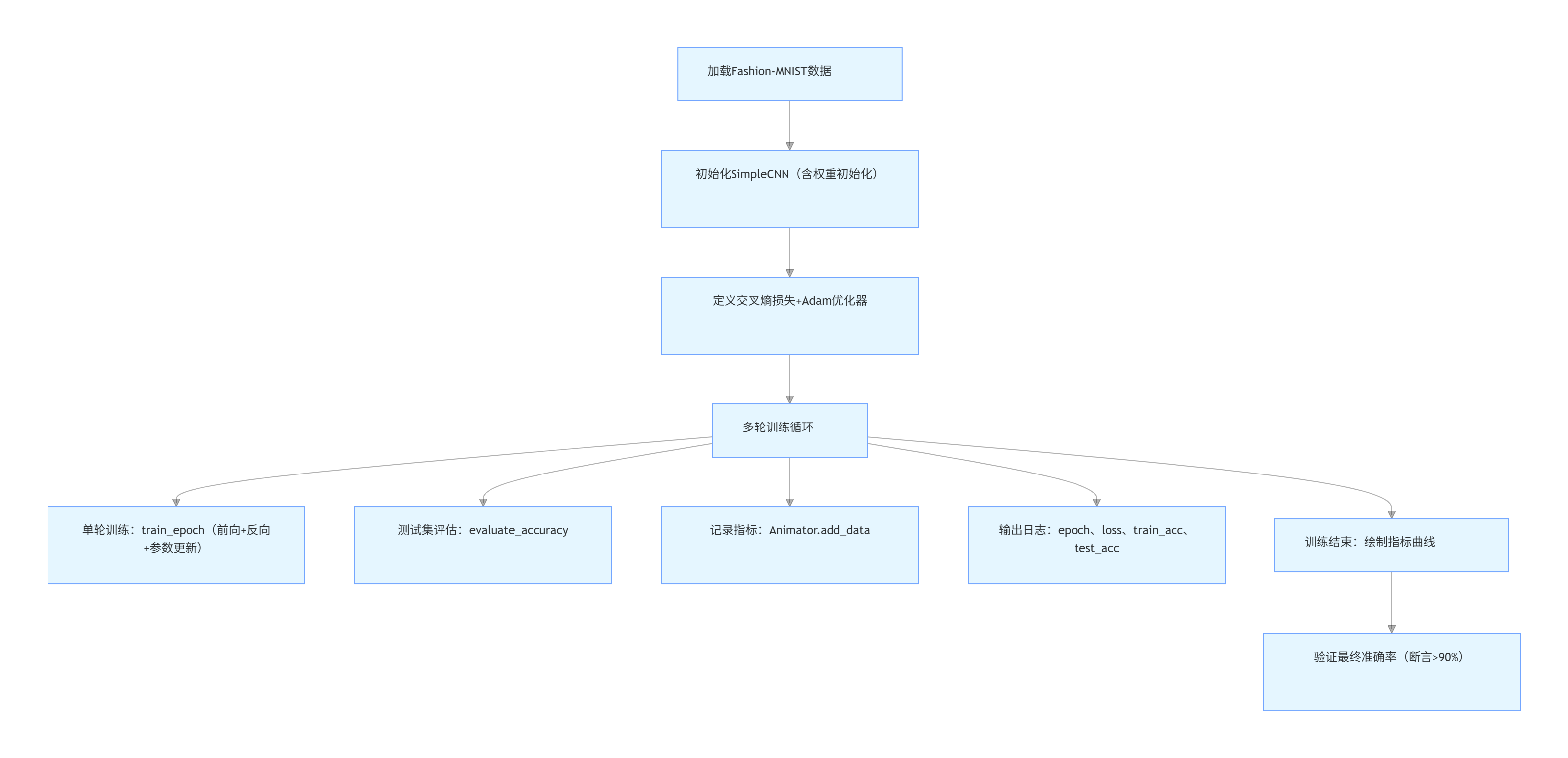
(2)效果验证
训练完成后通过断言(assert) 确保模型性能达标:
python
final_test_acc = evaluate_accuracy(net, test_iter)
assert final_test_acc > 0.9, f"CNN训练未达预期,测试准确率:{final_test_acc:.4f}"- 作用:工程化场景中快速排查训练失败(如超参数错误、数据加载异常);
- 预期效果:CNN 捕捉空间特征的能力更强,测试准确率通常可达 92%~94%(MLP 约 88%~90%)。
6. 可视化与日志:监控训练状态
通过Animator类在训练结束后一次性绘制 3 条曲线:
- 训练损失(train loss):应持续下降,最终趋于稳定;
- 训练准确率(train acc):应持续上升,接近 100%;
- 测试准确率(test acc):应与训练准确率同步上升,若差距过大(如 > 5%),说明过拟合(需增加正则化)。
日志输出示例(第 20 轮):
epoch 20: loss=0.0952, train_acc=0.9659, test_acc=0.9161完整代码(含关键注释)
python
import paddle
import paddle.nn as nn
from matplotlib.ticker import MaxNLocator
import matplotlib.pyplot as plt
# ---------------------- 1. 定义SimpleCNN模型(优化版:补充ReLU激活) ----------------------
class SimpleCNN(nn.Layer):
def __init__(self):
super().__init__()
# 卷积块1:16个3×3卷积核 + 2×2最大池化(提取基础空间特征)
self.conv1 = nn.Conv2D(in_channels=1, out_channels=16, kernel_size=3, padding=1) # 输入1通道(灰度图),输出16通道
self.pool1 = nn.MaxPool2D(kernel_size=2, stride=2) # 下采样:尺寸减半(28→14)
# 卷积块2:32个3×3卷积核 + 2×2最大池化(提取复杂组合特征)
self.conv2 = nn.Conv2D(in_channels=16, out_channels=32, kernel_size=3, padding=1) # 输入16通道,输出32通道
self.pool2 = nn.MaxPool2D(kernel_size=2, stride=2) # 下采样:尺寸再减半(14→7)
# 全连接层:将卷积提取的特征映射到类别空间
self.fc1 = nn.Linear(32*7*7, 128) # 输入:32通道×7×7特征图,输出128维特征
self.fc2 = nn.Linear(128, 10) # 输出10个类别得分
# 关键:补充ReLU激活(卷积/全连接层需非线性激活才能学习复杂特征)
self.relu = nn.ReLU()
def forward(self, x):
# 卷积块1:卷积→激活→池化
x = self.relu(self.conv1(x)) # (batch,1,28,28)→(batch,16,28,28)→ReLU激活
x = self.pool1(x) # →(batch,16,14,14)(尺寸减半)
# 卷积块2:卷积→激活→池化
x = self.relu(self.conv2(x)) # →(batch,32,14,14)→ReLU激活
