Makefile深度解析:从依赖推导到有效编译

🎬 Doro在努力 :个人主页
🔥 个人专栏 : 《MySQL数据库基础语法》《数据结构》
⛺️严于律己,宽以待人
文章目录
- Makefile深度解析:从依赖推导到有效编译
-
- 一、为什么需要Makefile?
- 二、依赖关系与依赖方法------Makefile的核心逻辑
-
- [2.1 从生活例子理解依赖](#2.1 从生活例子理解依赖)
- [2.2 Makefile的基本结构](#2.2 Makefile的基本结构)
- [2.3 语法细节与注意事项](#2.3 语法细节与注意事项)
- 三、Makefile的推导过程------栈结构的奥秘
-
- [3.1 从编译过程说起](#3.1 从编译过程说起)
- [3.2 推导过程的栈机制](#3.2 推导过程的栈机制)
- [3.3 默认目标与显式指定](#3.3 默认目标与显式指定)
- 四、项目清理与伪目标
-
- [4.1 为什么需要clean](#4.1 为什么需要clean)
- [4.2 引入.PHONY伪目标](#4.2 引入.PHONY伪目标)
- [4.3 "总是被执行"的深层含义](#4.3 "总是被执行"的深层含义)
- [4.4 最佳实践](#4.4 最佳实践)
- 五、文件的ACM时间------Makefile判断文件新旧的依据
-
- [5.1 什么是ACM时间](#5.1 什么是ACM时间)
- [5.2 三种时间的区别与联系](#5.2 三种时间的区别与联系)
- [5.3 Makefile如何利用ACM时间](#5.3 Makefile如何利用ACM时间)
- [5.4 用touch命令验证](#5.4 用touch命令验证)
- 六、有效编译------Makefile的效率之道
-
- [6.1 什么是有效编译](#6.1 什么是有效编译)
- [6.2 为什么编译目标不建议用.PHONY](#6.2 为什么编译目标不建议用.PHONY)
- [6.3 大型项目中的编译优化](#6.3 大型项目中的编译优化)
- 七、总结与思考
🎯 导语 :作为一名程序员,你是否曾经疑惑过------为什么第一次
make能编译成功,第二次却提示"已经是最新的"?为什么make clean每次都能执行?今天,我将带你深入Makefile的内部机制,彻底搞懂依赖推导、伪目标、ACM时间这些核心概念。
一、为什么需要Makefile?
在Linux环境下进行C/C++开发,我们最早接触的编译方式可能是这样的:
bash
