今天,阿里通义千问团队正式宣布开源Qwen3-VL系列的4B与8B版本,以更小的参数量实现了接近上一代72B旗舰模型的性能表现,为资源受限的开发环境提供了新的选择。

两款模型均提供Instruct和Thinking两个版本,满足不同场景下的使用需求。
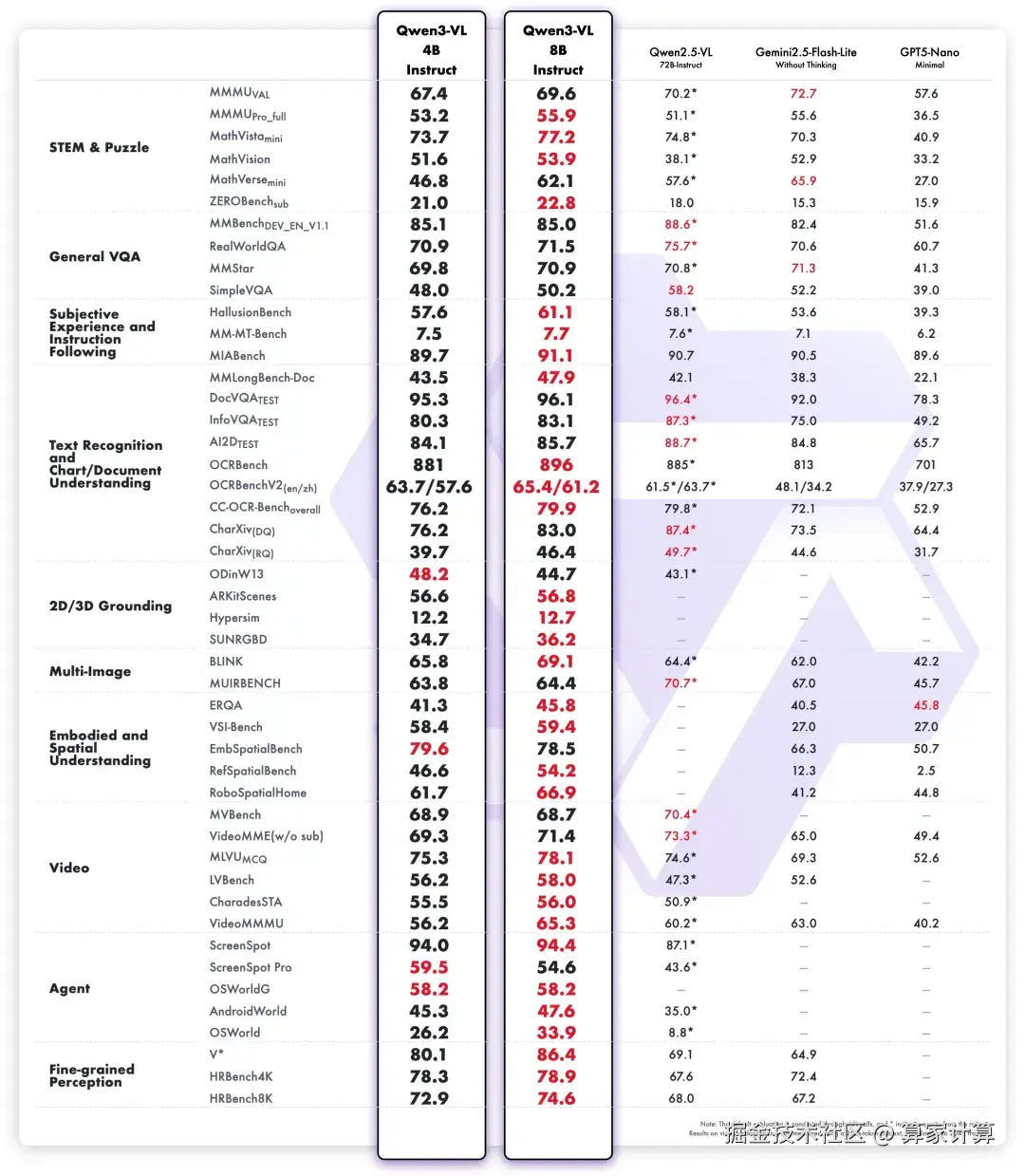
在多模态性能方面,Qwen3-VL-8B Instruct在MIABench、OCRBench、SUNRGBD、ERQA、VideoMMMU、ScreenSpot等30项权威基准测评中取得SOTA成绩,超越了Gemini 2.5 Flash Lite、GPT-5 Nano以及Qwen2.5-VL-72B等顶尖模型。
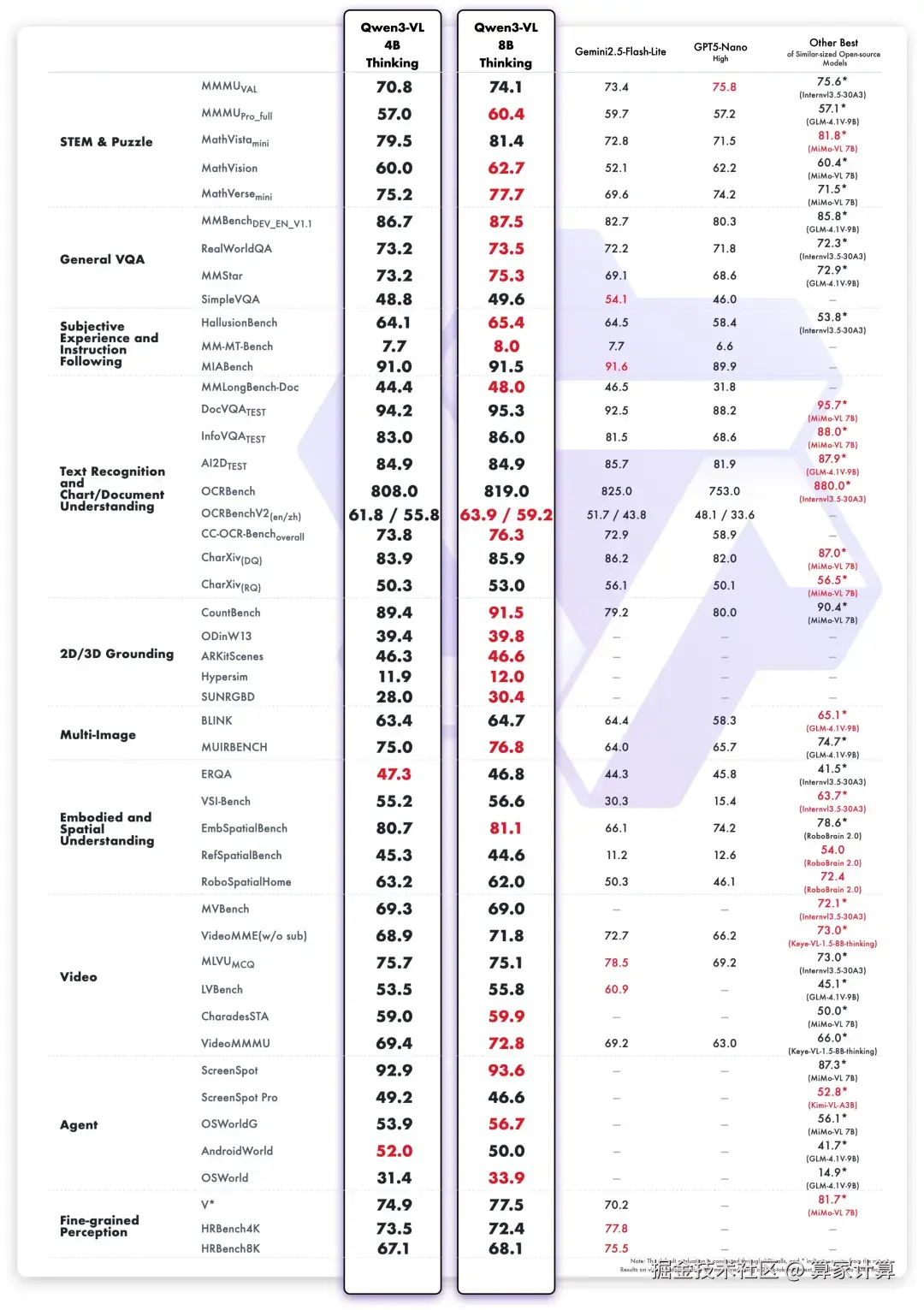
Thinking版本在MathVision、MMStar、HallusionBench、MM-MT-Bench、CountBench等23项权威基准测评中取得了SOTA成绩。
破解"跷跷板"难题
长期以来,小模型面临着一个棘手的问题------增强视觉能力时往往削弱文本理解,反之亦然。这种现象被业界称为"跷跷板"问题。
阿里通过架构创新与技术优化,成功解决了这一难题。新模型实现了"视觉精准"与"文本稳健"的协同提升,在强化多模态感知与视觉理解的同时,保持了原有的文本理解能力。
这一突破使得Qwen3-VL-8B Instruct在MIABench、OCRBench、SUNRGBD、ERQA、VideoMMMU、ScreenSpot等30项权威基准测评中取得SOTA成绩。不仅在视觉理解领域表现出色,在纯文本任务上也实现了整体性能提升。
