使用 Vela 编译器开发 Ethos-U NPU 流程导引
文章目录
- [使用 Vela 编译器开发 Ethos-U NPU 流程导引](#使用 Vela 编译器开发 Ethos-U NPU 流程导引)
-
- [Vela 编译器简介](#Vela 编译器简介)
- [部署 ML 模型的工作流程](#部署 ML 模型的工作流程)
- [在嵌入式源码工程中使用 TFLM CMSIS-Packs](#在嵌入式源码工程中使用 TFLM CMSIS-Packs)
-
- [在 Keil 工程中添加 TFLM 软件组件](#在 Keil 工程中添加 TFLM 软件组件)
- [向嵌入式系统的源码工程中添加 ML 模型](#向嵌入式系统的源码工程中添加 ML 模型)
-
- [将 ML 模型存放在文件系统中](#将 ML 模型存放在文件系统中)
- [将模型编译到固件同应用程序一道下载至 flash 中](#将模型编译到固件同应用程序一道下载至 flash 中)
- [在嵌入式工程中调用 TFLM 的 API 运行 ML 模型](#在嵌入式工程中调用 TFLM 的 API 运行 ML 模型)
- 参考文献
Vela 编译器简介
Ethos-U Vela 是 Arm开发的一款软件工具,可将 TensorFlow Lite(TensorFlow Lite for Microcontroller 是 TensorFlow LIte的一个子集)模型编译为可在 Ethos-U NPU上运行的优化版本。Vela 以 TensorFlow Lite模型为输入,应用包括内存优化和层融合技术在内的优化手段,编译生成专门针对 Ethos-U 架构优化的二进制文件。这一优化的二进制文件最大限度地利用了 Ethos-U NPU 的硬件特性,以高效执行机器学习工作负载。
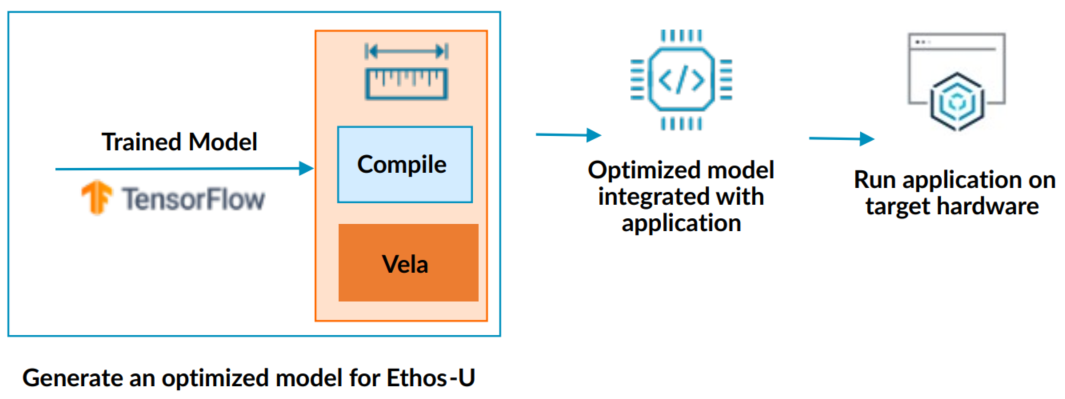
图x 使用 Vela 编译器编译 ML 模型
优化后的模型包含 TensorFlow Lite 专门设计的算子,可通过 Ethos-U NPU加速。模型中无法加速的部分保持不变,而是使用适当的内核在主机处理器(如 Cortex‑M 系列 CPU)上运行。
Ethos-U Vela 将会尝试多种不同的编译策略,并对每种策略应用了成本函数。然后,Vela 为每个受支持的 操作符 或 操作符组 选择最优的执行调用。Vela 与 TensorFlow Lite (量化)位精度一致,因此,使用 Vela 编译器优化神经网络时,不会损失精度。
Vela 编译器可以报告预估性能,但仅是近似估计。软件开发人员应考虑将机器学习推理顾问(Machine Learning Inference Advisor,另一个 ML 开发工具)与经过验证的高性能模型结合使用,以获得更准确的性能数据。
Vela 编译器执行各种内存优化,以减少固定存储(Flash)和运行时(SRAM)的内存需求。这些优化包括以下内容:
- 压缩模型中的所有权重,可以减少固定存储内存的使用。
- 通过将一组连续的算子的特征图(FM, Feature Map)拆分为多个分块(Stripe),从而减少运行时的内存使用。一个分块可以是特征图的全宽或部分宽度,也可以是特征图的全高或部分高度。然后,每次载入一个分块依次加载所有算子,以避免一次性载入巨大的计算量以及对应的内存使用需求。
模型中可优化和加速的部分被专门识别出来,并转换为 TensorFlow Lite 组件中的特定算子。这些算子随后被编译成命令流,由 Ethos-U NPU 执行。
最后,Vela 将优化后的模型输出为 TFLM 模型(仍然是 *.tflite文件),并生成性能评估报告。该报告提供了内存使用和推理时间等统计数据。
Vela 编译器提供了可配置的选项,使开发者能够指定嵌入式系统配置的各个方面,例如:Ethos-U NPU 的版本型号、内存类型和内存大小。此外,还有配置选项用于控制在编译过程中执行的优化类型。