gcc -o myprogram main.c utils.c helper.c -I./include -L./lib -lmylib这种手敲GCC命令的方式,对于单个文件或者简单项目或许还能应付。但是,当你的项目逐渐庞大,源文件达到几十个甚至上百个,每次修改后都要手动输入一长串编译命令,不仅效率低下,而且极易出错。更重要的是,如果某个源文件没有被修改,我们是否真的需要重新编译它?
Makefile正是为了解决这些问题而生的。
Makefile本质上是一个文本文件,它定义了一系列规则来告诉make命令如何构建我们的项目。而make则是一个解释并执行这些规则的工具。两者配合,可以实现项目的自动化编译,大大提高开发效率。
二、依赖关系与依赖方法------Makefile的核心逻辑
2.1 从生活例子理解依赖
在深入Makefile的语法之前,我想先用一个生活中的例子来帮助大家理解"依赖"这个概念。
想象一下,作为一名学生,你在上学期间依赖 你的父亲提供经济支持。这种依赖关系是客观存在的------你需要父亲的支持才能完成学业。但是,仅有依赖关系是不够的,还需要具体的依赖方法------也就是月底父亲给你打钱这个动作。如果父亲只是口头上说"我支持你",但实际上从不打钱,那么你的学业依然无法继续。
Makefile中的规则也是如此。
2.2 Makefile的基本结构
一个最基本的Makefile规则由两部分组成:
makefile
target: dependencies
[TAB]command- target(目标文件):冒号左侧,表示我们想要生成的文件
- dependencies(依赖文件列表):冒号右侧,表示生成target所需要的文件
- command(依赖方法):以Tab键开头的命令,表示如何由dependencies生成target
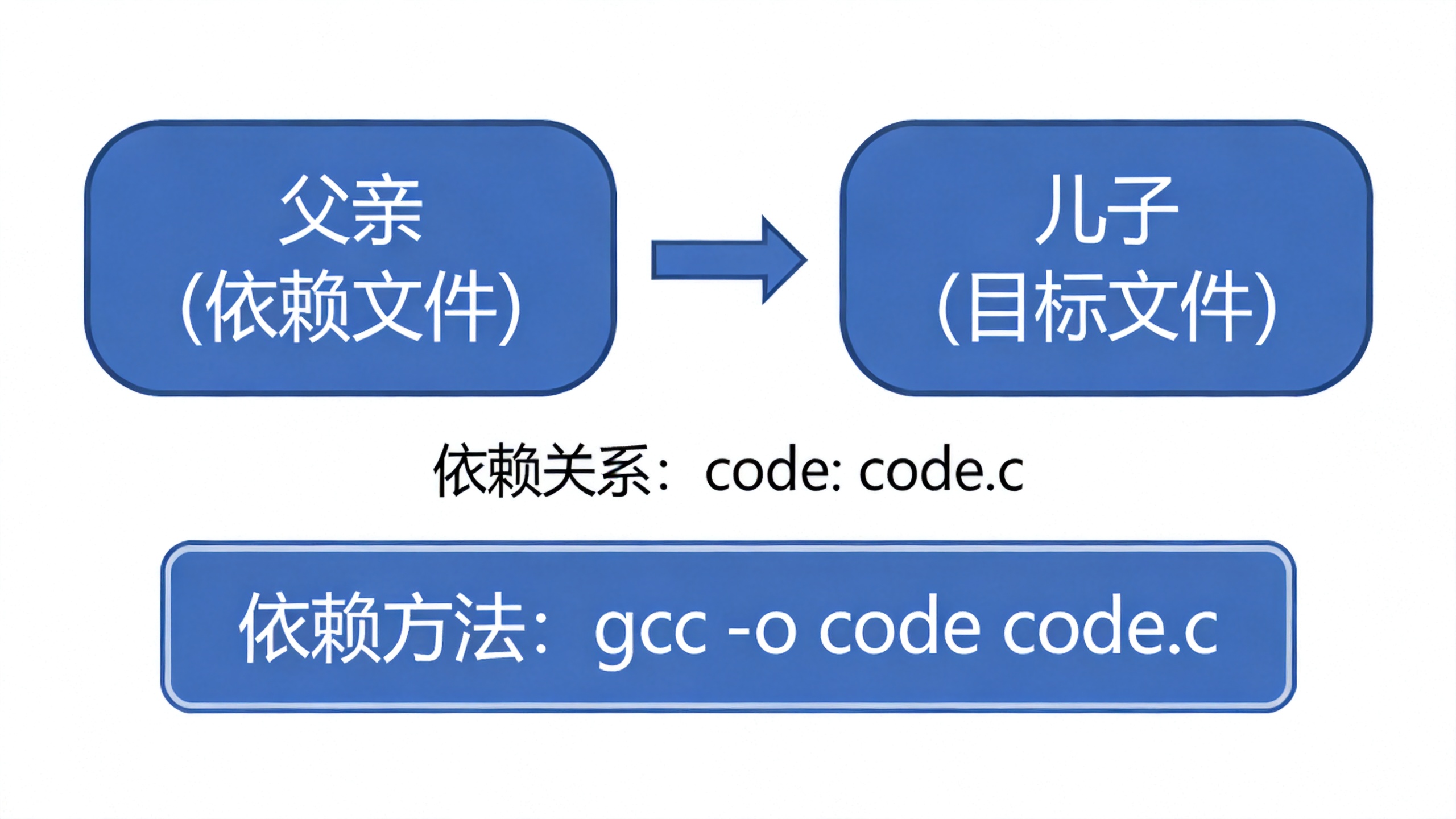
让我们看一个最简单的例子:
makefile
code: code.c
gcc -o code code.c这里,code是目标文件,code.c是依赖文件,gcc -o code code.c是依赖方法。这条规则的含义是:要生成code,需要依赖code.c,通过执行gcc命令来完成编译。
2.3 语法细节与注意事项
在编写Makefile时,有几个重要的语法细节需要特别注意:
第一,依赖方法必须以Tab键开头,不能是四个空格。 这是Makefile的硬性要求,如果用空格代替Tab,make会报错。这一点初学者非常容易踩坑,需要格外留意。