Qwen3-VL-4B特别侧重端侧应用,具备更高的性价比,适用于需要AI视觉理解能力的智能终端部署。这一特性使其在手机和机器人领域具有重大意义。
模型一经发布,便在外网引起热烈反响。有网友表示"终于,我在16GB的Mac上可以用了"。
作为阿里视觉理解领域迄今最强模型家族,上个月发布的Qwen3-VL系列在9月底的Chatbot Arena子榜单Vision Arena中位居第二,成为视觉理解领域的全球开源冠军。
同时,Qwen3-VL还斩获纯文本赛道的开源第一,成为首个揽获纯文本和视觉两大领域同时开源第一的大模型。
在全球知名的大模型API三方聚合平台OpenRouter图像处理榜单上,Qwen3-VL以48%的市场份额跃升至全球第一。
目前,两款模型已上线魔搭社区与Hugging Face平台,并提供FP8版本支持。为了帮助开发者更好地使用新模型,阿里还推出了Qwen3-VL Cookbook使用指南。该指南涵盖图像思维、计算机使用Agent、多模态编程、3D定位、空间推理、视频理解等多种多模态用例,为用户提供高效上手和深度应用的支持。
阿里通义千问大语言模型负责人林俊旸指出,小型视觉语言模型适合部署,尤其在手机和机器人领域意义重大。过去小模型与大模型性能差距大,此次发布的小模型在参数量大幅减少的情况下,仍能保持接近大模型的性能水平。
Qwen3-VL轻量版模型的开源,标志着视觉语言模型技术正朝着更高效、更普惠的方向发展。这些模型在保持高性能的同时大幅降低资源需求,为AI技术在边缘设备、移动终端等场景的落地提供了新的可能。
随着模型性能的不断提升和开源生态的完善,我们可以预见将有更多创新应用涌现,从智能家居到工业自动化,从移动应用到嵌入式设备,视觉语言模型将以更低的门槛为各行各业赋能。