至 于Vela 本身,是一个Python环境的库,除了必要的基础软件外(C语言运行时环境和Python运行时环境),可以通过Python安装组件库的方式,安装 Vela 工具:
python
pip3 install ethos-u-vela在Python的命令行环境中使用 Vela:
- 输入文件是
*.tflite,其中包含了将要编译的神经网络信息。 - 输出文件是
*_vela.tflite文件,仍是一个*.tflite文件,但是文件名中加了个_vela的后缀。以及一个*.csv文件,其中描述了预估模型性能的信息。 - 预估模型性能的摘要报告也会通过命令行终端输出。
python
$ vela my_network.tflite
Network summary for my_network
Accelerator configuration Ethos_U55_256
System configuration internal-default
Memory mode internal-default
Accelerator clock 500 MHz
Design peak SRAM bandwidth 4.00 GB/s
Design peak Off-chip Flash bandwidth 0.50 GB/s
Total SRAM used 0.95 KiB
Total Off-chip Flash used 106.98 KiB
CPU operators = 0 (0.0%)
NPU operators = 44 (100.0%)
Average SRAM bandwidth 0.04 GB/s
Input SRAM bandwidth 0.01 MB/batch
Weight SRAM bandwidth 0.00 MB/batch
Output SRAM bandwidth 0.00 MB/batch
Total SRAM bandwidth 0.01 MB/batch
Total SRAM bandwidth per input 0.01 MB/inference (batch size 1)
Average Off-chip Flash bandwidth 0.46 GB/s
Input Off-chip Flash bandwidth 0.01 MB/batch
Weight Off-chip Flash bandwidth 0.09 MB/batch
Output Off-chip Flash bandwidth 0.00 MB/batch
Total Off-chip Flash bandwidth 0.10 MB/batch
Total Off-chip Flash bandwidth per input 0.10 MB/inference (batch size 1)
Neural network macs 86952 MACs/batch此处特别注意,报告中的周期和带宽数字并不是实际性能数据的准确表示,也不应与使用不同设置或配置的其他编译结果进行比较。实际上,报告的数据仅供编译器做出优化决策,仅仅为 Vela 自己做参考。若要获得准确的性能数据,仍要在具体的硬件平台上运行网络并进行性能分析。
但此处如果用执行的周期数来表达计算量,可能会更加直观,此时可使用命令行参数--verbose-cycle-estimate获取额外的摘要信息:
python
Info: The numbers below are internal compiler estimates.
For performance numbers the compiled network should be run on an FVP Model or FPGA.
