标准 IO 基础
核心概念
-
POSIX 标准:统一不同操作系统的访问接口,让遵循该标准的程序能在 Linux、Windows 等系统间移植(比如标准 C 库的 IO 函数在多系统通用)。
-
标准 C 库 :遵循 POSIX 标准的函数集合,包含标准 IO 函数(如
fopen、fread),需通过头文件<stdio.h>调用。 -
<stdio.h>路径 :Linux 系统下路径为/usr/include/stdio.h。 -
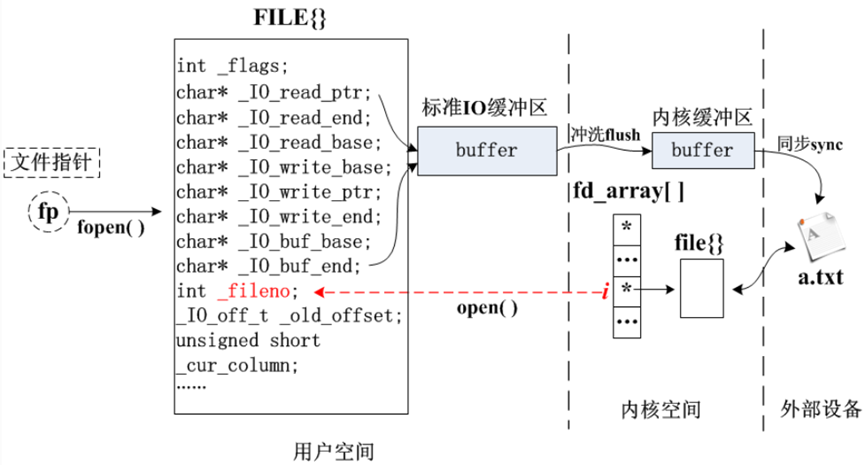
FILE 结构体:标准 IO 库管理文件的核心结构体,本质是 "文件信息容器",包含:
- 文件描述符(
_fileno):关联内核中的文件。 - 缓冲区指针(如
_IO_read_ptr读指针、_IO_write_ptr写指针):暂存读写数据,减少 IO 设备访问次数。 - 状态标志(
_flags):标记文件是否出错、是否到末尾等。 - 链表指针(
chain):内核用链表管理所有打开的文件,每个 FILE 结构体通过chain连接。
- 文件描述符(
-
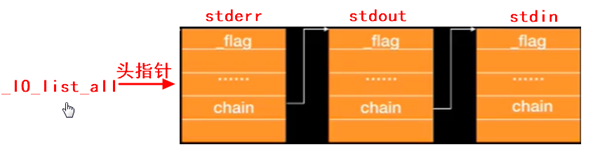
默认打开的 3 个流 :程序启动时,内核自动打开 3 个标准流,均为
FILE*类型:stdin:标准输入(默认对应键盘),行缓冲。stdout:标准输出(默认对应屏幕),行缓冲。stderr:标准出错(默认对应屏幕),无缓冲(错误信息需立即输出)。
核心标准 IO 函数
文件打开:fopen、freopen、fdopen
fopen(最常用,打开指定路径文件)
c
#include <stdio.h>
/**
* 以指定模式打开文件,返回文件流指针
* @param pathname 待打开文件的路径(如"demo.txt"、"/home/user/test.dat")
* @param mode 打开模式(字符串形式,决定读写权限和文件处理方式):
* - "r":只读,文件必须存在,不存在则打开失败
* - "r+":读写,文件必须存在,不存在则打开失败
* - "w":只写,文件不存在则创建,存在则清空内容
* - "w+":读写,文件不存在则创建,存在则清空内容
* - "a":追加写,文件不存在则创建,写入位置始终在文件末尾
* - "a+":追加读写,文件不存在则创建,写入在末尾,读取位置默认在开头(Linux下)
* @return 成功:返回指向FILE结构体的指针(文件流指针);失败:返回NULL(需判断,避免野指针)
* @note 打开成功后,内核从堆内存分配FILE结构体空间;
不可反复调用fclose关闭同一文件(会导致double free错误)
*/
FILE *fopen(const char *pathname, const char *mode);freopen(重定向流,如将 stdout 重定向到文件)
c
#include <stdio.h>
/**
* 重定向文件流(将指定流关联到新文件)
* @param pathname 新文件路径(如"log.txt")
* @param mode 打开模式(同fopen的mode,如"w"、"a")
* @param stream 待重定向的流(如stdout、stdin)
* @return 成功:返回重定向后的stream;失败:返回NULL
* @note 常用于将标准输出(stdout)重定向到文件,实现"日志写入"
*/
FILE *freopen(const char *pathname, const char *mode, FILE *stream);fdopen(将文件描述符转换为文件流指针)
c
#include <stdio.h>
/**
* 将内核的文件描述符(fd)转换为FILE*流(适配标准IO函数)
* @param fd 已打开的文件描述符(如open函数返回的fd)
* @param mode 打开模式(同fopen,但需与fd的权限匹配,如fd是只读的,mode不能用"w")
* @return 成功:返回FILE*指针;失败:返回NULL
* @note 用于"系统调用IO"(如open)与"标准IO"(如fread)的衔接
*/
FILE *fdopen(int fd, const char *mode);二进制模式 vs 文本模式
- 二进制模式 :使用
"rb"(二进制只读)、"wb"(二进制只写)、"r+b"(二进制读写)作为打开模式,数据按 "原始字节" 读写,系统不对任何字符进行解释或转换。适用场景:图片(如 JPG/PNG)、音频(如 MP3/WAV)、视频、可执行文件(如.exe/.out)等二进制文件,以及需要精确保留字节结构的文本文件(如配置文件)。例如,用二进制模式读取图片文件时,每个字节(包括\n、\r等特殊字符)都会原样保留,避免文件损坏。 - 文本模式 :使用