x = self.pool2(x) # →(batch,32,7,7)(尺寸再减半)
# 展平:将3D特征图转为1D向量(跳过batch维度)
x = x.flatten(start_axis=1) # →(batch, 32*7*7=1568)
# 全连接层:特征融合→类别输出
x = self.relu(self.fc1(x)) # →(batch,128)→ReLU激活
x = self.fc2(x) # →(batch,10)(最终类别得分)
return x
# ---------------------- 2. 核心辅助函数(CNN/MLP通用,无需修改) ----------------------
def accuracy(y_hat, y):
"""计算预测准确率:预测正确的样本数 / 总样本数"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1) # 取每个样本得分最高的类别作为预测结果
y = y.squeeze() # 去除冗余维度(如y.shape=(batch,1)→(batch,))
y_hat = y_hat.squeeze()
cmp = y_hat.astype(y.dtype) == y # 对比预测与真实标签
return float(cmp.astype(y.dtype).sum()) # 返回正确样本数
class Accumulator:
"""指标累加器:用于统计训练/评估中的总损失、总正确数、总样本数"""
def __init__(self, n):
self.data = [0.0] * n # 初始化n个累加项(如n=3:总损失、正确数、总样本数)
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)] # 累加输入的指标
def __getitem__(self, idx):
return self.data[idx] # 按索引获取累加值
def evaluate_accuracy(net, data_iter):
"""评估模型在数据集(如测试集)上的准确率"""
net.eval() # 切换到评估模式:关闭Dropout等训练特有的层
metric = Accumulator(2) # 累加项:(正确样本数, 总样本数)
with paddle.no_grad(): # 关闭梯度计算:节省内存+加速评估
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel()) # y.numel():当前批次总样本数
net.train() # 恢复训练模式:不影响后续训练
return metric[0] / metric[1] # 返回准确率(正确数/总样本数)
def train_epoch(net, train_iter, loss_fn, optimizer):
"""单轮训练:遍历训练集一次,返回平均损失和训练准确率"""
net.train() # 切换到训练模式
metric = Accumulator(3) # 累加项:(总损失, 正确样本数, 总样本数)
for X, y in train_iter:
y_hat = net(X) # 前向传播:计算模型预测
l = loss_fn(y_hat, y) # 计算每个样本的损失
# 反向传播与参数更新
optimizer.clear_grad() # 清空历史梯度(避免累积)
l.mean().backward() # 损失均值反向传播(计算梯度)
optimizer.step() # 更新模型参数