第二,Makefile中的注释使用#符号。 与C语言的//或/* */不同,Makefile使用井号来标识注释内容。
第三,一个目标可以有多个依赖方法。 这意味着你可以在一个规则中执行多条命令,每条命令占一行,且都必须以Tab开头。
三、Makefile的推导过程------栈结构的奥秘
3.1 从编译过程说起
在讲解Makefile的推导过程之前,我们需要回顾一下C程序的编译流程。一个C源文件要变成可执行程序,需要经历四个阶段:
- 预处理(Preprocessing) :处理宏定义、头文件展开、条件编译等,生成
.i文件 - 编译(Compilation) :将预处理后的代码翻译成汇编语言,生成
.s文件 - 汇编(Assembly) :将汇编代码转换成机器码,生成
.o目标文件 - 链接(Linking):将多个目标文件和库文件链接成最终的可执行程序
在Makefile中,我们可以显式地定义这四个阶段的依赖关系:
makefile
code: code.o
gcc code.o -o code
code.o: code.s
gcc -c code.s -o code.o
code.s: code.i
gcc -S code.i -o code.s
code.i: code.c
gcc -E code.c -o code.i3.2 推导过程的栈机制
现在,让我们深入探讨Makefile是如何处理这种多级依赖的。当你在当前目录下执行make命令时,背后发生了一系列复杂而精妙的操作。
首先 ,make命令会在当前目录下查找名为Makefile或makefile的文件。如果找到,它会自顶向下开始解析文件内容。
其次 ,make会寻找第一个目标文件。在上面的例子中,第一个目标是code。make发现code依赖于code.o,但当前目录下并不存在code.o文件,因此无法直接执行gcc code.o -o code这条命令。
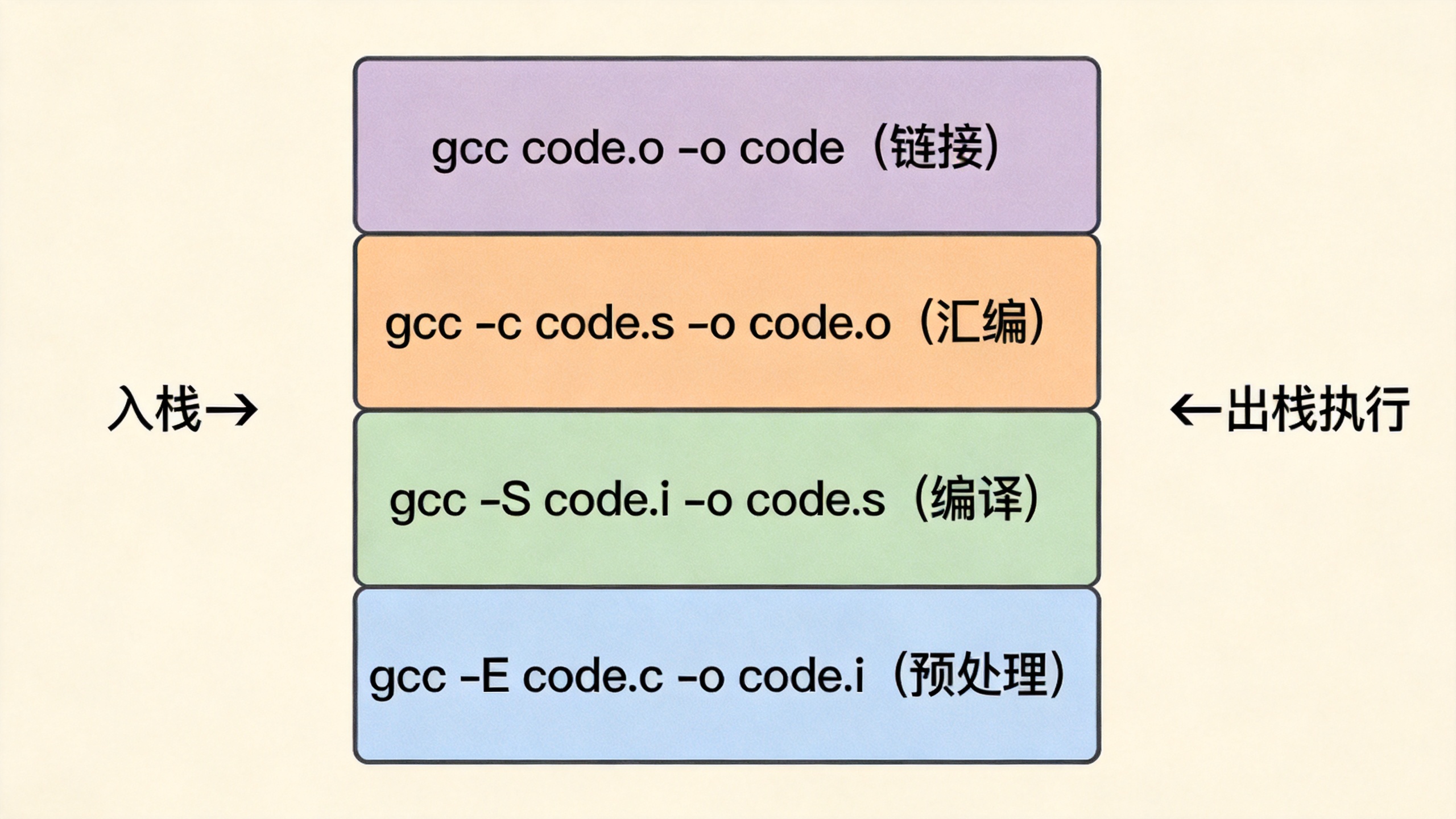
关键来了 ------此时make并不会直接报错退出,而是采用了一种类似于栈的数据结构来维护当前的依赖关系。
让我详细描述这个过程:
make发现需要生成code,但依赖的code.o不存在,于是将gcc code.o -o code这条命令入栈make继续查找如何生成code.o,发现它依赖于code.s,但code.s也不存在,于是将gcc -c code.s -o code.o入栈make继续查找如何生成code.s,发现它依赖于code.i,但code.i也不存在,于是将gcc -S code.i -o code.s入栈make继续查找如何生成code.i,发现它依赖于code.c,而code.c确实存在!