Network Tops/s 0.00 Tops/s
NPU cycles 21298 cycles/batch
SRAM Access cycles 2261 cycles/batch
DRAM Access cycles 0 cycles/batch
On-chip Flash Access cycles 0 cycles/batch
Off-chip Flash Access cycles 112755 cycles/batch
Total cycles 114098 cycles/batch
Batch Inference time 0.23 ms, 4382.18 inferences/s (batch size 1)其中,Total cycles 是每次通过中消耗周期最多的单个动作的总和,即,如果内存访问在每次通过中消耗的周期最多,那么这部分将计入总计中的通过周期数。需要澄清的是:对于每种类型的周期计数,每批的周期数是每层周期计数之和,其中每层的周期计数基于最大处理路径。
如果需要查看权重数据占空的内存空间大小,也可使用命令行参数--verbose-weights获取额外的摘要信息:
python
Original Weights Size 84.91 KiB
NPU Encoded Weights Size 89.30 KiB部署 ML 模型的工作流程
Ethos-U Vela 编译器以 ML 模型文件作为输入,将产生一个经过优化的二进制文件,可供Ethos-U NPU运行。下图x中,展示了使用 Ethos-U 运行 ML 模型的软件开发流程,相较于仅使用 Cortex-M 处理器的系统,在集成了 Ethos-U NPU 的情况下,开发流程的变化并不大。
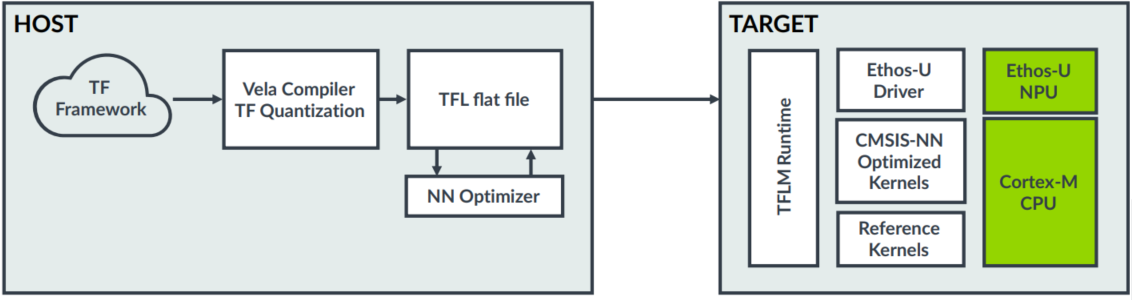
图x 使用 Ethos-U NPU 开发软件的过程
在 PC 主机上使用 TensorFlow Lite 和 Vela 编译器的开发工作:
- 预先准备好使用在 TensorFlow 机器学习框架下训练好的模型。这个模型可以是使用通用 TensorFlow 创建的模型,当然更建议使用 TensorFlow Lite 创建。
- Vela 编译的过程中,使用机器学习模型调节技术,如协同聚类、剪枝和量化感知训练(QAT, Quantization Aware Training),在保持准确性的前提下,以提高 Ethos-U 上运行模型的性能。
- Vela 编译器产生的