"r"(文本只读)、"w"(文本只写)、"r+"(文本读写)作为打开模式,不同操作系统对 "换行符" 的处理存在差异:- Windows 系统:写入时会将文本中的
\n(换行)自动转换为\r\n(回车 + 换行),读取时再将\r\n反向转换为\n; - Linux/macOS 系统:无任何字符转换(
\n直接表示换行)。适用场景:仅用于跨 Windows/Linux 且无需保留原始字节的纯文本文件(如.txt文档)。若跨系统处理文件,推荐优先使用二进制模式,避免因换行符转换导致数据错位(如 Linux 下用文本模式读取 Windows 生成的文件,会多出现\r字符)。
- Windows 系统:写入时会将文本中的
文件读取:按字符、按行、按块
按字符读取:fgetc、getc、getchar
fgetc(从指定流读 1 个字符)
c
#include <stdio.h>
/**
* 从指定文件流读取1个字符,同时移动文件光标(位置指示器)
* @param stream 待读取的文件流(如fp、stdin)
* @return 成功:返回读取字符的ASCII码(unsigned char转换为int);
* 失败/到文件末尾:返回EOF(宏定义,值为-1,定义在<stdio.h>中)
* @note 需通过feof()和ferror()区分"到末尾"和"读错误";
每次读取后,光标后移1字节
*/
int fgetc(FILE *stream);getc与getchar
getc:功能与fgetc完全一致,但getc是宏定义实现,多次计算stream参数(如getc(fp++)会出错,避免此类用法)。getchar:等价于getc(stdin),仅从标准输入(键盘)读 1 个字符
c
/**
* getc:同fgetc(宏实现,需注意参数副作用)
* @param stream 待读取的流
* @return 成功返回字符ASCII码,失败/末尾返回EOF
*/
int getc(FILE *stream);
/**
* getchar:仅从stdin读1个字符(等价于getc(stdin))
* @return 成功返回字符ASCII码,失败/末尾返回EOF
*/
int getchar(void);按行读取:fgets(安全读取一行)
c
#include <stdio.h>
/**
* 从指定流读取一行字符,存储到缓冲区,避免缓冲区溢出
* @param s 自定义缓冲区(用于存储读取的字符,需提前分配空间,如char buf[1024])
* @param n 缓冲区大小(最大读取n-1个字符,最后1个字节自动存'\0',保证字符串结束)
* @param stream 待读取的流(如fp、stdin)
* @return 成功:返回缓冲区s的地址;失败/到末尾(且未读任何字符):返回NULL
* @note 读取停止条件:读满n-1个字符、遇到'\n'(会保留'\n'在缓冲区)、遇到EOF;
* 若返回NULL,需用feof()和ferror()区分原因;3. 避免用gets()(无缓冲区大小限制,会溢出)
*/
char *fgets(char *s, int n, FILE *stream);按块读取:fread(高效读取二进制 / 大量数据)
c
#include <stdio.h>
/**
* 从流中读取指定数量的"数据块"(适合二进制文件,如图片、音频,或大量文本)
* @param ptr 自定义缓冲区指针(存储读取的数据,需提前分配空间)
* @param size 每个数据块的字节数(如读int类型,size=sizeof(int))
* @param nmemb 要读取的数据块总数(如读10个int,nmemb=10)
* @param stream 待读取的流
* @return 成功读取的"数据块个数":
* - 等于nmemb:读取完全成功;
* - 小于nmemb:可能是到文件末尾,或读错误;
* - 0:size/nmemb为0,或读取失败
* @note 总读取字节数 = 成功读取的块数 × size;
需用feof()和ferror()区分"末尾"和"错误"
*/
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);文件写入:按字符、按行、按块
按字符写入:fputc、putc、putchar
c
#include <stdio.h>
/**
* 将1个字符写入指定流,同时移动文件光标
* @param c 待写入的字符(需传入ASCII码,如'A'或65)
* @param stream 待写入的流(如fp、stdout)
* @return 成功:返回写入的字符(ASCII码);失败:返回EOF
* @note 若流是"追加模式"(a/a+),字符始终写入文件末尾
*/