当make找到最终存在的源文件code.c时,推导过程到达"出口"。此时,栈中已经按顺序存放了四条命令(从底到顶):
[栈底] gcc code.o -o code
gcc -c code.s -o code.o
gcc -S code.i -o code.s
[栈顶] gcc -E code.c -o code.i最后 ,make开始弹栈执行------从栈顶开始依次执行每条命令:
- 执行
gcc -E code.c -o code.i,生成code.i - 执行
gcc -S code.i -o code.s,生成code.s - 执行
gcc -c code.s -o code.o,生成code.o - 执行
gcc code.o -o code,生成最终的可执行程序code
这种栈结构的推导机制,使得Makefile能够自动处理任意层级的依赖关系。无论你的项目依赖关系多么复杂,只要正确定义了规则,make都能帮你自动推导并执行正确的编译顺序。
3.3 默认目标与显式指定
Makefile有一个重要的默认行为:它只会推导并生成第一个遇到的目标文件。
这意味着,如果你把clean目标写在最前面:
makefile
clean:
rm -f code code.o
code: code.c
gcc -o code code.c那么直接执行make时,它会默认执行clean,而不是编译code。这也是为什么我们通常把主要的编译目标放在文件最前面,而清理目标放在后面。
如果你想显式指定要生成的目标,可以在make命令后加上目标名:
bash
make clean # 执行clean目标
make code # 执行code目标四、项目清理与伪目标
4.1 为什么需要clean
在实际开发中,我们经常需要清理编译生成的临时文件。可能的原因包括:
- 解决奇怪的编译问题:有时候修改了代码但编译器似乎没有识别到,清理后重新编译可以解决问题
- 保持工作目录整洁 :编译生成的
.o、.i、.s等中间文件会占用空间 - 重新构建:在某些情况下,我们需要确保所有文件都是重新编译的
在Makefile中,我们通常这样定义清理规则:
makefile
clean:
rm -f code code.i code.s code.o4.2 引入.PHONY伪目标
现在有一个问题:如果当前目录下恰好有一个名为clean的文件,会发生什么?