*.tflite文件(TFL flatbuffer文件)相对于作为输入的通用*.tflite文件,其中的内容,已被转换成可以被 Ethos-U NPU 执行的二进制程序文件。 - Vela 编译器中的神经网络优化器(NN Optimizer)将会识别出要在 Ethos-U 上运行的图,并对这些图进行优化、调度和分配。
- Vela 编译器产生的
*.tflite文件将被无损地压缩,以减小文件的尺寸。
在嵌入式端(目标设备)的开发工作:
- 将Vela 编译器产生的
*.tflite文件部署至 TFLM(TensorFlow Lite for Microcontroller)的运行时环境中。嵌入式源码工程中已经部署了 TFLM 的运行时环境源码,其中包含了 Ethos-U 的驱动程序(使用 NPU 硬件计算)和 CMSIS-NN 的库(使用 Cortex-M CPU计算)。 - Ethos-U 驱动程序将承担起执行部分 Ethos-U NPU 能够执行的运行过程(计算单元、算子等)。
- CMSIS-NN 库将承担起其余的计算过程。基于 CMSIS-M 处理器使用软件实现计算过程,总是能够完成计算任务的。
在嵌入式源码工程中使用 TFLM CMSIS-Packs
本节中,将说明如何将 TFLM 运行时、Ethos-U driver 和Vela编译器产生的 *.tflite 文件(ML模型)集成到使用 Keil MDK 的嵌入式源码工程中。其中,主要包括几个环节:
- 在 Keil 工程中添加 TFLM 软件组件。
- 将 ML 模型(可以来自于 Arm 的 ML zoo 仓库,也可以自行创建)导入到源码工程中。
- 在源码工程中调用 TFLM 的 API 运行模型。
在 Keil 工程中添加 TFLM 软件组件
Keil 环境中的 TFLM 软件组件可以在 CMSIS-Pack(Arm Keil | CMSIS Packs)的网站上下载到,如图x所示。
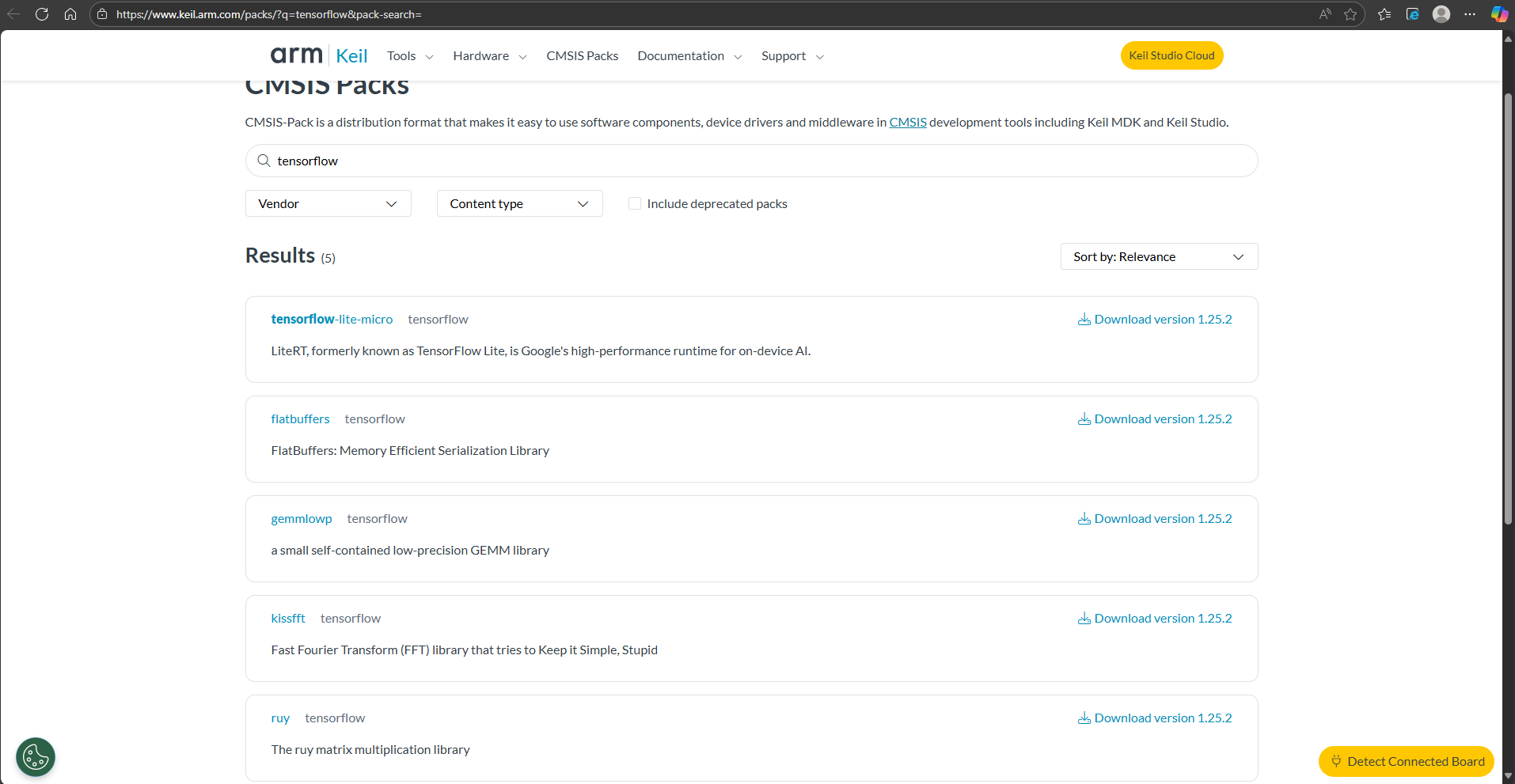
图x 在CMSIS-Pack网站上可下载适用于Keil环境的TensorFlow组件
这些组件的源码存放在Arm线上的软件仓库中,artificial-intelligence / ethos-u / Ethos-U Core Software · GitLab,如图x所示。
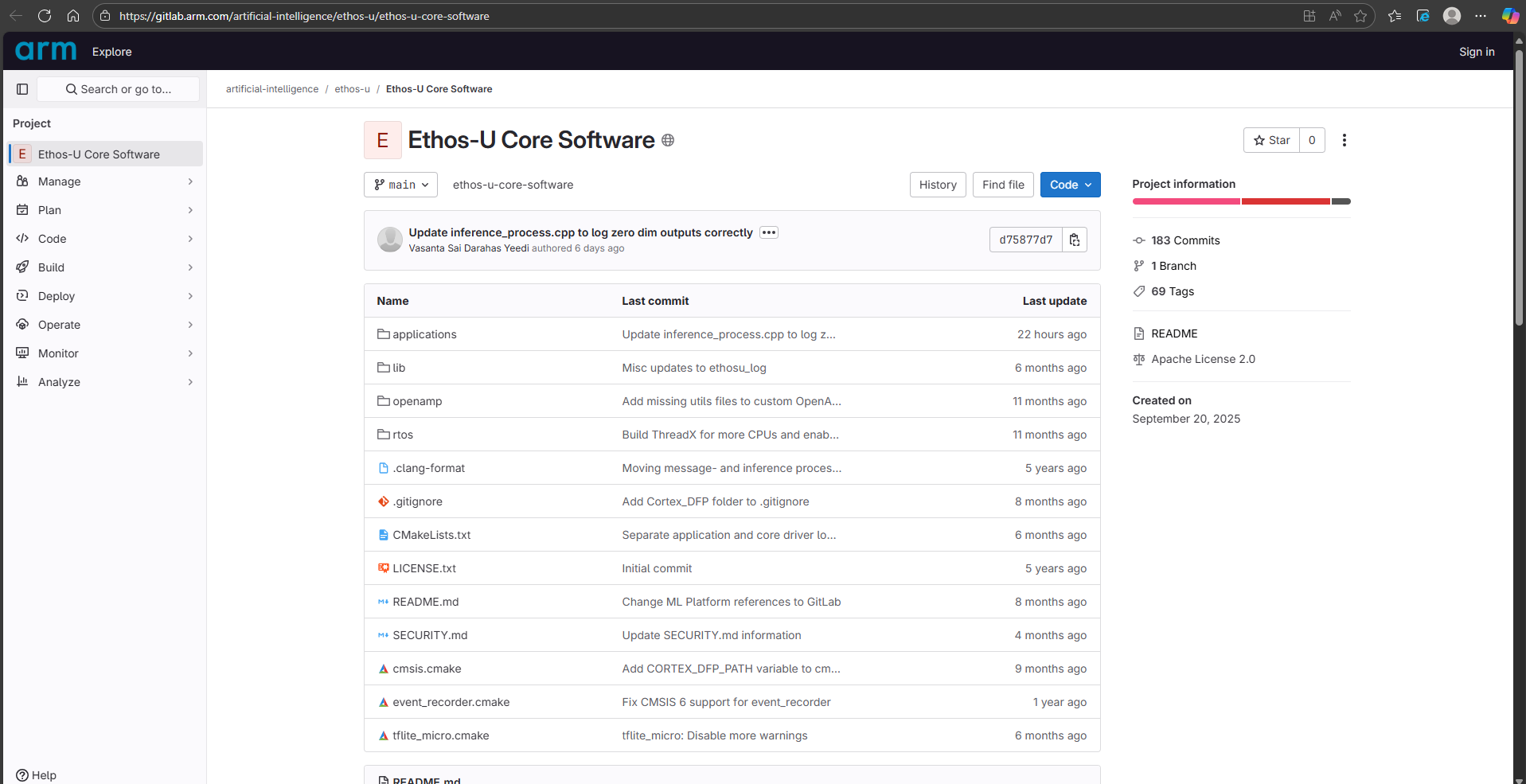
