TODO

看来AI的应用和应用之间,差别也是非常大。相比语音识别,视觉人形探测在各方面都简单一些。
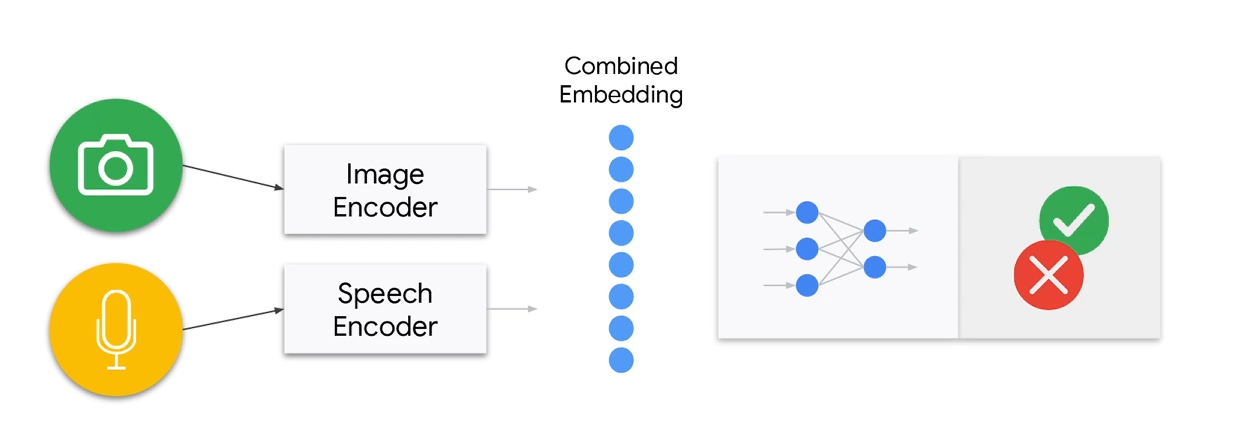
训练模型时,可以综合视频和音频。这里有一个典型场景,在疫情时期,如果希望不接触按键,同时电梯监测乘客是不是带了口罩。

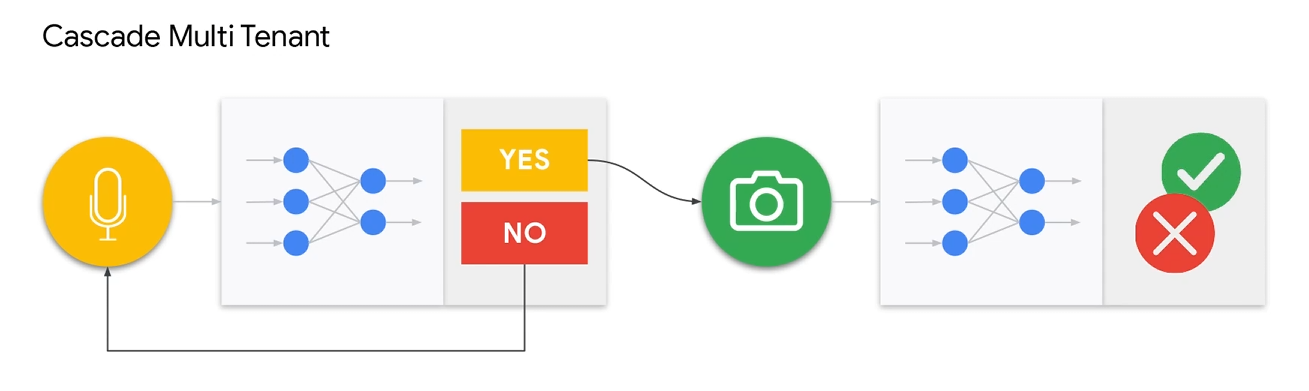
这里的有两种,第一种叫做MultiModal,一种是Multi-Tenancy。前阵就是多个传感器最后融合成一个模型,后者就是多个模型并行或者串行处理。
查了一下,目前在嵌入式AI领域,后者居多。在这个教程中,使用的也是后一种。
MultiModal
Multi-Tenancy
不过多模型,有一个内存限制的问题。主要是在SRAM方面。
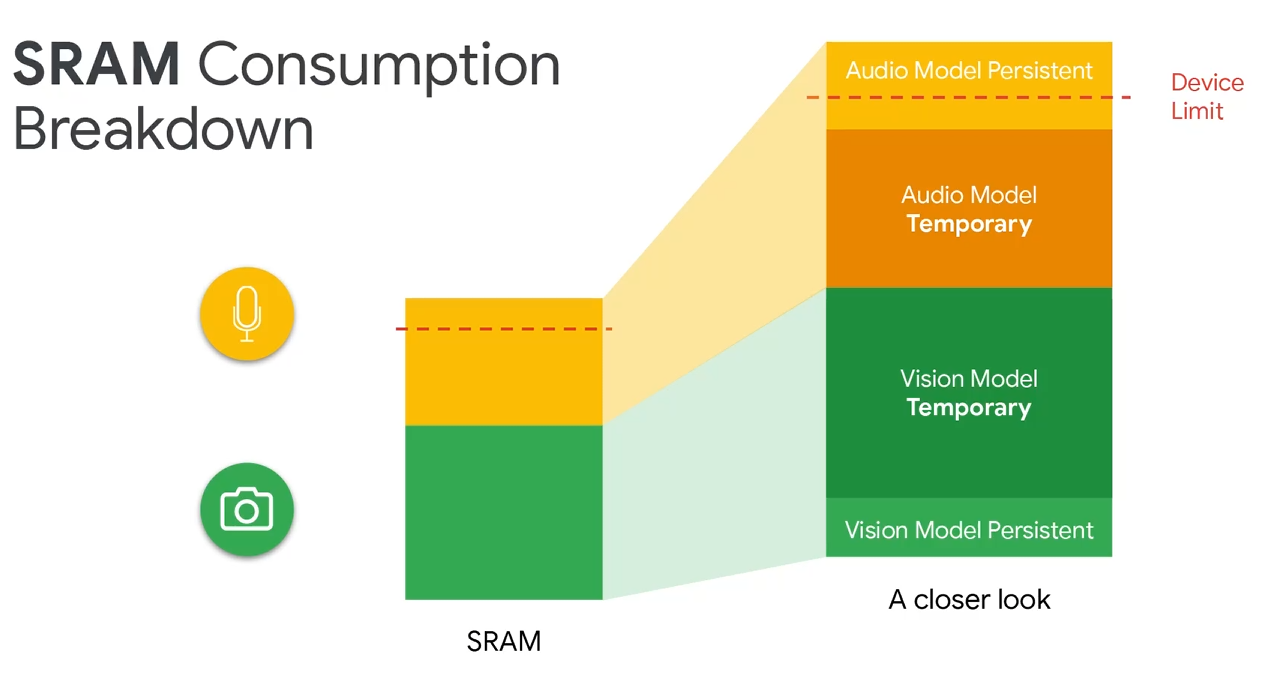
具体怎么解决,等待后面更新。。。
更换到OV7675。
Changes for the OV7670
To use the OV7670 instead of the OV7675, simply make the change you made in the camera test! Change the fourth argument of the call to Camera.begin() as highlighted below, from OV7675 to OV7670. That's it! The library will handle the rest! You can find the camera initialization in:
// Initialize the OV7675 camera
void if(!Camera.begin(QCIF, GRAYSCALE, 5, OV7675)) {
Serial.println("Failed to initialize camera");
While (1);
}
就是Arduino里面的例子。