bash
touch clean # 创建一个名为clean的空文件
make clean # 尝试执行清理你会发现,make会提示"clean is up to date",而不会执行rm命令。这是因为make发现当前目录下已经存在clean文件,且它的依赖列表为空(没有依赖文件需要检查),所以认为clean已经是最新的,不需要执行任何操作。
这显然不是我们希望的行为。清理操作应该每次都能执行,不受文件存在与否的影响。
这就是.PHONY伪目标的用武之地。.PHONY是Makefile中的一个关键字,用于修饰目标文件,表示该目标是一个"伪目标"。被.PHONY修饰的目标,其依赖方法总是被执行,不会进行文件新旧检查。
makefile
.PHONY: clean
clean:
rm -f code code.i code.s code.o现在,无论当前目录下是否存在clean文件,执行make clean都会正常执行清理操作。

4.3 "总是被执行"的深层含义
让我们更深入地理解"总是被执行"这个概念。为了对比,我们来看两个实验:
实验一:普通目标
makefile
code: code.c
gcc -o code code.c执行结果:
bash
$ make
gcc -o code code.c
$ make
make: 'code' is up to date.
$ make
make: 'code' is up to date.第一次编译成功,第二次、第三次都被拒绝了。
实验二:伪目标
makefile
.PHONY: code
code: code.c
gcc -o code code.c执行结果:
bash
$ make
gcc -o code code.c
$ make
gcc -o code code.c
$ make
gcc -o code code.c每次都能编译!
通过这个对比,我们可以清楚地看到.PHONY的作用:它让make忽略文件新旧检查,直接执行依赖方法。
4.4 最佳实践
在实际项目中,我们有以下最佳实践建议:
- 清理目标
clean应该使用.PHONY修饰 :因为清理操作需要确定性,每次调用make clean都应该执行 - 编译目标(如
code)不建议使用.PHONY修饰:这样可以利用Makefile的"有效编译"机制,只编译修改过的文件,提高编译效率
五、文件的ACM时间------Makefile判断文件新旧的依据
5.1 什么是ACM时间
现在我们来解决一个核心问题:Makefile是如何判断一个文件是否需要重新编译的?
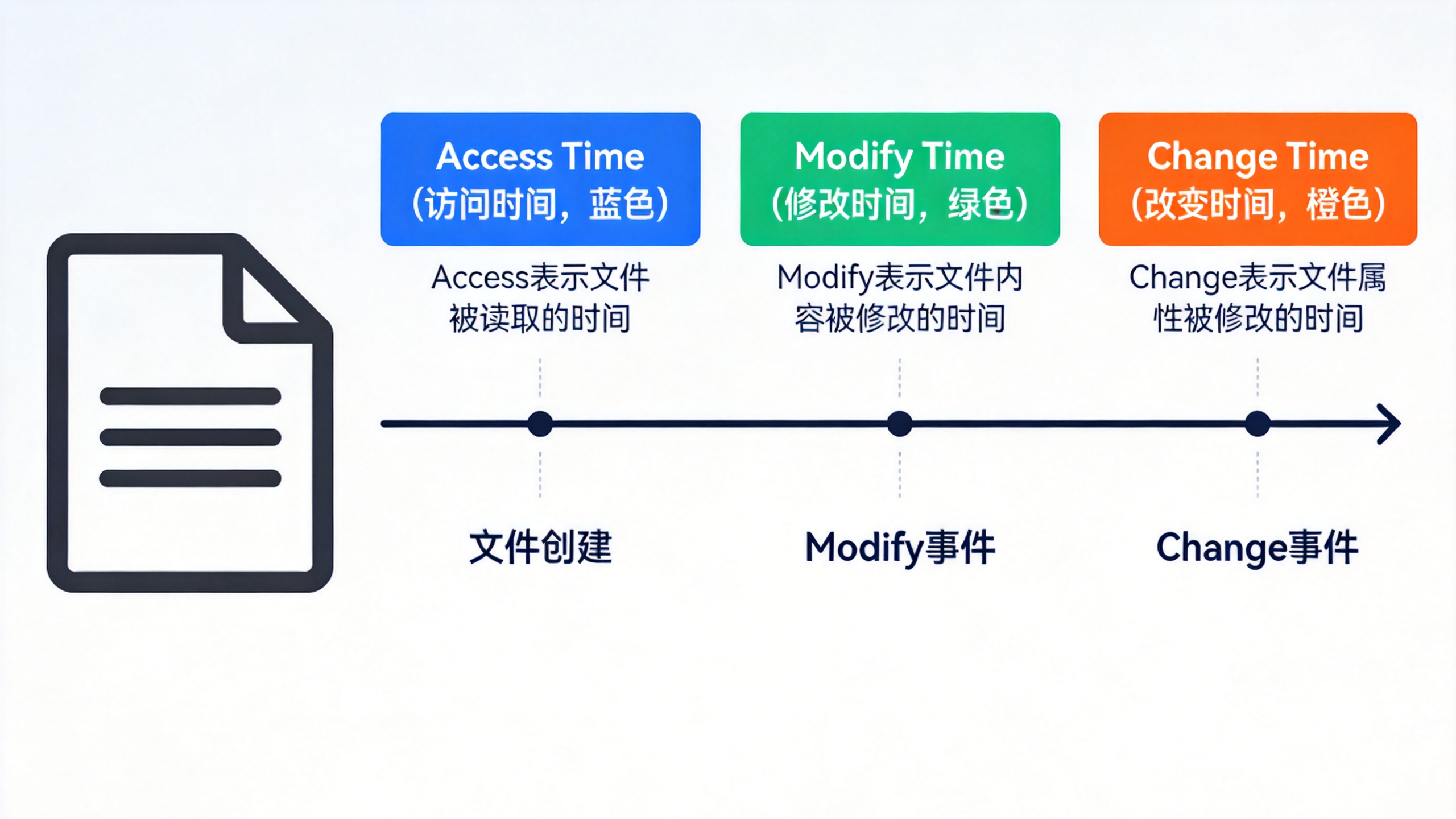
答案隐藏在Linux文件的ACM时间中。每个文件在系统中都维护着三个时间戳:
- Access Time(访问时间):文件最近一次被读取的时间
- Modify Time(修改时间):文件内容最近一次被修改的时间
- Change Time(改变时间):文件属性最近一次被改变的时间
5.2 三种时间的区别与联系
Modify Time 记录的是文件内容的变更。当你修改了文件的内容,比如添加、删除或修改了几行代码,这个文件的内容发生了变化,其Modify Time就会被更新为当前时间。