int fputc(int c, FILE *stream);putc:功能与fputc一致,宏定义实现,注意参数副作用。putchar:等价于putc(c, stdout),仅写入标准输出(屏幕)。
按行写入:fputs
c
#include <stdio.h>
/**
* 将字符串写入指定流(不自动添加'\n',需手动加)
* @param s 待写入的字符串(以'\0'结尾,'\0'不会被写入)
* @param stream 待写入的流
* @return 成功:返回非负整数;失败:返回EOF
* @note 与puts()区别:puts()会自动在字符串后加'\n',且仅写入stdout
*/
int fputs(const char *s, FILE *stream);按块写入:fwrite(高效写入二进制 / 大量数据)
c
#include <stdio.h>
/**
* 将指定数量的"数据块"写入流(适合二进制文件或大量数据)
* @param ptr 存储待写入数据的缓冲区指针
* @param size 每个数据块的字节数(如写int类型,size=sizeof(int))
* @param nmemb 要写入的数据块总数
* @param stream 待写入的流
* @return 成功写入的"数据块个数":等于nmemb为完全成功,小于则为写入错误
* @note 总写入字节数 = 成功写入的块数 × size;
二进制写入需用"wb"模式,避免换行符转换
*/
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);文件关闭:fclose
c
#include <stdio.h>
/**
* 关闭文件流,释放资源
* @param stream 待关闭的文件流(如fp)
* @return 成功:返回0;失败:返回EOF(如流已关闭仍调用)
* @note 关闭前会自动刷新流的缓冲区(未写入的数据会被写入文件);
* 关闭后stream指针变为野指针,不可再使用;
* 禁止多次关闭同一流(会导致double free错误,堆内存重复释放)
*/
int fclose(FILE *stream);缓冲区刷新:fflush
标准 IO 的缓冲区需 "刷新" 后,数据才会从缓冲区写入文件 / 设备。fflush用于手动触发刷新。
c
#include <stdio.h>
/**
* 手动刷新流的缓冲区(将未写入的数据写入文件/设备)
* @param stream 待刷新的流(如fp、stdout);若为NULL,刷新所有可刷新的流
* @return 成功:返回0;失败(如写错误):返回EOF
* @note 行缓冲流(如stdout)遇'\n'自动刷新;全缓冲流(如普通文件)满了自动刷新;
* 无缓冲流(如stderr)无需刷新,直接输出;关闭流(fclose)时会自动刷新
*/
int fflush(FILE *stream);文件位置控制:fseek、ftell、rewind
文件光标(位置指示器)默认在文件开头,读写时会自动后移。通过以下函数可手动控制光标位置。
fseek(设置光标位置)
c
#include <stdio.h>
/**
* 设置文件流的光标位置(仅支持二进制流;文本流限制较多,建议用二进制流)
* @param stream 待设置的流
* @param offset 偏移量(可正可负:正表示向后移,负表示向前移)
* @param whence 偏移基准点:
* - SEEK_SET:基准点为文件开头(offset必须≥0)
* - SEEK_CUR:基准点为当前光标位置
* - SEEK_END:基准点为文件末尾(offset负表示向前移,如offset=-10表示末尾前10字节)
* @return 成功:返回0;失败:返回非0(如offset超出文件范围)
* @note 二进制流可用所有基准点;
文本流仅支持offset=0且whence=SEEK_SET/SEEK_END
*/
int fseek(FILE *stream, long int offset, int whence);ftell(获取当前光标位置)
c
#include <stdio.h>
/**
* 获取文件流当前的光标位置(距离文件开头的字节数)
* @param stream 待获取的流
* @return 成功:返回光标位置(字节数,long类型);失败:返回-1L(L表示long)
* @note 常用于计算文件大小(光标移到末尾,用ftell获取位置即为文件大小)
*/
long int ftell(FILE *stream);rewind(光标移回文件开头)
c
#include <stdio.h>
/**
* 将文件流的光标移回文件开头(等价于fseek(stream, 0, SEEK_SET))
* @param stream 待操作的流