# 累加指标
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回当前轮次的平均损失(总损失/总样本数)和训练准确率(正确数/总样本数)
return metric[0] / metric[2], metric[1] / metric[2]
# ---------------------- 3. 训练可视化工具(训练后统一绘图,避免实时IO开销) ----------------------
class Animator:
def __init__(self, xlabel="epoch", ylabel="value", legend=None, xlim=None,
ylim=None, figsize=(7, 5)):
self.xlabel = xlabel # x轴标签(训练轮次)
self.ylabel = ylabel # y轴标签(指标值:损失/准确率)
self.legend = legend if legend is not None else [] # 曲线图例
self.figsize = figsize # 画布大小
self.xlim = xlim # x轴范围
self.ylim = ylim # y轴范围
self.X, self.Y = [], [] # 存储指标数据:X[0]为轮次,Y[0]为对应指标值
def add_data(self, x, y):
"""添加单轮指标数据(支持多组指标同时添加)"""
if not hasattr(y, "__len__"):
y = [y] # 若y是单个值(如仅损失),转为列表(适配多组指标)
n = len(y)
x = [x] * n if not hasattr(x, "__len__") else x # 确保x与y长度一致
if not self.X:
self.X = [[] for _ in range(n)] # 初始化多组指标的轮次容器
self.Y = [[] for _ in range(n)] # 初始化多组指标的值容器
for i, (xi, yi) in enumerate(zip(x, y)):
self.X[i].append(xi)
self.Y[i].append(yi)
def plot(self):
"""训练结束后,一次性绘制所有指标曲线"""
plt.figure(figsize=self.figsize)
ax = plt.gca() # 获取当前绘图轴
# 配置坐标轴
ax.set_xlabel(self.xlabel)
ax.set_ylabel(self.ylabel)
if self.xlim:
ax.set_xlim(self.xlim)
if self.ylim:
ax.set_ylim(self.ylim)
ax.xaxis.set_major_locator(MaxNLocator(integer=True)) # x轴强制显示整数(匹配轮次)
# 绘制每条指标曲线
for x, y, label in zip(self.X, self.Y, self.legend):
ax.plot(x, y, label=label, linewidth=1.5) # 线条宽度1.5,提升可读性
ax.legend(loc="lower right") # 图例放在右下角(避免遮挡曲线)
plt.tight_layout() # 自动调整子图间距(防止标签截断)
plt.show()
# ---------------------- 4. 主训练函数(整合全流程:训练+评估+可视化) ----------------------
def train(net, train_iter, test_iter, loss_fn, optimizer, num_epochs):