Change Time 记录的是文件属性 的变更。文件的属性包括权限(rwx)、所有者、所属组、文件大小等。当你使用chmod命令修改文件权限时,文件的内容并没有变化,但其Change Time会被更新。
bash
# 查看文件的ACM时间
stat code.c
# 输出示例:
# File: code.c
# Access: 2024-10-25 17:05:30
# Modify: 2024-10-25 17:05:25
# Change: 2024-10-25 17:05:25有趣的是,Modify Time的更新会伴随Change Time的更新。这是因为文件内容的改变通常会导致文件大小等属性的变化,所以Change Time也会随之更新。但反过来不成立------单纯修改属性(如权限)只会更新Change Time,不会影响Modify Time。
Access Time 记录的是文件被访问(读取)的时间。但是,由于读取文件是一个非常高频的操作,如果每次读取都更新Access Time,会导致大量的磁盘I/O操作,影响系统性能。因此,Linux对Access Time的更新做了优化------它不会每次访问都更新,而是按照一定的策略(如访问次数达到一定阈值)才进行更新。
5.3 Makefile如何利用ACM时间
Makefile判断是否需要重新编译的核心逻辑是:比较源文件和目标文件的Modify Time。
让我们用时间轴来理解这个过程:
初始状态 :只有code.c文件,没有code可执行程序
时间线 ──────────────────────────────────────────>
[code.c创建]第一次make :code.c存在,code不存在,执行编译
时间线 ──────────────────────────────────────────>
[code.c创建] [code生成]此时,code的Modify Time一定晚于code.c的Modify Time。
第二次make :比较code.c和code的Modify Time
code.c的Modify Time:较早(创建时)code的Modify Time:较晚(刚生成)
因为code比code.c"新",所以不需要重新编译。
修改code.c后make:
时间线 ──────────────────────────────────────────>
[code.c创建] [code生成] [code.c修改]此时,code.c的Modify Time被更新为当前时间,比code的Modify Time更"新"。因此,make会重新执行编译。
5.4 用touch命令验证
touch命令不仅可以创建空文件,还有一个重要功能:更新文件的ACM时间为当前系统时间。
我们可以利用这个特性来验证Makefile的时间判断机制:
bash
# 正常编译
make
# 此时再make会被拒绝
make # 输出: 'code' is up to date
# 用touch更新code.c的时间
touch code.c
