前言
日常很多应用、小程序都提供有文字识别功能,导致不少项目业主也会提这方面需求,但在线就意味着付费,本人在前面分享过一个在线调用百度OCR识别表格的应用工具也是付费的(一天免费调用50次,只够做免费调研),本篇将分享python自带的可离线使用的中文识别(cnocr)环境的搭建。
概述
之所以选择python,是因为python上有很多封装好的人工智能模块,通过简单的在线下载即可完成环境的搭建。
环境搭建
1、下载python
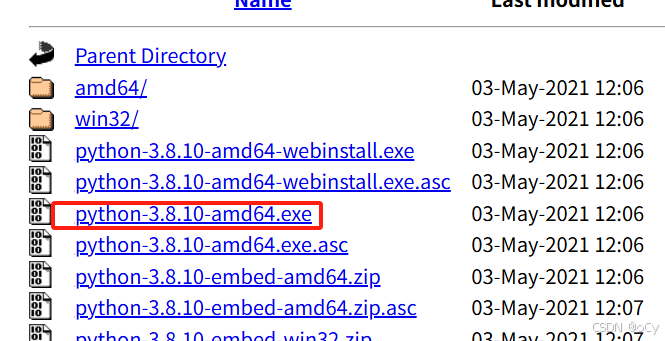
安装cnocr必须在python 3.8版本以上,本篇使用的是python 3.8.10。下载地址:
https://registry.npmmirror.com/binary.html?path=python/3.8.10/
64位window选择python-3.8.10-amd64.exe(python是吃性能的,如果用window作为服务器端部署,建议还是得用64位的系统)
2、创建python虚拟环境
装完python之后,如果只是体验,是可以不需要创建虚拟环境的,但下一篇我会分享怎么把python程序打包成.exe程序,使用虚拟环境才能达到"瘦身"效果。
python虚拟环境会以目录形式存在,我把虚拟环境放在D:\python目录下。
打开cmd命令窗口,进入D:\python目录,执行以下命令创建并激活虚拟环境
# 创建虚拟环境
python -m venv cnocr_env
# 激活虚拟环境
cnocr_env\Scripts\activate激活之后,如下图,在目录前面有虚拟环境的标识

3、升级pip
安装python3.8.10自带安装的pip不是最新版本的,无法下载cnocr,更新命令如下:
python -m pip install --upgrade pip
#如果以上命令报错就执行下面的命令
python -m pip install --upgrade pip --force-reinstall执行命令如果有问题,需要多执行几次。
4、安装 CnOCR
要关联下载的东西比较多,官网安装容易中断,下面用国内的镜像
pip install cnocr -i https://pypi.tuna.tsinghua.edu.cn/simple5、写代码测试
我在虚拟场景下创建了core目录存放python代码,代码内容如下
from cnocr import CnOcr
print('============1===========')