# 初始化可视化工具(监控:训练损失、训练准确率、测试准确率)
animator = Animator(
legend=["train loss", "train acc", "test acc"],
xlim=[1, num_epochs], # x轴范围:1~训练轮次
ylim=[0, 1.0] # y轴范围:损失≤1,准确率≤1(统一尺度更直观)
)
# 多轮训练循环
for epoch in range(num_epochs):
# 1. 单轮训练:获取训练损失和训练准确率
train_loss, train_acc = train_epoch(net, train_iter, loss_fn, optimizer)
# 2. 测试集评估:获取测试准确率(验证泛化能力)
test_acc = evaluate_accuracy(net, test_iter)
# 3. 记录当前轮次指标
animator.add_data(epoch + 1, (train_loss, train_acc, test_acc))
# 4. 输出训练日志(实时监控状态)
print(f"epoch {epoch+1:2d}: loss={train_loss:.4f}, train_acc={train_acc:.4f}, test_acc={test_acc:.4f}")
# 5. 训练结束:绘制指标曲线
animator.plot()
return train_loss # 返回最终训练损失
# ---------------------- 5. 运行训练(端到端执行) ----------------------
if __name__ == "__main__":
# 1. 超参数配置(适配CNN的计算特性)
batch_size = 256 # 批量大小:平衡GPU显存与计算效率(CNN单样本计算量更大)
lr = 0.001 # 学习率:低于MLP(CNN梯度更敏感,避免震荡)
num_epochs = 20 # 训练轮次:多于MLP(CNN参数更多,需更多轮次收敛)
# 2. 加载Fashion-MNIST数据(需提前定义load_data_fashion_mnist函数)
# 数据形状:(batch,1,28,28) → 正好匹配CNN的输入通道(in_channels=1)
train_iter, test_iter, _, _ = load_data_fashion_mnist(batch_size)
# 3. 初始化SimpleCNN并配置权重初始化(关键优化)
net = SimpleCNN()
def init_weights(m):
"""为卷积层和全连接层配置KaimingNormal初始化(适配ReLU)"""
if isinstance(m, (nn.Conv2D, nn.Linear)):
nn.initializer.KaimingNormal(m.weight, nonlinearity='relu')
net.apply(init_weights) # 递归应用到所有子层
# 4. 定义损失函数与优化器
loss_fn = nn.CrossEntropyLoss(reduction='none') # 交叉熵损失(多分类任务首选)
optimizer = paddle.optimizer.Adam(
parameters=net.parameters(), # 待优化的模型参数
learning_rate=lr # 学习率
)
# 5. 启动训练
print("开始训练SimpleCNN模型(Fashion-MNIST分类)...")