# 现在make会重新编译
make # 执行gcc -o code code.c同样,我们也可以touch可执行文件,让它比源文件"新",从而阻止重新编译:
bash
# 修改code.c
vim code.c
# 此时make应该重新编译
make # 会编译
# 修改后立即touch code
# 让code的时间比code.c更新
touch code
# 再次make会被拒绝
make # 输出: 'code' is up to date六、有效编译------Makefile的效率之道
6.1 什么是有效编译
通过上面的分析,我们现在可以理解Makefile的"有效编译"机制了:Makefile只会重新编译那些源文件比目标文件"新"的目标,没有被修改的文件不会被重复编译。
这种机制在大型项目中尤为重要。想象一下,如果你的项目有1000个源文件,每次编译都要把所有文件重新预处理、编译、汇编、链接,那将是多么耗时!而实际情况是,你可能只修改了其中的一两个文件,有效编译机制确保只有这一两个文件会被重新编译,然后重新链接即可。
6.2 为什么编译目标不建议用.PHONY
现在我们可以回答之前提出的问题了:为什么编译目标(如code)不建议使用.PHONY修饰?
因为.PHONY会让make忽略文件新旧检查,每次执行make都会强制重新编译。这意味着:
- 失去有效编译的优化
- 每次都要重新编译所有文件
- 大型项目的编译时间将大幅增加
而清理目标clean之所以要用.PHONY,是因为清理操作本身就是需要确定性的------每次调用make clean,我们都希望它能执行清理,而不是因为某个名为clean的文件存在就跳过。
6.3 大型项目中的编译优化
在大型项目中,Makefile的有效编译机制可以带来显著的性能提升。假设一个项目有100个源文件:
全量编译:
- 100个文件 × 预处理 + 编译 + 汇编 = 大量时间
- 链接100个目标文件 = 更多时间
有效编译(修改了2个文件):
- 2个文件 × 预处理 + 编译 + 汇编 = 很少时间
- 链接100个目标文件(98个旧的 + 2个新的)= 相对较快
这就是Makefile在工程实践中的价值所在。
七、总结与思考
通过本文的深入探讨,我们系统地学习了Makefile的核心机制:
核心概念回顾
- 依赖关系与依赖方法:Makefile规则的两要素,缺一不可
- 推导过程的栈结构 :
make利用栈来处理多级依赖,先入栈后出栈执行 - 伪目标
.PHONY:让目标总是被执行,适用于清理等需要确定性的操作 - 文件的ACM时间 :
make通过比较Modify Time来判断文件是否需要重新编译 - 有效编译:只编译修改过的文件,大幅提高大型项目的编译效率
实践建议
- 编写Makefile时,注意依赖方法必须以Tab键开头
- 清理目标
clean务必使用.PHONY修饰 - 编译目标不要滥用
.PHONY,保留有效编译的优化 - 理解ACM时间,有助于排查编译相关的奇怪问题
进一步思考
Makefile的设计体现了Unix哲学中的"做一件事,并做好"。它看似简单,却蕴含着深刻的工程智慧。理解Makefile的内部机制,不仅能帮助我们更好地使用这个工具,更能让我们体会到软件工程中"自动化"和"效率"的重要性。