ocr=CnOcr()
print('============2===========')
result=ocr.ocr('./123.png')
print('============3===========')
print(result)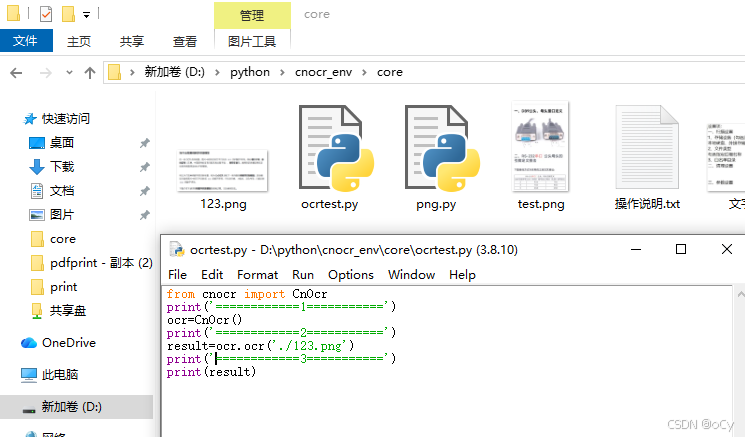
首次运行会报错未发现"onnxruntime"模块,onnxruntime是一个用于运行 ONNX(Open Neural Network Exchange)模型的 高性能推理引擎。它是 Python 的一个模块,专门用于在各种硬件平台上高效地执行深度学习模型。
6、安装onnxruntime
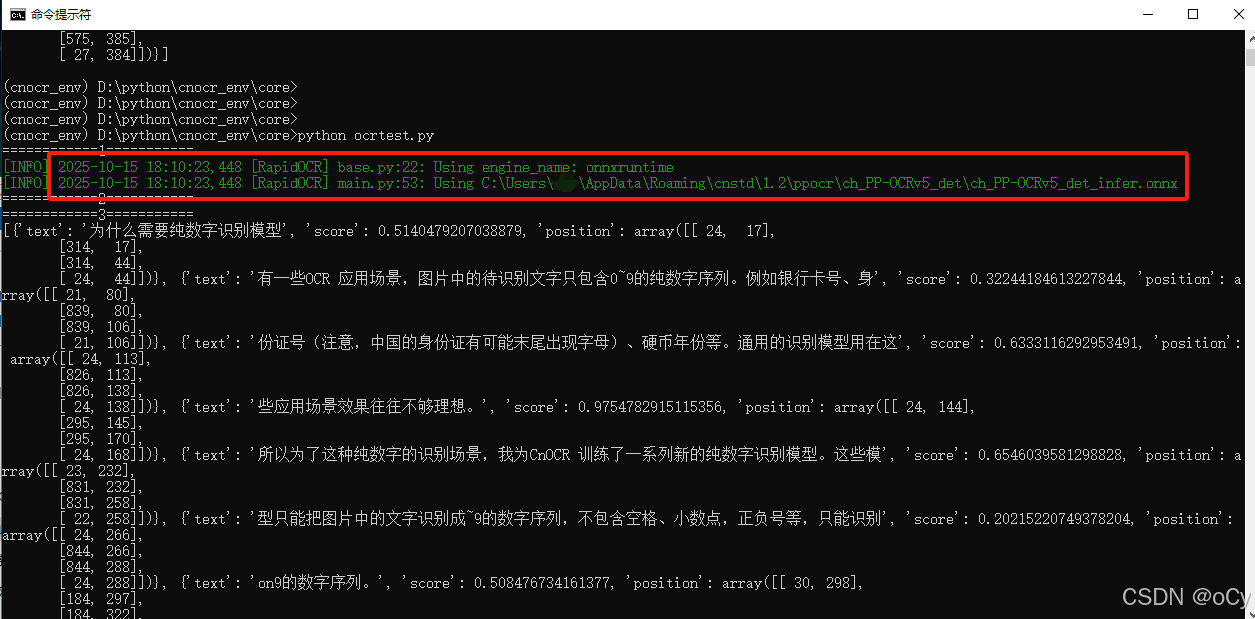
pip install onnxruntime -i https://mirrors.aliyun.com/pypi/simple/下载完成后,自动下载了一个训练好的模型ch_PP-OCRv5_det_infer.onnx,重新运行测试程序,可以看到有信息提示:
[INFO] 2025-10-15 18:06:41,321 [RapidOCR] base.py:22: Using engine_name: onnxruntime
[INFO] 2025-10-15 18:06:41,337 [RapidOCR] main.py:53: Using C:\Users\xxxx\AppData\Roaming\cnstd\1.2\ppocr\ch_PP-OCRv5_det\ch_PP-OCRv5_det_infer.onnx如下图所示,可以在提示的目录中找到ch_PP-OCRv5_det_infer.onnx
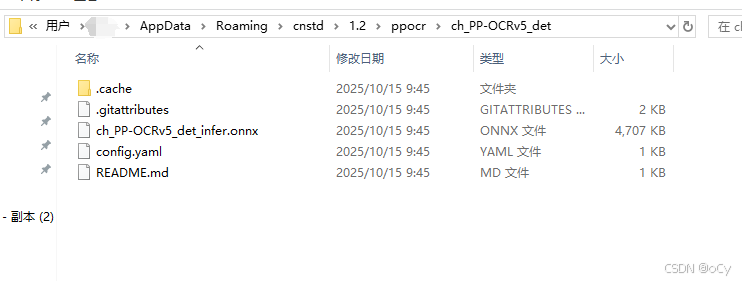
篇尾
以上安装的cnocr包含的ch_PP-OCRv5_det_infer.onnx模型,是百度飞桨(PaddlePaddle)框架的OCR工具库PaddleOCR 最新的文本检测模型之一**,**百度的AI接口平台也是基于PaddlePaddle提供的AI模型范围,所以准确度是有保障的,符合离线部署需求场景。
另外也分享下基于PaddleOCR的一个离线exe应用,功能比较丰富
https://gitcode.com/GitHub_Trending/um/Umi-OCR?source_module=search_result_repo