* @note 无返回值,无法判断是否成功;若需判断,建议用fseek
*/
void rewind(FILE *stream);错误与末尾判断:feof、ferror
fgetc、fread等函数返回 EOF 时,可能是 "到文件末尾",也可能是 "读写错误",需用以下函数区分。
c
#include <stdio.h>
/**
* 判断流是否到达文件末尾
* @param stream 待判断的流
* @return 是:返回非0值;否:返回0
* @note 仅在"读取操作返回EOF后"调用才有意义(提前调用可能误判)
*/
int feof(FILE *stream);
/**
* 判断流是否发生读写错误
* @param stream 待判断的流
* @return 是:返回非0值;否:返回0
* @note 错误标志需用clearerr()清除,否则后续操作仍会认为有错误
*/
int ferror(FILE *stream);
/**
* 清除流的"末尾标志"和"错误标志"
* @param stream 待清除的流
* @note 清除后,可重新对流转发读写操作
*/
void clearerr(FILE *stream);格式化 IO:fprintf、fscanf、sprintf、snprintf
fprintf(格式化写入流)
c
#include <stdio.h>
/**
* 按指定格式将数据写入流(如文件、屏幕)
* @param stream 待写入的流(如fp、stdout)
* @param format 格式控制字符串(如"%d %s",指定后续参数的类型和格式)
* @param ... 可变参数(需与format的格式匹配,如int、char*等)
* @return 成功:返回写入的字符总数;失败:返回负数
* @note 与printf()区别:printf()固定写入stdout,fprintf()可指定流
*/
int fprintf(FILE *stream, const char *format, ...);fscanf(格式化读取流)
c
#include <stdio.h>
/**
* 按指定格式从流中读取数据(需注意缓冲区残留问题)
* @param stream 待读取的流
* @param format 格式控制字符串(如"%d %s")
* @param ... 可变参数(需传入变量地址,如&int_var、char_var)
* @return 成功读取的"数据项个数";失败/到末尾:返回EOF
* @note 读取时会跳过空白字符(空格、换行、制表符);
读取字符串时遇空白字符停止
*/
int fscanf(FILE *stream, const char *format, ...);sprintf与snprintf(格式化写入缓冲区)
sprintf:将格式化数据写入字符串缓冲区(无大小限制,可能溢出)。snprintf:指定缓冲区大小,避免溢出(推荐使用)。
c
#include <stdio.h>
/**
* 将格式化数据写入字符串缓冲区(不安全,可能溢出)
* @param s 目标缓冲区(存储格式化后的字符串)
* @param format 格式控制字符串
* @param ... 可变参数
* @return 成功:返回写入的字符数(不含'\0');失败:返回负数
*/
int sprintf(char *s, const char *format, ...);
/**
* 将格式化数据写入字符串缓冲区(安全,指定最大写入字节数)
* @param s 目标缓冲区
* @param n 缓冲区大小(最大写入n-1个字符,最后加'\0')
* @param format 格式控制字符串
* @param ... 可变参数
* @return 成功:返回应写入的字符数(若n足够);失败:返回负数
* @note 若应写入的字符数≥n,仅写入n-1个字符,保证缓冲区安全
*/
int snprintf(char *s, size_t n, const char *format, ...);缓冲区机制(关键)
缓冲区的作用
IO 设备(如硬盘、键盘)速度远慢于 CPU,缓冲区暂存数据,减少 CPU 等待 IO 的时间(比如写文件时,先存缓冲区,满了再一次性写硬盘)。
三种缓冲区类型
| 缓冲类型 | 适用场景(含典型对象) | 刷新时机(数据写入设备的触发条件) |
|---|---|---|
| 全缓冲 | 普通文件(如文本文件 demo.txt、二进制文件 data.bin),非实时交互类数据存储场景 |
- 缓冲区被数据填满(默认大小通常为 4KB/4096 字节); - 调用 fflush 函数手动强制刷新; - 关闭文件流(fclose),关闭前自动刷新未写入数据; - 程序正常结束(如 return 0); - 对同一文件流调用读操作(如 fread)或修改缓冲区类型 |