图x Arm开放的Ethos-U driver及相关组件源码
这里涉及的关键组件包括:
- component: Machine Learning:TensorFlow:Kernel&Ethos-U
- component: Arm::Machine Learning:NPU Support:Ethos-U Driver&Generic U55
- component: ARM::CMSIS:DSP&Source
- component: ARM::CMSIS:NN Lib
- component: tensorflow::Data Exchange:Serialization:flatbuffers
- component: tensorflow::Data Processing:Math:gemmlowp fixed-point
- component: tensorflow::Data Processing:Math:kissfft
- component: tensorflow::Data Processing:Math:ruy
- component: tensorflow::Machine Learning:TensorFlow:Kernel Utils
可以通过的 Keil 的软件包管理器导入这些组件。
向嵌入式系统的源码工程中添加 ML 模型
这里介绍两种方式,可以在嵌入式系统中存放 ML 模型:使用文件系统在运行时导入和转换成源码集成至固件中。
将 ML 模型存放在文件系统中
Keil 的 TenserFlow 库可以解析*.tflite文件。当在一个工程的运行过程中需要分别使用多个模型时,这种方法就非常实用。
这里以使用 Keil 软件组件库中的文件系统组件为例,说明导入*.tflite文件的具体操作方法。至于这个文件系统,可以基于SD卡、或者U盘等可插拔的存储设备进行适配。
c
#include "rl_fs.h"
...
FILE *f;
char *buffer;
size_t buffer_size;
// Open the file for reading
f = fopen("/sdcard/my_model_vela.tflite", "r");
if (f == NULL)
{
// Error handling
}
// Get the size of the file and allocate a buffer
fseek(f, 0, SEEK_END);
buffer_size = ftell(f);