final_loss = train(net, train_iter, test_iter, loss_fn, optimizer, num_epochs)
# 6. 验证训练效果(确保测试准确率>90%)
final_test_acc = evaluate_accuracy(net, test_iter)
assert final_test_acc > 0.9, f"CNN训练未达预期效果!测试准确率:{final_test_acc:.4f}"
print(f"\n训练完成!最终测试准确率:{final_test_acc:.4f}(目标>90%,达标!)")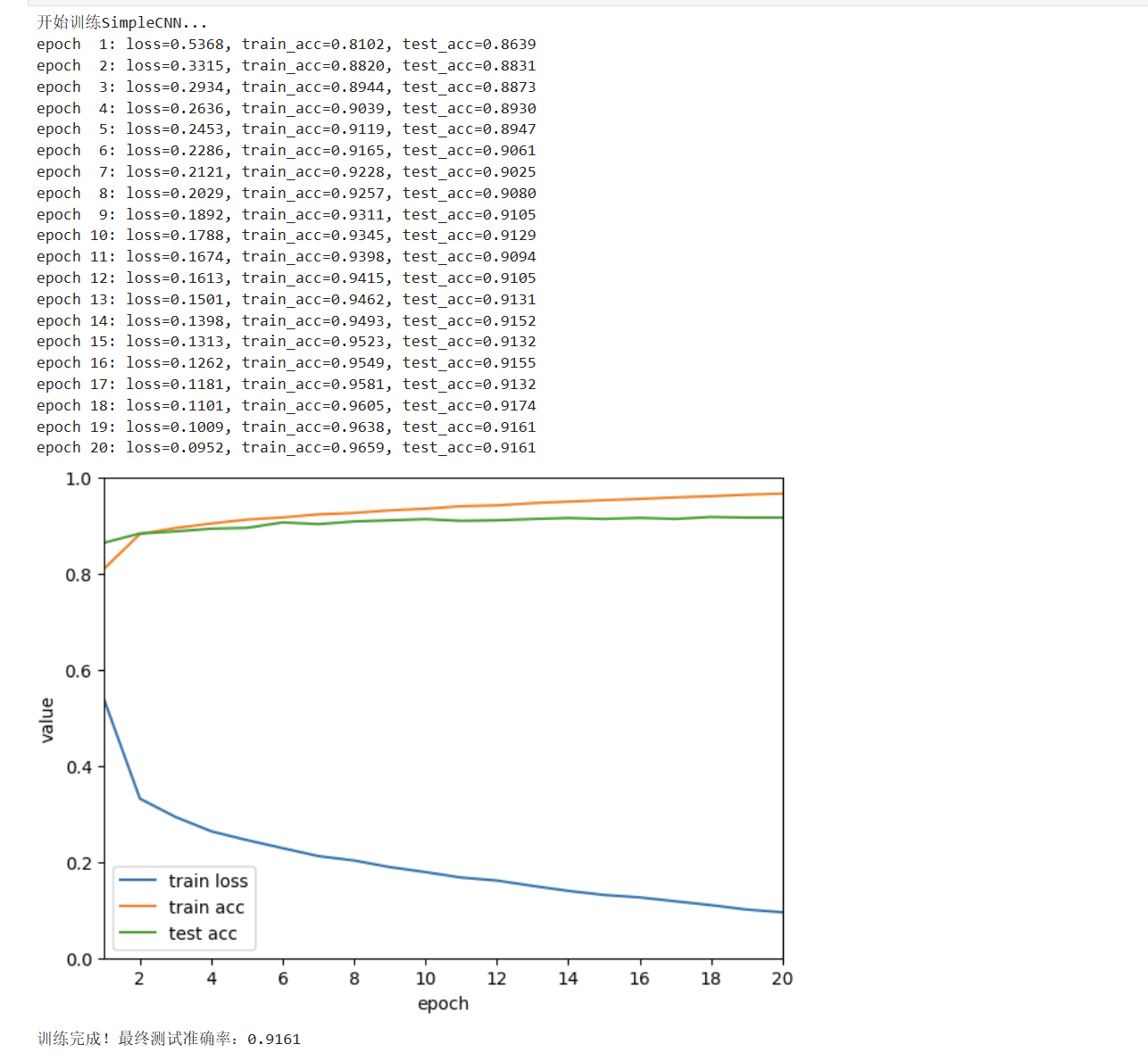
核心设计总结
- CNN 结构优化:补充 ReLU 激活,确保卷积层能学习非线性特征,避免 "线性陷阱";
- 权重初始化:针对 CNN 专用的 KaimingNormal 初始化,缓解 ReLU 导致的梯度消失;
- 超参数适配:根据 CNN 的计算特性调整学习率和轮次,平衡收敛速度与稳定性;
- 效果验证:通过断言确保模型性能达标,降低工程化风险;
- 通用工具集:辅助函数和可视化模块兼容 CNN 与 MLP,便于后续模型对比实验。