| 行缓冲 | 标准输出流(stdout,如 printf 终端输出),需按行实时反馈的交互场景(如终端打印日志) |
- 缓冲区中检测到换行符 \n (核心触发条件,无 \n 则暂存); - 缓冲区被数据填满(默认 4KB); - 调用 fflush 函数手动强制刷新; - 关闭流(fclose)或程序正常结束; - 对关联流调用读操作(如对 stdin 用 fgetc 读键盘输入,会触发 stdout 刷新) |
| 无缓冲 | 标准错误流(stderr,如 perror 错误提示),需即时输出紧急信息的场景(如程序报错) |
数据生成后直接写入设备 ,无需暂存到缓冲区;触发写操作(如 perror("error"))后立即输出,无延迟 |
标准 IO 缓冲区设置函数详解
以下函数均用于自定义标准 IO 流的缓冲区(类型、大小、存储地址),需在流打开后、首次读写操作前调用,否则可能导致缓冲区状态混乱或设置失效,相关功能在 C 标准及文档中均有约束。
int setvbuf(FILE *stream, char *buf, int mode, size_t size);
功能
最灵活的缓冲区设置函数,支持自定义缓冲区地址、类型(全缓冲 / 行缓冲 / 无缓冲)和大小,是后三个函数的 "底层实现依赖"()。
参数解析与返回值
c
#include <stdio.h>
/**
* @param stream 目标文件流(需已打开且未读写)
* @param buf 缓冲区地址:
* - 非NULL:使用用户提供的缓冲区(大小≥size)
* - NULL:使用系统自动分配的缓冲区(大小由size指定)
* @param mode 缓冲模式(必须是以下三者之一):
* - _IONBF:无缓冲(数据直接输出,类似stderr,)
* - _IOLBF:行缓冲(遇'\n'或缓冲区满刷新,类似stdout,)
* - _IOFBF:全缓冲(缓冲区满或关闭流时刷新,类似普通文件,)
* @param size 缓冲区大小(单位:字节):
* - 若mode为_IONBF:size无意义(可传0)
* - 若mode为_IOLBF/_IOFBF:size需≥1(系统自动分配时,size为最小缓冲大小)
* @return 成功返回0;失败返回非0(如mode无效、流已读写、size过小)
* @note 标准C函数(文档中明确列为文件访问函数,);
* 关闭流时,系统分配的缓冲区会自动释放(用户提供的buf需手动释放);
* 若buf非NULL,其内存需持续有效(全局/静态/堆内存,避免栈内存释放)
*/
int setvbuf(FILE *stream, char *buf, int mode, size_t size);关键特性
- 覆盖所有缓冲需求:例如 "无缓冲 + 用户缓冲区""行缓冲 + 系统分配缓冲区" 等场景;
- 文档中明确其与
setbuf共同管理缓冲区关联关系:关闭流时,通过这两个函数设置的缓冲区会与流解除关联(若为系统分配则释放,若为用户主动分配(如用malloc/calloc分配内存,再通过setbuf/setbuffer/setvbuf绑定到流)时,标准 IO 库仅使用缓冲区,不负责释放,需用户在缓冲区不再使用后手动释放(free))。
void setbuf(FILE *stream, char *buf);
功能
为指定文件流stream设置缓冲区,或禁用缓冲区,是setvbuf的简化版本(默认缓冲区大小通常为 4KB,与文档中行缓冲 / 全缓冲默认大小一致)。
参数解析
c
#include <stdio.h>
/**
* @param stream 目标文件流(如fp、stdout,需已通过fopen打开)
* @param buf 缓冲区地址:
* - 若为非NULL:使用用户提供的缓冲区(建议大小≥4096字节,匹配系统默认缓冲大小)
* - 若为NULL:禁用该流的缓冲区(等效于无缓冲模式,类似stderr默认特性,)
* @return 无返回值
* @note 必须在流首次读写前调用;
用户提供的buf需为全局/静态变量(避免栈内存释放后失效)
*/
void setbuf(FILE *stream, char *buf);关键特性
- 本质是
setvbuf(stream, buf, (buf==NULL)?_IONBF:_IOFBF, BUFSIZ)的封装(BUFSIZ是系统定义的默认缓冲大小,通常为 4096); - 若设置非 NULL 缓冲区,关闭流时该缓冲区会与流解除关联(但不会自动释放,需用户手动管理,)。
void setbuffer(FILE *stream, char *buf, size_t size);
功能
扩展setbuf的功能,允许自定义缓冲区大小(不再固定为 4KB),更灵活适配不同读写场景(如大文件读写需更大缓冲区)。
参数解析
c