rewind(f)
buffer = malloc(buffer_size + 1); // +1 for the null terminator
if (buffer == NULL)
{
// Error handling
fclose(f);
return;
}
// Read the file into the buffer
size_t num = fread(buffer, 1, buffer_size, f);
if (num != buffer_size)
{
printf("Failed to read file\n");
}
else
{
buffer[buffer_size] = '\0'; // Null-terminate the string
printf("File contents: %s\n", buffer);
fclose(f);
const tflite::Model* model = ::tflite::GetModel(buffer);
free(buffer);
...其中,将模型文件的原始内容读取到缓冲区变量buffer中,然后使用::tflite::GetModel(buffer)函数,将缓冲区中存放的无格式的内容提取成tflite::Model类型的对象,以便于后续使用模型的功能(例如,推理操作)。
但是,使用这种方法,加载模型文件需要大量内存,并不适合所有系统设计。这种使用模型的典型场景是基于某些资源丰富硬件的测试系统,在该系统中,需要加载许多不同的模型变体以进行性能分析。即使硬件目标上提供了文件系统,开发者可能也希望将模型与应用程序一起存储在只读存储器(ROM)中。那么,也可以考虑使用接下来介绍的方法。
将模型编译到固件同应用程序一道下载至 flash 中
这种开发方法,是将*.tflite文件中的内容转换成C语言的符号,然后同应用程序的源码一起编译集成到固件中去。此处,可以使用hex文件转换工具,例如xxd,将二进制的*.tflite文件转换成 C 语言的头文件my_network_model.h:
python
xxd -i my_model_vela.tflite my_network_model.h为了确保在 ROM 中存放的模型数据是 16 字节对齐存放的,可以如下方式在C源码中定义表示模型的数组network_model:
c
const unsigned char network_model __ALIGNED(16)
{
...