#include <stdio.h>
/**
* @param stream 目标文件流(需已打开且未进行读写)
* @param buf 缓冲区地址:
* - 非NULL:使用用户提供的缓冲区(大小由size指定)
* - NULL:禁用缓冲区(无缓冲模式)
* @param size 缓冲区大小(单位:字节):
* - 若buf非NULL,size需≥1(建议为2的幂,如1024、8192,提升IO效率)
* - 若buf为NULL,size无意义(可传0)
* @return 无返回值
* @note 非标准C函数(但POSIX系统普遍支持);
其他约束同setbuf(调用时机、缓冲区内存属性)
*/
void setbuffer(FILE *stream, char *buf, size_t size);关键特性
- 相比
setbuf,核心优势是自定义size,例如处理大文件时可设置 8KB/16KB 缓冲区,减少 IO 次数; - 若
buf非 NULL 但size过小(如 < 100 字节),可能导致频繁缓冲刷新,反而降低效率。
void setlinebuf(FILE *stream);
功能
强制将指定流stream设置为行缓冲模式,等效于 "设置行缓冲 + 默认缓冲区大小",适配需按行刷新的场景(如模拟 stdout 默认行为)。
参数解析
c
#include <stdio.h>
/**
* @param stream 目标文件流(需已打开且未读写)
* @return 无返回值
* @note 本质是`setvbuf(stream, NULL, _IOLBF, BUFSIZ)`的封装;
* 设置后,缓冲区遇'\n'或满时自动刷新(符合行缓冲特性);
* 若流原本为全缓冲/无缓冲,调用后会切换为行缓冲
*/
void setlinebuf(FILE *stream);关键特性
- 典型用途:将普通文件流设为行缓冲(如日志文件,需逐行写入以便实时查看);
- 与 stdout 默认行缓冲的区别:stdout 仅在关联终端时为行缓冲,关联文件时为全缓冲,而
setlinebuf可强制文件流也为行缓冲。
实战案例
案例 1:计算文件大小(命令行传参)
需求:通过命令行传入文件路径,计算并输出文件大小(单位:字节)。
c
#include <stdio.h>
#include <stdlib.h> // 包含exit
int main(int argc, char const *argv[]) {
// 步骤1:判断命令行参数是否正确(需传入1个文件路径,argc应为2)
if (argc != 2) {
printf("用法:%s <文件路径>\n", argv[0]); // 提示正确用法,如"./file_size demo.txt"
exit(1); // 退出程序,1表示错误退出
}
// 步骤2:以二进制只读模式打开文件
FILE *fp = fopen(argv[1], "rb");
if (fp == NULL) {
perror("fopen error");
exit(1);
}
// 步骤3:计算文件大小
fseek(fp, 0, SEEK_END); // 光标移到末尾
long file_size = ftell(fp); // 获取末尾位置(即文件大小)
// 步骤4:输出结果
printf("文件[%s]大小:%ld 字节\n", argv[1], file_size);
// 步骤5:关闭文件
fclose(fp);
return 0;
}编译运行:
bash
gcc file_size.c -o file_size
./file_size demo.txt # 输出:文件[demo.txt]大小:123 字节案例 2:文件拷贝(命令行传参)
需求:通过命令行传入源文件(A)和目标文件(B),将 A 的内容完整拷贝到 B(B 不存在则创建)。
c
#include <stdio.h>
#include <stdlib.h>
#define BUF_SIZE 1024 // 定义1KB缓冲区(平衡效率和内存)
int main(int argc, char const *argv[]) {
// 步骤1:判断参数(需传入源文件和目标文件,argc=3)
if (argc != 3) {
printf("用法:%s <源文件> <目标文件>\n", argv[0]); // 如"./copy demo.txt demo_copy.txt"
exit(1);
}
// 步骤2:打开源文件(只读)和目标文件(只写,不存在则创建)
FILE *src_fp = fopen(argv[1], "rb"); // 源文件:二进制只读
FILE *dest_fp = fopen(argv[2], "wb"); // 目标文件:二进制只写
if (src_fp == NULL || dest_fp == NULL) {
perror("fopen error");
// 若已打开一个流,需关闭
if (src_fp != NULL) fclose(src_fp);
if (dest_fp != NULL) fclose(dest_fp);
exit(1);
}
// 步骤3:循环读取源文件,写入目标文件
char buf[BUF_SIZE];
size_t read_cnt; // 每次读取的字节数
while ((read_cnt = fread(buf, 1, BUF_SIZE, src_fp)) > 0) {
// 读取多少,写入多少
fwrite(buf, 1, read_cnt, dest_fp);
}
// 步骤4:判断拷贝是否成功
if (ferror(src_fp)) {
perror("读取源文件错误");
}
else if (ferror(dest_fp)) {
perror("写入目标文件错误");
}
else {
printf("拷贝成功:%s → %s\n", argv[1], argv[2]);
}
// 步骤5:关闭文件
fclose(src_fp);
fclose(dest_fp);
return 0;
}案例 3:定时写入系统时间到日志
需求:每隔 1 秒获取当前系统时间,按 "yy 年 mm 月 dd 日 星期 x hh:mm:ss" 格式写入 log.txt(不存在则创建),无限循环。
c
#include <stdio.h>
#include <time.h> // 包含时间相关函数
#include <unistd.h> // 包含sleep函数(Linux下)
// 星期转换:tm_wday是0(周日)~6(周六),转换为中文
const char *get_weekday(int tm_wday) {
const char *week[] = {"日", "一", "二", "三", "四", "五", "六"};
return week[tm_wday];
}
int main() {
// 以追加模式打开log.txt(不存在则创建,存在则追加)
FILE *fp = fopen("log.txt", "a");
if (fp == NULL) {
perror("fopen error");
return -1;
}
while (1) { // 无限循环
// 步骤1:获取当前系统时间(秒数,从1970-01-01 00:00:00 UTC开始)
time_t now = time(NULL);
if (now == (time_t)-1) {
perror("time error");
fclose(fp);
return -1;
}
// 步骤2:将秒数转换为本地时间(年、月、日等)
struct tm *local_tm = localtime(&now);
if (local_tm == NULL) {
perror("localtime error");
fclose(fp);
return -1;
}
// 步骤3:按指定格式写入log.txt
// 格式:yy年mm月dd日 星期x hh:mm:ss(注意:tm_year是年份-1900,tm_mon是0~11)
fprintf(fp, "%02d年%02d月%02d日 星期%s %02d:%02d:%02d\n",
local_tm->tm_year % 100, // yy(取年份后两位)
local_tm->tm_mon + 1, // mm(加1,因为tm_mon是0~11)
local_tm->tm_mday, // dd
get_weekday(local_tm->tm_wday), // 星期x
local_tm->tm_hour, // hh
local_tm->tm_min, // mm
local_tm->tm_sec); // ss
// 步骤4:手动刷新缓冲区(避免日志延迟写入)
fflush(fp);
// 步骤5:等待1秒
sleep(1);
}
// 注:循环不会退出,实际使用中需按Ctrl+C终止,终止后会自动关闭流
fclose(fp);
return 0;
}注意事项
- 避免重复关闭文件 :
fclose多次调用同一流会导致 double free 错误,建议关闭后将指针置为NULL(如fclose(fp); fp=NULL;)。 - 二进制与文本模式区分 :读写图片、音频等二进制文件必须用
"rb"/"wb",避免系统转换字符导致文件损坏。 - 缓冲区刷新 :用 "追加模式" 写日志时,需手动调用
fflush,否则日志会暂存缓冲区,不及时写入文件。 - 命令行参数判断 :接收命令行参数(如
argv[1])时,必须先判断argc是否正确,避免访问空指针。 - 内存释放 :用
malloc分配的缓冲区(如fread的缓冲区),必须用free释放,避免内存泄漏。