}然后,在应用工程的源码中,引用my_network_model.h头文件,并通过调用 API 的方式导入模型,源码如下:
c
#include "my_network_model.h"
...
const tflite::Model* model = ::tflite::GetModel(network_model);
...在嵌入式工程中调用 TFLM 的 API 运行 ML 模型
本节中解释了如何在嵌入式工程的源码中调用 TFLM 的 C++ API 实现一个典型的 ML 模型应用。在该应用中,将执行输入Tensor、预处理,并输出推理结果等。
首先,在应用程序中需要先初始化 Ethos-U NPU硬件,调用ethosu_driver.c文件中的 ethosu_init()函数。这个函数通常在嵌入式工程中的初始化硬件的过程中被调用。一旦对 Ethos-U NPU 完成了初始化,就可以基于 Keil 的 TensorFlow Lite 运行时组件(已经集成了对 Ethos-U NPU 的支持)访问 Ethos-U NPU 了。如下源码展示了使用 TLFM 使用 Ethos-U NPU的资源:
c
#include "tensorflow/lite/micro/micro_mutable_op_resolver.h"
#include "tensorflow/lite/micro/tflite_bridge/micro_error_reporter.h"
#include "tensorflow/lite/micro/micro_interpreter.h"
#include "tensorflow/lite/schema/schema_generated.h"
// Include your model data. Replace this with the header file for your model.
#include "model.h"
// Define the number of elements in the input tensor
#define INPUT_SIZE 300*300
using MyOpResolver = tflite::MicroMutableOpResolver<10>;
// Replace this with your model's input and output tensor sizes
const int tensor_arena_size = 2 * 1024;
uint8_t tensor_arena[tensor_arena_size] __align(16);
void RunModel(int8_t* input_data)
{
tflite::MicroErrorReporter micro_error_reporter;
tflite::ErrorReporter* error_reporter = µ_error_reporter;
const tflite::Model* model = ::tflite::GetModel(g_model);
MyOpResolver op_resolver;
// Register your model's operations here
tflite::MicroInterpreter interpreter(model, op_resolver, tensor_arena, tensor_arena_size, error_reporter);
interpreter.AllocateTensors();
TfLiteTensor* input = interpreter.input(0);
// Add checks for input tensor properties here if needed
// Copy image data to model's input tensor
for (int i = 0; i < INPUT_SIZE; ++i)
{
input->data.int8[i] = input_data[i];
}
TfLiteStatus invoke_status = interpreter.Invoke();
// Add checks for successful inference here if needed
TfLiteTensor* output = interpreter.output(0);
// Add checks for output tensor properties here if needed
// Process your output value here
// For example, SSD models typically produce an array of bounding boxes
}在RunModel()函数中,创建了推理器interpreter,将解析好的模型和传入的参数转入推理器中,通过interpreter.Invoke()方法执行推理,并通过interpreter.outout(0)获取指向推理结果Tensor的指针,接下来,开发者就可以通过TfLiteTensor类型的指针output查看推理结果,并做出进一步动作了。
至于如何自己的创建模型,可以参考 Build and convert models | Google AI Edge | Google AI for Developers 中描述的开发过程。或者使用 Arm 的 GitHub - Arm-Examples/ML-zoo 中的模型。